
基于Octoparse的IPE环境数据采集
2022-05-09 13:53弓丽栋尹建华
计算机技术与发展 2022年4期
弓丽栋,尹建华
(1.中国能源建设集团,北京 100022;2.对外经济贸易大学,北京 100029)
0 引 言
任何科学研究的开展,不论是自然科学的实验研究还是社会科学中的实证研究,都摆脱不了对数据的依赖,甚至在个别情景中,研究数据的质量更是决定研究成败的关键[1-3]。然而,在社会科学领域,随着对传统数据库(Wind、CSMAR、RESSET等)的大众化普及和过度使用,尤其是在验证新兴领域或开拓性的研究问题时,单一的数据来源越来越难以满足科研人员的需求。在步入移动互联时代后,丰富的Web资源为各类研究学者提供了获取数据的备择通道,得益于数据采集技术的普及,大量研究开始逐渐采用此类数据[4-7]。
事实上,传统的数据采集技术不但要求操作者需拥有较为专业的编程技能,还应对Web标准有较为深入的理解。比如目前主流的Python语言,作为一种直译式计算机程序设计语言[8-10],在数据爬虫的过程中,要求科研人员了解通常的选择语句、循环语句,且对网站架构有基础理解,明确采集字段的XPath。因而对初学者来讲门槛较高,不易使用。相较于以上采集技术,Octoparse作为一种通用的Web数据采集器,可以模拟人访问的Web采集这一做法,将程序代码封装在指令集中,大大降低了对编程的依赖性,能够对Web页面中的任何可见内容进行采集,实现所见即所得。此外,Octoparse的数据导出功能可以较好配比目前主流的数据格式(如xls、xlsx、Mysql等),可以兼容主流数据分析软件。
该文以公众环境研究中心(以下简称IPE)为实验平台进行实例采集,是由于该网站作为国内首家运营企业环境信息披露的非政府组织,在学术界具有良好的受众基础,其所披露的企业环保处罚数据具有权威性、完备性以及较为规则的数据格式,是科研人员理想的数据采集网站[4,11]。该文设计的基于Octoparse数据采集技术的方案,可以通过模拟人工手动采集过程,为编程基础薄弱、不熟悉网站架构以及数据采集规则的社会科学研究人员提供一种较为理想的数据获取途径。
