
改进YOLOv5算法的钢筋端面检测①
2022-05-10 08:39张运楚孙绍涵张汉元
计算机系统应用 2022年4期
王 超,张运楚,2,孙绍涵,张汉元,2
1(山东建筑大学 信息与电气工程学院,济南 250101)
2(山东省智能建筑技术重点实验室,济南 250101)
钢筋作为不可或缺的结构材料,广泛应用于建筑、桥梁、交通等基建行业.无论是钢筋生产过程、还是施工现场,对钢筋进行准确计数是必不可少的环节.
在钢筋生产过程中,经轧制、冷却、剪切生产的散状钢筋,在传送链床上进行计数分钢、收集打捆、卸料,然后对每捆钢筋数量进行复核计数、称重,最后挂牌入库.散状钢筋常采用视频动态计数,通过融合多帧视频图像中钢筋端面检测和跟踪结果来实现.成捆钢筋的复核计数,则通过检测单帧图像中钢筋端面的数量来完成,准确度要求高,以捆为单位不低于98%,同时检测时间应小于100 ms/捆.在施工现场,需对进场成捆钢筋的数量进行复验,目前多采用人工计数,劳动强度大、工作效率低、出错率高,无法满足智慧工地的管理要求.
视觉成捆钢筋计数技术的关键,在于对钢筋端面的检测与分割,主要有基于传统图像处理的钢筋计数方法和基于深度学习的钢筋计数方法.
基于传统图像处理的钢筋计数方法主要利用图像增强、滤波、阈值分割进行钢筋端面检测和计数[1],或者对预处理后的图像进行模板覆盖以及空间相关性计算对钢筋端面进行检测计数[2].罗山等人[3]利用二值化后图像的面积法对成捆钢筋的根数进行统计,臧晶等人[4]首先利用双边滤波算法去噪声.然后采用最大类间方差(Otsu)算法对钢筋端面分割,再使用连通区域法对钢筋进行标记.袁中锦等人[5]运用直方图均衡化增强对比度后,再用高斯模板计算空间相关性,使钢筋截面特征更加显著,通过统计相关矩阵中的二维局部极大值点个数来得到最终计数.
近年来,基于深度学习的卷积神经网络(convolutional neural networks,CNN)在目标检测领域得到了快速发展,如YOLOv3[6]、YOLOv4[7]、YOLOv5、SSD[8]等单步目标检测算法和Fast R-CNN[9]、Faster R-CNN[10]等两步目标检测算法.
石京磊[11]利用卷积神经网络与红外相机对钢筋进行静态与动态检测,通过改进ResNeXt101 网络获得了一种级联式目标候选头网络对成捆钢筋端面进行静态检测和计数.Wu 等人[12]通过深度学习语义分割来实现钢筋计数,对弱监督标注的数据集训练语义分割,主干网络采用改进的U-net预测3 层不同的mask,推断得到语义分割二值图像,再使用轮廓提取算法找到各个钢筋端面.谢海桢[13]提出了基于全卷积网络的密集多目标识别算法MSFCN,在自建数据集上准确率和召回率均达到95%以上,相较传统算法精准度高出10%.唐楚柳[14]提出了一种由Inception-RFB-FPN 和改进ResNet34-FCN 组成的SWDA-CNN 网络用于钢筋计数,实验表明该网络提高了定位精度并节省推理时间.明洪宇等人[15]提出了一种基于RetinaNet 目标检测框架,采用基于EM 算法的高斯混合聚类方法解决检测歧义,改进后的模型mAP值为93%.王志丹[16]基于Faster R-CNN 算法利用微调后的预训练模型对增强后的数据集进行训练,得到98.3% 的mAP值,较原始Faster R-CNN 提高了2.1%,但该模型的计算复杂度较高,在实际应用中难以达到实时检测.
由于剪切的钢筋端面颜色接近,打捆后挤在一起,彼此之间界线不显著,且端面参差不齐、面积大小不一、形状不很规则等原因,基于传统图像处理的钢筋计数方法准确度和鲁棒性难以提高.基于深度学习的单步目标检测算法对密集小目标的漏检率较高,两步目标检测算法的实时性差.
本研究主要应用于两大场景,第一是钢筋生产企业入库复检,仓库的环境通常是一个整体偏暗的环境,需要灯带进行打光,除了需要打光之外在某些比较苛刻的工况下,需要定制固定的工位来进行检测,真实场景如自建数据集所示;第二是建筑工地计数,卡车运载着大量的钢筋进场,现场的验收人员需要对其进行盘点,该场景中拍照角度存在偏移,现场光照的不均,拍摄距离的远近不同导致钢筋面存在尺度不一致,真实场景如公共数据集所示.
本文提出一种基于改进YOLOv5 的钢筋端面识别计数算法,主要贡献如下:
(1)提出一种半自动数据标注方法,在公开数据集DataFountain 钢筋盘点竞赛数据集上训练YOLOv5 初始模型,对工厂环境下的自建数据集进行检测标注,自动生成标注文件,然后进行手工校正,大大提升数据集的标注效率.
(2)通过增加采样融合扩大特征图的尺度、增加模型检测层个数、改变SPP 模块在主干网络中的位置,获取更充足的端面纹理特征,丰富端面间轮廓信息,提升端面识别率.
(3)在公开数据集与自建数据集上与多个主流检测算法进行消融实验(ablation experiment),改进后的算法平均精度均值mAP达99.9%,高于所有其他模型,比原始YOLOv5 模型提升了1.1%,精准度Precision达95%,召回率Recall达99.8%.
1 YOLOv5 的改进及钢筋端面检测
本节对成捆钢筋端面检测的难点进行了总结并简要阐述了单阶段YOLO 系列检测算法框架,对YOLOv5初步实验后存在的问题进行分析,并提出改进思路.
