
基于YOLO 和单目深度估计的实时视频通信隐私保护
2022-04-26 02:51刘世军
通化师范学院学报 2022年4期
陈 晨,刘世军,沈 恂
人们日常使用实时视频通信如视频会议、网课、直播时,可能会将参会者身后的其他人员摄入画面,引发隐私保护问题,造成不必要的麻烦和尴尬.国内外视频会议提供商大多采用虚拟背景、背景模糊等方法对视频显示区域进行保护,但这些方法存在会完全隐藏背景环境信息的缺点,若定义距离摄像头较远的人员为非参会背景人员,改进目标是仅去除背景人员,保留背景环境.
为了从视频流中检测到不同人员并判别其距离摄像头远近,提出一个基于卷积神经网络的三任务深度学习系统,分别是:①目标检测,从视频中实时检测出不同人员;②语义分割,从视频中语义分割出不同人员实例,同目标检测的边界框(Bounding box)结合得到每位人员的实例分割;③单目深度估计,对每位人员实例或边界框估计深度,判别其是否为背景人员,再对其遮挡或模糊以实现隐私保护.
1 相关工作
系统的第一个任务是目标检测,按照是否生成候选框可以分为:两步法(Two-stage),如RCNN 及基于RCNN[1]改进的Fast-RCNN[2]、Faster-RCNN[3]等;一 步 法(One-stage),如YOLO[4]和SSD[5].一 步法 的 效 率 一 般 高 于 两步法,出于对实时性的考虑,编码器(Encoder)骨干网络(Backbone network)使用基于修改后的tiny-YOLOv3.
系统的第二个任务是图像分割,按照是否分割出单个实例可以分为:语义分割,如全卷积网络(FCN)[6];实例分割,如Mask-RCNN[7]、YOLACT[8]等.图像分割近年的改进是将简单的反卷积(Deconvolution)或上采样(Upsample)修改为解码器(Decoder)结构,加入跳级连接(Skip connection)实现高低层特征融合,解决细节缺失问题.本系统借鉴YOLACT 的思想,在语义分割的基础上叠加边界框,实例分割出图像中的不同人员.
系统的第三个任务是单目深度估计(MDE),基于单个摄像机的输入,将卷积神经网络(CNN)运用到单幅RGB 图像来预测深度图.先通过卷积神经网络的编码器(Encoder)获取高维特征信息,而后通过解码器获取原分辨率的预测图像.稠密(Dense)的深度估计与语义分割都是一种逐像素的分类任务,在深度估计中是预测某个像素属于哪一个深度,在语义分割中是预测某个像素属于哪一种物体,通过将不同深度或者物体分类的像素进行可视化渲染,获得人类易于理解的深度估计和语义分割图.
实践中可将以上三个任务在同个神经网络上进行联合训练、同时推理,这方面已进行了很多研究.YOLACT 同时进行目标检测和语义分割并最终合并两者结果实现实例分割.NEKRASOV 等在文献[9]中使用Light-Weight-Refinenet[10]作 为 骨 干 网 络,在 不 对 称 数 据 集上实现了实时的语义分割和深度估计,在NYU Depth v2(NYUDv2)和KITTI 上获得了很好的效果.CHEN 等则在文献[11]中实现了实时的三任务神经网络,在Cityscapes 数据集上实现了室外驾驶场景下同步的目标检测、语义分割和深度估计.
多任务计算机视觉网络经常使用深度可分离卷积,其在Google 的MobileNet[12]中提出.它可以保证与普通卷积同样运算结果的情况下,减少参数数量,降低运算量,加快推理速度.基本思想是将普通卷积分为两步,用深度卷积(Depthwise Convolution)降低分辨率,用点卷积(Pointwise Convolution)扩展特征图数量,获取高维特征.深度卷积的一个卷积核只独立地操作一个通道,点卷积可理解为1×1 的卷积,卷积核的尺寸为1×1×M,M为上一层的通道数,最终在深度方向上进行加权组合,生成新的特征图.网络中的所有非1×1 卷积操作都能使用深度可分离卷积替换.
