
异构Spark集群数据倾斜修正调度策略*
2022-04-21 05:05修位蓉
计算机工程与科学 2022年4期
卞 琛,修位蓉,于 炯
(1广东金融学院互联网金融与信息工程学院,广东 广州 510521;2.广州商学院信息技术与工程学院,广东 广州 511363;3新疆大学信息科学与工程学院,新疆 乌鲁木齐 830046)
1 引言
随着非易失内存的发展和高复杂度计算需求的提升,能够较好地支持迭代计算和数据密集型应用的内存计算框架[1-3]已经得到了广泛的应用。分布式内存计算框架Spark[4,5]作为其中的典型代表,利用分布式集群的节点,在内存对数据进行高效处理和临时缓存,具有高性能、高可靠和低延迟的特性。传统基于磁盘的分布式计算框架MapReduce[6]将应用简单划分为多个Map和Reduce操作,磁盘I/O的开销很大。与之不同的是,Spark将作业基于操作间的前后关系转化成DAG图,并根据处理的操作类型不同(宽依赖操作或窄依赖操作)划分成多个计算阶段(stage),各阶段串行处理,阶段内部由多个任务(task)并行处理。作业执行时间取决于所有阶段执行时间之和,若能够尽可能减少每个阶段的执行时间,则最终整个作业的执行时间就能够得到优化。由于每个阶段内的任务需要同步,完成时长取决于执行时间最长的任务,让每个任务都尽快完成才成达到优化目标,因此并发任务数(并行度)和计算量分配是影响任务执行速度的关键因素。
Spark框架的任务并行度是分布式内存计算环境中各阶段内部任务执行的并发程度。任务并行度包含物理并行度和逻辑并行度:物理并行度是集群资源限定下能够承载的最大并发任务个数,由注册的工作节点数及每个节点贡献的CPU核心数确定;而逻辑并行度为用户/程序所预期的任务并发程度,由Spark的执行参数确定。理想情况下,物理并行度和逻辑并行度一致时能够获得最佳效率,而由于存储容量限制,数据量较大或分布不均衡可能会导致内存空间不足或内存溢出,反而影响执行效率。同时,逻辑并行度设置过大时,也同样会带来调度和任务切换的额外开销。Spark的任务并行度通常在系统配置参数default.parallelism中设定,往往由程序员依靠经验预先设定,较难契合各类型的作业和集群环境,增加了溢写、容错甚至是程序异常的风险。同时,并行度在整个作业所有阶段的执行过程中恒定不变,与作业类型、数据特性和节点能力无关,每个阶段的数据分布和数据大小都不一样,不能很好地适应作业特点,提高并发执行效率。
在不改变分区规则的情况下,由原始数据分布和并行度参数共同决定计算数据量的分配,对作业执行效率和集群资源利用率均产生重要影响,在异构Spark集群中的表现尤为突出。因此,本文针对异构Spark集群节点性能与数据分配的适配性问题,研究数据分布和并行度设置对作业执行效率的影响,建立节点资源模型、数据分配模型和任务执行模型,分析数据分布、并行度参数和节点任务分配的耦合关系,异构Spark集群的数据倾斜修正调度策略DSCS(Data Skew Correction Scheduling strategy),包括并行度预估算法、数据倾斜修正和异构节点任务分配算法。并行度预估算法基于统计的输入数据总量、可用节点数量、可用核心数量和可用内存数量,对并行度和轮数进行预估;数据倾斜修正算法对输入数据分布倾斜度较高的阶段进行处理,尽可能均衡不同数据桶(Bucket)中的分配量,当部分键值(key)数据量明显大于其他键值时,对该健值的数据进行拆分并增加并行度;异构节点任务分配算法分别根据节点计算能力和内存空间大小倒序生成2个队列,优先分配更多的任务到计算能力更强的节点和内存可用空间更大的节点,从而使异构Spark集群能够通过并行调度策略,选择具有更小内存溢出量和更小任务调度开销的并行计算方案。
2 相关工作
在内存计算框架中,任务并行度设置的合理性将直接影响到作业执行效率和集群资源利用率。针对内存计算框架的任务并行调度效率问题,研究者从不同角度提出了优化方案。文献[7]针对嵌套型列存储Impala,利用多层查询树的结构提高了查询任务的并行度,有效地降低了系统广播和查询开销。文献[8]分析发现,在MapReduce环境中,并行度的设置会显著影响缓存在作业执行中的作用,合理的并行度能够有效提高作业执行效率,在此基础上提出了基于并行度优化的缓存设置算法。文献[9]研究表明,在Spark环境中,各计算阶段的任务并行度设置不合理会降低作业执行性能,增加作业的计算开销,在此基础上提出通过调整并行度来提高内存资源利用率的任务调度算法。文献[10]在MapReduce环境中,为了合理地设置节点任务并行度,有效地均衡节点通信成本,提高作业执行效率,设置了基于通信成本模型的任务调度算法。文献[11]在并行度设置的基础上,提出了任务本地化调度算法,从而优化任务执行机制,提高任务本地性,降低网络开销。文献[12]基于并行度分布的情况,提出了动态任务调度策略,利用任务的数据分布情况,结合节点的计算能力为任务分配相应的系统资源。文献[13,14]对Spark环境中的具体参数进行建模和预测,实现对包含并行度等多个作业参数的优化。
