
层次多标签文本分类方法
2022-05-09 10:59赵海燕陈庆奎
小型微型计算机系统 2022年4期
赵海燕,曹 杰,陈庆奎,曹 健
1(上海市现代光学系统重点实验室 光学仪器与系统教育部工程研究中心 上海理工大学光电信息与计算机工程学院 上海市军工路 516 号,上海 200093)
2(上海交通大学 计算机科学与技术系,上海 200030)
1 引 言
分类问题是机器学习中的经典问题.有一些对象具有多个类别,预测这些类别就成为了一个多分类问题,也被称为多标签分类问题.在现实世界的许多问题上,标签之间具有层次结构,其中,一个标签可以被特殊化为子类(Subclass)或者被一个超类(Superclass)所包含[1-3].层次多标签可以采用树(Tree)或者有向无环图(DAG)[4-6]进行表示(如图1所示,根节点下有Chemistry和Physics两个子类,而Chemistry有Inorganic Chemistry和Organic Chemistry两个子类,Physics有Mechanics和Optics两个子类;图2和图1的区别是Material Science是Chemistry和Physics的子类;后面使用图示类似),其中对于树结构来说,一个标签节点只有一个父节点;而对于DAG结构来说,一个标签节点可以有多个父节点.对于一个给定的样本,同时将一个或多个类标签指定给该样本[7],并且这些类标签以层次结构(Hierarchical Structure)的形式存储,这就是层次多标签分类(Hierarchical Multi-label Classification,HMC)问题.
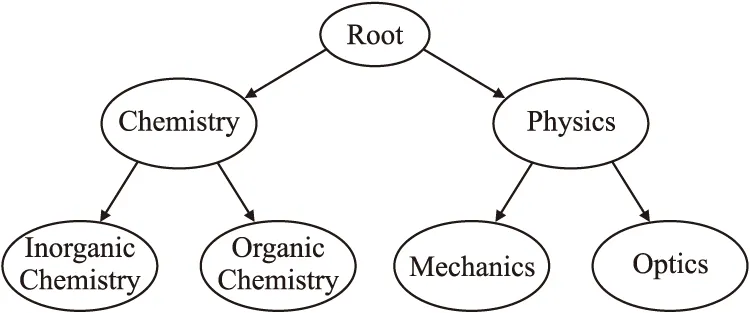
图1 树结构样例图Fig.1 Example diagram of tree structure

图2 有向无环图结构样例图Fig.2 Example diagram of DAG
层次多标签分类和标准平面多标签分类相比,在于前者的标签是以预定义的层次结构存储的,这带来了不同层级以及相同层级之间的标签之间的内在关系,而对于平面多分类问题不用考虑这种关联关系.如何学习和利用这些不同层级的关系、并对分类结果从层级关系遵循性的角度进行评价成为了层次多标签分类问题的难点和挑战.
在本文中,主要对层次多标签文本分类(Hierarchical Multi-label Text Classification,HMTC)方法进行总结和讨论.HMTC具有广泛的应用场景,比如国际专利分类[8,9]、产品注释[10]、Web网页分类[11]、问答系统等,同时它也可以应用于蛋白质功能预测[12]等可以用文本进行表示的场合.近年来围绕HMTC取得了许多的研究进展.有些工作专注于分类器设计,有些则针对文本表示进行研究.从如何利用预定义的层次结构信息可以分为局部方法、全局方法和混合方法;从利用的算法可以分为传统机器学习方法和深度学习方法.本文将对这些方法进行梳理、比较和讨论.
本文的后续内容安排如下:第2节给出层次多标签文本分类的相关概念,第3节给出层次多标签文本分类面临的一些挑战,第4节阐述层次多标签文本分类的研究现状,第5节分析常见的数据集和评估指标,第6节给出展望,第7节给出总结.
2 基本概念
2.1 分类问题
2.1.1 二元分类(Binary Classification)
对于一批样本X={X1,X2,X3,…,Xk},确定它们对应的标签L={L1,L2,L3,…,Lk},其中,|Li|=1,Li∈{l1,l2},其中k表示样本数目.
2.1.2 多类分类(Multi-Class Classification)
对于一批样本X={X1,X2,X3,…,Xk},确定它们对应的标签L={L1,L2,L3,…,Lk},其中,|Li|=1,Li∈{l1,l2,l3,…,lm},其中k表示样本数目,m表示的是标签总数目.
2.1.3 多标签分类(Multi-Label Classification)
对于一批样本X={X1,X2,X3,…,Xk},确定它们对应的标签L={L1,L2,L3,…,Lk},其中,|Li|=n,1≤n≤m,Li∈{l1,l2,l3,…,lm},其中k表示样本数目,m表示的是标签总数目,n表示的是每个样本的标签数目.
2.1.4 多输出-多类分类(Multioutput-Multiclass Classification,或者Multi-Task Classification)
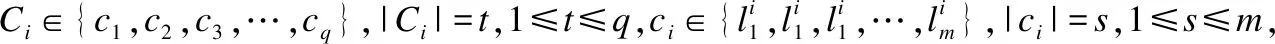

表1 对L个目标变量(标签),每K个值Table 1 For L target variables(labels),every K values
2.2 层次分类
2.2.1 层次结构(Hierarchical Structureγ)
文献[13]给出了层次分类的定义:基于树形结构的规则概念层次上偏序集(C,),其中C代表的是一个定义在应用领域中类概念的有限集,代表的是“IS-A”的关系,在该文献中作者将其认为是反自反的、传递的,但文献[4]添加了反对称这一特性;另外文献[14]在给出层次结构时,添加了补充说明,对于给定的层次结构H中C={C1,C2,C3,…,CH},其中Ci={c1,c2,c3,…}∈{0,1}|ci|,其中Ci代表的是层次结构H中第i所层的可能的类标签,而|ci|表示的是该层可能的标签的数目.综合这3方面的定义,可以给出层次分类的定义如下:
层次分类体系的树形结构中有且只有一个最大值为“R”的根(Root);
反对称:∀ci,cj∈C,ifcicjthencj≮ci;
反自反:∀cj∈C,cj≮cj;
传递:∀ci,cj,ck∈C,cicjandcjckimplycick;
2.2.2 层次多标签文本分类(Hierarchical Multi-Label Text Classification)
与多标签分类(Multi-Label Classification)类似,给定一个文档(Document)样本可以有一个或者多个类标签与之对应,不同的是,这些标签是以层次结构存储的[15],层次结构中低的标签受到层级较高的标签的约束[16],层次结构在带来类标签之间层次关系的同时,也带来了计算复杂等更具有挑战性的特点.
