
结合双注意力和结构相似度量的图像超分辨率重建网络
2022-04-26 07:22:58黄友文
液晶与显示 2022年3期
黄友文, 唐 欣, 周 斌
(江西理工大学 信息工程学院,江西 赣州 341000)
1 引 言
图像超分辨率(Super-resolution,SR)重建技术是从单帧或多帧低分辨率(Low resolution,LR)图像中重建出高分辨率(High resolution,HR)图像的过程,是近年来计算机视觉领域的一个重要研究方向,经历了基于插值的、重建和学习3个发展阶段[1]。随着深度学习的发展,基于学习的图像超分辨率重建算法成为研究的热点。Dong等人[2]提出卷积神经网络的超分辨率(Super-Resolution Convolutional Neural Networks,SRCNN),通过3层卷积结构实现图像重建,但其网络层次太浅,不能充分提取图像特征,且它对超参数的变化非常敏感。Kim等人[3]提出极深卷积网络的超分辨率,将网络加深到20层,同时引入残差思想减轻了网络训练的负担,但增加网络深度会加大模型的参数量和计算量,产生梯度消失的问题。Kim等人[4]又提出深层递归神经网络(Deeply-Recursive Convolutional Network,DRCN),使用深层递归的方法,在卷积层间共享参数,缓解了梯度消失问题,但DRCN网络层间信息流动性较差,没有充分挖掘图像不同层次间的特征。Lai等人[5]提出基于Laplacian金字塔的超分辨率,该网络通过残差学习和逐级上采样恢复HR图像,移除插值放大的预处理,减少了图像重建时间。Lim等人[6]提出增强的深度残差网络的超分辨率,通过去除残差块中的批归一化层,扩大模型的尺寸来提升重建质量。Zhang等人[7]提出残差密集网络(Residual Dense Network,RDN),该网络通过密集连接的卷积层提取并融合局部特征,然后进行全局融合。Zhang等人[8]提出深层残差注意力的超分辨率(Residual Channel Attention Networks,RCAN),该网络在残差块中加入通道注意力,使模型能够学习更多通道特征,提高网络的判别能力。Ledig等人[9]提出超分辨率生成对抗网络(Super-Resolution Generative Adversarial Network,SRGAN),该算法通过两个网络交替迭代训练,但SRGAN生成的高分辨率图像相对原图较模糊。Wang等人[10]又提出增强的超分辨率生成对抗网络,该网络使用密集残差块作为生成网络的主体,获得了较好的重建效果,但生成的图像存在过多的伪细节。Xiao等人[11]提出可逆缩放网络(Invertible Rescaling Networks,IRN),将HR图像经小波变换分解为低频分量和高频分量作为网络的输入,同时网络在缩放过程中使用指定分布后的潜在变量,来捕获丢失的信息分布,然后以此逆变换重建HR图像,该方法能有效提升重建模型的性能。
