
时敏目标的类型与瞄准点识别算法
2022-05-18 10:47:01吴晗张志龙李楚为李航宇
航空兵器 2022年2期
吴晗 张志龙 李楚为 李航宇






摘 要: 深度卷积神经网络模型在很多计算机视觉应用中取得了非常出色的结果,如何利用深度学习技术完成复杂战场环境下的辅助制导和瞄准点定位,是我军赢得现代信息化战争的关键。针对该问题,本文提出了一种时敏目标的类型与瞄准点识别算法,用于改善对时敏目标检测的质量,并为后续模块提供作战军事资源各个部件的打击价值。该算法对YOLOv3主干网络进行重新设计,使用深度可分离卷积神经网络的残差块对输入图像进行特征提取,然后将得到的特征图送入注意力模型,为含有目标部件等重要语义信息的特征图赋予相应的权值,最后将经注意力机制模型处理后的特征图送入回归网络进行时敏目标的类型与瞄准点识别。在COCO与VOC数据集上的实验结果表明,本文算法使用的特征提取网络与注意力模型有效提升了深度卷积神经网络对常见目标的检测精度(mAP); 在所建立的战场军事资源模型数据集上的实验结果表明,本文算法可实现对非合作时敏目标的瞄准点精准识别。
关键词: 时敏目标; 目标检测; 瞄准点识别; 深度学习; 注意力模型; YOLOv3; 神经网络
中图分类号: TJ760; TN957.51
文献标识码: A
文章编号: 1673-5048(2022)02-0024-06
DOI: 10.12132/ISSN.1673-5048.2020.0260
0 引 言
战场目标是指复杂战场环境下需要打击的作战对象,特指在一定的时间与空间范围内存在,具有重要战略、战役或战术价值的实体目标。时敏目标是指必须在有限的攻击窗口内发现、定位、识别和瞄准的目标。时敏目标瞄准点选择是指依据我方作战目的、武器装备性能及所获取的战场情报资料,在战时国际法的框架约束内,对战场时敏目标进行检测、分析、评估、排序后,从中选出重点打击目标的过程。
随着人工智能技术的兴起,大量具有一定自主意识的人工智能载体被投入到复杂战场环境中辅助作战,人们希望研究智能化程度较高的目标检测识别算法,准确智能地从人工智能侦察设备摄取的序列图像中发现各类移动目标,并输出提示或告警信息,以缓解操作员的心理负担。
时敏目标的瞄准点识别过程实质为目标检测任务中的部件识别过程。在现代信息化战争中,战场局势瞬息万变,不同的战术作战军事资源的各个部件具有不同的打击价值,如何有效地进行时敏目标的瞄准点识别是锁定并制导摧毁目标的关键步骤。
目标检测是计算机视觉领域中一个重要的研究方向,不同于图像分类与语义分割任务,目标检测任务既需要识别复杂背景下的目标类别,也需要回归目标边界框位置信息。传统意义上的目标检测算法主要分为两类: 基于目标结构知识的启发式方法与基于特征的方法。
启发式方法是根据目标的结构知识提出的,往往针对目标的一些特殊结构,采取滤波的方法,进行相应的特征提取。提取的特征包括直线特征、点特征和特殊结构特征等。例如,在飛机检测方面,利用飞机结构知识建立的圆周频率滤波算法[1]和数学形态学滤波算法来进行飞机检测; 在舰船检测方面,通过分析线段的空间关系检测港内舰船[2], 通过尾迹检测舰船,基于形状上下文检测舰船[3]; 在车辆检测方面,利用运动信息检测图像中的运动目标[4]等。
