
融合指针网络的Transformer摘要生成模型的改进
2022-05-11 01:30李维乾蒲程磊
西安工程大学学报 2022年2期
李维乾,蒲程磊
(西安工程大学 计算机科学学院,陕西 西安 710048)
0 引 言
文本摘要是从信息源中抽取核心内容的方法,用户获取文本所有的关键信息无需阅读整个文档,在获取信息时节省了大量时间。自20世纪70年代开始,自然语言处理( natural language processing,NLP)在文本摘要细分领域提出摘要任务以来,人们对摘要生成的技术一直在摸索中前进。随着去中心化时代所带来的信息爆炸以及自然语义理解( natural language understanding,NLU)、自然语言生成(natural language generation,NLG)技术的成熟,摘要生成有了显著的进展。目前,自动摘要根据生成方式分为抽取式摘要及抽象生成式摘要。抽取式摘要一般以句子为粒度,根据统计学算法做0、1分类问题[1-2],被分类成1的句子重组之后得到最终的摘要;抽象生成式摘要更像NLG生成任务,在理解原文语义的基础上,用生成的语言概括文章思想[3]。
基于传统无监督机器学习的抽取式摘要,LexRank、TextRank算法以PageRank算法为基础研究,模型简单易实现且生成的摘要也符合语法要求[4]。但抽取式摘要存在语句重复、句与句之间逻辑性差等问题。随着机器学习与深度学习技术的兴起,研究的重心更偏向抽象生成式摘要。RUSH等采用神经网络模型生成抽象生成式摘要,迈出了摘要任务从抽取式到抽象生成式关键的一步[5];NALLAPATI等提出编码-解码结构,编码器采用卷积神经网络,解码器采用循环神经网络结构[6],经过多个数据集和模型测试,以编码-解码结构为基础的框架被普遍认可,并出现了以此为基础,在编码与解码过程中嵌入不同神经网络模型的研究[7-10];还有学者们基于主题模型在抽取方式上进行了探索[11-13],这些研究共同推动了摘要生成任务的发展。
注意力机制在同属Seq2Seq重复问题的翻译任务中取得了较好的成果后,很快被引入到翻译任务中,但传统加有注意力机制的编码解码模型虽然解决了编码到中间语义向量过程中出现的遗漏或覆盖的问题,但无法获取输入文本的位置信息,而中文的写作特点也决定了在获取摘要时文本的位置信息的重要性[14-15]。因此,本文从中文摘要的任务需求出发,通过在解码部分引入指针网络,对传统Transformer模型进行了改进,用以生成新闻摘要。
1 摘要生成模型基础框架
随着机器学习和深度学习技术的兴起,在引入多种模型在处理摘要的任务上进行测试后,以编码器解码器结构为基础的模型成为主流的模型框架。编码-解码模型是一种应用于Seq2Seq的模型,目前广泛应用于NLP任务的各项分支任务中。编码是将输入的文本序列转化为一固定长度的向量,解码过程是将该固定向量转化为输出结果。为了解决序列预测问题,使用端到端的映射模型[14],用LSTM进行编码、解码操作,做英法互译的翻译任务。在Encoder-Decoder的基础框架下,所用的编码器和解码器都不是固定的,可根据任务与数据特点挑选适用的模型。
但Encoder-Decoder模型在处理Seq2Seq问题上存在明显的缺陷,即编码与解码之间的唯一联系是有固定长度的中间语义向量C。编码器将整个输入的文本信息进行压缩至固定长度的向量,出现了中间向量因长度固定无法完整地表示序列信息;当输入文本过长时,后续的输入被先输入的内容稀释或覆盖,并且随着输入序列的增长而愈发严重,解码无法获得完整的信息,导致准确度缺失,影响输出。