为进一步解决LR图像到HR图像的映射函数解空间极大,导致SR模型性能有限,难以产生纹理细致、边缘清晰图像的问题,本文在U-Net模型[12]的基础上提出一种结合双注意力和结构相似度量的图像超分辨率重建网络。本文主要创新包括:(1)该网络引入针对低级别视觉任务的数据增强模块对训练集进行预处理,增加训练样本的多样性,提高模型的泛化能力。(2)在改进的U-Net网络模型中引入残差双注意力模块,将特征提取集中在关键位置和通道中,残差块能有效缓解由于网络加深造成的梯度消失问题。(3)结合对偶回归损失和结构相似度量的损失约束,增强网络约束,有效提高生成图像的质量。本文方法在客观评价指标上优于其他对比的方法,有效减少了映射函数可能的解空间。
2 结合双注意力和结构相似度量的超分辨率重建网络
2.1 数据增强
训练样本有限时,数据增强能够增加样本的多样性。目前常用的数据增强方法大多是为高级别视觉任务开发的,而超分辨率重建是一种典型的低级别视觉任务,需要根据全局关系决定局部像素点的处理方式。本文引入针对低级别视觉任务的数据增强方法,主要包括RGB、Blend、CutMix[13]、Mixup、CutMixup和CutBlur[14]。RGB是打乱RGB像素的排列;Blend是添加固定像素值;CutMix是随机切除图像中的一块区域,并使用另一个图像替换随机切除的区域,使图像的上下文边界产生急剧变换;Mixup是随机将两个图像按照比例混合;CutMixup方法结合了CutMix与Mixup,可以使边界效应和混合图像上下文信息的比率最小化;CutBlur是切割一个低分辨率图像块,并粘贴到相应的高分辨率图像区域。根据文献[14]中的结论,采用混合增强方法(MOA)显著提高了各种场景的性能,尤其当模型规模很大并且数据集是来自于现实环境中。
2.2 网络结构
本文提出一种结合双注意力和结构相似度量的超分辨率重建网络,网络结构如图1所示。
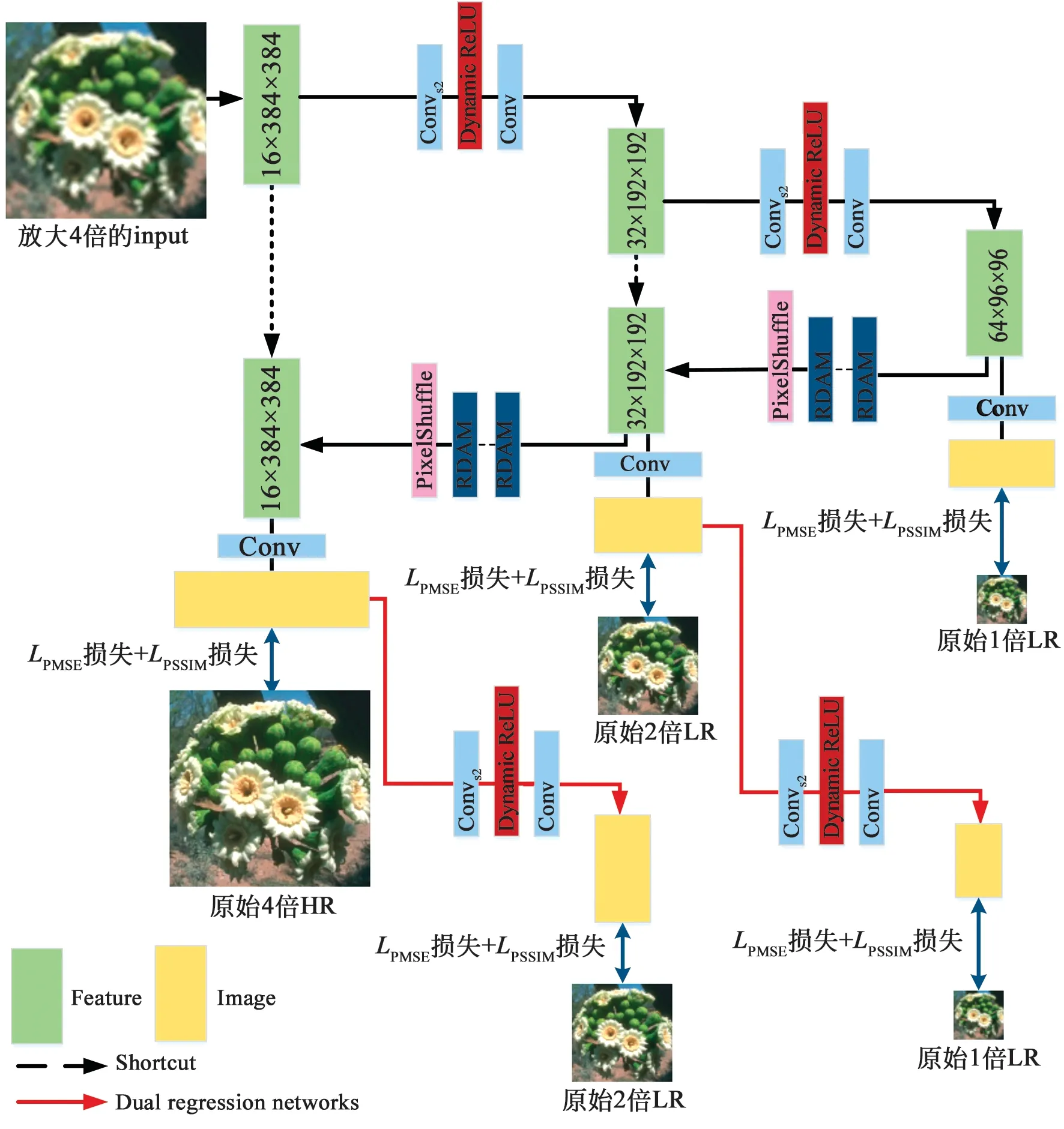
图1 网络结构Fig.1 Network structure
首先采用Bicubic方式对输入图像放大4倍,之后通过卷积提取该4倍图像的特征,维度是16×384×384。下采样模块由Convs2+Dynamic ReLU+Conv构成,其中Convs2是步长为2的卷积。通过下采样模块将输入特征逐级缩小,得到2倍和1倍的LR图像,下采样操作完成。生成的特征经过卷积层得到1倍的LR图像,与原始1倍LR图像比较,得到重建损失。