1.1 成捆钢筋端面的特点及检测难点
成捆钢筋的端面一种密集型小目标,在检测时具有目标类别单一、目标分布较为集中、彼此区分度低等特点.采用深度学习模型对成捆钢筋端面进行检测计数会面临以下难点:
(1)钢筋端面尺寸不一.钢筋端面直径视规格型号差距较大,本文涉及钢筋端面直径在12-32 mm 之间.
(2)每捆钢筋数量差异较大,视钢筋规格型号有95、290、380 根.
(3)应用场景复杂.拍摄的距离、角度和光线不完全受控,切割端面形状差异较大、端面锈蚀颜色和亮度差异较大且存在边界粘连,部分钢筋端面窜出或缩进造成遮挡等问题.
(4)计数精度和准确度要求高.钢筋产量和使用基数很大,如果检测结果中出现了误检和漏检,需要人工从大量的标记点中找出.只有达到极高的计数精度和准确度,才能保证验收人员的使用体验.
1.2 YOLO 系列目标检测框架
YOLO 系列为单步目标检测框架,对输入图像直接进行分类概率回归和包围框坐标回归实现目标检测.从YOLOv3 开始摒弃了池化层和全连接层,使用Darknet53 代替Softmax 对目标特征进行多尺度预测.YOLOv4 是对YOLOv3的改进,网络结构主要包括主干特征提取网络CSPDarknet53、空间金字塔池化(SPP[17])、路径聚合网络(PANet[18]),同时使用了多种数据增强技术来提升检测性能,相较于YOLOv3 模型mAP值提升10%.2020年Ultralytics 发布了YOLOv5,其性能与YOLOv4 相当但推理速度更快,且模型框架更便于工程部署.YOLOv5 使用C3Darknet 作为主干网络从输入图像中提取丰富的信息特征,使用PANet作为Neck 来聚合特征,模型检测层与YOLOv3 相同,Conv 卷积模块的激活函数采用SiLU[19]函数.此外,YOLOv5 通过设置depth_multiple 和width_multiple 两个参数调节主干网络的深度和宽度并划分出4 个量级的模型:YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x.
1.3 YOLOv5算法与改进方式
由于钢筋数据集中钢筋端面分布密集、类内差异较大、钢筋端面半径小且不统一,因此采用YOLOv5x这个较深层次的网络作为原始检测模型.
1.3.1 K-means 聚类锚点框
YOLOv5算法中,预测部分分为3 个特征层,每个特征层含有3 个大小不同的先验框,先验框是通过Kmeans 聚类算法对数据集中标注检测目标聚类得到的.在聚类过程中,通过随机化初始K个聚类中心位置、计算目标标注框与聚类中心点的交并比、分配交并比最大的聚类中心、重新计算聚类中心、直到聚类中心不再发生改变.最终聚类好K个先验锚点框(anchor)的宽、高.具体的目标函数D为:
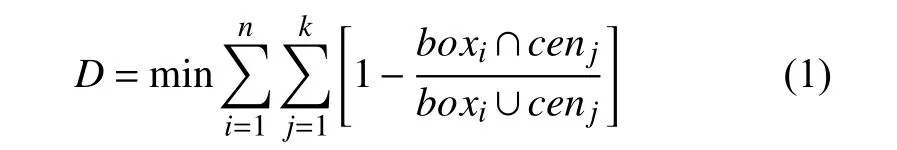
式中,boxi为检测目标中的第i个标注框的区域面积;cenj是第j个聚类中心的区域面积;boxi∩cenj为标注框与聚类中心区域交集的面积;n为检测目标的数量,k为聚类中心个数.
聚类时以准确率(Accuracy)作为聚类结果的评价指标,计算公式为:

使用K-means 算法对自建钢筋数据集的真实包围框进行聚类来确定性能最佳的K值,结果由图1所示.当K=12 时,Accuracy=91.57,指标处于较好性能.图2给出了K值分别为6、9、12、15 时数据集的真实框聚类结果图.
