
一种基于三维残差网络分组膨胀卷积的人体行为识别方法
2022-05-12 09:25王志强
现代计算机 2022年5期
王志强
(上海海事大学信息工程学院,上海 201306)
0 引言
随着深度学习技术的发展,基于视频的人体行为识别在人机交互、安全驾驶、智能家居等领域取得了广泛的应用,行为识别的研究也更加注重人体行为时空的变化。
Ji 等将2D 卷积扩展到3D 卷积,能够捕获多个连续帧中的运动信息,学习动态连续的视频序列,通过支持向量机(SVM)分类识别人体行为,但随着网络层数变深会引起梯度弥散。Tran等采用大小为3×3×3(××)的3D卷积核,其中是输入的帧数,是卷积核空间大小的宽和高,提出了C3D 网络提取时空特征,计算高效且具有很强的通用性。何恺明等利用残差网络结构ResNet 进行行为识别,残差网络通过shortcut 操作,不仅缓解了网络层数的增加带来的梯度消失问题,还可以优化和提升网络性能。
为进一步提高人体行为识别准确率,增强其特征表达能力,本文基于三维残差网络,利用分组卷积和膨胀卷积的思想,建立了一种三维残差网络分组膨胀卷积的行为识别模型。首先将视频数据输入到三维卷积神经网络进行时间维度和空间维度的浅层特征提取,接着通过3D GD-ResNet 残差块进一步提取深层图像特征。3D GD-ResNet 残差块利用分组卷积,将残差块分成32个并行分组,减少模型参数量,同时在分组卷积中引入膨胀系数,扩大卷积核感受野,以捕获更丰富的图像特征信息,最后经过平均池化和全连接层,通过softmax 分类函数输出。
1 本文模型
传统三维卷积随着网络深度的增加,参数量的增多导致过拟合,影响了网络的泛化性能。本文模型以3D-ResNet101 为基础,设计GDResNet 特征提取模块,以提取更深层次的图像特征。结构如图1 所示,模型共100个卷积层,一个最大池化层,一个平均池化层和全连接层。首先对输入视频数据进行三维卷积并归一化,然后输入到33个GD-ResNet 残差块进行特征提取。在每个GD-ResNet 块使用分组卷积,同时在卷积过程中引入用膨胀系数扩大感受野,使用膨胀卷积替代普通卷积,最后通过全连接层输出,使用softmax 函数输出行为识别的最终结果。
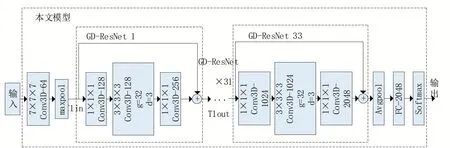
图1 本文3D GD-ResNet模型结构
1.1 本文模型结构特点
本文模型以3D ResNet101 为基础进行改进。三维卷积层中的每个特征图都会与上一层中多个临近的连续帧相连捕获人体运动信息,保证时序信息的关联性,其本质是对多个视频帧堆叠的立方体进行三维卷积运算,卷积过程如公式(1)所示。
