
基于轻量级图卷积的人体骨架动作识别方法
2022-05-14 03:28:52孙琪翔张聪聪刘圣杰
计算机工程 2022年5期
孙琪翔,何 宁,张聪聪,刘圣杰
(1.北京联合大学 北京市信息服务工程重点实验室,北京 100101;2.北京联合大学 智慧城市学院,北京 100101)
0 概述
人体动作识别是计算机视觉领域的重要研究方向之一。基于RGB 的人体动作识别方法往往对计算量有较高要求,且鲁棒性较差,易受环境因素影响,在实际应用中准确率和实时性不佳。基于骨架的动作识别可以明确地表现人体动作,仅依据骨架便可识别出大量动作[1]。与传统的RGB 数据相比,骨架序列不包含颜色信息,对视角变换、光照、遮挡等因素具有鲁棒性,因此,骨架序列引起研究人员的关注[2]并广泛应用于智能医疗、视频理解、人机交互等领域[3]。
早期基于骨架的人体动作识别方法将人体的关节点视为一组独立的特征,并且通过手工设计来模拟时空关节相关性[4],如YANG 等[5]提出基于关节位置差异的新型特征EigenJoints,其包含静态姿态、运动、偏移量等信息,进一步使用朴素贝叶斯最近邻分类器(Naïve-Bayes-Nearest-Neighbor,NBNN)进行动作识别。但是,这类方法很少探索身体关节点之间的关系,同时由于复杂度过高且准确率有限而逐渐被深度学习方法所替代。
目前,基于骨架进行动作识别的主流方法可以分为三类,即基于卷积神经网络[6]的方法、基于循环神经网络[7]的方法以及基于图卷积网络(Graph Convolutional Network,GCN)[8]的方法。LIU 等[9]将关节点映射到3D 坐标空间,分别对空间和时间信息进行编码,接着利用3D 卷积神经网络分别从时空信息流中提取深层特征,从而得到最终的动作识别结果。该方法的优势是可以在不同的时间区间提取到多尺度的特征,但其参数量过于庞大。DU 等[10]提出端到端的级联循环神经网络,其根据人体物理结构将人体骨架分为5 个部分,并分别输入到5 个子网络中,接着逐层进行信息融合,并在最后一层完成动作分类。该方法可以有效地学习时序特征,但其缺点是网络参数量过高,较难优化。结合人体关键点的空间特性,空间图卷积网络可以更好地学习人体动作特征,同时,结合人体关键点位置的时间序列,能对动作的上下文信息进行学习。
为了提高动作识别的准确率,本文在WANG 等[11]所提出的非局部神经网络的基础上,设计基于图卷积网络的非局部网络模块,该模块可以获取全局特征信息从而提高网络识别准确率。此外,本文利用多流数据融合算法,对4 种特征数据流进行融合,只需一次训练就可以得到最优结果,从而降低网络参数量。在此基础上,结合Ghost 网络[12]思想设计空间Ghost 图卷积模块和时间Ghost 图卷积模块,在网络结构层面进一步降低网络参数量。
1 相关工作
