
基于U-Net的多尺度视网膜血管分割方法
2022-05-10 00:02喻鲁立
计算机技术与发展 2022年4期
喻鲁立,陈 黎,2
(1.武汉科技大学 计算机科学与技术学院,湖北 武汉 430065;2.智能信息处理与实时工业系统湖北省重点实验室,湖北 武汉 430065)
0 引 言
视网膜血管的形态和结构一直是高血压、冠心病、糖尿病等疾病的重要诊断指标之一。视网膜血管作为人体内唯一可以无创观察到的清晰血管,其检测与分析对于上述疾病的研究有着重要的意义。但是由于视网膜血管密集且复杂,传统的形态提取方法是由医生来进行手工分割,耗时较多,不能满足大量病患的诊断需求,同时也容易受到分割者主观因素的影响导致手工分割的质量不高。因此视网膜血管分割任务成为了计算机图像处理领域的热点和难点。近年来,深度学习发展逐渐成熟,自2012年AlexNet[1]刷新了Imagenet[2]的最好结果之后,深度卷积神经网络在计算机视觉的各个领域都取得了不错的成绩。FCN[3]在PascalVOC分割任务中取得了卓越的成绩,U-Net[4]在某些医学图像处理上取得了最高的精度。PSP-Net[5]和DeepLab[6]也在其他的语义分割的任务中取得了好的成绩。在这些神经网络结构中,Ronneberger等[4]提出的结构在医学图像处理中是被应用的最广泛的一种。
目前,国内外研究人员提出了许多基于U-Net结构的视网膜血管分割方法,比如文献[7]提出了在U-Net中采用循环卷积块。文献[8-10]提出将注意力模块引入U-Net结构中使得网络能选择性地专注于显著部分,以便更好地捕捉视觉结构。文献[11-13]提出在U-Net结构中引入密集连接块(Dense Blocks)。文献[14-15]提出将U-Net结构中的卷积块替换成Inception模块增强网络对空间信息的提取能力。文献[16]提出基于U-Net的多路径网络,在U型结构中增加多个U型子网络。该文将基于U-Net进行改进,将多尺度策略和Gao Huang等[17]提出的密集链接相结合以增强模型对图片进行特征提取时在不同分辨率下的信息提取能力,使模型在视网膜血管末梢以及分叉处取得更精细的分割结果。
1 相关工作
1.1 更深层的神经网络
