
一种基于运动分析的行人异常行为检测*
2022-04-26 03:22秦彬鑫万文明
电讯技术 2022年4期
秦彬鑫,路 红,邱 春,万文明
(南京工程学院 机械工程学院,南京 211167)
0 引 言
随着人工智能和计算机视觉领域的蓬勃发展,基于视觉的异常行为检测成为研究热点[1-2]。在交通安全领域,通过异常行为检测技术可以监控到车内外的异常情况,从而减少交通事故[3];在公共场所安全领域,该技术可用于判断公共场所人员是否摔倒等异常行为,提高公共安全[4]。由于异常行为的少数性和不可预测性,并且复杂的视频场景和运动目标的不同姿态,影响着行为检测的精准性[5]。因此,准确检测、标识运动目标并且及时判断视频中出现的不正常情况是异常行为检测的关键[6]。
国内外学者在该领域开展了大量研究,取得了一系列成果。异常行为检测算法大致可以分为基于模型和基于规则的检测方法。基于模型的异常行为检测方法[7]基础是数据的驱动,从采集到的视频图像序列中的正常样本进行模型建立,所有在异常行为检测时将偏离建立好的正常样本判定为异常,但该方法容易造成运算资源浪费[8]。基于规则的异常行为检测方法[9]是自定义规则去判断目标行为,比如通过提取采集到图像的全局光流强度作为特征,结合统计图像熵在正常状态下的参数区间从而判定是否发生异常行为。但此类方法存在不足:当背景图像不稳定时,目标检测的准确性较低;对有光照等的复杂场景具有局限性;缺乏基于深度学习方法的特征选择的可解释性;计算复杂度高,运算时间长。
与以上方法不同,本文提出一种基于运动分析的异常行为检测方法,主要贡献有:利用三帧法建立背景模型,获取连续三帧图像中的像素信息进行背景图像重构,实现自适应背景更新,同时增加大津法自动获取最佳阈值,在保证环境自适应前提下利用背景差分准确提取前景目标;融合质心差值、外接矩形宽高比和倾斜角度的多个特征,设定不同行为的判定规则,判断是否发生异常行为,并设置预警检测方法,当行人将要发生异常行为时,发出警报声。
1 基于运动分析的异常行为检测
1.1 总体算法流程
算法流程如图1所示。

图1 本文总体算法流程图
1.2 运动目标检测
1.2.1 图像预处理
为去除阴影的干扰,本文根据HSV颜色空间前后阴影处像素点的差异,将阴影消除[10]。首先利用式(1)将像素颜色信息从RGB转换到HSV颜色空间:
(1)
式中:H表示色调,分量规范化在0°~360°;S、V分别表示饱和度和亮度,将S和V分量规范化在0~1。
再进行式(2)的阴影检测:
(2)
