
基于深度挖掘技术的ERP 系统数据录入误差检测方法
2022-05-06 13:32孙利民
电子设计工程 2022年8期
孙利民
(河钢集团有限公司,河北石家庄 050000)
ERP 是一种先进的集成计算机信息系统,在ERP 环境下,通过深度挖掘可以实现对内部控制系统的深入分析。ERP 按照国内通用标准能够控制和计算误差检测,但内部通用控制标准、控制方式需提前制定。然后通过数据控制中心和应用程序系统的嵌入模式设置,可进一步实现对数据信息的实时控制[1-2]。
目前,相关学者提出的数据深度函数种类较多,主要有空间深度、单纯深度等。在这些深度计算函数中,空间深度由于在计算方面较为复杂而在ERP系统中被广泛应用。在单纯深度中,数据深度不会随着数据值的增大而增大,此时就必须注意数据录入误差等问题。
为此,该文基于深度挖掘技术研究了一种新的ERP 系统数据录入误差检测方法。在ERP 系统中定义数据参数值时,聚类数量、聚类中心属性维数及样本数据节点采用标准的计算方法,聚类对比采用云分析的采样方式,ERP 系统中每一个类簇的点数据在不能使用的情况下可进行自适应匹配,在ERP 环境下,数据控制系统分析处理数据的作用日益突出,因此,应注重信息控制系统的有效性、可靠性和实时性。同时,在深入挖掘过程中,控制中心需及时地将关键信息输入云端数据库[3]。ERP 系统通过系统本身的数据分析仪和集中控制器对数据进行自动校验、核对、判断和监控,从而完成对深入挖掘误差数据的实时跟踪和控制。
1 ERP系统数据分类
在ERP 工作环境下,决策者和执行者能够快速交流深度挖掘的系统程序,使挖掘过程中存在的控制层级减少,降低施工以及数据计算的难度[4]。
ERP 工作环境下的深度挖掘过程如图1 所示。
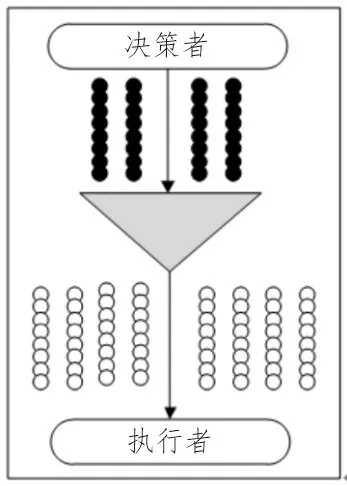
图1 ERP工作环境下的深度挖掘过程
在传统的数据误差检测方法中,通常由ERP 环境中的信息处理系统自带的功能所控制[5-6]。但观察图1 可知,ERP 工作环境下的深度挖掘过程减少了重复性的工作量。
在ERP 环境下,深度挖掘的整个挖掘流程以及数据检测流程通常是实时控制的核心,在很大程度上控制系统做到了对整个工作流程的实时控制。在ERP 作用下,深度挖掘技术的存在方式发生了变化,从而使得ERP 的信息处理系统与数据录入系统高度融合[7-8]。
信息处理和数据录入的融合过程如图2 所示。
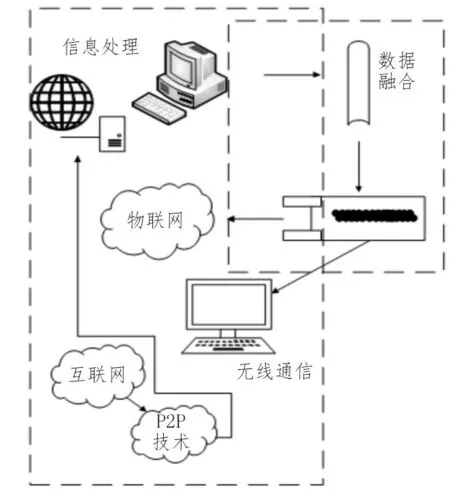
图2 信息处理和数据录入的融合过程
