
基于BERT的盗窃罪构成要件识别方法①
2022-05-10 08:40费志伟艾中良
计算机系统应用 2022年4期
费志伟,艾中良,张 可,曹 禹
1(华北计算技术研究所,北京 100083)
2(中国司法大数据研究院,北京 100043)
近年来,人工智能技术取得了长足的进步,并深入到生活的方方面面,在司法领域也是如此.2018年,司法部印发《“十三五”全国司法行政信息化发展规划》,明确提出我国到2020年全面建成智能高效的司法行政信息化体系3.0 版.在顶层政策大力推动下,全国各级法院参与研制了多种司法智能裁判辅助系统和装备,例如,北京市高级人民法院的“睿法官”智能研判系统、上海市法院的“上海刑事案件智能辅助办案系统”、杭州互联网法院的“智能立案”系统、浙江省高级人民法院的小AI 做庭审笔录等.
本文认为现有的司法领域中的人工智能系统可分为两种:
(1)利用人工智能技术建立的信息化系统.此类系统主要通过目前成熟的人工智能技术将案卷文书,庭审信息等材料信息化,录入到系统中.如通过OCR 技术,识别审问讯问笔录录入系统.通过语音识别技术将庭审过程中庭审语音转换成文字记录下来,辅助记录员记录信息[1]等.这种系统不涉及审理过程,不需要结合法律相关知识.直接利用现有成熟的人工智能技术,在这些任务上效果也很好.
(2)结合人工智能技术辅助法官审理的智能审判系统.此类系统面向司法领域中的任务,设计相关算法,来辅助法官审理案件,如量刑系统,通过人工智能算法根据案件事实得出量刑结果.这类系统需要面向司法领域的需求,结合法律知识和计算机知识设计相应算法,并设计相应的交互流程,以法官判案逻辑为主导,结合审理流程,来实现智能化判案的效果.
目前利用人工智能技术建立司法信息化系统已经取得了很好的效果,上述的庭审语音辅助系统切实的减少了记录员的工作量,让法院庭审过程更加高效.但在智能化辅助审理上效果不理想,如类案推荐系统一些法官表示无法提供精准类案,类案没有起到真正的参考价值.在江苏智慧审判系统的应用情况来看,部分法官甚至表示未使用该系统[2].本文认为目前智能化辅助审理系统主要面临着以下挑战:
计算机系统设计与司法领域知识结合不足.现有的辅助审判算法在设计时未考虑司法判案过程,未结合司法审判知识.如2018年“法研杯”量刑预测任务中,在算法设计时使用自然语言处理相关技术基于案件事实直接得到罪名以及判刑刑期结果,与法院通常的审理流程不符,及不具备法理上的解释性,在刑期任务中结果仍有很大的提升空间[3].
面对上述问题,本文认为在实际量刑人工智能系统的构建中需要引入量刑理论,依据司法判案中审理流程来构建相应算法.在我国,刑事案件判案过程中通常根据犯罪构成理论,目前主流的犯罪构成理论为四要件理论与三阶层理论,在实际司法审判中四要件理论使用更为广泛.犯罪构成是指依照我国刑法规定,决定某一行为的社会危害性及其程度而为该行为构成犯罪所必须的一切客观和主观要件的有机统一[4],依据四要件理论,主要包括犯罪客体、犯罪客观方面、犯罪主体和犯罪主观这4 方面.我国犯罪四要件理论起源于苏联,司法实践至今仍在沿用这一理论.在构建智能审判系统时应延续司法中四要件理论,将四要件识别引入系统设计中,在构成要件的基础上进一步来做刑期预测、类案推送等任务,为法官提供司法上的解释,来进一步辅助法官量刑.
本文主要贡献如下:
(1)梳理了盗窃罪构成要件标签体系,分析了构成要件识别的难点和挑战,并详细分析了识别构成要件所需的前置条件和内容.
(2)设计了构成要件识别模型,利用机器学习技术来识别构成要件,包括数据集的构建和构成要件模型的设计.
(3)对比了常见的方法与本文设计的方法,在本文构建的数据集上,对现有方法做了充分的测试.
本文设计的构成要件识别任务符合当下司法审理流程,在构成要件的基础上进一步来做刑期预测、类案推送等任务能提高现有方法的可解释性,能更加有效的辅助法官审理案件.