式中:SHSV(x,y)表示阴影检测结果值,SHSV(x,y)的值为1时判定为阴影部分;Hk、Sk、Vk表示第k帧图像在HSV空间H、S、V分量的值;Hb、Sb、Vb表示背景图像在HSV空间H、S、V分量的值;TH、TS、λ、μ为阈值。
1.2.2 背景建模
帧差法运算简单快速且对场景具有较强的适应性,但在灰度信息变化不大的场景中容易产生空洞。本文引入三帧法建立初始化背景模型。首先采集n帧视频图像序列,利用加权平均法对第k-1、k、k+1帧图像进行如式(3)的灰度化处理得到灰度图像ta(x,y):
ta(x,y)=0.299Ra(x,y)+0.587Ga(x,y)+
0.114Ba(x,y)。
(3)
式中:a=k-1,k,k+1;Ra(x,y)、Ga(x,y)和Ba(x,y)分别为第a帧图像的R、G和B三个分量的值。
然后进行如式(4)的运算,得到二值图像:
Ck(x,y)=|tk(x,y)-tk-1(x,y)|∩|tk+1(x,y)-tk(x,y)|。
(4)
式中:Ck(x,y)为二值图像,tk-1(x,y)、tk(x,y)和tk+1(x,y)分别为第k-1、k、k+1帧图像的灰度图像。
创建全部像素值为1的初始化背景模板和全部像素值为0的初始化背景图像,由式(4)分离第k帧图像的静止区域和前景目标区域。若当前像素值为0,则将该位置的灰度像素值更新到初始化背景图像中,并将背景模板的对应位置的像素值置为0。当k≤n时,继续对第k-1、k、k+1帧进行如式(4)的运算,若存在未填充的背景像素,则将该位置的像素及其周围8邻域的点都填充到初始化背景图像中,同时背景模板对应位置的像素值置为0;若不存在,继续对其余帧进行差分,直至背景模板中非零像素的个数小于设定的阈值时,背景模型建立完成。当k>n时,若背景建立完成则输出背景图像并保存;若背景仍不完整,将最靠近该像素点的邻近点作为背景像素点更新到对应初始化背景图像中,直至背景模板中非零像素的个数小于设定的阈值。
同时,为保证在复杂场景下的背景学习能力,提取连续三帧图像中的背景像素进行背景重构。若根据式(4)求出的前景目标的像素值变为0,且当前位置的背景像素值也为0,则认为该处为背景部分,并将背景模型中的对应位置的像素值置为0,实现背景图像的自适应更新,增强了在复杂场景下的背景模型的稳定性和环境适应性。
图2给出了常用的背景建模方法(均值法、混合高斯法)与本文方法的对比。混合高斯法不仅运算量大且容易产生噪声点,建立的背景模型模糊;均值法容易受环境影响,建立的背景模型与实际相差较大,尤其在第80帧的图像中还残留之前帧的运动目标部分;本文方法通过背景像素的不断填充融合,在第80帧时已经建立稳定的背景模型。与混合高斯、均值法相比,本文方法建立模型的速度更快、更稳定且贴合于实际场景。