2 网络结构
2.1 骨干网络
整个网络是解码器-编码器(Encoder-de⁃coder)结构,编码器的骨干网络是基于MobileNet的tiny-YOLOv3,解码器的设计参考了YOLACT,解码器的作用一是目标检测的多尺度预测,二是语义分割恢复原分辨率,最后将带深度信息的目标检测和语义分割叠加成最终输出.编码器和解码器加入跳级连接融合多特征,保证鲁棒性和精确性.系统命名为tiny-depth-YOLO,总体结构见图1.
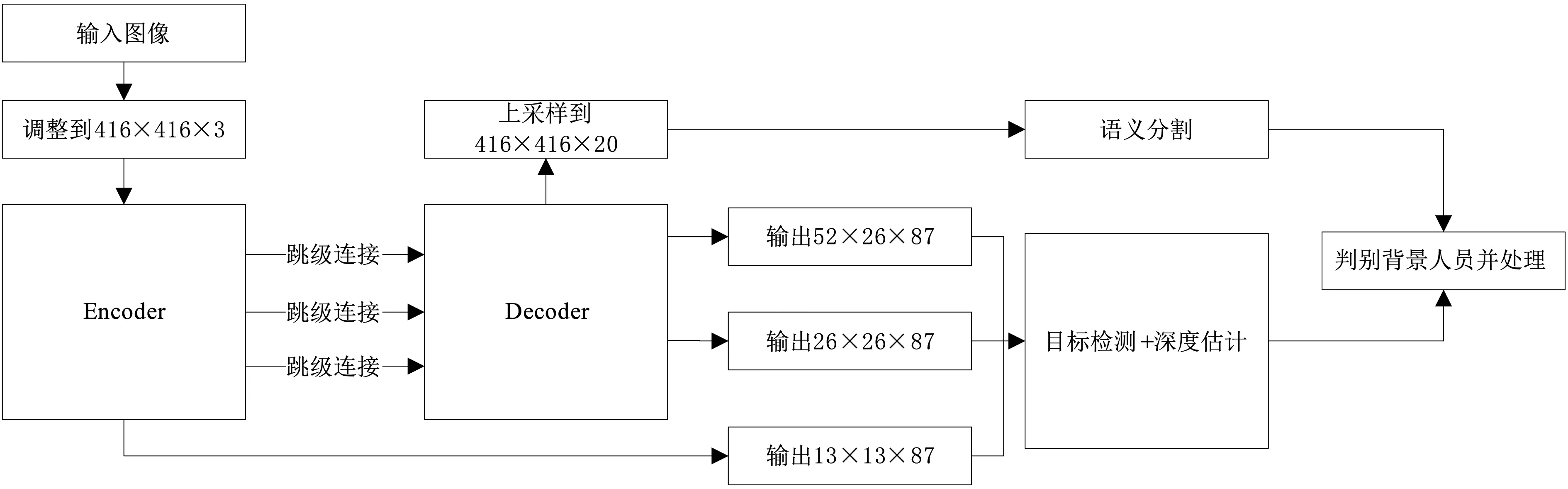
图1 tiny-depth-YOLO 系统总体结构
2.2 网络细节
tiny-depth-YOLO 只关心人员实例的相对深度关系,不需要稠密的深度估计图像,对每个检测到的边界框进行粗略的离散化深度估计,保留相对深度最浅的人员,其他被认为是背景人员进行遮挡和模糊.具体是将深度估计作为目标检测任务的一个模块,离散化数据集中的深度信息,根据深度图(Depth map)生成深度标签(Depth label),同YOLO 中的边界框、分类标签、置信度一同训练,在推理阶段一起进行回归,从而获得带有深度信息的边 界 框.FU 等 在DORN[13]中提 出 空间递 增 离散化,将8 位灰度值的真值深度(Ground-truth depth)按照空间递增的方法划分为5 个深度级别,回归问题转化为多分类问题.这种增距离散(Spacing-increasing discretization,SID)优于之前的等距离散(Uniform discretization,UD),解决了等距离散平均划分深度级别造成较大深度值下估计误差大的问题,实验证明增距离散划分对中短距离有更好的预测效果.