1 相关工作
案件构成要件识别根据构成要件理论,从案件事实中识别出构成要件.目前在构成要件识别中的工作较少,与之有一定关联的是案情关键要素识别,在计算机任务上可以看做文本分类任务.在案件要素识别方面主要有CAIL2019 法研杯提出的案情要素识别任务,该任务在案情描述中重要事实描述基础上,识别案情要素.基于速裁案件要素式审判的理论,法律专家梳理了婚姻家庭、劳动争议和借款合同3 个领域的案情要素体系.该数据集包含民事案件内容,不包括刑事案件内容.王得贤[5]提出基于层次注意力的模型在该数据集上进行测试.刘海顺等人[6]提出编码器解码器结构,利用BERT 对文本内容进行编码,提出BERT 模型后三层参数融合策略,然后使用LSTM 作为解码器得到最终的预测结果.其他工作在可解释性上,也使用了案情要素这一概念,Devlin 等人[7]构建了一个可解释的智能量刑模型,该模型一定程度上能解释模型如何确定其最终输出.但机器关注的关键部分与司法审理中关注的焦点并不相同,现有的通过注意力机制等方法提取出的案件要素并不具备司法上的解释性.钟皓曦等[8]基于强化学习和深度学习,提出通过问答的方式,获取案件事实中的影响定罪的元素,并通过这些元素来确定最终量刑并提供一定的解释性.但是该文并未详细阐述如何筛选案件要素,在单个罪名下的案件要素量少,该文选出的案件要素在司法上的支撑薄弱,在实际审理中的参考价值模糊.在实际司法中需要考虑更多的信息,按照本文所述的构成要件来进行审理.
案件构成要件识别的难点在于不同的案件构成要素不同,在梳理时需要法律人士参与,需要针对每个罪名梳理对应的构成要件体系.其次是利用大数据技术或深度学习技术依赖大规模标注数据集,如何利用现有的公开信息,构建一个构成要件数据集,减少人工标注工作量也是案件构成要件识别面临的挑战.
2 盗窃罪构成要件分析
2.1 盗窃罪构成要件
根据刑法第二百六十四条,盗窃罪是指以非法占有为目的,盗窃公私财物数额较大或者多次盗窃、入户盗窃、携带凶器盗窃、扒窃公私财物的行为.审理一起盗窃案件时,根据犯罪构成中四要件理论,要判断一起案件的主体要件、主观要件、客体要件和客观要件这4 个构成要件是否存在.主体要件刻画了行为人是否具有刑事责任能力,主观要件分析了行为人对自己实施的危害社会的行为及其结果所持的心理态度,客体要件描述犯罪侵犯的法益,客观要件描述了犯罪行为事实.
本文详细梳理了盗窃罪的构成要件部分,并阐述了构成要件与法院认定事实之间的关系.在盗窃罪主体要件中主要从主体行为人是否具有刑事责任能力,是否为未成年人,是否有犯罪前科和是否为中国居民这些方面来判断.
主观要件可从5 点进行考察,故意、非法占有为目的、牟利为目的、对特殊情节的明知和转化为其他罪名.故意主要从犯罪嫌疑人有主动参与作案的动机、犯罪过程中有无策划、是否事先通谋、事后销赃的行为人,通谋的内容包括盗窃行为和有无共犯这4 个方面进行识别.非法占有为目的从对他人财物的明知和对盗窃后果的明知两点进行识别.牟利为目的,主要从盗窃他人通信线路、复制他人电信码或者明知是盗窃、复制的电信设备、设施使用来判断.对特殊情节的明知,可依常识推论犯罪嫌疑人是否知道被害人是残疾人、孤寡老人或者丧失劳动能力的人、被盗财物是否为珍贵文物,或者救灾、抢险、防汛、优抚、扶贫、移民、救济款物,盗窃地点是自然灾害、事故灾害、社会安全事件等突发事件期间的事件发生地.转化为其他罪名从犯罪嫌疑人对行为对象的性质、功能等特征是否存在明确的认知来判断是否构成特别罪名.
客体要件从他人占有的财物和价值来考察,他人占有的财物主要从实践中的表现和学理解释来认定,如被害人对所盗财物拥有合法权利.学理解释根据法学理论判断客体的一些属性如是否为遗忘物,基于委托关系的占有等.价值在确定刑事处罚时有重要意义,根据被盗物品价值确定案件的基准刑以及在相应的量刑格中确定增减刑.
客观要件从客观行为事实来对案件进行考量,不同的客观行为事实会影响盗窃罪的认定.在盗窃罪的客观行为事实中需要考虑时间、地点、犯罪参与人、动机、手段、方法、被害人、行为对象、情节和后果这些方面.
法官依据证据以构成要件为指导归纳、认定案件事实,在司法证据中识别案件构成要件,并最终归纳总结出案件事实,最终认定的案件事实包含这起案件所涉及的全部构成要件.盗窃罪构成要件标签体系如表1中所示.