图2 背景建模的对比
1.2.3 前景目标检测
Otsu法[11]计算简单且不受图像亮度的影响,本文使用该算法自动获取最佳阈值。假设图像IM×N在(x,y)位置的灰度值为f(x,y),当灰度值i的总像素数为n时,对应的灰度出现的概率为
(5)
式中:g(i)为灰度值i出现的概率,灰度i范围为[0,L-1],M×N为图像I的总像素数。
接着利用阈值T将像素分为C0和C1两部分,此时C0部分出现的概率为
(6)
式中:w0为C0部分的概率,C0部分由灰度值在[0,T-1]的像素组成。
C1部分出现的概率为
(7)
式中:w1为C1部分的概率,C1部分由灰度值在[T,L-1]的像素组成。

(8)
(9)
(10)
式中:j为在[0,L-1]选取的最佳阈值,T=j时,方差σ2(j)最大。
得到背景图像b(x′,y′)后,与当前帧进行如式(11)的差分运算:
(11)
式中:fk(x′,y′)为第k帧的图像,cf,b(x′,y′)为含有运动目标的二值图像。
最后对cf,b(x′,y′)进行如式(12)的形态学处理,去除图像中存在的噪声点及目标的空洞部分:
(12)
式中:Close()表示形态学开运算,Open()表示形态学闭运算。
选取标准公共数据库WEIZMAN、庭院Courtyard、UCF-ARG 数据集和国际标准数据集subway的不同场景,将本文方法与帧差、背景差分法进行对比,结果如图3所示。

(a)WEIZMAN场景的目标检测结果对比
其中,图3(a)~(d)的第1行为原始图像,第2~3行分别为背景差分、帧差法和本文方法的检测结果。图3(c)场景的背景比图3(a)的背景更加复杂且前景目标与背景颜色特征相似,此时利用帧差法检测到的目标不明显,如图3(c)第163帧的目标检测丢失;背景差分法比帧差法检测的目标轮廓更加清晰,但目标存在拖影现象,如图3(c)第26帧产生严重的目标拖影;而本文方法在面对背景复杂场景时,不仅可以较好检测出目标,不造成目标丢失,并且不会因为拖影、目标丢失而影响进一步的行为检测。图3(b)中存在光照影响,利用背景差分法检测的目标因受光照影响而检测出不属于目标的部分;帧差法与背景差分相比,能够较好地适应光照的影响,但检测的目标不够完整;根据帧差法具有较强环境适应性和背景差分法检测准确性高的优点,在有光照影响的场景中也能较好的检测出运动目标,如图3(b)第2列的第27帧检测结果对比图。图3(d)是多目标检测的结果对比,利用帧差法检测的目标缺失严重;背景差分法稍优于帧差法,能够检测出部分目标,但容易漏检且出现拖影,如图3(d)第70帧中背景差分法只检测到场景中的4个目标,其他目标丢失;本文方法相较于以上两种方法可以更完整、更清晰地检测到目标,如图3(d)第1帧的检测结果,本文方法检测的目标更完整。