上采样模块由30个RDAM模块和PixelShuffle构成,RDAM由残差和双注意力模块组成,将残差映射依次输入到双注意力模块中产生注意力权重,再经过残差块进行差值计算,通过原始输入和残差结果进行求和输出。PixelShuffle像素重组的主要功能是将一个输入为H×W的特征图通过卷积和多通道间的重组得到大小为rH×rW的特征图,其中r为上采样因子,r=2。通过上采样模块将输入特征逐级放大,生成2倍和4倍的图像,上采样操作完成。虚线箭头部分利用跳跃连接将下采样输出和上采样输入的特征图连接起来,相当于将低层特征拼接到相应的高层特征上,创造了信息的传播路径。图1中红色箭头部分表示对偶回归网络(Dual regression networks)[15],通过反向下采样操作得到2倍和1倍的LR图像,与原始的LR图像比较,得到对偶回归网络损失,增加网络的约束。蓝色双箭头部分表示本文损失函数的实现路径。
2.3 残差双注意力模块
何恺明等人提出残差网络(Residual Neural Network)[16],通过残差学习能有效简化模型训练,缓解网络加深造成的梯度消失问题。本文将残差块引入超分辨率重建网络中,与双注意力模块[17]构成残差双注意力模块(Residual Dual Attention Module,RDAM),结构如图2所示。
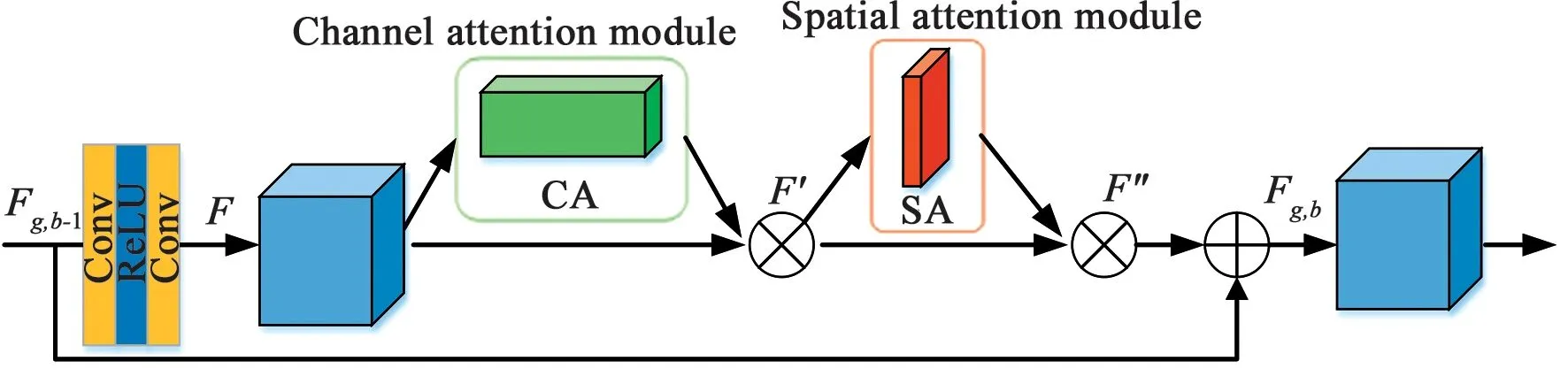
图2 残差双注意力模块Fig.2 Residual dual attention module
首先对输入特征进行卷积操作得到残差映射,完成特征维度匹配。由于Batch Norm对图像来说类似于对比度的拉伸,图像经过Batch Norm层后,其色彩分布会被归一化,破坏了图像原本的对比度信息,影响图像输出的质量。本文在残差映射块中去掉Batch Norm层,由两个标准卷积层和ReLU激活函数构成。其计算过程如公式(1)所示:
F=W1δ(W0Fg,b-1),
(1)
其中F表示从输入Fg,b-1中学习到的残差映射,δ表示ReLU激活函数,W0和W1分别表示残差块中卷积层的权重。
注意力机制是人类视觉所特有的大脑信号处理机制,其主要思想是强化特征,以获取更多关注目标的细节信息。图2中的注意力模块是由通道注意力 (ChannelAttention,CA)和空间注意力 (SpatialAttention,SA)依次级联的双注意力模块[17],从通道和空间两个维度提取注意力特征。
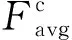
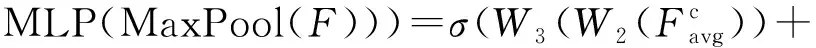
(2)
Mc(F)与输入特征信息F进行元素点乘运算得到F′,如公式(3)所示:
F′=Mc(F)⊗F.
