
融合文本特征的老挝语文字识别方法研究
2022-05-10 01:29杨志婥琪周兰江周蕾越
小型微型计算机系统 2022年4期
杨志婥琪,周兰江,周蕾越
1(昆明理工大学 信息工程与自动化学院,昆明 650500)
2(昆明理工大学 津桥学院 电子与信息工程学院,昆明 650106)
1 引 言
老挝是我国邻邦,老挝语为老挝的官方语言,属于低资源语言.面对老挝语语料匮乏的问题,老挝语的光学字符识别(Optical Character Recognition,OCR)技术相较于人工录入较为节省人力和时间,可为老挝语自然语言基础任务的研究提供大量语料,也对其他东南亚小语种的文字识别研究有一定促进作用.
目前,国内外有关汉语[1]、英语[2]等大语种的光学字符识别研究已趋于成熟,而老挝语的相关研究还处于起步阶段,国内对小语种的OCR技术研究主要是针对藏文[3]、蒙古文[4]、维吾尔文[5]等.因此,研究老挝语的OCR技术需借鉴其他语种的研究方法,但老挝语有其独特的行文方式,如:老挝语有着固定的词序,不通过词的内部形态变化表示语法,且老挝词字符结构丰富,存在音调等非水平位置的字符等,使得其他语种的文字识别方法并不完全适用于老挝语.因此,对于老挝语的光学字符识别,目前存在如下问题:
1)由于老挝语属于低资源语言,可用于老挝光学字符识别模型训练的文字图片资源极少,较少的训练语料导致模型不能提取足够特征,识别效果较差.
深度学习的发展使得端到端的OCR技术已成为主流.文献[6]中的端到端文本序列识别框架,用卷积神经网络(Convolutional Neural Networks,CNN)作为特征提取器,采用双向长短期记忆网络(Bi-directional Long Short-Term Memory,BiLSTM)编码候选特征,CTC(Connectionist Temporal Classification)进行解码,简化工作流,并在基准数据集上取得较好的结果;文献[7]采用基于注意力的方法解决OCR任务,通过注意力机制获得文本序列中每个位置的权重,打破了文本固有的从左到右排序的假设;文献[8]则尝试将注意力机制设置在编码部分,进一步增强CNN提取的特征值,提高文本识别的准确性;文献[9]结合字符级向量,并通过BiLSTM网络来识别文本序列.
本文借鉴前人的研究,针对老挝语文字识别存在的困难,以端到端模型为基础,构建了融合文本特征的老挝语文本识别模型.首先,将老挝文字图片输入具有残差结构的CNN网络以提取图片的特征信息,并加入卷积注意力模块[10](Convolutional Block Attention Module,CBAM)进一步获取图片关键信息.其次,采用Glove语言模型[11]对图片标签集进行预训练,获取具有上下文语义信息的标签字符向量和词向量,并与CNN提取的图片特征信息通过注意力机制动态分配权重进行组合,得到包含图像特征和全局语义信息的特征向量,融合图像信息和文本信息能有效提升模型文字识别准确率.再次,将组合的特征向量输入双向长短期记忆网络(BiLSTM),结合上下文语义信息预测出文本序列标签的真实分布,同时,将老挝音节组成规则融入模型,作为预测老挝音节规则标签的分支,用BiLSTM提取特征,以参数共享的形式优化老挝文字识别模型,并通过该分支的损失值增强模型训练效果.最后,采用CTC转录,把从循环层获取的标签分布进行序列对齐,得到最终识别结果.
本文主要贡献如下:1)将图片标签的文本语义信息融入文字识别模型,与图像信息动态组合,语义信息能有效提升老挝文字的识别效果;2)提取图片标签的词法特征,并以参数形式与老挝文字识别模型共享,能有效识别字符结构复杂的老挝文字;3)在CNN网络中引入带有卷积注意力模块(CBAM)的残差结构,提高了模型的特征提取能力,加快了模型的收敛速度,并能进一步获取图片关键信息.
本文结构如下:第1部分,介绍OCR技术的研究背景和本文的研究目的和方法,第2部分,介绍OCR识别技术当前的研究现状,第3部分,介绍有助于提高文字识别准确率的老挝语文本特征,第4部分,介绍本文的模型结构,第5部分,介绍本文模型的设置与相关实验结果及分析,第6部分,关于本文的总结与展望.