通过人体姿态估计算法或高精度的深度摄像头可以获取人体关节点特征,而由关键点连接的人体骨架能够形成图结构。YAN 等[13]提出将图卷积网络扩展到时空模型上的时空图卷积网络(Spatial Temporal Graph Convolutional Networks,ST-GCN),其基础是时空图结构,可以从输入的关键点中建立一个时空图,该方式保留了骨架关键点的空间信息,并使得关键点的运动轨迹以时序边的形式得到展现,提高了网络的特征表现能力和鲁棒性。SHI等[14]在ST-GCN 的基础上,提出2s-AGCN(Two-streamAdaptive Graph Convolutional Networks),其有自学习的邻接矩阵策略,提高了网络对空间特性的抽取能力。LI等[15]提出动作结构图卷积网络(Actional-Structural Graph Convolutional Networks,AS-GCN),该网络创新性地从原始坐标信息中提取Action-Link 和Structural-Link 进行加权以作为GCN 的输入,提升了网络的准确率。SI 等[16]提出将图卷积与LSTM 融合的新型网络(Attention Enhanced Graph Convolutional LSTM Network,AGC-LSTM),该网络使用注意力机制增强关键点的特征,同时利用LSTM 提高学习高层次时空语义特征的能力。SHI 等[17]提出使用有向无环图构建人体骨架结构的新型模型(Directed Graph Neural Networks,DGNN),该模型为了更好地适应动作识别任务,构建可以根据训练过程自适应改变图的拓扑结构,同时利用骨架序列的运动信息和空间信息进一步提高双流框架的性能。YANG 等[18]提出CGCN(Centrality Graph Convolutional Networks),其利用被忽视的图拓扑信息区分关节点、骨骼和身体部分。相较基于循环神经网络和卷积神经网络的方法,上述基于图卷积网络的方法对非欧氏数据(Non-Euclidean data)具有有效性[19]。
SHI等[20]提出一种新型解耦时空注意网络(Decoupled Spatial-Temporal Attention Network,DSTA-Net),其可以根据注意力网络发现骨骼数据的关联性,无需利用结构相关的卷积神经网络、循环神经网络或图卷积神经网络,体现了注意力机制的优越性。
当前众多学者致力于轻量级网络研究[21],目的是在减少网络参数量的同时保持较好的特征提取能力。网络轻量化方法主要分为3 类,即网络参数轻量化、网络裁剪以及直接设计轻量化网络。网络参数轻量化指降低表征网络的参数量,VANHΟUCKE 等[22]提出一种利用8 位整数定点消除冗余参数的方法,GΟNG等[23]提出针对密集权重矩阵进行量化编码来实现压缩的方法。此外,Binary Connect[24]、Binarized Neural Networks[25]和Xnor-net[26]方 法虽然对 网络压 缩的程度较高,但是也会对网络的准确率造成较大损失。网络剪裁通常应用于压缩网络模型,HANSΟN 等[27]提出基于偏置参数衰减的网络裁剪方式。和常规网络相比,轻量级网络结构所需的网络参数量和浮点运算量(Floating-point Οperations Per second,FLΟPs)更小。因此,轻量级的网络结构更适合在嵌入式设备和移动终端上应用。IANDΟLA等[28]在卷积神经网络结构层面,利用瓶颈结构设计具有更少参数量的卷积神经网络,根据该思路,其设计了一种精度与AlexNet 相当的轻量级网络结构,该网络参数量的大小只有AlexNet 的1/50。HΟWARD 等[29]利用深度可分离卷积建立轻量级深度神经网络,结合2 个超参数乘法器和分辨率乘法器设计MobileNets 网络结构,其网络参数量大小只有标准卷积方法的1/9。张洋等[30]提出改进的EfficientDet 网络并结合注意力机制,在保证网络参数量的前提下提高了网络准确率。