随着神经网络的网络层加深,不同的模型之间的差异更加明显,这也驱使着研究人员开始重新审视以往的研究思路,并且开始探索网络层间不同的连接方式。Highway Networks[18]是第一个能对一百层以上的端到端网络进行有效训练的网络结构,通过使用旁路和可学习的门限机制使得部分信息流在无衰减的情况下通过一些网络层。而这些跳过一些网络层的跳层链接被认为是减轻深层网络带来的梯度消失影响的关键,文献[3,19]证明了卷积神经网络的跳层链接是有效的。而ResNets[20]的提出进一步证明这一观点。由此,Gao Huang等[17]提出密集连接网络。在传统网络结构中,通常将第L层的输出结果作为第L+1层的输入,从而有转换XL=HL(XL-1)。而ResNets[20]增加了一个跳层链接,通过公式(1)跳过了非线性转换。
XL=HL(XL-1)+XL-1
(1)
ResNets[20]的一个优点是梯度可以直接从后面的网络层传递到较早的网络层,但是这也可能会阻碍网络层之间的信息传递。而更密集的连接可以进一步改善层与层之间的信息传递。Gao Huang等[17]提出了一种不同的连接方式,将每一层的输出都当成后续网络层的直接输入。也就是说网络中的第L层的输入是前面0至L-1层的输出。
XL=HL([X0,X1,…,XL-2,XL-1])
(2)
其中,X0,X1,…,XL-2,XL-1是L层以前的各个层生成的特征图的串联。这样的连接方式减轻了深层网络梯度传播对网络性能的影响。同时,Krizhevsky等[1]提出的ReLU激活函数已经在主流神经网络结构中替代了sigmoid激活函数。使用ReLU激活函数被证明可以使加深的网络层更容易收敛,ReLU激活函数的公式如下:
ReLU(x)=max(x,0)
(3)
Batch Normalization[21]作为一种可以学习的归一化层,可以在一定程度上减轻梯度消失和梯度爆炸给网络带来的负面影响,同时也不会消耗过多的算力。可以通过在网络中逐层进行归一化处理的方式来减小反向传播时较远层因梯度传递造成的负面影响。
1.2 多尺度策略
目前大多数语义分割网络都采用了编解码结构。由于在编码过程中降低了图像的分辨率,所以这种方法会忽略图像中的一些细节。为了解决这一问题,Ronneberger等人[4]提出在编码器和解码器之间建立跃层连接,使得网络能更加有效地提取到不同层次的特征,从而取得更精确的分割结果,但对于目标信息仍然会有丢失。为了解决这一问题,文献[22-23]通过在传统网络中引入多尺度学习策略来增强目标信息的特征提取从而提升任务精度。文献[6]证明可以通过引入较低级别的特征进一步加强细节信息的获取。随着多尺度策略的进一步研究,多尺度特征融合策略引入了上下文相关的组合,共同利用高级特征和低级特征的优势。文献[24-26]合并了多尺度特征以进行语义分割,并提升了分割结果的精度。同时,Sun Ke等[27]提出的高分辨率网络,在整个过程中维护高分辨率的特征,逐步增加高分辨率到低分辨率的子网,形成更多的阶段并将多分辨率子网并行连接。这个方法在人体姿态任务中取得了良好的效果。因此多尺度策略可提升网络的性能。
