
基于深度学习的无参考图像质量评价综述
2022-04-27 00:37:16李嘉锋
测控技术 2022年4期
韩 翰, 卓 力*, 张 菁, 李嘉锋
(1.计算智能与智能系统北京市重点实验室,北京 100124; 2.北京工业大学 信息学部 微电子学院,北京 100124)
随着信息化时代的发展,数字图像在各种行业中扮演着越来越重要的角色[1]。数字图像可以被采集、传输和应用到不同的场景中[2],发挥巨大的作用,例如智能安防、智慧交通等。而数字图像在采集、传输和处理的过程中,由于各种因素的影响,不可避免地会引入各种失真[3-4],导致图像质量下降。其中最常见的失真类型包括压缩、噪声、模糊等。如何对图像的失真程度进行评估,判断图像质量是否满足应用要求就显得至关重要。
图像质量评价(Image Quality Assessment,IQA)是图像处理、图像/视频编码等领域的基础性问题,可以广泛应用于评价图像处理算法的性能和指导处理算法的设计。例如,IQA可以被用在图像超分辨率重建任务中,帮助生成高精度、高质量、高分辨率的清晰图像[5];类似的应用还包括图像复原,借助IQA可以设计复原模型帮助去除失真图像的模糊、噪点、水印等[6-7];在手机、摄像机等图像采集设备中,IQA被用于评估和调试产品的成像参数。此外,IQA还被广泛应用于遥感领域,可用于收集和过滤遥感图像信息,以及帮助识别和分类感兴趣区域等[8]。
本文旨在对近年来出现的各种无参考图像质量评估方法进行综述。首先介绍图像主观、客观质量评价方法,然后着重介绍无参考质量评价中的一些代表性工作,以及IQA领域常用的数据集和评价指标。之后对一些常见的无参考IQA方法进行性能比较,最后给出结论和展望。
1 IQA方法分类
IQA根据打分方式可以分为主观质量评价方法和客观质量评价方法两种[9]。下面对这两种方法进行介绍。
1.1 主观质量评价
主观IQA法通过观测者的主观打分来判断图像质量[10]。其具体的做法是:让观测者根据事先规定好的评价准则或者自己的主观经验,对待评价图像按照视觉效果做出质量判断,并给出质量分数,最后对所有评价人员给出的质量分数进行加权平均,得到的结果就是该幅图像的平均主观分值(Mean Opinion Score,MOS)。MOS得分越高则说明图像的质量越好。
这种打分方式由于综合了多个评价人员的意见,所以可以直接反映人的主观感受,是最为准确、可靠的质量评价方法。主观质量评分法又可以分为绝对评价和相对评价两类。绝对主观评价是在无标准的参考情况下将图像按照视觉感受分级进行评分,评价人员除了直接观察,还需要借助自身的经验给出图像失真程度的判断。它相对主观评价方法增加了标准图像的参考,评价人员在此基础上再进行分级和判断好坏,最后给出相应的图像质量评分结果。国际电信联盟[11]提供了多种主观评价方法的操作标准,其中具有代表性的有3种,分别是双刺激损伤分级法、双刺激连续质量分级法和单刺激连续质量分级法。
主观IQA方法的优点是可以真实地反映人的主观视觉感受,评价结果直接、准确、可靠。但是该方法通常受观测环境和实验人员数量等客观因素影响,存在很多的局限性,例如存在操作难度大、实现起来比较困难等问题,无法满足实际应用需求。
1.2 客观质量评价
客观IQA方法是一种根据人眼的视觉系统建立数学模型,对待测图像进行打分的评价方式。这种方法成本低,具有可批量处理、结果可重现等优点,更容易被应用于多种场景中。根据对参考图像的依赖程度,客观质量评价方法可分为三类,即全参考、半参考和无参考评价方法。
1.2.1 全参考评价