为了解决传统模型存在的问题,文献[7]在翻译任务上提出了Attention模型。Attention模型不局限在全局语义的定长编码向量C上,在输出时会产生后续输出时需要着重关注的范围,再根据标记的区域产生下一个输出。相比传统的编码-解码模型,Attention模型在处理Seq2Seq问题时不要求所有输入信息压缩至定长的中间向量,解码的同时每次都由规则选择一个来自中间向量的子集,使输入序列所携带的信息在每次输出时都被充分利用。
在中文摘要任务中,注意力机制的引入解决了RNN在编码上的问题,但Attention模型无法提取位置信息,即和法学习输入序列中的顺序关系[16-17]。Transformer模型具有比传统模型效率更高的自注意力机制,并且可以获得输入文本的位置信息,更符合中文摘要的任务特点,故选择对Transformer模型进行改进。摘要任务的输入文本较长,导致最终生成的摘要文本长度较短,与机器翻译任务虽有类似,但摘要任务对解码的要求更高。因为传统的Seq2Seq模型输出的是针对输出词汇表的一个概率分布,但指针网络[18]输出的则是对输入序列的概率分布。对于摘要任务来说,最终生成的文本所陈述的内容来源应来自输入文本,指针网络的这一特征更契合摘要任务最终所生成的文本要求,并且指针网络适合用于解决非登陆词(out of vocabulary,OOV)问题,可以使最后生成的摘要在保留与原文内容一致性的前提下,使冗余性低的摘要有更好的可读性。
2 生成式摘要模型
2.1 编码解码模型
Encoder-Decoder模型中,在编码阶段将完整句子压缩到固定维度的向量空间,会形成包含文本信息的中间语义。当输入的文本内容较多时,固定维度的向量难以包含完整的输入信息,而解码则受限于该固定长度的向量表示,造成解码时的信息缺失。这一局限性使摘要任务进展很难,但随着注意力机制被引入到Encoder-Decoder模型中,就不需要将所有信息都存储在中间语义中。引入注意力机制的编码解码模型结构如图1所示。

图 1 引入注意力机制的编码解码模型结构Fig.1 Encoder-Decoder model with attention mechanism
解码过程与Encoder-Decoder模型类似,即将原本的语义向量C转为Ci,Ci是对每个输入的(x1,x2,x3,…,xt)编码后的隐性状态的权重相加,即
(1)
(2)
eij=a(sj-1,hi)
(3)
式中:aij表示在生成第i个输出时受第j个输入的影响;hij表示编码的隐性状态;sj表示经过解码的隐性状态;eij表示第i个编码处的隐性状态和第j-1个解码后的隐性状态的匹配;a表示神经网络共同训练结果,反映hj的重要程度。
2.2 Transformer模型的改进
文章写作结构特点、文本位置信息对摘要任务尤为重要。在可嵌入文本位置信息的Transformer模型基础上改进更契合摘要任务的要求,在解码阶段加入指针网络解决了OOV问题,规避了Seq2Seq模型常见的重复问题,提高了最终生成摘要的准确性和语言的流畅性。改进的Transformer模型结构示意图如图2所示。
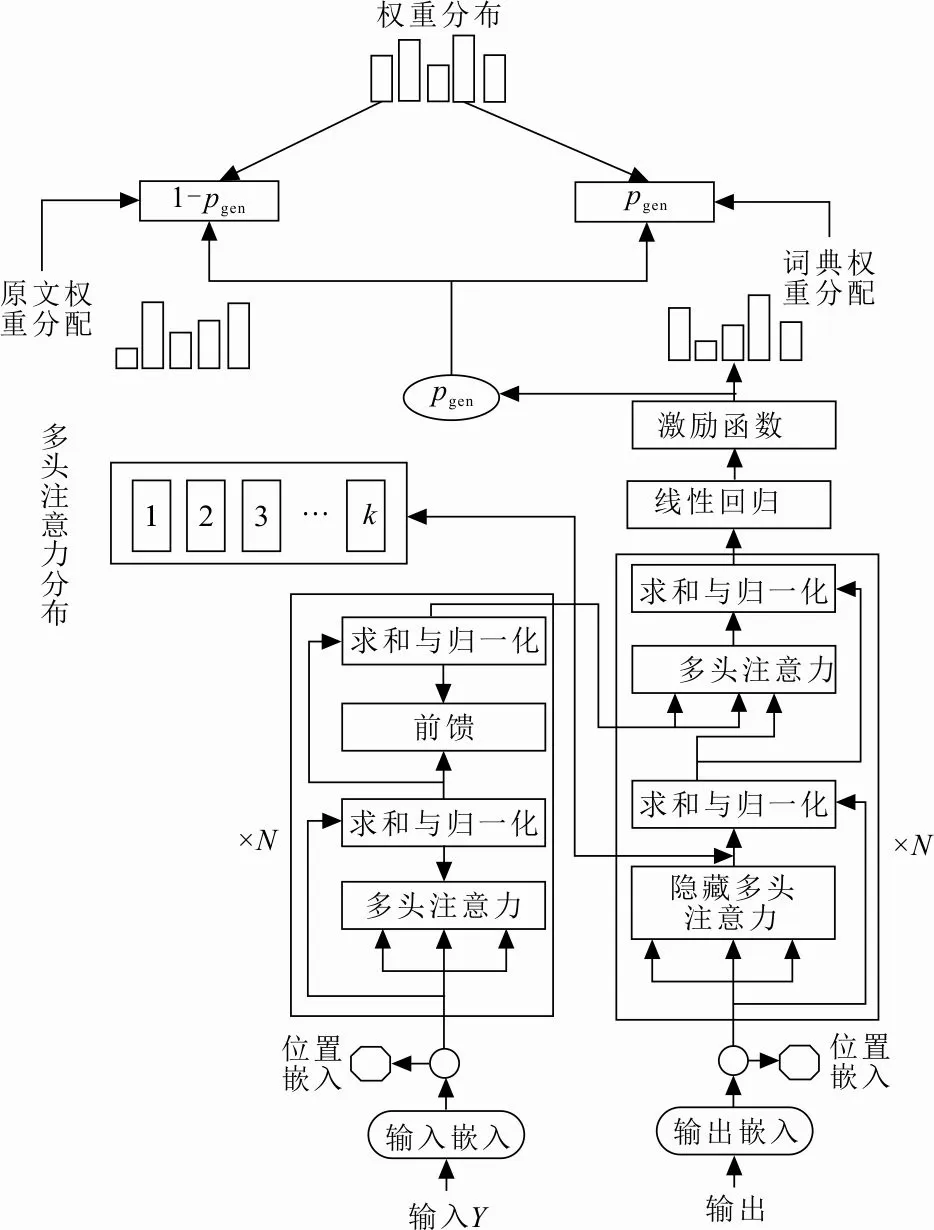