为了同时实现较低的网络参数量以及较高的网络准确率,本文主要进行如下研究:
1)针对预先定义图拓扑结构所导致的准确率降低的问题,提出一种基于图卷积网络结构的非局部网络模块,直接关注所有关节点并判断其是否存在连接,从而提高网络的准确率。
2)为了减少网络训练的次数,提出多流数据融合算法,将关节点信息流、骨长信息流、关节点运动信息流、骨长运动信息流进行融合,使得网络通过一次训练即可得到最优结果,从而降低网络参数量。
3)结合Ghost 卷积的思想,分别设计空间图卷积网络和时间图卷积网络,从主干网络的层面降低网络参数量。
4)设计新的时空图卷积基础模块和时空图卷积网络,并在NTU60 RGB+D[31]和NTU120 RGB+D[32]数据集上进行验证。
2 融合多流数据的Ghost 图卷积网络
在ST-GCN 的基础上,本文利用GhostNet 网络中的Ghost卷积结构来降低网络参数量,其中,用Ghost卷积替换空间图卷积,命名为GSCN(Ghost Spatial Convolutional Network)模 块,连接一个BN(Batch Normalization)层和一个ReLU层,以加快训练;用Ghost卷积替换时间卷积,命名为GTCN(Ghost Temporal Convolutional Network)模块,连接一个BN 层和一个ReLU 层,以加快训练。如图1 所示,一个基础Ghost图模块(Ghost Graph Convolution Networks,GGCN)由一个GSCN、一个dropout 层和一个GTCN 组成,其中,dropout参数设置为0.5,同时,为了稳定训练,网络中增加了残差连接。
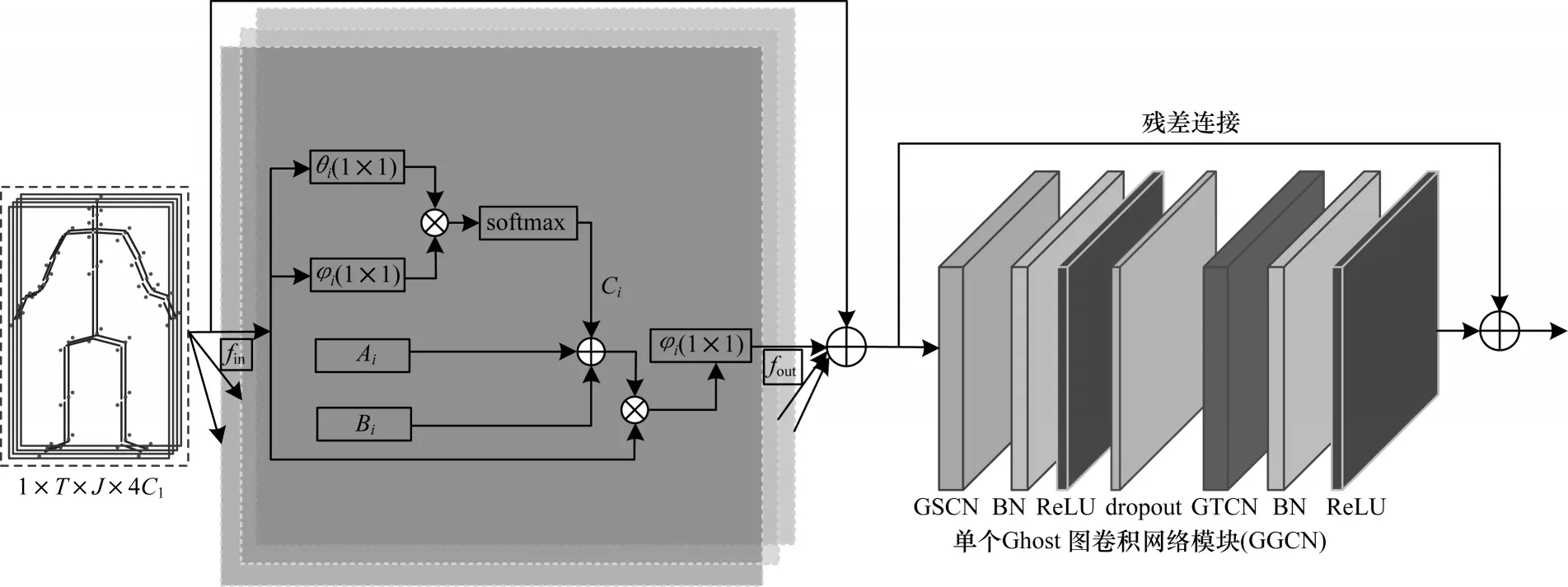
图1 非局部网络模块和单个GGCN 网络模块Fig.1 Non-local network module and single GGCN network module
2.1 非局部网络模块
对于传统的图卷积,人体的物理结构是设计图拓扑结构的基础,但是这样的设计对于动作识别并非有效,例如,在由NTU-RGB+D 数据集提供的拓扑图中,头和手之间没有联系,但是在“wiping face(擦脸)”和“touching head(摸头)”等动作中,头和手之间的关系就是很重要的信息,因此,连接关系不应局限在相邻节点中。随着信息在不同网络层间的传递,不同网络层的语义信息将不同,因此,图网络结构也应该随着信息的传递而更新。
针对上述问题,结合WANG 等[11]提出的非局部神经网络,本文提出一种非局部网络模块,该模块可直接关注所有的关节点,继而判断所有关节点间是否存在连接。在训练过程中,以端到端方式对不同层和样本分别学习图结构。与原始非局部神经网络不同,本文所提非局部网络模块包括3个部分,如图1所示:第1部分Ai是物理结构图,和ST-GCN[13]中的物理结构图保持一致;第2 部分Bi是可以共享的图结构,对于不同样本而言这个部分是相同的,其可以表示关节点之间连接的一般模式;第3 部分Ci可为不同样本学习独一无二的图结构,其为个性化的图结构,针对任意一个样本捕捉到独特的特征图。具体地,针对第3 部分Ci,本文采用归一化嵌入式高斯函数计算2 个关键点之间的相似性,如式(1)所示:

其中:N代表关节点的数目;T表示帧数;θ和ϕ用来进行维度变换。通过点积计算可以得到所有关键点之间的相关性,进而得到非局部邻接矩阵。
如图1 所示,使用1×1 卷积表示嵌入函数,每个输入特征图的个性化图的计算如式(2)所示:
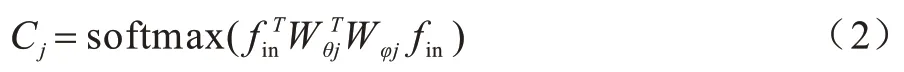
其中:softmax 操作将结果归一化在0~1 之间;W是1×1 卷积的参数,初始值为0,与共享图相同,它也需要采用残差连接。综上,图卷积的定义公式如下:
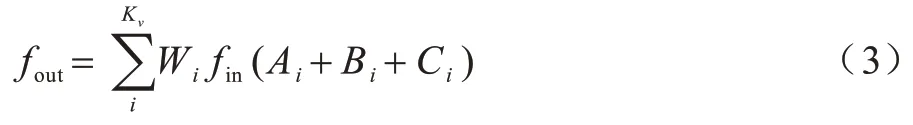
2.2 图卷积网络
图卷积网络方法主要分为基于频谱的方法(spectralbased)和基于空间的方法(spatial-based)。基于频谱的图卷积网络中的图卷积操作可以看成将原始的处于空间域的图信号变换到频域之后,对频域属性进行滤波,然后再恢复到原来的图信号所在的空域中,从而完成特征提取[33],该操作的缺点是灵活性低、普适性差、运行效率不高;基于空间的图卷积让图中的节点在空间域中相连并达成层级结构,进而进行卷积,因此,其能降低复杂度,增强泛化能力,提高运行效率。空间域图卷积方法是动作识别领域的主流方法。
将骨架数据表示为N个节点,T帧的时空图为G=(V,Ε)。人体动作的骨架坐标可以表示为X∈RN×T×d,其中,d是关节点的维度。基于图卷积的模型包含空间图卷积和时间图卷积2 个部分。
对于空间图卷积,将节点的邻域定义为邻接矩阵A∈{0,1}N×N。为了更好地说明空间图卷积,将邻接矩阵划分为向心点、本征点和离心点3 个部分。对于单帧,F∈RN×C代表输入特征,F′∈RN×C′代表输出特征,其中,C和C′分别代表输入和输出特征的维度。图卷积计算如式(4)所示:

其中:P={本征点,向心点,离心点}代表空间分区是归一化的邻接矩阵,定义如式(5)所示。

根据文献[34],时间卷积是通过连接连续帧的节点并在时间维度上进行1 维卷积来实现。卷积核的大小由kt表示,通常设置为9。
基于上述图卷积的模型有2 个缺点:
1)需要大量的算力。例如,ST-GCN[13]识别一个动作样例需要16.2GFLΟPs,其中,空间图卷积消耗4.0GFLΟPs,时间图 卷积消 耗12.2GFLΟPs。一 些ST-GCN 的相关算法甚至需要消耗100GFLΟPs[17]。
2)不论是时间图结构还是空间图结构,都是预先定义好的,尽管一些研究工作[14]采用了可学习的邻接矩阵,但是其仍受常规图卷积架构的限制。
2.3 Ghost 模块
受限于内存和算力,在嵌入式设备上部署神经网络比较困难。例如,给定输入数据X∈Rc×h×w,其中,c代表输入数据的通道数,h和w分别是输入数据的高和宽。用于产生n个特征映射的任意卷积层的操作如式(6)所示:

其中:*代表卷积操作;b代表偏置项;Y∈代表输出的有n个通道的特征图,h′和w′代表输出数据的高和宽;f∈Rc×k×k×n代表这个层的卷积滤波器,k×k代表卷积滤波器f的卷积核大小。如图2 所示,此时FLΟPs 可以由n·h′·w′·c·k·k计算,由于滤波器和通道数通常非常大(如256、512 等),因此FLΟPs 通常高达数十万。