在ERP 系统中,控制数据在深度挖掘数据检测过程的自动化控制中起到了关键性的作用。根据数据处理中心控制过程的实现方式,数据检测的自动化控制通常由程序编码固化控制和数据参数控制构成,程序编码固化控制将挖掘数据嵌入到控制系统源程序代码中,数据参数控制在ERP 系统运行过程中对数据匹配方式和信息系统进行统一控制,然后对比程序编码控制。数据参数集中控制在操作上更方便、灵活,是广泛采用的一种控制系统,其在数据参数控制以及处理信息方面扮演了重要的角色[9-10]。
数据参数集中控制过程如图3 所示。
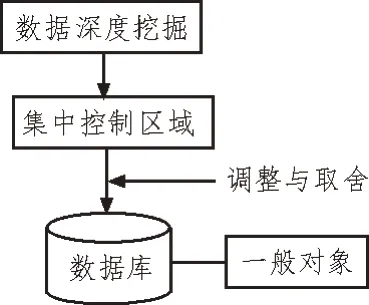
图3 数据参数集中控制过程
观察图3 可知,ERP 系统在操作过程中可对深度挖掘误差数据进行集中设置,也可以在运行过程中进行部分调整和取舍。
根据误差数值的大小,ERP 系统数据可分为布局级控制数据、分级控制数据和分数级控制数据。其中,布局级控制数据适合深度挖掘中遇到的可控性问题,这影响着ERP 系统用户权限实现的全过程,这种控制数据通常稳定性较好且数据较完整,布局级控制数据被设置后,深度挖掘过程中的执行人员必须按照指令执行,其设置的权限通常在ERP 系统的中心管理层[11-12]。分级控制数据主要是对ERP 系统进行有针对性的设置,这种控制数据通常很多,并且在具体执行过程中不会被轻易修改[13-14]。分数级控制数据主要对ERP 中的基础误差数据进行设置,这种控制数据需要深度挖掘实施中的相关资料,但其操作通常较简单。
2 ERP系统数据聚类
ERP 系统在应用时,物体处理中会形成散斑,通过对系统的信息处理使其具有光属性的像素点。但在深度挖掘数据误差过程中,ERP 难以在中心系统中形成散斑,所以在运行过程中也就难以获得该系统中心点的数据参数。
一般情况下,深度挖掘中采集到的数据点通过测量将会得到深度值为1。根据数据变换关系从而计算出他们的具体数值,在采集中心数据时,把测量值为0 的点统称为噪点。ERP 系统数据聚类如图4所示。
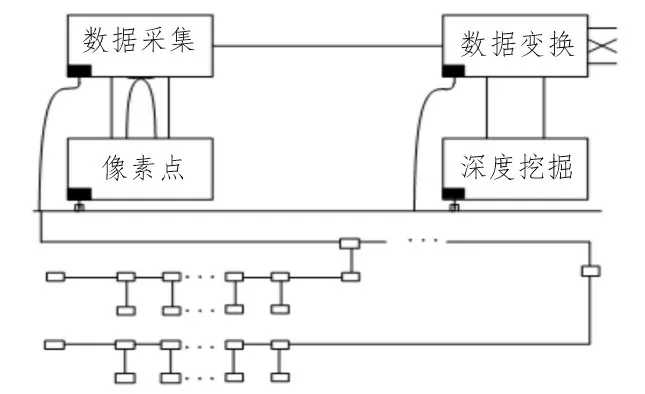
图4 ERP系统数据聚类
当采集云端数据参数时,大部分数据参数在分布时采用多种方式密集分布,ERP 系统的离散点在云端数据库中可形成原始的排列场景,原始的误差数据经过预处理后可采用立体投影的方式将二维数据转换为三维数据,之后可对二维数据的分布进行聚类。当ERP 系统聚类时,集中点的高度要在深度挖掘的最大值和最小值之间,使二维数据能更好地筛选、保存[15]。