根据文献[14],一组文本文档M可以表示为带有期望层次类别的元组形式,X={(D1,L1),(D2,L2),…,(D|M|,L|M|)},其中Di=(w1,w2,w3,…,wn),n表示的是统一的文档摘要表示的单词数目,wi表示的文本文档中第i个单词,而Li={l1,l2,l3,…,lH},表示的文档期望的标签体系,li⊂Ci是在层次结构γ中对应的类标签.
所以有了上一节对层次结构的定义以及本节对文档的定义后,可以将HMC问题描述为,给定一组文档和相对应的层次类别结构,希望找到文档D对应的层次结构γ,通过训练数据学习一个模型Ω,用于预测未见过的文档层次类别L,上述表述可以形式化定义为:
Ω(D,γ,θ)→L,其中θ是模型Ω要训练得到的参数.
2.3 HMTC问题的处理过程
HMTC问题中涉及到数据集获取、文本预处理、文本表示、特征降维、层次结构标签表示、分类器设计、结果输出等工作,其中文本预处理、文本表示、特征降维、层次结构标签表示、分类器设计比较重要.
1)文本预处理:文本预处理是处理文本分类任务的重要过程,通过文本预处理可以抽取文本中的重要信息[17],去除不必要的内容.文本预处理的一般步骤是固定的,包括分词(一般英语单词已经分词,而对中文需要进行分词)、词干提取(去除单词的不同词性表示,得到一致的单词表示)、删除停用词等.
2)文本表示:文本是非结构化数据,而拟合训练的模型输入一般需要的是结构化数据,所以在上面的文本预处理阶段后,一般采用以向量的形式来表示文本,准确的向量文本表示可以在很大程度上提升模型的效果.常用的文本向量化的方法主要有两种:第1种是离散的表示,常见的有独热编码(One-Hot Encodding)、N-Grams模型等;第2种是分布式的表示(Distributed Representation),比如有BERT[18]、Word2vec[19]、Dov2vec[20]等等.
3)特征降维:由于向量空间模型来描述的文本向量通常具有较高的维度,这对于后续的分类任务来说,将带来效率低下和精确性下降的危害.在文本分类中,特征降维可以分为基于特征选择(Term Selection)和基于特征提取(Term Extraction)的方法.
4)层次结构标签表示:由于HMTC问题对应的标签体系是存储在层次结构中的,所以越来越多的混合方法[6,14,16]不仅考虑了文本提供的信息,也对层次结构标签进行了相应的表示,未来的方法也将会越来越重视标签的表示来提高模型性能.
5)分类器设计:由于层次结构标签体系下,标签之间具有结构关系语义,因此,其分类器的设计也与一般的分类器不同,本文将重点对分类器的设计进行讨论.
3 层次多标签文本分类面临的挑战
3.1 合适的文本表示方式
文本一般是非结构化或者半结构化数据,而分类模型的输入一般是结构化的向量或者张量等,所以怎样将文本进行编码表示,以尽可能保留文本中单词和单词、单词和句子以及句子和句子的顺序和语义关系信息是文本分类的第一步,也是很关键的一步.
3.2 层次标签结构语义表示
在层次多标签文本分类中,标签之间具有的天然层次依赖关系,例如父-子关系、祖先-后代关系等,这些关系有着不同权重的依赖,它们也叫做标签的层次约束(Hierarchical Constraint)[21],文本和这些标签具有不同层次不同的关联如何利用它们之间的关系以及标签之间的关系是一个挑战,以树或者DAG结构进行建模是目前普遍使用的方法.不过,这些方法相对简单,对标签之间以及文本和标签的复杂语义关联刻画并不充分.
3.3 缺乏合适的评估指标
3.4 数据集倾斜问题
HMTC任务中,很多会有这样的现象,即存在一些标签、一般在层次标签结构的底层或者叶子节点处,数据集中的对应样例很少,因此,有数据分布倾斜的问题,导致分类器很少学习到这些标签的特征,从而很少预测甚至不预测这类标签.层次多标签文本分类中数据集倾斜的问题尤为严重,怎样解决和处理这个问题是个难点.
3.5 分类器的设计
分类器不仅要关注于文本的层次关系,而且要关注不同层次不同标签和文本的关系,分类器如何利用文本的层次关系以及文本和标签之间的关系,利用的程度有多深,这些都是需要研究的难点,当然这也取决于具体的任务.
4 层次多标签文本分类器研究现状
根据是否利用层次类标签信息以及如何利用层次信息,可以将层次多标签分类算法主要分为非层次方法和层次方法:非层次方法又可以叫做平面方法;层次方法主要可以分为3种,分别是局部方法、全局方法以及它们的组合—混合方法.
4.1 平面方法
平面方法忽略层次标签之间的依赖关系,将其转换为平面的多标签分类问题,然后再使用多标签分类的方法进行处理,对于层次标签的内部标签节点,以层次约束为准则,任何被归类为子标签的样本都自动被归类于其所有祖先标签节点.
在这种方法中,许多多分类方法都可以应用.例如,文献[9]使用了朴素贝叶斯(Naïve Bayes,NB)、K-Nearest Neighbors(K-NN)、支持向量机(SVM)等这些传统机器学习进行平面分类.