网络各层细节见表1.这里层的命名参考YOLO,Conv 表示卷 积层,每 个非1×1 的Conv层事实上都由深度可分类卷积组成,表中没有展示,Max pool 表示最大池化层,416×416×16 表示输出416×416×16 的张量,Route 12 表示将第12 层输出的特征图作为下一层卷积层的输入,Route 23 6 表示将第23 层和第6 层输出的特征图连接为52×52×256 作为下一层卷积层的输入.3 个YOLO 层进行预测,每个尺度3个锚框,YOLO 前的87 由3×(5+19+5)计算得到,表示3 个锚框,每个边界框的5 个参数,19个分类标签,5 个深度标签.
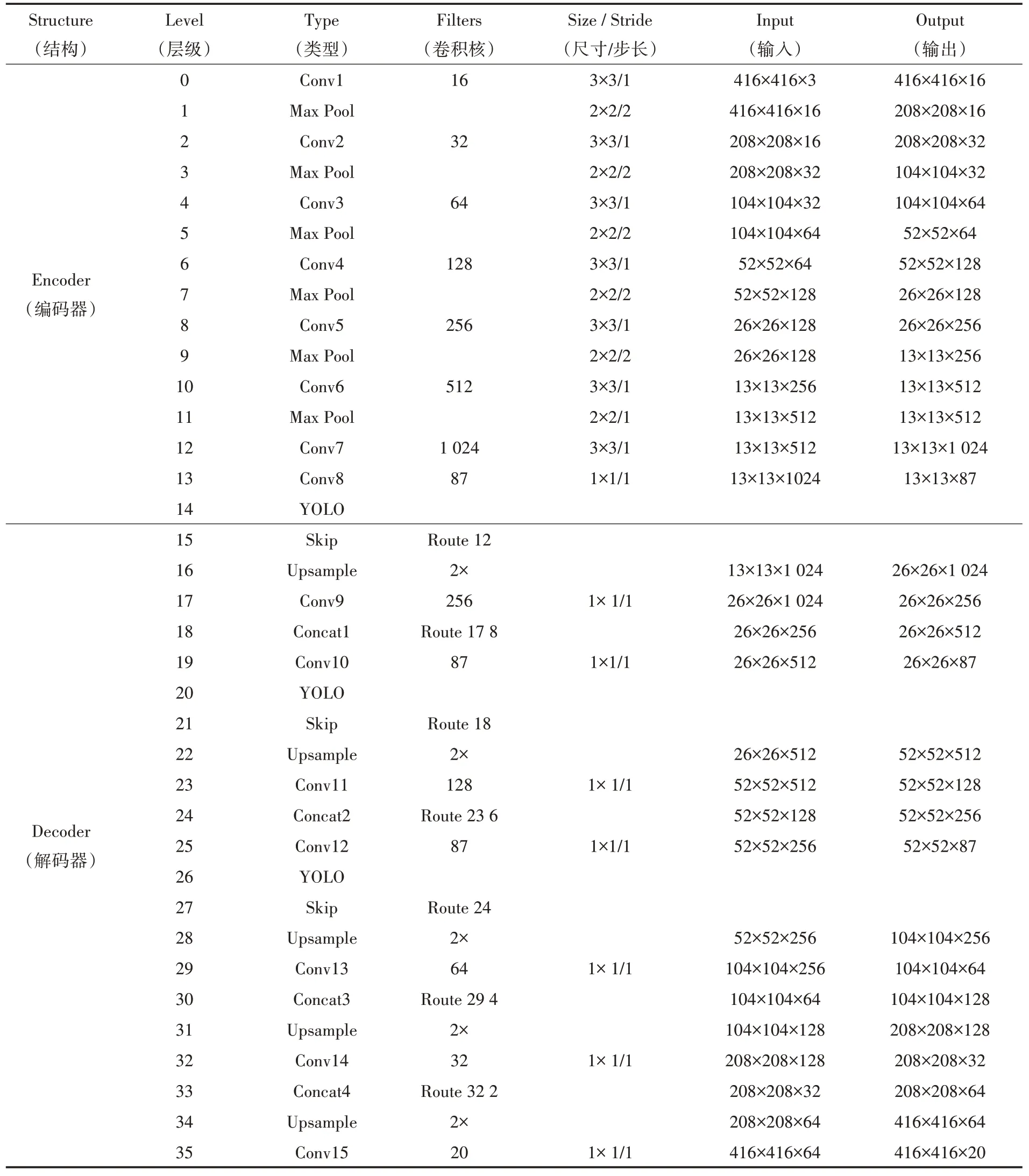
表1 tiny-depth-YOLO 网络各层细节
3 实验
3.1 数据集生成
本文的三任务网络要求数据集的标注应包括用于目标检测的边界框和类标签、用于语义分割逐像素着色和类标签,以及用于深度估计的逐像素深度信息.NYUDv2 数据集中仅有1 449 幅图像同时含有语义和深度标注(795 幅训练集,654 幅验证集),超过300 000幅图像只有深度标注.PASCAL VOC 2007(5 011幅训练集,4 952 幅测试集)则只有实例和目标检测标注,缺少深度标注.这样的数据集即非对称数据集.NYUDv2 缺少大量面对镜头的person 图 像,PASCAL VOC 2007 则 有 很 多,实时视频通信中面对镜头的person 是需要处理的主要目标图像,将两个数据集联合起来进行训练.