ERP 系统的聚类是把深度数据参数通过集中处理嵌入到另一个深度数据参数中,统一划分,其分类方式多样,目前应用较为广泛的是以测量值为测算条件的方法。
在此基础上,数据参数的选择可通过数据分散分析和数据特征分析来实现,然后对其进行相似性判定,以此分析两种特征数据参数的聚类方式。
在ERP 系统聚类分析中,采集节点采集到的深度挖掘数据参数范围广,挖掘中障碍物的有效识别采用ERP 聚类的方式,所以聚类方式可根据二维数据特性进行密度和距离的分布设置。分布方式可由KMYIU 来代表类簇数量,类簇中含有所要测量的深度挖掘数据参数,采集过程中又可根据点云数据类簇进行数据重叠,ERP 系统根据数据参数个数N和参数K的数量选择有效的数据特征聚类中心,在将数据点分配的平均值调整为距离最小的聚类数据点的误差平方[16]。这种聚类算法可广泛应用到深度数据挖掘中,其设定的密度值可归为点集中的同一类簇,根据最大密度相连集合的属性,可对ERP 系统的数据对象进行概念和参数的算法集合。
聚类后的数据簇如图5 所示。
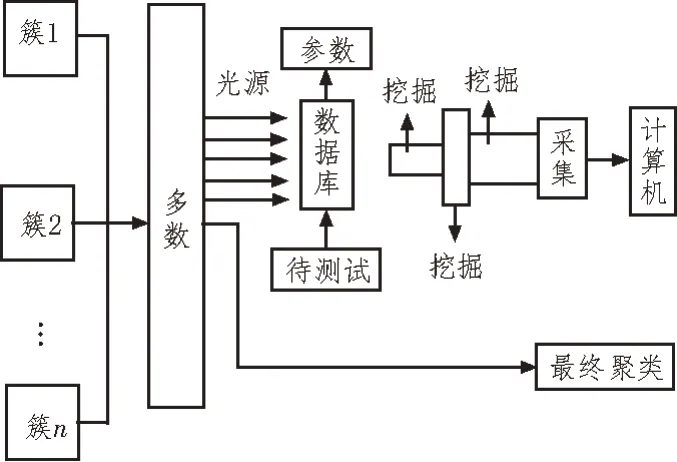
图5 聚类后的数据簇
3 ERP系统数据录入误差检测
在ERP 系统待测样本中,通过深度模型来计量误差,深度模型如式(1)所示:
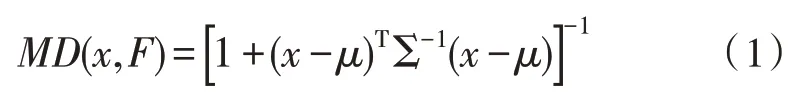
其中,F为总体累计函数,Σ 为平均值向量,在计算数据录入误差检测中可采用样本的协方差矩阵计算方式,样本的深度值趋于稳定时,总体的均值向量μ处取最大深度2,x为待测样本。深度值的大小由待测样本点中的累计方向量决定。对于二维数据样本,深度值在一定程度上代表真实数据的偏离属性。因此,综合考虑距离差异,引用常用的高斯径向几何函数,可得到样本形式的单纯深度,数据深度体现出待测样本与深度值的非参数特性,深度值越小说明录入数据误差越小。深度模型的分布方式如图6所示。
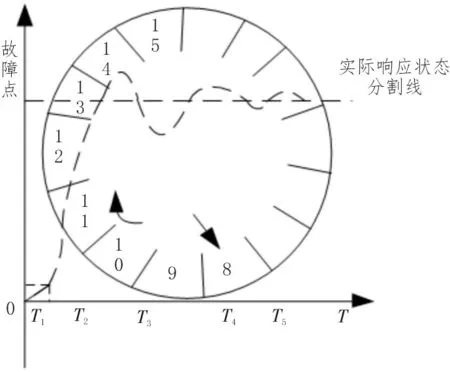
图6 深度模型的分布方式
所测的样本点不是故障样本,可利用参数统计量的相关性质来计算,核空间深度为Di,征集样本的深度值从大到小可排序为D(n)≥…≥D(2)≥D(1),定义i=1,2,…,R,…,n,可以得到R的取值服从样本离散分布,线性统计量接近正态性,根据深度挖掘的数据建立函数深度模型,获得正常运行过程中的数据误差值,代入模型空间深度值中,以此来确定相应深度函数的最大值σ。计算公式为:
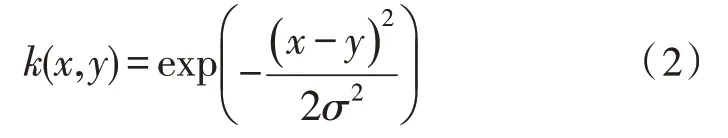
利用样本空间深度代替内积,得到样本点对应的秩,此时R的取值有n种可能,通过近似公式得到数据检测的误差总值。
4 实验研究
为了验证该研究提出的基于深度挖掘技术的ERP 系统数据录入误差检测方法的有效性,设计实验将其与传统方法展开性能对比。
实验参数如表1 所示。
表1 实验参数
根据上述参数,选用该文提出的方法和传统的方法进行实验对比,得到不同方法的存储数据量如图7 所示。误差检测对比结果如图8 所示。
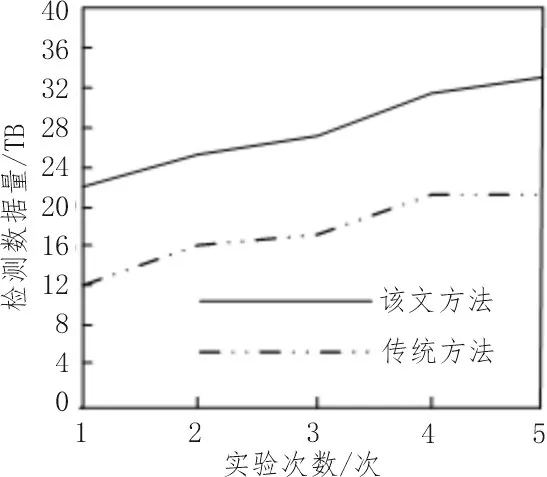
图7 不同方法检测数据量对比结果
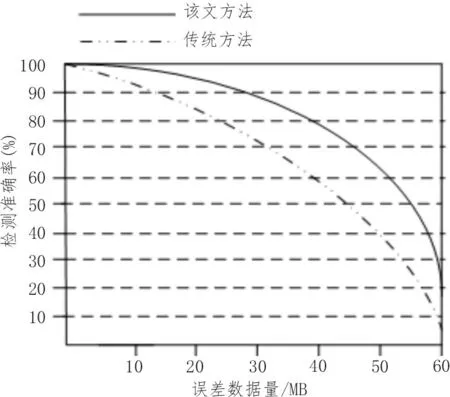
图8 误差检测对比结果
分析实验结果可知,相比于传统方法,基于深度挖掘技术的ERP 系统数据录入误差检测方法可存储的数据量更大、误差检测准确率更高,证明其是一种更为先进的方法。产生这一结果的原因在于该方法通过分析流程寻找ERP 各个环节节点的关键控制点,从根本上提高了检测关键控制节点的内部控制有效性。同时,在ERP 环境下,将深度挖掘技术的内部控制标准嵌入到系统的应用程序或数据设置中,成为数据误差检测的重要手段,该手段可在系统功能设置中进行设定与配置。在相关设置界面中可查看结果,录入的误差数据保存在云端数据库中,可实时查询。结合数据中的性能参数可提高深度挖掘的有效率,降低检测过程中发生错误的概率,将数据误差检测结果控制在最小范围,从而大大提高了数据误差检测工作的效率。
5 结束语
ERP 系统中的控制数据意义重大。为此,该研究基于深度挖掘技术设计了一种ERP 系统数据录入误差检测方法。检查录入数据的误差及准确性是ERP 系统中控制测试测量过程准确性的重要手段,能够帮助发现误差数据以及其中的微小测量值,从而解决普遍存在的批量性问题。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
哈尔滨轴承(2020年2期)2020-11-06
今日中国·法文版(2020年7期)2020-07-04
领导决策信息(2018年16期)2018-09-27
智富时代(2018年5期)2018-07-18
智富时代(2018年5期)2018-07-18
雷达学报(2017年6期)2017-03-26
数学学习与研究(2017年3期)2017-03-09
互联网天地(2016年1期)2016-05-04
现代计算机(2016年17期)2016-02-28
