
基于被引位置的数据论文价值分析*
——以数据期刊Scientific Data为例
2022-05-14 06:37王传清黄国彬
图书情报研究 2022年2期
吴 宁 王传清 黄国彬
(1.中国科学院文献情报中心 北京 100190;2.中国科学院大学经济与管理学院图书情报与档案管理系 北京 100190;3.富媒体数字出版内容组织与知识服务重点实验室 北京 100038;4.北京师范大学政府管理学院 北京 100875)
0 引言
“数据论文”是一种特殊的学术论文,它对数据采集过程中数据收集、处理、使用软件、数据内容、数据产生背景和数据质量与结构等元数据进行详细的描述,但不提供分析方法与分析过程,不会产出研究成果与结论。近年来,数据论文获得了出版商、期刊和科研基金资助机构等的大力支持和推广。例如ViBRANT(Virtual Biodiversity Research and Access Network for Taxonomy)和BioFresh(a program to support freshwater biodiversity)获得了欧盟的资助,积极参与数据论文推广,甚至创办了专门发表数据论文的下一代生物多样性数据杂志Biodiversity Data Journal。哥伦比亚的亚力山大洪堡特生物资源研究所(Colombia’s Alexander von Humboldt Biological Resources and Research Institute)也致力于出版数据论文。2012年Wiley发行了Geoscience Data Journal,发表了地理科学的原始数据论文,供同行评议和研究人员获取[1]。自然出版集团于2014年5月推出开放存取的数据期刊Scientific Data,该期刊以出版有科学价值的科学数据为目的,大力推动数据出版进一步发展。
数据论文与传统论文有明显区别,研究人员可以完全公开地阅读数据描述文件、下载原始数据集。然而,数据论文撰写与发表的机制以及相关工具还远远没有获得推广,从丰富的研究元数据生成数据论文,截至目前这种做法仍然只是小众做法。
数据期刊层出不穷,数据论文也不断增多,现代科学已经越来越重视数据共享和重用。科研人员开始广泛引用数据论文,对其内容和数据集进行二次分析,对已有研究结果进行检验和再现,从而减少科研过程中的重复性工作,并以已有研究为基础不断深化,得到更进一步的研究结论[2]。数据论文的引用频率、引用动机和数据论文对科研产生的影响,代表着数据论文的重要程度,也是数据论文与数据期刊的重要评价标准。本研究拟从对数据论文的引用出发,调查数据论文的引用位置,总结数据论文的引文功能和应用现状,从新角度出发认识数据论文的发展情况,为科研数据出版和管理提供新的视角。
1 相关研究进展
1.1 数据论文相关研究
数据论文目前的出版流程依旧与学术论文的出版流程基本一致,但由于数据论文的特殊性,使得数据论文的出版模式更加复杂。刘凤红[3]和刘晶晶[4]分别针对性解释了全球生物多样信息网络(GBIF)和Penspft出版社与自然出版集团推出的Scientific Data的出版流程。欧阳峥峥[5]等调研了15种数据期刊,对其发展现状、出版方式、收录内容、版权协议等进行了对比分析,认为科研数据通过数据期刊以正式出版物的形式发表,提高了数据的规范性、可理解性和可引用性。对数据论文中的科研数据,欧阳峥峥[5]指出,已发表论文的科研数据和新产生的数据都可以作为数据论文的描述对象,而为了更好地描述数据,保证数据集质量和数据可重用性,部分数据期刊制定了数据论文专门的模板和指南。