全参考评价利用全部原始图像的信息,通过计算待评价图像与原始图像之间的偏差来进行质量评估。早期最具代表性的方法是均方差(Mean Square Error,MSE)和峰值信噪比(Peak Signal Noise Ratio,PSNR)[12-13]。下面给出这两种评价指标的数学表达式:
(1)
(2)
式中:MSE为均方差;L为图像量化的灰度级数。
MSE和PSNR的计算形式易于理解,物理含义清晰,但是这种方法并没有考虑人类视觉系统对失真差异的感知能力,只从数学方面进行了失真图像和原图之间的距离度量。这种方法往往会出现主客观评价结果不一致的问题,无法准确反映出用户观看视频的主观体验[14]。
基于此,学者们开展了基于人眼视觉特性的客观IQA方法的研究,并成为现阶段IQA的研究热点。2004年,Wang等[15]提出了结构相似性(Structural Similarity,SSIM)度量算法,SSIM认为人类视觉感知能高度自适应提取场景中的结构信息,因此分别度量参考图像和失真图像之间的亮度、对比度和结构等信息的失真,最后综合3种因素完成图像质量打分。SSIM的取值范围是[0,1],值越大,表明图像质量越好。在此基础上,人们提出了各种SSIM的改进算法。例如,Chen等[16]提出了基于梯度的结构相似度(Gradient-Based Structural Similarity,GSSIM)算法,首先对参考图像和失真图像分别求梯度,然后在梯度图像的基础上进行距离度量。类似的工作还有MS-SSIM(Multi-Scale Structural Similarity)[17]和IW-SSIM(Information Content Weighted Structural Similarity)[18]等。
还有一些方法是基于人眼视觉系统(Human Visual System,HVS)的特性进行建模[19-21]。这种方法将失真图像和参考图像之间的绝对误差映射为能被人眼觉察的单位[22]。当误差映射后不能够被人眼捕捉到,那么这部分误差量就被忽略,可以被人眼察觉到的绝对误差则被保留并计算。
1.2.2 半参考评价
半参考评价方法[23-24]通过提取图像的部分信息,利用参考图像进行特征提取和分数回归,进而完成图像质量分数预测。这样的做法具有计算量小、评价准确的优点。
与全参考评价方法不同的是半参考评价方法只比较参考图像和失真图像之间的部分信息。Soundararajan等[25]提出的基于信息理论的半参考熵差异(Reduced Reference Entropic Differencing,RRED)的IQA方法[25]是具有代表性的半参考评价方法之一。该方法将原始图像和失真图像分解为不同方向和尺度的分量,并进一步度量原始图像和失真图像有关小波系数的熵差异以计算相应的图像质量分数。王体胜等[26]提出首先提取图像中的视觉敏感系数,再通过统计失真图像与原始视觉图像视觉敏感系数的关系来评价图像质量。
目前,全参考和半参考评价方法的准确性越来越高,但其缺点是都需要提供原始的参考图像,这在实际应用中通常很难获得,因此这两种评价方法的应用范围受到了极大限制。
1.2.3 无参考评价
图像的无参考评价(No-Reference Image Quality Assessment,NR-IQA)是目前图像客观质量评价的研究难点和热点。这种评价方法无须任何原始参考图像信息,仅利用图像自身的特征进行质量评估,因此非常灵活,可以广泛应用于各种场景。早期的NR-IQA方法更多地是面向特定类型的失真评价任务。这类方法利用图像的统计信息可以对已知失真类型的图像进行质量评价,但是当面临评价未知失真类型的图像质量时就会受到局限[27]。目前,NR-IQA的研究趋势逐渐转为面向通用失真类型的图像进行失真类型预测和失真程度度量,这种趋势正成为研究的主流方向。