(3)

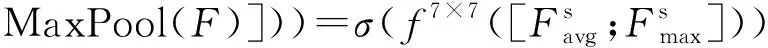
(4)
Ms(F′)与F′进行点乘运算得到最终残差注意力特征信息F″,如公式(5)所示:
F″=Ms(F′)⊗F′.
(5)
最后将此残差注意力特征信息与原始输入进行元素求和,如公式(6)所示,其中Fg,b-1和Fg,b分别表示残差双注意力模块的输入和输出。
Fg,b=Fg,b-1+F″.
(6)
2.4 激活函数
在神经网络中常用的激活函数有ReLU、LeakyReLU和PReLU等,这些激活函数的参数往往是固定的。文献[18]中提出Dynamic ReLU激活函数,该函数能够根据输入特征动态地调整对应的分段函数,有效提升了网络的表达能力。

(7)
(8)
2.5 损失函数
本文中改进的U-net网络的损失函数由对偶回归网络损失和重建损失两部分叠加组成,通过均方误差和结构相似度进行度量。
2.5.1 均方误差
均方误差表示生成图像与原始图像间存在的均方误差值(Mean Square Error,MSE),公式如式(9)所示,其中M与N分别为图像的高度和宽度,X(i,j)和Y(i,j)分别为原始图像和生成图像。
(9)
文中MSE损失公式如(10)、(11)所示:
(10)
(11)
其中:P(xi)为改进的U-Net网络,D(P(xi))为对偶回归网络,W=3是上采样逐级放大1倍、2倍和4倍;Q=2是反向下采样逐步缩小2倍和1倍。
2.5.2 结构相似度
图像之间的像素相似度往往不能充分反映重建图像的好坏,利用结构相似度(Structural Similarity,SSIM)能够衡量图像之间的结构相似程度,SSIM是对亮度、对比度和结构等不同因素间的整体估算,SSIM与人类视觉感知系统(Human vision system,HVS)相似。如式(12)所示:
(12)
其中:μx和μy为像素均值,是对亮度的估计;σx2和σy2为方差,是对比度的估计;σxy为图像的协方差;c1=(k1L)2;c2=(k2L)2;L是像素的取值区间,一般的k1=0.01,k2=0.03,L=255。SSIM损失计算公式如(13)所示,N代表图片数量:
(13)
本文中SSIM损失计算公式如(14)、(15)所示:
(14)
(15)
2.5.3 对偶回归网络损失
受对偶回归网络[15]的启发,引入对偶回归网络损失,用于评估重建图像经下采样得到的LR图像与参考图像的差异。通过生成4倍的HR图像进行下采样得到2倍和1倍的LR图像,与真实的LR图像比较,得到对偶回归网络损失LD,用于对偶回归网络的训练,如公式(16)所示,其中λ和β为权重参数,本文采用λ=0.1,β=10。
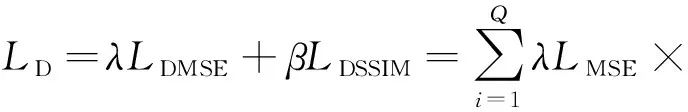
(16)
2.5.4 重建损失
重建损失是用于评估改进的U-net网络重建得到的图像与参考图像的差异,网络通过下采样得到1倍的LR图像和上采样生成2倍和4倍的图像,与真实的HR图像比较,得到重建损失LP,如公式(17)所示,α为权重参数,本文采用α=20。
(17)
对改进的U-net网络进行训练时采用公式(18)所示的总损失LTotal进行约束,其中LP为重建损失,LD为对偶回归网络损失。
LTotal=LP+LD.
