
基于二阶隐马尔可夫模型的连续手语识别①
2022-05-10 08:42:02梅家俊王卫民戴兴雨
计算机系统应用 2022年4期
梅家俊,王卫民,戴兴雨
(江苏科技大学 计算机学院,镇江 212100)
手语识别技术其实是利用计算机等智能设备,将手语动作转换为能够与其他社会群体交流的信息[1].目前中国手语大约有5 500 多个常用词汇[2].然而真正理解手语含义的人却数量极少,大部分非聋哑人对手语基本上一无所知,并且也很少有人愿意去花时间和精力去学习手语这项技能,这也是聋哑人群体与其他社会群体之间产生沟通障碍的原因之一.因此,研究手语识别技术不仅能使聋哑人更好地适应社会环境,还可以促进人机交互的发展,为用户提供更好的人机交互体验[3].
本文将隐马尔可夫模型和深度学习结合起来,其中由于深度学习具有很好的迁移能力,故而将深度学习用于手语词汇的特征提取以及候选词汇的选择,而隐马尔可夫模型可以将现有的语言学的模型应用到手语的识别中,并且二阶隐马尔可夫模型可以更好地运用经验知识来辅助识别[4].
1 相关工作
根据识别手语的方法上划分,可以将手语识别分为四类,分别为:基于体感设备的手语识别、基于穿戴式设备的手语识别、基于传统机器学习的手语识别,以及基于深度学习的手语识别.
基于体感设备的手语识别就是采用体感设备Kinect来进行手语的识别.如2019年,千承辉等[5]借助Kinect得到人体的深度图像以及骨骼特征信息提取出手部特征,实现动态的手语识别,准确率可达95%,2020年,陈德宁等[6]运用Kinect 设备提取到人体的骨骼信息,对手语进行分类和识别.
基于穿戴式设备的手语识别,即通过运用数据手套以及位置跟踪器获取手势的实时变化信息,如Oz等[7]使用CyberGlove 数据手套以及位置跟踪器对300个美国手语单词进行识别,得到了90%的识别准确率.
基于机器学习的手语识别,就是使用传统的机器学习算法,如隐马尔可夫模型[8],支持向量机等[9].2019年,蒋贤维等[10]使用精度高斯支持向量机(FGSVM)对中国手语手指语图像样本进行实验,最终分类达到92.7%的识别率,2020年,包嘉欣等[11]使用综合多要素的手语肤色分割与改进VGG 网络的手语识别方法,得到了对手语图像97%以上的平均识别率.
深度学习方法的出现,使手语识别迎来了新的机遇.例如2018年,梁智杰等[12]运用三维卷积神经网络,提取出视频的短时特征,并运用双向LSTM 输入到残差网络中,最终得到了很好的性能表现.
然而,无论在国内还是国外,都很难在市场上看到成熟的手语识别设备,主要原因是基于体感设备的手语识别,虽然识别准确率很高,但体感设备Kinect价格昂贵且体积较大,对于非室内的手语识别环境不是很方便;而基于穿戴式设备的手语识别方式,虽然数据手套准确率高,但手套设备昂贵,且不易操作,不便于携带,很难普及和推广;基于机器学习的手语识别,虽然不需要配套的设备,但整体的识别率比使用相关设备的识别方法低;而基于深度学习的手语识别,在训练量较少的时候效果并不佳,只有在有大量数据的情况下,深度学习方法才可以得到一个较好的识别准确率.
2 基于HMM2 的连续手语识别方法
手语识别是将一段完整的手语视频转换为中文语义的过程[13].手语识别主要是由语料库和手语词汇视频库的建设、滑动窗口的切分及手语视频识别等技术组成.
连续手语识别的系统运算流程如图1所示.
