
Seq2Seq模型的短期水位预测
2022-05-16 10:30:20康爱卿李建柱雷晓辉
水利水电科技进展 2022年3期
刘 艳,张 婷,康爱卿,李建柱,雷晓辉
(1.天津大学水利工程仿真与安全国家重点实验室,天津 300072;2.中国水利水电科学研究院流域水循环模拟与调控国家重点实验室,北京 100038)
水位预测对水资源的合理开发、利用及优化配置具有重要意义。由于河流水位受多方面因素的影响,变化频繁,因此短期的精细化预测相对中长期的趋势预测更有实际价值。目前,水位预测的研究方法可以归纳为两类,即过程驱动模型和数据驱动模型。过程驱动模型通过有物理依据及经验性的公式,描述水流运动与影响因素的关系,由于影响水位的因素较多,考虑降雨、地形、水工建筑物等的物理模型会十分复杂,模型精度很难达到水位控制要求[1]。数据驱动模型通过挖掘输入与输出数据之间的相关信息进行预测,而不研究物理过程。常用的模型包括以数理统计为基础的时间序列分析,以及以人工神经网络(artificial neural network,ANN)、支持向量机(support vector machine,SVM)为代表的机器学习。已有的研究采用一种或集合多种数据驱动方法建立水位预测模型,并使用遗传算法等优化方法获得最优参数[2-5]。数据驱动模型在水位预测方面取得了丰硕的成果,但仍存在很大的改进空间,如传统SVM模型只能单步输出,以及浅层神经网络不足以充分挖掘数据的所有特征等。
近年来,人工智能和大数据驱动技术给水文研究带来了新的研究思路和技术方法,以深度学习为代表的新一代人工神经网络已经在水文领域进行探索性应用[6]。深度学习是一种特殊的机器学习方法,从简单的线性网络发展到经典的生成式对抗网络(generative adversarial networks,GAN),经历了深度信念网络(deep belief network,DBN)、稀疏编码(sparse coding)、卷积神经网络(convolutional neural network,CNN)、结构递归神经网络(recursive neural network,RNN)的快速迭代[7]。长短期记忆网络(long short-term memory,LSTM)是RNN的改进版,通过引入记忆门控单元缓解梯度消失,是进行时间序列数据仿真模拟及预测的首选。在水位预测方面,LSTM模型受到越来越多的关注,相关研究成果已表明LSTM模型预测精度较高,预测效果优于SVM、RNN等模型[8-14]。然而,现有的大部分研究是预测未来某个时间的水位,而不是水位序列。有少数研究对多步水位进行预测,但没有考虑数据输出的先后顺序。
序列到序列(sequence-to-sequence,Seq2Seq)模型是一种由序列生成序列,且序列长度互不影响的模型,被广泛应用于机器翻译、行为预测等任务中[15-17]。水位序列与语言上下文以及其他时间序列具有相似的特征,但Seq2Seq模型在水位预测方面的研究甚少。因此,本文提出了一种基于Seq2Seq模型的短期多步水位预测模型,以克服上述数据驱动模型存在的不足。以流溪河的水位数据为例,对所提模型进行验证,并与LSTM和ANN模型进行比较,分析评价预测精度和计算效率。
1 研究区及数据处理
1.1 研究区概况
流溪河位于广东省广州市北部,地理位置介于113°10′12″E~114°2′00″E,23°12′30″N~23°57′36″N之间。流溪河是广州市辖区内唯一的一条全流域河流,也是集雨面积最大的河流[18]。河流全长约为171 km,流域面积约为2 300 km2。该流域处于亚热带季风气候区,气候温湿,雨量丰沛。年平均降雨量为1 800 mm,年径流量约为28.4亿m3。84%的降雨集中在汛期(4—9月),有较强的季节性。
流溪河梯级闸坝工程开发力度较大,从上至下共有11座拦河闸坝,依次为良口坝、青年坝、胜利坝、卫东坝、人工湖坝、水厂坝、街口坝、大坳坝、牛心岭坝、李溪坝和人和坝[19]。流溪河是广州市最早的供水水源地,目前仍然是重要的工农业和生活用水水源地,广州市30%的自来水来自流溪河,被誉为广州的“母亲河”。拦河闸坝的修筑对于广州市水资源开发利用发挥着重要作用。本文选取良口坝、大坳坝和李溪坝为研究对象,如图1所示。

