
RDF问答系统中一种基于N-gram的消歧方法
2022-05-10 08:45:36江伟豪屠要峰周祥生李忠良
小型微型计算机系统 2022年5期
江伟豪,严 丽,屠要峰,周祥生,李忠良,
1(南京航空航天大学 计算机科学与技术学院/人工智能学院,南京 211106)
2(中兴通讯股份有限公司,南京 210000)
1 引 言
RDF(1)https://www.w3.org/TR/rdf-primer/(Resource Description Framework)资源描述框架,被广泛应用于表达互联网中的资源以及资源之间的语义关系[1].RDF的基本结构为主语、谓语、宾语所构成的三元组,可以记作
对于RDF数据的查询,具有语义知识背景的专业人员可以通过构建结构化查询语言SPARQL[2]来对RDF数据进行查询.虽然结构化语言具有很强的表达能力,但由于该语言复杂的语法以及RDF数据概要的约束,使用SPARQL对RDF数据进行查询对于普通用户而言需要很高的学习成本.而通过关键词搜索[3]的形式对相关RDF资源进行查询的方式虽然操作简单,但关键词的表达能力有限,仅通过几个关键词难以明确表达用户的查询意图.同样,使用受限的自然语言[4]来表达用户的查询意图,所提供的输入模板无法满足用户查询需求的多样性.对于基于自然语言处理的RDF问答系统,其中需要弥补自然语言与结构化查询语言之间的差异,而在具体转化过程中往往要解决由自然语言的语义多样性所造成的歧义,有研究人员依赖于提供用户交互操作[5]来解决其中的歧义问题,然而交互的次数不稳定会影响用户的查询效率.所以,解决转化过程中所产生的歧义问题成为了设计RDF问答系统的关键.
基于自然语言处理的RDF问答系统主要包含以下两个处理阶段:用户意图理解和查询验证.用户意图理解的主要工作是弥补非结构化的自然语言与结构化的查询语言之间的差异,在本文中的体现则是识别用户自然语言输入的查询意图,以及将查询意图转化成相应的SPARQL查询语句的过程.而查询验证阶段则是根据构造好的查询语句匹配出与问句相关的答案并进行验证的过程.其中,本文的工作更注重于用户意图理解的阶段.由于用户表达的歧义性以及自然语言的多样性,在该过程中往往会存在歧义问题,从而导致所构造的查询语言有多种组合.在用户意图理解阶段识别出与用户查询意图最匹配以及最有可能执行成功的top-k组合,相比穷举验证的效率要高.
以下,将结合例子介绍本文的研究动机.由于所提方法是针对英文语言的输入,所以本章后续的所有例子当中都以英文自然语言问句作为用户输入进行讨论.以自然语言问句:“What is the name of the film that directed by Steven Spiel-berg?”为例,该问句所对应的SPARQL查询语句组合如图1所示.表1中展示了示例的RDF片段,其中RDF数据由三元组表示,以主语、谓语、宾语的形式组成,主语为实体资源,谓语代表关系资源,而宾语可以表示为资源也可以表示为字面量.从自然语言问句转化为SPARQL查询语句的过程中分为三个处理阶段:意图提取,资源映射,语句转化.