针对任务计算量分配问题,也涌现出大量的研究成果。文献[15]提出了SkewReduce,通过建立代价模型评估分区容量,在作业执行过程中进行元数据的逐步收集,达到契机时执行分区优化函数并实施新的分区方案。文献[16]提出了SkewTune策略,该策略并不期望在执行计划阶段就建立均衡的分区,而是建立了Reduce端的任务剩余代价评估模型,任何Reduce端的任务完成后,都将触发其他未完成任务的剩余代价评估,并将未处理数据向已完成任务的工作节点迁移,从而达到数据分配的整体均衡。文献[17]提出了一种基于采样的分区策略,该策略通过在Map端增加独立的采样进程获得近似数据分布,采样达到阈值后对已生成的分区进行拆分和重组,从而提高数据分配的均衡性。文献[18,19]提出了精细分区和动态拆分2种算法,首先通过精细分区算法生成固定数量的分区,同时进行采样获得近似数据分布,当完成一定比例的Map任务后,触发动态拆分函数,达到数据合理分配的目标。文献[20,21]提出了基于数据块的采样分区方法,该方法将原生的键值对转换为〈blocking_key,entity〉形式,通过设计评估函数对块内数据进行评估,对不符合条件的数据块进行调整。文献[22]提出先对输入数据进行25%的随机采样,通过采样结果获得数据分布并制定分区函数,然后启动任务填充数据。文献[23]提出了LEEN策略,通过对输入数据的预扫描获取数据分布,在Map任务执行过程中对数据的键值进行频率统计,然后综合数据分布和键值频率统计设定合理的分区函数。文献[24]提出了一种任务级别的启发式调度策略,通过收集任务特性和资源需求,将任务发送到最适合的工作节点,监测慢任务并进行重定向,但对任务划分的合理性则没有进行评估和改进。H-Scheduler[25]和Selecta[26]主要针对计算集群的存储结构,评估HDD+SSD混合存储结构对作业执行效率的影响。H-Scheduler利用存储类型和数据本地性对任务进行分类,再根据分类结果重新定义任务调度优先级和工作节点映射。Selecta则分析影响作业效率的潜在因素,采用协同过滤算法对作业在不同配置环境中的性能表现进行预测,预测结果有94%的最佳性能配置命中率和80%的最优成本命中率。
本文与现有研究成果的不同之处在于,发现并行度和计算量分配都是决定任务执行时间的重要因素且两者存在耦合,无法通过已知直接求得2个相互耦合未知数的最优解,因此也并不期望在作业计划阶段就确定适合异构Spark集群的最优并行度和最佳数据分配,而是在多阶段任务执行过程中为每个阶段制定相对合理的并行度,通过后期调整来优化数据分配。首先通过建立计算节点资源模型、数据分配模型和任务执行模型,确定并行度设置的约束,分析任务并行度和计算量分配的耦合关系,在此基础上提出异构Spark集群的数据倾斜修正调度策略DSCS,包括并行度预估、数据倾斜修正和异构节点任务分配算法。并行度预估算法基于有限的数据集信息和Spark工作节点的资源状况,预估并行度、分配轮数的相对合理值,实施作业的发送。在作业并行计算过程中,首个计算阶段任务运行完毕后进行数据分布的采集和存储,根据倾斜情况对数据进行切分,更新并行度参数。最后,在考虑节点异构的情况下,根据节点计算能力的不同,将数据分配到不同节点,从而有效均衡节点计算能力和计算数据量之间的关系。
3 问题的建模与分析
本节主要分析Spark作业的并行执行机制,进行模型定义和相关定理证明,为第4节算法设计提供理论基础。
3.1 模型定义
定义1(节点计算能力) 定义由n个节点构成的Spark集群w={w1,w2,…,wn},其中wx为第x个Spark计算节点(简称节点x)。内存计算框架的节点计算资源主要包括CPU资源、内存资源和网络资源,通常同一个集群的网络资源及传输能力相近,因此节点x的节点计算能力可定义为cx=(CPUx,Memx)。对节点计算能力进行统计分析时,计算能力主要反映单位时间处理的数据量,其中CPU贡献用主频和核数之积来评判,表示为CPUx=fx×corex。内存则以吞吐量为指标,由于吞吐量牵涉的因素较多,而内存计算的最大瓶颈是容量问题,因此可定义内存处理能力为Memx,用于表示内存空间大小。