1.3 损失函数
视网膜血管分割是一个像素二分类问题,视网膜血管区域定义为正样本,其他区域定义为负样本。而在数据集当中,正负样本的比例接近1∶9,正负样本比例严重失衡,如果采用图像分割任务中常用的均方差损失函数或二分类交叉熵损失函数,网络则会更加关注样本多的类别,使模型的预测结果强烈地偏向负样本。因此,样本少的部分经常缺失或是只能被部分检测到。所以实验中,该文采用Fausto Milletari等[28]提出的Dice损失函数来对模型进行参数更新。公式如下:
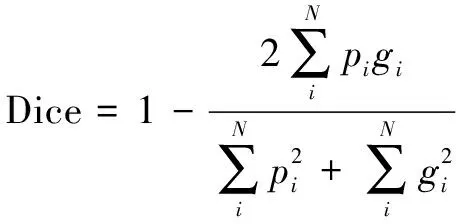
(4)
其中,N表示模型需要预测的像素点总数;pi[0,1]表示每个样本的预测值;gi{0,1}表示每个像素的标签值。Dice对每个像素点计算梯度的公式如下:
(5)
2 文中方法
文中提出的方法是基于U-Net[4]改进的模型,主要改进是在U-Net网络的编码阶段和解码阶段之间通过增加密集连接网络的方式维持了网络对编码阶段每一层输出的特征图的学习。然后将密集连接网络输出的特征图输入到解码器的相应层中,接着与其他各层的特征图进行融合。以此来提高网络的特征提取能力,从而使网络学习到更多的细节信息。
提出的模型整体呈一个四层的倒梯形结构,每一层都保持着该层对应分辨率下的特征表达。其网络结构如图1所示。网络中有三次下采样和三次上采样,该文将保持编码阶段每次下采样之前得到的特征图的表达,直到与解码阶段对应的上采样特征图融合进入该层对应的解码阶段,并且通过ReLU激活函数来加强特征图的细节信息,从而提高网络对特征图细节信息的提取能力,在特征图融合的时候对不同尺度的特征图的尺度和通道进行融合,然后将融合后的特征图输入到对应的解码阶段。
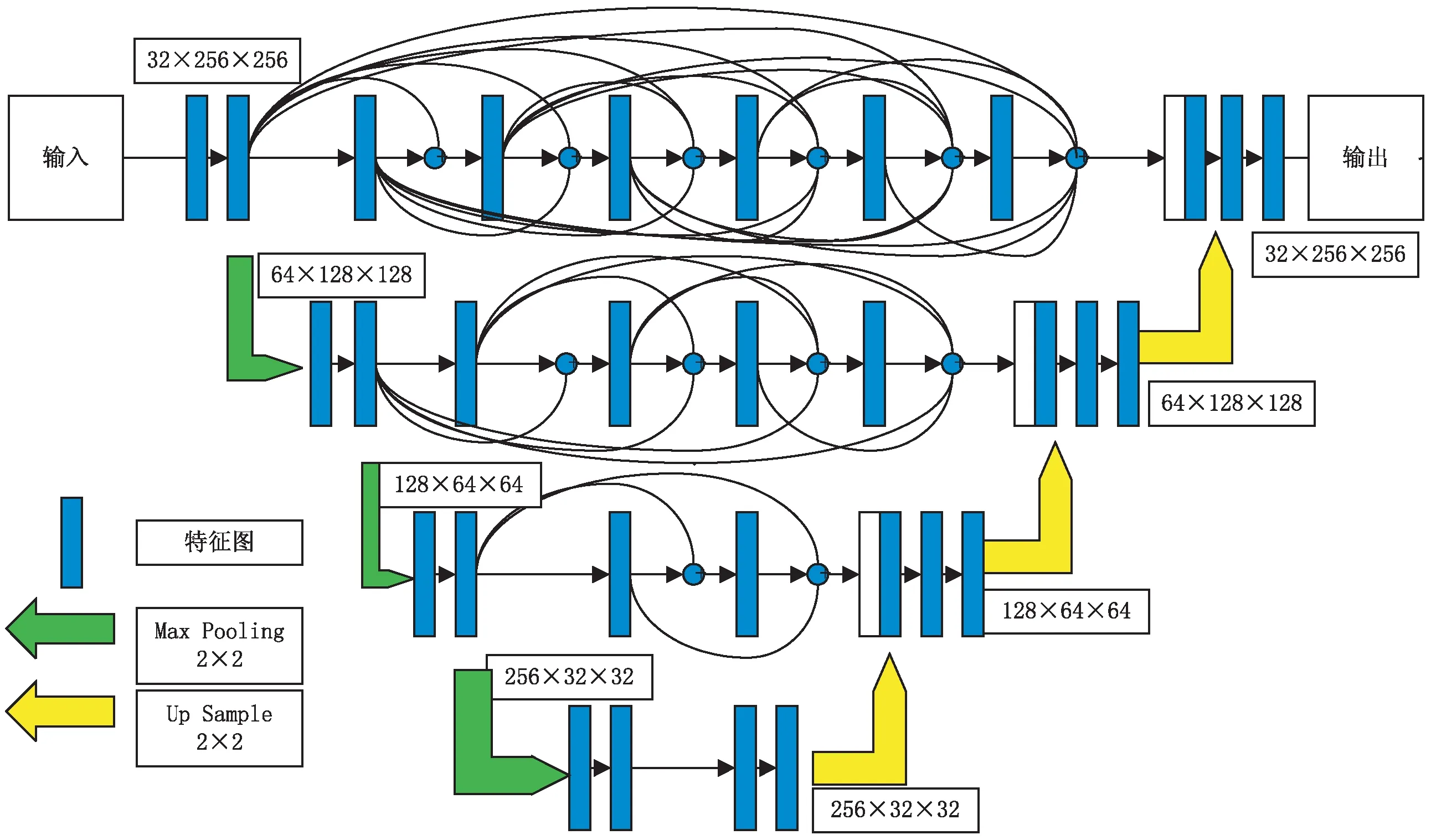
图1 提出的网络结构
2.1 多尺度方法
为了保持不同分辨率下特征图的表达,使网络能更好地学习到图像中所包含的信息,该文在编码阶段和解码阶段的对应网络层中间增加了部分卷积块用来保持模型对不同尺度特征的学习。然后将经过这些增加的卷积块进一步提取信息后输出的特征图输入到解码阶段对应的网络层中,与低分辨率网络层经过上采样以后的特征图进行融合,使网络尽可能地保留不同尺度的特征信息。方法如图2所示。