下面对近年来面向非特定失真类型的NR-IQA的研究进展进行综述。
2 无参考图像质量评价研究进展
根据所采用的框架,NR-IQA方法可以分为两类,如图1所示。第一类采用“特征提取+回归/拟合”的框架,首先提取图像的特征,然后采用机器学习的方法建立特征与质量分数之间的映射模型;第二类采用端到端的框架,通过深度学习直接建立待观测图像与质量分数之间的映射模型。

图1 NR-IQA的两种框架
2.1 基于特征提取+回归/拟合框架的NR-IQA
基于特征提取+回归/拟合框架的NR-IQA方法包括两个关键部分:特征提取和拟合/回归。其中,特征用于表达图像的内容,直接决定算法的优劣。根据所采用的特征,可以分为人工特征和深度特征。拟合/回归方法则包括支持向量回归(Support Vector Regression,SVR)、随机森林、深度神经网络等。各种代表性的评价模型如表1所示,表中列出了4个代表性的IQA模型所采用的特征提取方法、回归方法和采用的数据集等。
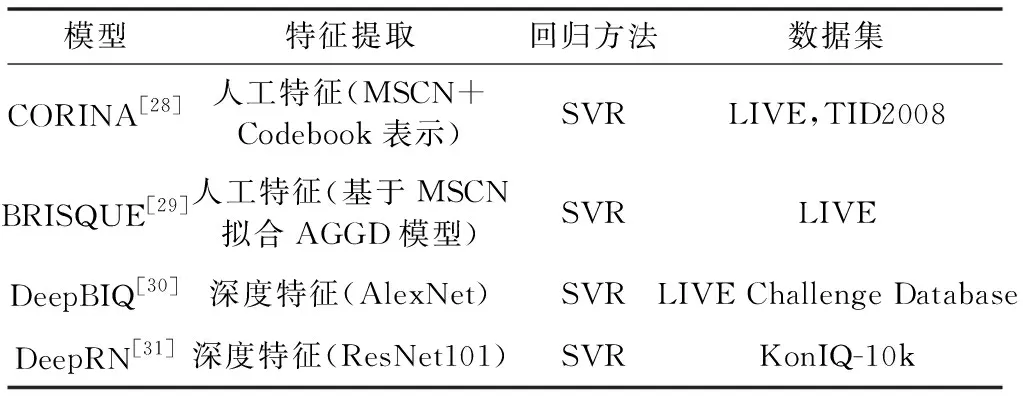
表1 基于特征提取+回归/拟合框架的代表性NR-IQA模型
其中CORINA和BRISQUE的特征提取方式相似,都采用人工特征-MSCN系数,再使用SVR拟合方法得到质量评价得分。下面详细介绍这两种具有代表性的利用人工特征进行NR-IQA的方法。
2.1.1 CORINA模型
CORINA[28](Codebook Representation for No-Reference Image Assessment)模型是Ye等于2012年提出的利用人工特征进行NR-IQA的方法。该方法将待评价图像分成若干个patch块,随机提取若干patch块计算去均值对比度归一化系数(Mean Subtracted Contrast Normalized,MSCN),再使用K-means聚类的方法建立码书,码书训练使用的是CSIQ数据集。在预测阶段,采用了软分配策略生成码字,对码字合并后得到特征矢量,通过SVR建立特征矢量与图像分数之间的映射模型,用于预测分数。这种基于码书的方法学习效率高,无须人为调整参数,并且允许自动学习。实验证明,这种基于码本提取局部特征并使用SVR预测分数的评价策略具有较好的泛化性,在多个数据集上都取得了领先的性能。
2.1.2 BRISQUE模型
BRISQUE[29](Blind/Referenceless Image Spatial Quality Evaluator)是Mittal等提出的另一种采用人工特征进行NR-IQA的模型。其基本思路是从图像中提取MSCN系数,提取MSCN系数时考虑了相邻像素之间的关联信息,选取了4个方向分别计算MSCN系数。然后将MSCN系数拟合成非对称广义高斯分布(Asymmetric Generalized Gaussian Distribution,AGGD),利用失真对分布造成的参数影响来提取高斯分布特征。另外,还将空间相邻差值、均值减去以及对比度归一化等作为特征参数。最后使用SVR作为拟合工具,进行特征到分数的回归计算,从而得到图像质量的评估结果。
与前两种方法不同,DeepBIQ和DeepRN都采用深度神经网络作为特征提取器,提取图像的深度特征,再使用SVR进行拟合。下面对这两种有代表性的基于深度特征的NR-IQA方法进行详细介绍。
2.1.3 DeepBIQ模型