在平面方法中,分类器的设计不是重点,许多工作集中于如何对文本信息进行表示上.传统的模型一般使用词袋(Bag-of-Words)或者预训练向量作为输入,而文献[22]以文本的独热(One-Hot)向量表示作为输入,然后设计了以两个不同深度神经网络,分别是Seq-CNN和Bow-CNN,来进行一维CNN卷积运算,获取文本的局部特征用于后阶段的文本分类;使用一维卷积是考虑了文本中的词序,作者还对CNN框架设置了并行运算,可以学习和组合几种类型的嵌入,它们可以互补得到更高的分类性能.文本训练数据中不是所有单词都对分类有着重要的贡献,所以一个好的关键词提取算法可以提高下游的文本挖掘任务.传统的关键词提取算法大都是基于文本的离散词袋类型的词表示,文献[23]针对这个问题,为平面分类提出一个关键词抽取算法,用于专利分类,该算法基于Skip-Gram模型、K-Means和余弦相似度,其中Skip-Gram模型用于训练模型获取单词的嵌入表示,K-Means算法作为著名的聚类算法用来获取当前的质心向量,余弦相似度用来计算每个候选关键词向量和质心向量的相似度来获取前N个关键词;为了评估抽取关键词的质量,使用SVM提出了一套基于信息增益的评估指标,实验证明,该关键词抽取算法能对专利文档进行有效的分类.
将HMTC问题转换为平面多标签任务是最差的方法,因为它忽略了层次分类中各类别之间的依赖关系,这种依赖关系不仅存在于不同层级之间,也存在于同一层级的不同类之间,平面方法没有考虑这些特点.
4.2 局部方法
局部方法是利用分而治之的思想,将整个分类问题转换成多个局部的子问题,通过解决多个子问题,在层次结构上建立多个局部分类器,最后再将这些分类结果组合起来为全局的分类结果.
根据使用局部信息的不同,局部方法可以划分为不同的策略,主要有LCN(one Local Classifier per Node)[24]、LCPN(one Local Classifier per Parent Node)[25]、LCL(one Local Classifier per Level)[26].它们的结构分别如图3,图4和图5所示.
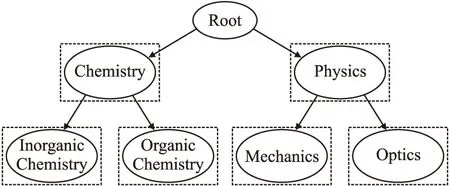
图3 LCN示例图,图中每个圆形代表一个类节点,每个虚线矩形代表一个分类器Fig.3 LCN example diagram,in which each circle represents a class node and each dotted rectangle represents a classifier
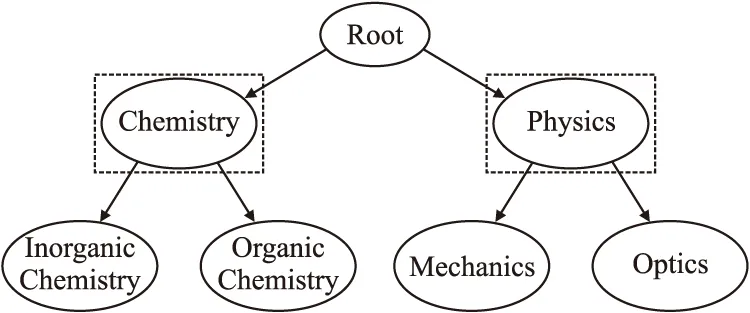
图4 LCPN示例图,图中每个圆形代表一个类节点,每个虚线矩形代表一个分类器,用于预测它们的子类Fig.4 LCPN example diagram,in which each circle represents a class node and each open dotted represents a classifier for predicting their subclasses

图5 LCL示例图,图中每个圆形代表一个类节点,每个虚线矩形代表一个分类器,用于预测每个层级的类别Fig.5 LCL example diagram,in which each circle represents a class node and each dotted rectangle represents a classifier to predict the category of each level
局部方法的3种策略训练的分类器个数不同,另外使用的局部标签依赖信息也不同,比如LCN和LCPN是使用不同层级的关系,而LCL使用了同一层级的关系,但是在测试阶段却都是以自上而下(Top-Down)的范式进行的,即从根节点开始,只有被当前的分类器预测为正的样本才会被传递给其子节点的分类器,依此类推,直至到达叶子节点分类器;需要注意的是,随着类层次向叶子方向移动,错误分类也有着向下传播的风险,除非采取特别的方法进行处理[27],比如对于非强制性叶节点预测,不同层级不同标签设置不同的阈值来阻止分类器向下传播.
4.2.1 传统机器学习方法
1)基于贝叶斯方法
贝叶斯方法是用有向无环图构建一个概率模型网络,网络中的每个节点代表一个变量(特征),若两个节点之间存在边则说明它们之间存在直接的概率依赖关系,否则说明这两个特征是条件独立,即它们之间没有直接的概率依赖,但是这些节点可以通过中间特征来产生依赖关系.贝叶斯分类器的基本过程是通过某样本的先验概率,以贝叶斯公式计算对应的后验概率,选择后验概率最大的或者最大的几类作为最终的分类类别.
文献[28]分析了平面方法无法利用层次信息的缺陷以及以全局方法解决层次分类的计算代价大的问题,提出了利用局部信息在分类树的每个节点上建立一个贝叶斯分类器的模型,属于LCN方法.算法分为两个步骤:先进行特征选择,使用基于齐夫定律(Zipf′s Law)的特征修剪方法减少原始训练集的特征数目,然后根据信息论的特征选择方法确定原始领域特征的子集,接着在每个子任务上建立分类器,最终各个分类器组织为层次结构.在预测的时候,以自上而下的方式进行预测,所以出现错误不可修正[29],文献[30]和之类似,训练多个分类器后使用贝叶斯网络来判断标签的后验分布.