1 Octoparse数据采集
1.1 采集原理与流程
Web数据采集(Web Scraping)是指从网站上提取信息的一种计算机软件技术[4]。Web数据采集程序模拟浏览器的行为,能将任何可以在浏览器上显示的数据提取出来,因此也称为屏幕采集(Screen Scraping)[12-13]。Web数据采集的最终目的是将非结构化的信息从大量的网页中抽取出来以结构化的方式存储(CSV、JSON、XML、Access、Mssql、Mysql等)[14]。简而言之,Web数据采集就是从指定网站采集所需的非结构化信息数据,分析处理后存储为统一格式的本地数据文件或直接存入本地数据库中[8]。
如图1所示,Octoparse是一种基于C#的、运行在Windows系统客户端的Web数据采集工具,分为两个模块,分别为数据采集模块和数据导出模块,其采集对象包括政府政务网站、企业官网、电商、社交媒体、科研等各个领域。数据采集模块主要承担数据采集任务的配置和管理,可自动识别信息采集的列表进行遍历,通过在采集规则中自定义cookie字段或登录字段可将cookie一起投送到服务端;数据导出模块负责将采集到的HTML数据进行预处理并以结构化的形式导出至本地,其导出格式包括Excel、SQL、TXT、MYSQL等。
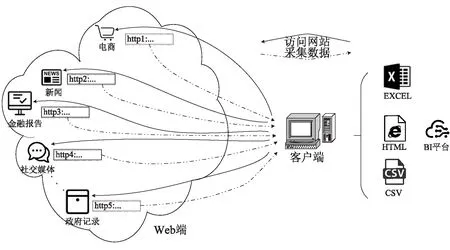
图1 Octoparse采集示意图
Octoparse的整个采集过程分为以下三个阶段:(1)使用requests访问并定位采集内容位置;(2)采用Xpath解析并采集内容;(3)使用pandas将采集后的数据保存到xls、CSV以及MySQL等数据库中。在第1个阶段中,需新建采集任务,并打开网站;在第2个阶段中,需通过点击元素(包括文字、图片、按钮、链接等)进行采集、单击或创建循环等;在第3个阶段中,确认采集内容。在应对复杂的采集对象时,还可综合采用输入文字、验证码识别、下拉菜单以及设定判断条件等,进行个性化采集。
1.2 采集优势与不足