Bianco等提出的DeepBIQ模型[30]是基于深度特征进行NR-IQA的代表性工作之一。该模型采用AlexNet[32]作为骨干网络进行特征提取,AlexNet网络用“预训练+细调”的策略进行训练。首先在ImageNet数据集上进行预训练,得到模型的初始化参数。在细调时,首先根据MOS值大小将图像质量从好到坏分成5个等级,根据等级对IQA数据集进行重新标定,再利用重标定的数据集对AlexNet进行细调。从细调后的网络模型中提取图像的全连接层特征作为图像的深度特征,使用SVR作为拟合工具学习深度特征到分数之间的映射模型。DeepBIQ使用平均合并图像的多个子区域的分数预测图像质量。在LIVE In the Wild Image Quality Challenge Database[33]上,DeepBIQ取得了最优的性能,在人工模拟失真数据集LIVE[34]、CSIQ[35]、TID2008[36]、TID2013[37]上也取得了领先的性能。
2.1.4 DeepRN模型
Varga等提出的DeepRN模型[31]采用ResNet101[38]作为骨干网络进行特征提取,在网络的末端加入了自适应空间金字塔池化层,使骨干网络能提取到固定尺寸大小的全连接层特征。这样的设计使网络可以处理任意尺寸大小的图像,不管输入图像的尺寸是多大,经过特征提取网络后,得到的全连接层特征向量维度均为18432。得到特征向量之后使用SVR进行特征到分数的拟合回归。Lin等[39]基于KonIQ-10k数据集进行了多个实验,得到当时最领先的性能。
从上面的分析可以看出:
(1) 早期NR-IQA主要采用的是人工特征,包括局部特征和全局特征。人工特征提取采用的数据集主要是CSIQ,规模较小。由于过分依赖手工调节参数,人工特征中包含了少量的参数,因此特征的表达能力有限,导致性能不高。
(2) 2012年以后,随着深度学习技术的迅猛发展,深度特征被越来越多地应用在NR-IQA中。而深度学习需要利用大数据进行网络模型训练,因此各种大规模数据集被不断推出,包括自然图像数据集LIVE In the Wild Image Quality Challenge Database、KonIQ-10k等,以及合成失真数据集LIVE、TID2008、TID2013等。研究结果表明,深度特征取得的性能远超过人工特征。与人工特征相比,深度特征具有以下优势:
① 通过构建一个多层神经网络,深度学习采用有监督或者无监督的方式,可以从大数据中自动学习隐含在数据内部的关系,所付出的代价是计算复杂高、所需的存储空间大。
② 深度网络模型中可以包含成千上万的参数,因而深度特征可以具有更好的区分与表达能力。与人工特征相比,在提取图像的多层次特征和上下文信息方面具有更为突出的优势。
③ 深度特征具有很高的泛化性和效率。深度学习只需调整参数就能改变模型结构,这能够使网络根据任务的具体特点自动建模,具有良好的泛化性。
2.2 基于端到端框架的NR-IQA方法
基于端到端框架的NR-IQA方法的思路是直接通过训练深度神经网络得到待评价图像到分数之间的映射模型。代表性的评价模型如表2所示,表中给出了各种模型采用的网络框架和数据集等。
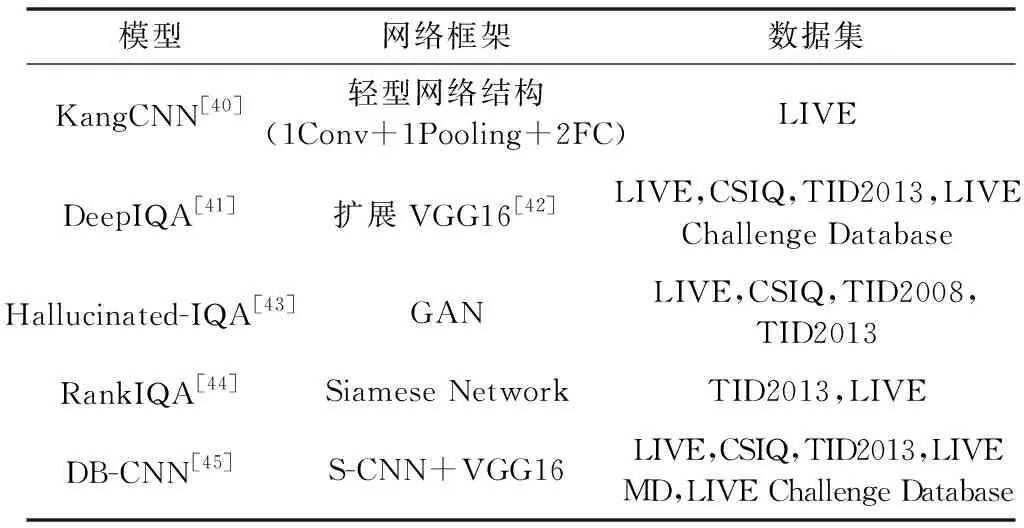
表2 基于端到端框架的代表性NR-IQA模型
下面详细介绍这几种最具代表性的NR-IQA模型。
2.2.1 KangCNN模型
KangCNN模型是Kang等[40]提出的,是最早采用卷积神经网络(Convolutional Neural Networks,CNN)解决NR-IQA问题的模型。它将特征提取和分数回归纳入到一个统一的框架内实现。CNN一共有5层,其中包括1个卷积层、1个池化层、2个全连接层和1个输出结点层。整幅图像的质量得分建立在局部质量估计评分的基础上,通过对评分取平均值得到。池化层分别对卷积层的全尺寸特征图进行最大池化和最小池化操作,可以得到两个维度为50的特征向量,全连接层之间使用的是比较流行的ReLU单元。最后采用的损失函数与SVR类似,形式上可以看成是SVR将ε取为零。虽然该模型网络结果比较简单,但是在2014年取得了当时最领先的性能。