(18)
3 实验及结果分析
实验平台硬件配置为Intel Xeon 3104处理器、16 GB内存、NVIDIA 2080Ti显卡,并使用64位操作系统Ubuntu 18.04 和PyTorch深度学习框架进行训练和测试。
3.1 数据集及设置
实验采用DIV2K数据集对网络模型进行训练,该数据集包含800张2K高质量图像。本文选取Set5、Set14、BSD100和Urban100为测试集,分别包括5,14,100,100张高分辨率图像。DIV2K数据集中每张高清图片都通过Bicubic操作得到了对应的缩小2倍和缩小4倍的低分辨率图像。对于每次训练迭代,本文以相同的概率从RGB、Blend、CutMix、Mixup、CutMixup和CutBlur这6种增强方法中随机选择一种增强方法对输入的训练数据进行预处理,增加了训练样本的多样性,进一步提升模型的泛化能力。在训练过程中,采用Adam优化函数来优化网络,其中β1=0.9,β2=0.99,网络的初始学习率设置为10-4,采用余弦退火算法对学习率进行自动调整。
3.2 客观实验结果分析
为验证算法的效果,本文采用峰值信噪比(Peak Signal-to-Noise Ratio,PSNR)和结构相似度(Structural Similarity,SSIM)来评估改进的网络。本文在Set5、Set14、BSD100和Urban100标准测试集上验证4倍超分辨率重建的性能,并与一些当前代表性的超分辨率重建方法进行比较,结果参见表1。其中对比方法的PSNR和SSIM数值均来自文献[19]中的结果。从表1可以看出,本文方法在4个测试集上的PSNR和SSIM数值均获得了较好的结果。对于Set5、Set14、BSD100和Urban100测试集,本文方法与SRCNN相比,PSNR分别提升2.06,1.36,0.87,2.24 dB,SSIM值分别提升0.036 5,0.036 6,0.032 9,0.083 7。与SRFBN相比,PSNR分别提升0.07,0.05,0.05,0.16 dB,SSIM值分别提升0.001,0.001 1,0.002 1,0.004 3。对于Urban100测试集,本文方法与DBPN相比,PSNR提升0.38 dB,SSIM值提升0.011 2。