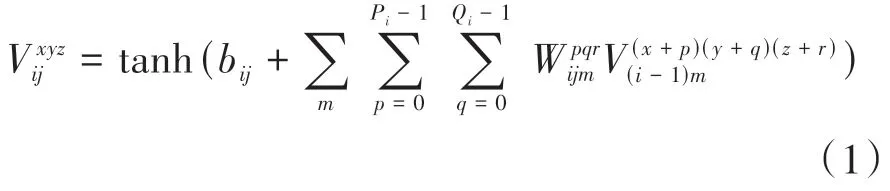
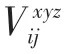
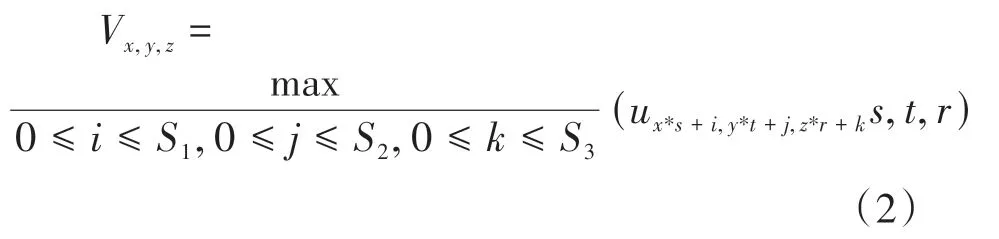
其中V为池化后的输出,为池化层的输入,,,为不同方向的采样步长。
网络的输入输出以及卷积核的大小用××的三维张量来表示,、、分别表示时间长度,宽度和高度,本文3D GD-ResNet 的网络结构参数如表1 所示(其中表示分组卷积的组数,表示膨胀系数,为了简化描述,表中省略了输出尺寸特征的通道数)。
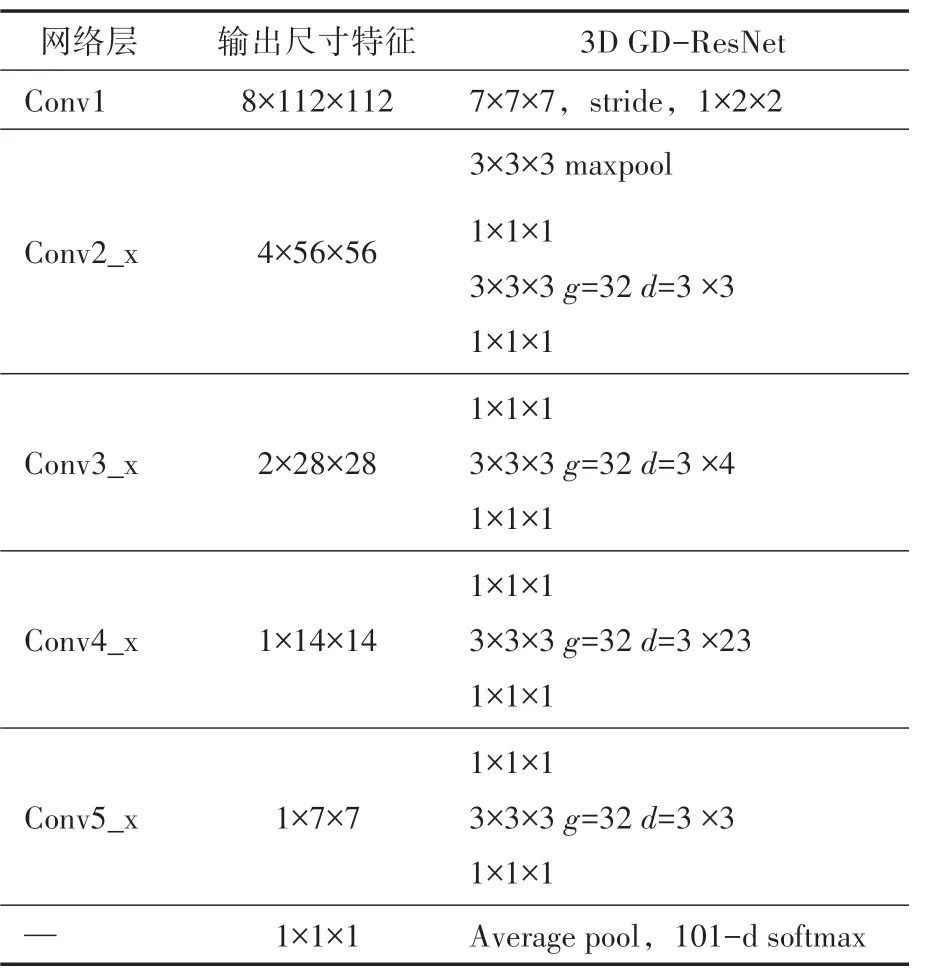
表1 3D GD-ResNet的网络结构参数
本文采用对输入视频帧归一化处理为224×224 大小的预处理方式,以连续16 帧大小为224×224 的图像输入到Conv1 层中,采用大小为7×7×7,步长为1×2×2 的卷积核进行浅层特征提取,其中7 表示时间长度,7×7 表示卷积核空间维度的大小,将得到的8×112×112 大小特征图通过Conv2_x的最大池化层,池化层卷积核大小为3×3×3,步长为2,通过同时对时间维度和空间维度进行下采样,减小计算量,输出特征图大小为4×56×56,并产生64 维特征图。之后依次通过33个GD-ResNet 特征提取模块进行深层特征提取。网络的Conv2_x-Conv5_x层都采用了残差连接,并在每个残差块中使用了分组膨胀卷积,优化网络性能。最后通过全连接层和softmax层,输出101个类别概率。
1.2 GD-ResNet特征提取模块
残差结构通过shortcut 操作,在加深网络的同时,减少了性能下降,但依然存在参数量过多、信息丢失等问题。本文设计GD-ResNet 特征提取模块,以图1 中的GD-ResNet1 为例,其内部结构及处理过程如图2所示。输入视频帧经过卷积和最大池化操作后输出特征图T1in,大小为4×56×56,输入到GD-ResNet1 特征提取模块。在L1 层采用1×1×1 大小的卷积核进行3D 卷积,通道数为128,增加特征的非线性转换次数。为了降低参数量,将L2层分成32个并行分组,用3×3×3 大小的卷积核在每个分组上做特征变换,输出特征图大小不变。不增加参数量的前提下,对每个分组引入膨胀率为3的膨胀卷积代替普通卷积,在不改变卷积核大小的情况下扩大感受野,最后将分组膨胀后的特征图合并输入L3 层,卷积核大小为1×1×1,通道数由128 增加到256。在每一层卷积操作后添加BN操作以保持数据分布一致,加快网络训练,最后对整个残差块使用ReLU 激活函数克服梯度消失。