图2 常规卷积操作Fig.2 Conventional convolution operation
HAN 等[12]提出的Ghost 模块可以有效解决上述问题。一个训练好的深度神经网络通常包含很多冗余的特征图,在这些特征图中,有些是彼此近似的,因此,用大量的网络参数和FLΟPs 逐个生成冗余特征图没有必要。假设有m个固有特征图Y′∈由初始卷积生成,如式(7)所示:

其中:卷积滤波器为f′∈Rc×k×k×m,m≤n。其他超参数(卷积核、步长、空间大小等)与原始卷积保持一致。为了得到所需要的n个特征图,可以利用一系列线性操作在固有特征图Y′上生成s个Ghost 特征,如式(8)所示:
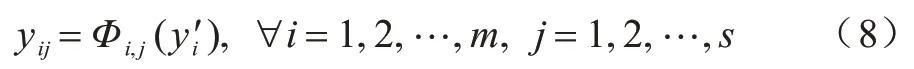
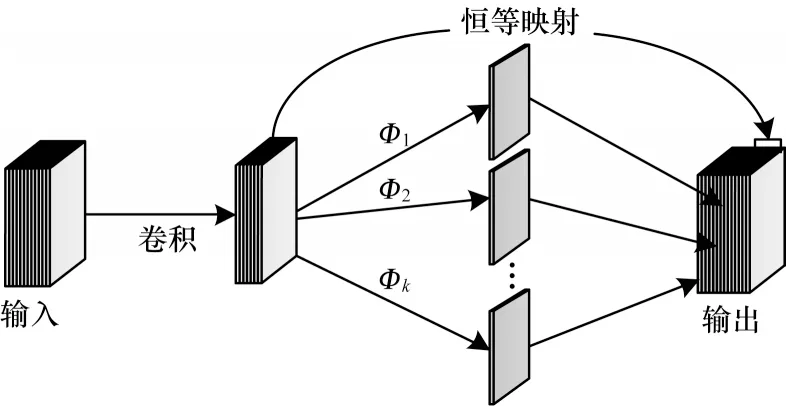
图3 Ghost 卷积操作Fig.3 Ghost convolution operation
Ghost 模块包含一个恒等映射和m·(s-1)=(n/s)·(s-1)个线性运算,理想情况下普通卷积与Ghost 模块的参数量比如式(9)所示,即用Ghost 模块代替普通卷积操作可以使参数量缩小s倍。
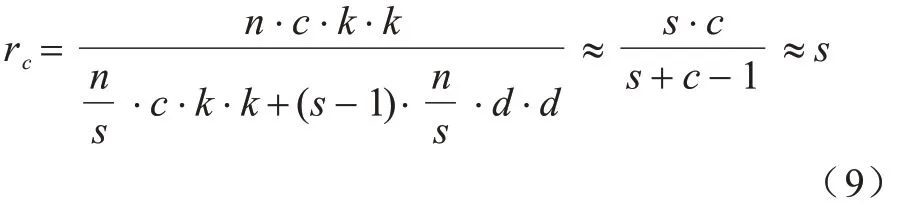
2.4 多流数据融合
基于图卷积的方法通常利用训练多流数据集的方式提高精度。特征流数据是指针对同一对象来描述这些数据的不同视角。利用多流数据之间的互补性可以学到更好的特征表示。本文提出一种将多流数据融合到图卷积中的方法,该方法对关节点信息流、骨长信息流、关节点运动信息流、骨长运动信息流进行融合。进行多流数据融合,一方面使得构建的邻接矩阵具有全局特性,另一方面能够减少运算次数,降低运算成本,实现网络轻量化。针对图卷积网络参数量过大的问题,本文设计轻量化Ghost 图卷积网络,其包含空间Ghost图卷积和时间Ghost 图卷积。
对于一个给定的骨架序列,其关节点的定义如式(10)所示:
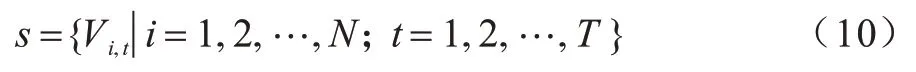
其中:T为序列中的总帧数;N为总关节点数;Vi,t表示t时刻的关节点i。为了完成多流数据融合,需要对骨架序列s进行多样化预处理。本文分别给出骨长信息流、关节点运动信息流和骨长运动信息流的定义。
1)骨长信息流。通常定义靠近人体重心的点为源关节点,坐标为Vi,t=(xi,t,yi,t,zi,t),远离人体重心的点为目标关节点,坐标为Vj,t=(xj,t,yj,t,zj,t)。通过源关节点与目标关节点的差值计算骨长信息流,即骨长信息流的定义如式(11)所示:
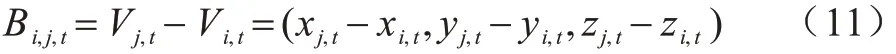
2)关节点运动信息流通过计算相邻2 个帧中相同关节点之间的差值得到。定义在t帧上的关节点i,其坐标为Vi,t=(xi,t,yi,t,zi,t),在t+1 帧上的关节点i则定义为Vi,t+1=(xi,t+1,yi,t+1,zi,t+1)。在关节点Vi,t与关节点Vi,t+1之间的运动信息流如式(12)所示:
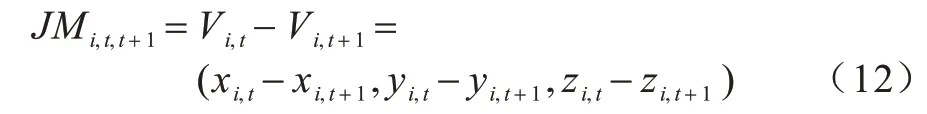