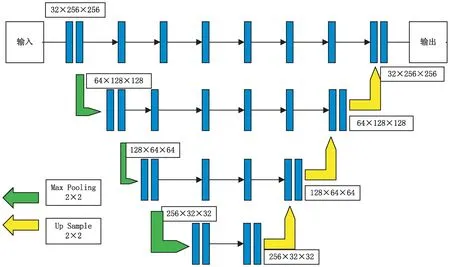
图2 保持多尺度特征提取的结构
2.2 密集连接
由于该文在编码阶段和解码阶段中间增加了部分卷积块,导致网络变的更深,使得网络丧失了部分浅层的特征,同时产生了深层网络常有的梯度消失问题。所以在增加的卷积块之间使用密集连接,增强网络中的信息传递,解决梯度消失和浅层特征缺失的问题。以图3为例。特征图进入模型编码阶段后输出的结果为x1,x1经过归一化处理后作为该层后面每一个卷积块的输入,x1经过第一个卷积块后生成的特征图x2再经过归一化处理后也作为该层后面每一个卷积块的输入,所以第二个卷积块的输入为y2=H([x1,x2])。以此类推,解码阶段对应层的输入为y=H([x1,x2,x3,x4])。
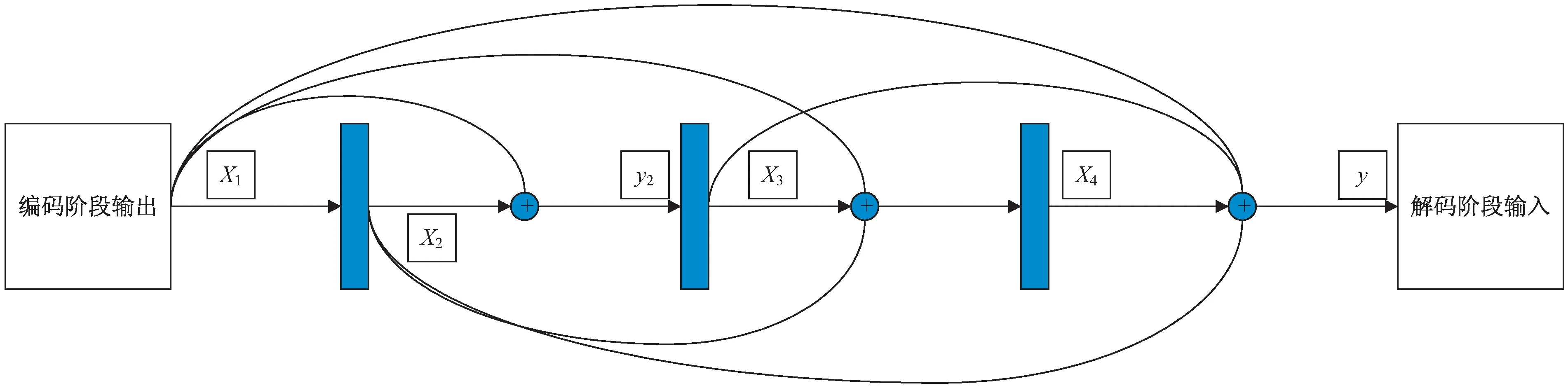
图3 密集连接
常规的U-Net采用的是编码器最后一层的输出作为解码器的输入,这一输入含有最丰富的语义信息,但是图像经过多重卷积和池化操作后会缺少一些细节信息,因而对于分割目标会出现过分割和欠分割的问题,所以该文选择保持不同分辨率下的特征表达,并使用密集连接的方式保证网络中的信息流通。最后将多尺度多层次的特征图输入到解码阶段对应的网络层中与其他尺度的特征图进行融合。从而使最终的特征图保留不同尺度下的细节信息。
3 实验结果及分析
实验在一个工作站上运行,操作系统为ubuntu18.04,工作站配备Intel(R) Xeon(R) CPU E5-2620 V4处理器,主频为2.10 GHz,内存64G,GPU由四个TiTan XP组成。
3.1 实验数据及其预处理
实验采用了DRIVE数据集和CHASE_DB1数据集。DRIVE数据集中包含40张彩色视网膜图像以及视网膜图像标签,其中前20张图像及其标注图像作为实验的训练样本,后20张图像及其标注图像作为实验的测试样本;CHASE_DB1数据集中包含28张彩色视网膜图像以及视网膜图像标签,在该数据集随机挑中20张图像及标注用于训练样本,其余的8张图像及标注用于测试样本。在只有少量样本用于实验的情况下,为了提升模型的分割效果,增强模型的鲁棒性,实验中对每个数据集进行如下操作:首先对每张图像以48为间隔裁剪成256×256的图像块,并且对每个图像块及其标注图像以25%的概率随机进行上下左右翻转。同时也对每个图像块随机进行图像增强操作。由于模型对图像进行了三次下采样,所以该实验需要将图片填充至长宽都为8的倍数,所以在测试前在图片周围填充一些值为0的像素点。