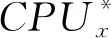
(1)
(2)
则节点x的综合归一化计算能力则可表示如式(3)所示:
(3)
定义2(节点资源占用率) 节点资源占用率是指系统中节点资源的已使用比率,占用率越高,节点计算能力越低;反之,则计算能力越高。节点x的资源利用率ux可定义如式(4)所示:
ux={ucx,umx|0≤ucx≤1,0≤umx≤1}
(4)
其中,ucx表示CPU占用率,umx表示内存占用率。
ucx和umx均可通过系统性能监测软件获得,本文利用nmon软件进行监测。当CPU利用率为ucx时,则实际的CPU计算能力为fx×corex×(1-ucx),当内存资源占用率为umx时,则实际的内存可用空间为Memx×(1-umn)。
定义3(数据分布) 输入数据分布对应Spark作业的每个阶段,第1个阶段的输入数据分布是原始数据集的键值分布情况,若输入数据中包含m个键值,且km对应的数据量为vm时,则输入数据分布如式(5)所示:
d=(〈k1,v1〉,〈k2,v2〉,…,〈km,vm〉)
(5)
后续计算阶段的输入数据分布对应前一个阶段的输出结果,假设某个阶段包含r个数据分区(partition),则需统计r个分区中键值的数量,则第b个分区的数据分布db=(〈k1,vb1〉,〈k2,vb2〉,…,〈km,vbm〉),而输入总数据量则如式(6)所示:
(6)
定义4(数据倾斜度) 输入数据倾斜是某个键值的数据量相较于其他键值数据量的差异程度,因此可定义为某个键值的数据量与总体数据量均值的方差。对于输入数据的第j个键值,其数据倾斜度可定义为:
(7)
skewj越大,表示该键值数据倾斜度越高;反之,则表示该键值的数据量与平均数据量差距越小。
因此,输入数据分布d的数据倾斜度可表示如式(8)所示:
(8)
S越大,表示数据分布越不均匀;S越趋近于0,则数据分布越均匀。
定义5(key-bucket分布) 对于作业中每个计算阶段的输出,需要将输出数据按键值分配到多个数据桶中。Spark系统根据哈希函数映射,将每个分区数据的键值关联到对应的桶中,如式(9)所示:
bucketid=hashfunction(key)
(9)
每个计算阶段输出的数据桶个数由设置的并行度参数决定,若当前并行度数为p,则数据桶的id取值为0到p-1。

定义6(数据桶倾斜度) 数据桶倾斜度是对于同一计算阶段的多个数据桶,某个数据桶的数据量与总体数据量均值的方差。对于第p-1个数据桶,其数据倾斜度可定义为:
(10)
skewbucketp-1越大,表示该数据桶倾斜度越高。若所有数据桶的倾斜度越趋近于0,表示各数据桶的数据量分配越均匀。
定义7(任务内存需求) 由于Spark利用内存处理来提升计算效率,因此分配足够内存既能够保障内存计算的执行速度,同时也能避免因不正确配置参数导致的不可预期程序异常。记Memtaskh为第h个任务的内存需求,若共有q个任务,则作业总体内存需求如式(11)所示:
(11)
内存需求量主要包括3部分:(1)基本内存需求,即数据集中对象大小的2~3倍;(2)访问这些对象的内存消耗;(3)垃圾回收消耗。因此,某个任务的执行区需求量与所需计算的数据量有关。实际执行区需求量可通过实时查看内存所占用空间大小和溢出量来综合判断。
3.2 定理分析
定理1并行度适度法则:并行度的选择符合适度法则,既不能太少,也不能太多,需要和执行作业的需求以及集群计算能力相匹配。若分区数较少,会产生额外磁盘开销,影响执行效率;若分区数较多,会增加任务切换的开销,且生成较多的小文件。
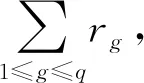

因此,并行度的设置既不能太小也不能太大,想要获得较好的性能,需根据作业DAG及具体数据状况选择合适的并行度。
□
定理2数据溢出规避法则:在某个计算阶段中产生数据倾斜时,分配更大的并行度,使得每个任务内存需求量减小,其内存溢出量也会随之降低。
证明记节点x分配的内存大小和核数分别为Memx和fx。设分配的任务数量为l。
任务内存需求量分别为{Memtask1,Memtask2,…,Memtaskl}且Memtask1>Memtask2>Memtaskl,即将l个任务按照所需内存大小降序排列,随着l变大,则每个任务的内存需求量随之减小。