3)骨长运动信息流通过计算相邻2 个帧中相同骨骼之间的差值得到。根据式(10),可以定义在t帧上的骨长信息流为Bi,j,t,在t+1 帧上的骨长信息流为Bi,j,t+1。因此,骨长信息流如式(13)所示:

如图4 所示,根据关节点信息流、骨长信息流、关节点运动信息流、骨长运动信息流的定义,多流数据融合的计算如式(14)所示:
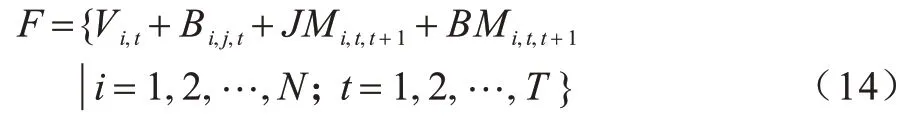
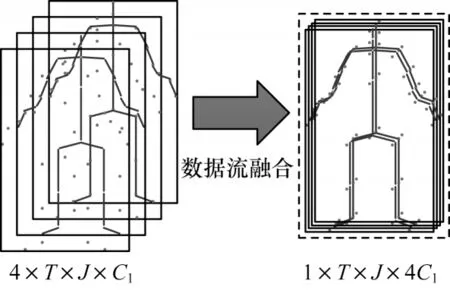
图4 多流数据融合Fig.4 Multi-stream data fusion
2.5 网络架构
如图5 所示,非局部Ghost 图卷积网络(Non-Local Ghost Graph Convolutional Network,NL-GGCN)是由9个基础模块堆叠而成,每个块的输出通道数分别为64、64、64、128、128、128、256、256 和256。在网络的开始阶段增加数据BN 层,用来归一化输入数据,在网络的最后增加一个全局平均池化层(Global Average Pooling,GAP),将所有不同的骨架样本池化到相同的尺寸大小,最后通过softmax 分类获得预测结果。

图5 非局部Ghost 图卷积网络结构Fig.5 Non-local Ghost graph convolutional network structure
2.6 本文算法流程
本文算法流程如算法1 所示。
算法1轻量级人体骨架动作识别算法

3 实验结果与分析
本文实验环境设置为:64 位Ubuntu 18.04 操作系统,Intel®Xeon®CPU E5-2678v3@2.50 GHz,内存12 GB,显卡RTX2080Ti、Cuda10.0.130、Cudnn7.5、PyTorch1.4和Python3.6软件平台。
3.1 数据集和评价指标
本文实验的人体骨架数据集包括NTU60 RGB+D数据集和NTU120 RGB+D 数据集,骨架样例如图6 所示,通过可视化代码表现上述数据集中人体骨架在不同动作下的状态。
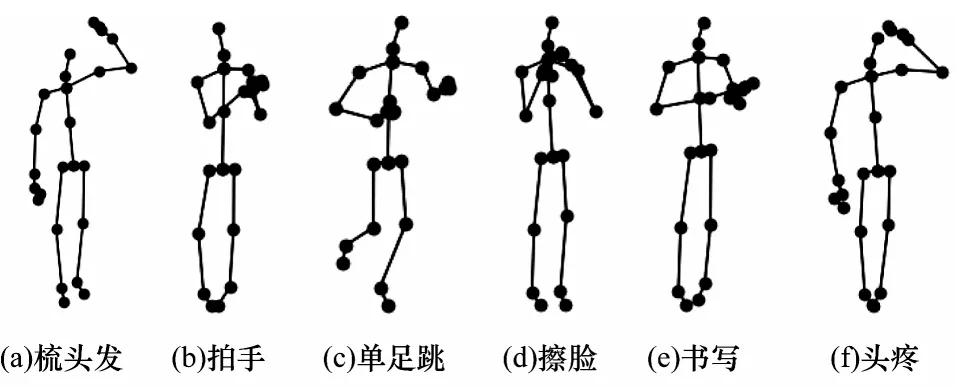
图6 NTU RGB+D 数据集中6 种动作的可视化效果Fig.6 Visualization of six actions in NTU RGB+D dataset
NTU60 RGB+D 数据集由南洋理工大学提出,由3 个Microsoft Kinectv2 相机同时捕获完成,包括56 880 个动作片段,60 个动作分类,17 种相机摆放位置组合,有40 名演员参与到数据集的采集工作,具体的采样点分布如图7 所示,该数据采集的样本关节点数目为25。
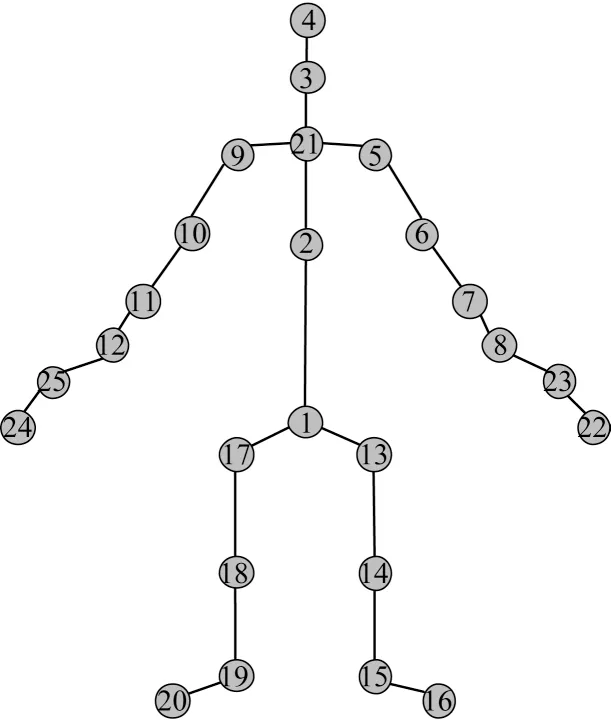
图7 NTU60 RGB+D 数据集关节点标签Fig.7 Joint point labels of NTU60 RGB+D dataset
本文采用该数据集中的2 种评判标准:
1)跨表演者(Cross-Sub),表示训练集和验证集中的动作来自不同的演员,其中,身份标示为1~38 的演员所演示的动作用于训练,身份标示为39~40 的演员所演示的动作用于测试,训练集样本数为40 320,测试集样本数为16 560。