2.2.2 DeepIQA模型
Bosse等提出的DeepIQA[41]也是基于端到端框架的IQA模型。该模型采用扩展过的VGG16作为骨干网络,相比于其他IQA模型具有更深的层数,在多个数据集中也取得了较好的表现。DeepIQA的创新点是将图像随机分割成patch块进行IQA数据集扩充。并且在训练阶段,每个patch块都返回一个权重,最后将每个patch块及其对应的权重进行合并,用于预测图像质量得分。需要强调的是,DeepIQA将全参考IQA任务和NR-IQA任务融合在一个网络中实现。使用孪生网络进行全参考IQA的训练,使用孪生网络的一个分支稍加改动就可以用于NR-IQA。DeepIQA在人工模拟失真数据集和自然失真数据集中都取得了很好的效果。
2.2.3 Hallucinated-IQA模型
Lin等[43]创新性地将生成对抗网络(Generative Adversarial Networks,GAN)加入到NR-IQA领域,提出从新的角度解决NR-IQA的不适定性问题。具体做法是引入幻觉引导质量回归网络来捕捉失真图像和幻觉图像之间的感知差异,从而可以精确地预测感知质量。其网络架构主要由3个部分组成,包括质量感知生成网络、判别网络和幻觉引导质量回归网络。生成网络通过对抗性学习的方式,在特殊设计的判别网络的帮助下产生幻觉图像。将幻觉图像与失真图像作差得到残差图,将残差图和失真图像一起送入质量回归网络,得到图像质量的评分。该模型在人工模拟失真数据集和自然失真数据集中都取得了很好的效果。除了Hallucinated-IQA模型,Ren等提出的RAN4IQA[46]也使用GAN的思想,首先生成未失真的原图,然后用类似于全参考的评价方式得到质量得分,也取得了不错的性能。
2.2.4 RankIQA模型
Liu等提出的RankIQA[44]首次用排名训练的方法学习图像质量好坏的评价准则。RankIQA使用孪生网络(Siamese Network),对已知图像间质量相对好坏的数据集进行合并,用于训练网络模型。这种自动生成失真的方式组成的图像数据集不需要费力的人工标注,所以可供训练的数据集规模很大。训练完成后,再将孪生网络的一个分支提取出来,使用公开的IQA数据集进行微调。微调阶段使用特征和人工标注值进行映射。在LIVE和TID2013两个数据集上的测试结果表明,RankIQA可以获得比当时的NR-IQA方法,甚至一些全参考IQA方法更优的性能。目前也有很多工作借鉴Learning-to-Rank的思路进行NR-IQA,例如Ma等提出的DipIQ[47]、Prashnani等提出的PieAPP[48]等,都采用学习排序图像的方法获得图像质量感知模型,且均取得了不错的结果。
2.2.5 DB-CNN模型
Ma等提出了一种基于双线性池化的CNN结构[45]用于NR-IQA。该网络由两个分支网络和一个双线性池化模块[49]组成。其中一个分支网络采用轻型网络结构,使用滑铁卢数据集[50]和Pascal VOC数据集[51]组成的训练集进行训练。利用数据集中的高质量图像合成不同类型、不同程度的失真图像,用分类的方式对分支网络进行训练。另一个分支网络采用VGG16,该网络在ImageNet数据集上进行了预训练,用于提升整个网络对于自然失真的感知能力。最后,利用双线性池化模块融合两个网络的全连接层特征,作为图像的深度特征,进而再拟合深度特征与质量得分之间的映射关系。这种方法在合成失真和自然失真IQA数据集上都获得了最高的性能,为目前的NR-IQA研究工作带来了新思路。