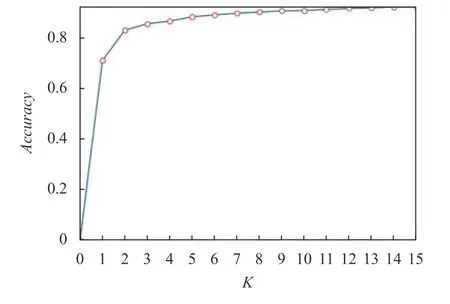
图1 Accuracy-K 折线图
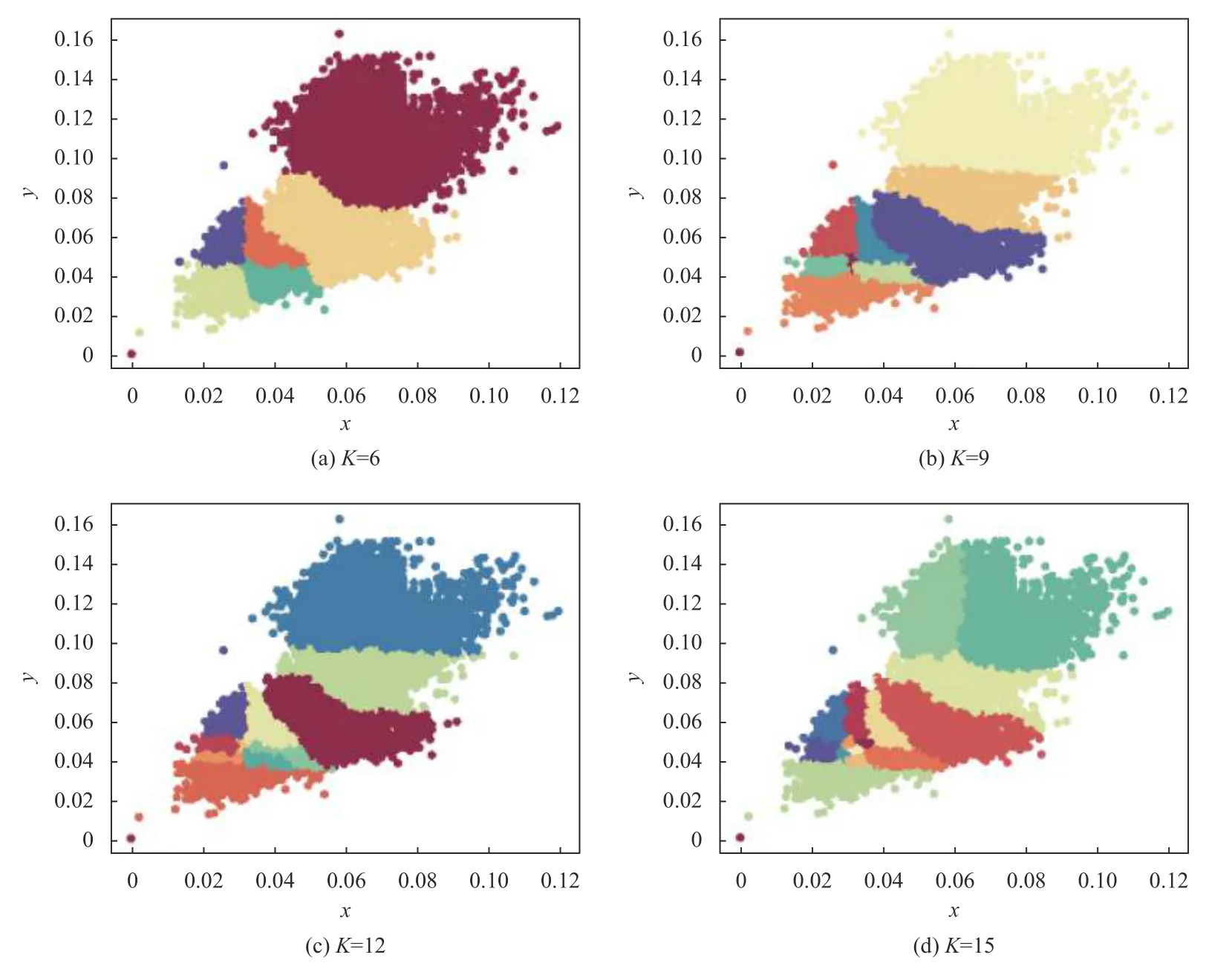
图2 样本包围框K-means 聚类可视化图
1.3.2 改进YOLOv5算法
在自建数据集上对原始YOLOv5 模型进行初步实验,自建数据集的构建将在第2 节介绍,训练参数设置将在第3.1 节给出,模型评价指标详见第1.4 节.
训练结果如图3所示,由曲线图可以看到精准度只有80% 左右,当IOU值为0.5 时的平均精度均值(mAP)为98.8%.对测试集进行检测的结果如图4 和图5所示,图中部分遮挡目标存在漏检和误检情况,原因是YOLOv5 模型只有3 个检测层各对应3 组初始化anchor,当输入图像尺寸为640×640 时,主干网络C3Darknet 第3 层对应的检测层大小为80×80,此时该层对应的感受野最小,只能用来检测大小在8×8 以上的目标.主干网络第5 层对应的检测层的大小为40×40,只能用来检测尺度在16×16 以上的目标.主干网络第7 层对应的检测层的大小为20×20,此时对应的感受野最大,只能用来检测32×32 以上的目标.
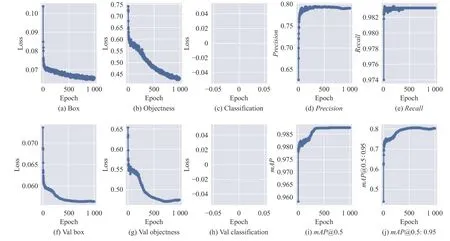
图3 原始YOLOv5 模型训练曲线图

图4 模型自建数据集检测效果图

图5 Data Fountain 数据集检测效果图
因此,当被检测目标尺度小于8×8 时,无法被检测器准确检测到,为了避免这种情况,在Neck 结构的第17 层后,继续对特征图进行上采样等处理,使特征图继续扩大,同时在Neck 第20 层,将获取到的大小为160×160 的特征图与主干网络第2 层特征图进行Concat 融合,以此获取更大的特征图进行小目标检测.改进后的YOLOv5-P2 模型结构如图6所示,其中主干Backbone 红色箭头加粗虚线是新增采样对应于Head 层160×160 预测头.由K-means 算法对数据集聚类得到效果最佳的K值为12,当anchor 的数量为12时能够得到更精确的anchor 的宽高值.所以网络模型改进思路的正确性得到初步验证.
为了找到适配数据的最佳感受野大小,另一种改进方法是把SPP 模块当作变量,添加在主干网络的不同位置.本文在主干网络第6 层与第7 层之间加入SPP模块,增大感受野提取重要的特征,来提升钢筋端面小目标检测精度.SPP 模块置于位置如图6 加粗红色虚线处所示,得到改进的YOLOv5-SPP 模型.