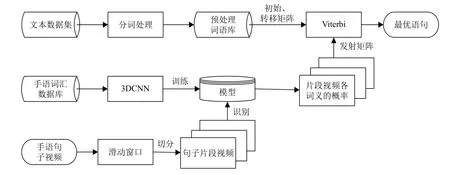
图1 系统流程图
2.1 语料集和手语词汇视频库的建设
中文语料集以及手语词汇视频库的建设是手语识别中最基本也是最重要的环节.通过收集大量的中文文本建立语料集,再通过各种渠道,大量收集手语词汇的视频,其中包括人、衣物、食品、生活用品、生活、工作、社会活动、哲学、伦理、心理、行为、事物的状态、性质、特点、民族、宗教、历史、政治、法律、国防外交、经济、文化教育、时间、空间、数学、物理、化学、信息学、生物等共54 大类共5 586个手语词汇[14].把收集到的视频按各自表达的意思进行分类,构建完整的手语词汇视频库[15].
2.2 滑动窗口的切分
由于手语语句是由多个手语词汇组合而成,因此需要把手语视频进行切分,分割成多个长度较短的视频,使每个视频能够代表一个词汇[16].因此采用滑动窗口对手语视频进行切分,根据窗口大小Size以及滑动步数Step,将原视频V切分成多个相互重叠的视频片段V1,V2,…,Vm,其中m是切分后的视频个数.
2.3 手语视频识别(基于HMM2)
2.3.1 初始化HMM2
初始化隐马尔可夫模型的3 个参数矩阵:初始状态矩阵,转移状态矩阵和发射矩阵,以及两个序列:状态序列和观测序列.状态序列s=W1,W2,…,Wn,其中n表示手语词汇个数,Wi表示第i个手语词汇,观测序列V=V1,V2,…,Vm,其中Vi表示切分出的第i个视频.主要计算过程如下所示.
(1)文章分句
输入L篇文章,对L篇文章进行如下处理:使用标点符号“?.!”进行分句处理,设分句后的结果为S1,S2,S3,…,Sy,其中y为L篇文章的句子总个数,Si为L篇文章的第i个句子.
(2)计算初始状态矩阵
计算所有字在句首出现的频次,设字序列为C1,C2,…,Cx,对应的频次序列为Count(C1),Count(C2),…,Count(Cx),其中Ci表示第i个字,Count(Ci)为字Ci出现的频次,于是有:
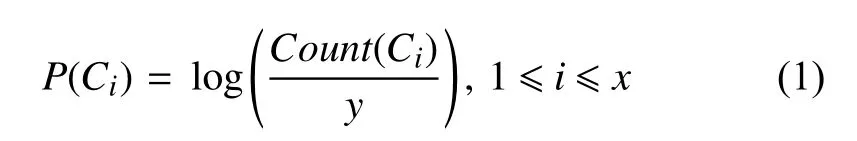
由此得到了初始状态矩阵:
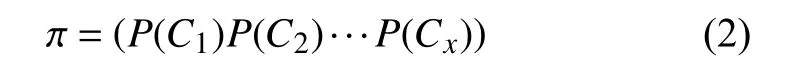
(3)句子分字
对所有的句子进行频次统计:把y个句子中相应的C1,C2,…,Cx替换为C1,C2,…,Cx的下标1,2,…,x.去除其他非1,2,…,x的词汇,再把下标1,2,…,x替换回相对应的字,由此就得到了分字的结果.
(4)计算一阶转移矩阵
首先统计出Ci的频次Count(Ci)以及CiCj的频次Count(CiCj),其中Count(CiCj)表示为字Ci后出现Cj的概率.再计算出每个字后出现所有字的频次总和,记为O1,O2,…,Ox,其中Oi表示Ci后出现每个Cj的频次总和.