文献[31]提出了层次贝叶斯分类器Hbayes,它为所有层次节点训练一个分类器,并为所有训练样本计算类概率.其分类过程为:先在集合中对所有类进行初始化;然后分类将逐个移除类标签,每次给样本赋予一个给定的类标签,同时,考虑层次约束,样本也会被分配给属于该类和根节点之间的所有路径上的类标签.只有在某个节点是叶子节点或者其子树的所有节点都已经被移除,则可以从集合中移除它,至此集合中剩下的类节点就是为当前样本赋予的类标签.而文献[32]提出它的变体HBayes-CS(HBayes Cost Sensitive),来平衡假阳性和假阴性的错误成本,通过引入一个权重参数实现,此外,HBayes-CS更适合处理倾斜数据集,即数据集中存在层次结构中位于较低层的标签具有较少的实例的问题.
上述的工作都使用了局部的层次信息,但是较少考虑层级之间的依赖关系,文献[33]的改进之处在于对于上层输出概率,会作为附加信息传递给下层分类器,这样从某种程度上利用了层次各级别之间的关系,类似地,分类器使用的是朴素贝叶斯分类器,输入使用文献[34]中的双正态分离度量(BNS)来进行特征选择,然后附加上文档属于父节点的概率;该方法可以很容易扩展到任意深层次,但是若深度太长,会影响特征向量的长度,为了限制长度,可以只包含前一级的概率,即上层的概率只影响到其直接子女的分类.
2)基于多标签分类问题转换方法
基于多标签分类问题转换方法,将层次多标签分类任务按照层次结构进行分解,然后在每个子问题上利用多标签分类,主要方法括二元关联(Binary Relevance,BR)和标签Powerset(Label Powerset,LP).二元关联是将每个标签当做一个单独的二元分类问题,标签Powerset是将训练数据中所有的唯一的标签的组合训练一个多类分类器,显而易见,随着训练数据和标签的增多,标签的组合数目也越来越多,另外,对于在训练数据中没有出现过的标签组合将不能在测试数据中进行预测.
文献[35]中提出了两个局部方法,分别是HMC-LP和HMC-CT,HMC-LP基于标签交叉[36]的LCL方法,对于每个示例样本,在特定的层次上将所有的标签组合成新的唯一的标签,组合过后就可以将问题转变成层次单标签问题,然后自顶向下进行训练,在预测时恢复原来的多标签分类.可以看出,这种方法横向考虑了同级类之间的关系,但是不同的标签组合会大大增加类的数量,而有些类的组合可能只包含很少的样本.HMC-CT是基于交叉训练(Cross-Training)方法[37],它在训练时会多次使用多标签数据,将每个样本作为其所属的每个类别的正例使用,这会避免出现使用LP策略可能出现的数据稀疏问题,因为它使用了可用于每个模型的所有相关数据.在此过程中,对于每个样本,每个可能的类都被视为序列中的正类,在训练阶段多次使用多标签数据,这种方法会大大增加训练时间和计算成本.该篇文献中还对比了HMC-BR,对层次树中的各个节点训练二元分类器,属于当前类的是正例,而其他都是负例,忽略了类之间的关系,所以泛化能力较差;上述方法都采用支持向量机(SVM)进行分类,文献[38]扩展了文献[35],使用了不同算法作为基分类器.可以看出,上述方法部分考虑了层次关系,或从横向考虑,或纵向考虑,这也是总体上局部方法性能优于平面方法的一个原因.
3)基于集成方法
集成方法,是把多个弱分类器整合成一个强分类器的方法,值得注意的是,不是所有集成学习都能提高整体的泛化能力,一般需要满足两个条件:一是分类器之间应该有差异性;二是每个分类器的精度必须大于50%.
文献[39]提出了TREEBOOST.MH,它是ADABOOST.MH[40]的变体.TREEBOOST.MH针对层次结构中的非叶子节点各自生成分类器,所以首先确认是否到达叶子节点,如果未到达,则先递归地将层次结构划分为以当前节点为根节点的子树,然后对训练数据进行特征选择,得到简化的特征集,接着运行ADABOOST.MH算法,最后对递归得到的子树执行这个过程,从而生成一个分类器树.经过实验证明,TREEBOOST.MH的计算成本比ADABOOST.MH要低,并且宏观平均有效性更高,这得益于该算法在训练时局部地选择约简的特征集,有利于处理倾斜分布的数据集.
文献[24]以集成方法,提出了真路径集成(True Path Rule Ensemble,TPR),作者将层次分类问题转换为路径预测问题,每个局部分类器都会对给定样本作出各个类别的预测,在集成阶段,从自上而下和自下而上两个方向上传递不对称的预测信息:对一个类别的正预测向上影响祖先,负预测向下影响后代,这是基于树形结构层次约束的事实,一个样本属于一个类别就必定属于其所有祖先类别,而若不属于一个类别就必定不属于其所有后代类别,以这种TPR的方式考虑层次关系,最终得到一致的总体概率.文献[41]和文献[42]对TPR方法添加了一个调整类和其后代预测之间的关系,在父类使用了一个父亲权重参数wp,wp的取值范围为0到1,按照wp的比例划分局部分类器和其后代分类器之间的重要程度,越接近1越重视局部分类器.文献[43]和文献[24]类似,将问题建模为基于路径选择(Based on Path Selection,BPS)的方法,BPS为层次标签树的内部节点每个训练一个分类器,以含有其兄弟节点标签的数据集作为负例样本,用于路径的裁剪,解决可以预测内部节点的问题,该方法根据路径得分,选择层次树中的一条或者多条路径.
集成方法可以在不需要提出更高性能分类器的情况下,使用几个弱分类器能够获得较高的分类效果.这是在得不到非常好的分类器的情况下不错的选择.
4.2.2 深度学习方法
随着深度学习的蓬勃发展,越来越多的研究者转向神经网络,HMTC任务也不例外.