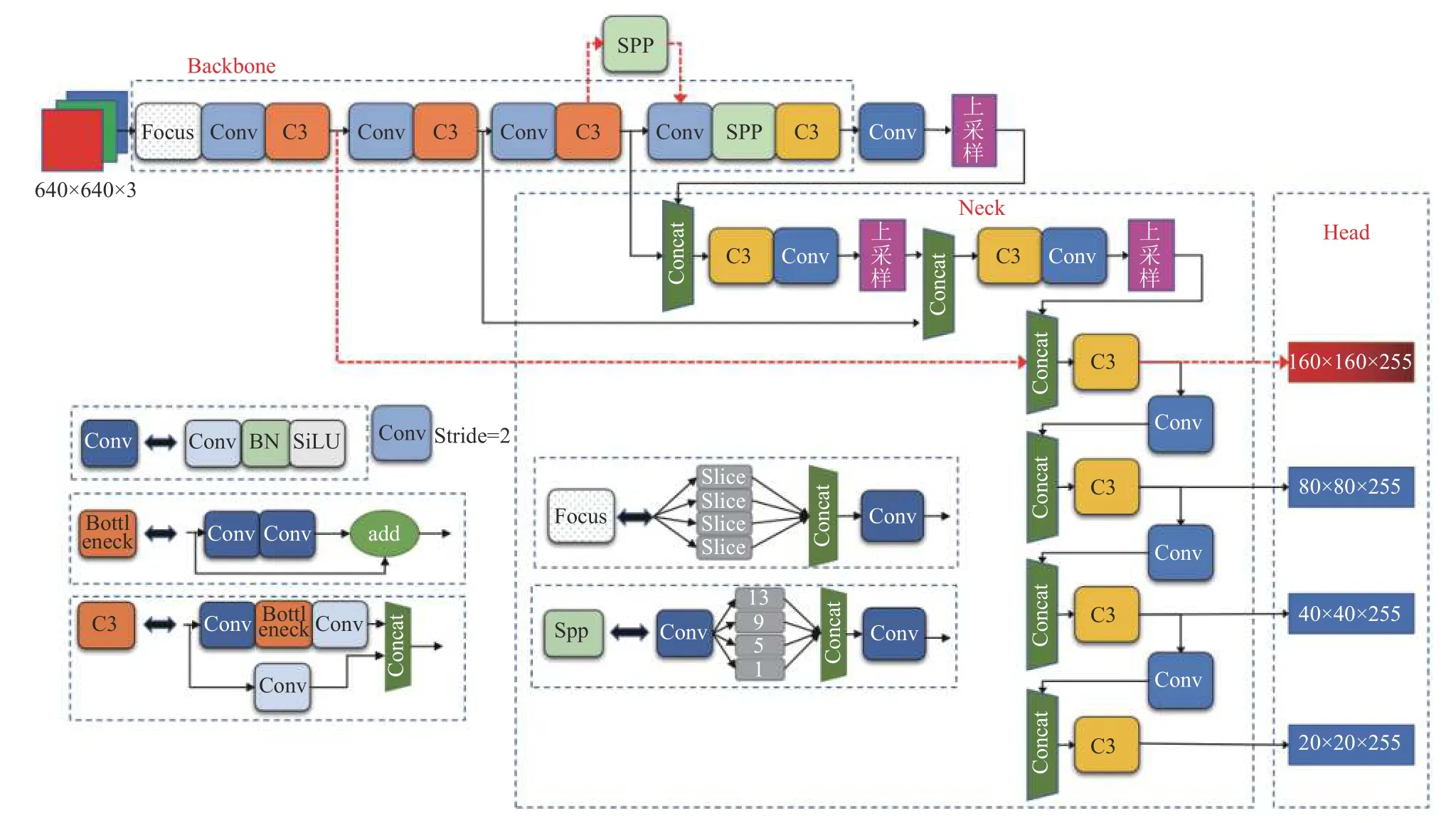
图6 改进后的 YOLOv5-P2 模型网络结构图
1.3.3 YOLOv5 改进模型损失函数
损失函数反映了预测框与真实框之间的差值,是衡量检测模型性能的重要指标.YOLOv5 模型中损失函数Loss包括预边界损失函数Lbox、置信度损失函数Lconf、分类损失函数Lcls,因此损失函数可以表示为:
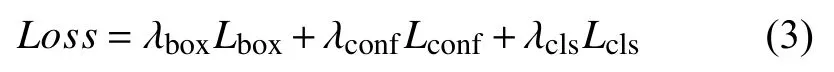
式中,λbox、λconf、λcls分别是坐标损失权重,置信度损失权重和分类损失权重.
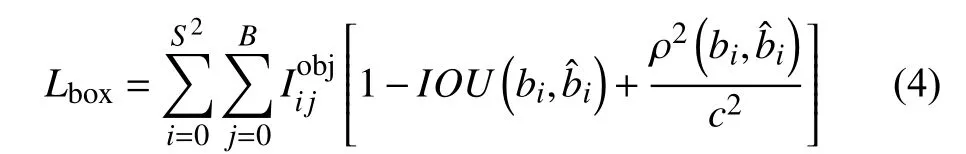
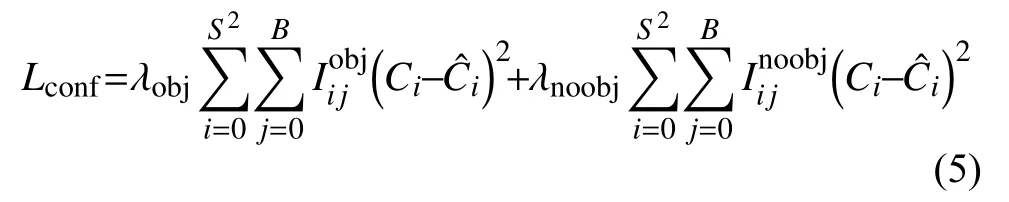
式中,Ci表示预测框的置信度得分,表示真实框的置信度得分;分别代表第i个单元的第j个锚点.