1.3 异常行为检测
1.3.1 运动目标标识
为更好标识目标,提高行为检测的准确性,本文以行人为检测对象,如图4中利用最小面积和垂直于地面的两种外接矩形完整描述人体轮廓,对人体进行拟合。当人正常行走时,两个矩形重合(图4(a));当行人行为变化时(如图4(b)行人弯腰),最小外接矩形会随着人体变化而发生倾斜。

图4 目标标识
1.3.2 运动目标特征提取
为有效检测异常行为的发生,基于两种外接矩形对人体进行分析,通过提取三个区域特征(质心、矩形宽高比、倾斜角度)对人体运动状态进行描述。
(1)质心的差值分布
质心的位置可以准确反映人体所处位置,并且不受人体姿态等变化的影响。假设运动目标的外接矩形区域为rect,按式(13)求出质心坐标:
(13)

再求出质心的差值分布β:
(14)

当行人正常行走时,质心高度变化平稳,β处于一个较小的范围;当行人奔跑时,质心忽高忽低,β的值会不稳定;当行人发生摔倒时,质心逐渐下降,β的值会突变,明显变小。
(2)矩形的宽高比
运动人体行为发生变化时,其最小外接矩形框也会发生一定变化。比如,当运动人体发生摔倒时,矩形的宽W和高H会发生变化,结合图4可求得宽高比B:
(15)
式中:xAa和yAa(a=1,2,3,4)分别为矩形区域rect在x轴和y轴上的坐标值。
当行人正常行走和奔跑时,最小外接矩形的H的值远远大于W的值,则B的值明显小于1;当行人发生摔倒时,行人高度降低,H的值会逐渐减小,W的值增大,此时矩形的宽高比B的值会大于1。
(3)矩形框的倾斜角度
定义如图5所示的倾斜角度φ(φ∈[0,π])。
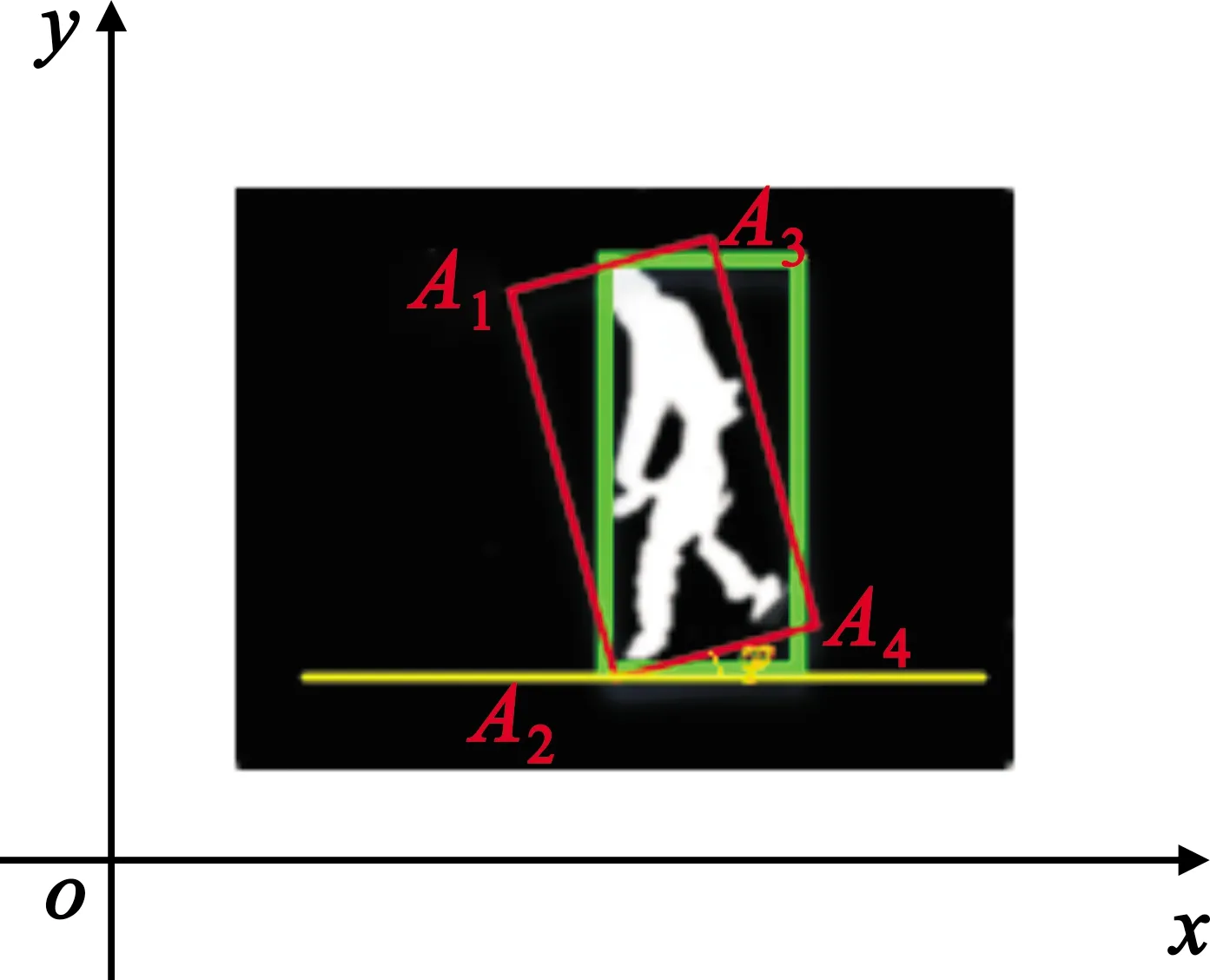
图5 运动人体的倾斜角度
根据式(16)计算出倾斜角度φ,根据φ的变化判断行人是正常行走、奔跑还是摔倒。
(16)
利用投影法将含有目标的二值图像投影到x-y轴上,其中,x1和y1分别表示点A1的横纵坐标值,x2和y2分别表示点A2的横纵坐标值。
当行人正常行走时,矩形框垂直于地面,不发生倾斜,倾斜角为90°;当行人发生奔跑时,此时人体会向前后倾斜,其中前倾斜角比后倾斜角度大,前倾斜角不会小于45°,后倾斜角相对较小,一般不会超过20°,因此倾斜角度基本维持在一定的范围;当行人忽发摔倒,人体向前倾斜摔倒时倾斜角度为(0°,45°),人体向后倾斜时倾斜角度在(145°,180°)范围内。