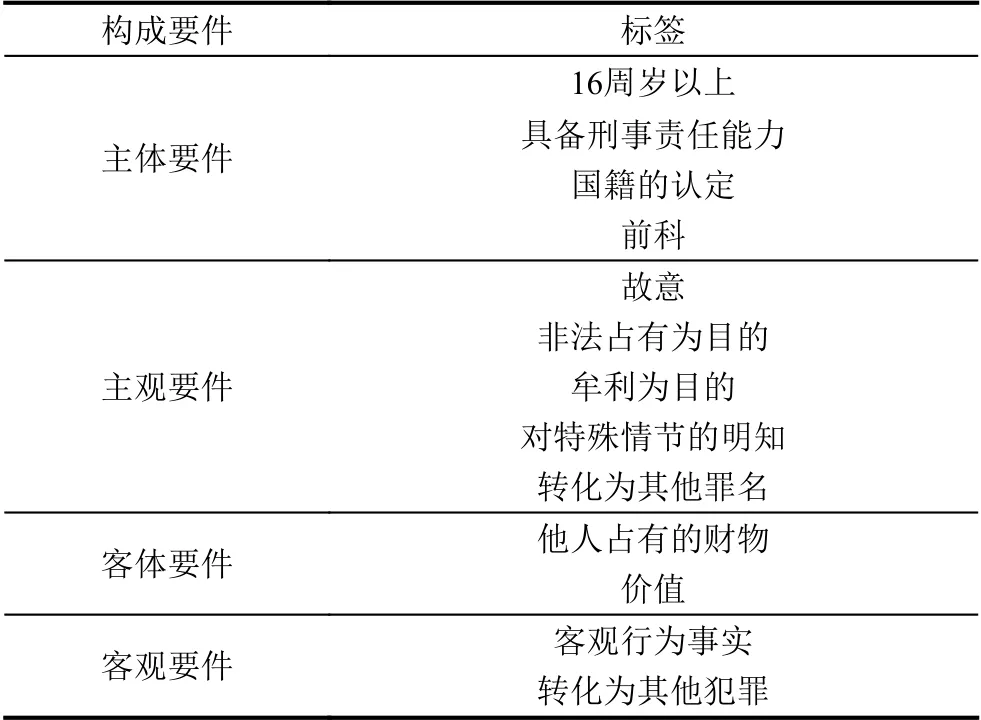
表1 盗窃罪构成要件标签体系
本文选取了客观要件作为识别对象,进一步分析客观行为事实,筛选识别的要件内容.在案件审理中,法官以客观要件中的客观行为事实来判定罪名以及量刑.在上述客观行为事实中主要考察时间、地点,犯罪参与人、动机、手段方法、被害人、行为对象、情节和后果这些内容,其中手段方法在审理中对案件的罪名有关键的作用,是判断一起案件是否构成盗窃罪,区别此罪与比罪的核心.
审理过程中犯罪情节和后果对最终处罚的基准刑有着关键作用.参考《最高人民法院量刑规范化的指导意见》第三节盗窃罪相关量刑基准中涉及到的情节,本文认为在情节和后果中可将盗窃情节分为一般盗窃行为、量刑从轻、减轻的情节和从重处罚情节这3 种方面.一般盗窃行为中根据盗窃数额来判断对该案件处以多重的刑罚.如设立盗窃财物金额标准,划分数额较大,数额巨大和数额特别巨大这几档来确定基准刑.对被盗物品和时间以及行为人和后果进行划分,可设立量刑从轻、减轻情节,如盗窃近亲属财物,初犯、偶犯,未成年人犯罪等.对盗窃行为进行划分可确定从重处罚情节,如多次盗窃,入户盗窃,教唆未成年人盗窃等.
2.2 盗窃罪构成要件识别任务
本文提出的构成要件识别任务根据法院认定的犯罪事实来识别包含的构成要件.在形式上通过给系统输入案件的事实描述部分,得到该事实中包含的构成要件标签.给定法官认定的事实句子序列X={x1,x2,x3,···,xm},预测与X对应的构成要件标签集合其中m是序列X的长度,xi表示序列中的第i个词.Y={y1,y2,y3,···,yn}为构成要件标签集合.n为构成要件类别总数,一个案件事实至少对应一个构成要件标签,可能对应多个构成要件标签,所以是Y的子集.
2.3 盗窃罪构成要件数据集构建
在构建数据集时,本文充分利用公开信息,在上述分析基础上,首先确定构成要件标签,之后在裁判文书网上筛选相应的数据作为本文的训练和测试数据.主要方法如下:
(1)本文在盗窃罪客观构成要件客观行为事实中情节和后果的基础上,依据无需金额标准的情形构建数据集,无需金额标准的情形主要包含四类,依据《最高人民法院、最高人民检察院关于办理盗窃刑事案件适用法律若干问题的解释》第三条,分别是多次盗窃,入户盗窃、携带凶器盗窃和扒窃.选取入户盗窃、携带凶器盗窃、多次盗窃和扒窃作为本文分析的盗窃罪构成要件中客观要件需要识别的部分.并加入其他标签来区分其他构成要件和其他情形.
(2)从中国裁判文书网[9],通过下载裁判文书网上刑事案件中的盗窃罪一审判决书,分析判决书中本院认为部分,查找上述分析出的关键词.图1所示,一则盗窃罪案例中,本院认为部分中包含“以非法占有为目的,在公共场所扒窃他人财物,其行为已构成盗窃罪”.从中获取关键词“扒窃”.将该文书的认定事实部分、被告人基本信息部分抽取出来,作为数据集中文本的内容.