不同于其他计算机语言,Octoparse通过模拟人的思维操作方式,将整个采集流程进行代码封装,并通过精准定位网页源码中各个数据的XPath与正则表达,实现对目标数据的可视化采集。这不仅最大限度地降低了编程门槛、减少了科研人员的Web知识储备(Html和HTTP协议),而且规避了传统采集程序的盲视操作,拥有所见即所得的采集优势。表1列示了Octoparse在数据采集过程中的优势和不足。

表1 Octoparse数据采集的优势和不足
具体地,相较于传统计算机语言,Octoparse具有以下优势:
(1)Octoparse采用模拟人的采集方式,利用程序访问网页,从目标网页提取数据,对数据进行正则表达,最后存储到数据库或者本地文件,通过可视化采集技术,其自带的条件分支、循环点击等功能大幅降低了对操作者编程能力的要求;
(2)Octoparse采集系统拥有自有云计算平台,可以实现本地编码+云端采集的并行采集,通过将采集任务部署到云计算服务器中,能够在短时间内能够从不同网页采集所需的结构化数据,摆脱对本地搜索及收集数据的依赖[15];
没有什么比了解拍摄地更关键了。选择一个离家比较近的地方,尽量在每种光照条件和季节中都多调查几次。你会逐渐积累起重要的知识,不仅可以得知在哪里能找到拍摄对象,还能了解光线变化的方式和机会较多的地方。
(3)Octoparse自带的正则工具,可以利用正则表达式在采集数据的同时进行初步数据清洗[16-17],将数据格式化,其方式包括去除(替换)特定字符、筛选日期、截取特定字符串等。
由于封装了采集语句的指令集,操作者无法打开其内部黑箱代码,因此相较于Python、R等软件,Octoparse在数据采集过程也会面临以下不足:
(1)只适用于源码数据格式较为统一的网页,比如京东、淘宝、IPE等网页架构清晰、XPath定位明显的网站;
(2)在少数翻页循环的情形下,会出现无限循环翻页前几页的情形,这是由于循环结束时的XPath设定不合理导致;
(3)个别待采集的数据,其XPath需手动配置,这需要一定HTML基础知识。
2 基于Octoparse的数据采集实例
