
分布式数据库隐私信息增量式更新方法仿真
2022-05-14 10:27王玲维黄汉云
计算机仿真 2022年4期
王 华,王玲维,黄汉云
(1. 广东科技学院计算机学院,广东 东莞 523083;2. 湖南工业大学机械自动化学院,湖南 株洲 412000)
1 引言
分布式资料库系统一般采用小型电脑系统将多台不同位置的电脑通过网路连结在一起,形成逻辑上完整且物理上分散的大型资料库[1,2]。由于数据库中存储大量的用户信息和隐私数据,所以在对分布式数据库进行数据调用和更新时,可能会产生隐私信息泄露的问题。因此,需要针对分布式数据库中的隐私信息进行优化,设计相应的更新方法[3]。
目前,分布式数据库同步更新已成为学术界研究的热点之一[4],并取得了一系列较为成熟的研究成果,如分布式本体调试信息的存储优化与增量更新方法[5]、邻域多粒度粗糙集信息更新增量方法[6]等,但由于实际运行环境复杂多变,传统数据库更新速度慢,更新效率不高,因此引入增量更新的概念。
增量式开发过程的技术基础是具有参考透明度的特性。基于此特性就可以显示出数据及其规格的一致性。为此,本研究设计了一种分布式数据库隐私信息增量式更新方法,在保证有效保护数据库隐私信息的基础上,提高了数据更新的效率。
2 分布式数据库隐私信息增量式更新方法设计
2.1 分析分布式数据库存储结构
图1中显示了具体的数据库存储结构。

图1 分布式数据库结构图
从图1中可以看出,分布式数据库从结构上可以划分为四个层级,在数据存储过程中采用单一数据的存储模式,并在不同的层级上生成数据备份,也就是在数据库的不同节点上存储两个相同的数据。
2.2 注册分布式数据库
DataSourceRegistrations的作用是为分布式异构数据库同步系统提供数据库登录信息和注册用户表结构,这些信息全部保存在XML结构中。资料来源登记后可取得之资料库资讯有:资料库类型、IP位址、用户名及密码等[7]。
在数据源注册成功后,数据库下所有用户表的表结构将被提取以生成TableInfo.xml,以便在系统中生成映射文件。如果没有注册数据库,或者数据库注册不成功,则无法参与映射文件的生成。如果已成功注册数据源,则无法在该数据库类型下注册相同数据库的名称;如果已注册数据源的登录信息发生了更改,则可以通过修改功能按钮修改登录信息;如果更改用户表,则还可以通过更新表结构按钮更新Tablelnfo.xml文件。图2中显示了数据库的具体注册过程。