图1 裁判文书中构成要件示例
上述构成要件识别主要依据认定的犯罪事实.无需个人信息、过往犯罪经过等信息,本文在构建数据集时,将法院裁判文书中认定的事实部分作为数据输入,将构成要件作为标签.盗窃罪构成要件数据实例如表2所示.

表2 盗窃罪构成要件数据集示例
3 基于BERT 的构成要件识别模型
3.1 模型整体流程
本文先构建盗窃罪构成要件数据集,然后基于预训练模型设计构成要件识别模型,在本文构建的盗窃罪构成要件数据集上进行训练,并取验证集上最优模型作为最终的模型,整体流程如图2所示.
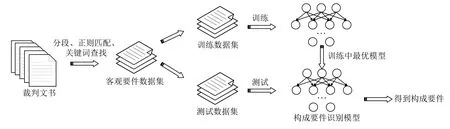
图2 构成要件识别流程图
3.2 BERT-BiLSTM-Att 模型
本文提出基于BERT的盗窃罪构成要件识别模型首先通过BERT 获取语句的向量表示,之后运用BiLSTM模型提取句特征,并结合注意力机制进一步.
获取对分类结果有重要影响的特征.具体流程如下:
(1)通过预训练语言模型获取句向量.预训练模型的大小会影响下游任务的效果.本文选用了BERTbase 模型,能接受的最长文本长度m=512字符.隐藏层维度d=768,编码层层数为l=12.在预训练模型上使用了目前最新的公开中文预训练数据集.
(2)构建盗窃罪客观要件识别模型.使用BERT 最后一层输出向量作为文本表示,并拼接BiLSTM-Att 模型,下游任务设置为多分类任务,通过下游任务对预训练神经网络进行微调.具体结构如图3所示,将得到的文本向量送入BiLSTM-Att 模型中,通过该模型识别盗窃罪构成要件并在最后使用交叉熵损失函数进行训练.
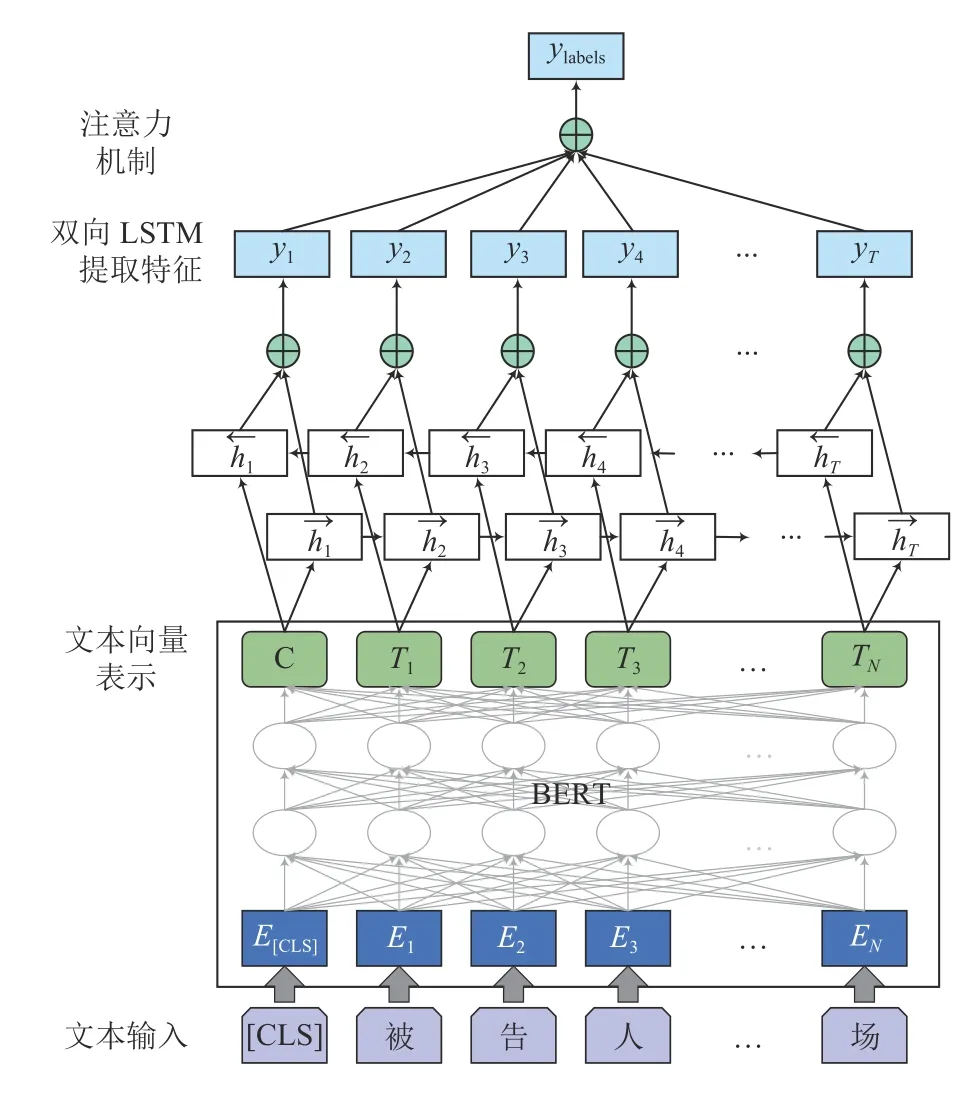
图3 BERT-BiLSTM-Att 模型结构图
在训练时设置学习率为3e-5,参数优化使用BERT-Adam 优化器.训练epoch 为60,batch-size 大小为16.