图1 SPARQL语句方案
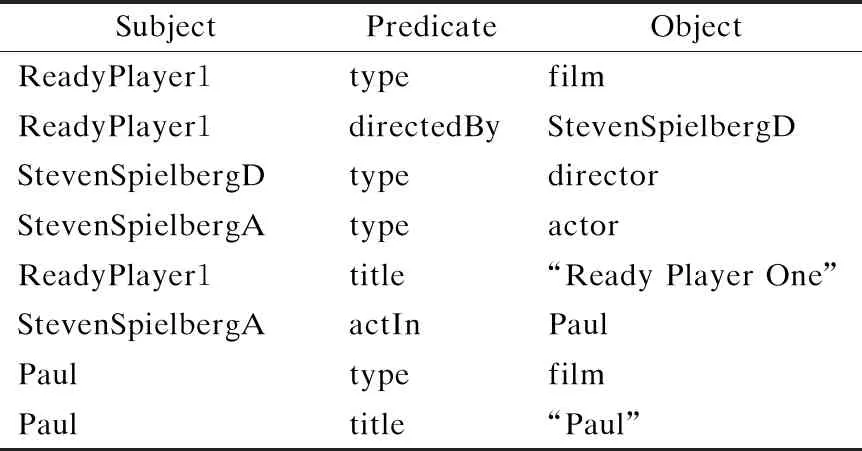
表1 RDF片段示例
以例句当中的关键词所组成的用户查询意图可表示为:
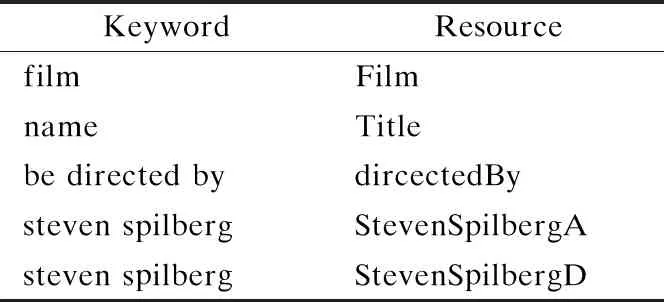
表2 资源映射表示例
对于映射歧义问题,关键词“Steven Spielberg”所映射的资源
文章基于N-gram模型的原理,利用所查询数据当中三元组所映射的关键词组合来充当语料库建立语义概率模型.在用户查询意图理解的过程中,通过语义概率模型计算用户查询意图中关键词组合的联合概率,再通过比较相应组合的联合概率,消除其中的映射歧义.然后筛选出概率最高的top-k查询语句,执行查询语句查找相应的结果.通过基准数据集与现存的方法进行比较,本文所提出的方法在精确度和召回率方面表现优异,特别是在处理隐式关系问题方面要优于其他方法,而且本方法执行的是最能表达用户查询意图的top-k查询语言,节省了无效查询语句的运行时间.
2 背景知识
2.1 RDF
RDF是用来描述互联网上资源以及资源之间相关关系的数据模型.这个资源可以是互联网中物理上的物体或者是概念的表述,比如一个人物、一个网站或者一个地址.而且资源一般使用IRI(国际资源标识符,International Resource Identifier)作为唯一的标识,例如
定义1.设G为表示RDF数据所代表的RDF图,则该RDF图是由三元组所构成的,三元组表示为
2.2 用户查询意图
由于非结构化的自然语言与结构化SPARQL查询语言之间存在差异,如何从自然语言问句当中识别出用户的查询意图并将其翻译为SPARQL查询语言是构建RDF问答系统的关键.通过借助斯坦福自然语言分析工具(Stanford Parser(2)https://nlp.stanford.edu/software/lex-parser.shtml)对自然语言进行解析,解析后可获得包含自然语言问句语法特征的类型依赖关系树(Typed Dependencies Tree)[1].如图2所示,为例句“What is the name of the film that directed by Steven Spielberg?”所对应的类型依赖关系树.每一个单词代表一个节点,节点中使用词性标注(Part of Speech tagging,POS)[7]对该单词的词性就行标识,节点之间存在的关系(边)则为类型依赖关系(Typed Dependencies),标识两个单词在句子中的语法依赖关系.本方法将从以上类型依赖关系树当中根据语法规则抽取描述用户查询意图的关键词组合,我们把每个查询意图组合定义为语义关系