基于特征的目标检测算法是通过在空域或变换域中提取特征来描述图像,以达到对目标检测识别的目的。常见的空域特征应用包括: HOG特征用于行人检测[5]; Haar-like特征用于物体检测和实时的人脸检测[6]; SIFT特征用于描述机场,并用一种特征点匹配的方法进行目标检测[7]等。常见的变换域方法包括: Ridgelet变换、小波变换、Gabor变换等,Ridgelet变换检测道路边缘,离散小波变换在SAR图像中检测舰船等。虽然传统意义上的目标检测算法可在计算资源占用较小的情况下实现检测识别,但在复杂背景条件下,其整体识别率不高、泛化能力不强且鲁棒性较弱[8]。
在2012年的ImageNet竞赛中,AlexNet[9]算法在图像分类领域取得了质的飞跃,其将一千类图像的分类正确率提升至84.7%。自此,深度学习(Deep Learning)就开始被广泛地应用于目标检测识别任务。无论是以Faster R-CNN[10]和Mask R-CNN[11]为代表的双阶段目标检测算法,还是以SSD[12]和YOLO[13]为代表的单阶段目标检测算法,都在大规模目标检测数据集上取得了优秀的识别性能。针对单/双阶段目标检测算法的检测速率与精度平衡问题,Tian等提出的FCOS算法[14]采用语义分割的思想来实现目标检测任务,其基于Anchor-free的策略能在节省大量计算资源的情况下获得较高的目标检测识别率。
深度学习中的注意力机制借鉴了人脑系统处理大量冗余信息的视觉注意力思维方式[15],即视觉信息处理过程中着重关注包含信息量最为丰富的区域,抑制次要区域信息对整体的影响。Hu等的SE模型[16]通过对深度网络提取的特征图进行压缩与释放操作,使得深度模型给予高响应通道特征更大权值。Woo等的CBAM模型[17]通过对深度网络提取的特征图进行池化与并行编码,使得特征图中对应语义信息丰富的区域得到更高程度的响应,这种策略让网络模型可在额外占用一定计算资源的情况下,提高目标检测的识别精度。
本文提出了一种时敏目标的类型与瞄准点识别算法。该算法对YOLOv3主干网络进行重新设计,使用深度可分离卷积神经网络的残差块对输入图像进行特征提取,然后将得到的特征图送入注意力模型,其对含有目标部件等重要语义信息的特征图赋予相应的权值,最后将经注意力模型处理后的特征图送入回归网络进行时敏目标的类型与瞄准点识别。经注意力机制处理后的深度模型可更加关注输入图像中包含目标部件等重要语义信息的区域,从而可实现高精度、鲁棒性强的时敏目标瞄准点识别。
1 相关工作
瞄准点识别的过程实质是目标的部件识别过程。目前主流的部件识别算法仍是将目标部件作为一种目标类型,经过标注、训练等强监督学习步骤后,分类与回归出目标的类型与边界框信息。虽然这类方法可在一定程度上取得较好的部件检测性能,但仍陷入了单/双阶段目标检测算法的检测速率与精度平衡问题,且由于没有利用特征图中目标各个部件的上下文信息,其检测精度有待进一步提升。