每个单位的源数据库系统管理员负责数据库资源的注册、共享内容的定义、共享数据的访问权限登记等工作。源数据库通过数据库管理员提供的注册信息连接到相应的数据库,并通过中心数据库提供的网络服务进行注册,将相关的同步表信息传送到中心数据库。每个单位的源数据库管理员根据系统提供的数据库表和视图,并设置可以共享的内容和权限[8]。每一个单元的数据库管理员都要对自己提交的信息进行确认,然后提交到中心数据库服务器,等待系统管理员进一步处理数据中心数据库。
中央资料库系统管理员负责审核各申请登记之异构资料来源资料,以及各资料来源共享内容及存取权限的确认与分配。此外,在注册新的数据源时,如果数据库连接不成功,则注册失败,应用程序将直接结束;如果连接成功,则在整个注册过程结束时,首先提取用户表表结构生成TableInfo.xml,然后提取所有表结构并生成DBinfo.xml文件。在修改注册信息后,可以通过所选数据源更新表结构信息或修改登录信息。
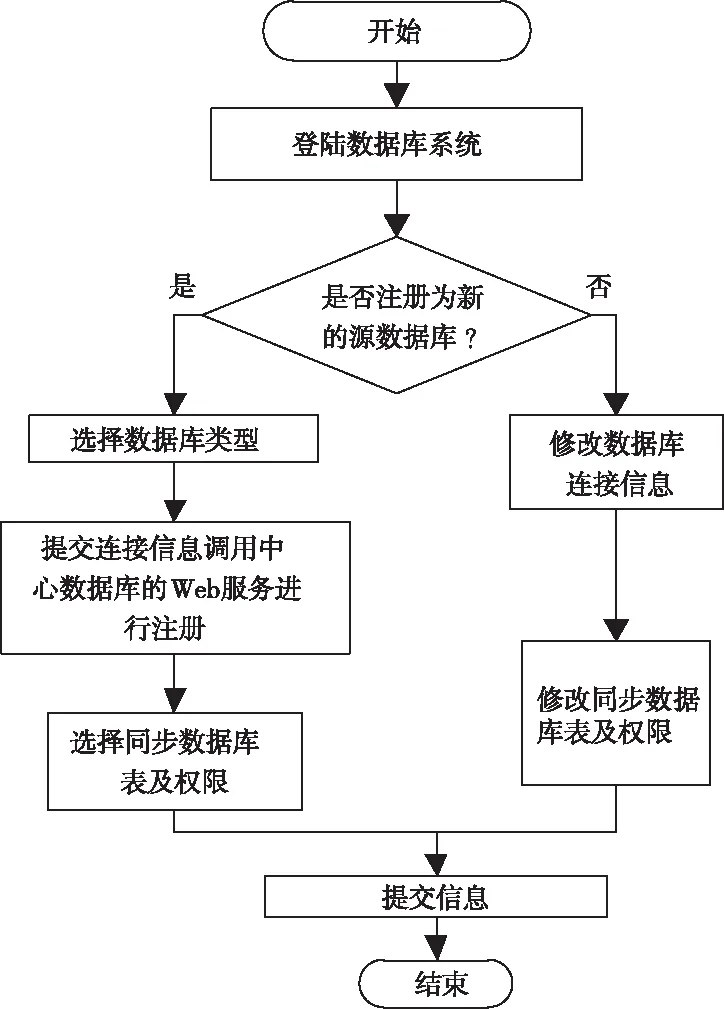
图2 数据库注册流程图
2.3 捕获增量变更数据
在此基础上,根据数据库日志表的增量情况捕获变更数据。在用户执行数据库写入操作的同时启动触发器,并将更改和新写入的信息备份到增量日志表中,手动生成事件驱动[9]。具体的变更数据捕获过程如图3所示。
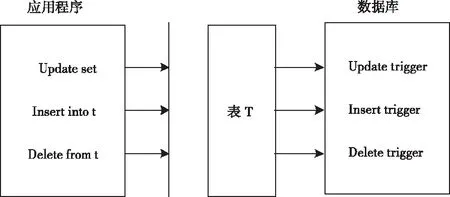
图3 触发器执行框架
图3中采用了推拉式组合方式,在触发器的驱动支持下,将采集到的数据变化提交给中间传输。源数据库的增量更新日志表结构如表1所示。
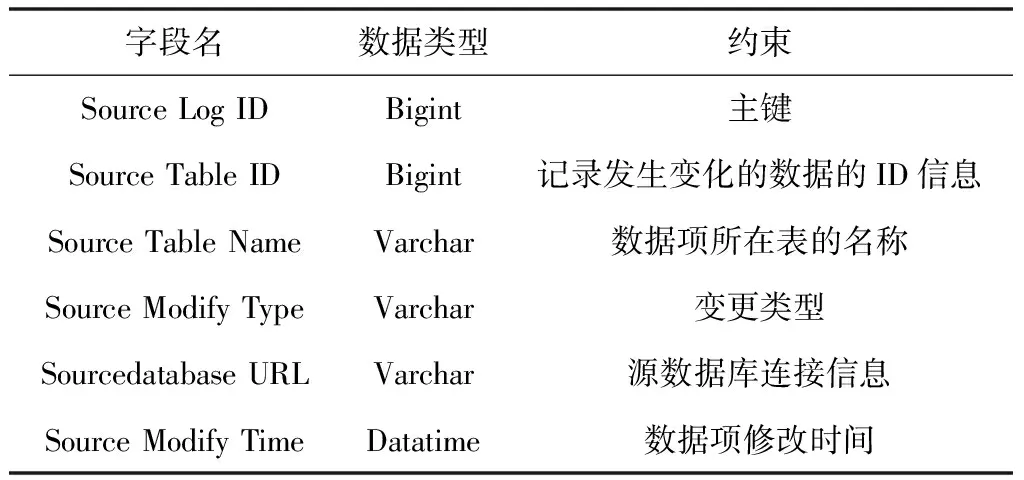
表1 源数据库日志表结构
数据库日志表是根据table info表和word info表中相对应的表信息和字段信息,从table info表中获取的,因此需要确定数据在中心数据库中的插入位置。图4中显示了它们的变更捕获关系。
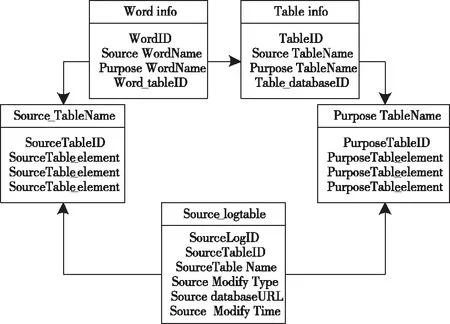