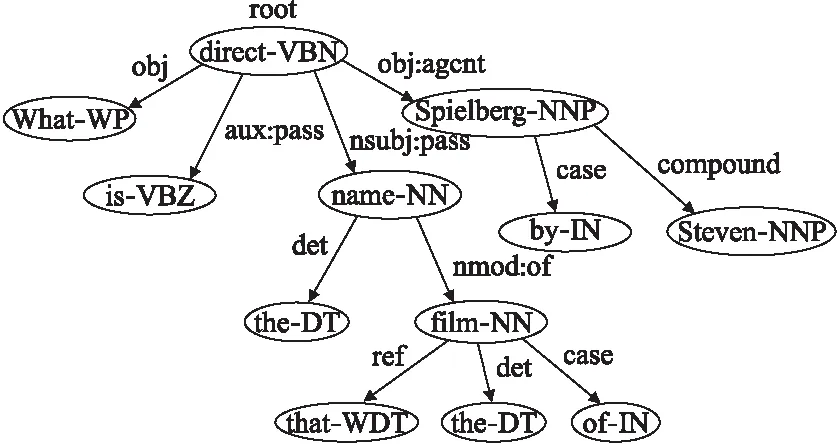
图2 类型依赖关系树示例
定义2.语义关系
2.3 N-gram模型
N-gram模型是一种语言模型(Language Model,LM),该语言模型是一个基于概率的判别模型[9].该模型描述的是,在一个自然语言句子当中,第i个单词出现的概率只与前i-1个单词相关,而与其他的单词无关,其中组成整个句子的概率则等于每个词出现的概率的乘积,即:
P(w1,w2,…,wm)=P(w1)*P(w2|w1)…P(wm|w1,w2,…,wm-1)
基于马尔科夫链的假设,当前第i个单词仅与其前n个词相关,则以上概率计算可以简化为:
其中每一项的条件概率将使用词语组合出现的频数C根据极大似然估计法(Maximum Likelihood Estimation,MLE)来计算:
在现实应用中N的值一般取2和3,其对应的是BiGram和TriGram模型.N-gram一般应用于词性标注、词汇分类、机器翻译以及语音识别等工作当中.
3 处理流程
本文所提出的基于自然语言处理的RDF问答系统的处理流程如图3所示,主要包括以下流程:1)利用斯坦福自然语言分析工具解析自然语言获取相应的类型依赖关系树;2)从类型依赖关系树当中提取与用户查询意图相关的语义关系;3)利用所建立的语义概率模型对语义关系进行消歧与组合,得到联合概率top-k的语义关系组合;4)基于top-k的语义关系组合构建相应的SPARQL查询语句,在SPARQL端口上进行查询.由于本文的贡献在于语义概率模型的建立以及如何利用语义概率模型进行消歧,其他流程均使用较为成熟的方法来实现,因此以下将按照语义概率模型的建立以及查询语言的消歧过程进行讨论.
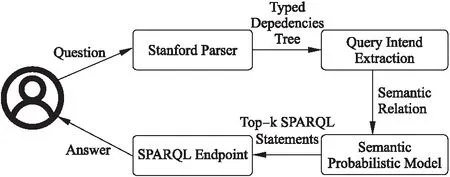
图3 处理流程图
3.1 语义概率模型的建立
由于所建立的语义概率模型需要反映所查询数据的特征,而本文所查询的数据集来源于DBpedia(2015),所以我们使用该数据集所映射的关键词集合来建立语义概率模型.对于数据源当中的每一个实体资源,首先需要知道实体与描述该实体的关键字之间的对应关系,形如表3中的关键词与实体资源的映射词典DE.DBpedia的实体资源映射表一般建立的方法是以Wikipedia中的链接为锚点链接(Anchor Link)[10],从该链接中的文章抽取关键词建立相应的映射关系,如CrossWikis[11]所实现的实体映射词典.而本方法则是直接从DBpedia-lookup(3)http://lookup.dbpedia.org/中的关键词与实体资源的映射索引中抽取映射关系实现我们的映射词典.