2 相关工作
近年来,文字识别主要存在两种方案,一种是传统的文字检测-文字识别,另一种是端到端的文字识别模型:
传统方法将文字识别分为多个阶段.公保杰等人[3]对印刷藏文的文字识别采用传统方法,通过预处理、行列切分、特征提取、文字识别的技术路线达到了较高的识别准确率;传统的文字识别方法常采用机器学习的方法进行分类识别,如支持向量机[12]方法,缺点是计算量大,在实际应用中并不适用;Tian等人[13]提出的CTPN模型具有垂直定位机制,可同时预测文本的位置和文本及非文本得分;Long等人[14]提出的TextSnake模型能够以水平,定向和弯曲形式表示文本实例,重构文本的精确形状和区域轮廓.这在一定程度上提高了文本检测精度,也对后一阶段的文字识别任务有所帮助.
端到端模型与检测-识别的多阶段文字识别不同,其在一个模型中完成文字检测和文字识别工作.端到端的文字识别模型架构目前主要有CTC-based方法和Attention-based方法.Shi等人[6]提出的CRNN模型,用CNN提取图片特征,将特征序列作为RNN输入,对特征序列进行预测,最后使用CTC将预测结果转化为标签序列,该模型可处理任意长度的序列;Deng等人[7]提出的基于注意力的文字识别算法,可以时刻读取相关信息,而不必完全依赖于上一时刻的隐藏状态;Lee等人[15]提出的基于注意力端到端模型使用CNN提取图像特征,再利用RNN学习单词串中自然存在的字符顺序动态,最后使用注意力机制对序列进行解码.He等人[8]提出将注意力机制插入CNN编码器和BiLSTM编码器之间,进一步提取输入图像中的特征,并允许在标准方向传播框架内进行端到端训练;Ding等人[16]则提出一种具有完全注意力机制的端到端文本识别模型,在编码端采用残余注意力增加网络深度,更有效地提取图像特征,解码端采用seq2seq模型得到识别结果;Gao等人[17]提出使用堆叠的卷积网络代替RNN架构去有效捕获输入序列的上下文相关性,避免了RNN计算复杂和训练困难的问题;仅采用CNN进行图像特征提取,深层的神经网络会使模型训练困难,而ResNet[18]作为一种残差学习框架,在一定程度上增加模型深度的同时简化了之前深度网络的训练;Inception-v4(1)Szegedy C,Ioffe S,Vanhoucke V,et al. Inception-v4,inception-resnet and the impact of residual connections on learning. https://arxiv.org/pdf/1602.07261.pdf,2016.将Inception网络与残差连接相结合,加速了模型的训练,明显改善了模型的识别性能.
传统的文字识别方法将文字检测和文字识别分为两部分,过程复杂费时,且检测与识别不能共享特征,而端到端文字识别模型流程简单,可减少训练时长,本文模型输入老挝文字图片,输出预测的老挝文字序列,降低了模型复杂度.传统的文字识别采用机器学习等方法对图像进行特征提取和分类识别,但由于老挝语字符结构复杂而特征提取不明确,传统分类识别也无法解决老挝语的识别问题,因此,本文结合神经网络强大的学习能力对老挝文字图片进行特征提取及识别预测,以期模型的更佳表现.
3 老挝文本特征
3.1 词法特征
老挝语是一种词间无分隔语言,其由音节搭配组成,故要对老挝语进行词法分析,就需对音节构成进行分析.老挝文字是由元音、辅音、特殊标记、声调符号、数字组成的拼音文字,其中,元音28个,辅音32个,音调符号4个,数字符号10个,特殊标记2个,如表1所示.

表1 老挝语字母表Table 1 Lao alphabet
老挝语的键入规则基于主辅音字符,主辅音周围可能有元音字符或标记(位于主辅音的前方,后方,上方,或下方),主辅音字符还可以在其上方具有可选的音调标记,并在其后具有可选的更多辅音字符,如图1所示.
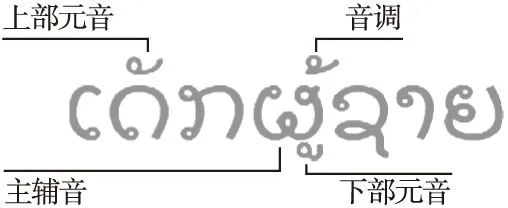
图1 老挝语书写规则Fig.1 Lao writing rules
为进一步分析音节的组成方式,本文用图2表示老挝音节组成结构.图中的英文字母顺序表示这些字符相对于彼此的键入顺序,X代表主辅音,在B和C之间键入,如果A,B和C不为空,则X永远不能为空.