从上面的介绍中可以看出,与“特征提取+拟合/回归”框架相比,这种端到端的NR-IQA方法可以将特征提取与拟合/回归两个环节纳入到一个统一的框架中,同时进行优化。这也成为目前主流的NR-IQA方案。在这种框架下,近几年出现了一些IQA方法,主流思路包括以下几类:第一类是用GAN对失真图像进行恢复,使用生成的复原图像和失真图像进行损失计算和距离度量,生成质量分数;第二类是使用Rank学习的思路,这种学习方法可以解决IQA没有大规模数据集的问题,从而提高模型精度。除此之外,有的研究思路是使用注意力机制提高感兴趣区域权重,对图像质量进行评价[52];还有的做法是通过元学习的方法学习先验知识,解决无参考图像数据集规模过小的问题[53]。
3 IQA指标和数据集
数据集和评价指标用于评价各种算法的性能。下面介绍NR-IQA常用的各种数据集和评价指标。
3.1 NR-IQA常用数据集
NR-IQA领域最常用的数据集有LIVE、TID2008、TID2013、CSIQ、LIVE In the Wild Image Quality Challenge Database、KonIQ-10k等。其中,LIVE In the Wild Image Quality Challenge Database和KonIQ-10k是自然失真数据集,其余的4个是人工模拟失真数据集。
3.1.1 LIVE
LIVE(Laboratory for Image & Video Engineering)[34]数据集由美国德克萨斯大学奥斯汀分校LIVE实验室建立,是目前最常用的数据集。数据集中包含了29幅参考图像,分辨率从438像素×634像素到512像素×768像素不等。这些图像经过模拟降质生成了5种不同类型的失真图像,共计779幅。失真类型包括JPEG2000失真、JPEG失真、白噪声失真、高斯模糊失真和快速瑞利衰减失真。该数据集提供了所有失真图像的差分平均主观值(Differential Mean Opinion Score,DMOS),取值范围是[0,100],其中0表示图像没有失真。
3.1.2 TID2008
TID(Tampere Image Database)2008[36]由芬兰坦佩雷理工大学于2008年建立,包括25幅分辨率为384像素×512像素的彩色参考图像,失真类型有 17种,每种失真含有4个不同等级,共计1700幅图像。模拟失真包括加性高斯噪声、颜色成分中的相加噪声比亮度成分中的相加噪声更密集、空间相关噪声、掩蔽噪声、高频噪声、脉冲噪声、量化噪声、高斯模糊、图像去噪、JPEG压缩、JPEG2000压缩、JPEG传输差错、JPEG2000传输差错、非偏移图案噪声、不同强度的局部逐块失真、平均偏移(强度偏移)和对比度变化。数据集提供所有测试图像的MOS值及其标准差。MOS值取值范围是[0,9],其中9表示图像无失真。
3.1.3 TID2013
TID2013[37]由芬兰坦佩雷理工大学于2013年建立,包括25幅参考图像,每幅图像产生了24种失真,每种失真有5种级别,共计3000幅失真图像。相比于TID2008数据集,增加了7种失真类型,分别是改变色彩饱和度指数、有损压缩、多重高斯噪声、彩色图像量化、稀疏采样、色差和舒适噪声。该数据集的标注类型是DMOS,由971名观测者观察524340个样本,再通过统计的方式得到标注结果。DMOS的取值范围是[0,9],值越大表示图像质量越差。
3.1.4 CSIQ
CSIQ(Categorical Subjective Image Quality)[35]由美国俄克拉何马州立大学建立,其中包含分辨率为512像素×512像素的参考图像30幅,失真类型6种,包括整体对比度缩减、JPEG压缩、JPEG2000压缩、加性高斯粉红噪声、加性高斯白噪声和高斯模糊等,每种失真含有4~5个失真等级,共有866幅失真图像。数据集也提供了所有测试图像的DMOS值,由25位测试人员进行了多次主观评分统计得到。DMOS值取值范围为[0,1],值越大表示图像质量越差。