3.2 评价指标
在视网膜血管的分割中,若模型预测的结果与专家的标注图像相同则该像素点为真阳性(TP),若相反,则该像素点为假阳性(FP);对于图像背景,若预测图像像素点与标注图像相同则该像素点为真阴性(TN),若相反则该像素点为假阴性(FN)。
为了定量分析网络模型的分割结果并且更好地与其他方法进行对比,采用准确率(ACC)、灵敏度(SE)、特异性(SP)和F1分数(F1-score)这四个通用指标来客观评价模型对视网膜血管的分割效果。其中F1分数越高,表示模型的分割结果与标注图像越相似。以上指标计算公式如下:
(6)

(7)
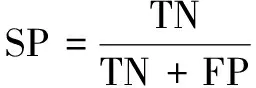
(8)
(9)
(10)
(11)
3.3 参数设置及训练
该优化方法采用随即梯度下降算法(stochastic gradient descent,SGD);训练批次设置为1 000;batchsize设置为8;测试批次为1;学习率初始化为0.001,权重衰减设置为0.9,在训练中使用poly策略对学习率进行调整,公式如下。
(12)
3.4 实验结果与分析
为了证明密集连接的有效性和必要性,进行了是否加入密集连接的对比实验。结果如表1所示。
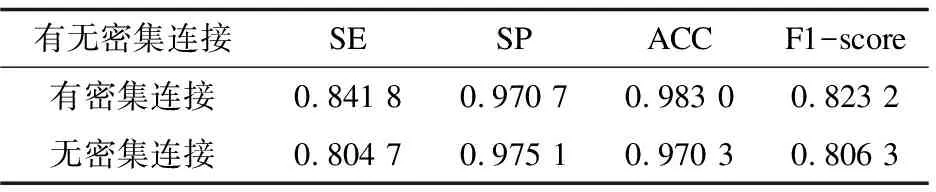
表1 是否增加密集连接的消融实验
经过实验发现,该模型的分割能力和损失函数的采用有关。为了取得更好的效果,使用分割中常用的交叉熵损失函数(BCE loss)和Dice损失函数进行了对比实验,结果如表2所示。实验结果表明,使用Dice损失函数得出的分割结果在灵敏度和F1-score上要大幅优于使用交叉熵损失函数得出的结果。这是由于在视网膜血管在图像上存在严重对类别不平衡,使用交叉熵损失函数训练网络容易导致模型受到样本占比较多的类别影响导致模型过拟合。而Dice损失函数可以解决样本分布不均衡的问题,并在训练过程中对难以学习的样本进行有针对性的优化。从而缓解样本分布不均衡带来的负面影响,提升模型的性能。
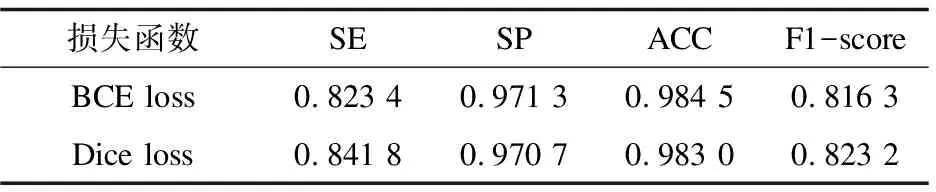
表2 损失函数的消融实验
为了验证文中算法的模型分割性能,,将文中算法与U-Net[4]、Residual U-Net[29]、Ladder-Net[30]、R2U-Net[7]四种分割网络进行对比实验。采用相同的网络训练参数,对以上五种网络分别进行训练,并利用验证集对训练好的模型性能进行测试。