文献[7]中提出了HMC-LMLP模型,是针对树形结构的LCL的局部方法.该模型在各个层级上都训练一个多层感知机(Multi-Layer Perceptron,MLP),每个层级的输出是该层级的预测向量,所以该输出层的神经元的个数为当前层级的类别的总数,作为下一个MLP的输入,利用了上一层提供的信息,直到最后一个汇集整个层次结构的预测,其中第一层是对文档的特征向量化.通过使用LCL策略,可以在使用局部信息的时候避免全局方法和局部方法的缺陷,由于文档的特征只在第一层会被作为输入,会导致特征被稀释,从而出现预测不一致[4]的情况,这不同于混合方法[4,5,16]的通过重复使用输入特征,所以作者提出的后续处理不一致的策略是直接将没有预测超类的预测类别移除;另外,和LCN和LCPN相比优点在于没有划分为大量的子问题,避免丢失很多重要的局部信息[4].
由于传统方法和深度学习方法都有各自的优势和缺点,所以文献[44]针对新闻分类问题,在浅层以CLR(Calibrated Label Ranking)策略构建多标签分类任务,使用朴素贝叶斯方法进行训练,深度学习方法以二元相关(Binary Relevance,BR)策略构建,使用CNN训练;以Word2vec和Glove作为词嵌入表示(语义),然后乘以词干频率(词义)来结合单词和句子之间的关系,这种方法关注了文本的层次结构(单词和句子之间).
局部方法的缺点在于随着层次结构加深和类标签的增多,计算成本明显提高,并且依赖于级联分类器,更适合从类层次的区域中获取信息,会最终导致过拟合;优点在于没有预测不一致的问题等.
4.3 全局方法
全局方法利用整体的信息,在层次结构上只建立一个分类器[4]来同时处理所有的类别.大多数全局方法是基于平面方法修改得来的.近年来,全局方法大部分是以神经网络实现的,当然也有基于传统机器学习方法的,所以本节从这两种大类入手.
4.3.1 传统机器学习方法
1)基于决策树方法
决策树以树形结构为架构,在面对分类问题时,通过信息增益或者信息增益比等以各个特征对实例样本进行分类的过程,即通过树形结构的模型,在每一层上对特征值进行判断,递归到叶子节点的决策过程.
C4.5[45]算法原本是平面的决策树算法,不能用于层次分类,而文献[46]提出的HMC4.5方法,基于C4.5对计算类熵的方法进行了修改:在C4.5原始的算法中,每次都是选取信息增益比最大的属性作为当前分类的子树根节点,但是HMC4.5使用所有类的熵的和,相当于描述属于一个示例的所有类的信息量之和.该模型将整个层次归纳为一个决策树,归纳过程较为复杂,但是会生成一组简单的规则.
预测聚类树(Predictive Clustering Trees,PCT)是决策树的推广,通过对标准的决策树自顶向下进行贪婪归纳而得到,文献[27]基于PCT提出了Clus-HMC,决策树被自上而下划分为簇状结构,每个簇包含相应训练样本,以加权欧氏距离来关注层次依赖,即认为处于层次结构更深层次的类比更高层次具有更多的信息,因为处于层次结构越深处,其信息越具体,所以权重随着深度的加深而降低,另外作者还将结构从树形结构推广到了DAG结构.
基于决策树的方法的优势在于具有很高的可解释性,对样本作出的决策易于理解,但是缺点在于会归纳出过于复杂的规则,所以一般需要对决策树进行剪枝,以提高泛化能力,对于更深的层次结构和更多的类别而言,会提高计算代价.
2)基于集成方法.
文献[47]中,提出了一个由Clus-HMC[27]为基础引入决策树的集成来改进HMC,即Clus-HMC-ENS,该模型利用Bagging机制[48]在训练数据中进行复制(Bootstrap),从而为每个复制版本训练一个分类器.预测的结果由目标值结合而成:如果是回归问题,则求平均值;如果是分类问题,则由投票得到.
文献[49]将基因功能注释看做文本分类问题,并考虑层次结构上的语义,文中提出一个基于AdaBoost.MH[40]的全局方法,该方法针对DAG结构采用非强制性叶节点预测(NMLNP):先对文本数据进行预处理,然后结合AdaBoost.MH进行数据集上的规则学习,最后对样本进行测试且对预测不一致进行处理:对不一致的节点,考虑其所有祖先类的预测置信度,如果它们的置信度足够高,那么就将其所有祖先类来标记实例,否则去除掉该不一致的类标记.此外,作者提出了3个指标来弥补使用“平面”评估指标的弊端,分别是hierarchical-Precision(hP)、hierarchical-Recall(hR)、hierarchical F-measure(hF),这些同样也在文献[6]中被提到,将在后面详细说明.
4.3.2 深度学习方法
1)基于图的文本表示(对文档和标签结构使用图的表示)
对于文本表示,传统的方法只是简单地使用词袋模型;对于层次多标签文本分类来说,每个文档具有多个不同层次的主题标签,词袋模型可能就不够了.而深度学习模型已经被证明能够有效地获取低级别的特征和高级别的特征.例如,文献[50]以Word2vec为基础作为模型输入,然后使用不同大小的窗口作为特征提取器进行卷积运算,得到不同层次的文本表示.
RNN只能在短文本上捕捉语义,而CNN类似于N-Grams,只能在单词上建模,文献[51]使用了单词图(Graph-of-Words)来获取文本中非连续和长距离的语义.作者提出的HR-DGCNN模型首先对文本以词共现矩阵将文本转换为图,然后使用Word2vec进行图嵌入,类似图像一样进行交替卷积、池化操作,最后通过全连接层进行分类预测.模型中以递归正则化(Recursive Regularization)来利用标签之间的层次关系,将递归正则化和网络模型最后的交叉熵函数共同加权作为损失函数,在全局的层次上考虑层次关系;为了减少模型的复杂度,采用递归层次分割将原始问题转换为多个子问题,从而降低整个问题的复杂度.模型整体上没有改变基于CNN的本质,是将文本表示成图来进行处理,而且文本的图表示的边是无权边,可以对其加上权重来表示不同单词的之间的不同权重关系.