图2 GD-ResNet1模块的分组膨胀卷积处理
传统CNN 中每一个输出通道都与输入通道相连接,通道之间采用稠密连接,计算复杂度高且容易产生过量的参数,本文分组卷积中通道被分成了32 组,每组通道数为4,输出通道只与该组内的输入通道连接,与其他通道无关。采用分组卷积能减小计算复杂度且拥有较强特征表示能力。
若定义输入特征图尺寸为××,卷积核尺寸为×,输出特征图尺寸为××,采用标准卷积的参数量为:

其中、表示输入和输出通道数,、分别表示特征图的宽和高。而采用分组卷积,则输入特征图按通道分成组,分别对每组进行单独的卷积操作,则卷积操作中每组输入特征图的尺寸为××,对应卷积核的尺寸为××,卷积操作完成后对组进行组合,输出特征图通道数为,每组卷积特征图通道数为,分组卷积的参数量可表示为:
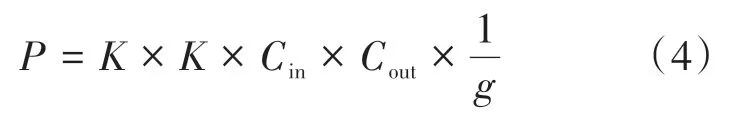
由公式(4)可知,分组数为的分组卷积参数量为标准卷积的1,在GD-ResNet1模块中,当输入特征图尺寸为128×4×56×56 时,其中128表示卷积核个数,4表示时间长度,56表示特征图的宽和高,普通卷积和本文GD-ResNet1参数量的对比如表2所示。

表2 普通卷积和GD-ResNet1参数量对比
普通卷积和GD-ResNet1分别表示ResNet101和本文分组卷积的第一个残差块,分组卷积组数取32,本文3D GD-ResNet 参数量是无分组卷积参数量的132,表明分组卷积能有效降低参数量,防止模型过拟合,提高网络性能。
感受野是CNN 网络每一层输出特征图的像素点在原始图像上的映射区域大小,膨胀卷积可通过控制窗口的宽度,扩展感受野区域,提取更多的特征图信息,能够保持图像分辨率不受损失的情况下减少空间信息的损失。经过膨胀处理后,感受野大小如式(5)所示:

其中表示卷积核的大小,表示膨胀卷积的扩张率,表示扩张后的感受野。
GD-ResNet 模块中对每个分组的卷积核上增加膨胀系数为3 的膨胀率,由公式(5)计算可知,卷积核大小为3×3×3 时,感受野大小为7×7。以图1 中GD-ResNet1 为例,当膨胀系数为1和本文膨胀系数为3时,卷积过程如图3所示。
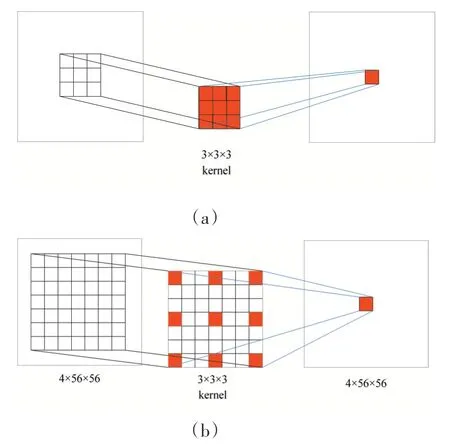
图3 膨胀系数为1和3时卷积输出过程
