
基于信息化的酒店评论情感分析
2022-04-23 01:32:09吴昔遥刘欣凯王孝杰
中国新通信 2022年4期
吴昔遥 刘欣凯 王孝杰


【摘要】 本文通过爬虫获取酒店评论数据,对数据进行预处理,包括数据清洗、评论内容分词等。为了模型性能更优,本文对数据进行特征工程,将其分为两步:一、使用主成分分析法进行数据降维;二、使用卡方检验筛选特征。接下来构建分别决策树和随机森林算法并使用处理好的数据进行训练,通过测试集计算出两种算法的ROC性能曲线,发现随机森林算法相比决策树有着更好的性能,满足酒店评论情感分析的需求。
【关键词】 随机森林 机器学习 评论分析 机器学习
引言
隨着互联网的迅速发展,人们越来越习惯于网购,很多人外出住宿都会网上订购酒店,产生了大量的在线评论[6]。评论信息作为只有入住过的顾客亲身体验后的信息,很快就变成了人们看重的酒店服务质量指标。现在去哪儿网是中国最大的旅游平台之一,其中的在线评论由用户原创且能互动,因此这些评论信息具有很大的挖掘意义[1]。
本文以去哪儿网上的酒店评论信息为实验数据进行信息的挖掘,得到酒店情感分析模型。
一、 数据爬取和预处理
(一)数据爬取
Scrapy是一个爬取网站数据,提取结构性数据而编写的Python框架, 广泛利用于数据挖掘、信息处理等领域。本文我们使用Scrapy对去哪儿网的酒店信息进行爬取。