本实例中采集对象为京津冀、长三角、珠三角总计758家的废水国控重点污染监控企业,采集时间段为2004~2017年,采集内容包括:企业名称、年份以及对应年份的企业监管记录条数共三类主要信息。这需要遍历758家企业在IPE上的URL,并依次采集其2004年至2017年间所有的监管记录条数和对应年份,总计约6 000多页数据。
2.1 企业URL采集
IPE公众环境研究中心的网页具有结构化、便于采集等优点,以上优点可以保证仅使用一套采集规则便可完成所有数据采集。
在Web数据采集之前,首先需确定目标网站(网址),图2为企业网址搜集流程。以该文所采集的废水国控重点监控企业为例,在此基础上,采用IPE公众环境研究中心的数据服务中提供的批量检索功能,可以配对企业URL。但需注意的是,IPE公众环境研究中的初步检索结果中,包含大量模糊检索的结果。具体的,对同一名称的企业单位,一是可能检索到具有相同关键词的其他企业,如:搜索“江苏阳光集团有限公司”,却出现“山东凯翔阳光集团有限公司”;二是检索到同一单位下不同的厂部,如:检索“依利安达(广州)电子有限公司”,结果中却包含“依利安达(广州)电子有限公司(西区)”;三是出现个别单位名称的错拼、漏拼甚至繁体简体互换,如:“瀚宇博德科技(江陰)有限公司”。对第一类结果,进行了直接删减、剔除;对第二类结果,进行了合并;对第三类结果,在经过企业地址比对确认之后,进行了修正整合。

图2 企业网址检索流程
2.2 数据采集
如图3所示,在获取所有企业URL队列之后,便可开始采集数据,本例中的企业监管记录数据需使用一对嵌套循环进行循环采集:如图3中箭头(1)所示,第一个母循环为企业URL列表循环,网址来源于图2中所遍历并储存的所有企业网址;如图3-A1中箭头(2)所示,第二个子循环嵌套于第一个循环中,并对上述每个企业的监管记录数据进行以年份为list的循环采集,采集对象包括企业名称(冀东水泥扶余有限责任公司)、监管年份(2017、2010)以及监管条数(1、1)。