其中,P(Cj|Ci)表示为Ci到Cj的转移概率,得到了一阶转移状态矩阵:
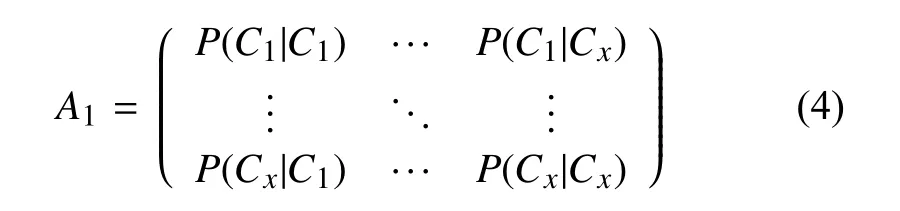
(5)计算二阶转移矩阵
统计出CiCjCk的频次,记为Count(CiCjCk),其中Count(CiCjCk)表示为CiCj后出现Ck的概率.再计算每两个字后出现所有字的频次总和,记为Z11,Z12,…,Zxx,其中Zij表示CiCj后出现每个Ck的频次总和.于是有:
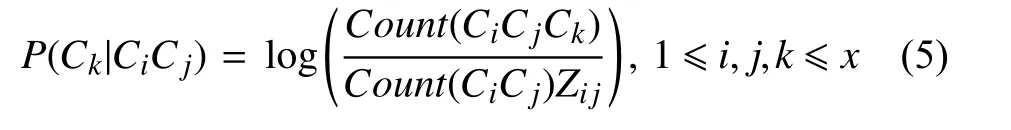
其中,P(Ck|CiCj)表示CiCj到Ck的转移概率,由此得到了二阶转移状态矩阵:
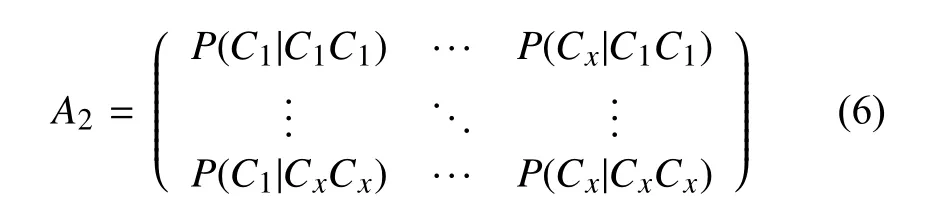
(6)三维卷积模型
每个手语词汇W1,W2,…,Wn都包含k个视频,将这些视频分别记为d11,d12,…,dnk,其中dij表示为第i个手语词汇的第j个视频.将所有的手语词汇视频进行训练,最终得到一个三维卷积模型.卷积结构如图2所示.

图2 三维卷积网络结构
(7)计算发射矩阵
将切分之后得到的m个视频V1,V2,…,Vm,利用训练好的三维卷积模型进行手语词汇识别,其中第i个切分视频的描述内容为第j个手语词汇的概率记为P(Wij).对每个切分视频按照概率大小P(Wij)进行排序,保留排好序的前5 个P(Wij),其余P(Wij)赋值为0.将每个手语词汇对m个切分的视频所得的值求和得到h1,h2,…,hn.于是有:
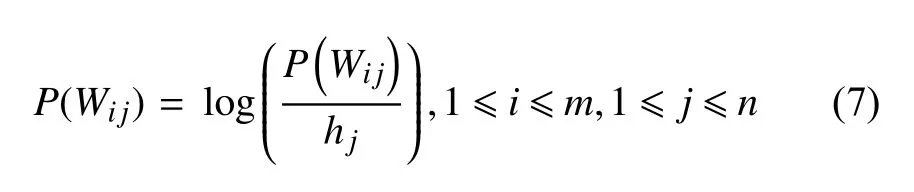
对所有P(Wij)中的非数值型的结果赋值为无穷小,由此得到了发射矩阵:
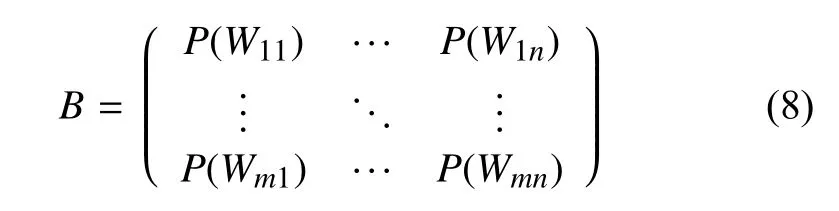
2.3.2 计算最佳路径
运用Viterbi 算法计算HMM2 的最佳路径,主要过程如下所示:
给定一个观察序列O=V1,V2,…,Vm和HMM2 模型λ=( π,A1,A2,B),并选择一个状态序列S=W1,W2,…,Wn,其中Vi表示第i个切分的视频,Wi表示状态序列中的第i个词汇:
(1)首先计算状态序列中的所有词汇作为句首的概率P(Wi),从发射矩阵B中找出当观察值为V1时,相对应词汇的概率值B(Wi|O=V1),得到Viterbi 算法中观测值为V1的结果:
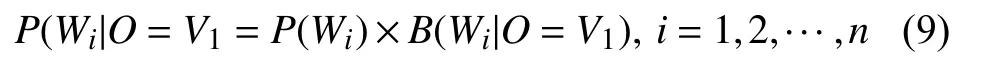
