
汉字识别技术的研究进展分析
2022-05-06 13:18李阳娟
科技和产业 2022年4期
李阳娟
(莆田学院 工程实训中心, 福建 莆田 351100)
光学字符识别(OCR)技术指对图像中的文字进行检测并识别出文字内容。OCR是人工智能和计算机视觉领域的热点研究方向。2020年4月,国家发改委明确将人工智能等新技术基础设施列入“新基建”范围,从政策布局上加速了人工智能产业的不断成熟。随着人工智能的飞速发展以及中文汉字的广泛使用,汉字识别技术有着重要的研究价值和社会意义,在金融、政府、医疗和教育等多个领域有极其广阔的应用前景,如车牌识别、机器翻译、卡证票据识别和无人驾驶系统等[1-5]。
由于汉字本身字符量多、字形结构复杂且有较多的相似字等特点,汉字识别的研究仍存在着许多的困难与不足之处[6]。因此,充分了解近年来汉字识别领域的研究现状及发展趋势对相关领域的研究者有一定的参考价值。本文以2001—2021年Web of Science(WOS)数据库中汉字识别的文献数据作为研究对象,利用文本可视化软件CiteSpace[7]绘制知识图谱并对文献内容进行分析,从量化视角挖掘汉字识别领域近几年的研究现状、热点和研究前沿,为汉字识别的研究与发展提供参考。
1 数据来源及研究方法
选取WOS核心数据库中2001—2021年汉字识别领域的相关文献作为文献数据来源,采用的检索式为TS=(Chinese character recognition OR Chinese text recognition) AND SU=(Computer),文献类型为Article或Review或 Proceedings Paper,排除掉非计算机视觉领域的研究内容后获得1 119篇文献,检索时间为2021年9月20日。CVPR、ICCV和ECCV这3个权威的计算机视觉领域的国际会议收录了该领域最新且重大的研究成果,因此会议论文也是文献数据的重要来源。
CiteSpace软件主要基于共引分析理论,可以绘制和可视化科学知识领域的知识结构,探寻学科领域演化关键路径及知识转折点[8]。本文利用CiteSpace 5.8.R1对采集到的文献数据进行文献计量分析,并对机构与作者、关键词和共被引文献进行可视化知识图谱分析,以全面深入地掌握汉字识别领域的研究进展情况与前沿发展趋势。