针对上述算法的问题,有学者提出了基于目标关键点特征的部件检测算法[18-19],其利用目标部件之间的相互位置关系来提升目标部件的识别性能。如图1所示,这类算法首先将目标部件视为关键点特征,并且利用级联深度卷积神经网络,实现包含丰富语义信息的目标关键位置检测,然后利用这些关键位置定位结果来优化Faster R-CNN候选框筛选机制和输出策略,从而降低了目标检测模型的网络复杂度,实现较高精度的部件检测性能。这类算法虽然可以实现较高鲁棒性的目标检测,但是,其并未有效降低算法所需的计算资源,而由于Faster R-CNN算法检测速度过于缓慢,更难以满足复杂战场环境下嵌入式设备部署所需求的高效性与实时性。
在保证目标检测精度的基础上,尽可能地提升时敏目标瞄准点检测识别的速率,本文提出了一种基于注意力机制的部件识别算法,通过对含有目标部件等重要语义信息的特征图赋予相应的权值,网络最终的输出会更多地受到输入图像中目标部件的影响。由于特征提取网络与回归网络处于一个端到端的模型之中,并且所使用的通道注意力机制可在不占用额外计算资源的情况下自学习特征响应,因此,本文算法可以在高算力設备支持下实现实时目标检测。
2 网络结构的设计
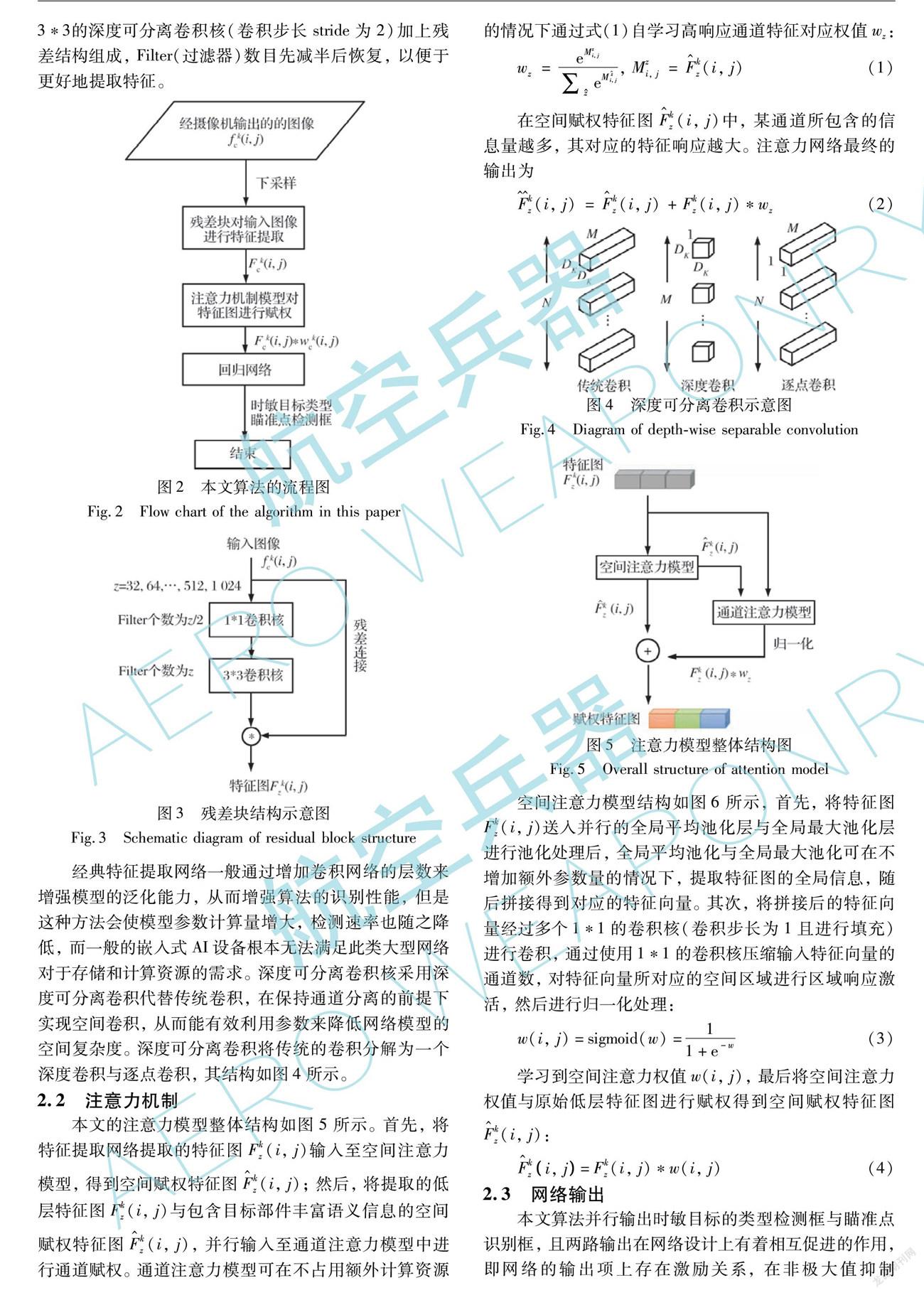
本文算法采用瓶颈结构(Bottleneck)所构成的残差块,对输入图像进行特征提取; 然后将得到的特征图送入注意力模型,其对含有目标部件等重要语义信息区域的特征图呈现高响应回归; 最后将注意力模型处理后的特征图送入常用分类回归网络,进行时敏目标的类型与瞄准点识别。其整体流程图如图2所示。
2.1 特征提取
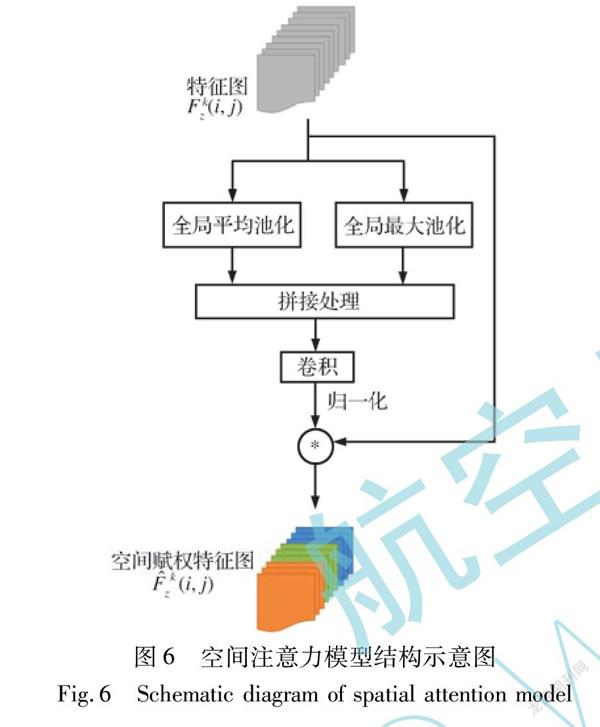
本文算法所设计的特征提取网络包含多个残差块,其将可见光域的图像集合中的某图像fkc(i, j)进行多层次
特征提取得到特征图Fkz(i, j)。如图3所示,每个残差块由1*1的深度可分离卷积核(卷积步长stride为1)和3*3的深度可分离卷积核(卷积步长stride为2)加上残差结构组成,Filter(过滤器)数目先减半后恢复,以便于更好地提取特征。
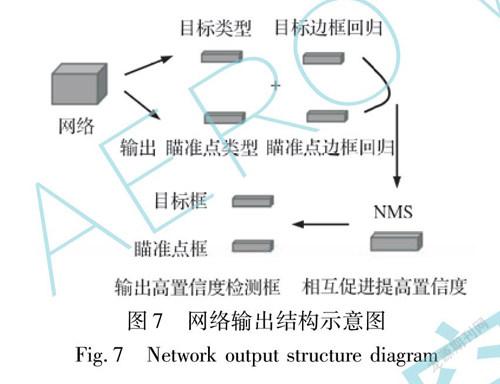
经典特征提取网络一般通过增加卷积网络的层数来增强模型的泛化能力,从而增强算法的识别性能,但是这种方法会使模型参数计算量增大,检测速率也随之降低,而一般的嵌入式AI设备根本无法满足此类大型网络对于存储和计算资源的需求。深度可分离卷积核采用深度可分离卷积代替传统卷积,在保持通道分离的前提下实现空间卷积,从而能有效利用参数来降低网络模型的空间复杂度。深度可分离卷积将传统的卷积分解为一个深度卷积与逐点卷积,其结构如图4所示。
2.2 注意力机制
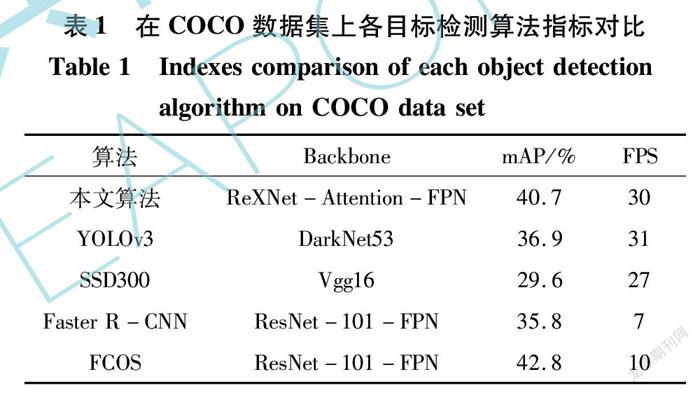
本文的注意力模型整体结构如图5所示。首先,将特征提取网络提取的特征图Fkz(i, j)输入至空间注意力模型,得到空间赋权特征图F^kz(i, j); 然后,将提取的低层特征图Fkz(i, j)与包含目标部件丰富语义信息的空间赋权特征图F^kz(i, j),并行输入至通道注意力模型中进行通道赋权。通道注意力模型可在不占用额外计算资源的情况下通过式(1)自学习高响应通道特征对应权值wz:
wz=eMzi, j∑z^ eMi, jz^, Mzi, j=F^kz(i, j)(1)