图中(a)表示膨胀系数为1时卷积输出过程,卷积核在特征图上的感受野为3×3,(b)表示本文加入膨胀系数为3 时卷积输出过程,4×56×56的特征图T1in为GD-ResNet1残差块的输入,通过加入膨胀卷积,卷积核在特征图上的感受野为7×7,输出特征图大小不变。本文通过实验表明,膨胀卷积能够提取更丰富的特征图信息,优化网络性能。
2 实验结果与分析
2.1 实验环境与数据
本文实验采用UCF101数据集,包含101个类别,共13320 段视频,其中训练数据集9537个视频,测试数据集3783个视频,视频帧图像大小为320×240。
实验在Linux 操作系统下进行,计算机显卡为NIVDIA的Tesla V100,采用PyTorch深度学习框架。用预训练3D ResNet101 神经网络初始化本文模型的权重参数,采用随机梯度下降算法优化模型。网络训练的初始学习率为0.1,每经过50epoch 学习率降为原来的10%,动量为0.9,batch_size 设置为128,共训练200 epoch。分别比 较 了 3D ResNet101、 不 同 分 组 数 3D ResNet101和加入分组卷积基础上采用不同膨胀率的对比结果,通过实验验证了本文方法的有效性。
2.2 原始3D ResNet 101实验结果
本文实验以3D ResNet101 为基础模型,采用Kinetics 数据集预训练3D ResNet101 初始化权重参数,对模型1 在UCF101 数据集上进行训练和测试。采用训练损失loss和acc(accuracy)准确率曲线验证模型性能和准确率。如图4所示,横坐标表示迭代次数,纵坐标表示模型训练和测试的准确率和损失值,由图可见,在没有加入分组膨胀卷积下,3D ResNet101 训练集准确率高,loss损失值小,而测试集损失值大,准确率低,由于UCF101 数据集相比Kinetics 数据集过小而出现了严重过拟合。
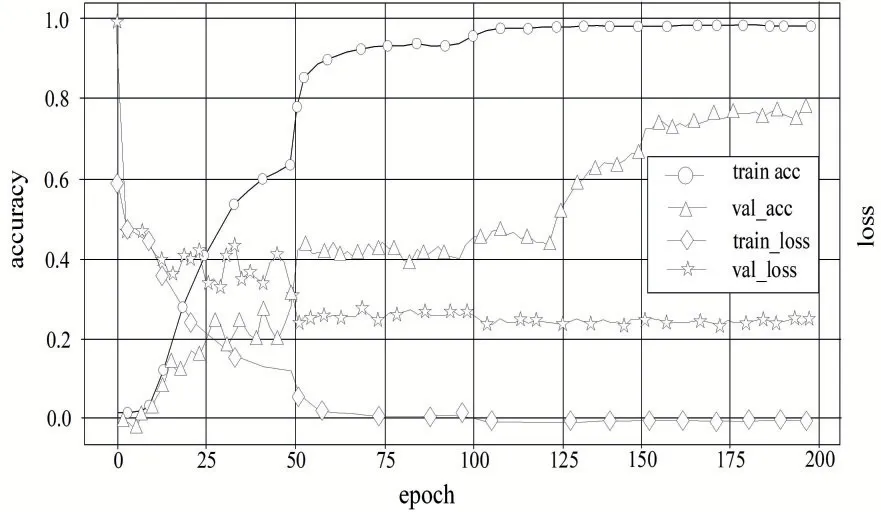
图4 模型1在UCF101上的准确率和loss损失
2.3 模型完善过程及实验结果分析
针对模型1存在过拟合严重问题,在实验中加入不同组数的分组卷积,通过对比选择最优分组数,以模型1 为基础,模型2 将残差块分成64 组,模型3 将残差块分成32 组,以验证不同分组数对模型识别准确率的影响。结果如图5所示,结果表明,采用32 组分组比64 组稳定,模型识别准确率更高。从图4和图3 的实验结果对比看,引入分组卷积,参数量减少,有效降低了模型过拟合。

图5 模型2和模型3的准确率和loss损失对比