图1 流溪河及拦河坝位置示意图
1.2 数据处理
本文采用的数据长度为2014年10月至2020年5月,监测频率为1h,其中,2014年10月至2018年2月为训练期,2018年3月至2020年5月为验证期。
数据质量是影响数据驱动模型效果的关键因素。在建模之前要对原始数据进行预处理,包括数据整理和数据变换。针对水位数据,数据整理主要是噪声数据识别和空缺值填充。噪声数据是指在测量和收集数据时由机器采集或者人为造成的误差。噪声数据远远超过或不及其他数据,明显偏离一般水平,一般将其剔除然后按照空缺值的方法填充。空缺值是指较少且不连续的数据缺失,一般采用平均值、众数等进行填充。考虑到研究对象水位时间间隔较短,对于空缺值采用线性插值的方式处理。数据变换是对数据进行规范化,本文采用标准化算法对模型输入数据进行处理[20],处理后的序列均值为0,标准差为1。计算公式为
(1)

2 模型构建与评价
2.1 模型构建
本文利用历史水位作为输入,预测未来一定时间内的连续水位,因此选用处理时间序列的神经网络。LSTM是RNN的一种特殊类型,可以从隐藏的长期依赖信息中学习[21]。LSTM通过引入门控单元统筹并传递对当前时刻重要的历史信息,提升了循环神经网络的长时间记忆,并保持了训练过程中梯度下降的稳定性。但LSTM的每一个输入都对应一个输出,因此只能处理输入输出序列时序一致的数据。
Seq2Seq模型最初是因机器翻译而诞生,随后被广泛用于处理输出序列长度与输入序列长度无关的相关任务。Seq2Seq模型由编码器和解码器组成,编码器和解码器本质上是循环神经网络。编码器将可变长度序列数据编码为一个固定长度的中间向量,解码器将固定长度的中间向量进行解码作为预测输出,实现了任意长度的输入序列可以映射到任意长度的输出序列的目的。
在实际应用中,编码器和解码器有多种选择,本文选用两个LSTM模块组成Seq2Seq模型对水位进行预测。当输入历史时间序列的长度为n,预测输出时间序列的长度为m时,构造的输入向量X及输出向量Y如下:
X=(X1,X2,X3,…,XN)
(2)
Y=(Y1,Y2,Y3,…,YN)
(3)
Xi=(x1+m(i-1),x2+m(i-1),x3+m(i-1),…,xn+m(i-1))
(4)
Yi=(xn+1+m(i-1),xn+2+m(i-1),xn+3+m(i-1),…,xn+mi)
(5)
式中:N为样本总数;Xi、Yi分别为第i个样本的输入和输出(i=1,2,…,N)。此种输入输出向量构造方法可同时得到一个预测长度的各步长预测结果,避免了使用前一步预测结果作为真实值输入所造成的误差累积。
将样本(X1,Y1)代入Seq2Seq模型中,其中X1=(x1,x2,…,xn)表示输入的历史水位,Y1=(y1,y2,…,ym)表示输出的预测水位。编码器由单层LSTM单元组成,将输入序列按照时间顺序分步读入,每一时刻的隐藏层状态ht都由当前时刻的输入数据xt与上一时刻的隐藏层状态ht-1和细胞状态ct-1共同决定,即
ht=f(xt,ht-1,ct-1)
(6)
式中:ht、ht-1分别为t时刻、t-1时刻编码层的LSTM神经元隐藏层状态;xt为t时刻的输入;ct-1为t-1时刻编码层的LSTM神经元细胞状态。
LSTM单元内部由输入门、遗忘门和输出门组成。首先,遗忘门决定舍弃多少细胞状态ct-1;接下来,输入门决定保留多少当前外部信息(即输入xt),并生成候选细胞状态ct;然后,根据遗忘门和输入门的结果更新细胞状态ct;最后,输出门决定输出细胞状态ct的哪些状态特征,并生成隐藏层状态ht。当t=1时,h0和c0对应编码层起始状态隐藏层的输出,采用0进行初始化。上述过程对应公式如下:
ft=σ(Wf(ht-1,xt)+bf)
(7)
it=σ(Wi(ht-1,xt)+bi)
(8)
(9)
(10)
ot=σ(Wo(ht-1,xt)+bo)
(11)
ot=ottanhct
(12)

