
Dual Variational Generation Based ResNeSt for Near Infrared-Visible Face Recognition
2022-05-09 06:48:14DINGXiangwu丁祥武LIUChaoQINYanxia秦彦霞
DING Xiangwu(丁祥武), LIU Chao(刘 超), QIN Yanxia(秦彦霞)
College of Computer Science and Technology, Donghua University, Shanghai 201620, China
Abstract: Near infrared-visible (NIR-VIS) face recognition is to match an NIR face image to a VIS image. The main challenges of NIR-VIS face recognition are the gap caused by cross-modality and the lack of sufficient paired NIR-VIS face images to train models. This paper focuses on the generation of paired NIR-VIS face images and proposes a dual variational generator based on ResNeSt (RS-DVG). RS-DVG can generate a large number of paired NIR-VIS face images from noise, and these generated NIR-VIS face images can be used as the training set together with the real NIR-VIS face images. In addition, a triplet loss function is introduced and a novel triplet selection method is proposed specifically for the training of the current face recognition model, which maximizes the inter-class distance and minimizes the intra-class distance in the input face images. The method proposed in this paper was evaluated on the datasets CASIA NIR-VIS 2.0 and BUAA-VisNir, and relatively good results were obtained.
Key words: near infrared-visible face recognition; face image generation; ResNeSt; triplet loss function; attention mechanism
Introduction
Face recognition has always been a hot topic in computer vision. Although conventional face recognition is relatively mature, it is sensitive to illumination environment and cannot properly perform face recognition in low light or dark environment[1]. In contrast, near infrared (NIR) imaging can capture high-quality face images in low light or even dark environment, so the robustness of NIR imaging to light can largely compensate for the shortcomings of conventional face recognition.
Near infrared-visible (NIR-VIS) face recognition is a branch of heterogeneous face recognition (HFR), and current NIR-VIS face recognition faces two major challenges. (1) Cross-modality gap: NIR face images are captured under infrared imaging device and VIS face images are captured under visible imaging sensor. And this difference leads to a significant gap between face images from the same identity in different modalities. (2) Lack of sufficient paired NIR-VIS face images: one of the reasons that traditional face recognition is relatively well developed is a large number of VIS face images available. However, the size of the currently available NIR-VIS face images is relatively small, and using small-scale datasets to train the HFR is prone to overfitting. Obtaining pairs of NIR-VIS face images is a time-consuming and expensive task.
The current NIR-VIS face recognition methods can be mainly categorized into three classes[1]: invariant feature learning, subspace learning, and image synthesis. Invariant feature learning is used to learn identity-related features only between NIR face images and VIS face images, such as the deep transfer convolutional neural network for NIR-VIS face recognition proposed by Liuetal.[2], which learns invariant features on NIR-VIS face images by fine-tuning a model pre-trained with VIS face images. Yangetal.[3]combined adversarial learning to integrate modality-level and class-level alignments into a quadratic framework. Modality-level alignment in the framework is used to eliminate modality-related information and retain modality-invariant features, and class-level alignment is used to minimize the intra-class distance and to maximize the inter-class distance. The subspace learning approach focuses on learning identity discrimination features by mapping NIR face image features and VIS face image features into a common subspace. For example, Heetal.[4]used Wasserstein distance to minimize the feature distance between the NIR face image and VIS face image of the same person in a common subspace. Huangetal.[5]proposed a discriminative spectrum algorithm that minimized the feature distance between NIR face image and VIS face image from the same person in the subspace and maximized the feature distance between NIR face image and VIS face image of different identities. The image synthesis method is to synthesize cross-modality face images from the source domain to the target domain, thus transforming a cross-modality recognition problem into a single modality recognition problem. For example, a method for reconstructing VIS face images in the NIR modality is proposed by Juefei-Xuetal.[6]. Heetal.[7]used an end-to-end depth framework based on generative adversarial networks (GAN)[8]to convert NIR face images into VIS face images. Fuetal.[9]proposed an image synthesis method based on dual variational generation (DVG) from the perspective of expanding the training set, which could generate a large number of paired NIR-VIS face images from noise, thus effectively increasing the size of the training set.