表3 关键词实体资源映射词典
除了关键词实体映射词典外,仍需要关键词与关系之间的映射词典DR,如表4所示,而关系则相当于连接两个实体的关系路径,如之前表达“directed by”的关系

表4 关键词关系映射词典
具备上述的关键词实体资源映射词典DE和关键词关系映射词典DR,对于数据集当中的三元组
定义3.描述三元组的关键词组合为(K(s),K(p),K(o))=((a1,a2,…,ai),(c1,c2,…,ck),(b1,b2,…,bj)),而为了区分该关键词所代表的资源是充当主语还是宾语,将以上关键词组合扩展为(,(a1,a2,…,ai),(c1,c2,…,ck),(b1,b2,…,bj),,ai,ck,bj,
P(ai,ck,bj)=P(ai|)P(ck|ai)P(bj|ck)P(
根据贝叶斯公式,需要记录(×K(s)),(K(s)×K(p)),(K(p)×K(o)),(K(o)×
定义 4.对于三元组,(d1,d2,…,dp),(c1,c2,…,ck),(e1,e2,…,eq),,dp,ck,eq,
P(dp,ck,eq)=P(dp|)P(ck|dp)P(eq|ck)P(
根据贝叶斯公式,需要记录(×K(T(s))),(K(T(s))×K(T(p))),(K(T(p))×K(T(o))),(K(T(o))×
根据以上定义建立语义概率模型,总的空间复杂度为O((ijk)2+(pqk)2).该语义概率模型不仅可以在用户意图理解阶段进行消歧以优化处理过程.基于该语义概率模型还可以实现输入提示机制,在用户输入自然语言问句的时候显示与前一个词最相关的top-k关键词以协助用户进行输入描述问题.
3.2 基于语义概率模型进行消歧
问答系统需要将自然语言问句中用户的查询意图翻译成相应的SPARQL查询语句进行查询,其中存在由语义多样性所造成的资源映射歧义以及结构歧义的问题.本小节将介绍利用上述所建立的语义概率模型在用户查询意图翻译为SPARQL语句的阶段解决以上歧义问题.
对于表示用户查询意图的语义关系,arg2,rel,arg1,和
对于包含疑问词的语义关系,如(“What”,“is the name of”,“film”),只需以变量代替疑问词的位置,则得到的语义关系为.而对于带变量的语义关系的联合概率的计算,其中P(rel|?x)的计算需要在语义概率模型中查找以rel为后缀片段的数量,然后加入到条件概率的计算当中,而对于语义关系
由于用户的语义使用习惯不同以及关键词与资源的一对多关系会存在资源映射歧义的问题.当语义关系
假设:prefix和suffix属于语义关系
1)当C(prefix)≠0且C(prefix_suffix)=0时,查找满足C(prefix_*)≠0的关键词集合σ1(wi),计算σ1(wi)中关键词与suffix的语义相似度θ(wi,suffix),当相似度大于所设定阈值γ,即θ(wi,suffix)>γ时,加入wi到suffix的候选集合当中参与联合概率的计算.
2)当C(suffix)≠0且C(prefix_suffix)=0时,查找满足C(*_suffix)≠0的关键词集合σ2(wj),计算σ2(wj)中关键词与suffix的语义相似度θ(wj,suffix),当相似度大于所设定阈值γ,即θ(wj,suffix)>γ时,加入wj到suffix的候选集合当中参与联合概率的计算.
例如在该语义关系所计算的语义关系中,rel在语义概率模型中是可以查找到的,即C(rel)≠0,由于用户的使用习惯或者语义的多样性导致用户所输入的词语arg1和arg2无法在语义概率模型中找到,表现为C(prefix_rel)=0,C(rel_suffix)=0.此时我们从语义概率模型中找出满足C(*_rel)≠0的关键词集合σ1(wi),计算其中关键词与rel的语义相似度θ(wi,rel),当该值大于我们所设定的阈值γ时,表示该关键词wi与原关键词arg1是有语义相似性的,所以将wi加入到arg1的候选集合c(arg1)当中,参与联合概率的计算.同样,满足C(rel_*)≠0的关键词σ2(wj),当其中的关键词满足θ(wj,rel)>γ时,也将wj加入到arg2的候选集合中,所以最初的语义关系
P(arg1,rel,arg2)≈P(wi,rel,wj)wi∈c(arg1)&wj∈c(arg2)
在应用中,计算语义相关性的工具有很多,比如WordNet(4)https://wordnet.princeton.edu/.而在实现中我们使用了Word2Vec来计算关键词的语义相关性,Word2Vec可以指定训练语料库去训练隐藏层的模型,在应用过程中可以使用反映所查询数据集数据特征的语料库用作训练数据集.而阈值γ的选取反映了所加入候选词与原关键词的语义相似程度,在实现中将γ设置为0.5,也可通过训练的形式寻找最佳的γ值.