分类损失函数采用二值交叉熵损失,损失函数公式为:

其中,c是当前检测到的目标类别,classes是所有目标类别;和pi(c)分别是预测类别和真实类别.
1.4 检测模型评价指标
mAP(mean average precision)是多个验证集的平均精度均值,在目标检测任务中作为衡量检测精度的重要指标.AP(average precision)为平均精度,是P-R(precision-recall)曲线与坐标轴围成的面积值.P-R 曲线是以Recall和Precision作为横纵坐标的二维曲线.Precision和Recall的定义如式(7)和式(8):
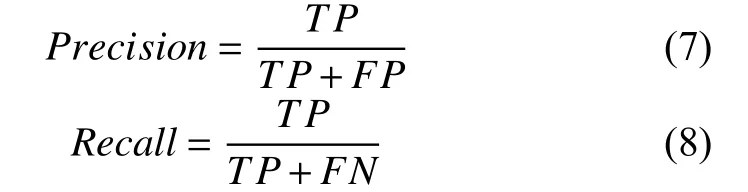
式中,TP为正确划分为钢筋的数量,FP为错误划分为钢筋的数量,FN为被错误地划分为非钢筋的数量.
绘制P-R 曲线来计算单个类的AP值,再计算各类AP值的平均值,得到整个模型的mAP值:
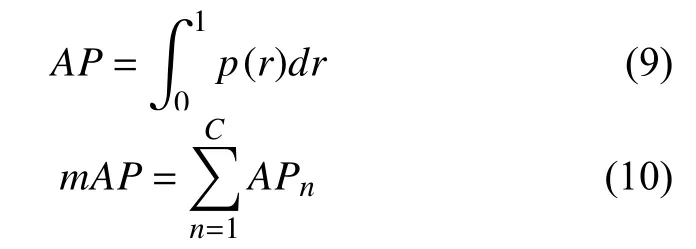
式中,p为准确率,r为召回率,C为类别总数.本文是对钢筋的单类目标检测,所以计算所得AP值就是mAP
除了mAP外,目标检测算法的另一个重要性能指标是速度.衡量速度的一个常用指标是每秒帧数(FPS),即每秒可以处理的图片数量.
2 数据集的构造及增强
2.1 数据集的获取
本文使用的数据集由两部分组成,一部分是由Data Fountain 的智能盘点钢筋数量AI 识别比赛标注好的数据集,共有标注图片250 张,图片规格是2666×2000;另一部分是自建的企业私有数据集,使用HIKVISION摄像机拍摄钢厂链条上成捆钢筋所得,共有未标注的图片958 张,图片规格为1600×1200.
2.2 数据集的半自动标注方式
钢筋数据集手工标注耗时费工,为提高工作效率,本文利用已经标注好的智能盘点钢筋数据集,训练得到初步模型,然后使用该模型检测未标注的自建数据集,生成XML 标注文件,再使用LabelImg 数据集标注软件进行手工修正标注框,以防止漏标和误标,如图7.

图7 图像半自动标注示例
2.3 数据集增强
原始数据集共有1 208 张图像,为避免模型训练产生过拟合,本文采用数据增强扩充数据集.通过水平/垂直镜像、亮度/色彩调节、随机裁剪等方式对数据集进行扩充,并自动生成扩充后的XML 标注文件,最终的数据集被扩充为3 295 张图像.图8 给出了数据增强得到的样本及其自动标注示例.

图8 数据增强得到的样本及其自动标注
2.4 数据集划分
本文使用数据集中包含了日间室外逆光、顺光和夜晚室内灯带打光等场景.
将数据集以8:1:1 比例划分训练集、验证集和测试集.选取数据集中2 636 幅图像作为训练数据集,选取未经过数据增强的图片330 张作为测试集.对划分的训练集真实目标分布情况进行可视化,结果如图9所示.

图9 训练集的目标分布统计图
3 实验及结果分析
本实验硬件配置使用Intel Core i7-9800X CPU@3.80 GHz 处理器、NVIDIA GTX 2080 Ti 显卡、32 GB RAM、3 TB 机械硬盘,操作系统是Windows 10 64 位系统.编程语言为Python,深度学习框架为PyTorch,GPU 加速库为CUDA10.2 和CUDNN8.0.
3.1 模型训练
YOLOv5 钢筋端面检测模型使用的深度学习框架为PyTorch.YOLOv5算法训练的初始参数设定为:优化器使用随机梯度下降SGD[22]和余弦学习速率衰减策略来训练网络,初始学习率(learning rate)为0.01,最终衰减速率为0.001,迭代次数(epochs)为1 000.批处理大小(batch size)为8,动量因子为0.937,输入图像分辨率为640×640,设置损失权值λbox=0.05、λconf=1、λcls=0.5、 λobj=1、 λnoobj=0.5.
批量处理多张训练图片时,同YOLOv4 算法类似采用了Mosaic[23]、Cutout[24]等方法,此外还使用了图像扰动,改变亮度、对比度、饱和度、色调,加噪声、随机缩放、随机裁剪(random crop)、翻转、旋转、随机擦除等数据增强方式.
3.2 实验结果分析
本文通过在模型Head 层修改检测层个数、增加采样融合扩大特征图的尺寸提升模型的性能.首先,为了改善钢筋端面密集小目标的检测效果,在原始主干网络上增加P2 采样层,并在head 层增加第4 个输出层.与原始模型相比,改进后的YOLOv5-P2 模型的mAP和FPS 如表1所示.

表1 模型添加小目标检测层的测试结果
由表1 可知,改进后模型在主干网络增加P2 采样层、Head 输出增加为4 层时,模型的输出特征图增大,在Neck 层提取到更多轮廓特征,提升了小目标检测精度,mAP值由98.8%提升到99.9%,Precision由原始模型的80%改进后提升到95%.尽管检测速度有所降低,仍能满足实际需要.