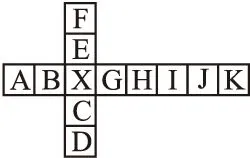
图2 老挝语音节结构Fig.2 Lao syllable structure
其中,每个结构位置包含的字符如表2所示.

表2 各个结构位置对应的字符Table 2 Characters corresponding to each structure position


3.2 字符向量及词向量特征
老挝文字图片的标签序列具有丰富的语义信息,结合语义信息能使老挝文字序列的预测更具上下文逻辑.目前,对自然语言表征的主流方法是通过分词工具将句子切分为词,以词作为语义单元进行分析[21].但对于老挝语这样词间无分隔的语言,该方法并不符合老挝语言特征.首先,老挝语的分词结果并非完全正确;其次,用词作为语义单元进行表示,忽略了词内字符间的信息,但老挝语中单独的一个字符也并不能准确地表示完整的语义信息.因此本文考虑结合词向量与字符向量,以获得更好的语义表示.
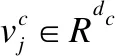
(1)
(2)
4 融合文本特征的老挝文字识别模型
4.1 模型结构
本文对于老挝语的文字识别问题,把连续图像的特征序列转换为文本,采用经典的深度学习模型来进行训练和预测,不进行字符分割,可识别任意长度的序列,同时,在残差结构的3个卷积层中执行放大操作,可将输入的老挝文字图像在垂直方向的像素上隐式展开为单行图像,获得一个线状特征图,而无需执行任何明确的分段.
具体模型结构:
1)输入层:老挝文字图片;
2)注意力卷积层:提取图片特征信息,同时加深关键信息的特征值;
3)注意力层:将注意力卷积层输出的图像特征信息与图像标签预训练的字符向量和词向量用注意力机制进行权重预测,并通过加权求和来组合不同特征向量;
4)BiLSTM层:对特征信息进一步编码,预测出老挝文字序列标签的真实分布,并使预测音节规则标签分支以参数共享的形式将老挝词法特征融入到老挝文字识别模型中;
5)转录层:用CTC对从编码部分获取的标签分布进行序列对齐操作.
本文模型结构如图3所示.
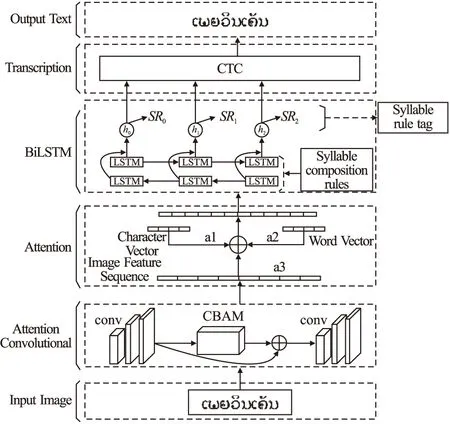
图3 模型结构图Fig.3 Model structure diagram
4.2 注意力卷积层
本文在CNN中加入残差结构,利用深层的特征提取网络进行特征提取的同时加快模型收敛速度.而由于部分老挝字符结构复杂以及背景噪声等因素干扰,普通网络模型提取的特征序列模糊,关键特征不明确.因此,本文在残差结构中加入CBAM,使CNN网络更集中于关键特征的提取.CBAM在通道和空间维度上运用注意力机制,以提升CNN的特征提取能力.CBAM的结构如图4所示.

图4 CBAM结构图Fig.4 CBAM structure diagram
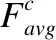
F′=Mc(F)⊗F
(3)
F″=Ms(F′)⊗F′
(4)
(5)
(6)
本文对输入的老挝文字图片用加入残差结构的CNN网络提取图像特征信息,并在部分残差模块中嵌入CBAM模块以取得更好的特征提取效果.带有注意力机制的残差结构如图5所示,其中⊕表示对应元素相加.

图5 带有CBAM的残差结构Fig.5 Residual structure with CBAM
CNN网络结构如表3所示,其中,Conv_Bn_Relu表示卷积层Conv,归一化层Bn和激活函数Relu结构,Residual_Block表示残差结构,out_channels表示网络层输出通道数,k表示卷积核大小,s表示步长大小,p表示填充值大小.