To tackle the challenges in NIR-VIS face recognition, a DVG based on ResNeSt[10](RS-DVG) is proposed in this paper, which adopts the idea of DVG[9]and focuses on generating paired NIR-VIS face images. RS-DVG can generate a large number of paired NIR-VIS face images from noise, and is only concerned with the identity consistency between the generated NIR-VIS face images in pairs. Moreover, a triplet loss function which maximizes the inter-class distance and minimizes the intra-class distance in the input face images is introduced, and a novel triplet selection method is proposed specifically for the training of NIR-VIS face recognition model.
1 Proposed Method
This section is a detailed introduction to the RS-DVG proposed in this paper. Firstly, the ResNeSt used in this paper will be introduced, followed by a detailed introduction to the RS-DVG and its associated loss function, and finally the RS-DVG based NIR-VIS face recognition and the corresponding loss function will be introduced.
1.1 ResNeSt
ResNet[11]is a widely used convolutional neural network, which is proposed to reduce the difficulty of training deep neural networks, but ResNet has a limited receptive field size and lacks interaction between cross-feature map channels. ResNeSt[10]compensates for the shortcomings of ResNet by introducing a split attention module. The ResNeSt and ResNet structures are shown in Fig. 1. The Conv in Fig. 1 indicates the convolutional layer in the network.
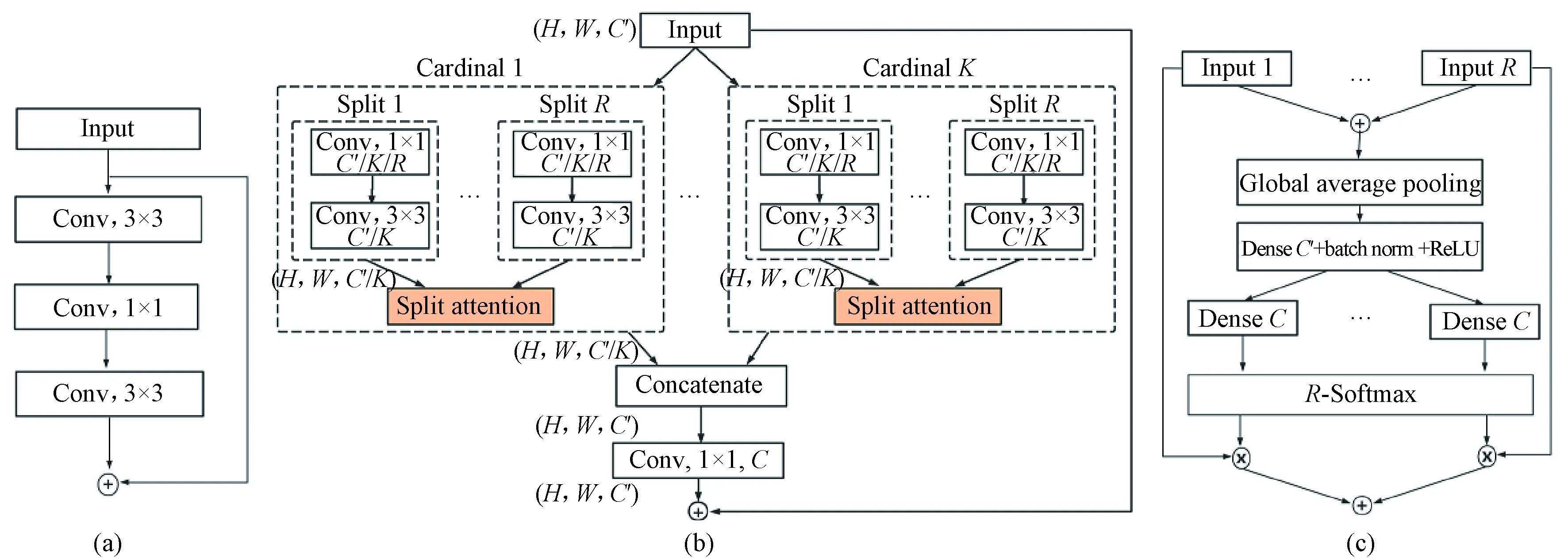
Fig. 1 Structures: (a) ResNet; (b) ResNeSt; (c) split attention unit
ResNet improves the efficiency of information propagation in the network by adding a skip connection between multiple convolutional layers, as shown in Fig. 1(a), but it does not take into account the interaction between input feature map channels. ResNeSt introduces a split-attention module based on ResNet, as shown in Fig. 1(b). ResNeSt splits the input feature map intoKcardinal groups along the channel dimension and splits each cardinal group intoRsplits. So the total number of feature splits isG=K×R. The intermediate representation of a split