在空间赋权特征图F^kz(i, j)中,某通道所包含的信息量越多,其对应的特征响应越大。注意力网络最终的输出为
F^^kz(i, j)=F^kz(i, j)+Fkz(i, j)*wz (2)
空间注意力模型结构如图6所示,首先,将特征图Fkz(i, j)送入并行的全局平均池化层与全局最大池化层进行池化处理后,全局平均池化与全局最大池化可在不增加额外参数量的情况下, 提取特征图的全局信息,随后拼接得到对应的特征向量。其次,将拼接后的特征向量经过多个1*1的卷积核(卷积步长为1且进行填充)进行卷积,通过使用1*1的卷积核压缩输入特征向量的通道数,对特征向量所对应的空间区域进行区域响应激活,然后进行归一化处理:
w(i, j)=sigmoid(w)=11+e-w(3)
学习到空间注意力权值w(i, j),最后将空间注意力权值与原始低层特征图进行赋权得到空间赋权特征图F^kz(i, j):
F^kzi, j=Fkz(i, j)*w(i, j)(4)
2.3 网络输出
本文算法并行输出时敏目标的类型检测框与瞄准点
识别框,且两路输出在网络设计上有着相互促进的作用,即网络的输出项上存在激励关系,在非极大值抑制(NMS)模块中,时敏目标的瞄准点识别框将用于修正时敏目标的类型检测框,从而使目标领域内的置信度更高。反之亦然,其结构如图7所示。
3 实验结果分析
本文实验采用的硬件平台为: Intel i5-9400 CPU@ 2.90 GHz; 两块NVIDIA 2080TI显卡(11 G)、 16 GB内存; 操作系统为Ubuntu 16.04; 深度学习框架为Pytorch与Tensorflow; 配置环境为CUDA 10.0, CUDNN 7.4。
3.1 目标检测实验结果分析
为了验证本文算法对时敏目标类型检测的适用性与性能,关闭网络的瞄准点识别框输出通道,并且在公开的Microsoft Common Objects in Context (COCO)数据集[20]与PASCAL-VOC2012数据集[21]上开展目标检测精度评估实验。其中所使用的COCO数据集包含80个目标类别,81 769张图像作为训练集, 10 126张图像作为验证集, 11 348张图像作为测试集,平均每幅图像有5个标签信息。所使用的VOC数据集包含20个目标类别,总共包含5 515张图像,平均每幅图像有2个标签信息。目标检测精度评估实验过程中的VOC数据集划分为: 4 000张图像作为训练集,415张图像作为验证集,1 100张图像作为测试集。
在目標检测精度评估实验过程中,本文算法使用的分类回归网络是YOLOv3算法中的YOLO-head结构。表1与表2分别展示了在COCO数据集与VOC数据集上,本算法与当前主流目标检测算法的目标检测精度(COCO数据集测试IOU=0.75下的mAP; VOC数据集测试IOU=0.5下的mAP)与速度(FPS: 每秒检测图像数)对比。实验结果表明: (1)与当前主流目标检测算法相比,本文算法具有较好的目标检测性能; (2)本文算法可在提升目标检测精度的同时保证检测速率,基本可以满足复杂战场环境下嵌入式设备部署所需求的高效性与实时性。
3.2 瞄准点识别实验结果分析