为了找到适配数据的最佳感受野大小,本文在主干网络的第6 层与第7 层之间加入SPP 模块,得到YOLOv5-SPP 模型,增大感受野提取重要的特征,来提升钢筋端面小目标检测精度.对比结果如表2所示.

表2 模型改变SPP 模块位置的测试结果
本文的检测目标是钢筋端面.在增强后的训练数据集上,将检测的钢筋端面预测框的平均精度均值mAP作为检测效果的衡量标准.
为了能够更好的观察各个检测层的输出以及模型各检测层的特征提取效果,对改进前后模型的检测层的特征图(feature map)进行了可视化.如图10所示,其中图10(a)为原图,图10(b)-图10(d)为原始模型的检测层可视化结果,图10(e)-图10(h)为改进模型检测层可视效果.由改进前后的图10(b)、图10(e),即小目标特征图可以看出改进后的图10(e)的可视化效果更佳,与原始图像具有空间上的对应关系,目标间的轮廓信息更丰富,此时的感受野最小,能够提升对小目标的检测效果.
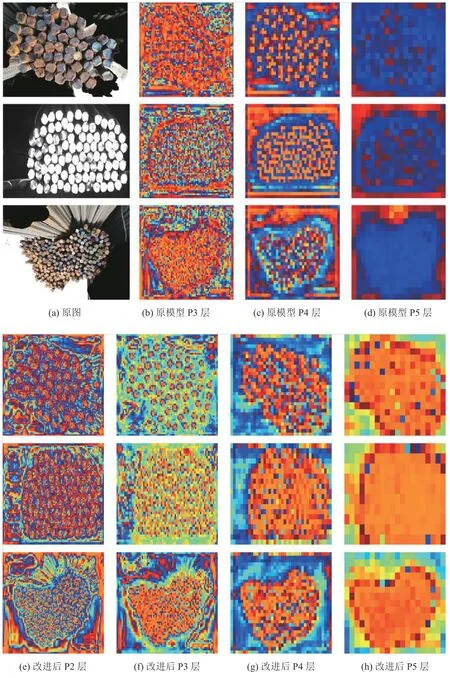
图10 特征图可视化
本文除了将改进模型与原始YOLOv5 模型进行对比外,还与YOLOv3、YOLOv3-SPP 以及YOLOv4和ScaledYOLOv4[25]等主流实时目标检测算法进行消融实验对比,结果如表3所示.表中,Augmentation 代表是否进行数据增强,K-means 表示模型是否对锚点进行聚类,epoch 表示训练迭代的次数,通过控制不同的变量来验证改进算法的效果.
未进行K-means 聚类之前默认的锚点框为[10,13],[16,30],[33,23],[30,61],[62,45],[59,119],[116,90],[156,198],[373,326],进行K-means 聚类之后锚点框为[18,30],[18,34],[19,23],[19,27],[20,31],[22,29],[22,33],[32,42],[39,67],YOLOv5-P2 模型使用的锚点框为[17,31],[17,22],[18,27],[19,32],[19,30],[20,24],[20,36],[21,28],[21,31],[24,33],[33,43],[39,67].
与目前主流的目标检测算法相对比,本文改进的算法在Precision以及mAP均取得最优.其原因如下:(1)平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化.相较于YOLOv3,YOLOv4 模型,本文模型使用了SiLU 激活函数,与Lekey-ReLU 相比,SiLU 梯度更平滑,保持准确性更好且更准取得地传播信息.(2)Neck 网络与YOLOv4 模型相似本模型使用SPP 与PANet 结构.SPP 利用4 个池化核大小分别为13×13、9×9、5×5、1×1 进行处理,该结构能分离出最显著的上下文特征,是强有力的特征提取,池化后再进行堆叠;PANet 结构是一种反复提取特征的实例分割算法,过程包括上采样、再堆叠卷积重复,之后再进行下采样、堆叠.此外本文算法还采用Mosaic 数据增强,扩充了数据集,均衡大中小目标数量:随机使用多张图片随机拼接,且通过随机缩放可以获得很多小目标,让网络的鲁棒性更好.通过以上几点对密集小目标检测效果有了很大提升,这也证明了本文模型的训练效果.
如表3 中所示,分别对几大主流目标检测模型采用相同的数据集进行训练,其中YOLOv3 模型、YOLOv3-SPP 模型均在Windows 10 环境下进行的,输入图片尺度为640×640,batch size 为8 训练的迭代次数epoch 为200.YOLOv4 模型与YOLOv4-CSP 模型均在Linux 环境下训练的,其中YOLOv4 模型的输入图片尺度为608×608,YOLOv4-CSP 模型输入图片尺度为640×640,batch size 为4,训练的迭代次数epoch为500.训练得到的模型分别在330 张测试集上设置置信度参数conf=0.15,非极大值抑制阈值IOU=0.45 进行检测得到mAP值以及FPS.

表3 不同检测算法消融实验检测精度对比
图11 给出了3 个钢筋端面检测模型的mAP值以及P-R 曲线图,其中蓝色曲线1 代表YOLOv5-P2 模型,绿色曲线2 代表YOLOv5 模型,红色曲线3 代表YOLOv3 模型.由曲线图可知改进后的YOLOv5-P2 模型检测效果优于另外两个模型.