对于语义关系
算法1.筛选top-k联合概率最高的语义关系
输入:语义关系组合R
输出:top-k 语义关系组合
1.M ← Ø
2.δ(R)←find_All_Combinations(R)
3.for r in δ(R):
4. p=1.0
5. for
6. c(arg1)← w from C(arg1_rel)=0 &
C(w_rel)≠ 0 & θ(w,arg1)> γ
7. c(rel)← w from C(arg1_rel)=0
& C(arg1_w)≠ 0 & θ(w,rel)> γ
8. c(arg2)← w from C(rel_arg2)=0 &
C(rel_w)≠ 0 & θ(w,arg2)> γ
9. c(rel)← w from C(rel_arg2)=0 &
C(w_arg2)≠ 0 & θ(w,rel)> γ
10. for wiin c(arg1):
11. for wjin c(rel):
12. for wkin c(arg2):
13. p=p * P(wi,wj,wk)
14. M ←((wi,wj,wk),p)
15.sortwithP(M)
16.return top-k semantic relation in M
由于自然语言表示的多样性,在自然语言表述当中存在显示关系和隐式关系的表达,例如,“Which electronics companies were founded in Beijing?”为隐式关系表达,而其对应的显示关系表达为“Which company′s industry is electronics were founded in Beijing?”.显式关系所抽取的用户查询意图为
4 实 验
本文在DBpedia上的基准数据集中验证所提出的方法.所使用的自然语言问题来自QALD-6.QALD(5)http://qald.aksw.org/是针对关联数据问题回答的一系列评估活动.与QALD-6当中的CANaLI[13],UTQA[14],KWGAnswer[15],NbFramework[16],SEMGraphQA.进行对比.文章所提方法是使用Java语言实现的,所进行的实验运行于搭载Intel Core CPU 3.80GB Hz,32 GB RAM 的Windows 10平台当中.
4.1 实验数据集
DBpedia是一个从维基百科(WikiPedia)中提取结构化信息,并且将数据存储为RDF形式发布到互联网上的组织.本次实验中所使用的数据集为2015年发布的DBpedia数据集(6)http://downloads.dbpedia.org/2015-10/core-i18n/en/,其中包含了约5百万个实体,约11亿个三元组,所包含RDF数据集的容量约为8.9GB.
文章中所使用的计算词语之间的语义相关性的工具为Word2Vec_Java(7)https://github.com/NLPchina/Word2VEC_java,是基于文献[18]中所介绍的Word2Vec模型建立的Java应用工具.Word2Vec是一个用于生产词向量的相关模型,该模型为浅而双层的神经网络.我们所用的训练语料集为Wikipedia+Gigaword 5(6B)(8)https://github.com/3Top/word2vec-api,维度为300,词典大小为400000.
4.2 实验验证
本次实验将验证QALD-6中的多语言回答问题(Multilingual question answering over DBpedia)的100个测试问题.由于我们的方法是处理英语语言方面的自然语言问题,所以在对比的时候也是使用英语语言的自然语言问句.对于中文的自然语言处理方法,可根据目标领域(如文献[19]中面向电商领域的问答)选取语料训练集建立语义概率模型,使用中文自然语言解析器(如Stanford Parser的中文解析模块)对语句进行解析,再根据中文语法对解析结果进行查询意图的提取,利用所建立的语义概率模型或者自定义消歧方法(如文献[20]中的滑动语义消歧方法)进行消歧后转化为相应的查询语句即可查询相关内容.在实验当中,我们将与上述所提方法在以下指标中作对比,分别为准确率(Accuracy,A),所解决的问题占问题总量的比例;精确度(Precision,P),所查出的正确资源占结果总量的比例;召回率(Recall,R),所查出的正确资源占正确问题总量的比例;F-1(F1-Measure)=2×P×R/(P+R),为精确度与召回率的调和平均值.表5中展示了我们所提方法(简称为NGQA)与各方法在执行测试数据后测量的以上指标的数值.