采用本实验室所制备的战场军事资源模型数据集,该数据集包含18种战场军事资源模型,包含履带、顶盖与车轮三种瞄准点标注信息。数据集划分情况为: 1 010张图像作为训练集,144张图像作为验证集,289张图像作为测试集,分辨率均为1 920×1 080。
在瞄准点识别算法的训练过程中,对训练数据采用数据增强处理。对训练样本采取平移、翻转、选择、饱和度变换与颜色变换等,从而让有限的训练样本产生更大的训练价值,使得神经网络具有更强的泛化能力。
在深度学习的研究中,利用类别激活图(CAM)[22]的梯度权重激活映射,对卷积神经网络的分类与回归结果进行解释,因为其可以在输入的图片中粗略地显示出模型预测出的类别所对应的重要性区间。
本文在战场军事资源模型数据集上开展对时敏目标的类型与瞄准点识别评估,分三个部分进行实验:
(1) 将本文注意力模型级联的特征提取网络的输出与仅作特征提取的残差块输出做CAM可视化分析,结果如图8所示。CAM可视化结果表明,经过注意力机制改进的神经网络模型最终的输出结果,将受到包含目标部件等关键信息区域的影响。
(2) 在本文建立的战场军事资源模型数据集上,开启/关闭网络的瞄准点识别框输出通道,进行瞄准点识别模型的训练与对比测试。表3显示了本文算法多路输出和单路输出的部件检测精度(测试IOU=0.5下的mAP)与速度(FPS: 每秒检测图像数)对比,可以看出,本文算法的目标类型与瞄准点识别过程具有相互促进作用。
(3) 在本文建立的战场军事资源模型数据集上进行瞄准点识别模型的训练与测试。表4显示了本文算法与基于目标关键点特征的部件检测算法[17]等的部件检测精度(测试IOU=0.5下的mAP)与速度(FPS: 每秒检测图像数)对比。可以看出,本文算法具有较好的瞄准点识别综合性能。
图9展示了本文算法在测试集上的目标瞄准点识别结果。可以看出,在输入图像含多个目标重要部件的情况下,本文算法仍具有良好的瞄准点识别效果。
4 结 论
本文提出了一种时敏目标的类型与瞄准点识别算法。该算法可在不额外占用计算资源的情况下,通过注意力模型自学习高响应特征来影响神经网络模型最终的分类与回归结果。在公开的COCO数据集、VOC数据集与本文建立的战场军事资源模型数据集上进行实验,结果表明: 本文算法可在提升目标检测精度的同时,保证检测速率; 在输入图像包含多个目标部件的情况下,本文算法仍具有良好的瞄准点识别效果。下一步将继续优化瞄准识别算法的特征提取网络结构,以实现在复杂背景条件下的目标多类瞄准点特征的自适应提取。
参考文献:
[1] An Z Y, Shi Z W, Teng X C, et al. An Automated Airplane Detection System for Large Panchromatic Image with High Spatial Resolution[J]. Optik, 2014, 125(12): 2768-2775.
[2] Lin J L, Yang X B, Xiao S J. A Line Segment Based Inshore Ship Detection Method[C]∥ International Conference on Remote Sen-sing, 2010: 261-269.