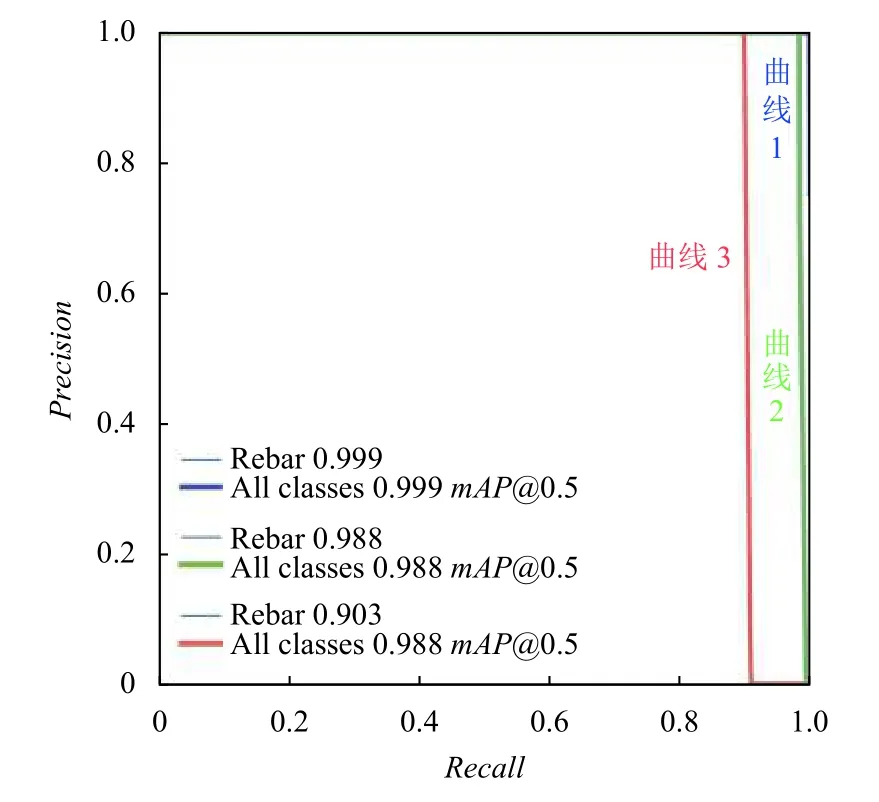
图11 各个模型P-R 曲线与mAP 值
图12 给出了为本文改进后的YOLOv5-P2 模型的训练曲线图,主要指标为mAP@0.5、精准率Precision、召回率Recall以及训练集、验证集的目标与包围框损失曲线,由于本文设计的是单类目标检测器因此分类损失函数恒为零.
使用TensorBoard 对训练过程进行可视化,可视化结果由图13所示,模型输入图片尺度为640×640,batchsize=8 时的训练曲线图.图13(a)是mAP@0.5(IOU=0.5)曲线图,即IOU=0.5 时,计算所有图片每一类的AP 值;图13(b)是mAP@0.5:0.9 曲线图:表示在IOU不同阈值(从0.5 到0.9,步长0.05)的mAP值;图13(c)表示训练集预测框损失曲线图;图13(d)表示验证集目标损失曲线图;图13(e)表示验证集预测框损失曲线图;图13(f)表示训练集目标损失曲线图.
从图13 可以看出,改进后的两个模型在mAP@0.5 曲线(曲线1、曲线2)以及mAP@0.5:0.95 曲线图中表现最优,这是衡量检测器的首要标准.图13 中曲线1 代表YOLOv5-P2 模型,曲线2 代表YOLOv5-SPP 模型,曲线3 代表YOLOv5x 模型,曲线4 代表YOLOv3 模型,曲线5 代表YOLOv5s 模型.在训练损失以及验证损失曲线图中YOLOv5-P2 模型(曲线1)比YOLOv5-SPP 模型(曲线2)损失更低,说明模型预测框与真实框更接近.
图12 给出了置信度阈值一致时训练的3 种模型,在自建数据测试集设置置信度阈值conf=0.15,NMS 阈值IOU=0.25 时钢筋端面检测的效果.从图中可以看到,对于目标边界存在粘连的情况,YOLOv3、YOLOv5 出现漏检,改进后的YOLOv5-P2 则能够准确检测出,说明改进后的模型对小目标的检测效果有很大提升.

图12 YOLOv5-P2 模型训练曲线图
图13 给出了当超参数设置一致时训练的3 种模型,在Data Fountain 测试数据集上设置置信度阈值conf=0.15,NMS 阈值IOU=0.25 时钢筋端面检测的效果,从圈出的细节图可以看出,YOLOv3 模型和YOLOv5对存在遮挡、光线过强的目标有漏检、误检情况,而YOLOv5-P2 模型能够准确的检测到钢筋目标,说明改进后的模型对两个数据集同时具有很强的自适应性和健壮性.