can be defined asUi=i(X), whereidenotes the transformations performed on the inputXin spliti,i∈{1, 2,…,G}. The representation of each cardinal group can be defined ask∈{1, 2,…,K},C′=C/K, andH,W, andCdenote the feature map size of the input of ResNeSt block. Besides, the global average pooling operation across the spatial dimensionsk∈RC′is used to obtain the global contextual representation information of the statistical information of each channel, for example, the formula for thec-th component can be expressed as(i,j).

(1)
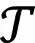
1.2 Dual variational generation based ResNeSt
The RS-DVG structure proposed in this paper is the same as DVG[9], which consists of two encodersENandEV, and a decoderDI, as shown in Fig. 2.Fipis the face image feature extractor, as seen in section 1.3. The encoder and decoder network structure in DVG is based on ResNet, but the encoder and decoder network structure in RS-DVG is based on ResNeSt, as shown in Fig. 3, where Fig. 3(a) represents the network structure ofENandEV, and Fig. 3(b) represents the network structure ofDI.
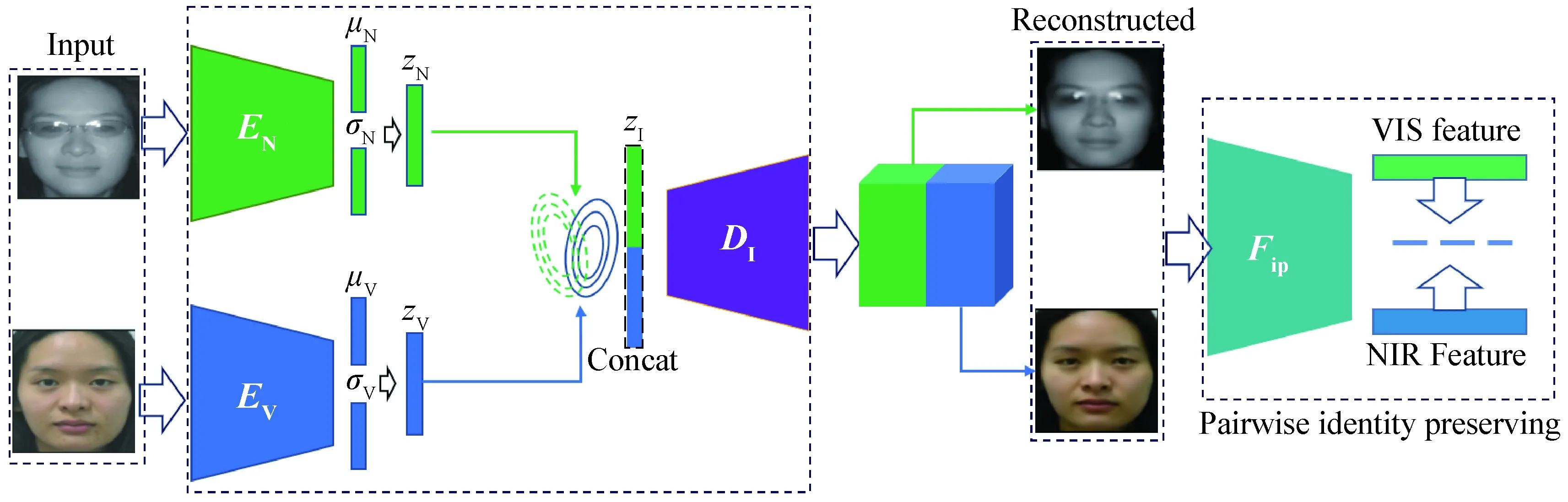
Fig. 2 Structure of RS-DVG

Fig. 3 Structures in RS-DVG: (a) encoder; (b) decoder
The two encoders in RS-DVG are used to map the input NIR face imagexNand VIS face imagexVto the distributionsqØN(zN|xN) andqØV(zV|xV), respectively, where ØNand ØVare the parameters learned by the encoder. The encoder is trained so that the encoding resultsqØN(zN|xN) andqØV(zV|xV) can sufficiently approximate the distributionp(zi) corresponding to the latent variablezi, wherei∈{N,V}. In this paper, the distributionsp(zN) andp(zV) are set to be multivariate standard Gaussian distributions. The meanμiand standard deviationσi(i∈{N,V}) can be obtained from the output of the encoder. Since the backpropagation operation cannot be performed directly onμiandσi, to train the decoder, a reparameterization operation is adoped in this paper:zi=μi+σi⊙, wherei∈{N,V},is the standard Gaussian distribution sampling value, and ⊙ in this paper is the Hadamard product. The decoder is used to reconstruct the joint distributionpθ(xN,xV|zI) of the NIR face image and the VIS face image, wherezIis the result of combiningzNandzVobtained by sampling fromqØN(zNxN) andqØV(zVxV), respectively, andθdenotes the parameter learned by the decoder.