1.3.3 设定行为的判定规则
不同行人的外接矩形宽高比之间存在较大差异,人体质心在正常行走时一般保持恒定,在奔跑或者摔倒时的质心和倾斜角度会有明显变化,因此本文融合1.3.2节中提取的多个特征,设定检测行人行为的判定规则,更好地反映行为的本质特点,并在多种应用条件下进行运动行为分析,提高异常行为识别的准确率。主要对行人正常行走、奔跑、摔倒的行为进行实验。
定义一个集合F{f1,f2,f3}帮助区分正常和异常行为,其中f1、f2和f3分别表示行人正常行走、奔跑和摔倒的判定规则,如式(17)~(19)所示:
(17)
(18)
(19)
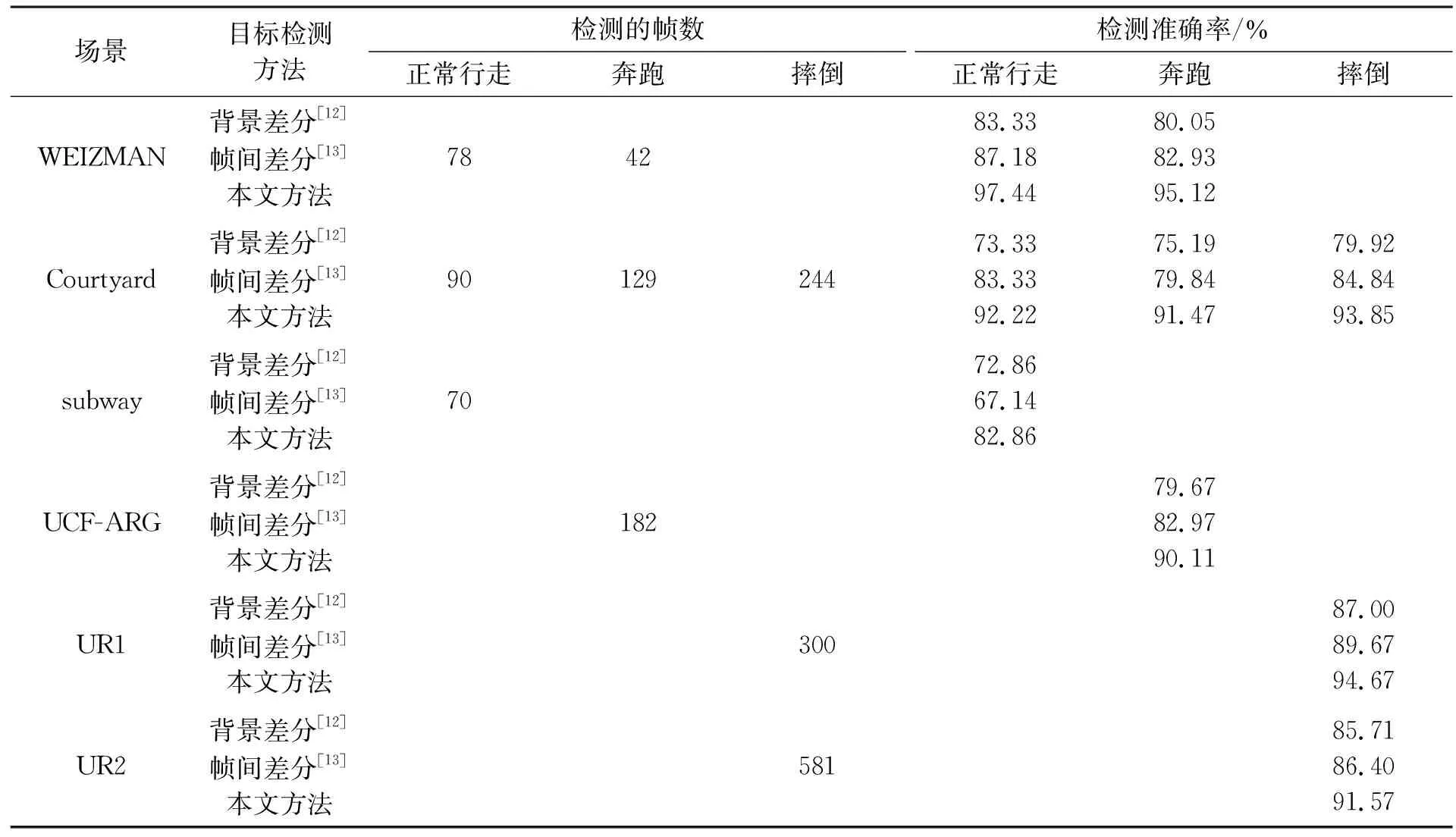
式(17)~(19)中的“0”和“1”表示没有发生和发生正常行走、奔跑、摔倒的行为。当满足1 为了测试视频中行人行为的检测性能,本文所有实验均在Windows 10、Matlab R2018b操作系统下完成;采用标准公共数据库WEIZMAN、庭院拍摄的视频Courtyard、UCF-ARG数据集、跌倒数据集UR和国际标准数据集subway,其中视频序列Courtyard主要面临的挑战为光照不均,WEIZMAN和UCF-ARG主要面临的挑战为背景环境的复杂程度,subway主要面临的挑战为目标数量较多,UR主要面临的挑战为不同角度的摔倒检测。利用本文方法在不同场景中进行检测,利用绿、红色矩形框标识运动人体并用绿、红色字体表示当前发生的行为,用“!!!”作为系统的预警,表示该视频中的行人可能要发生异常行为,图像左上角表示帧数。 检测行人正常行走的实验结果如图6所示。图6(a)的场景较为简单且为单目标检测,检测目标框能够完整包围行人且能够正确检测出行人行为,此时行为检测准确率较高。与图6(a)相比,图6(b)由于光照影响产生阴影,本文方法能够较好地抑制阴影,图6(b)第73帧的外接矩形框未完全拟合行人,但总体不影响对行为检测。与图6(a)、(b)两个场景相比,图6(c)的场景中的行人数量较多,属于多目标检测,图6(c)第2帧中身穿黑衣服的行人与背景的颜色特征相似,导致漏检,第41帧中目标大部分离开场景,不认为是正常行为。总体而言,本文融合多特征进行行为检测的方法能较为准确地定位和检测出场景中行人的行为,尤其是对单目标的检测。 图6 行人正常行走的检测结果 检测行人奔跑的实验结果如图7所示。图7(a)为较简单的WEIZMAN场景,融合多个特征进行行为检测的方法能够准确检测出行人行为。图7(b)为存在光照影响的Courtyard场景,由于光照而产生阴影的影响,图7(b)第31帧的矩形框未能完全拟合行人,但对整体的行为检测没有造成太大影响,因此本文方法在有光照影响的情况下具有可行性。