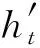
(13)


(14)
式中yt为t时刻的输出。经过分步解码,形成最终的输出序列。
2.2 模型参数设置
对良口坝、大坳坝和李溪坝的逐小时水位进行连续6 h、12 h和24 h的预测,即模型输出长度m分别是6 h、12 h、24 h。深度学习模型参数有两类:一类是可训练参数,通过训练集自动率定,主要是研究方法中提到的权重和偏置;另一类是超参数,根据训练过程中评价指标的结果进行经验调参。Seq2Seq模型的计算步骤及参数设置如下:
步骤1对数据进行预处理。
步骤2设置模型预测目标及输入数据。模型预测长度m分别为6 h、12 h、24 h,模型输入长度n分别设为72 h、168 h、168 h。
步骤3建立编码层与解码层的网络结构。编码层和解码层均为单层LSTM,编码层隐藏层单元数量分别为32、128、128,解码层隐藏层单元数量分别为8、64、64。
步骤4利用训练集的样本训练模型。训练过程以均方误差为损失函数,使用ADAM优化模型参数,学习率为0.001。由于数据集较大,将批量尺寸参数batch-size设置为256,最大训练次数设为200。
步骤5对模型输出进行反归一化处理,得到水位预测结果。
步骤6结果分析。
2.3 评价指标
本文采用纳什效率系数(NSE)、均方根误差(RMSE)和平均绝对误差(MAE)定量评价模型的预测性能,NSE的变化范围从-∞到1,越接近1,拟合越完美,模型可信度越高。同时采用RMSE和MAE衡量模拟值和实测值之间的偏差,变化范围从0到+∞,越接近0,模型整体模拟效果越好。当MAE相等时,RMSE越大,数据离散度越高。
3 结果分析
3.1 整体预测效果评价
选择NSE、RMSE和MAE对Seq2Seq模型在良口坝、大坳坝和李溪坝的短期水位预测结果进行评价,结果见表1。由表1可知:在所有预测时间,MAE均小于0.1 m;NSE均大于0.7,最大值为0.98;RMSE最大值为0.17 m;Seq2Seq模型取得了较好的预测效果。对比同一站点不同预测长度的评价指标结果可以发现,当预测长度为6 h时,NSE均大于0.9,模型的预测效果最佳。随着预测长度的增加,RMSE和MAE不断增大,而NSE不断减小。以良口坝为例,预测长度从6 h增加到24 h时,测试集的NSE降低了0.08,RMSE和MAE分别增加了0.06 m、0.02 m。

表1 各站点预测结果对比
图2给出了3种不同预测长度下各站点测试集的预测与实测水位对比,从中可以看出,Seq2Seq模型能够较好地反映坝上水位随时间的波动趋势。各个站点连续6 h的预测水位与实测水位最接近,连续24 h的预测水位不能很好地再现实测水位涨落过程。Seq2Seq模型对于高水位或低水位(极值)的预测效果相对较差。为了定量分析预测误差大小,计算良口坝水位小于64 m,大坳坝水位大于24 m以及李溪坝水位小于10 m范围内水位预测的最大误差、最小误差和MAE,结果如表2所示。由表2可知,总体上MAE随预测长度的增大而增大。与表1相比,极值预测的MAE远高于全过程的MAE,说明模型整体预测性能较好,但对极值的预测略有不足。这主要是由于影响水位的因素较多,比如闸坝调度、灌溉取水等,只考虑历史水位数据不能很好地呈现水位突变的趋势。