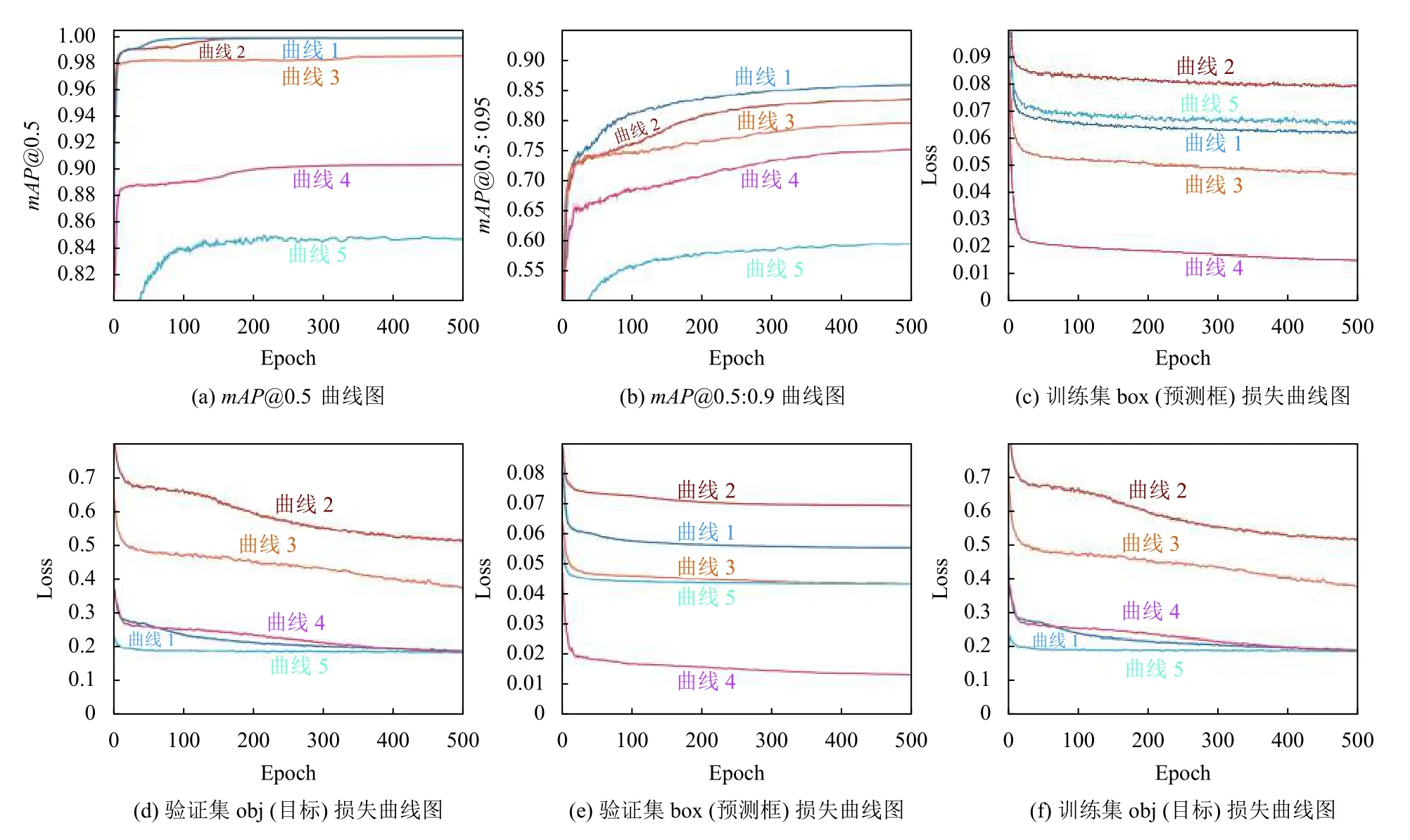
图13 各模型训练曲线对比图
改进后YOLOv5-P2 模型相较于改进前YOLOv5模型,增加了网络上增加P2 采样层,并在head 层增加第4 个输出层,目标间的轮廓信息更丰富,锚点框由9 个增加到了12 个,感受野减小特征图增大能够提升对小目标的检测效果.与YOLOv3 模型相比优化了激活函数和Mosaic 增强以及网络结构改良,因此对于实例中目标检测效果有较大提升.
为了进一步说明改进后的模型在应用于中的优越性,在330 张训练集上设置相同的置信度阈值和非极大值抑制阈值对模型进行测试得到的结果如表4所示,改进后的算法模型在测试集上检测的误检率和漏检率明显降低,正确率相对于改进前提升了2.1%.
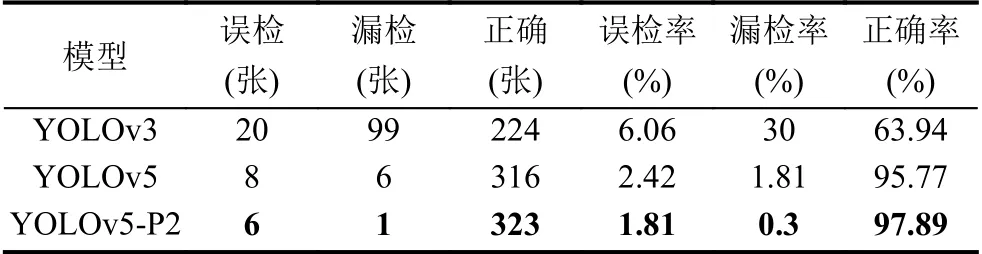
表4 在测试集多个模型检测结果对比
4 结论与展望
钢筋是建筑施工领域一种重要的材料,精准、快速的盘点出钢筋的数量代替人工盘点是一项具有重要意义的工作.本文根据钢筋端面的特点,基于改进的YOLOv5 模型框架,设计了一种钢筋端面检测计数算法.本文的主要贡献为:(1)针对目前钢筋数据集稀缺且实际应用场景复杂的问题,创建了一个新的钢筋端面数据集,并使用水平、垂直镜像、亮度色彩调节、随机裁剪等方法进行数据增强;使用预训练模型对数据进行半自动标注.(2)通过改进YOLOv5 网络结构,使输出特征图感受野扩大,路径聚合网络(PANet)能够提取更多的目标边缘特征,从而提升了密集小目标的检测精度.实验结果表明,本文方法在钢筋端面检测中的mAP和Precision等指标均有所提高,能满足实时检测的基础上显著提升密集成捆钢筋的检测精度.未来工作将考虑进一步改进网络结构对深层网络进行剪枝,在保证精度的基础上提升检测速度.
猜你喜欢
汽车实用技术(2022年19期)2022-10-19
新高考·高二数学(2022年3期)2022-04-29
汽车实用技术(2022年4期)2022-03-07
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
数学大王·低年级(2019年8期)2019-08-27
中国建筑金属结构(2018年6期)2018-08-31
科技创新导报(2016年29期)2017-03-15
电子技术与软件工程(2016年23期)2017-03-06