图 2 改进的Transformer模型结构示意图Fig.2 Model structure diagram of improved transformer
最早提出Transformer模型是作为一种基于注意力机制来实现的特征提取器,用于代替传统神经网络卷积神经网络和循环神经网络来提取序列的特征。在NLP领域中,Transformer模型对输入的文本进行编码,在词嵌入阶段加入位置信息嵌入,对文本位置信息进行编码,输入Y应首先通过嵌入词向量与位置编码。在词嵌入过程中通过语料库训练表示词向量,可以很好地将相关任务场景下的外部知识引入模型并建立字典,即每个字无论中英文都有其唯一的信息与之对应。假设编码模型一次性输入训练的文本规模为一个批次的句子,输入Y=(gij)bs×l文本矩阵数据,bs表示批次规模大小,l表示句长,则每个字都有一串规模为demb长度的数字表示嵌入信息,即
Y=(E+EP)×L(Y)
式中:E表示输入编码;EP表示位置编码。Transformer模型以捕捉输入位置信息的方式,替代了循环神经网络的迭代操作用来识别顺序关系,在位置向量规模lmax×demb中,lmax为限定最大单个句长的超参数。起始的输入信息词向量维度为v×demb,通过使用sin和cos函数的周期变换提供模型位置信息,即
EP(p,2i)=sin(f(p)×1 000×2m)
(4)
EP(p,2i+1)=cos(f(p)×1 000×2m)
(5)
式中:p表示句中字的位置,p∈[0,lmax);i表示词向量维度,i∈[0,demb);m表示向量的最大维度,即m=512。函数周期从2π 到2π×103变化,而每个位置都会得到sin和cos函数取值组合不同的结果。随着维度序号的增大,周期变化会愈发减缓,产生特定的位置信息,模型从而学习到输入序列之间的位置依存关系和文本的时序特性。经过嵌入词向量和位置信息的编码后,对输入文本计算自注意力。输入词向量Y的自注意力为Ya,
Q=LQ(Y)
K=LK(Y)
VV=LV(Y)
Ya=As(Q,K,V)
式中:LQ、LK、LV均为线性映射。
自注意力的计算不依赖词之间的顺序,而是通过词与词之间相似度的挖掘顺序信息[19-21],从而规避了传统的编码解码模型在输入序列过长时所引发的中间误义缺失,以便更好地理解上下文,提高了编码解码模型的效率。
在计算自注意力过程中,通常一次计算多句话,即输入Y的维度为bs×l,Y由多个长度不一致的句子构成,其中每个句子需要按照长度最长的句子用0补至等长。
经注意力矩阵加权后的A(Q,K,V),通过对矩阵进行转置,使其保持与Y维度一致。每个模块都需经过之前的模块元素求和并进行残差连接,一直到训练阶段。以梯度进行反向传播,并通过标准化层将隐藏层归一至标准正态分布来帮助加速训练、收敛。
经过前向传播、隐藏层的残差连接与标准化,得到中间语义隐藏层的信息Yh,维度为bs×l×demb,将编码得到的信息整合即可进行解码操作。
指针网络对中间语义解码的每一步,都会计算出决定生成还是复制的概率Pgen∈[0,1],指针网络分别由词汇表和原文本作为来源。

式中:Pvocab(w)表示按原词表计算的单词概率分布;P(w)表示按加入OOV后新词表计算的单词概率分布。
如果预测的单词是“win”,而单词不在事先构建好的词表中,即Pvocab(win)为0,“win”的注意力权重与(1-Pgen)的乘积作为该单词的概率。基于此概率从原文复制“win”到摘要中。如果预测的词是“beat”,单词在事先构建好的词表中而不在原文中,则“beat”没有注意力权重。按原词表计算的概率生成“beat”到摘要中。这样的生成方式解决了OOV问题。