(2)接着计算当观测到V1的状态值为Wi时,观测到V2的状态值为Wj的概率P(Wj|Wi),从发射矩阵B中找出当观察值为V2时,相对应词汇的概率值B(Wj|O=V2),则得到Viterbi 算法中观测值为V2的结果:
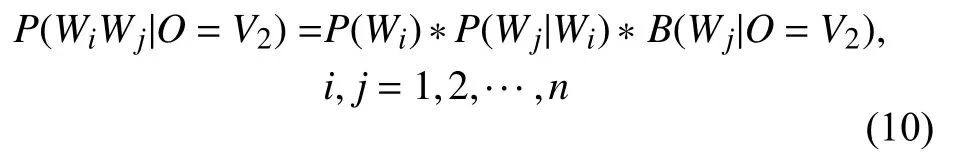
(3)观测值为Vt时,其中2≤t≤m,计算出当t-1 时刻观测值为Wj并且t-2 时刻观测值为Wi时,观测到Wk的概率P(Wk|WiWj),从发射矩阵B中找出当观察值为Vt时,相对应词汇的概率值B(Wj|O=Vt),则得到Viterbi算法中观测值为Vt的结果:
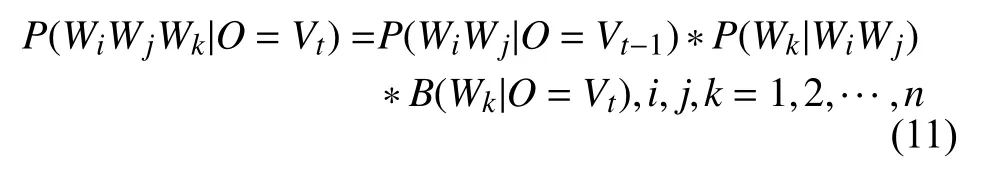
(4)求取最佳序列状态:找出P(WiWjWk|O=Vm)的最大值,并记录下相对应的Wi,Wj,Wk,通过Wi,Wj依次找出前一个观测时刻的Wi,最终得到一条概率最大的路径,即识别出的最终结果.
3 实验
3.1 实验数据来源
为了验证该系统的可行性,本次实验从新浪、搜狐上爬取50 篇新闻文章构成语料集,并获取中国科学技术大学视觉手语研究小组(VSLRG)发布的中国孤立手语词数据集作为手语视频库,该数据集由50 个唯一的参与者执行,每个参与者对每个类别进行5 次.数据集包含500 个不同的类别,例如:身体、头部、头发、女士、妹妹、杯子、灯光等.并且每个类别具有250 个实例,共计125 000 个手语词汇视频,对于125 000个手语词汇视频,按照9 比1 的比例,随机划分卷积模型的训练集和测试集,训练集共112 500 个词汇视频,测试集共12 500 个词汇视频.再获取VSLRG 发布的中国连续手语数据集,该数据集包括100 种不同含义的句子,从每种句子中随机挑选5 个视频,共500 个连续手语视频作为手语识别的测试集.其中图3 为连续手语数据集中的一个视频的关键帧,图4 为孤立手语词数据集的一个词汇视频的关键帧.

图3 “他的同学是警察”的关键帧

图4 手语词汇“外祖父”的关键帧
3.2 模型训练及手语识别
首先给定一个前提:测试集中的每一个连续手语视频中,表示手语的速度与手语词汇视频中,某个人表示手语的速度是相似的.
每个手语词汇W1,W2,…,Wn都包含k个视频,将这些视频分别记为d11,d12,…,dnk,其中dij表示第i个手语词汇的第j个视频,并且每一个手语词汇视频都有不同长度的帧数,记为F11,F12,…,Fnk,其中Fij表示为第i个手语词汇的第j个视频的帧数,把所有视频的帧数统计出来,如表1所示.