为验证感受野的大小对网络性能的影响,在模型3 的基础上,引入不同的膨胀率进行对比。模型4 的膨胀系数为2,本文模型膨胀系数为3,图6 分别比较了模型4和本文模型不同膨胀系数下的准确率和损失,从图中可以看出,本文模型比模型4的损失值更小,测试准确率更高,特征更有区分度,测试识别率达到了88.4%。
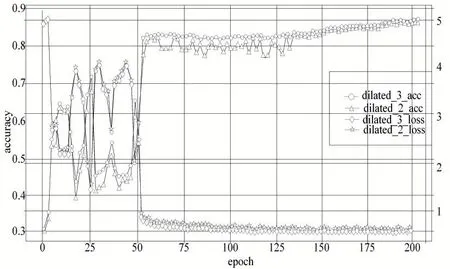
图6 模型4和本文模型的准确率和loss损失对比
上述五个模型实验结果对比如表3所示,结果表明,模型1 在UCF101 上存在过拟合;在引入分组卷积以后,由于参数量减少,有效降低了过拟合,当采用分组数为32 的模型3 时,测试效果更好,识别率达到了82%,比模型2 高1个百分点;在模型3基础上,加入膨胀系数后本文模型行为识别准确率曲线稳定且达到了88.4%,比膨胀系数为2 的模型4 高了1.4%。表明本文模型中的GD-ResNet 特征提取模块能有效减少模型参数量,提取更多图像特征,提高人体行为识别准确率。
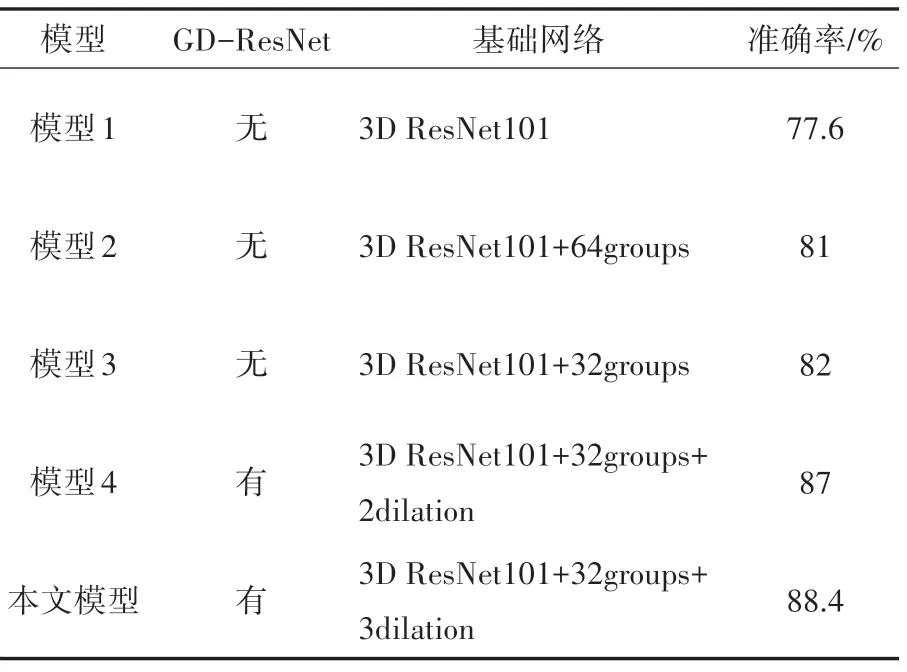
表3 五种不同模型行为识别准确率比较
2.4 与其他方法比较
为了进一步检验本文模型对人体行为识别的效果,将本文方法和3D 卷积神经网络(C3D)模型、刘潇等提出的三维残差卷积神经网络、Varol G 等提出的LTC 网络模型在相同数据集下进行了对比。结果如表4所示,可见本文模型方法较其他方法行为识别准确率有所提高。

表4 不同方法结果对比
3 结语
本文建立了一种基于三维残差网络分组膨胀卷积的人体行为识别方法,以3D ResNet101网络为基础,利用三维残差网络提取时空特征。GD-ResNet 将残差块分成32个并行分组,减少了模型参数量,并在每个分组上使用膨胀率为3的膨胀卷积,增大了模型感受野,提取了更为丰富的特征图信息,最后通过softmax进行分类。在UCF101数据集上进行测试,行为识别准确率为88.4%,验证了本文方法的有效性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13
农业工程学报(2022年12期)2022-09-09
心理学报(2022年9期)2022-09-06
计算技术与自动化(2022年1期)2022-04-15
心理学报(2022年4期)2022-04-12
上海师范大学学报·自然科学版(2019年5期)2019-12-13
电机与控制学报(2018年9期)2018-05-14
中国新通信(2017年9期)2017-05-27
计算机应用(2016年10期)2017-05-12
科技与创新(2015年19期)2015-10-14