文献[52]也把文本建模为图结构,这和文献[51]类似,使用随机游走生成标签的序列,接着使用Skip-Gram训练得到标签的嵌入表示,提出基于标签相似度的权重损失函数来捕捉标签之间的依赖关系,通过优化这个损失函数,保持标签之间的依赖关系.文献[53]通过共现矩阵将文本转换为图表示,而标签结构是自然的树形结构或者DAG结构.
2)基于注意力机制(Attention Mechanism)
注意力机制(Attention Mechanism)[54]就是把注意力放在重要的信息上,在文本分类情境下,就是将和层次结构各层最关联的文本内容利用注意力机制,对文本语义表示的不同部分分配不同的权重来突出实现的.
文献[53]在将文本和标签使用图表示后,将文本以BERT和双向GRU进行上下文语义信息抽取,并通过多头注意力机制,将标签的图表示作为查询,文档作为键值对,让标签的层次信息融入到文本表示输出中,抽取文本的不同部分和标签层次中各个层次、各个类别之间的关系信息,在作者使用的90多万的中文数据集上获得了很有竞争力的结果.
文献[55]使用双向LSTM将文档转换为向量表示,在每层基于注意力生成不同的动态表示,这种想法在混合方法[6]中得到了更广阔的应用,以多层感知机来预测当前层次的级别.动态生成的各个层级的文档表示不仅能够提高模型的性能,同时提供了额外的可解释性;此外,还以主题类别分类法的形式使用了外部知识.
注意力机制除了可以对不同层级的文本表示之外,还可以通过编码器的堆叠提取深层次的文本特征,文献[56]将金融事件检测建模为一个层次多标签文本分类问题,提出了F-HMTC的模型,模型由嵌入网络和标签预测网络组成,嵌入网络的输入类似Transformer,由Token和位置信息连接组合而成,然后通过多个编码器的堆叠,最后输入到标签预测网络.对标签的依赖是以基于距离的度量HMD和文献[51]相同的递归正则化来实现的,损失函数为这两个部分的加权之和.
文献[52]分别在文本的单词级、句子级和子图级上使用多头注意力的Transformer,这种层次的Transformer能够捕捉文本中不同部分的语义信息。
上述的几个模型建模期间没有考虑标签的依赖关系,而是根据最后的损失函数以不同的优化项来体现层次结构的,这当然也是一种方式,混合方法[5,6,14]是在建模中显式考虑了层次依赖,局部方法[24,41]也是以显式的方式考虑的.
3)其他网络
文献[12]提出了一个新的基于竞争人工神经网络(MHC-CNN)的全局分类器.竞争网络的特征之一是实现从输入空间到输出空间的映射,并且能够保持各自的拓扑结构,其中学习过程基于竞争学习[57].在MHC-CNN中,输入层连接到输入向量数据集,处理层也叫作输出层是一个网络拓扑结构,对应于DAG层次结构,其中每个神经元和其祖先(父亲)和后代(孩子)神经元相连;此外,输出层中的每个神经元都连接到输入层的所有神经元.与传统的竞争网络一样,将训练过程分为3个阶段:竞争、合作和适应;在竞争阶段,根据输入实例的类的数量,分类器根据输入向量和每个输出神经元权重向量的欧式距离,选择最小相应数量的“赢家”;在合作阶段,“赢家”倾向于更新其邻域的神经元的权重,在该算法中,邻域标准是通过当前神经元和其祖先及后代之间的层次关系确定;最后在适应阶段,与期望输出对比,对于正确预测时,将调整输出权重,使得更接近实例;对于预测错误时,权重将被更新到距离实例更远的地方;不断迭代这个过程,直到选择所有实例.
另一种网络结构叫做胶囊网络,文献[10]将胶囊网络(Capsule Networks)[58,59]第1次应用在HMC任务上,胶囊的一大特点就是通过将每个胶囊和层次结构中各个标签节点相关联来为各个节点进行编码,然后组合各个胶囊独立的编码特征进行分类,从而获得比之前的方法更好的效果,这是因为父节点和子节点会共享类似的特征.胶囊的这一特点也让传统的分类器很难获得父-子节点的这种关系,从而会出现预测出错的情况,特别是在训练样本中未出现特定父-子标签组合的情况下.胶囊网络的第1层被称为初级胶囊,接收来自卷积层或者循环网络的隐藏状态作为输入.第2层被称为分类胶囊,其输入是初级胶囊的预测向量的加权求和,这些权值是由动态路由启发式(Dynamic Routing Heuristic)算法[58]计算而得.路由机制与最大池化类似,不过后者关注最突出集中的特征而会忽略其他特征,而前者在关注突出的特征的同时也不会忽略其他特征,从而提高了组合和概括信息的能力,这一特点也让路由算法在HMC问题中对出现次数较少的父-子节点关系得到更好的层次分类,实验结果也表明胶囊网络比CNN和LSTM性能更好,标签层次信息也被直接应用于在预测阶段执行标签校正(Label Correction).
全局方法的优点在于计算代价通常比局部方法低,并且没有局部方法存在的错误传播问题,因为在预测时每个分类器的都是在上个标签被预测为正才会被启用,缺点在于不能从层次结构中获取信息,可能导致欠拟合.对全局方法的总结如表2所示.

表2 对全局方法的总结Table 2 Summary of global approaches
4.4 混合方法
为了结合局部方法和全局方法的优势,可以在利用层次结构局部信息的同时也利用全局信息,最后对这两部分进行统一处理,这类方法叫做混合方法.目前,大多数混合方法是基于神经网络的.