表1 词汇视频帧数统计
由于最长词汇视频帧数过大,测试集中部分连续手语视频达不到此帧数,因此统计100 帧以下的视频占比,如表2所示.

表2 100 帧以下词汇视频总数占比
共有97.51%的视频处于一百帧以内,并且对于连续视频而言,切分的窗口过大,反而会产生不必要的误差.于是,设置计算过程中词汇视频帧数为100,大于100 帧的词汇视频取前100 帧计算,小于100 帧的词汇视频补零补到100 帧.将处理好的训练集进行训练,共计训练1 000 轮.
为验证算法的识别性能,将通过与其他算法,如余弦相似度[17]和二维卷积模型[18],进行对比Top-1 及Top-5 的准确率.
其中网络模型如图1所示,训练中设置批量大小batch_size 为64,使用Adam 优化器,根据训练的效果,依次调整初始学习率为1×10-4,1×10-6,1×10-8,其他参数保持不变,并设置训练迭代次数epochs 为1 000.实验结果如表3所示.
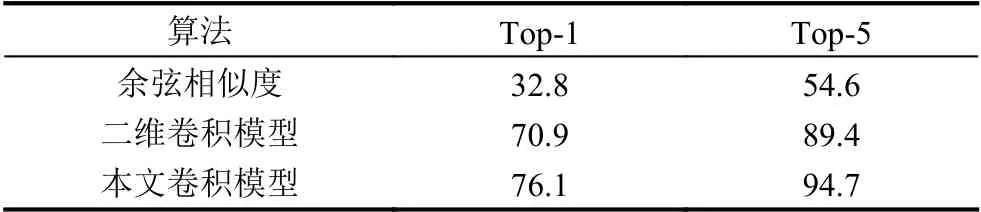
表3 不同算法的识别效果(%)
对测试集中每一个连续手语视频,进行如下处理:
以当前连续手语视频的前100 帧作为第一个手语短视频,利用训练好的三维卷积模型进行手语词汇识别,找出其中概率最大的五个手语词汇,按照这5 个手语词汇的概率比例,与每个手语词汇中250 个词汇视频帧数的平均值进行计算,得到滑动的帧数并进行滑动,得到第二个手语短视频.第二个短视频也进行词汇识别,同样以概率最大的5 个手语词汇计算出第二次滑动的帧数.直至滑动得到的手语短视频的帧数小于100 帧后滑动结束.
由此得到了当前连续手语视频的发射矩阵,并根据语料集得到初始状态矩阵,一阶转移矩阵以及二阶转移矩阵.最终通过Viterbi 算法进行识别,结果如表4所示.

表4 识别效果
表5 为本文算法HMM2 与传统一阶隐马尔可夫HMM1 的对比情况.

表5 手语视频识别精度
4 结语
本文采用了二阶隐马尔可夫模型与深度学习相结合的方式,其中深度学习用于词汇的特征提取以及候选词汇的选择,极大地缩小了候选词汇的范围,而二阶隐马尔可夫能够更好地运用经验知识来辅助识别,通过结合深度学习得到的候选词汇,形成连续手语视频的句义.在连续手语数据集上实验结果表明,本文算法的Top-5 识别精度为94.7%,比二维卷积模型提高5.3%;二阶隐马尔可夫模型对于连续语句的识别精度为88.6%,比一阶隐马尔可夫提高6.8%,具有更好的识别精度.
猜你喜欢
疯狂英语·新阅版(2023年5期)2023-05-31 05:43:06
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
活力(2019年15期)2019-09-25 07:23:06
电子制作(2019年11期)2019-07-04 00:34:38
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
数学理论与应用(2016年3期)2016-05-17 04:50:14
青少年科技博览(中学版)(2015年8期)2015-10-28 21:26:56
核科学与工程(2015年3期)2015-09-26 11:58:25
哈尔滨师范大学自然科学学报(2015年1期)2015-04-19 06:55:33
作文大王·笑话大王(2014年11期)2014-11-13 09:01:43