2 汉字识别领域的发文趋势及研究力量分析
2.1 发文趋势分析
对2001—2021年汉字识别领域的发文情况进行统计分析,如图1所示。汉字识别领域在这些年的发展过程中出现了两个明显的增长高峰。第一个高峰出现在2008年,文献数量在2008年以前缓慢增长,之后呈现下降趋势。第二个增长高峰在2017年,文献数量从2012年急速增长直到2017年,之后维持在较高的水平。通过文献调研可知其主要原因:第一个增长时期是由于智能手机等设备的流行,汉字识别领域迎来了应用高潮;第二个增长时期则由于卷积神经网络的发展带来了技术的革新,在汉字识别领域引发了一轮新的发展热潮。
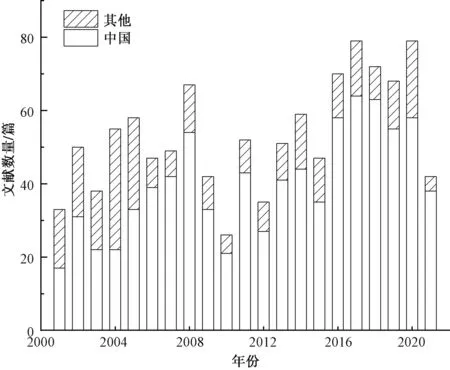
图1 汉字识别研究领域的发文趋势
2.2 研究力量分析
对研究机构及作者的发文情况和合作关系进行分析,可以得到汉字识别的研究力量分布,有助于发现研究汉字识别的权威机构及有影响力的作者。从汉字识别研究领域的国家或地区的贡献来看,使用汉字的国家或地区成为汉字识别领域的研究主力,如图1所示,中国发表的论文数量占总论文的75%以上,在汉字识别研究领域起主导作用。
表1列出了发文量前10位的研究机构,这些机构共发文398篇,占全部文献量的32%,说明了汉字识别领域的研究力量比较集中,绝大多数是中国的高校和研究所。中国是汉字使用大国,同时也是汉字识别研究的核心力量。中国科学院以127篇的发文量位居榜首,明显高于其他研究机构,清华大学和华南理工大学紧随其后,这3所院校及研究机构是当前汉字识别研究领域的重要基地。利用CiteSpace软件绘制各个机构间的合作网络图谱,如图2所示。图中每个节点代表着相对应的机构,节点越大表示发文量越多,节点间的连线代表机构间的合作关系,连线的粗细与合作次数成正比。图中有3个明显的大的节点:中国科学院、清华大学和华南理工大学,与统计结果相符。中介中心性是衡量节点在网络中重要性的一个指标,数值越大表明节点在网络中越重要[9]。在图2中,中国科学院的中介中心性的数值达到0.15,且节点处有圆圈标识,说明了该节点在图谱中的重要性高,与其他机构有着较强的合作关系。