表5 验证QALD-6的测试问题
从实验结果中得知,本文所提出的方法在F-1评价中排名与NbFramewrk并列第二.我们的方法在一百个问题当中能够解决其中的58个问题,精确度为0.85,召回率为0.88,其中召回率只比CaNaLI要低,但是比其他的方法要高.其中需要注意的是,CaNaLI需要用户输入受限的自然语言问句,即用户需要以准确的资源名称(IRI表示)去表达问句当中的资源以及关系.换言之,CaNaLI解决受限自然语言V在用户层面,以用户自身的认知去进行消歧的,而我们的问答,方法却没有这种限制.
在实验过程当中,本文的方法在解决单三元组问题(如问题:“Who was the doctoral supervisor of Albert Einstein?”查询时只包含单个三元组:

表6 错误问题分析
如表7所示各方法在处理数据集中15道隐式关系问题(如:“What is the name of the school where Obama′s wife studied?”)的正确率.由于本文所提出的方法主动验证修饰词与实体词之间是否包含隐式关系,而且结合类型的联合概率计算扩展后隐式关系语句的概率,从而导致本文的方法在处理隐式关系问题方面要优于其他方法.

表7 针对隐式关系问题的准确率比较
如图4所示,从正确通过的58个问题当中随机选取10个问题进行验证时间进行测试,并与数据集当中基准的验证时间做比较,验证时间包含从查询意图转化为查询语句和查询语句查询出答案的过程.其中所选问题的验证时间均低于基准值,则是由于我们所提出的方法是通过计算查询意图可能组合的联合概率得出top-k个最优的查询组合进行查询,其中排除了几乎不可能正确的查询语句,从而缩短了验证时间.
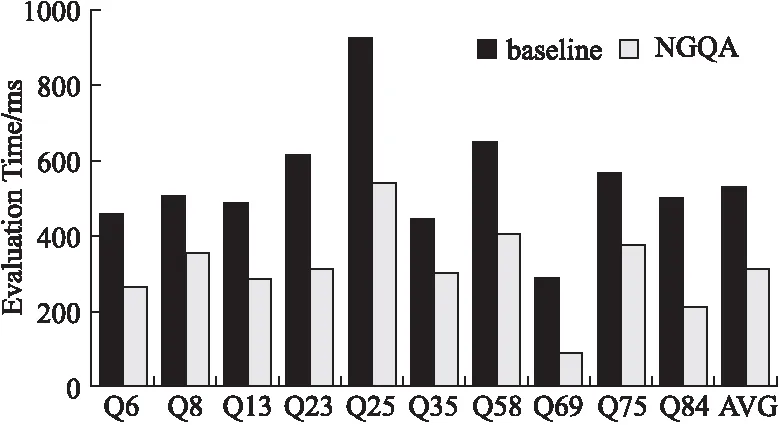
图4 验证时间比较
5 结 论
本文介绍了应用在RDF问答系统中的一种基于N-gram的消歧方法.在用户意图理解阶段,利用建立好的语义概率模型计算用户意图可能组合的联合概率,通过前缀/后缀片段对组合进行扩充,解决了映射歧义的问题,通过比较得出top-k最优组合,排除可能性较小的组合,不仅解决了结构歧义的问题,而且还提高了查询验证的效率.实验表明,本文方法在性能评估方面要优于大部分所比较的方法,特别在解决隐式关系问题中要优于其他的方法.下一步将建立更高阶的语义概率模型,优化解决联合查询以及聚合查询的问题.
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31 08:40:44
法律方法(2022年2期)2022-10-20 06:42:20
福建基础教育研究(2022年4期)2022-05-16 08:48:40
中学生数理化·高一版(2021年3期)2021-06-09 06:10:16
山西大学学报(自然科学版)(2021年1期)2021-04-21 03:38:02
法律方法(2021年3期)2021-03-16 05:56:58
五邑大学学报(自然科学版)(2019年3期)2019-09-06 02:22:22
电子测试(2018年10期)2018-06-26 05:53:50
中学生数理化·中考版(2015年10期)2015-09-10 07:22:44
延河(下半月)(2014年3期)2014-02-28 21:06:46