为保证和提升数据论文的可用性和可信度,数据期刊对出版的数据论文内容和结构会有不同的要求。Gorgolewski等人指出,数据论文内容和结构方面的要求保障了科研数据的透明和可重用性,进一步推动数据共享[6]。Candela等调查了100余种数据期刊,发现数据论文格式和内容还没有统一的规定与标准,部分数据期刊对数据论文提出非常详细的要求,更多的期刊则对论文的内容给予充分的自由[7]。他另外指出,研究人员有可能将一项数据内容分为多个部分进行展示,因此这不利于数据论文出版过程的发展和完善,也不利于保障数据共享[7]。
为保障期刊质量,几乎所有的数据期刊都采取同行评议的机制,然而目前不同期刊采用的评估方法和评审标准不尽相同。Candela把数据论文的同行评审分为封闭式同行评审(closed peer review)、开放式同行评审(open peer review)、半开放式同行评审(semi-open peer review),而数据集、数据描述、数据集与数据描述的一致性和数据论文对数据集的开放获取作用,都是评议数据论文的独特重点[7]。另一方面,数据论文的同行评审还存在许多争议,例如:数据质量对数据论文有着更重要的作用,但目前尚无统一的公认的数据质量评价标准;传统的同行评议不够透明,评审的过程需要更多的发展和完善。
1.2 文献引用相关研究
规范理论(Normative Theory)来源于莫顿科学社会学,而社会建构观(Social Constructivist View)则来自构建主义[8],这两种理论对引用行为和引文本质有不同的定义,是引用行为研究领域中相互竞争的理论。规范理论认为引用行为是施引者对参考文献研究价值的认可,因此可以通过被引频次评价文献的学术价值[9];社会建构观则指出,知识传承不是文献引用的目的,引文发挥的功能是说服读者,使文献更有可信性,因此被引情况作为学术评价依据缺乏权威性[10]。
调查发现,研究者主要通过两种方式对引用行为开展实证研究。第一种是通过内容分析方法对引文上下文语境(Citation Context)进行判定和解读,对被引文献的功能进行分类,从而对科研人员的引用动机进行解读。Willett分析了10篇论文,从18个可能的引用动机中挑选出了最重要的10个,并且对作者的引用动机进行调查,将其与判读的引用动机进行比较[11];Brooks[12]从引用动机文献中总结筛选出七种引用动机:新颖性(currency)、操作性信息(operational information)、负面证据(negative credit)、正面评价(positive credit)、说服(persuasiveness)、提醒读者(reader alert)、社会认同(social consensus);Peritz[13]提出可以根据引文在论文中所发挥的不同功能对引用动机进行分类。另一种是采用问卷调查法或访谈法直接地剖析施引者的引用行为。邱均平[14]等通过已有研究文献,总结出知识主张、价值感知、信息源便利性、引用输出、引用重要性五种引用动机,并将其分为内在引用动机和外在引用动机;通过量表式问卷对科研人员进行调查,通过结构方程建模的方法验证引用行为以及不同引用动机之间的影响关系。Liu M[15]通过调查问卷,对1981-1987年在Chinese Physics上发表文章的415位作者进行调査,构建引用动机的理论模型,分析引用行为的各种影响因素及其各因素之间可能存在的联系。
科研论文通常都遵循着严格的章节结构,引文内容在施引文献中出现的位置,可以反映出某一领域文献的引用规律。Sombatsompop[16]等学者将引用位置划分为“引言”、“实验与材料”、“结果与讨论”、“结论与其他”,通过引用位置来评价学术论文的引用价值。他们认为引用位置在“结果与讨论”中的内容比被引用在“引言”部分的更重要。Catalini等学者持相似意见,但他们将文章分为“引言”、“材料与方法”、“结果与讨论”、“其他”四个部分。他们分析了Journal of Immunology上从1998到2007年共15 731篇文献的引用位置后发现,有约84%的内容在“结果与讨论”部分被引用[17]。张梦莹[18]等人将引用位置分为“引言”、“文献综述”、“方法”、“结果”、“讨论”、“结论”等六个部分,以PLoS One期刊为数据来源,从中抽取2006-2015年6个不同学科刊载的3 414篇论文,对5 320条引文内容数据进行分析,发现引用集中于“引言”部分。