作者合作图谱显示了汉字识别研究领域所有作者的发文数量与合作关系。在CiteSpace软件中绘制作者合作网络图谱,如图3所示。图中有3个较大的节点:刘成林(CHENGLIN LIU)、金连文(LIANWEN JIN)和丁晓青(XIAOQING DING),节点越大表明发文量越多。围绕这3个高产的核心作者形成了3个较大的作者合作网络群,分别是中科院的刘成林教授团队、华南理工大学的金连文教授团队和清华大学的丁晓青教授团队。刘成林教授团队主要研究文档图像分析、模式识别与机器学习,该团队发布了大型手写汉字数据库CASIA-OLHWDB 和CASIA-HWDB,包含了孤立的手写字符和连续的文本,可用于各种手写文档分析任务的研究,促进了汉字识别领域的学术研究和技术研发[10]。金连文教授团队主要的研究方向为基于深度学习的文档图像分析与理解,所研发的联机手写识别技术已在搜狗等知名公司获得了规模化应用。丁晓青教授团队主要研究智能图文信息处理与图像分析,创造性地将信息熵理论引入模式识别,从而解决汉字识别的众多问题,形成的TH-OCR系列文字识别软件产品广泛应用于国内外多家知名公司。这些研究团队的合作关系显著、取得成果较多且研究力量较强。还有一些其他的作者合作网络,但是发文量较少,形成的合作网络较小。从作者合作网络图谱的整体上看,有较强合作关系的作者发文量较多。

表1 发文量前10位的研究机构
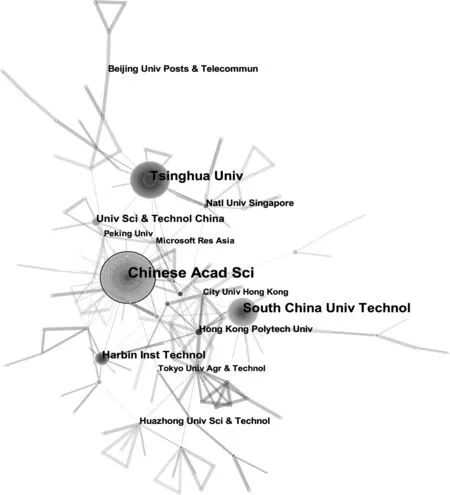
图2 研究机构合作网络图谱
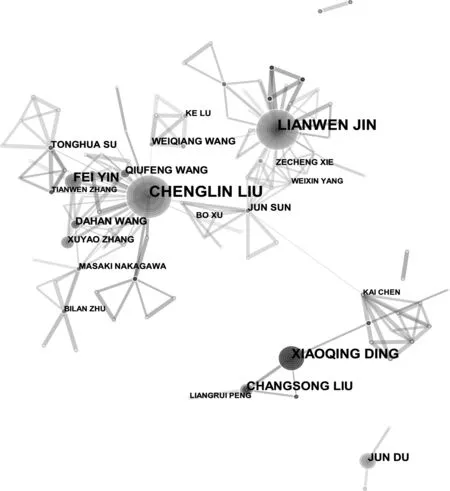
图3 作者合作网络图谱
3 汉字识别领域的关键词分析
关键词是对文章主题内容的精炼和概况,文献数据中的关键词出现的频次越高,说明该主题的研究热度越高。引入CiteSpace软件进行关键词共现知识图谱分析,如图4所示。图4中频次越高的关键词节点半径越大,研究热度也越高,节点间的连线代表了各关键词间的关联强度。图中最大的几个节点为识别、字符识别、特征提取、联机和分割。
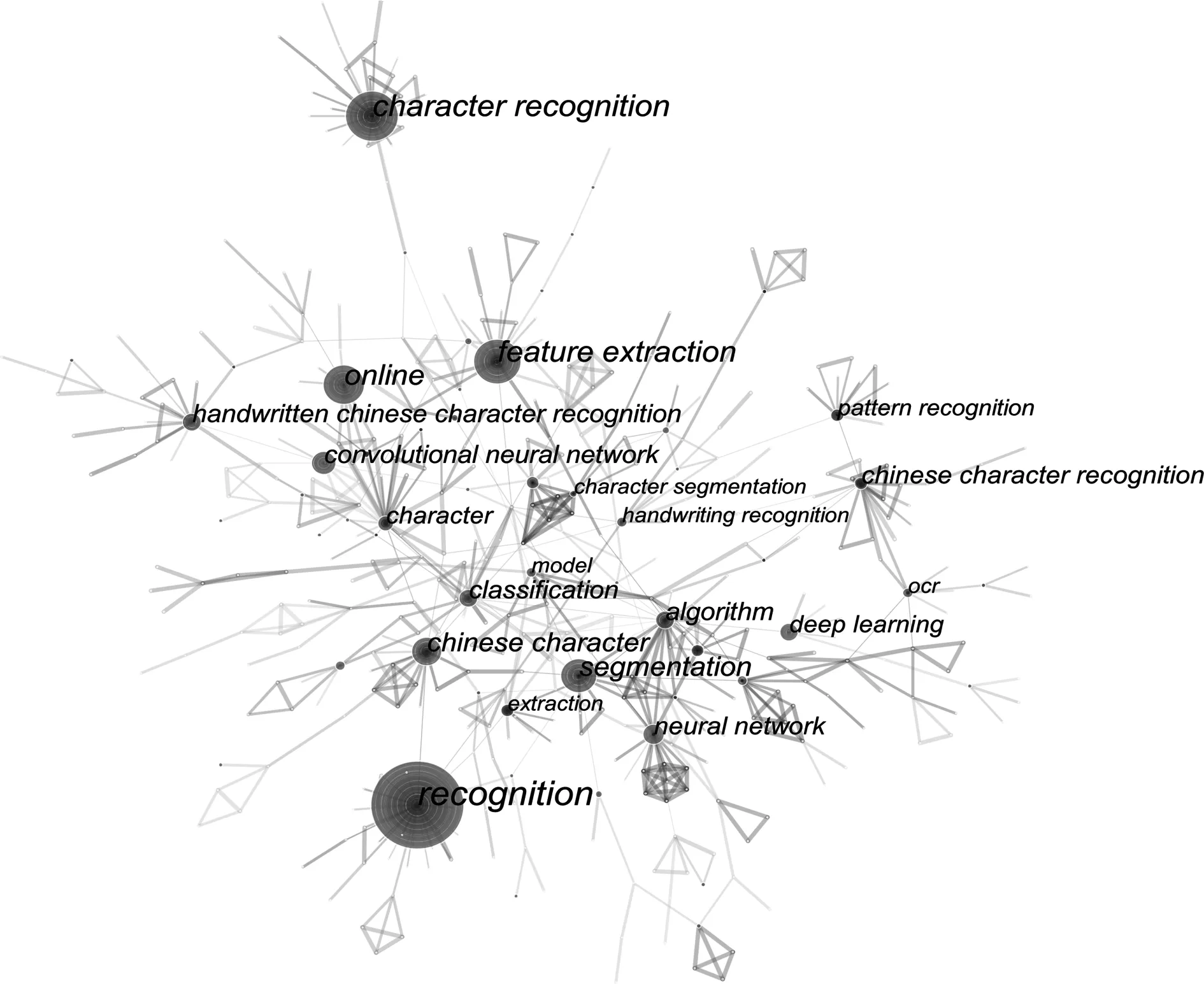
图4 关键词共现图谱