图2 基于Seq2Seq的水位预测对比
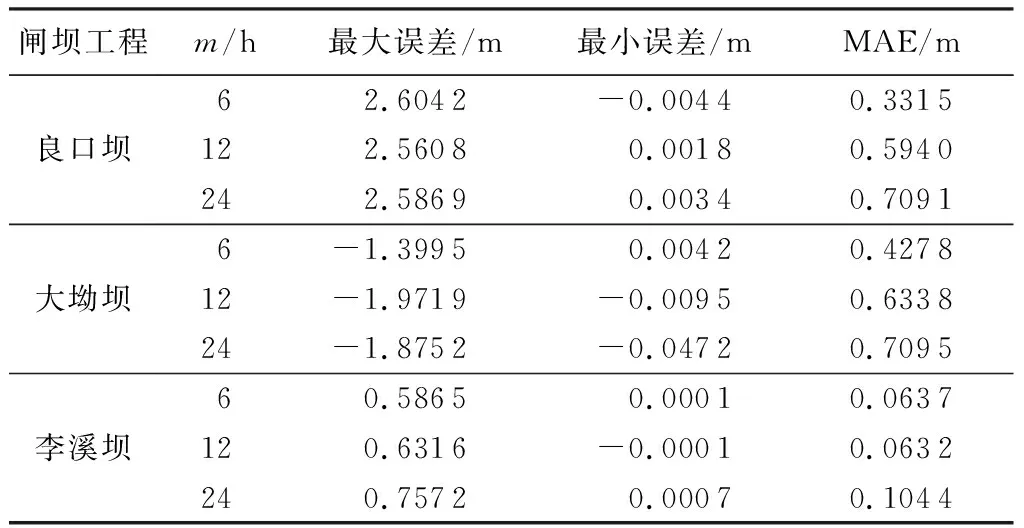
表2 各站点极值的预测误差对比
此外,对于测试集,在预测长度分别为6 h、12 h、24 h的情况下,大坳坝的NSE比良口坝的NSE依次小0、0.07和0.07,李溪坝的NSE比良口坝的NSE依次小0.01、0.08和0.12。结合NSE和水位过程对比可以看出,良口坝的水位预测效果最好,大坳坝次之,李溪坝较差。这是由于从河流上游至下游,随着预测站点到河源的距离增大,影响水位的因素增加;同时,当预测长度增大时,上下游站点之间差异有增大的趋势。
3.2 与LSTM和ANN模型的对比
为了便于模型之间的比较,除Seq2Seq模型外,本文还构建了LSTM模型和ANN模型。ANN模型采用的是最基本的3层结构,即输入层、隐藏层、输出层,又称为全连接神经网络(full connected neural networks, FCNN)[22]。LSTM模型和ANN模型隐藏层的神经元数量与Seq2Seq模型的编码层神经元数量一致,其他参数也与Seq2Seq模型相同。基于测试集,对比分析Seq2Seq、LSTM和ANN模型的预测结果。
图3~5为3种模型在不同预测长度下的评价指标。从图3~5可以看出,ANN模型的NSE均小于0.9,最小值为0.67,RMSE和MAE的最大值分别超过了0.20 m和0.10 m。LSTM和Seq2Seq模型的NSE最小值分别为0.70和0.73,MAE最大值分别为0.09 m和0.08 m,可见这两个深度学习模型各项指标均优于简单神经网络模型。当预测长度为6 h时,Seq2Seq和LSTM模型的各项指标基本相等;当预测长度为12 h时,在良口坝的水位预测中,Seq2Seq模型相对LSTM模型来说,NSE提高了大约0.05,RMSE和MAE分别降低了大约0.03 m和0.01 m,其他站点的各项指标值较为接近;当预测长度为24 h时,Seq2Seq模型在3个站点的各项指标结果均有不同程度的改进。