综上,通过对国内外相关研究的调研,可以发现目前对数据论文的研究主要集中于对数据论文及数据期刊相关概念、数据论文同行审议、出版机制和权益机制等过程的总结与阐述,对数据论文发展过程的综述性研究也比较完善。文献引用相关研究局限在对普通学术论文的被引情况研究,对数据论文被引情况的研究较少。
本文拟研究数据论文的引用情况,着重调研引文功能和引用位置,总结数据论文的引用现状。
2 研究设计
Scientific Data是自然出版集团推出的专门的科学数据期刊,其收录的论文涵盖生物、地球与环境、健康、物理、科学界与社会等领域。该期刊的主要论文类型为Data Descriptor,将传统的叙述内容与精心策划的数据描述(元数据)相结合,为数据共享和重用提供了新的框架。
笔者于2020年3月10日在Web of Science中检索2015-2019年Scientific Data中刊发的数据论文,并选定被引频次最高的50篇文献。通过追溯数据论文的施引文献,并筛选出其中的“论文”(Article)和“会议论文”(Proceeding Paper)两种文献类型作为统计对象,共获得3 011篇文献。然后获取这批文献的全文,人工找寻数据论文在其中的引用位置,按照文章结构或上下文,判断分类数据论文的引用位置;借助EXCEL、“百度图说”等可视化统计工具,统计高被引数据论文的关键词、学科、机构、国别等特征,并以条形图、气泡图等形式进行可视化呈现,将其功能与自身属性联系起来,找寻数据论文引用行为的规律与特点。
3 研究结果
3.1 引用位置分析
IMRD结构模式是近代实验科学兴起时就已形成的大量现代学术研究论文遵循的模式。该模式建立在观察可重现原则之上,由界定研究所关心的问题(Introduction)、介绍研究问题的方法(Method)、陈述研究的发现(Result)以及发现的意义(Discussion)共四个部分组成。Voos和Dagaev[19]在1976年最早提出引用内容位置的有关研究,他们发现,在施引文献中分布在不同位置的引用内容,其价值并不相同。因此,数据论文在施引文献中的不同位置分布,意味着数据论文承担着不同的引文功能。本文借鉴张梦莹[18]等人在构建引文内容分析数据集时,将引用位置划分的“引言”、“文献综述”、“方法”、“结果”、“讨论”、“结论”等六个部分,并结合Sombatsompop[16]等学者对引用位置的划分,最后确定引言、综述、数据/方法、结果、讨论、结论、附录、致谢八种引用位置分类。
本文通过人工逐篇追溯数据论文的施引文献的方式,根据数据论文在其中的引用位置和施引文献上下文,判断数据论文发挥的引用功能,对数据论文作为参考文献的引用情况进行总结分析。由于一篇数据论文可能会在施引文献中被多处引用,即一篇论文可能有多种引文功能[20],在统计编码过程中,将回溯数据论文每次被引的位置,因此一条文献会存在多条重复记录。
通过追溯上述数据论文在施引文献中出现的位置及上下文,判断其引文功能,并按引言、综述、数据/方法、结果、讨论、结论、附录、致谢八种进行分类。数据论文总计被引3 871次,总体引文位置分布见图1。

图1 引文位置分布