图4 变化捕获关系ER图
2.4 数据库隐私信息加密保护
为确保数据库更新过程中隐私信息的安全,需要对数据库中的隐私信息进行加密处理[10]。假定P表示未加密的明文数据,K表示加密密钥,那么数据的加密过程可以表示为
M=J(K,P)
(1)
式中输出的是对应于数据库隐私信息的密文。在数据融合过程中,采用随机密钥分配机制进行加密和解密,系统从包含大量密钥的密钥池中随机抽取少量密钥,形成密钥环。在邻接节点之间通过共享密钥实现数据的安全传输。如果键池足够大,机制的安全性就会更强。将密钥总数设为k为key-pool,k为key-pool中的密钥数。随机两个节点在网络中具有相同密钥的概率是
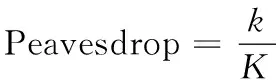
(2)
式(2)的计算结果表明,攻击者可以窃取任意两个通信节点之间的链路,即隐私数据被窃听的概率。由式(2)可知,为了使通信链路更安全可靠,需要密钥池中密钥的数量k越大,从而能够保证节点间通信链路被窃听的概率Peavesdrop越小,隐私数据泄露的可能性越小。假定网络中k取值为10000,节点的键环大小为200,则任何两个节点之间的Poverhear概率值为0.2%,足以满足数据的隐私保护要求。
2.5 实现分布式数据库隐私信息增量式更新
2.5.1 制定数据映射文件
单表到单表的映射关系在一对一数据库中分为两种情况:源表字段少于目标表,源表字段多于目标表。首先,建立映射文件是基于源表,源表有三个字段,目标表有四个字段,目标表按照系统映射文件准则,目标表字段必然不与源表相对应。若要使两表成功同步,字段必须为空。因为这种建立映射文件的方法具有目标表字段总数节点和每个字段所在位置节点[11,12]。如果源表字段的数目超过了目标表的数目,那么仍然选择按字段建立映射文件方式。在这种情况下,源表字段的数量大于目标表,因此,当创建一个映射文件时,将优先考虑目标字段的数量,过程如图5所示。根据目标表字段数,图5中只需要建立三次源字段和目标字段之间的映射关系。生成恢复语句时,只需从源表的三字段中提取有效信息值。
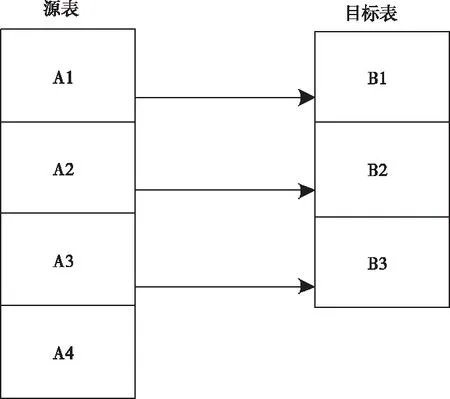
图5 源表字段个数多于目标表字段个数