表2列出了关键词频次前20位的高频关键词。可以看出大部分的高频关键词在2003年之前出现,如:特征提取、字符分割、字符识别、光学字符识别(OCR)、手写汉字识别、模式识别等。此阶段的研究重点在利用模式识别的模型算法来进行汉字识别及手写汉字识别。2005年新增高频关键词:联机。2009年新增高频词:卷积神经网络(CNN)、手写识别。2015年新增高频词:深度学习。这些高频关键词及其出现时间反映了汉字识别领域的热点演变趋势。将高频关键词所涉及的研究热点总结为以下3点:基于传统方法的OCR技术、基于深度学习的OCR技术和手写汉字识别。
1)基于传统方法的OCR技术。汉字识别是模式识别的一个重要的研究领域。汉字识别通常采用传统的OCR技术流程:先预处理目标图片,再对文字区域进行字符切分,对单字符进行特征提取,最后利用分类器分类并识别出文字。其中特征提取和分类识别是汉字识别中的重点和难点。Liu等[11]利用传统的统计模式识别方法进行单字符手写汉字识别,在联机手写数据库OLHWDB和脱机手写数据库HWDB上获得最高的准确率为93.95%和90.71%。传统的OCR技术在单字符的汉字识别中识别精度较高,但对于复杂背景等情况的文字识别精度较低。
2)基于深度学习的OCR技术。卷积神经网络(CNN)是典型的深度学习网络结构。深度学习以神经网络为主要模型,无须手动提取特征,由神经网络自动提取特征并识别出结果。在2012年的ImageNet图像识别大赛上,Krizhevsky等[12]设计了深度卷积神经网络AlexNet,并以较大的优势赢得了冠军。自此以后,CNN网络发展非常迅速,相继产生了许多著名的网络框架,如VGGNet[13]、GoogleNet[14]和ResNet[15]等,卷积神经网络在图像识别领域获得了巨大成功。借鉴和采用深度学习的汉字识别技术省略了人工的特征提取过程,简化了传统OCR技术的流程,在识别精度上有了质的飞跃。在2013年ICDAR举办的汉字识别竞赛中,基于卷积神经网络的联机手写识别和脱机手写识别的准确率分别达到了97.39%和94.77%,超过了采用统计模式识别的方法[16]。目前,基于深度学习的汉字识别技术已成为汉字识别领域的主流技术[17-19]。