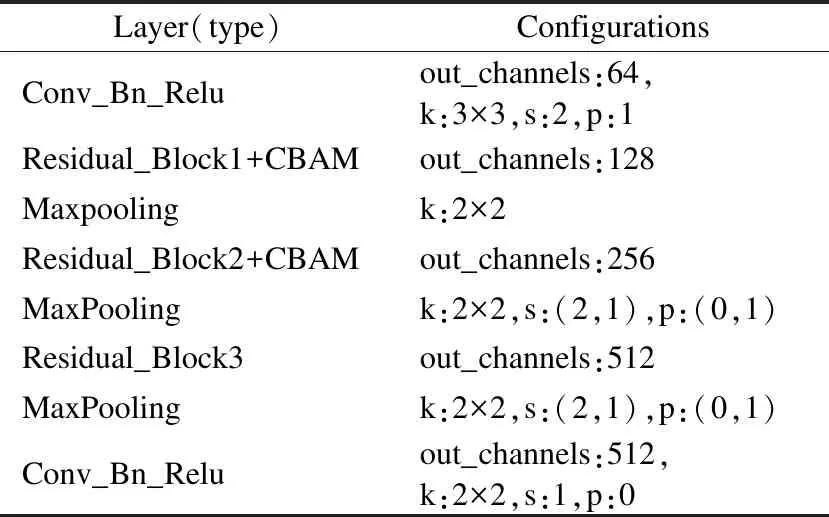
表3 CNN网络结构设置Table 3 CNN network structure settings
4.3 注意力层
本文图像信息与文本信息的融合若只是简单拼接特征向量来融合信息,随着拼接的向量越来越多,RNN网络效率会变得逐渐低下,因此,本文借鉴Kiela等人(2)Kiela D,Wang C,Cho K. Dynamic meta-embeddings for improved sentence representations. https://arxiv.org/pdf/1804.07983.pdf,2018.的方法对注意力卷积层提取的图像特征信息与预训练的图片标签序列的文本信息进行融合.该方法可利用注意力机制对图像信息和文本信息动态分配权重并进行组合,有效融合关键信息.首先,通过线性变换将老挝图像特征序列和图片标签的词向量表示及字符向量表示wi,j∈Rdi(i=1,2,…,n表示特征向量类型,j表示第i种特征向量矩阵的第j个向量)3种特征向量投影到公共d′维空间,如式(7)所示;其次,通过加权和来组合投影的老挝特征向量,如式(8)所示;最后将组合后的老挝特征向量输入下一层网络中进一步编码.
(7)
(8)
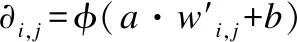
4.4 BiLSTM层
LSTM网络解决了RNN在获取长距离依赖信息时会出现梯度消失的问题[22].LSTM计算公式如式(9)-式(14)所示.
it=σ(Wixt+Uiht-1+bi)
(9)
ft=σ(Wfxt+Ufht-1+bf)
(10)
ot=σ(Woxt+Uoht-1+bo)
(11)
(12)
(13)
ht=ottanh(ct)
(14)
其中,it为输入门,ft为遗忘门,ot为输出门,ht为当前输入的老挝特征序列x的隐藏状态,ct为当前时刻状态值,σ为sigmoid函数,Wi,Wf,Wo,Wc,Ui,Uf,Uo,Uc为权重参数,bi,bf,bo,bc为偏置量.

4.5 转录层
BiLSTM输出结果若直接用于序列标记,则必须对训练数据进行预分段,难以直接应用于序列标记,而CTC消除了分段训练数据和解决了输出文本对齐的问题[22].
CTC将输入老挝特征序列的每个时间步长独立标记为单个分类,同时,将BiLSTM输出转换为标签序列上的条件概率分布,通过使用目标函数,使正确标记的概率最大化,得到最终老挝文本标签序列.