图7(c)的UCF-ARG场景的部分背景区域特征与目标特征相似,但仍能较好地定位行人位置并准确判定出行为。面对图7(a)、(b)和(c)场景中的行人大小、奔跑角度和高度等各不相同的问题,本文方法对行人的奔跑行为检测仍能取得良好的效果。 图7 行人奔跑的检测结果 检测行人发生摔倒的实验结果如图8所示。图8(a)UR1场景的第69~150帧时,检测到行人正常行走时忽然摔倒,此时的β、B和φ符合设定的摔倒规则,到第226帧时,行人自己慢慢站立起来,此时β、B和φ符合设定的预警规则,出现红色的“!!!”并发出声音进行警告,与图8(b)Courtyard场景的第74帧和图8(c)UR2场景的第324帧类似,行人将要摔倒,系统进行预警。图8(c)UR2场景的第581帧中,能够完整检测行人,未将与行人颜色特征相似的外套检测成行人部分,可以看出,本文方法有较高的检测准确性和鲁棒性。在图8(a)、(b)和(c)中,不管是行人的摔倒方向、姿态还是行人的正面与背面,利用本文方法都可以较为准确地检测出来,并且对有可能发生的异常行为进行预警,保证了视频中行人的人身安全。 图8 行人摔倒的检测结果 为测试本文方法检测行人行为的准确性,定义检测准确率P如式(20)所示: (20) 式中:W为检测次数,A和B分别为正常和异常行为检测正确的次数。该检测准确率可以直观反映本文方法行为检测的准确性。为更好地表现本文目标检测方法的准确性,表1给出了不同目标检测方法的对比实验结果。 表1 不同目标检测方法下的行为检测准确率对比 表1中采用标准公共数据库WEIZMAN、自己拍摄的庭院视频Courtyard、UCF-ARG数据集、跌倒数据集UR和国际标准数据集subway。分析表1的实验数据可知,不管是不同场景还是不同的目标检测方法,由于行人奔跑的幅度不够大,质心的差值和倾斜角度变化不明显,导致奔跑行为的检测准确率比行走和摔倒行为低高,但在本文方法的平均检测准确率达到92.23%。由于背景差分法对应用场景具有较高的要求,帧差法具有较好的环境适应性,因此在存在光照影响的Courtyard场景中,帧差法比背景差分的检测准确率高,本文提取帧差法良好的适应性和背景差分检测准确性高的优点并进一步改进,最后在有光照场景中的三种行为的平均检测率达到92.51%;UCF-ARG的场景环境较为复杂,目标在移动过程中会与背景的部分颜色特征相似,此时背景差分法容易造成漏检,帧差法容易产生空洞无法对前景目标进行精确提取,造成行为检测准确率的降低,而本文方法可以较好地克服以上问题,