[3] Sreedevi Y, Reddy B E. Ship Detection from SAR and SO Images[C]∥ International Conference on Advances in Computing, 2013: 1027-1035.
[4] Kirchhof M, Stilla U. Detection of Moving Objects in Airborne Thermal Videos[J]. ISPRS Journal of Photogrammetry and Remote Sensing, 2006, 61(3/4): 187-196.
[5] Dalal N, Triggs B. Histograms of Oriented Gradients for Human Detection[C]∥IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 2005: 886-893.
[6] Viola P, Jones M J. Robust Real-Time Face Detection[J]. International Journal of Computer Vision, 2004, 57(2): 137-154.
[7] Tao C, Tan Y H, Cai H J, et al. Airport Detection from Large IKONOS Images Using Clustered SIFT Keypoints and Region Information[J]. IEEE Geoscience and Remote Sensing Letters, 2011, 8(1): 128-132.
[8] Girshick R, Donahue J, Darrell T, et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2014: 580-587.
[9] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[C]∥Advances in Neural Information Processing Systems , 2012: 76-83.
[10] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[C]∥IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015: 1137-1149.
[11] He K M, Gkioxari G, Dollar P, et al. Mask R-CNN[C]∥IEEE International Conference on Computer Vision (ICCV) , 2017.
[12] Liu W, Anguelov D, Erhan D, et al. SSD: Single Shot MultiBox Detector[C]∥European Conference on Computer Vision, 2016: 21-37.