1.3 Loss function in RS-DVG
This subsection provides a detailed description of the loss functions involved in the training process of the RS-DVG.
For training the encoder, Eq. (2) is used as
(2)
whereDKLdenotes the KL divergence, and both the distributionsp(zN) andp(zV) are multivariate standard Gaussian distributions. To enable the decoder to reconstruct the face imagesxNandxV, the following equation is used
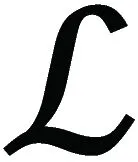
(3)
wherepθ(xN,xV|zI) is the joint distribution fitted by the decoder, andqØV(zV|xV)∪qØN(zN|xN)denotes the joint distribution of the distributions fitted by the two encoders, separately.

(4)
(5)
(6)
whereλ1andλ2are the trade-off parameters.
1.4 NIR-VIS face recognition based RS-DVG
This paper uses LightCNN-29[13]as the feature extractorF, as shown in Fig. 4, whereDIis the decoder in the trained RS-DVG.

Fig. 4 Structure of NIR-VIS face recognition
The structure ofFis shown in Fig. 5, where MFM is the activation function max-feature-map which is an extension of the maxout activation function. Maxout uses enough hidden neurons to be infinitely close to a convex function, but MFM makes the convolutional neural network lighter and more robust by suppressing a small number of neurons.

Fig. 5 Structure of LightCNN-29
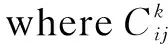
(7)
1.5 Loss function in NIR-VIS face recognition
In this paper, real data and generated data constitute the training set for NIR-VIS face recognition. What the generated data and the real data have in common is the identity consistency between every paired NIR-VIS face images, while the difference is that the generated face images do not belong to a specific category, while the real face images have their corresponding identity categories. Therefore, different loss functions were used in the training for both generated and real data, which were described in detail in this subsection.