损失函数以损失交叉熵计算。以P(w)计算损失,记为l。t时刻表达式为

求出梯度后根据其计算函数的变化更新参数,即
(6)
(7)
式中:R、W1、W2为训练最终得到的参数。
指针网络的引入,在解码时对摘要的基于原文的复制或从字典的生成提供了更多的可能,并且解码使用的集束搜索与损失交叉熵的计算都使生成的摘要更具流畅性、准确性。
3 实验设计与结果分析
3.1 实验数据
训练语料库采用LCSTS[22],该语料库超过200万个中文实际短文本,每个数据包含原文和对该短文出自原作者的简短摘要,每篇文本的长度约100个字符,作者每篇摘要约20个字符。通过实验数据构建训练集与测试集,并将10 666个相关性的简短摘要标记为其相应的参考作为验证集。在验证集上训练调整模型参数,测试集用于检测评分。
3.2 实验设计
在训练模型参数调优的设置上,根据对数据的统计将原文本长度的范围限制为[50,100],生成摘要长度范围限制为[10,30]。根据数据整理出字典大小为5 000个字符,词向量与词向量的规模均为500维,每批次训练256个。采用梯度下降法训练模型并获取参数,学习率为0.35。通过PyTorch框架进行代码实现,模型共训练了35个epochs。选取以下模型进行对比分析:
1) RNN[6],即最早提出实验数据集的模型。
2) RNN-context[6],在RNN模型的基础上使用了注意力机制。
3) Cover-5[23],在注意力基础上添加了覆盖机制的Seq2Seq摘要模型。
4) PGC[24],以编码-解码为框架的基于注意力与指针网络的生成网络,作为本文实验的基线模型。
5) Transformer+Pointernetwork为本文模型。
本文评价指标采用ROUGE评估模型的优劣,ROUGE是以生成结果与参考摘要中n元公共子序列的个数计算得出评分,生成的结果与参考摘要中共现的词语越多,ROUGE得分就会越高。
3.3 结果与分析
以ROUGE-1、ROUGE-2、ROUGE-L进行评价,ROUGE-1和ROUGE-2分别指1元和2公共元子序列,ROUGE-L表示最长公共子序列。从测试结果中抽取得分最高的句子进行ROUGE评测,ROUGE评分对比结果见表1。

表 1 ROUGE评分对比Tab.1 Comparison of ROUGE score
从表1可以看出,基于RNN的方法在是否添加了注意力机制的对比中,RNN-context模型在3个指标中平均高出其他模型6分,说明在NLP任务中对注意力机制的依赖性。通过Cover-5模型与RNN、RNN-context 2个模型的对比发现,Cover-5模型融合了可以避免让注意力机制在同一个地方赋予高权重的覆盖机制,可以消除重复的语句,其处理结果在ROUGE的评测中的表现比RNN好。但对于信息更好地编码解码指针网络,其优越性更高。相比于其他模型,本文提出的模型在ROUGE的各指标上都有提升,平均高于基线模型2分。在编码阶段,Transformer模型对位置信息的捕捉,以及多头自注意力机制对输入文本的局部与全局所分配的权重配比,同时解码阶段的指针网络展现出更大的生成优势。验证了各阶段选取的模块都更适合摘要任务的需求。
不同模型生成摘要重复率对比如图3所示。