图3 不同模型预测结果的NSE对比

图4 不同模型预测结果的RMSE对比

图5 不同模型预测结果的MAE对比
LSTM模型和ANN模型预测结果同Seq2Seq模型一样,都表现出随着预测长度的增加,预测性能逐渐下降的特性。对于评价指标值的变化幅度,当预测长度增加到12 h时,Seq2Seq模型预测结果最小,LSTM模型预测结果和ANN模型接近;当预测长度增加到24 h时,ANN模型预测结果最大,Seq2Seq模型在大坳坝和李溪坝预测结果最小,而LSTM模型在良口坝预测结果最小。此外,LSTM和ANN模型受站点位置的影响规律与Seq2Seq模型一致,即中上游站点的预测效果优于下游站点,且下游站点与中上游站点之间的评价指标值差距随着预测长度的增大而增大。
由于ANN模型的预测效果较差,仅对Seq2Seq与LSTM模型的计算效率进行比较。以良口坝为例,在相同环境下两模型完成一次计算的时间如表3所示。由表3可以看出,预测长度为12 h的计算时间大于预测长度为24 h的计算时间,表明神经元数量相同时,样本数越多运行时间越长;预测长度为6 h的计算时间小于预测长度为12 h的计算时间,表明样本数虽多,但神经元数量减少,模型运行时间依然较短。由以上分析可知,样本数和神经元数量都影响计算效率,且神经元数量的影响较大。对比同一预测长度下两模型的计算时间可以发现LSTM模型计算时间更短。图6给出了不同预测长度下两模型的训练过程。由图6可知,Seq2Seq模型的RMSE均小于LSTM。当预测长度为6 h和12 h时,LSTM先收敛;当预测长度为24 h时,Seq2Seq模型的收敛速度较快。大坳坝和李溪坝计算效率的对比结果与良口坝相似。以上对预测精度和计算效率的对比表明,在实际应用中,需根据对精度和效率的要求选择合适的预测模型。

表3 不同模型的计算时间对比

图6 不同模型的训练过程对比
4 结 论
a.基于Seq2Seq模型建立了未来6 h、12 h和24 h的逐小时水位预测模型,使输入与输出的长度设置不受限制,模型训练过程平稳,预测效果较好。
b.当预测长度为6 h、12 h和24 h时,Seq2Seq模型的MAE均小于0.1 m,NSE均大于0.7,表明该模型具有较高的预测精度。同时表现出预测长度越小,评价指标越优的趋势;相同预测长度下,上游水位比中下游水位的预测效果更好。
c.本文测试集ANN模型、LSTM模型和Seq2Seq模型的NSE最小值分别为0.67、0.70和0.73,MAE最大值分别为0.12 m、0.09 m和0.08 m,可见Seq2Seq模型整体效果优于LSTM模型和ANN模型。LSTM模型的计算时间较Seq2Seq模型短,但当预测长度为24 h时,Seq2Seq模型收敛速度更快。
猜你喜欢
数学小灵通(1-2年级)(2020年9期)2020-10-27 03:24:46
电子制作(2019年14期)2019-08-20 05:43:42
国际呼吸杂志(2019年1期)2019-01-28 09:37:02
作文大王·低年级(2017年11期)2017-12-05 00:08:45
小学生学习指导(低年级)(2017年12期)2017-11-22 06:22:39
中国自行车(2017年1期)2017-04-16 02:53:52
故事会(2016年21期)2016-11-10 21:15:15
华东理工大学学报(自然科学版)(2015年1期)2015-11-07 09:15:59
读写算(上)(2015年6期)2015-11-07 07:17:55
河南科技(2014年4期)2014-02-27 14:07:11