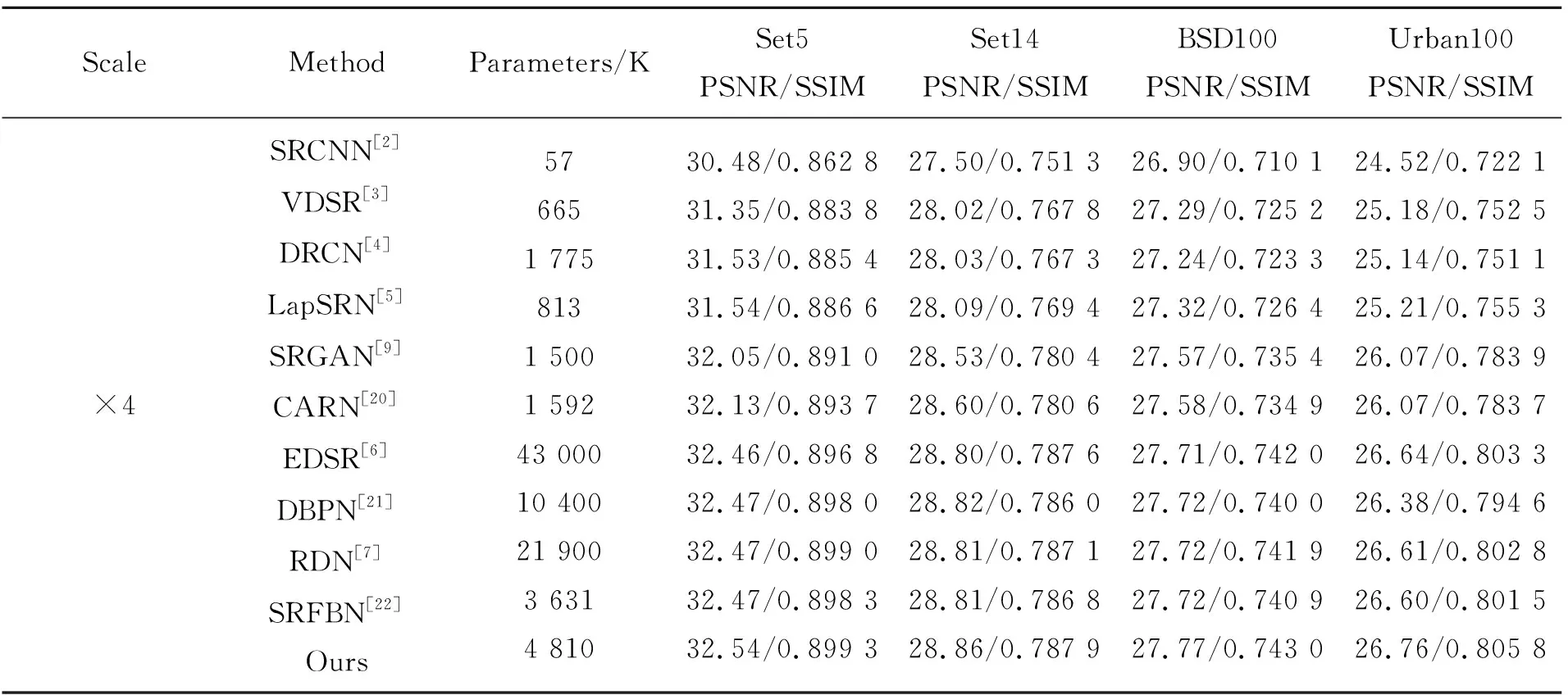
表1 各超分辨率方法的客观评价对比Tab.1 Objective evaluation comparison of various super-resolution methods
同时本文也比较了在Set5标准测试集下,不同超分辨率重建方法的参数数量和PSNR均值的关系,对比结果参见图3。其中SRCNN方法的网络结构只包含3层,故参数量较小,但其PSNR值最低。DBPN和RDN方法参数量较大,本文方法的参数量只有RDN的大约25%,本文使用较少的参数量获得了较好的重建效果。
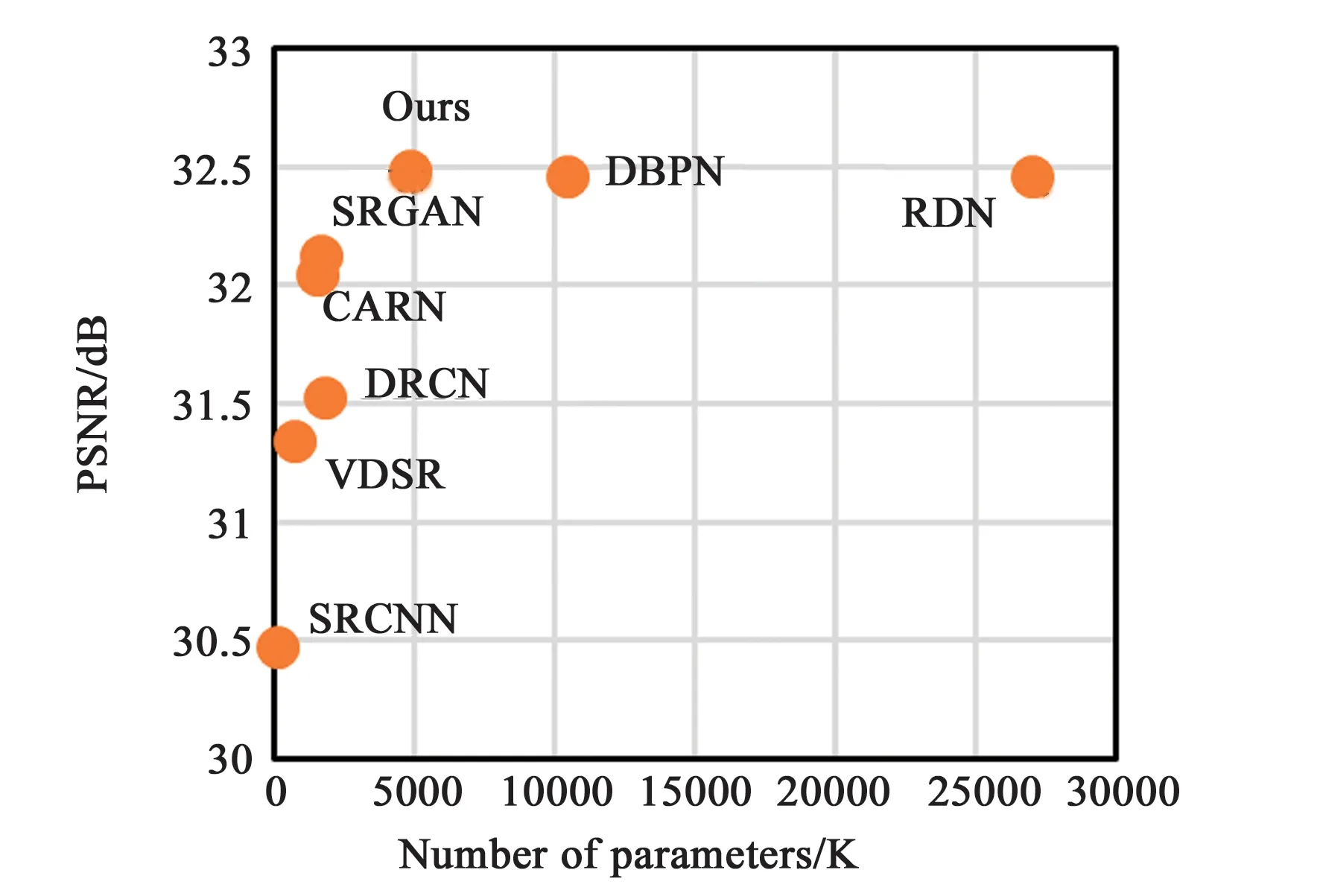
图3 Set5测试集下超分辨率重建方法的参数量和PSNR的关系Fig.3 Relationship between the number of parameters of the super resolution reconstruction method and PSNR under Set5 test set
3.3 RDAM模块对网络的影响
为验证RDAM模块对网络性能的影响,进行了5组4倍超分辨率重建实验,分别比较了网络中采用残差双注意力模块RDAM、仅采用残差通道注意力模块RCAB和3组空白对照实验:(1)None,不使用残差块和双注意力机制;(2)仅使用残差块,不使用双注意力机制;(3)仅使用双注意力机制,不使用残差块时,在4个标准测试集下PSNR和SSIM均值的变化。实验结果如表2所示,通过3组空白对照实验可以看出,网络在采用RDAM模块时,PSNR和SSIM数值均最高,可以说明当残差块和双注意力机制结合时,能有效地提升网络的性能。

表2 不同残差注意力模块对重建效果的影响Tab.2 Influence of different residual attention modules on the reconstruction effect
3.4 数据增强对网络的影响