3.1.5 LIVE In the Wild Image Quality Challenge Database
LIVE In the Wild Image Quality Challenge Database是美国德克萨斯大学奥斯汀分校LIVE实验室建立的野外图像质量挑战LIVE数据集[33],其中包括1162幅图像。这些图像的失真类型不是计算机模拟产生的,而是使用智能手机和平板电脑等各种移动摄像头拍摄得到的真实图像。在成像过程中,这些图像会受到各种各样随机发生的失真和真实拍摄伪影的影响。为了保证这些图像的主观质量得分具有客观性,科研人员设计并实施了一个全新的在线众包系统,由8100位观测者进行IQA,得到了35万个意见分数,这些分数综合后作为评估结果。MOS值取值范围为[0,100],与LIVE数据集保持一致。
3.1.6 KonIQ-10k
为了解决真实失真数据集规模太小的问题,德国康斯坦茨大学建立了KonIQ-10k[39]数据集。从大型的公共多媒体数据集YFCC100M[54]中随机选择了大约1000万幅图像,然后分阶段筛选了10073幅图像,用于建立数据集。这些图像中存在的失真类型包括噪声、JPEG伪影、混叠、镜头运动模糊、过度锐化等。基于采集到的数据集,科研人员进行了大规模的众包实验,从1467名观测者中获得了120万个评价结果,用取均值、去掉极端分数等统计方法确定最终的MOS值。图像的尺寸为1024像素×768像素。MOS值的范围为[0,5],值越大表示失真越小。

表3 NR-IQA模型代表性数据集对比
3.2 性能评价指标
IQA有许多评价指标,其中PLCC、SROCC、KROCC和RMSE是目前最常用的IQA算法的性能评价指标,定义如下。
① 皮尔逊线性相关系数(Pearson Linear Correlation Coefficient,PLCC):
(3)
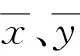
② 斯皮尔曼等级相关系数(Spearman Rank-Ordered Correlation Coeffcient,SROCC):
(4)
式中:rxi、ryi分别为两组得分各自数据序列中的排序位置。SROCC主要用于衡量算法预测的单调性。
③ 肯德尔秩相关系数(Kendall Rank Order Correlation Coeffcient,KROCC)
(5)
式中:nc为数据集中一致性元素对的个数;nd为数据集中不一致元素对的个数。KROCC也可以有效衡量算法的单调性。
④ 均方根误差(Root Mean Squared Error,RMSE):
(6)
式中:xi为主观MOS值;yi为质量预测得分。RMSE用于直接衡量人的主观得分和算法预测得分之间的绝对偏差。
4 代表性IQA模型的性能对比
本文对具有代表性的几种IQA模型在不同数据集上进行了对比。参与对比的模型包括经典的FRIQUEE[55]、DIIVINE[56]等,还有近些年具有代表性的MEON[57]、DeepIQA、DB-CNN、DeepBIQ、DeepRN、RankIQA等。本文选择PLCC和SROCC作为评价指标,表中实验结果均来自于参考文献,这些数据均在相同的数据集上测试得到。测试数据集既包括LIVE In the Wild Image Quality Challenge Dataset等真实失真数据集,也包括了LIVE、TID2013等模拟失真数据集。对比结果如表4~表6所示。