3.3 BERT 模型获取句向量
BERT 模型[10]在双向Transformer[11]编码器的基础上实现,其中每个Transformer 编码单元由6 个Encoder 堆叠在一起,Transformer 编码器单个Encoder架构图如图4所示.
图4 中N代表编码器层数,一个Transformer 编码器包含两层,一个是多头的自注意力层,另一个是前馈神经网络层.多头自注意力层中自注意力机制能弥补循环神经网络面临的长依赖问题,不仅关注当前几个词,能够获取更长的全文信息.并通过多头的方式获取不同的交互关系.

图4 Transformer encoder 模块结构图
自注意力机制的可以看做在一个线性投影空间中建立模型输入中不同向量之间的交互关系.自注意力机制的运算过程中,首先会计算出3 个新的向量:Q(query),K(key),V(value),这3 个向量是词嵌入向量与一个矩阵相乘得到的结果,该矩阵是随机初始化的维度为(64,512)的矩阵.当输入一个句子时,该句子中的每个词都与其他的词进行Attention计算,Attention的计算公式如下:
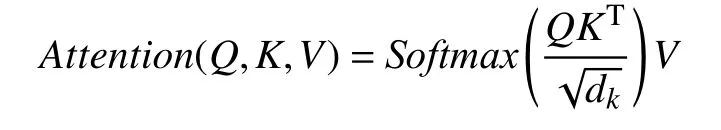
其中,dk表示每个字的query 和key 向量的维度,Softmax()是归一化指数函数.最终得到的Attention值是一个矩阵值,矩阵值的每一行代表输入句子中相应字的Attention向量,其中包含了句子中该词和其他位置的词的相互关系信息,是一个新的向量表示.由此,我们可以看到,BERT 模型使用带有自注意力机制的双向Transformer 模型获得了句子的前后语义关系,从而更好地获得了一个句子的语义表达.
在预训练过程中,BERT 使用MLM(masked language model)任务和NSP(next sentence prediction)任务进行预训练.一般使用BERT 做文本分类任务时使用BERT 最后一层池化后的输出,在其基础上使用全连接层和交叉熵损失函数进行训练,如图5所示.文本选取BERT 输出作为文本向量表示.
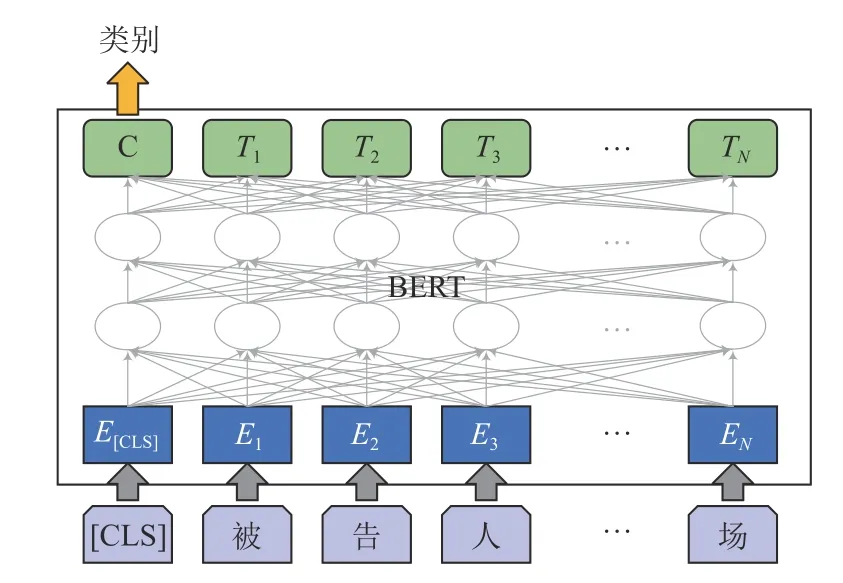
图5 BERT 文本分类模型
3.4 BiLSTM-Att 分类模型
LSTM(long short-term memory network)[12,13]是循环神经网络的一种变体,通过引入门控机制来控制信息的累计速度,包括有选择地加入新的信息,并有选择地遗忘之前累积的信息来改善循环网络的长依赖问题.BiLSTM-Attention[14]模型在LSTM 基础上,以其作为基础的网络层,通过增加一个逆句子顺序的网络层,来获取一个词的上下文关系,增强网络的表示能力.并在获取的表示后加入注意力机制来更好的获取关键的信息.