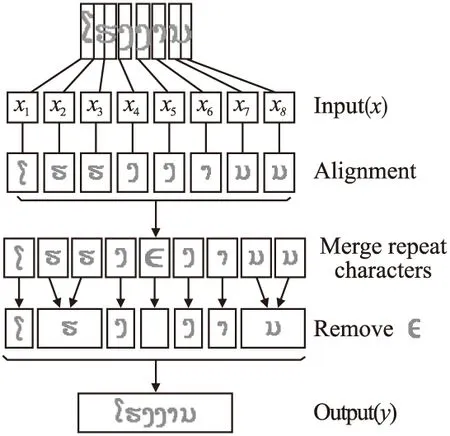
图6 CTC对齐过程Fig.6 CTC alignment process
CTC采用动态规划的思想对寻求最大可能性路径的求解进行简化,并使用SGD梯度下降法最小化CTC损失函数,如式(15)所示.其中,给定输入序列x=x1,x2,…,xn,n表示训练数据个数,l表示真实标签序列,p(li|xi)表示每一条可能输出路径的条件概率.
(15)
值得注意的是,本文模型的损失值是老挝文字识别的损失值与预测音节规则标签分支的损失值相加,并通过控制预测音节规则标签分支的损失值的权重以增强模型训练效果.预测音节规则标签分支采用softmax函数来预测音节规则标签,并用交叉熵损失函数计算损失值,如式(16)所示.其中,SR表示老挝音节规则标签,hi表示BiLSTM输出的老挝特征向量.故本文模型的损失值为式(17)所示,其中,α参数表示音节规则标签分支的重要性,值为0.2.
(16)
o=oCTC+αoSR
(17)
5 实 验
5.1 数据准备及模型设置
本文数据集包括两部分:第1部分,真实的老挝文字图片.本文从老挝国会、老挝广播电视台等官方网站爬取了189MB的老挝PDF文档,共计620页,经处理最终抽取出528页,并从中截取出10700张真实老挝文字图片;第2部分,生成的老挝文字图片.本文从维基百科爬取的6931.9KB的老挝语文本,用爬取的老挝文本批量生成24670张固定尺寸(32×840像素)的老挝文字图片.本文将第1部分数据集按9:1划分为训练集和测试集,并对该部分训练集进行人工标注,再与第2部分数据集共同组成完整训练集.由于本文旨在将模型应用到真实的老挝文字识别任务中,故将第1部分真实老挝文字图片作为主要的训练集和测试集语料.但低资源老挝语的真实数据集较少,且人工标注语料匮乏,极大影响模型的有效训练,因此,将第2部分生成的老挝文字图片扩充到训练集中,使模型能从充足的训练集中学习到更丰富的图像特征及文本特征.同时,本文对语料库进行了如下预处理操作:
1)对生成的老挝文字图片进行图像增强工作,包括文字模糊、背景噪声、文字位置、膨胀、腐蚀、多种字体,以增加图片复杂性、丰富性,使其更接近真实数据集.
2)将PDF文档删除图片页,空白页和空白比例较大的页面,抽取出字符页,并切分成图片.
3)针对图像中存在模糊、噪点、歪斜情况影响识别效果的问题,用cv2模块对图片对比度,亮度等进行调整,并对图像进行灰度化,二值化和倾斜校正处理.
4)对图片标签进行预处理,对图片标签进行分词和音节规则标注,并将分词后的图片标签使用Glove预训练词向量和字符向量.
本文模型使用Python语言及Pytorch框架进行实现,经多次实验调整,老挝文字识别模型超参数设置如表4所示.

表4 超参数设置Table 4 Hyper parameter settings
其中,Embedding_dim是词向量维度;Char_Embedding_dim是字符向量维度;Learn Rate是学习率;LSTM_Num_Hidden是LSTM隐藏神经元个数;本文采用学习率衰减算法,并采用Adam优化器训练模型.
本文采用单字符识别准确率作为模型的评估指标,准确率计算公式如式(18)所示,其中,N为总字符数,R为替换字符数,I为插入字符数,D为删除字符数.
(18)
5.2 实验结果与分析
为了验证本文模型的有效性,本文设置了4组对比实验:1)不同训练集测试集组合对比实验;2)模型设置对比实验;3)特征有效性对比实验;4)文字识别模型对比实验.本文模型测试单张老挝文字图片识别时间达11.12秒(每张图片包含1100个左右的老挝字符).
5.2.1 不同训练集测试集组合对比实验
本文对真实数据集和生成数据集进行不同的训练集测试集组合:(1)将真实数据集按9:1划分为训练集和测试集;(2)训练集为生成老挝文字图片,测试集为真实老挝文字图片,训练集与测试集比例为9:1;(3)在(1)的基础上将生成数据集扩充到训练集中.实验对比结果如表5所示.