文献[5]提出的HMCN的混合模型,是第一个结合局部和全局信息进行层次分类的基于神经网络的HMC方法,可以适用在树结构或者DAG结构,它有两个版本,分别是前馈版本HMCN-F和递归版本HMCN-R,二者的主要区别在于前者需要训练更多的参数,而后者因为在层级之间共享权重矩阵并且使用类LSTM结构对层次信息进行编码,在关联相邻层次结构的同时也减少了需要训练的参数,并且随着层级越多递归版本的优势越大.在标签层级结构的每一层都会输出局部预测以及最后的全局预测,而最终的预测是各个局部预测的连接以及全局预测的加权组合而成;此外,各层的输入结合了上层的激活和重用输入特征,从而在原始特征和给定层级之间建立紧密的联系;对于预测不一致的情况,则通过在优化局部和全局损失函数的同时加上惩罚层次违规来保存预测遵循层级制约.与HMC-LMLP、Clus-HMC相比,HMCN同时利用了局部和全局信息,所以它是一个混合方法.
针对文献[5]中提出的HMCN没有对文本进行有效的词嵌入、没有考虑文本和层次标签结构的关系等问题,文献[14]基于注意力机制提出了一个递归神经网络模型HARNN以处理树结构的层次类型.该模型先对文本和层次结构进行预训练嵌入表示,然后对文本表示以双向LSTM进行增强表示;基于注意力机制的递归层(HARL)是该模型的重点,以自上而下的方式将文本和层次结构每层类标签的依赖关系以注意力建模,限制每个单词和每层各个类别的贡献,并且文本类别相关信息也会影响到下一个类别,这就考虑到了文本表示和层次结构的关联以及层次结构中不同层次的关系;对于类别预测,与文献[5]类似,最终的预测由每层的局部预测和全局预测加权集成,由于该模型在HARL中考虑了层次之间的依赖,所以在损失函数中没有考虑类别依赖关系.
模型HARNN是基于文本的典型注意力来实现的,和层次结构的多个层次关联,而不同层次的注意力是不同的,所以这样做会导致文本的相关特征被稀释,另外局部和全局使用了相同的文本嵌入.文献[6]为了解决这些问题,提出了基于标签的注意力机制的模型LA-HCN,从各层标签出发建模与文本的关联,文本-标签的依赖在层次之间共享,可以基于不同的标签来捕获文本的重要信息,而HARNN只能抽取到前一层的信息,所以对下层重要的信息可能由于和上层信息不那么重要而会被忽视,从而在下层时捕捉不到.对于文本和层次标签的关系,模型引入组件(Component Mechanism)机制,有助于在标签和文本单词之间建立潜在的联系;另外,该模型在局部和全局的分类器使用不同的嵌入表示,从而减少了错误传播的问题.除了LA-HCN对层次特征进行了抽取之外,文献[60]也基于文档结构(即从单词到句子)而不是标签结构来提取层次信息,接着进行后续的文本分类任务,文献[61]除了使用BERT为基础模型外,其他和HAN类似.文献[62]基于NMF-SVM(Non negative Matrix Factorization-Support Vector Machine)抽取文本的层次特征,在深度学习模型中生成相应的词向量,使用基于句间亲和度文本注意力机制SEAM与词向量生成新的矩阵表示,作为深度模型的输入,经过卷积运算后全连接进行分类.
不同于上述的基于深度神经网络的监督学习方法,文献[63]将层次文本分类视为马尔可夫决策过程,为了解决训练和推理之间的不匹配问题,也能更好地对标签的依赖性进行建模,提出了一个新颖的基于深度强化学习的模型HiLAP,它可以结合不同的神经编码器作为端到端的基础学习模型,然后在强化学习的策略网络(Policy Network)中采取行动、奖励以及更新状态来将对象放置在标签层次结构中的适当位置来标记对象,通过学习标签分配策略以确定在哪里放置(Where to place)对象以及何时停止(When to stop)分配过程.
除了上面提出的各种模型之外,腾讯[64]还推出了一个开源的NLP的深度文本分类工具包,叫做NeuralClassifier,它提供了多种文本编码器,比如FastText、TextCNN、Transformer等;主要分为4层,包括输入层、嵌入层、编码器层和输出层.输入层将输入的单词序列组织处理成单词、字符或者N-Gram,嵌入层处理各种嵌入,可以选择的嵌入有4种,分别是随机嵌入、预训练嵌入、区域嵌入[65]、位置嵌入(Position Embedding)[54],其中位置嵌入是Transformer中提出的考虑输入序列位置信息的嵌入方法.输出层对于层次标签的依赖,使用递归正则化将层次依赖合并到参数的正则化结构中,从而鼓励层次中比较接近的类节点共享相似的模型参数.对混合方法的总结如表3所示.

表3 对混合方法的总结Table 3 Summary of hybrid approaches
混合方法结合了局部方法和全局方法的优点,越来越得到研究者的欢迎,但是由于如今的方法很多都是基于深度神经网络来实现的,所以可解释性和可视化能力不够,这需要更多的研究.
5 常用数据集和评估指标
5.1 常用公开数据集
本文搜集了一些用于层次多标签文本分类研究的公开数据集,其基本信息如下:
1)BlurbGenreCollection(BGC)[10](1)https://www.inf.uni-hamburg.de/en/inst/ab/lt/resources/data/blurb-genre-collection.html:是作者收集的由书籍介绍以及层次结构的写作题材组成,共有91892个文本,4个层级,146个类别,4个层级分别有7,46,77,16个类别.
2)WOS-11967(Web of Science)[66]:由Web of Science发表的论文的摘要组成,共有11967个文本,两个层级,40个类别,两个层级分别有7,33个类别.
3)WIPO-alpha(2)https://www.wipo.int/classifications/ipc/en/ITsupport/Categorization/dataset/index.html:共有4个层级,5229个类别,4个层级分别有8,114,451,4656个类别.
4)Enron[67]:是一个邮件的语料数据集,共有3个层级,56个类别,3个层级分别有3,40,13个类别.
5)Reuters[68]:是由路透社提供的人工新闻分类数据集,有超过800000条的数据,共有3个层级,101个类别,3个层级分别有4,55,42个类别.