2.5.2 数据加载
数据加载模块主要完成SQL语句恢复、冲突处理以及数据导入等操作,实现数据导入。基于对三个XML文件(Datal.xml、DB info.xml、Mapping File.xml)的解析结果加载数据。分析Data Xml主要使用同步数据和源表信息,同步数据保存在List
2.5.3 数据复制
分布式数据复制模块主要由两部分组成:源数据库管理模块和目标数据库管理模块。其中,源数据库管理模块包括监控采集、拷贝管理、同步传输控制和日志变更表四个子模块功能。目标数据库管理模块主要有同步传输控制、数据导入、一致性维护三个模块。在这些模块中,日志模块主要记录触发器引发的语句的操作和数据。具体地说,包括被更新表的名称、字段、运行时间、操作者、同步目的地信息以及相应的插入、更新、删除语句信息等。通过预先设置的定时器触发同步传输控制模块,根据监控获取和日志记录两个模块提供的纯变化数据,将其打包后以服务方式传送到目标数据,接收到传输数据后加压,并按照定制规则将数据转换为与目标数据库一致的数据格式。在数据导入模块中,按照预先设定的规则对数据进行一致性维护处理,使用事务的方式导入数据,返回真值进行响应,若失败,事务回滚,源同步控制模块将再次开始与该记录同步。图6中显示了具体的复制处理过程。
2.5.4 隐私信息增量式同步更新
数据库中的数据不断发生变化,在网络服务适配器的协调下实现数据的同步更新。同步时,应在中央数据库的Pure insert STUDENT类中调用Pure insert STUDENT方法。该方法主要对同步数据进行逻辑处理,源表是以Web服务的形式发布的中心数据库。同步更新的数据以Web服务的形式发布。
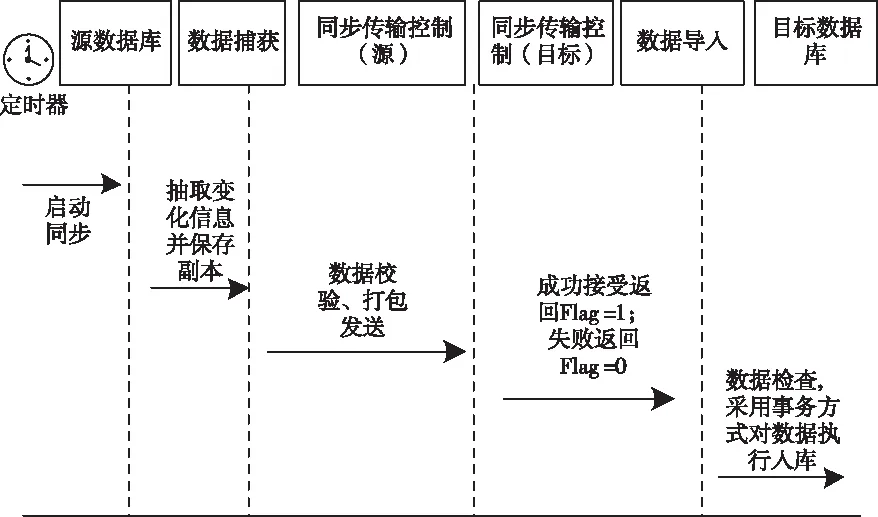
图6 数据库隐私信息异步复制流程图
3 仿真分析
为验证上述设计的分布式数据库隐私信息增量式更新方法的应用性能,设计如下仿真。实验将VMware虚拟机设置在模拟实验环境,虚拟机内嵌4核处理器和64位 CentOS6.5操作系统。另外实验中使用的分布式数据库配置如表2所示。

表2 实验数据库配置表