表5 不同组合对比结果Table 5 Different combinations comparison results
由表5可知,(1)中识别准确率较低是因为作为训练集的真实老挝文字图片较少,导致模型在训练中难以学习足够特征,(2)采用预处理中已通过图像增强工作的生成老挝文字图片作为训练集,尽可能接近真实数据,且数据量充足,因此能达到不错的识别准确率,而(3)采用真实图片进行训练,使模型能更有效地针对真实老挝文字图片进行识别,又用生成图片进行训练集的扩充,使模型能在充足的训练集中充分学习数据特征,从而得到更好的识别效果.
5.2.2 模型设置对比实验
本文模型在CRNN模型的基础上,通过改变卷积层的网络结构,增加残差结构和注意力机制等不同设定对模型进行训练.具体设定如下:(1)CRNN模型,为本文基础模型(Baseline),其中,RNN部分采用BiLSTM,并用CTC解码;(2)在(1)的基础上进行改进,加入残差结构;(3)对3个阶段残差结构的第1阶段加入CBAM注意力模块;(4)在前两个阶段的残差结构中加入CBAM注意力模块;(5)在3个阶段的残差结构中都加入CBAM注意力模块.
其中,模型(1)和模型(2)用来比较残差结构对模型性能的影响;模型(3)和模型(4)用来比较注意力机制对模型性能的影响;模型(3)-模型(5)用来验证注意力机制的最佳设置方式.模型的实验结果如表6所示.

表6 模型对比结果Table 6 Model comparison results
由表6可知,在CNN网络中加入带有注意力机制CBAM的残差结构能有效提高模型性能,模型的识别准确率比基准模型提高了1.81%.由模型(1)和模型(2)对比可知,残差结构的引入使模型识别准确率提高了0.67%,这是由于仅使用深层CNN进行训练容易出现梯度消失的现象,而加入残差结构可利用深层的特征提取网络进行特征提取,能加速模型收敛,并有效解决梯度消失问题,从而提高模型性能.在模型(2)的基础上加入一个注意力机制CBAM,模型(3)识别准确率较模型(2)提升了0.53%,注意力机制本就可以更有效提取序列的关键特征,而CBAM在Channel和Spatial两个维度上同时运用注意力机制,有效提高了CNN的特征提取能力.另外,由模型(3)-模型(5)的实验结果对比可知,在两个阶段残差结构中加入CBAM时模型准确率最高,达到87.69%,并不是加入越多注意力模块模型性能越好,原因是注意力机制虽能够提升模型的特征提取能力,但过多的注意力模块会使得模型计算量增大,甚至引起过拟合问题,导致训练结果不理想.因此,实验结果表明,本文的模型能更有效地提取老挝图片的关键特征信息,并从多个维度对特征进行表征,本文模型的设置对老挝文本识别的研究是有效的.
5.2.3 特征有效性对比实验
本文将老挝语的词法特征,图像标签的预训练词向量特征和字符向量特征加入到老挝语文字识别模型中,对不同特征及不同特征组合设置进行对比实验:1)仅融合图像标签预训练的字符向量特征(Char_Embedding);2)仅融合图像标签预训练的词向量特征(Word_Embedding);3)融合图像标签预训练的字符向量特征和词向量特征;4)加入融合词法特征的分支(Lexical_Feature_Branch);5)融合图像标签预训练的词向量特征和字符向量特征,同时加入融合词法特征的分支.对比实验结果如表7所示.

表7 特征有效性对比结果Table 7 Feature validity comparison result
由表7可知,融合字符向量特征的模型比表5中取得最优准确率的模型(准确率达87.69%)准确率提升了0.13%,说明老挝词相对固定的音节组合规则使老挝语字符之间具有相互关系,使用字符向量特征能更好表征老挝文本的语义信息.而融合词向量特征的模型准确率仅提升了0.06%,原因是老挝文本的分词结果并非完全正确,且词类别数远大于字符类别数,影响了词向量的准确度.字符向量与词向量结合的模型效果比仅融合字符向量和仅融合词向量都更好,原因是词向量的结合弥补了老挝语中单个字符并不能准确表示完整语义信息的缺点.加入融合词法特征的预测老挝音节规则标签分支与分别融合字符向量和词向量相比,模型识别准确率提升更大,说明老挝语的构词规则对老挝文字识别有较高贡献度,能使模型有效预测老挝文字序列的标签分布.同时融合3个特征,使高级的语义信息与老挝构词方法相结合,模型准确率提升了0.94%.因此,实验结果表明,融合文本特征的老挝文字识别模型是有效的.