BiLSTM-Att 模型如图6所示,其中et为词向量,为某一顺序上LSTM 在该时刻的向量,为将两个向量拼接后的向量,最后将yt通过注意力层得到该句子的表示.在得到的句子表示上加入Attention层之后为BiLSTM-Attention 模型.
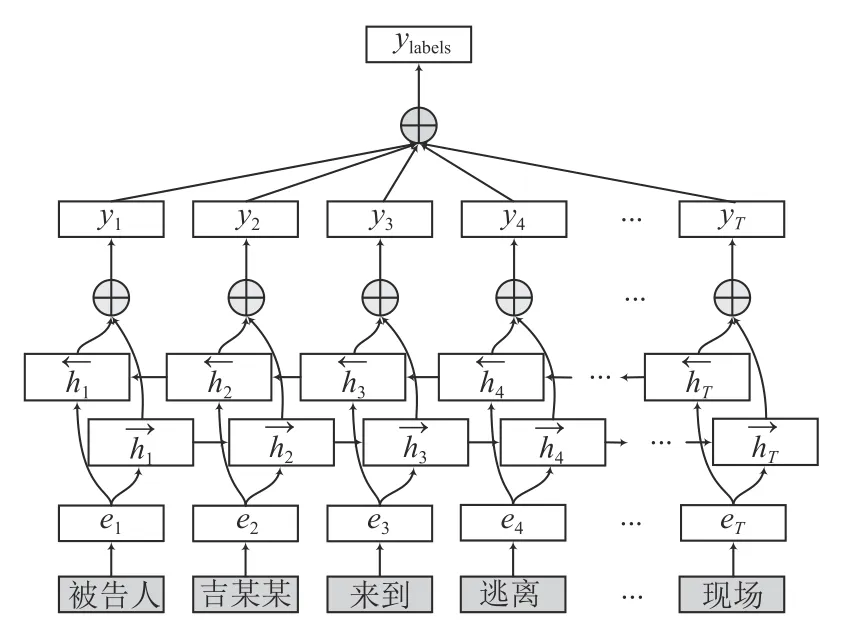
图6 BiLSTM-Att 文本分类模型
4 实验结果分析
4.1 测试数据
本文从裁判文书网上下载盗窃罪一审判决书1 万份,通过正则的方式获取文书中案件事实部分,之后对判决书提取判决结果.通过本院认为部分,提取判决结果中包含上述标签的案件构建2 400 条数据,筛选标签示例如图7所示,样例数据如表2所示.
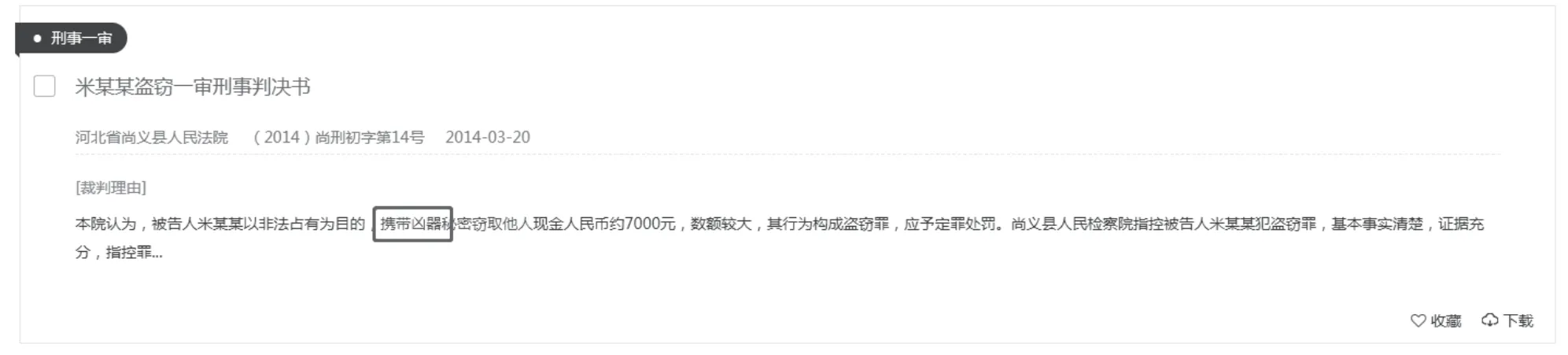
图7 判决书中标签示例
通过对案件事实和标签进行统计分析,本文构建的数据集在文本长度上按字符统计,平均文本长度为235 字,最大文本长度653 字,最小文本长度为124 字.统计相应的占比,本文构建的数据集中其他文书600 份,入户盗窃587 份,携带凶器盗窃122 份,扒窃836 份,多次盗窃483 份.占比如图8所示.