3)手写汉字识别(HCCR)。由于汉字的类别繁多、相似字多且书写风格随意等特点,手写汉字识别的难度很大,所以一直是汉字识别研究领域的热点问题[20]。手写字体识别有联机(online)和脱机(offline)两种方式。联机手写汉字是在智能手机等电子设备上人工书写而成,书写过程中能够即时获得笔画轨迹特征,使得汉字更易被识别。而脱机手写汉字识别处理的是经扫描仪或摄像头等设备采集到的图片,由于没有笔画笔顺等信息,而且图片中的文字背景或分辨率等存在着一定的噪声干扰,脱机手写汉字识别比联机手写汉字识别更具有挑战性。
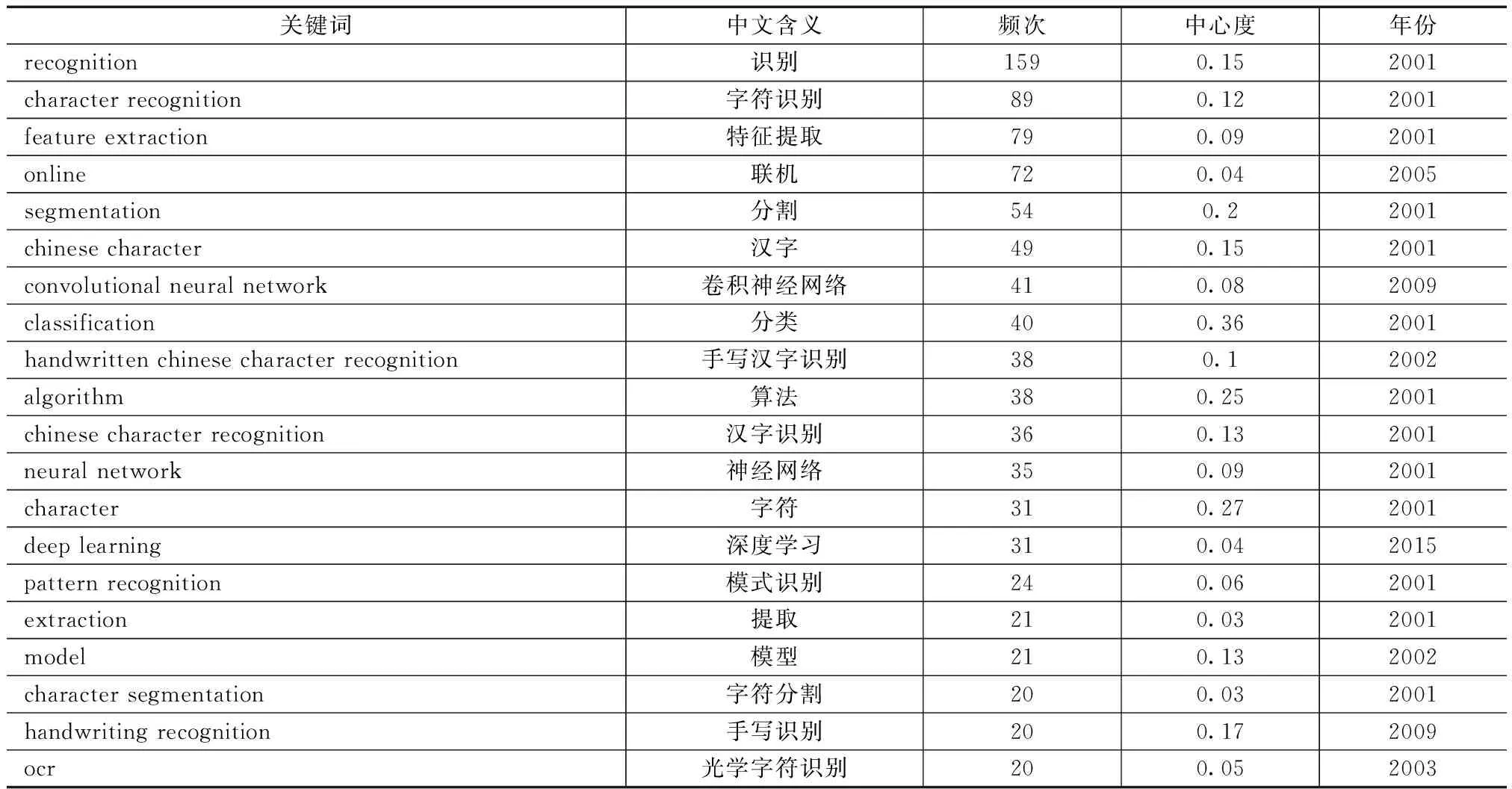
表2 频次前20的高频关键词列表
4 汉字识别领域的引文分析
4.1 主题演进分析
利用CiteSpace软件进行共被引文献分析,将共被引文献按照研究方向进行聚类,聚类的主题反映了研究前沿的领域[21]。科技发展日新月异,及时地识别研究领域的前沿有助于推动该领域的研究发展。在CiteSpace中进行共被引文献分析,通过LLR算法提取聚类主题,生成共被引时间线图谱,如图5所示,共生成了19个聚类。时间线图谱展现了汉字识别领域随着时间推移而不断演进的研究前沿动态。图5中,节点越大表示文献被引用的频率越高。通过聚类文献的时间跨度来探究研究领域的兴起、繁荣和衰落过程。有些研究领域短暂兴起后淡出,而有些研究领域顺应时代发展而被学者重视,开展深入研究并创造出许多高影响力的成果。为了更加直观地分析前沿主题的演进过程,将各聚类名称及时间跨度罗列在表3。结合时间线图谱分析,可将汉字识别研究的主题演化按照起始时间大致划分为早期、中期和近期3个研究阶段。
1)早期阶段。聚类#1、#9、#10、#11、#14、#16、#17、#19这8个聚类是早期的研究主题,它们是从2000年之前延续或刚兴起的研究主题,其中只有聚类#1修正二次判别函数(MQDF)受到的关注最多,热度持续时间最长,直到2013年结束。其他聚类的文献引用频次不高,影响力不足。在此阶段中,通常采用传统的OCR技术,它有一个成熟的技术流程:图像预处理、特征提取和分类识别。常用的分类方法有掩模匹配法、支持向量机、MQDF等[22-25]。传统的OCR技术在单字符的汉字识别中识别精度较高,但对文本行识别或复杂背景文字等情况的识别精度较低,且难以取得突破性进展。

图5 共被引文献时间线图谱