首先对两个数据集中的分类标签进行预处理.将NYUDv2-40 中的person 类保留出来,其他类映射到NYUDv2-13 的13 个类中(这13个类中没有person),加上保留的person 类,生成一个NYUDv2-14 的数据集.PASCAL VOC 2007原先有20 个类,考虑视频通信的应用场景,去除掉户外的分类,只保留bottle、cat、chair、dog、person、sofa、tvmonitor、diningtable、potteplant 这9 个类,同时chair、person、sofa、tvmonitor 分 别同NYUDv2-14 中的chair、person、sofa、tv 类 重复,所以认为它们是一类.将这些分类合并,最终获得的分类是19 类,均为室内场景目标.
其次将两个数据集的图像调整到一个固定大小(416×416).引入别的效果良好的神经网络,计算其在另一任务中的预测结果作为合成真值(Ground-truth)数据.训练时使用合成真值数据先预训练网络,然后再使用拥有两种真实标签的真值数据对网络调优.最终的数据集生成及训练步骤如下:
step 1 将NYUDv2 中1 449 幅标注图像(记作NYUDv2-labled-1449)和只有深度标记的图像(300 000 中随机选取2 000,记作NYUDv2-unlabled-2000)通过YOLACT 生成实例分割,取每个实例上的最小、最大x和y坐标,获取边界框.
step 2 PASCAL VOC 2007 的数据集通过FastDepth[14]生成稠密深度图,将5 011 幅原训练集分为3 011 幅的预训练集(记作PASCAL VOC 2007-train-3011)和2 000 幅的训练集(记作PASCAL VOC 2007-train-2000).
step 3 将NYUDv2 和PASCAL VOC 2007 中所有的深度图转换为深度标签,对每一个边界框,只取实例分割的像素,对其深度图使用DORN 的SID 生成离散的深度标签,并且认为一个边界框中的深度标签是相同的.
step 4 将NYUDv2-unlabled-2000 和PAS⁃CAL VOC 2007-train-3011 合并后输入网络,进行预训练.
step 5 将NYUDv2-labled-1449 中795 幅 训练集数据和PASCAL VOC 2007-train-2000 合并对网络进行再次训练调优.
step 6 使 用PASCAL VOC 2007 4 952 幅 的测试集和NYUDv2 654 幅的测试集测试.
在实验测试中,只训练person 类,效果并不如对多个类别进行训练,最终选定NYUDv2-13分类和PASCAL VOC 2007 分类的并集进行训练,具体已经在前文说明,只是在推理阶段输出检测和分割到的person 类并对其深度进行估计.