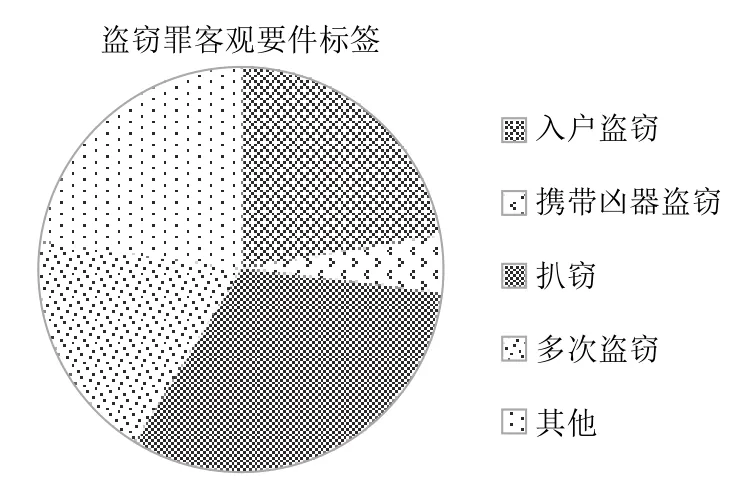
图8 各标签占数据集比例
4.2 测试环境
实验硬件设备如表3所示.

表3 实验环境
4.3 评价指标
将数据集划分为2 000 条作为训练数据,200 条作为评测在200 份测试数据中进行,评测上述所有的标签分类结果,从精度(precision),召回率(recall),F1值3 方面评测算法的结果.
精度(precision)是指标记为正类的元组实际为正类的百分比,计算方法为:
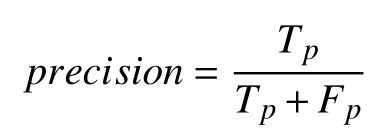
其中,Tp为被分类器正确分类的正元组个数,Fp为错误标记为正元组的负元组个数.
召回率计算方法为:
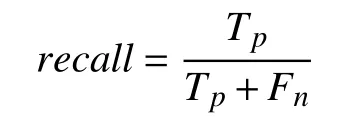
其中,Tp为模型预测出的标签正确的标签个数,Fn为被错误标记为负元组的正元组个数,即假负例个数.
F1值计算方式为:
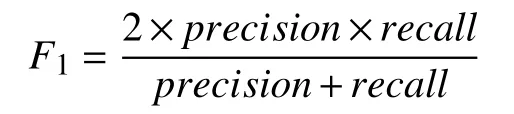
其中,precision为上述精度,recall为上述召回率.
对上述3 个指标从micro 指标进行考察,计算方式如下:
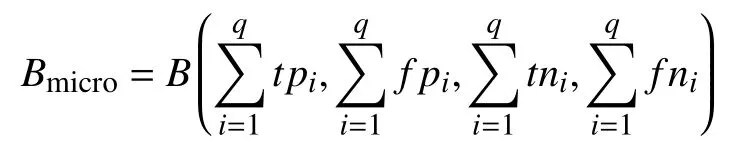
其中,B(·)为计算precision,recall和F1算符.
4.4 结果分析
数据集划分为训练数据2 000 条,验证数据200 条,测试数据200 条.实验对比了目前文本分类中常用的模型和最新的模型.对比了多个预训练模型,主要有科大讯飞开源的中文预训练语言模型[15],和清华大学开源的司法数据上的预训练语言模型.
常用的模型比较了LSTM 和基于LSTM的一些改进模型,主要有LSTM、BiLSTM 和BiLSTM-Att.模型输入的词向量本文使用Google 团队发布的Word2Vec工具[16],通过在CAIL2018 罪名预测数据集[17]的事实部分作为训练语料库,使用结巴分词将语料分词后进行训练.Word2Vec 中选择的方法为CBOW,该方法通过中心词周围的词来预测中心词.预训练词向量维度为300 维,训练设置的相关参数如表4所示.

表4 Word2Vec 参数设置
主要比较的预训练模型如下:
BERT-xs:该预训练模型在663 万篇刑事文书上进行预训练,未采用全词覆盖训练策略,训练时以字为力度进行切分.
BERT-wwm:该预训练模型在中文维基百度上进行训练,采用全词覆盖训练策略,训练时一个完整的词的部分子词被覆盖,则同属该词的其他部分也会被覆盖.
BERT-wwm-ext:该预训练模型在上述预训练方法的基础上增加了数据,其中EXT 数据包括:中文维基百科,其他百科、新闻、问答等数据,总词数达5.4 B.