图3-A3为相对应的数据采集流程图:循环(1)在于建立URL列表循环,此步操作需在Octoparse的循环打开列表中添加全部758个URL,用于模拟人访问每个企业网址;在循环(2)中,需循环采集2004至2017年的所有监管记录,每次采集内容包括企业名称以及list文本框中的所有字段,即图3-A1中的“2017(1)”和“2010(1)”,这样在完成一次循环采集后,可保证采集到所有年份的数据。
需注意的是,由于该两组数据同处于一个list文本框中,在提取数据字段之后,需要添加一步正则表达,将字段“2017(1)”分离为“2017”以及“1”两组数据,该步骤即可在Octoparse中完成,也可在后期数据导出至Excel之后使用分栏完成。
对以上规则进行配置之后,启动运行Octoparse数据采集。表2展示了本采集方案下所采集到的部分数据。但囿于原始数据的披露情况,最终采集的企业污染违规数据格式并非平衡面板,因而在后期的研究过程中需对其进行再清洗和整理。需注意的是,目前大多数主流网站均采用了一定的规则和特定算法构建了反爬虫机制[18-19],为应对上述挑战,可适当设置访问间隔,在循环打开下一个网页时,设定大约5 s~8 s左右的时间隔断,避免频繁访问网站而造成IP封锁。
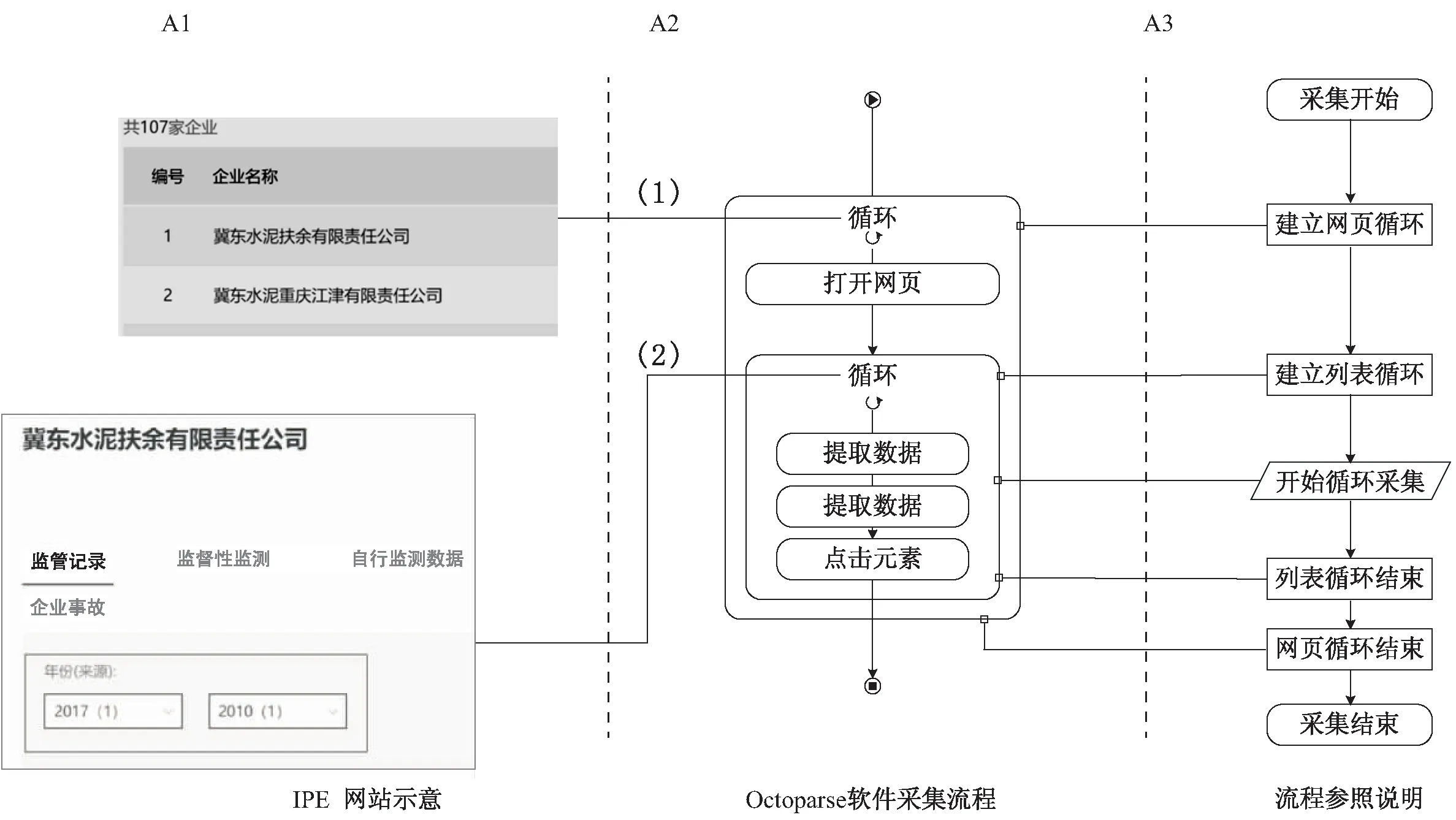
图3 基于Octoparse的IPE企业监管条数数据采集
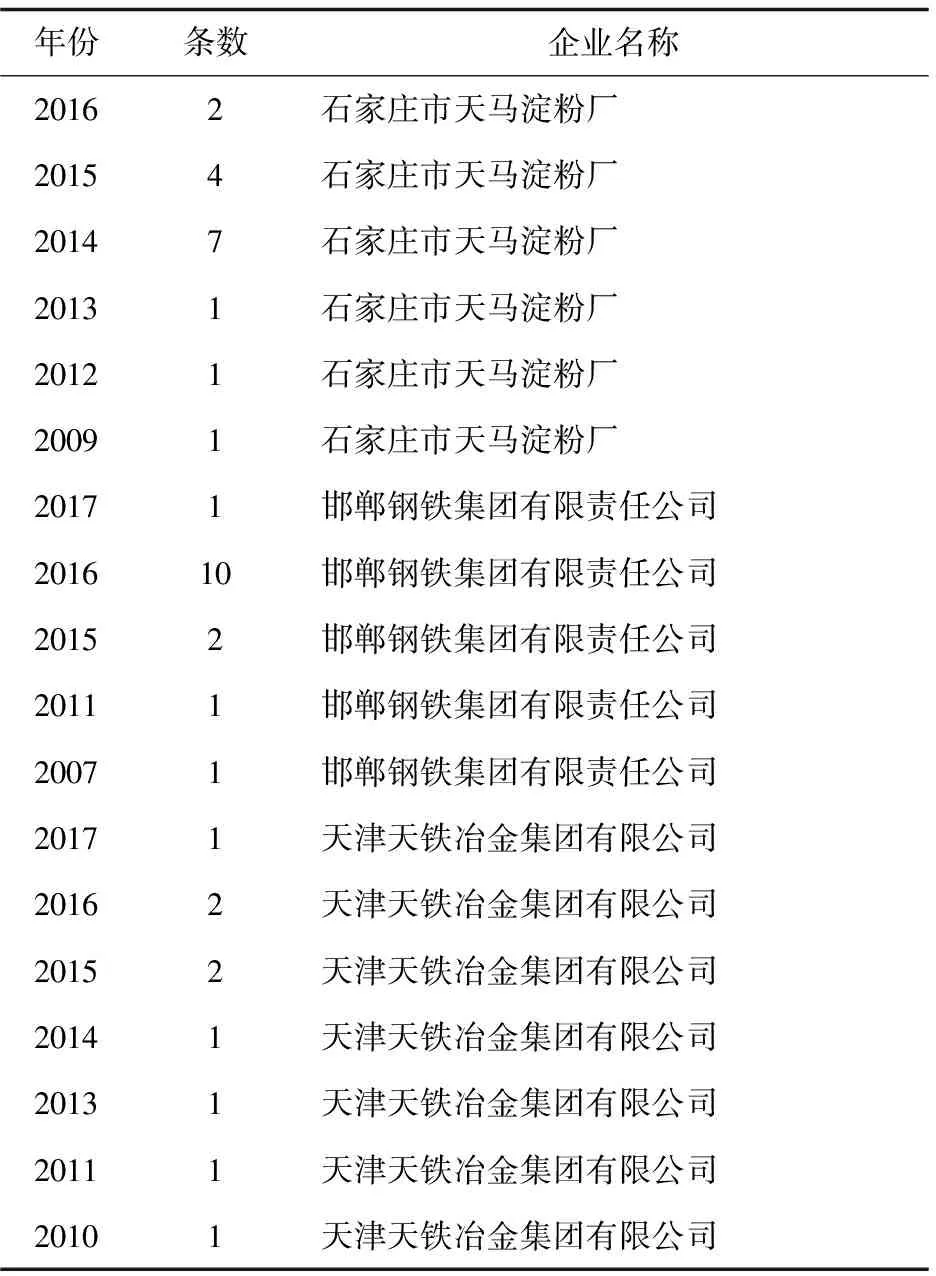
表2 部分采集数据一览
2.3 采集性能测试
实验机器为Thinkpad S2 2nd Gen,CPU为Intel® CoreTMi5-7200U 频率2.50 GHz,内存为Samsung DDR4 8 GB 频率2 133 MHz,运行环境为Win 10下Octoparse 6.4.3。
整个性能测试中,总计发生临时暂停15次,24小时内共采集到6 154条数据。表3分用网高峰中午时段和用网低谷凌晨时段的采集测试显示,在一般网速时段(网速<1 MB/s),单位小时内的平均采集信息361条,网页采集数量71页,二者均大约占较高网速时段(网速>2 MB/s)的所采条数和网页的60%左右(分别为619条和114页)。因此建议在采集过程中避开网路拥堵的高峰时段,必要时选择在夜间或者凌晨运行。