由表4可以看出,DeepBIQ和DeepRN取得了领先于其他方法的评价结果。这两种方法都基于“特征提取+回归”的框架进行NR-IQA。而对基于端到端框架的深度学习方法来说,DB-CNN性能最好。

表4 LIVE In the Wild Image Quality Challenge Dataset数据集上的SROCC和PLCC性能对比
由表5可以看到,RankIQA模型在两个指标上都取得了最好的结果,PLCC达到了0.982,SROCC达到了0.981。这也说明采用Learning-to-Rank的思路解决IQA问题具有很大的潜力。

表5 LIVE数据集上的SROCC和PLCC性能对比
由6可以看到,MEON模型的两个指标都取得了领先的结果,PLCC和SROCC都达到了0.912。综合以上各表数据可以看出,MEON、DB-CNN、DeepIQA等基于端到端框架的深模型可以较好地应对模拟失真数据集。而在自然失真数据集上,采取“特征提取+回归”框架的DeepBIQ和DeepRN模型取得了更领先的性能。

表6 TID2013数据集上的SROCC和PLCC性能对比
5 总结与展望
目前NR-IQA已经成为了研究的重点。NR-IQA的应用范围广,具有重要的研究价值,同时研究难度也更大,需要解决的问题也更多。随着研究的深入,研究人员已经提出了多种有效的NR-IQA方法和模型,在一些经典的模拟失真数据集上都取得了非常好的性能。但是在一些更具有挑战性的数据集,例如LIVE In the Wild Image Quality Challenge Database、KonIQ-10k等真实失真的数据集上,很多经典方法都没办法取得较好的结果。由于在大多数实际应用中失真类型很复杂,很难用计算机模拟生成对应的失真图像,所以面向真实失真的IQA应用空间更大。这种类型的评价任务还有很大的研究空间。
在未来的研究工作中,可以从以下3个方面深入开展研究。
① 基于端到端学习的NR-IQA方法虽然可以在人工模拟数据集中取得较好的测试结果,但是可扩展能力不强。例如基于Rank排序学习的NR-IQA方法在人工模拟失真数据集上效果较好,但是应用到真实失真类型的数据集时则效果不太理想。所以如何设计具有鲁棒性的IQA模型值得进一步研究。
② 目前已经有很多新的研究成果,这些方法往往在各种数据集中评价精度很高,但是实际评价结果和人眼的主观感受还有一定差距。如何使评价结果能够符合人眼视觉特性,与人的主观评价结果保持一致也值得深入研究[58]。
③ 由于主观图像质量得分需要用大量人员进行观察和统计,标注难度较大,所以通常IQA数据集规模较小。这种问题在真实失真数据集中尤其突出。所以如何使算法克服训练数据量不足的问题,训练出更适合人眼主观感受的质量打分模型值得进一步研究。
猜你喜欢
中共云南省委党校学报(2022年1期)2022-04-26 13:55:44
小学生优秀作文(低年级)(2020年4期)2020-07-24 08:31:16
疯狂英语·新策略(2019年10期)2019-12-13 08:43:28
当代陕西(2019年10期)2019-06-03 10:12:04
电子制作(2018年19期)2018-11-14 02:37:08
法律方法(2018年2期)2018-07-13 03:22:06
数学小灵通·3-4年级(2017年9期)2017-10-13 08:10:54
自动化学报(2017年11期)2017-04-04 02:52:58
噪声与振动控制(2015年4期)2015-01-01 07:08:21
河南科技(2014年23期)2014-02-27 14:19:15