通过观察发现,汉庭酒店的某城市下(如廊坊)的所有酒店可在城市页面得到,具体页面情况如图1所示。通过跳转每一个酒店的页面来爬取酒店的基本信息,包括城市、名称、地址、房间数等;然后爬取酒店的评论信息和评分情况,包括综合评分、性价比评分、环境卫生评分等。最终我们得到需要进行分析的数据,部分参数如表1[2]。
(二)数据预处理
在爬取完相关数据后,需要对数据做一些清洗和预处理,才能做进一步的可视化和建立算法。对数据使用pandas进行导入后,进行一系列的预处理操作,例如对数据进行连接汇总;对省和市的名称进行清洗,并去除省和市映射的重复值;对一些数据进行清洗,转化为数值类型。经过处理后的数据集包括434400条样本,样本包含四个属性,如表2所示[3]。
除上述基本操作外,最重要的操作是将评论信息是用jieba进行分词和关键词统计。jieba是一款非常流行中文开源分词包,具有速度快、准确、可扩展等特点,目前主要支持python,其他语言也有相关版本。它支持多种分词模式、繁体分词、自定义词典等功能。本文将所有评论按照不同评分分组,将评论分成中文的词语并进行词性标注,返回评分、词语、词频。处理后的结果输出到csv文件进行保存[4]。
(三)中文特征构造
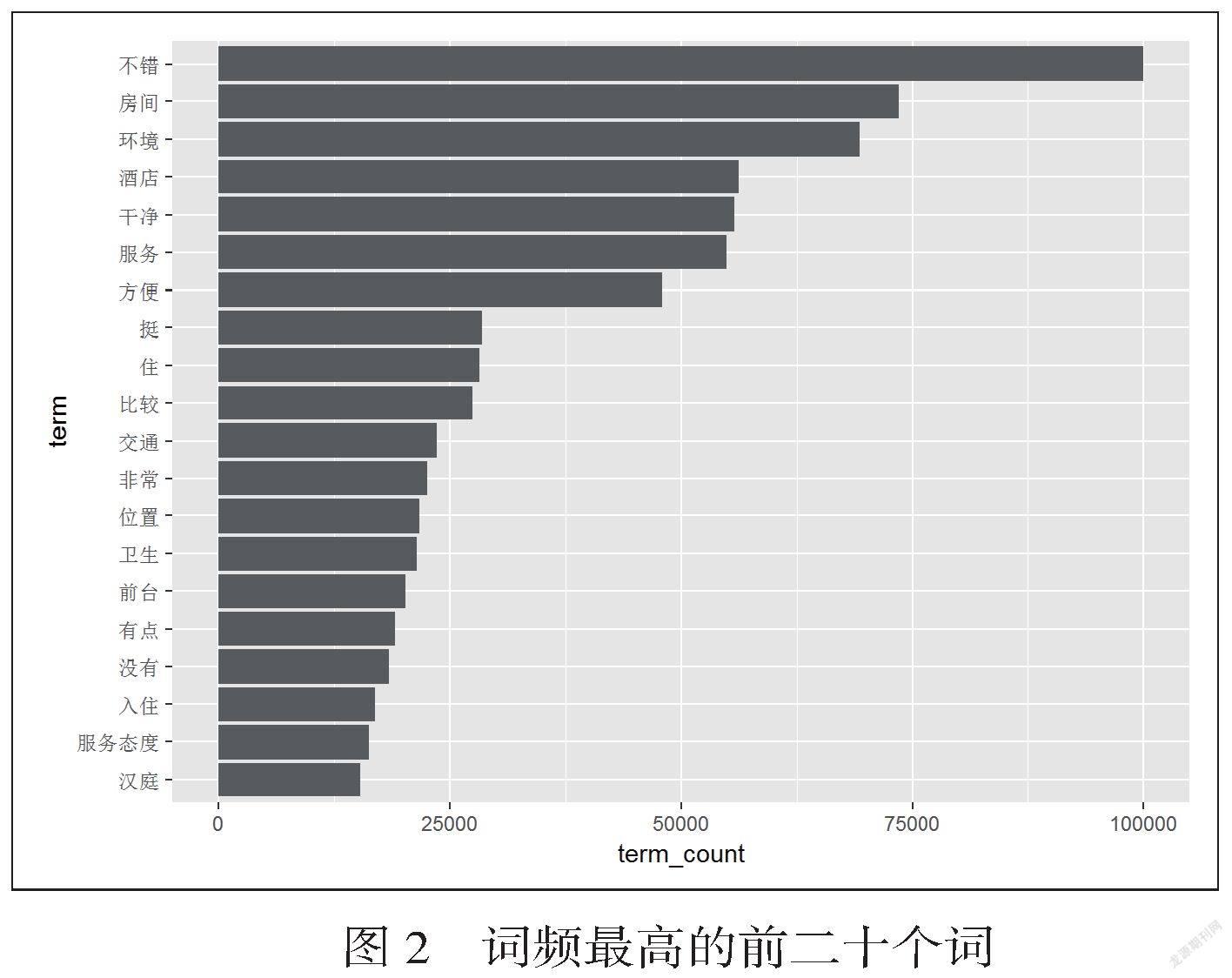
在数据中评论的评分为1-5,本文将4和5分定义为好评,1和2定义为差评,将评分为3的评论全部删除。评论中分词后的词语实际上有着一些没有意义的词语,通过载入jieba停用词库进行排除。除此之外还包含一些并无实际意义的特殊字符也需要对其进行筛除,仅保留完全由中文字符组成的词语。其中词频最高的前二十个词如图2所示。