2)跨视角(Cross-View),表示标号为2 和3 的摄像机拍摄的动作用作训练,标号为1 的摄像机所拍摄的动作用作测试,训练集样本数为37 920,测试集样本数为18 960。
NTU120 RGB+D 数据集是对NTU60 RGB+D 数据集的扩充,相机摆放位置组合为32 个,动作分类增加到120 类,演员人数增加到106 人,动作片段数增加到114 480,样本关节点数保持25 个不变。
3.2 实验设置
本文中的所有实验都是在PyTorch 深度学习框架下进行[35]。实验优化策略采用Nesterov momentum(0.9)的随机梯度下降(Stochastic Gradient Descent,SGD)。批大小(Batch size)为64,模型迭代次数(Epoch)设置为50,初始学习率为0.1,当迭代次数分别为30和40时,学习率除以10。
3.3 消融实验
为了验证本文算法的有效性,在NTU60 RGB+D和NTU120 RGB+D 这2 个数据集上进行实验对比。
首先,验证本文多流数据融合方案的性能和有效性,设计6 组数据流,测试不同数据流对实验结果的影响,结果如表1 所示,最优结果加粗表示,下同。其中:J 代表关节点信息流;B 代表骨长信息流;JM 代表关节点运动信息流;BM 代表骨长运动信息流。从表1 可以看出,骨长信息流对实验结果影响较大,实验数据验证了本文所提多流数据融合方案的有效性。
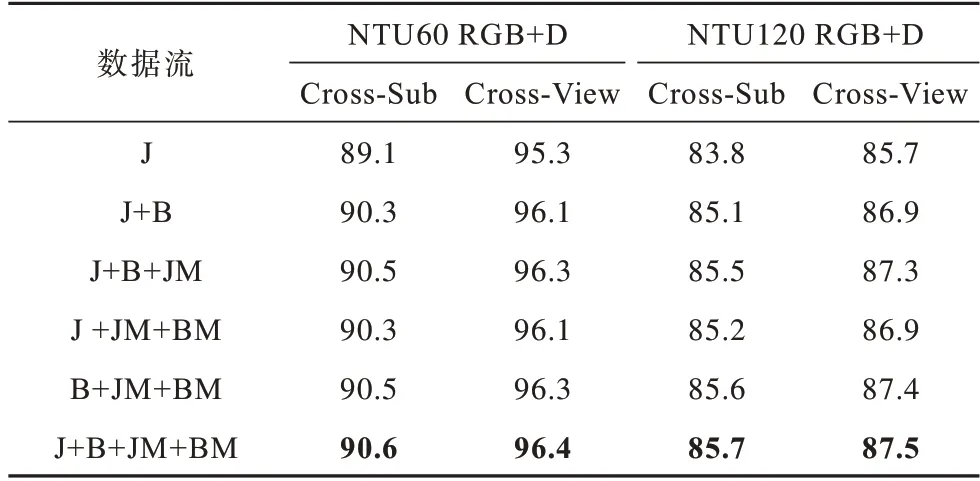
表1 不同特征数据流对实验结果的影响Table 1 Effects of different characteristic data streams on experimental results %
其次,为了验证本文所提网络的有效性,以融合的多流数据作为输入,在NTU60 RGB+D 数据集上进行实验,以Cross-View 作为评价标准,分别构建8 组实验网络,测试该网络模块对整个实验结果的影响,结果如表2 所示,CV 表示Cross-View。
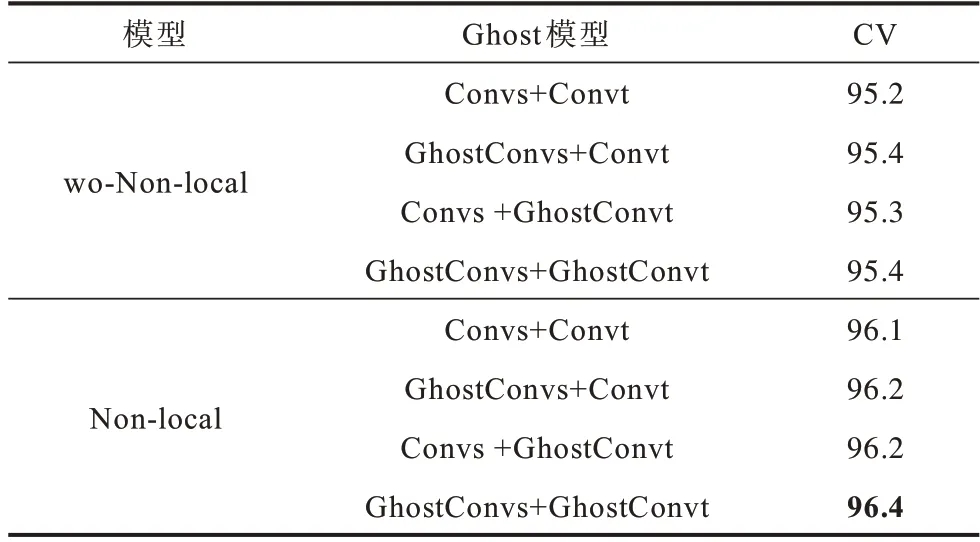
表2 不同网络架构的准确率对比Table 2 Comparison of accuracy of different network architectures %
在表2 中,Non-local代表增加了非局部网络模块,wo-Non-local(without Non-local)代表没有非局部网络模块,Convs 代表常规空间图卷积,GhostConvs 代表Ghost 空间图卷积,Convt 代表时间图卷积,GhostConvt代表Ghost时间图卷积。从表2 可以看出,非局部网络模块对准确率有较大的提升效果,Ghost结构对准确率提升效果有限。
从网络参数量的角度,本文以融合的多流数据作为输入,在NTU60 RGB+D 数据集上进行实验,以Cross-View 作为评价标准,分别构建4 组实验网络,测试不同网络结构对实验结果的影响,结果如表3所示,其中,GFLΟPs 代表浮点运算量。从表3 可以看出,Ghost 架构在有效降低网络参数量的同时保持了较高的准确率。