3.2 损失函数
损失函数由三部分组成,目标检测误差(Lobj)、深度估计误差(Ldepth)和语义分割误差(Lseg),目标检测错误使用YOLOv3 定义的损失函数,由三部分组成,分别是边界框坐标误差(Liou)、置信度误差(Lcoef)和分类误差(Lcls).YOLOv3 在论文中描述三者均是均方差(Sum of squared error loss,SSE),研究其开源实现,发现分类误差实际使用的是二值交叉熵(Binary cross entropy,BCE).对于深度估计误差,将深度图转换为深度标签,使得深度估计转换为分类问题,因此深度估计误差也使用BCE.语义分割误差使用softmax 交叉熵(Softmax cross entropy).整个损失函数的简略定义如下:
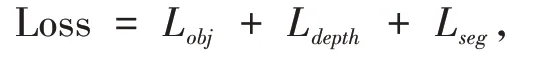
其中目标估计误差为:
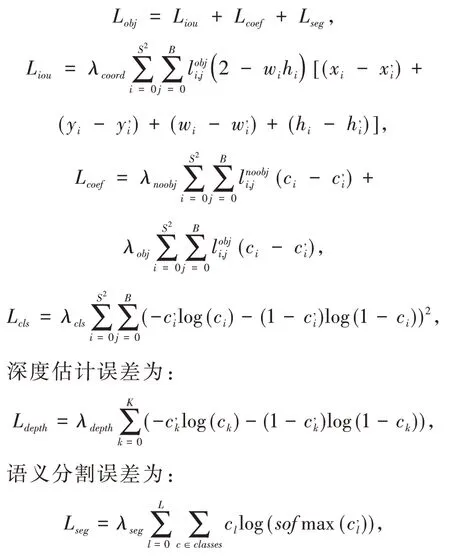
其中:带点上标的表示预测值,c表示不同分类,lobji,j表示i,j处边界框有目标则为1,否则为0,lnoobji,j定义相反,K表示图像中所有人员的边界框,L表示图像中逐像素个数.
3.3 最终训练标签
神经网络语义分割分支输出的是416×416×(19+1)的张量,19 是19 个分类标签,1 代表背景.目标检测分支最后的输出是一个S×S×B×(5+C+D)的张量,表示S×S个小格能预测B个框的5 个参数(w,h,x,y,coef)和C个分类,以及D个深度标签.B是3,每个尺度使用tiny-YOLO 的3 个 锚 框(Anchor box),C是19,D取5,分别标记为depth0,depth1,depth2,depth3,depth4,距离由近到远.应注意的是,最后输出的边界框对于不同的图像,可能最小的只有depth2,那么此时将大于depth2 的边界框中的人员算为背景人员,即最终只关心深度的相对关系.
3.4 实验结果及评价
系统使用PyTorch 实现,在i7 CPU、16G 内存、GTX 1650 的机器上进行训练.激励函数使用Leaky Relu 函数.预加载YOLO 官方提供的tiny-YOLOv3 的权重,然后冻结某些层,修改网络结构后继续训练.
(1)目标检测.计算机视觉领域多使用mAP(Mean average precision)来评价目标检测的效果.mAP 的本质是多类检测中各类别最大召回率平均值,也可看作是找到精确率-召回率(Precision-recall)图下面的面积.tinydepth-YOLO 同数种YOLO 实现比较目标检测的mAP,代码来自官方或著名开源实现,使用3.1 生成的数据集重新进行训练.IOU 阈值范围从0.5 到0.95,mAP-50 表示若IOU>0.5,认为是正样本,mAP-75 表示若IOU>0.75,认为是正样本.结果见表2(mAP 的值越大越好).
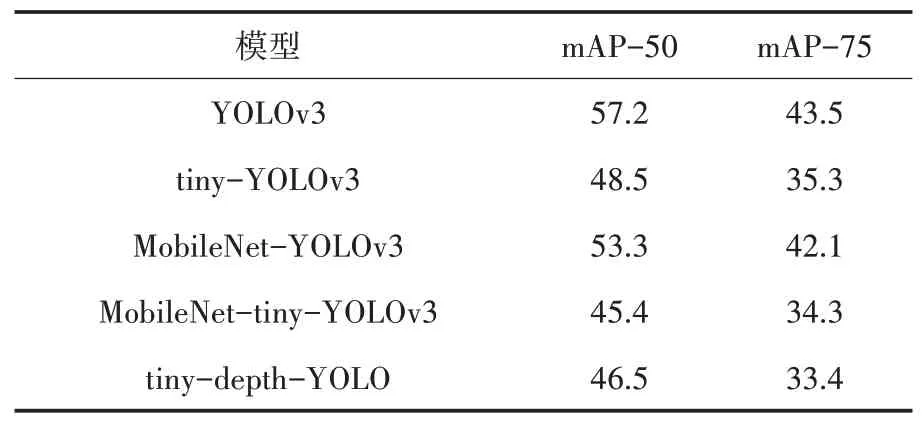
表2 数种基于YOLO 的目标检测网络mAP 同tiny-depth-YOLO 的比较
由 表2 可 知,tiny-depth-YOLO 的mAP 略低 于YOLO 和MobileNet-YOLO,同MobileNettiny-YOLO 处于同一水平,对视频通信中人员的检测达到了可用可信任的水平.