模拟实验环境中分布式数据库存储的数据取自 LUBM标准测试数据集LUBM-1,LuBM-10,LuBM-100.设置初始数据集中的数据量为2.7 GB,并将单位时间生成的数据设置为分布式。在实验环境下,将设计的分布式数据库隐私信息增量式更新方法导入其中得出设计方法的运行界面,如图7所示。
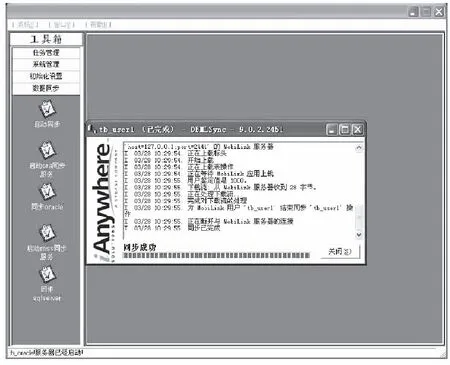
图7 增量式更新方法运行界面
实验以更新同步效率和隐私信息保护性能为验证内容。其中,更新同步效率通过数据库产生新数据到数据库更新完成所消耗的时间来体现,隐私信息保护性能主要通过更新前后隐私信息数据量的变化情况来体现。为了形成实验对比,将传统的分布式本体调试信息的存储优化与增量更新方法(文献[5]方法)、邻域多粒度粗糙集信息更新增量方法(文献[6]方法)作为对比。经过相关数据的读取与统计,得出实验结果,如表3所示。
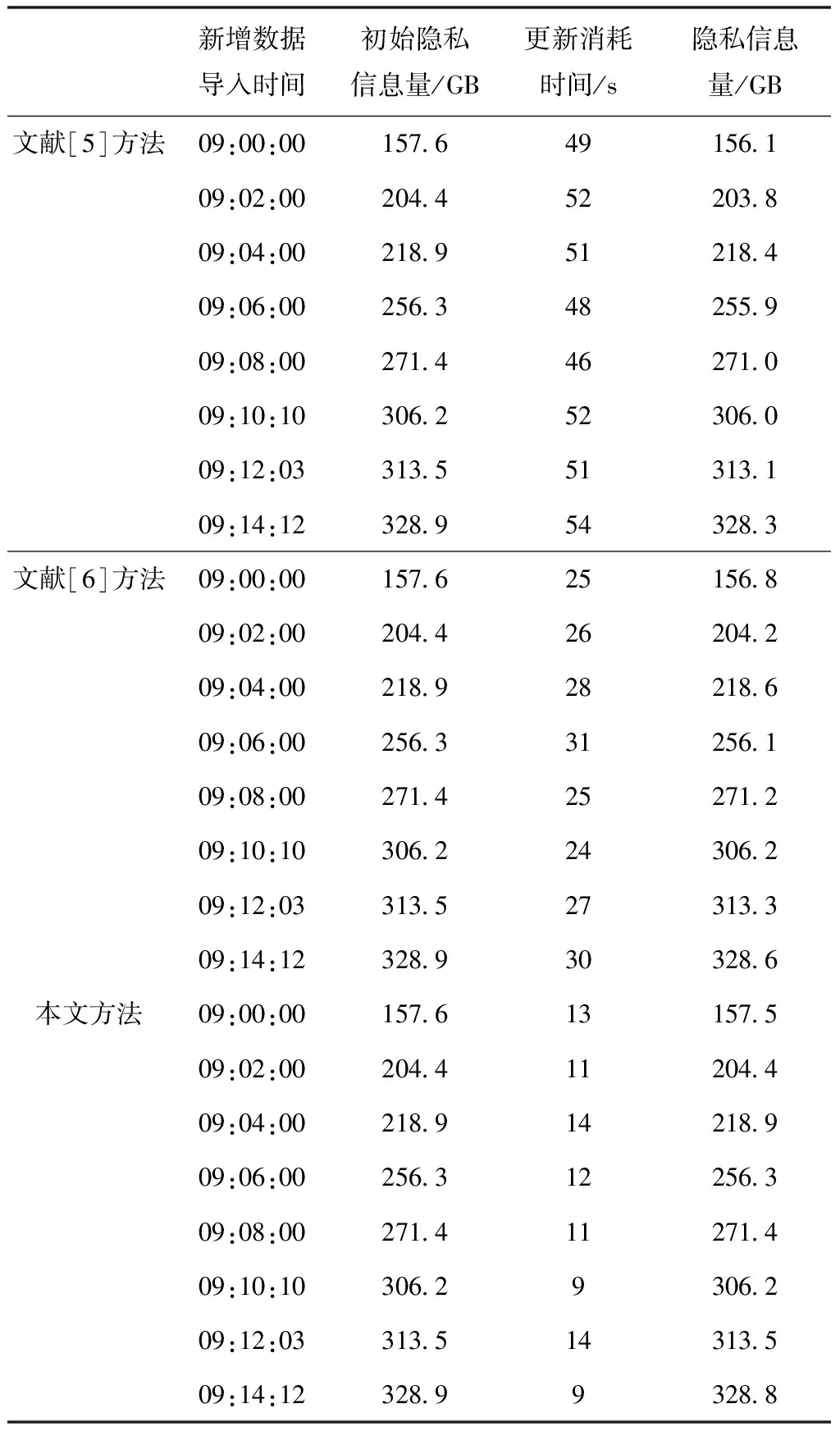
表3 仿真测试对比结果
从表3中可以看出,相比于两种传统方法,本文设计的更新方法的更新速度更快。从隐私信息保护性能方面来看,本文设计的更新方法在运行过程中隐私数据的丢失量更少。
综上所述,本研究设计的分布式数据库隐私信息增量式更新方法的更新效率更优,且在隐私信息保护方面更加具有优势。
4 结束语
分布式数据库能够保存大量的数据信息,本研究设计了分布式数据库隐私信息增量式更新方法,通过增量式概念的应用,提升了数据的更新效率,能够保证数据库中数据的时效性。然而仿真主要从隐私信息盗取方面进行测试,未考虑隐私信息的窃取情况,因此在未来的研究工作中还需要做进一步的研究。
猜你喜欢
当代水产(2022年3期)2022-04-26
财会月刊·下半月(2022年4期)2022-04-25
当代陕西(2022年6期)2022-04-19
故事作文·低年级(2022年2期)2022-02-23
故事作文·低年级(2022年1期)2022-02-03
科学与财富(2021年35期)2021-05-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
妇女生活(2019年1期)2019-01-17
计算机与网络(2018年2期)2018-09-10
西安交通大学学报(2009年12期)2009-02-08