表3 不同网络架构的网络参数量对比Table 3 Comparison of network parameters of different network architectures
为了说明本文所提算法对网络实时性的影响,以融合的多流数据作为输入,在NTU60 RGB+D 数据集上进行实验,以Cross-View 作为评价标准,分别构建4 组实验网络,测试不同网络结构对网络实时性的影响,结果如表4 所示,其中,Time 代表检测单个动作样本所需时间。从表4 可以看出,随着Ghost架构的应用,网络检测单个动作样本所需时间降低,Ghost 时间图卷积网络架构对网络实时性影响较大。
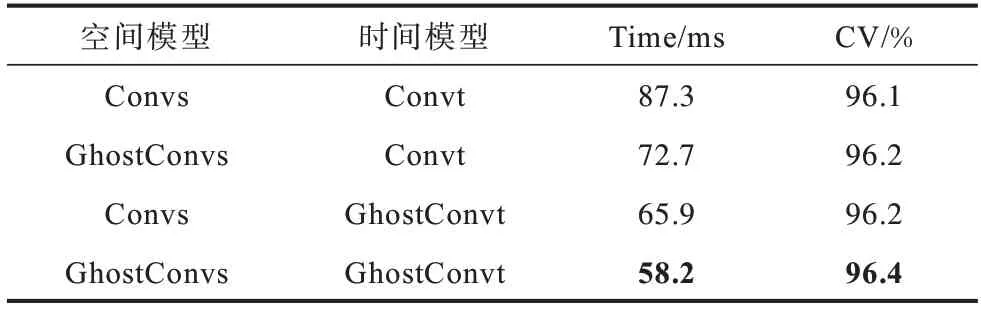
表4 不同网络架构的网络实时性对比Table 4 Comparison of network real-time performance of different network architectures
3.4 结果分析
在NTU60 RGB+D数据集上,本文将所提NL-GGCN与最先进的基于骨骼的动作识别方法在准确率和模型参数量上进行比较,实验结果如表5 所示,CS 表示Cross-Sub。从表5 可以看出,本文NL-GGCN 的模型参数量远小于其他方法,同时在准确率方面,以Cross-Sub作为评价标准,本文NL-GGCN 性能优势明显。

表5 NTU60 RGB+D 数据集上的实验结果对比Table 5 Comparison of experimental results on NTU60 RGB+D dataset
4 结束语
为解决目前动作识别方法计算复杂度过高的问题,本文提出一种轻量级的人体骨架动作识别方法。针对人体骨架的特征,设计一种非局部网络模块,以提升网络的动作识别准确率。在数据预处理阶段,进行多流数据融合,通过一次训练即可得到最优结果。在网络结构上,分别将Ghost网络结构应用在空间图卷积和时间图卷积上,进一步降低网络参数量。动作识别数据集NTU60 RGB+D和NTU120 RGB+D上的实验结果表明,该方法在实现较低网络参数量的情况下能达到较高的识别准确率。在未来,人体动作识别将向着高实时性和高准确率的方向发展,以期广泛应用于安防监控、陪护机器人等领域。后续将结合Transformer、heatmap stack、EfficientNet等新型网络架构,进一步提升本文动作识别方法的鲁棒性、准确率并降低网络参数。
猜你喜欢
电子乐园·上旬刊(2022年5期)2022-04-09 22:18:32
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
军事运筹与系统工程(2020年1期)2020-09-11 06:41:08
中国新技术新产品(2020年5期)2020-05-06 03:36:28
铁道通信信号(2018年12期)2019-01-31 05:36:40
军事运筹与系统工程(2018年1期)2018-11-10 05:33:12
军营文化天地(2017年6期)2017-06-28 11:30:19
军事运筹与系统工程(2015年3期)2015-09-08 13:12:35
中国煤层气(2014年3期)2014-08-07 03:07:45