(2)语义分割.逐像素比较IOU,对比算法采用原论文开源代码或著名开源实现,预加载已训练好的权重,使用3.1 生成的数据集重新进行训练,检查person 类的IOU.结果见表3.

表3 数种语义分割网络IOU 同tiny-depth-YOLO 的比较
实验表明,tiny-depth-YOLO 的语义分割虽然比单任务、双任务算法有一定差距,但是同其他的三任务网络处于同一水平,配合目标检测,可以实现对人员的实例分割.
(3)深度估计.稠密的深度估计多使用RMSE 来评价输出的深度图,tiny-depth-YOLO使用DORN 的UID 将深度图离散化为深度标签,只关心深度标签的相对关系,因此深度估计的评价使用分类问题的评价标准,即比较每个检测正确的边界框(IOU>0.75)的深度标签和ground-truth 的深度标签,统计分类错误率和相对关系错误率.
深度分类错误考查单个边界框的深度标签分类是否准确,错误是指depth2 分类成了depth3.
深度相对关系错误则是考察整幅图像中数个边界框的原本相对关系是否被修改,假设画面中三个人员a、b、c 的深度标签分别是depth1、depth3、depth4,有三种分类情况:①depth1,depth1,depth4;②depth2,depth1,depth4;③depth1,depth2,depth4. 保 留 最 浅 深度标签的处理,只有①②的分类错误会影响画面最后的结果:①中第二个人员b 被当成了前景人员,没有处理;②中前景人员a 被处理了,背景人员b 没有处理;③中虽然b 的depth3被分类成了depht2,他依然会被算作背景人员.结果见表4.

表4 深度分类错误率和深度相对关系错误率
实验表明相对关系错误保持在了一个较低水准,可以根据深度信息判别视频通信中背景人员,为后续的模糊或者遮挡做准备.
(4)执行效率.前三个实验使用3.1 中步骤6 测试集中的单幅图像进行,下面使用网络公开的一些视频测试系统推理效率.在i7 CPU、16 G 内 存、GTX 1650 的 机器 上,在640*360 的分辨率下,帧数达到15.1 FPS,在1 280*720 的分辨率下,帧数达到10.3 FPS,基本达到了实时要求,可以应用于实时视频通信中的隐私保护.系统运行展示见图2.

图2 系统运行效果,使用灰色色块遮盖深度标签不是最低分类的人员
4 结论
tiny-depth-YOLO 是 基 于tiny-YOLOv3 提出的三任务神经网络,其主要工作在于:①将逐像素的稠密的深度图转换成稀疏的深度标签,直接回归出带有深度信息的边界框,同时进行目标检测、深度估计和语义分割;②进行数据增广,使用NYUDv2 和PASCAL VOC 2007双数据集进行联合训练以提高模型的泛化能力;③使用基于MobileNet 的YOLO 作为骨干网络,减少推理阶段的运算量.该系统在性能和实时性上达到了平衡,可以应用在实时视频通信中对背景人员的隐私保护.同时依然有改进方向:在目标检测、深度估计和语义分割三个子任务的性能方面,只是使用了一些基础的网络结构,近年来有很多提高其性能的实现方法,如果将这些修改引入该网络,可以进一步提高判别背景人员的准确性.在实时性方面,也可以引入TVM、TensorRT 等对系统结构进行自动优化,进一步提高推理速度.如何提升判别背景人员的准确性、提高推理速度是后续的研究方向.
猜你喜欢
儿童时代·幸福宝宝(2021年11期)2021-12-21
小学科学(学生版)(2021年4期)2021-07-23
现代装饰(2020年4期)2020-05-20
开放教育研究(2020年2期)2020-03-31
证券法律评论(2018年0期)2018-08-31
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
中国社会历史评论(2016年2期)2016-06-27
现代语文(2016年21期)2016-05-25
公民与法治(2016年10期)2016-05-17