为验证数据增强对网络的影响,进行了3组4倍超分辨率重建实验,分别比较了网络中不采用数据增强方法(None)、采用一种CutBlur增强方法和采用混合增强方法(MOA)时PSNR和SSIM均值的变化。从表3可以看出,在4个标准测试集中,采用混合数据增强方法(MOA)与不采用数据增强方法(None)相比,平均PSNR提升约0.15 dB,平均SSIM提升约0.003 7。

表3 不同数据增强方法对重建效果的影响Tab.3 Influence of different data enhancement methods on the reconstruction effect
3.5 损失函数对网络的影响
为验证损失函数对网络性能的影响,进行了5组4倍超分辨率重建实验,分别比较了网络中采用本文的损失函数LP+LD和4组对照实验:(1)仅对网络采用重建损失约束LP;(2)仅对网络采用对偶回归网络损失约束LD;(3)仅对网络采用MSE损失约束LPMSE+λLDMSE;(4)仅对网络采用SSIM损失约束αLPSSIM+βLDSSIM时,在4个标准测试集下PSNR和SSIM均值的变化。实验结果参见表4,可以看出,网络采用本文的损失函数LP+LD时,PSNR和SSIM数值均最高,说明对改进的U-net网络采用重建损失LP和对偶回归网络损失LD共同约束时,能最大化提升网络的性能。
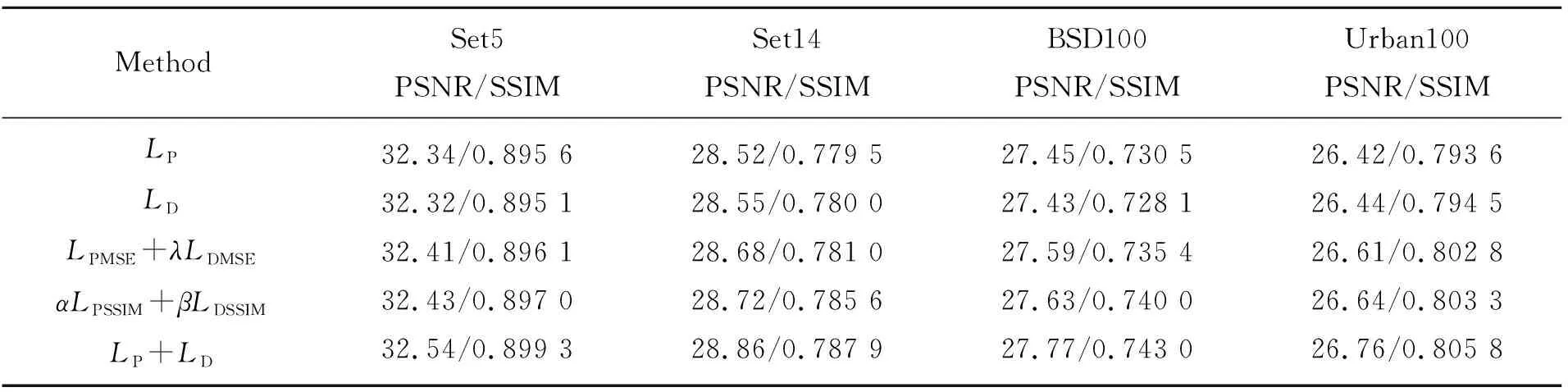
表4 不同损失函数对重建效果的影响Tab.4 Influence of different loss functions on the reconstruction effect
3.6 主观实验结果分析
PSNR和SSIM客观评价图像质量的结果与人眼主观视觉感知不是完全一致的。为了验证本文方法的有效性,本文与其他超分辨率重建方法对比,在Set14、BSD100和Urban100测试集上选取部分图像的4倍超分辨率重建结果,参见图4。便于观察,本文将对比图像进行了局部裁剪和放大。其中,红色方框中图像是放大区域,各重建方法标注在图像的下方。