RoBERTa-wwm-ext:使用RoBERTa 并使用上述的训练策略和训练数据,将模型换为RoBERTa,RoBERTa 相比于原始的BERT 做了如下改进:训练时间更久,并增大了batch size;移除了BERT 预训练任务中的NSP 任务;训练了更长的序列和动态调整mask策略.
经计算得到本文使用的模型precisionmicro为 93.54%,recallmicro为95.75%,F1micro为94.63%.
表5 中BiA 表示BiLSTM-Att 部分,BERT-xs-BiA 代表使用BERT-xs 预训练模型得到文本句向量,再送入BiLSTM-Att 中做分类,识别构成要件.BERT-xs表示只使用BERT 做分类,识别构成要件,其他模型标识同理可得.
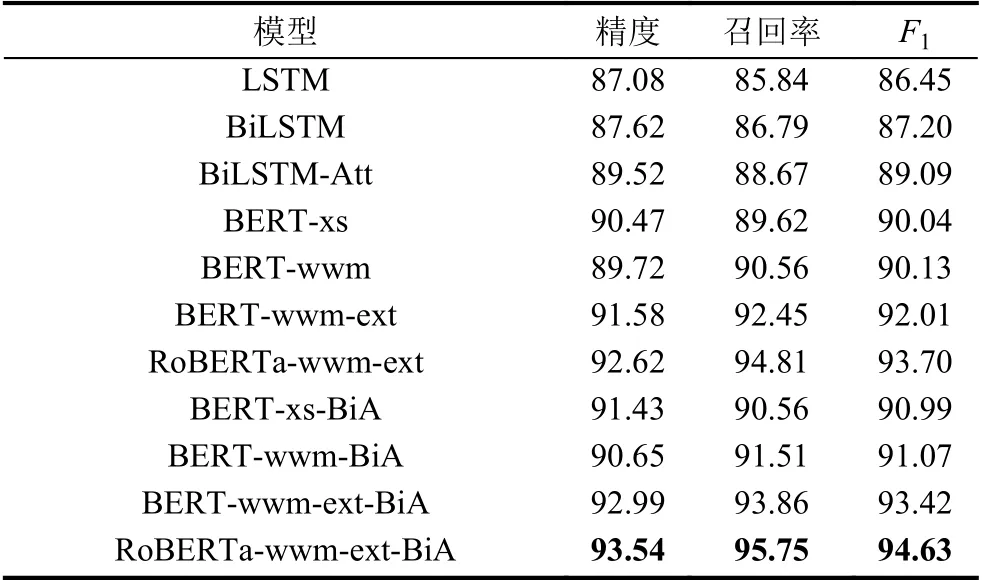
表5 测试结果(%)
从实验结果可以看到,相比于BiLSTM 和带注意力层的BiLSTM,BERT 预训练模型优于传统的模型,这表明BERT 模型能够在训练数据较少的情形下,通过面向下游任务进行微调,取得较好的结果.
通过BERT-xs 和BERT-xs-BiA 对比和其他预训练模型间比较可知使用了BERT 提取句向量做为输入比使用Word2Vec 训练得到词向量得到的结果好.这表明通过BERT 模型获取的文本向量能够更好的表示文本,通过与BiLSTM-Att 结合能进一步提高识别效果.
在基于预训练语言模型的对比中,预训练语言模型的选择也相当重要,选择合适的预训练模型能提高一定的准确率,如BERT-wwm、BERT-wwm-ext 和RoBERTa-wwm-ext 模型三者模型大小相差不大,使用RoBERTa-wwm-ext 能提高一定的准确率.在训练时BERT-xs 能够更快的学习到司法任务相关的内容,在前几个epoch 结果优于其他模型.但在最终结果上并非最优,本文认为这与下游任务有关,在司法文本分类任务上通用语料库上预训练的语言模型能达到司法文本上预训练的语言模型的结果.
5 总结
本文设计了盗窃罪构成要件识别任务,结合量刑理论,提出结合构成要件的司法智能系统构建思路.从案件审理的四要件角度,详细梳理了盗窃罪的构成要件和识别该要件所需的前置条件.之后构建了首个盗窃罪的构成要件数据集,从公开数据上利用搜索和正则匹配等方式筛选数据,构建了数据集.最后设计了基于BERT 模型的构成要件识别模型,对该数据集进行分类,并测试了相关结果.在本文构建的数据集上,该模型达到了93.54%的准确率,优于传统模型.本文提出的构成要件识别任务有很强的司法理论支撑,能够指导规范案情要素识别的内容,并且在本文工作基础上构建智能审判相关算法,能够更好的为法官提供指引,有很强的实际意义.
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
世界家苑(2020年6期)2020-06-29
山东青年(2020年1期)2020-03-24
世界家苑(2019年3期)2019-04-29
法制博览(2017年12期)2018-02-11
中国校外教育(下旬)(2016年11期)2016-12-27
中国检察官·经典案例(2016年11期)2016-12-07
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
云南大学学报法学版(2004年3期)2004-02-03