TF-IDF是一种对关键词进行统计和分析的方式,被广泛用于预估一个词在文件或语料库中的重要程度。一个词的重要程度跟它在文章中出现的次数成正比,跟它在语料库出现的次数成反比。此方法能有效地避免常用词对关键词的影响,提高关键词与文章之间的相关性。TF指的是某一个词在文章中出现的总次数,通常表示为TF = 某词在文档中出现的次数/文档的总词量,这样可以防止结果偏向过长的文档。IDF逆向文档频率,包含某词语的文档越少,IDF值越大,说明该词语的区分能力越强。
本文使用一个向量化器将文本转换为TF-IDF矩阵。通过设置文档中的停用词,使得停用词不纳入计算范围,提高算法的精确性。
二、评论情感分类算法建立
(一)特征工程
模型训练前对数据进行划分,训练集为253047条评论,测试集为108450条评论。每一条数据由评论id和评论内容组成。使用TF矩阵对数据进行编码转换,得到1000维的特征向量。
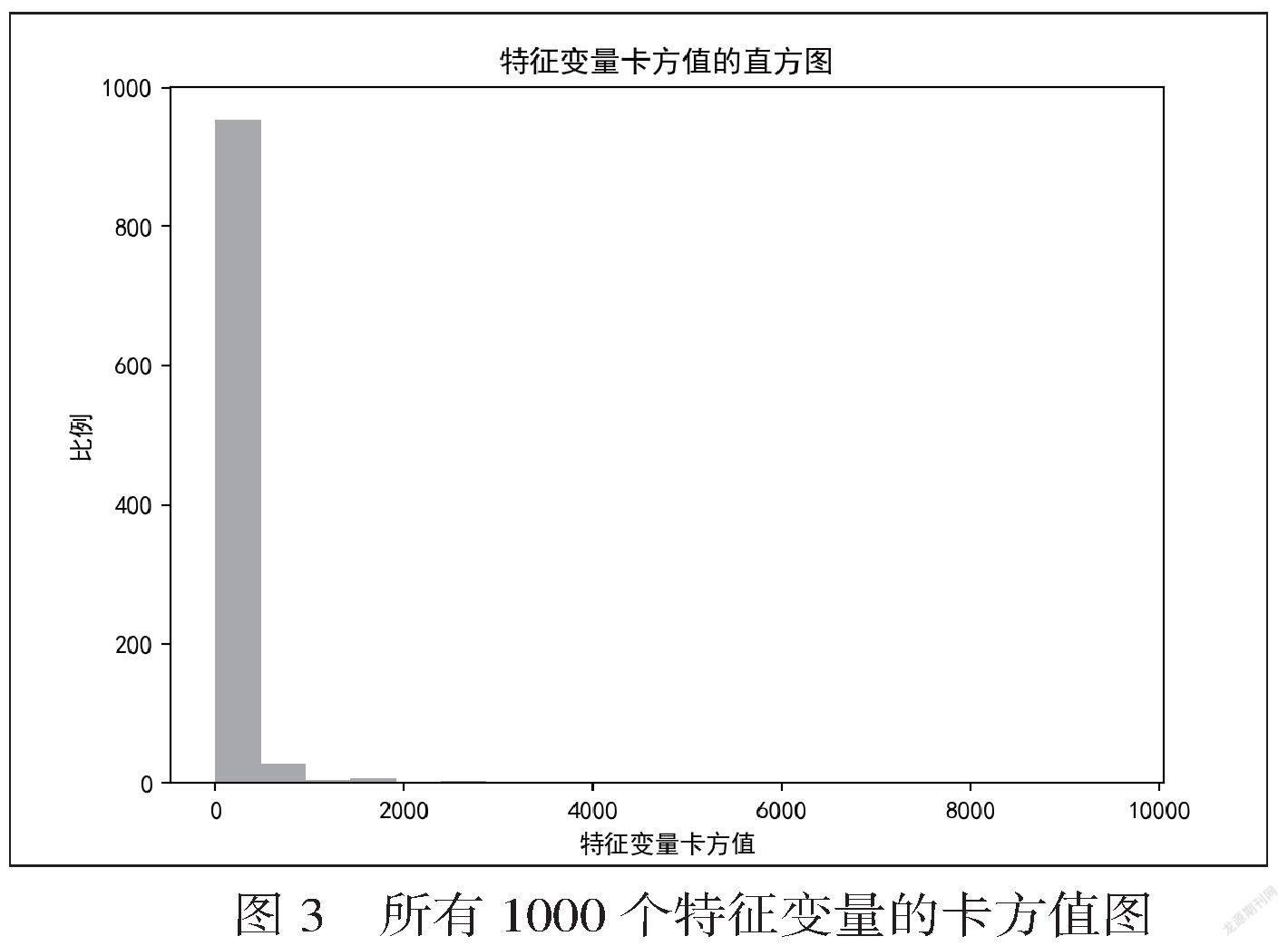
特征工程是从原始数据中提取特征的过程,转化后的数据,可以让模型更好的拟合问题。经过处理,数据已经转化为1000维的特征向量,通过主成分分析法(PCA)进行数据的降维,减少冗余信息造成的误差。画出所有1000个特征变量卡方值的直方图,如图3所示。可以看出,大部分特征的卡方值都在1000以下,即预测能力较弱,并不适合进行模型的训练。