论文的引言部分是研究的总体概述,其目的是简略描述研究主题及相关环境或背景,对论文正文起到引导的作用,同时可以激发读者的阅读兴趣。在引言部分引用数据论文达1 048次,占所有引文位置的27.07%。数据论文在引言部分被引用,可以帮助研究者阐述研究主题,并通过新旧研究的对比说明这项研究工作的意义与创新点。
文献综述部分通常是总结梳理该研究领域的相关研究文献,阐明研究现状和当前存在的问题,并阐明研究课题研究的必要性、意义和所要实现的目标。统计发现,综述部分引用数据论文268次,占所有引文位置的6.92%。由于数据论文的独特性,施引文献在综述部分引用数据论文的目的主要在于对阐明某项研究的数据来源、数据获取的规则与手段、数据描述方法进行总结概括。数据论文在引言和综述部分被多次引用,证明了在科学研究的传承中,数据论文具有重要意义。
数据/方法部分指研究的数据来源和实验过程与方法部分,从图1中可以看出,数据论文在数据/方法部分总共被引用了1 427次,在所有引文位置中占到了36.86%,是被引最为集中的一部分。数据论文的被引集中于此部分,说明在施引文献的数据来源、数据集选择、数据获取、数据描述、研究方法以及实验设计等方面,数据论文对相关研究提供了较多的帮助。统计还发现,许多文献甚至直接选取数据论文中提供的数据集或数据描述方法进行不同角度或更深层次的分析和解释,这充分体现出数据论文在不断地推动数据共享和重用,为科研数据的进一步利用和潜在价值地挖掘奠定了基础。
数据论文在施引文献的结果部分被引用了411次,在这部分中,研究人员通过描述在科学实验中获得的客观结果,提出自己的看法以及对实验结果的评价和认识。数据论文在这一部分被引用,旨在帮助研究人员交待做出了什么,根据实验结果可以得到什么,使前期有待证明的假说或者提出的科学理论得到证实,以证明研究人员提出的假说是合理的,观点是正确的。在这一部分,许多数据论文的数据集直接以图表的形式在施引文献中出现,作者将引用信息标注在图表的脚注部分。这也进一步说明数据论文共享的数据集可作为直接的研究结果支撑,科研数据得到了充分的重用。
在讨论部分中,数据论文被引用了546次。研究发现是讨论部分的核心,而数据论文的引用是为了有力地支持研究发现。在讨论部分数据论文可以直接作为证据来支持研究的结果;其次,可以将已有的数据结果作为参照,与本次研究进行比较,针对数据的一致性或差异性对研究进行扩展性的讨论;此外,可以引用既往的研究数据,来说明本次的研究对这一领域的贡献。
结论部分是对研究工作中最重要结果的总结,不是简单地总结研究得出的要点,而是要以更高的抽象水平解释研究的发现,并阐述研究者是否成功解决了研究问题中所述的需求,或达到了何种程度。在此部分引用数据论文是辅助研究进行进一步的展望,或借鉴其他研究对本研究提出意见或建议,分析目前研究的不足。
在正文之外,数据论文在附录被引用了14次。虽然附录的重要性和必要性不如正文,但一般选择将较大的图表等对研究具有重要参考价值的内容以附录的形式出现,作为对正文的补充,以更好地支撑论文观点。附录中的数据论文一般在表格或公式中出现。
数据论文帮助施引文献节约了大量成本和工作量, 45篇施引文献的致谢部分对数据论文予以感谢,这既是研究人员之间互相的尊重,也是对数据共享行为的鼓励。
本文在统计数据论文引用位置的同时发现,对数据论文的引用内容与对传统学术论文的引用内容存在差异。学术论文通常会在实验性、理论性或预测性上有别于现有研究,提出新观点或思路,或是某种已知原理的新应用、新实践。数据论文不同于传统学术论文,它通常只发表某项研究相关的数据集,包括描述数据内容、数据产生背景、数据质量和结构的元数据文件,而不发表观点。对数据论文中数据方法、数据集部分内容的引用更能体现数据论文在科学数据共享中发挥的作用及其独特的数据共享价值。而这样的引用更多地体现在数据/方法、结果和附录部分:
(1)在数据/方法中引用数据论文,更多的是引用数据论文中的数据方法,对其中的数据收集、存储、处理方法进行借鉴,来辅助研究获取、加工数据。还有少部分论文会引用数据论文中的数据集,直接作为自身研究的数据来源,进行二次分析,获得与原研究不同的研究结果,进一步发掘数据资源的潜在价值。
(2)在结果部分,多数论文会引用数据论文中的部分数据集,与研究获取的数据进行比较,增加研究结果分析的层次和深度,也会在已有研究结果的基础上,与数据论文数据集结合,提出进一步的假设和预测。在这部分中,部分施引文献直接将数据论文的数据集进行图表化分析,并在图表脚注部分标明引用信息,通过可视化呈现实现更科学有效的比较分析。
(3)在附录部分,施引文献会引用数据论文的部分或全部数据,这意味着施引文献通过引用数据论文,作为推理、证明的支撑,是支持自身论点的直接依据。
3.2 引用频次与数据集分析
3.2.1 引用频次分析
本文统计施引文献的被引频次,并按照对数据论文的引用位置分类,借助“百度图说”,制作出气泡图,见图2,横坐标为八种引用位置,纵坐标为施引文献的被引频次,气泡大小代表相同被引频次的文献量。此外,去除未被引用的文献,对不同引用位置的施引文献,按被引频次分段统计其文献量占比,如表1。从图2和表1可以看出,虽然数据论文发挥着不同的引用功能,但是除了无被引的文献,施引文献的被引频次都集中在1~10次。进一步结合引用位置分布和被引频次情况分析,在综述、致谢引用数据论文的文献被引频次50次以上占比更大,分别为3.92%、6.26%。此外,在数据/方法、引言部分引用数据论文的文献最多,同时其被引频次的峰值分别为954次、706次,明显高于其他文献。

图2 被引频次气泡图

表1 被引频次分段统计表
仅从引文的被引频次对参考文献进行评价过于片面,一方面无法判断施引者的引用动机,另一方面没有考虑到引文在被引过程中的价值差异性。因此,将引用位置与被引频次进行结合,通过数据论文在文章中被引用的不同位置体现出数据论文的不同价值,而被引频次体现出数据论文对研究价值的贡献。综合调研数据发现,数据论文往往在引言和数据/方法中发挥自身作用,同时也是在这两部分中使施引文献更有价值。
3.2.2 高被引数据论文数据集分析
本研究选取50次以上频次,且在数据/方法部分对引用数据论文的施引文献中的数据集进一步分析,所涉及的16篇数据论文如表2。在收集阅读了16篇数据论文后,笔者认为,这些数据论文在学科领域、数据内容、数据获取方式、数据形式、数据可重用性等方面有如下特点:
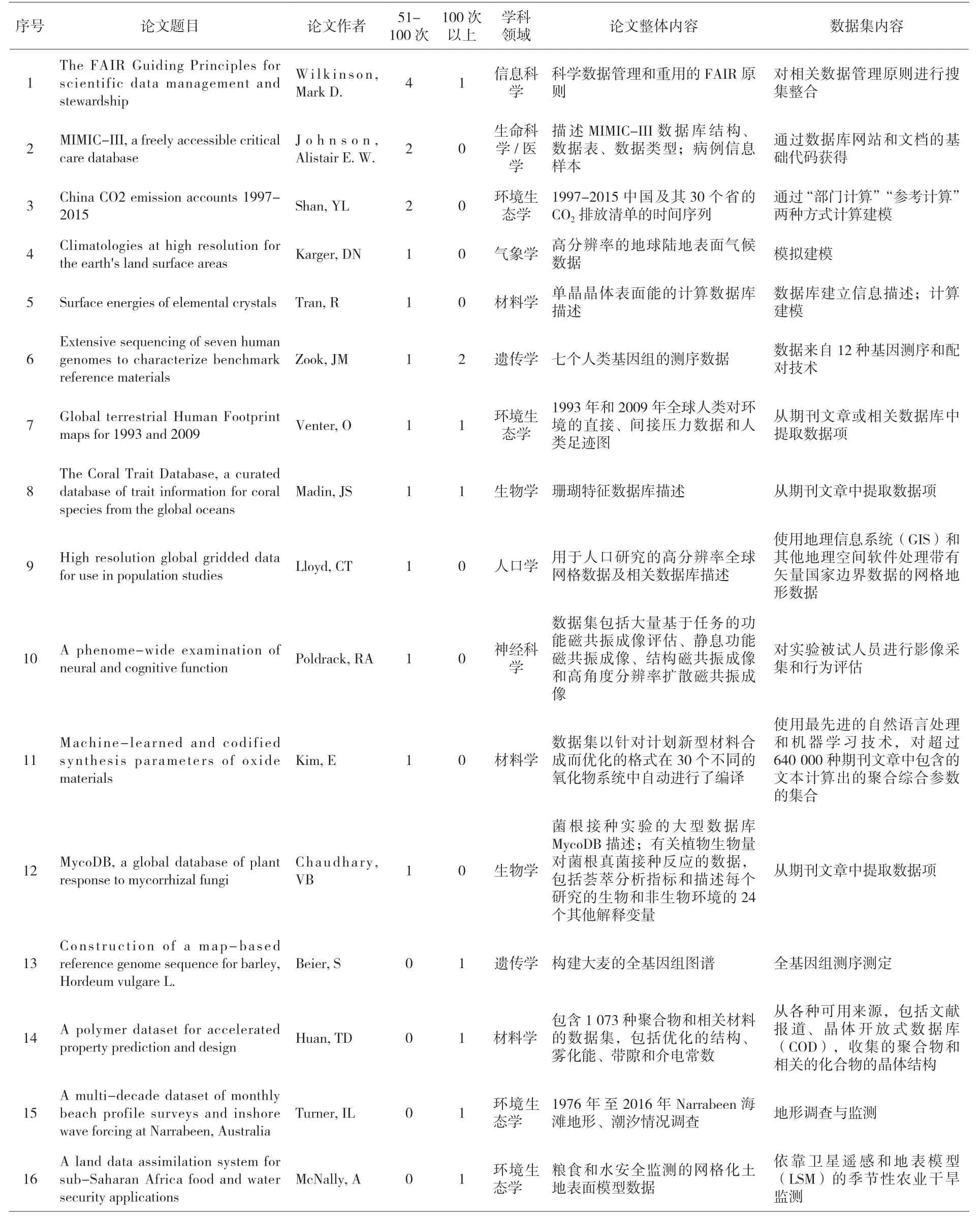
表2 高被引数据论文基本信息
(1)学科领域方面:其中4篇属于环境生态学,3篇属于材料学,遗传学、生物学各2篇,另外有信息科学、生命科学/医学、神经科学、人口学、气象学各1篇,学科领域分布基本与前期分析的数据论文总体学科情况相符。
(2)论文内容方面:除了本学科领域的科研数据与元数据外,还有对各种数据库的信息的详细描述,这也从另一方面说明随着研究涉及的数据量不断增加,各种学科领域的科研人员对数据管理和存储方面也越来越重视。
(3)数据获取方面:除了直接实验测量获得的数据,还有模拟建模、从各种可用来源收集整理等不同方式,另外,自然语言处理与机器学习也被广泛应用于从期刊文献中提取数据。目前人工智能领域的快速发展带来了越来越多的数据需求,同时也产生了庞大的处理数据,成为主要的数据来源渠道之一,这使得数据共享渐渐成为科学研究的基础,极大地减少科学人员的重复性工作。
(4)数据形式方面:大多数据集以数据矩阵的形式呈现,大规模数据集会在专门的数据平台提供另外的数据文件,而且数据有多种可视化形式呈现,如一般的条形图、折线图、扇形图、散点图、热图,数据处理方面的信息还会以流程图、设计概念图的形式出现,部分数据分布情况也以地理分布图的形式呈现,能更加清晰地表现数据情况。