5.2.4 文字识别模型对比实验
为进一步验证本文模型的有效性,本文与5个现有文字识别模型进行了对比.对比模型分别为:(1)CRNN(CTC解码)模型[6]:使用CNN提取特征序列,再用BiLSTM预测特征序列的标签分布,最后进行CTC转录;(2)Lee等人[10]提出的CNN+RNN+Attention模型:使用CNN提取图像特征,再利用RNN进一步编码,最后使用注意力机制对序列进行解码;(3)He等人[8]提出的CNN+Attenion+BiLSTM+CTC模型:将注意力机制插入CNN编码器和BiLSTM编码器之间,并采用CTC解码;(4)Ding等人[16]提出的CNN+Attention+Seq2seq的全注意力机制模型:使用带有Residual Attenion机制的CNN网络进行编码,解码使用seq2seq注意翻译模型得到识别结果;(5)Gao等人[17]提出的Stacked CNN+Attention+CTC模型:使用加入Residual Attenion机制的堆叠卷积层代替RNN,最后使用CTC预测标签序列.实验结果如表8所示.

表8 文字识别模型对比结果Table 8 Text recognition models comparison results
由表8可知,CRNN作为目前主流的文字识别模型,达到了不错的识别准确率,而模型(2)使用Attention解码,准确率比其低5.19%,原因是老挝语字符结构复杂,且多为较长的连续字符,CTC解码是沿着序列从左至右依次识别,而Attention解码则是每个时间步都计算文本序列中每个位置的权重,在老挝语这样字符结构复杂的文本序列中,权重计算准确率降低,从而降低了识别效果.模型(3)的识别准确率比CRNN提高了0.74%,原因是插入的Attenion进一步提取关键特征,提高了模型识别的准确率,但与本文在CNN网络中加带有注意力机制的残差结构相比,本文模型不仅能更有效地提取关键特征,残差结构还能克服在关注特征过程中随着网络深度的增加出现梯度消失的问题.模型(4)有较高的识别准确率,因为Residual Attenion使CNN有较好的特征提取能力,但seq2seq的注意力解码与模型(2)一样不适用于老挝语的文字识别;模型(5)使用带有Residual Attenion的堆叠CNN替换RNN结构,建模速度更快,但对于老挝长文本序列,堆叠CNN捕获序列上下文信息的效果不如BiLSTM.本文模型对CRNN模型进行改进,在CNN网络中加入带有注意力机制的残差结构以提取图像特征,融合图像标签的预训练词向量和字符向量,并结合老挝词法特征对文字识别模型进行优化,与上述5种现有文字识别方法相比,本文模型在识别准确率上有一定提升.
6 结 论
本文根据老挝词由音节构成,且老挝字符按一定的音节组成规则构成音节的特点分析老挝语词法特征,并结合老挝文字图片标签的文本信息,提出了一种融合文本特征的老挝文字识别方法,在经典CRNN模型的基础上,使用加入了带有注意力机制的残差结构的卷积层提取图片特征信息,并用注意力机制以动态分配权重组合特征的方式融合文本特征,同时,根据老挝音节组成规则对图片标签序列进行音节规则标签预测,以参数共享的形式提高老挝文字识别模型的性能.实验结果表明,在有限语料库中,本文方法取得了88.63%的准确率,对老挝文字的识别达到了不错的效果,但准确率仍有待提升.本文的研究在一定程度上解决了老挝语该低资源语言语料匮乏的问题,为老挝语的其他NLP下游任务的研究提供了前提条件,具有一定的应用价值.下一步将着重于对模型识别结果进行后处理的研究,对老挝语的拼写规则、词法和句法特征进一步分析,形成纠错机制,以提高老挝文字识别模型的准确率.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
电脑报(2021年41期)2021-11-04
云南画报(2021年12期)2021-03-08
电脑知识与技术(2019年29期)2019-12-16
电脑爱好者(2019年8期)2019-10-30
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
农机使用与维修(2014年10期)2014-10-23