(8)
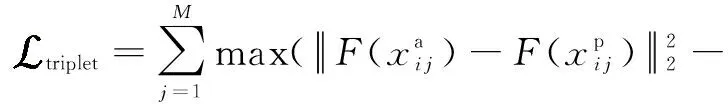
(9)

(10)
whereα1is the trade-off parameters.
2 Experiments Evaluation
In this section, some experiments will be carried out on two challenging datasets, including CASIA NIR-VIS 2.0[14]and BUAA-VisNir[15], to illustrate the effectiveness of RS_DVG framework in paired NIR-VIS face images generation. Then, the accuracy of RS_DVG’s NIR-VIS is evaluated against state-of-the-art heterogeneous face recognition on these datasets.
2.1 Datasets and protocol
The total number of the subjects in CASIA NIR-VIS 2.0 dataset is 725. Each subject has 1-22 VIS and 5-50 NIR face images. This training follows the View2[14]protocol and includes tenfold cross-validation, where the training set includes nearly 6 100 NIR face images and 2 500 VIS face images from about 360 identities, and the testing set contains 358 VIS face images and 6 000 NIR face images from 358 identities. There was no intersection between training and testing sets. The final evaluation metrics were Rank-1 accuracy and verification rate at a false acceptance rate of 0.1%(i.e.,VR@FAR=0.1%).
The BUAA-VisNir dataset consists of NIR face images and VIS face images from 150 identities. The training set consists of approximately 1 200 face images from 50 identities, and the test set is approximately 1 300 face images from the remaining 100 identities. The test was conducted using NIR face images to match VIS face images. The final evaluation metrics were Rank-1 accuracy,VR@FAR=1.0%, andVR@FAR=0.1%, respectively.
2.2 Experimental settings
The backbone for the encoder and decoder in RS-DVG is ResNeSt, with a parameterKof 2 and a parameterRof 1. The feature extractor used in RS-DVG is LightCNN-29[13], pre-trained on the dataset MS-Celeb-1M[16], with an optimizer Adam and an initial learning rate of 2×10-4. The NIR-VIS face recognition backbone is LightCNN-29 with a stochastic gradient descent optimizer and an initial learning rate of 10-3, which decreases to 5×10-4as the model is trained.
2.3 Experimental results
2.3.1 Datageneration
For experimental comparison, the VAE[17]was trained with CASIA NIR-VIS 2.0 dataset. Samples drawn from it after training are shown in Fig. 6(a). The proposed RS-DVG was trained with CASIA NIR-VIS 2.0 dataset, and then 100 000 paired NIR-VIS face images were generated by it. Generated samples(128×128) are shown in Fig. 6(b). With BUAA-VisNir dataset, RS-DVG was trained, and also generated 100 000 paired NIR-VIS face images. Part samples are shown in Fig. 6(c).

Fig. 6 NIR-VIS face images generated from: (a) VAE trained with CASIA NIR-VIS 2.0 dataset; (b) RS-DVG trained with CASIA NIR-VIS 2.0 dataset; (c) RS-DVG trained with BUAA-VisNir dataset(the first row shows the NIR face image and the second row shows the corresponding VIS face image)
These experiments show that RS-DVG outperforms its competitors, especially on CASIA NIR-VIS 2.0 dataset. RS-DVG generates new paired images with clear outline, and abundant intraclass diversity (e.g., the pose and the expression).
2.3.2 NIR-VISfacerecognition
The recognition performance of our proposed RS-DVG is demonstrated in this section on two heterogeneous face recognition datasets. The performance of state-of-the-art methods, such as transfer NIR-VIS heterogeneous face recognition network (TRIVET)[2], Wasserstein CNN (W-CNN)[4], invariant deep representation (IDR)[18], coupled deep learning (CDL)[19], disentangled variational representation (DVR)[20], and DVG is compared in Table 1.