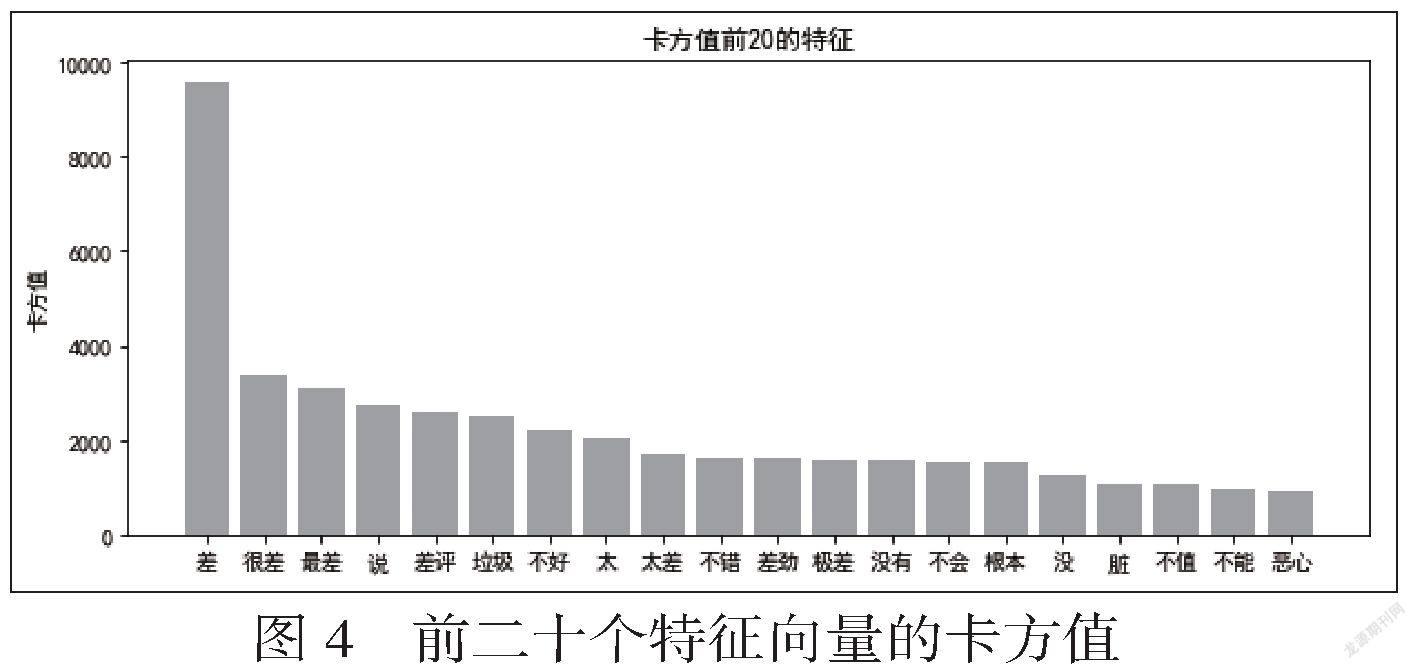
使用卡方检验选取预测能力最强的100个特征变量,并按照卡方值从大到小排序,前二十个特征向量如图4所示。
(二)算法建立
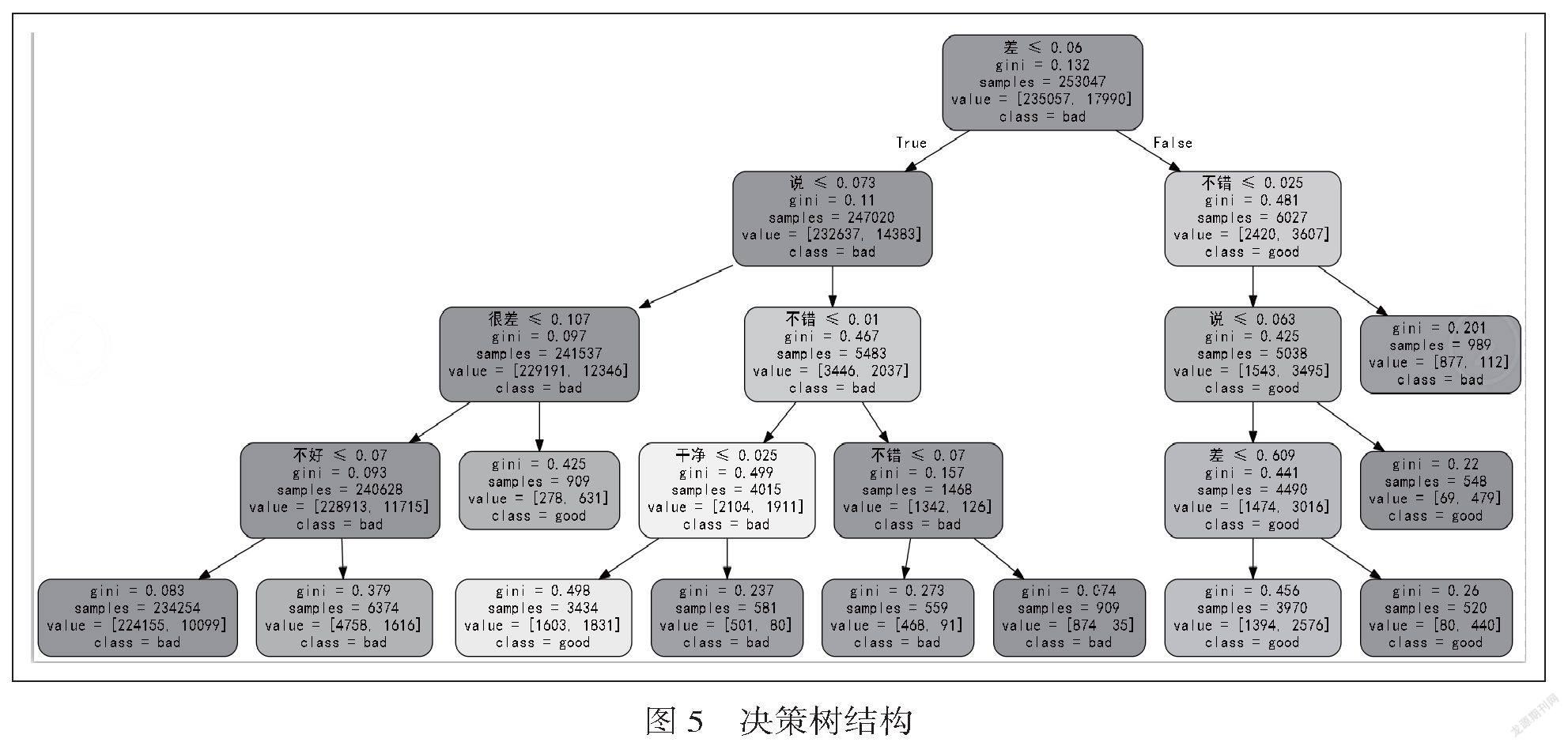
决策树是将数据分为不同的区域,每个区域有独立参数的算法。它基于实例的归纳学习,从训练样本中提炼出树型模型。决策树生成分为特征选择和决策树生成。特征选择指从训练集选择合适的特征为分裂标准。决策树生成指根据特征评估,从上到下递归生成子树,直到数据集不可分[8]。决策树模型结构较简单,训练速度很快,但性能一般。训练时指定决策树的相关超参数防止过拟合,决策树最大深度为4,叶子结点最小样本为500。使用特征构建完的决策树如图5所示。
随机森林是将多棵树联系起来的集成学习算法,它的基本思想是袋装采样和决策树。每棵决策树都是一个分类器,而随机森林正式集成了所有分类器的结果,以最靠谱的预测类别作为最终的输出。与支持向量机、BP神经网络等算法相比,随机森林具有更低的错误率,更不易被数据噪声所影响,减少了过拟合,体现了集成学习算法的优越性[7]。训练时对随机森林的参数进行设置,决策树数量为100,决策树的最大深度为4,叶子节点至少包含100个样本。
该分类问题是一个类的分布具有不平衡性,这会损害分类模型的性能。将多数类的样本降采样,使多数类的样本数量与少数类达到一致。