6)中文新闻数据集[53]:是作者收集得到来自电视台的真实新闻稿件,该数据集包含932354条文档,共有3个层级,683个类别,3个层级分别有13,163,507个类别.
5.2 评估指标
对于层次多标签文本分类的评价指标来说,很多研究者使用了平面方法的评价指标,这些指标并不能体现这个问题的特点[4].本文总结了研究者提出并使用地较为广泛的针对层次分类的评价指标.
首先是针对传统的平面多标签分类所使用的精准率和召回率以及汉明损失.
1)精准率(Precision)[27],对于给定类别i∈C,其TPi,FPi,FNi分别表示混淆矩阵中的真阳性、假阳性、假阴性的数量,Precision见公式(1):
(1)
2)召回率(Recall)[27],各种变量的解释同Precision,其Recall见公式(2):
(2)
3)汉明损失(HammingLoss)[69],汉明损失越低,模型的效果越好,汉明损失见公式(3):
(3)
其中,N表示文档个数,q表示每篇文档的标签数,Z,Y分别表示一篇文档的预测和真实的标签集合,而运算符Δ表示的是二者集合的对称差.
下面的是层次评估指标,对于预测类别和实际类别处于层次中不同位置予以不同的关注,从而考虑了标签的层次结构的特性,分别有hP、hR和hFβ.
4)h精准度(hierarchical-Precision,hP):
文献[5]提出了hP、hR、hF3个指标.简单来说,就是对部分正确的分类给予信任,对距离更远的预测错误更大的惩罚,对更高层次的预测错误更大的惩罚,hP的值越大,说明模型预测为真的样本更多的为正例.见公式(4):
(4)
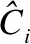
5)h召回率(hierarchical-Recall,hR):
hR的值越大,说明模型将更多为真的样本预测正确,h召回率见公式(5):
(5)
6)如上而言,hP和hR分别从真实样本和预测为真的样本出发,考虑不够全面,所以有指出可以将二者结合起来,就变成了hFβ,见公式(6):
(6)
一般,将β取为1,表示将hP和hR赋予同等重要的权重,这也是大多数研究中缺省设置的参数值.
虽然在很多应用场景中,没有一个评估指标可以被认为是最好的,但是hP、hR和hF可以在大多数情况下表现良好,在文本分类任务也是不差的.它们不仅可以运用于树形结构也可以用于DAG结构,但是文献[4]指出了hP和hR的一些问题:分别是泛化错误(Generalization Errors)和特定化错误(Specialization Errors).这两种错误是对于非强制性叶节点预测而言,前者表示的是预测的类别比真实类别更一般的情况,即预测的层次结构更浅,这对于一个固定的预测类别,泛化错误越大(即真实为更深的类别),hR值越小,hP值则不变,后者表示的预测的类别比真实类别更具体的情况,即预测的层次结构更深,这对于一个固定的预测类别,特定化错误越大,即预测更深的类别,hP值越小,hR值则不变.
6 展 望
未来的需要继续突破的研究方向主要包括下面几点:
1)分类器的设计.本文的重点在于关注文本分类器的设计,在此过程中如何利用文本和各层标签的关系、如何利用层次标签的依赖关系是考察分类器优劣的一个重要方面,这也是本文划分层次方法的依据,只有在具体的任务中较为精准地抓住上述的关系,并在标签预测时,将这些关系进行有机的利用是一个难点,也是未来的一个重要研究方向.
2)寻找更好的文本编码表示.文本分类和其他分类的一个很大区别在于,因为文本一般是非结构化或者半结构数据,如何将其表示并能够较少地损失其原来蕴含的信息,这对后续的文本分类来说很重要,当然,Transformer和BERT是两个目前效果较好的语言模型,也可以寻求其他方法来表示文本,比如文本的图表示等.但是这些表示都是通用的表示方法,而什么样的编码表示更适合于层次多标签文本分类还有待进一步研究.
3)极端的层次多标签文本分类问题.随着应用的深入,不少应用面临极端的层次多标签文本分类任务.它的特点是层次标签的数目非常多,层次级别也非常深,造成模型规模可能非常庞大,目前的计算能力难以处理.如何高效地处理极端层次多标签文本分类问题将成为未来的一个研究方向.
4)现实数据集中标签的长尾问题.在现实数据集中,大部分标签的数据是相对较少的,即很少的数据和一些标签关联,甚至没有数据关联,特别在层次结构的底层靠近叶子节点处.长尾问题在极端的层次多标签文本分类问题中尤其严重.这种情况对于模型学习将造成困难,可能导致无法预测的问题.因此,如何处理层次多标签文本分类中的长尾问题,也是未来的一个重要研究方向.
7 总 结
本文对层次多标签文本分类的相关概念做了总结,分析了层次多标签和普通多标签分类问题的区别和联系,以及这些区别所带来的挑战;接着从不同的角度对层次多标签文本分类的研究现状进行了阐述,将分类方法主要分为非层次方法和层次方法,非层次方法忽略预定义的层次标签给出的标签之间的依赖关系;层次方法根据使用层次信息的不同分为局部方法、全局方法和混合方法,它们利用层次信息的程度逐步加深,然后对于这些方法下依据使用不同的技术进一步划分,这些方法里面有的是对分类器进行了着重研究,有的是关注于文本的嵌入表示,还有的强调对标签结构关系的有效利用,最后本文对本领域常用数据集和评估指标进行了说明,并对未来的研究方向进行了展望.
猜你喜欢
计算机时代(2022年9期)2022-11-03
现代电子技术(2022年15期)2022-07-28
电子产品世界(2022年4期)2022-04-21
少儿画王(3-6岁)(2020年4期)2020-09-13
东方教育(2018年20期)2018-08-22
软件导刊(2017年4期)2017-06-20
科技创新与应用(2017年3期)2017-02-18
电脑知识与技术(2016年25期)2016-11-16
无线互联科技(2015年11期)2016-03-04
企业导报(2015年9期)2015-05-18