表3 IPE数据采集测试表
此外,还对比了Octoparse和Python对目标网站的采集性能对比,图4显示,基于Octoparse的数据采集,虽然其数据采集速度比Python低出约10个百分点,但连续采集过程中波动性更低,采集速率更加稳定。可以看出,该文所采用的采集方案具有一定优势。
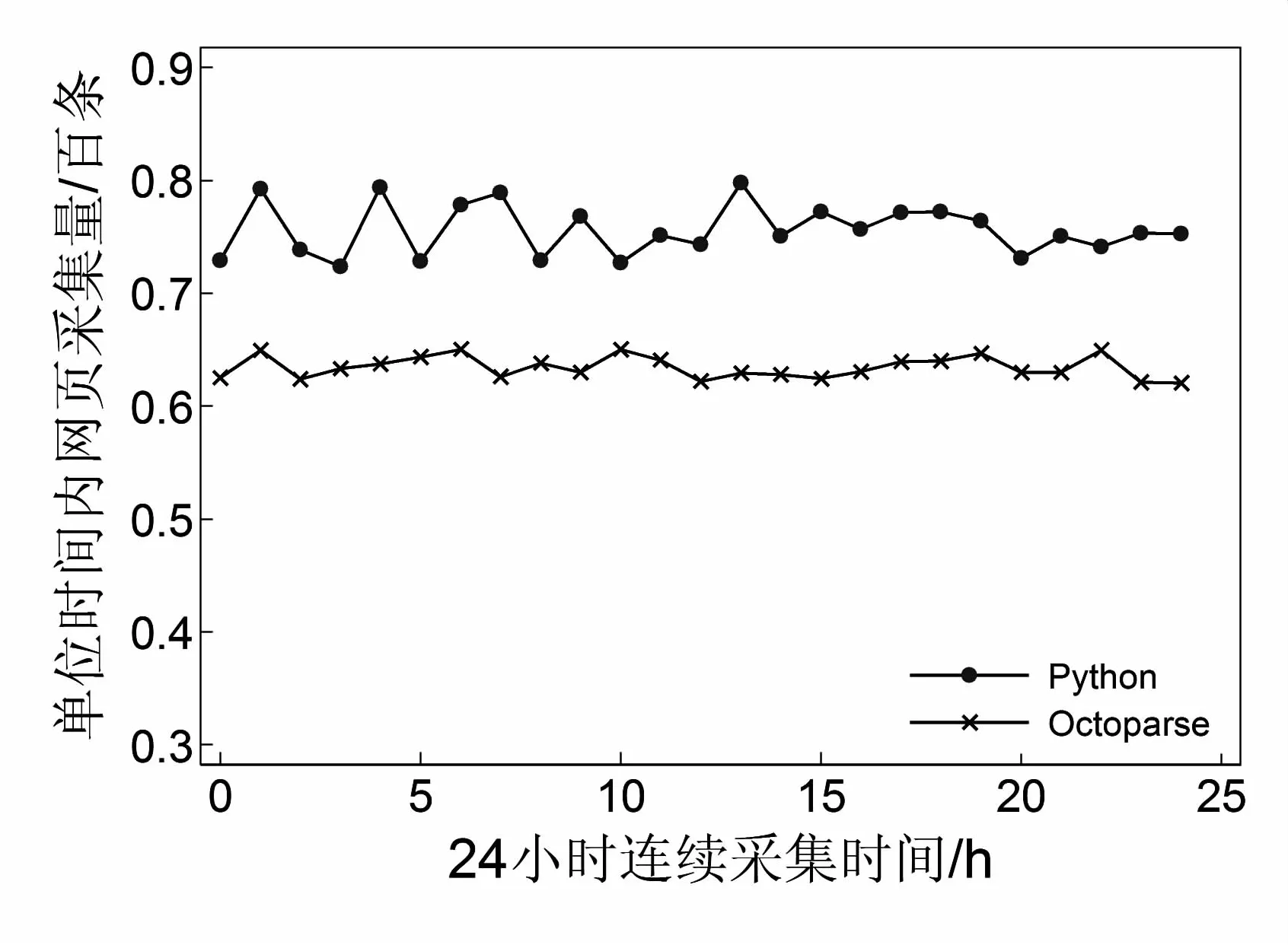
图4 数据采集性能对比
3 结束语
随着各研究领域对科研问题的不断拓展和推进,科研人员日益增长的研究数据需要同日渐枯竭的传统数据库之间的矛盾,已经成为横亘在大多数研究学者心间的症结。能否发掘最新的数据来源,以及可否获取高质量的研究数据,业已成为影响科研工作能否继续推进的核心因素。在移动互联新时代,浩瀚的Web数据为广大科研人员提供了最便捷、最有效的数据通道,但如何对其进行高效且精准的采集则是阻碍数据获取的又一道壁垒。
有鉴于此,以IPE公众环境研究中心为例,采用基于Octoparse数据采集技术的Web数据采集方案,不仅解决了传统数据采集技术编程难的问题,而且简化了采集流程,极大地提高了数据采集的效率和速度,特别是为专研环境保护、企业信息披露以及环境经济领域的专家学者,提供了一种可操作性强、可借鉴性高、可完全复制的数据采集思路,进而可以为企业环境信息的分析、地方环境政策的评估以及区域环境经济的预测提供优质的数据支撑。
猜你喜欢
当代水产(2022年8期)2022-09-20
当代水产(2022年6期)2022-06-29
当代水产(2022年5期)2022-06-05
当代水产(2022年3期)2022-04-26
当代水产(2022年2期)2022-04-26
云南画报(2020年9期)2020-10-27
电脑爱好者(2019年14期)2019-10-30
电脑爱好者(2019年17期)2019-10-30
魅力中国(2018年5期)2018-07-30
中学科技(2016年7期)2017-05-16