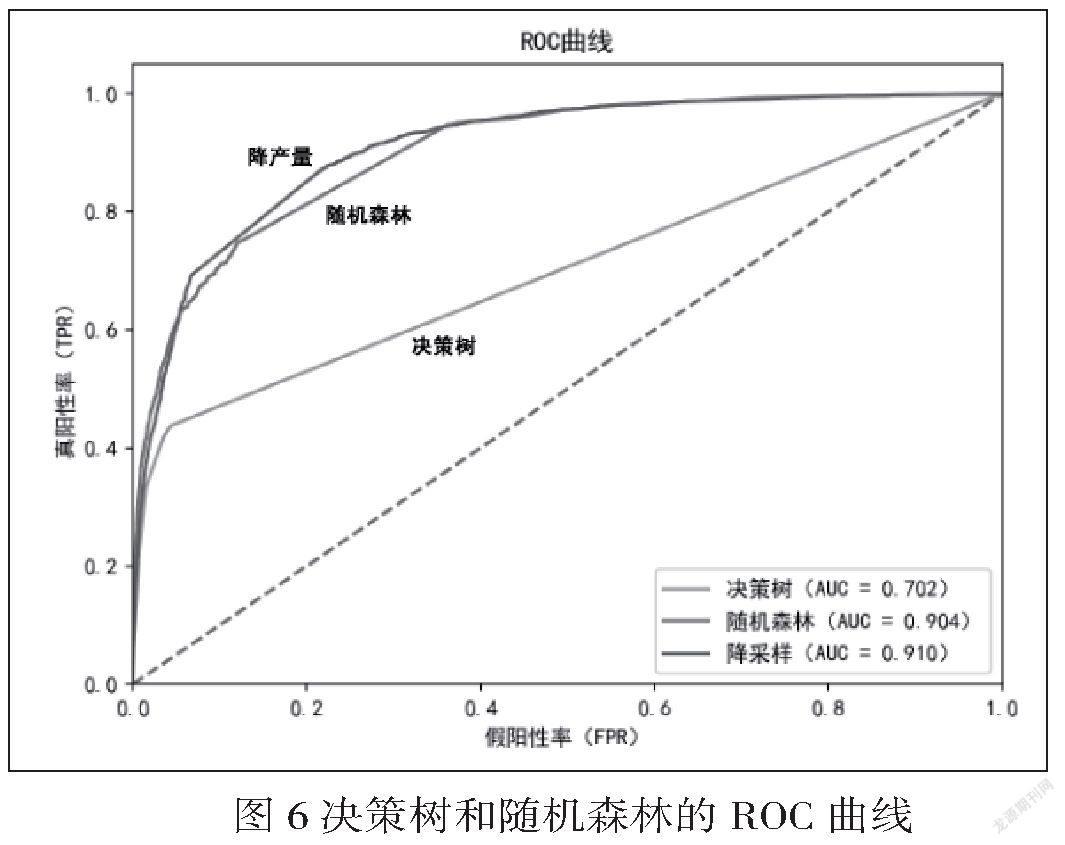
在机器学习中,分类器性能评估方法受到了广泛关注。ROC曲线是选择特征参数及分类阈值的高效工具,可以可视化地评估分类器性能,从而进行模型选择[9]。训练完成后得到模型在测试集上的性能分析,我们发现此时因为样本比例不均衡,此时精确度并不是一个很好的性能指标,改用ROC曲线来衡量模型性能[9]。
最后得到分别在决策树、随机森林和降采样后的ROC曲线,如图6所示。根据ROC曲线看出,随机森林算法在评论情感分析时有着较好的性能[5]。
三、结束语
本文通过爬虫得到酒店评论数据,进行数据预处理和特征工程等过程。使用处理好的数据进行随机森林算法和决策树算法的构建,通过对比ROC曲线得出随机森林算法相比决策树有着更好的性能,满足酒店评论情感分析的需要。
参 考 文 献
[1]胡译文. 基于情感倾向的酒店评价分析与研究[D].哈爾滨工程大学,2018.
[2]王冬旭. 基于Python的旅游网站数据爬虫研究[D].沈阳理工大学,2020.
[3]易小群. 面向智慧出行的酒店评论数据可视化技术研究与实现[D].西南交通大学,2019.
[4]王鸽. 中文产品评论的情感分析与观点识别技术的研究[D].山东科技大学,2018.
[5]吕结红. 基于文本挖掘的酒店在线评论研究[D].华中师范大学,2020.