2)中期阶段。聚类#5、#6、#7、#12、#18这5个聚类主题在2006年附近开始逐渐受人关注,其中聚类#6联机、聚类#7字符串识别这2个聚类的高被引文献较多,关注度较高。在此期间随着智能手机的流行,基于智能设备的联机手写汉字识别迎来了应用高潮,不断产生新的应用和技术需求。OCR技术从单字符的识别转变为字符串及文本行的识别,通过利用文本行的序列信息,提升识别效果[26-28]。
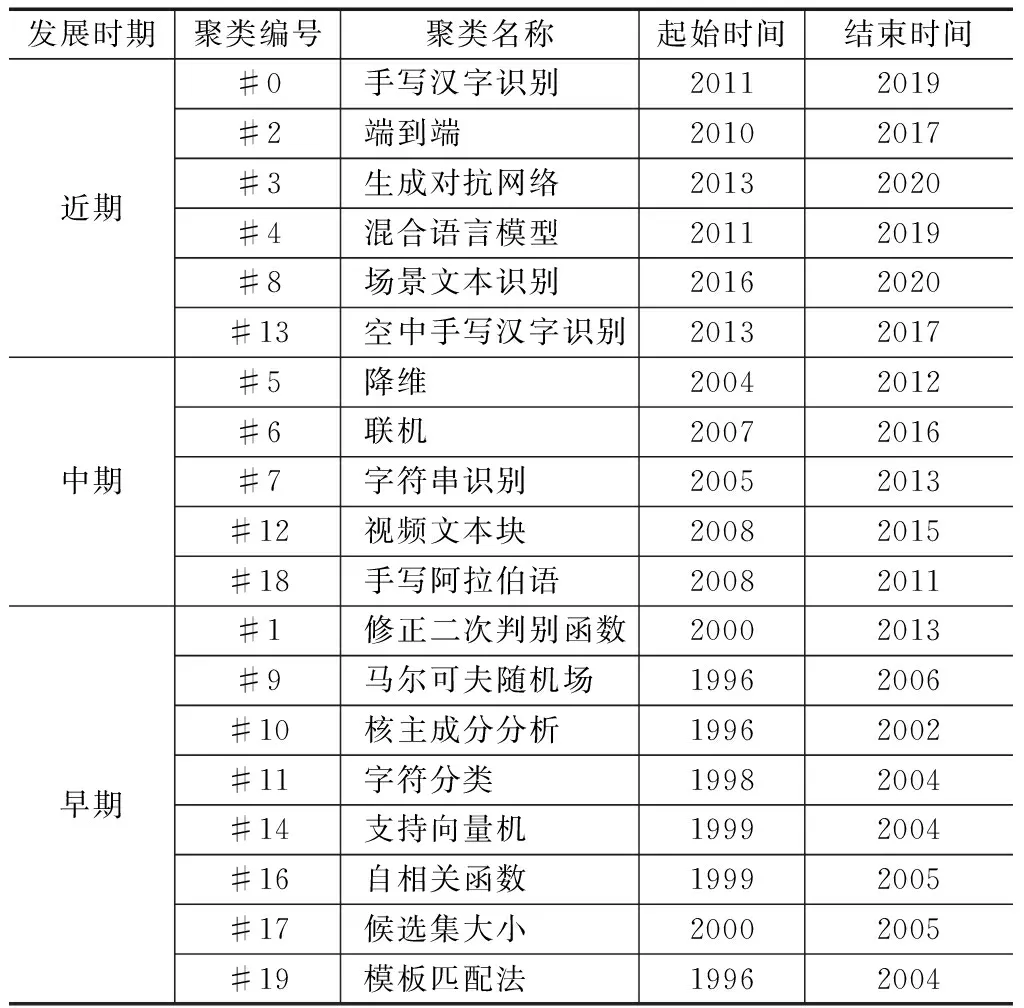
表3 共被引聚类的时间跨度
3)近期阶段。聚类#0、#2、#3、#4、#8、#13这6个聚类主题在2010年后开始出现且研究热度持续到近几年,这些主题有较多的高被引文献,影响力高[29-31]。因此,这几个聚类主题是需要重点关注的研究前沿领域。在此期间,汉字识别技术出现重大变革,由传统方法的OCR技术识别转变成基于深度学习的OCR技术。随着深度学习的不断发展以及计算设备能力的不断提升,基于深度学习的汉字识别取得极大进展。在应用上向社会生产生活各领域渗透,产生的应用领域有脱机手写汉字识别、空中手写汉字识别、特定场景文本识别及自然场景文本识别等。
4.2 研究前沿分析
如果一篇论文的引用频次突然呈现急速增长,表明该研究领域受人关注或具备里程碑意义,也代表了该研究领域的前沿。CiteSpace具备探测引文突现功能,在共被引分析的基础上,通过“Burstness”进行突变率检测,得到汉字识别领域引用频次激增的参考文献[32]。为了探测近期的研究前沿,应重点关注引文突现时间持续到最近的文献,共有7篇文献,详见表4。这些文献分布在聚类#0手写汉字识别、#3生成对抗网络、#4混合语言模型和#8场景文本识别这4个聚类中,说明这4个聚类主题是近期的研究热点及前沿,将这4个聚类的详细信息罗列在表5。
聚类#0手写汉字识别是汉字识别研究领域开展最早且发展时间最长的研究主题。聚类中突变率最高的文献是2015年发表在Nature上的深度学习综述[33],介绍了各种深度学习的模型及发展现状,包含CNN、DBN和RNN等。其中,CNN在处理图像、视频、语音等方面带来了突破性的进展,而RNN则在文本和语音等顺序数据方面大放异彩。在以CNN为代表的深度学习技术的协助下,手写汉字识别能力大步提升。