准确率提高约10%;UR1和UR2的场景分别为行人不同姿势的摔倒,由于UR2场景背景更为复杂且场景中行人在穿衣过程中摔倒,衣服的颜色特征与行人相似,容易产生误检,但相较于背景差分和帧差法,本文方法的检测准确率提高约6%;subway场景的目标较多并且背景区域的颜色特征与部分行人相似,导致漏检,相比于单目标的检测,多目标的检测准确率较低。综上所述,目标检测的准确性是行为检测的关键,本文方法可以建立稳定的背景模型,准确描述目标轮廓,提高目标检测的准确率,有利于提高家庭、实验室等场所的行人安全。 由上述分析可知,基于改进三帧法和背景差分结合的目标检测方法对行人行走、奔跑和摔倒的行为检测具有较好的效果。 表2为Courtyard场景中不同行为的检测方法的对比,该视频中存在光照影响。文献[14]和[15]的方法对三种行为的平均检测率分别为83.51%和86.97%和92.51%。文献[14]利用矩形的宽高比进行检测,虽然可以较好地判别行走和摔倒行为,但当行人奔跑时,无法区分是行走还是奔跑。文献[15]在文献[14]的基础上增加轮廓特征选取,但环境适应性较低,尤其是在Courtyard场景中,检测的准确性降低。本文融合多个特征进行行为检测,更加全面地描述行人行为,平均检测准确率达到92.51%,证明了本文方法的准确性与可行性。 表2 不同异常行为检测方法的检测准确率对比 本文提出了一种基于运动分析的行人异常行为检测的方法,利用HSV色彩空间变换法进行图像预处理,有效去除阴影对检测精度的影响;利用三帧法进行背景模型训练,建立初始化模型,构建自适应背景更新策略,从而建立稳定的背景图像;增加自适应选取最佳阈值,利用背景差分准确提取运动目标;通过融合多个特征进行行人的行为分析,根据设定的判定规则进行行为检测。 尽管本文方法在现有场景中的单个目标检测取得较高的准确性,后续工作中还需加强对环境变化较大以及多个运动目标的视频场景的行人异常行为检测,提高检测方法的普适性和准确性,以保证行人在不同场所的安全。2 实验与分析
2.1 行人行为检测结果分析



2.2 系统的性能分析

3 结束语
猜你喜欢
河北理科教学研究(2021年3期)2022-01-18
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
意林(2021年5期)2021-04-18
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
中学物理·高中(2016年12期)2017-04-22
汽车与安全(2016年5期)2016-12-01