从主观视觉效果可以看出,本文方法重建后的超分辨率图像效果优于其他的方法,更好地恢复了图像的边缘和纹理,使细节清晰可见。在图4(a)中,对于银饰和难以恢复的衣领细节,SRCNN和VDSR方法遭遇边缘失真的现象,DRN方法重建的图像较为清晰,但本文方法对于弯曲的银饰细节上恢复效果更好,观感接近原图。在图4(b)中,对于斑马纹理细节,SRCNN方法学习到的高频特征少,恢复的图像边缘较为模糊,DBPN方法重建出的蝴蝶纹理出现了一些噪点,本文方法重建出的斑马画面更加纯净,接近原HR图像。在图4(c)中,对于石块纹理的细节,SRCNN和VDSR遭遇了不同程度的边缘失真,本文方法相对于DBPN和RDN,能够重建更锋利的石块边缘细节,效果接近原图。在图4(d)中,本文方法相对于其他的方法,在玻璃窗和难以恢复的树枝细节上,表现得更加清晰,边缘细节更丰富。
4 结 论
由于图像超分辨率重建映射函数的解空间极大,往往导致重建模型性能有限,不能产生纹理细致、边缘清晰的图像。本文提出了一种结合双注意力和结构相似度量的图像超分辨率重建网络。该网络采用残差双注意力模块,结合数据增强方法、自适应参数线性整流激活函数,增加均方误差和结构相似损失约束,有效提高了生成图像的质量,使生成的图像更逼近真实图像。实验结果表明,本文方法对比SRCNN方法,在Set5、Set14、BSD100和Urban100测试集上的平均PSNR提升约1.64 dB,SSIM提升约0.047。本文方法能够更好地重建图像纹理和边缘细节,在客观评价和主观视觉上获得了较好的效果。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23 13:26:48
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
北京航空航天大学学报(2020年10期)2020-11-14 09:26:02
自动化学报(2019年6期)2019-07-23 01:18:32
数学物理学报(2019年3期)2019-07-23 01:15:40
家庭影院技术(2018年9期)2018-11-02 05:31:32
传媒评论(2017年3期)2017-06-13 09:18:10
自动化学报(2017年5期)2017-05-14 06:20:52
成都信息工程大学学报(2017年6期)2017-03-16 03:04:32
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