聚类#4混合语言模型,该聚类中还包含空中书写、GoogLeNet、cnn压缩、手写体中文文本识别等研究内容,与聚类#0的研究内容存在交集。聚类#4中含有4篇突发文献,说明了该聚类是关注度较高的研究前沿。突变率最高的文献是微软研究院的He等[15]于2016年发表的关于ResNet网络模型的设计及应用,该模型通过增加相当的深度来提高识别准确率,且能够有效降低深层CNN模型的梯度消失问题。华南理工大学研究团队[34]和中科院研究团队[35]都利用了传统的特征提取方法与神经网络相结合的混合语言模型来提高手写汉字识别性能。由于深度神经网络的训练过程既耗时又非常消耗计算机资源,使得它们无法在便携式设备中部署。Xiao等[36]设计了一种降低计算成本的算法和9层CNN模型用于脱机手写汉字识别,在保证识别精度的前提下大大提高了计算速度。
聚类#3生成对抗网络是一种深度学习模型,包含生成模型和判别模型,两者之间互相对抗学习以提升模型精度[37]。该聚类还包含了人工智能、输入自然图像、密集卷积网络等研究内容。与聚类#8场景文本识别的研究内容有部分重叠。聚类#3中的突现论文介绍了一种汉字生成的方法,该文利用RNN模型实现了一个富有挑战性的任务,即教会机器自动书写汉字[38]。
聚类#8场景文本识别,不同于发展地比较成熟的特定场景的OCR技术,自然场景中的文字具有字体多变、排列不一且文字背景复杂等特点,一直都是汉字识别研究领域的难点[39]。聚类#8中的突现论文突变率排在第2名,高达12.37,表明了该研究主题的关注度越来越高。该文提出了一种端到端的CRNN网络,将检测和识别过程在同一个网络框架中进行,实现了基础特征的共享,既能够减少重复计算又能提高特征质量,实现了自然场景文字的高效识别[40]。
综上所述,通过引文的突现探测,得到了7篇近期的突现文献,这些文献的关注度激增,反映了汉字识别领域的研究前沿。这些文献所涉及的研究内容有深度学习、深度残差网络、传统方法与深度学习相结合的混合模型、CNN加速与压缩、汉字生成、端到端OCR模型、手写汉字识别与场景文本识别。归属于以下4个前沿聚类主题:手写汉字识别、混合语言模型、生成对抗网络和场景文本识别。
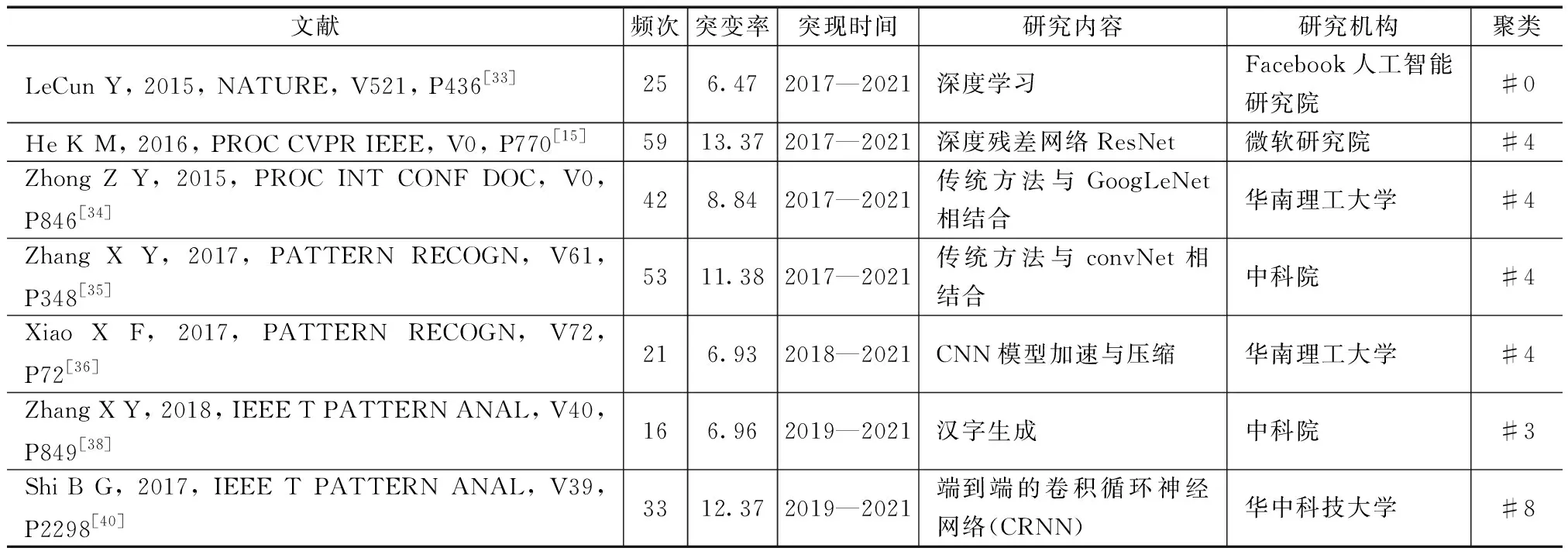
表4 基于引文突现的前沿分析

表5 研究前沿的聚类信息
5 结论