[6]熊伟,郭扬杰.酒店顾客在线评论的文本挖掘[J].北京第二外国语学院学报,2013,35(11):38-47.
[7]仉文岗,唐理斌,陈福勇,杨甲锋.基于4种超参数优化算法及随机森林模型预测TBM掘进速度[J].应用基础与工程科学学报,2021,29(5):1186-1200.
[8]李鹏,雷雨秋,刘宗杰,杨圆,邵明鑫,周玮.基于决策树算法的断路器弹簧操动机构振动诊断技术[J].高压电器,2021,57(9):1-8+18.
[9]董元方, 李雄飞, 李军,等. 基于分辨粒度的gROC曲线分析方法[J]. 软件学报, 2013,(1):109-120.
猜你喜欢
安徽农学通报(2017年1期)2017-02-15 17:49:06
软件(2016年7期)2017-02-07 15:54:01
南水北调与水利科技(2016年6期)2017-01-06 13:43:27
电子技术与软件工程(2016年22期)2016-12-26 21:36:42
科技创新与应用(2016年31期)2016-12-03 03:33:48
时代金融(2016年27期)2016-11-25 17:51:36
科教导刊(2016年26期)2016-11-15 20:19:33
电脑知识与技术(2016年23期)2016-11-02 23:25:12
科学与财富(2016年28期)2016-10-14 21:19:17
科教导刊·电子版(2016年10期)2016-06-02 18:04:11