[13] Redmon J, Divvala S, Girshick R, et al. You only Look Once: Unified, Real-Time Object Detection[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 779-788.
[14] Tian Z, Shen C H, Chen H, et al. FCOS: Fully Convolutional One-Stage Object Detection[C]∥IEEE/CVF International Conference on Computer Vision (ICCV), 2019: 9626-9635.
[15] 李楚為, 张志龙, 杨卫平. 结合布尔图和灰度稀缺性的小目标显著性检测[J]. 中国图象图形学报, 2020, 25(2): 267-281.
Li Chuwei, Zhang Zhilong, Yang Weiping. Salient Object Detection Method by Combining Boolean Map and Grayscale Rarity[J]. Journal of Image and Graphics, 2020, 25(2): 267-281.(in Chinese)
[16] Hu J, Shen L, Albanie S, et al. Squeeze-and-Excitation Networks[C]∥IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018: 2011-2023.
[17] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional Block Attention Module[C]∥European Conference on Computer Vision, 2018: 3-19.
[18] 吴建雄. 基于卷积神经网络的车辆部件检测[D]. 武汉: 华中科技大学, 2017.
Wu Jianxiong. Detection of Vehicle Parts Based on Convolution Neural Network[D]. Wuhan: Huazhong University of Science and Technology, 2017. (in Chinese)
[19] 舒娟. 基于深度學习的车辆部件检测[D]. 武汉: 华中科技大学, 2017.
Shu Juan. Vehicle Component Detection Based on Deep Learning[D]. Wuhan: Huazhong University of Science and Technology, 2017. (in Chinese)
[20] Lin T Y, Maire M, Belongie S, et al. Microsoft COCO: Common Objects in Context[C]∥European Conference on Computer Vision, 2014.
[21] Everingham M, van Gool L, Williams C K I, et al. The Pascal Visual Object Classes (VOC) Challenge[J]. International Journal of Computer Vision, 2010, 88(2): 303-338.
[22] Zhou B L, Khosla A, Lapedriza A, et al. Learning Deep Features for Discriminative Localization[C]∥IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016: 2921-2929.
Recognition Algorithm for Types and Aiming
Points of the Time-Sensitive Target
Wu Han, Zhang Zhilong*, Li Chuwei, Li Hangyu
(National Key Laboratory of Science and Technology on ATR,
National University of Defense Technology, Changsha 410073, China)
Abstract: Deep convolutional neural network model has achieved excellent results in many computer vision applications. How to use deep learning technology to complete auxiliary guidance and aiming points positioning in complex battlefield environment is the key for army to win the modern information war. To solve this problem, this paper proposes a recognition algorithm for types and aiming point of the time-sensitive target to improve the quality of time-sensitive target detection, and provides the strike value of various components of military resources for subsequent modules. This algorithm redesigns the YOLOv3 trunk network and uses the residual block of the depth-wise separable convolutional neural network to extract the features of the input image, then sents the obtained feature maps into the attention model, and assigns corresponding weights to feature maps with important semantic information such as target components. Finally, feature maps processed by the attention model is sent into the regression network for the recognition of time-sensitive target types and aiming points. The experimental results on COCO and VOC data sets show that the feature extraction network and attention module used in this algorithm effectively improve the mean average precision of deep convolutional neural network in common target detection. The experimental results on the data set of the battlefield military resource model established in this paper show that this algorithm can accurately recognize the aiming points of non-cooperative time-sensitive targets.
Key words: time-sensitive targets; target detection; aiming point recognition; deep learning; attention model; YOLOv3; neural network
猜你喜欢
电子制作(2019年19期)2019-11-23 08:42:00
软件(2016年4期)2017-01-20 09:38:03
科教导刊·电子版(2016年28期)2017-01-10 22:25:23
新教育时代·教师版(2016年23期)2016-12-06 06:02:38
法制与社会(2016年32期)2016-12-01 15:25:53
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
科学与财富(2016年28期)2016-10-14 23:45:18
重型机械(2016年1期)2016-03-01 03:42:04
科技视界(2016年4期)2016-02-22 13:09:19