将WOS核心合集数据库中的汉字识别领域的相关文献作为数据来源,对2001—2021年的发文趋势、研究力量、热点关键词和引用文献进行分析和可视化,从量化的角度总结了汉字识别领域的研究现状、研究热点和研究前沿。综合上述研究,可得到如下结论:
1)汉字识别领域在2001—2021年的发展历程中出现了两个明显的增长高峰:2008年和2017年。中国发表的论文数量占总论文的75%以上,在汉字识别研究领域起主导作用。对研究力量的分布进行分析,中科院的刘成林团队、华南理工大学的金连文团队和清华大学的丁晓青团队在汉字识别研究领域取得的成果较丰硕,团队的合作关系显著。结果显示有较强合作关系的作者发文量较多。为了促进汉字识别研究领域的发展,应加强研究机构之间或者研究者间的合作交流,资源共享及共同进步。
2)高频关键词反映了汉字识别领域主要的研究热点:汉字识别技术和手写汉字识别。汉字识别技术由传统的OCR识别技术转变为基于深度学习的识别,并成为了近几年重要的研究热点。
3)基于共被引聚类时间图谱的分析,得到汉字识别领域的前沿主题演化趋势:由早期基于传统方法的OCR技术研究演化为中期的联机手写汉字识别与文本行识别,再到近期基于深度学习的汉字识别研究。
4)对近期的引文突现进行分析得知,研究前沿的主题为手写汉字识别、混合语言模型、生成对抗网络和场景文本识别。
随着深度学习技术在OCR领域的应用,汉字识别的性能得到了显著的提升,OCR技术将朝着高效率、智能及一体化发展。汉字识别的应用范围从简单的印刷体识别,逐步演进到手写文本识别与自然场景文本识别等复杂情形。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
南京理工大学学报(2022年1期)2022-03-17
故事作文·低年级(2021年12期)2021-12-21
速读·下旬(2021年11期)2021-10-12
计算机应用与软件(2021年7期)2021-07-16
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
大东方(2019年12期)2019-10-20
文苑·经典美文(2019年8期)2019-08-06
科学与财富(2017年22期)2017-09-10
商情(2017年1期)2017-03-22