图 3 不同模型生成摘要重复率对比Fig.3 Comparison of repetition rates of summaries generated by different models
从图3可以看出,传统的编码解码模型生成的重复率较高,并且在每个指标上均明显高于参考结果。虽然采用了不同公共子序列重复率有所下降,但下降的幅度仍然过于迟缓。本文基于Transformer改进的模型加入了指针网络后,重复率基本保持与训练数据集中的参考摘要同样的下降速率,但在长度较短的指标上与参考存在差距。
不同模型生成摘要的新词生成率对比结果如图4所示。

图 4 不同模型生成摘要新词生成率对比Fig.4 Comparison of new word generation rates for summaries generated by different models
从图4可以看出,在不同长度的评测指标中,本文模型生成的摘要比参考摘要、基本模型都低,虽然基本模型生成的新词较多,但其包含大量不恰当的词语,造成结果的事实性偏差。本文模型所生成的摘要更可靠,对原文中的细节信息有更好的捕捉能力。
从整体摘要的评判ROUGE来看,判定中所关注的点为关键信息显著性、语言流畅性、内容重复性、陈述事实性以及摘要与原文的一致性,选取的样例更加直观地展现本文模型在摘要任务上的优势。
例1 原文:百盛青岛啤酒城项目金狮广场已现雏形外墙醒目的大字预示着这里将来的商业繁荣百盛14亿收购青岛购物中心相关消息称百盛未来新开门店将以店中店和购物中心为主不再开设单体百货外资第一百货品牌百盛也开始走自我转型 的道路。
摘要:青岛啤酒城项目更名青岛购物中心。
例2 原文:记者采访获悉阿里集团电商资产将于年内上市这将是陆兆禧出任阿里集团CEO所面临的首要任务届时阿里巴巴将可能成为全球第三大市值公司估值为 腾讯与百度市值之和陆兆禧2011年出任阿里B2BCEO时曾成功完成香港退市的任务。
摘要:阿里集团电商资产年内上市。
4 结 语
本文提出了基于Transformer改进的混合模型在处理中文文本生成式摘要任务时,通过对Transformer模型的改进,达到了比传统引入注意力机制的编码解码模型更好的效果。Transformer的多头自注意力机制有更高的效率,在编码阶段对位置信息的捕捉可获得更为契合摘要任务的中间语义;使用指针网络进行解码,不但可以缓解OOV问题,同时在生成摘要的准确性上表现较好。模型在数据集LCSTS上ROUGE的评分提升明显。生成的摘要在保证内容事实性的前提下,保持对于原文极低的重复率。生成式摘要比抽取式摘要在NLU和NLG的技术上要求更高,但仍然存在不准确和重复词。在保证摘要事实性的前提下,可进一步提高新词生产率以逼近人为书写的摘要。在后续的工作中不断优化模型,提高生成摘要的准确性。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国典型病例大全(2022年7期)2022-04-22
睿士(2020年6期)2020-08-18
南方周末(2019-12-19)2019-12-19
南方周末(2019-07-18)2019-07-18
娃娃画报(2019年4期)2019-05-14
南方周末(2019-05-09)2019-05-09
广东第二课堂·小学(2017年9期)2017-09-28
软件工程(2014年3期)2014-03-15
电影新作(2014年2期)2014-02-27