(5)数据可重用性方面:为了提高数据可重用性,大部分数据论文会采用学科专业的数据验证方式或者其他实验、研究结果进行比较验证,也有部分数据论文设计了专门的方法体系来确保数据质量,或对获取数据的不确定度进行详细分析。
在数据论文的引用过程中,数据使用的层次有所不同,在文献中发挥的功能不同,对文献质量及文献的被引频次也有不同程度的影响。一篇数据论文中可能共享了不止一个数据集,而数据集可以灵活地被科研人员重用,可以多个数据集进行组合,也可以把数据集拆分为子集。对数据论文可以在引言、综述部分引用其中对数据库的描述和数据共享规则机制的描述,为整个研究奠定理论基础;或在数据/方法中仅引用一个特定的数据集和数据记录,为研究提供数据源,或完善已有的数据结构和数据描述。数据论文构成的复杂结构使得数据论文可以有效推动研究人员对数据集的收集、管理和重用过程,这也同时提升了研究的质量,完善研究成果。
4 总结与展望
4.1 研究结论
本文针对Scientific Data中被引频次最高的50篇数据论文,回溯其在施引文献中的引用位置,分别对引言、综述、数据/方法、结果、讨论、结论、附录、致谢八个部分对数据论文的引用目的和数据论文发挥的功能进行分析。研究发现:
(1)数据论文并不重点报道基于科学假设和科学问题的研究结果,而是重点描述科学数据本身这一独特性,对数据论文的引用具有鲜明的特点。引用数据论文中数据方法、数据集部分内容更能体现数据论文在科学数据共享中发挥的作用。
(2)在数据论文的引用过程中,数据使用的层次有所不同,在文献中发挥的功能不同,对文献质量及文献的被引频次也有不同程度的影响。数据论文往往在施引文献的引言和数据/方法中发挥自身作用,同时也是在这两部分中使施引文献更有价值。
(3)从高被引数据论文来看,一篇数据论文中可能共享了不止一个数据集,而数据集可以灵活的被科研人员重用,可以多个数据集进行组合,也可以把数据集拆分为子集进行使用。数据获取方式是否明确、数据格式是否统一明晰、数据可重用性是否有保障,都关系到数据论文的可利用情况。
4.2 研究展望
本文对于数据论文引用现状和数据论文引用功能的研究只基于Scientific Data上发表的数据论文,没有考虑到期刊学科特性的影响,对数据论文的引用现状的评价尚不成熟且不完善。在后续研究中,希望能够结合多种数据论文期刊,提出更加科学有效的数据论文评价指标体系,并为数据论文引用的评价研究提供理论基础。
对数据论文引用位置分布和被引频次部分的分析,本文选取的文献规模较小,在后续的研究中,可以扩展数据论文规模,增添数据格式、数据完整性等方面,与施引文献的引用位置和被引频次进行综合分析,推断数据论文质量与其在施引文献中发挥功能的相关性。
本研究将数据论文的情况和被引情况进行了多个方面的呈现,通过对数据论文引用位置的标引和数据论文与传统学术论文的对比,展现了数据论文在数据共享和科研数据潜在价值发掘方面的独特贡献。希望以此让科研人员看到数据论文对科学研究做出的贡献,鼓励科研人员发表数据论文,提高数据共享意识,充分发掘科研数据价值,减轻科研负担,推动科学研究进步。
猜你喜欢
军事运筹与系统工程(2022年1期)2022-11-15
质量安全与检验检测(2022年2期)2022-11-13
速读·下旬(2021年11期)2021-10-12
中国现代医药杂志(2020年10期)2020-01-08
大东方(2019年12期)2019-10-20
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
浙江大学学报(工学版)(2015年11期)2015-03-01
浙江大学学报(工学版)(2015年5期)2015-03-01
浙江大学学报(工学版)(2015年1期)2015-03-01