文中算法与U-Net[4]、Residual U-Net[29]、Ladder-Net[30]、R2U-Net[7]在各项评价指标上的对比情况如表3和表4所示。在CHASE_DB1数据集上,文中算法相比于其他四种分割网络的灵敏度、特异性、准确率和F1-score均有不同程度的提高;在DRIVE数据集上,文中算法相比其他四种分割网络的灵敏度、准确率和F1-score均有不同程度的提高。
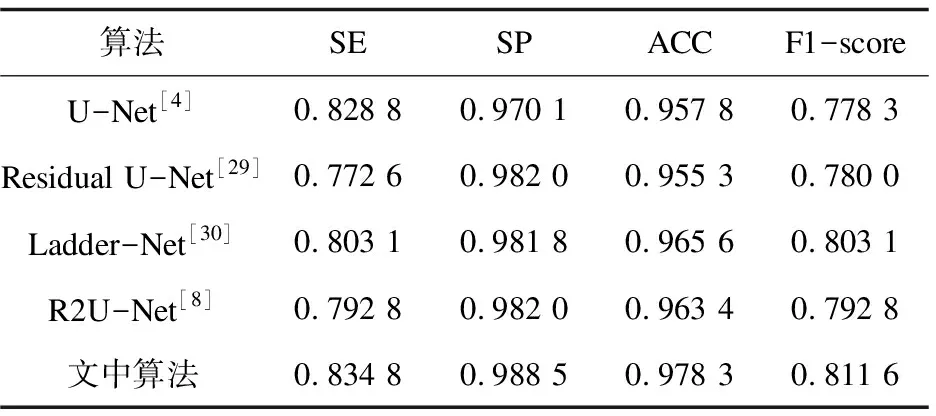
表3 在CHASE_DB1数据集上的分割性能对比
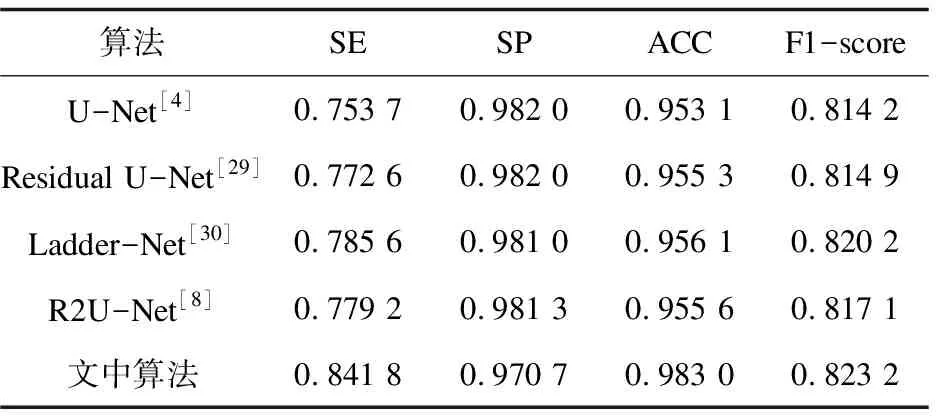
表4 在DRIVE数据集上的分割性能对比
图4展示了文中算法的分割效果。由图4可以很直观地看出,对于DRIVE数据集,文中算法的分割结果相比于U-Net的分割结果,对于图像右侧和图像中部的细小血管保留更加完整,分割轮廓也更加清晰。对于CHASE_DB1数据集,文中算法的分割结果相比于U-Net的分割结果,在图像四周的细小血管末梢分割更为清晰,并且有效解决了细小血管断裂的问题,血管的连通程度更高。
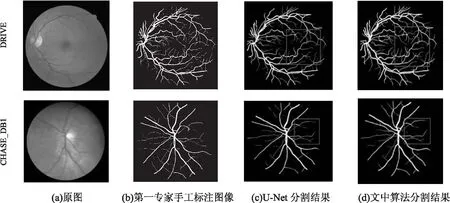
图4 分割结果对比
4 结束语
针对视网膜图像处理和医学影像的分割特点,传统的分割网络对于过分割和欠分割等问题,提出了一种通过在网络编解码结构中采用密集链接的方式增加卷积块的方法,增强了模型在不同尺度下对于图像细节的提取能力,确保最大程度地保留细节信息。从实验结果可以看出,该算法相比于其他算法有更好的分割效果。在后面的工作中,将着重于解决部分细小血管分割断裂的问题,进一步提升模型的分割精度。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
计算机仿真(2022年7期)2022-08-22
现代仪器与医疗(2022年2期)2022-08-11
老友(2022年4期)2022-05-18
计算技术与自动化(2022年1期)2022-04-15
农村百事通(2021年12期)2021-01-17
上海师范大学学报·自然科学版(2019年5期)2019-12-13
保健与生活(2019年12期)2019-07-31
中国信息化周报(2015年1期)2015-04-09