Table 1 shows that on CASIA NIR-VIS 2.0 dataset, RS-DVG achieves 99.9% and 99.8% recognition rates in the Rank-1 andVR@FAR=0.1%, respectively. And compared to DVG, it improves Rank-1 accuracy from 99.8% to 99.9%. On BUAA-VisNir dataset, RS-DVG also achieves the highest Rank-1 accuracy. Compared to DVG, RS-DVG improvesVR@FAR=0.1% from 97.3% to 97.5% and improvesVR@FAR=1% from 98.5% to 98.6%.
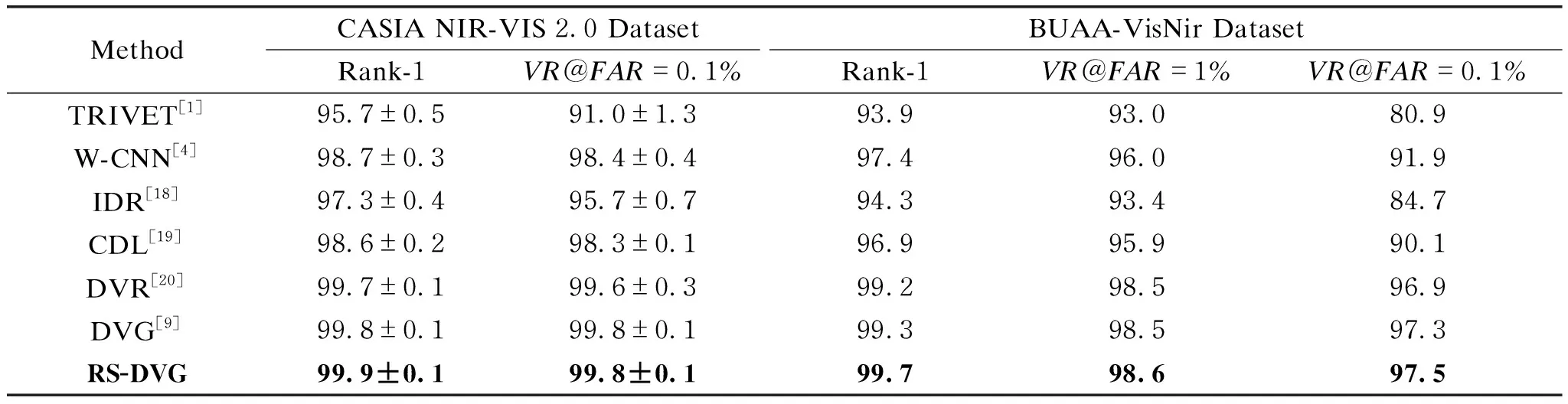
Table 1 Experimental results of NIR-VIS face recognition
3 Conclusions
In this paper, a dual variational generator based ResNeSt is proposed, which can generate a large amount of pairwise heterogeneous data from noise, which can effectively expand the training set size of heterogeneous face recognition. A triplet loss function is introduced and a novel triplet selection method is proposed specifically for the training of the current heterogeneous face recognition, which maximizes the inter-class distance and minimizes the intra-class distance in the input face images. The experimental results on two datasets demonstrate the effectiveness of the method proposed in this paper.
 Journal of Donghua University(English Edition)2022年2期
Journal of Donghua University(English Edition)2022年2期
- Journal of Donghua University(English Edition)的其它文章
- Specific Enthalpy Based Heat Stress Index for Indoor Environments without Radiation Effect
- Structure and Properties of Pure Cotton Low-Twist Single Yarn Based on Addition of Long-Staple Cotton
- Maximum Group Perceived Utility Consensus Models Considering Regret Aversion
- Crop Leaf Disease Recognition Network Based on Brain Parallel Interaction Mechanism
- Temperature-Dependent Growth of Ordered ZnO Nanorod Arrays
- Hydrothermal Synthesis of Ordered ZnO Nanorod Arrays by Nanosphere Lithography Method