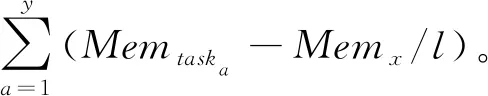
若l
□
4 异构并行调度策略
本节基于模型的相关定义及定理证明,首先描述算法的程序模块和代码更新,然后进行异构Spark集群并行调度策略的整体描述,最后提出并行度预估算法、数据倾斜修正算法和异构节点任务分配算法。
4.1 并行调度策略总体描述
自适应异构并行调度策略根据数据的倾斜情况和节点计算能力,在作业执行过程中对并行度和任务分配进行调整。计算各阶段并行度的前提是获取前序阶段的任务数及其对应输出数据量,然后根据计算节点的资源情况对任务进行有效分配。对于迭代执行的算法,首轮执行Spark任务时,根据并行度预估算法的默认并行度执行,在第2轮开始,根据前一轮的数据统计和倾斜分析,利用预估算法和数据倾斜修正算法对当前的并行度进行调整,任务分配时,则需要通过异构节点任务分配算法根据当前节点的资源状况进行任务量分配。自适应异构并行调度策略的主要过程如下所示:
(1)除第1个阶段之外,其余每个计算阶段收集前序阶段输出数据大小、数据分布和可用节点的空闲内存及核数资源情况,构建算法所需的元数据。
(2)根据采集的元数据,执行初始并行度预估算法(见4.2节),计算当前计算阶段的初始并行度。
(3)根据并行调度策略的机制,首先预判断不均衡的键值,利用数据倾斜修正算法(见4.3节)对键值进行拆分评估, 对数据倾斜度较高的键值增加前缀,使其能够映射到多个数据桶,然后将倾斜的数据桶进一步划分,增加相应的并行度。
(4)当确定并行度后,根据异构节点任务分配算法(见4.4节)对(3)中待分配数据桶进行划分和映射。
(5)迭代(1)~(4),在多宽依赖作业中实施多次分配,为后续计算阶段确定合理的并行度和数据分配。
4.2 并行度预估算法
根据3.2节定理1可知,并行度设置应当在执行任务内存需求不超过所分配工作节点可用容量的情况下,选择额外调度开销尽可能少的并行度设定值。因此,算法通过前序计算阶段的数据量和可用节点的内存空间计算并行度,并且保障任务平均分配数据大小不超过平均内存空间大小。并行度预估算法详细步骤如下所示:
(1)统计系统各节点资源情况,并将其存储在node表中,其中包括节点内存容量和核心数等。
(2)在计算开始前,基于作业DAG生成计算阶段结构树stageTree。
(3)遍历计算阶段结构树,记录计算阶段集合stagei(wdi,inputRDDi和outputRDDi),其中inputRDDi和outputRDDi分别为stagei中输入RDD和输出RDD,可以是一个或多个RDD。
(4)初始化stage0,其并行度划分取决于作业输入数据在HDFS中分块的个数blockNum,该值由输入数据大小inputSize和默认HDFS分块大小blockSize共同决定。
(5)在stage1到stagen执行阶段中,获取当前可用节点的可用资源情况,存储在availableResource表,包括内存和核心数,统计可用内存总容量tms和可用核心总数tcn。
(6)同时统计每个任务的键值分布和数据大小。当前序stagei执行结束,统计各分区大小ptSize和数据分布情况〈key,Value〉,并计算所有parentRDD的总容量prSize。
(7)假定内存需求量与数据量的比值关系为xp,默认情况下将xp设置为2,即数据在内存中所需的内存空间为数据量大小的2倍,则计算parentRDD总容量与可用内存总容量tms和核心总数tcn乘积的商值,即(xp×prSize/tms)×tcn。
(8)若(xp×prSize/tms)×tcn≤1,则初始并行度设置为tcn。
并行度预估算法如算法1所示。
算法1并行度预估算法
输入:作业DAG,系统配置systemconfigruarion,输入数据块个数blocknum,可用资源availableResource,内存需求比xp。
输出:初始并行度stagei.Pa0
初始化:prSize←0;xp←2;
①stageTree←generate(DAG);//获取执行计划
②stage0.Pa←blockNum;/*初始化第1个计算阶段*/
③for(i=1 tostageTree.length-1)
④stagei(wdi,parentRDD)←get(DAG);
⑤ptnumi←stagei.partitionnum;
⑥tms←sum(availableResource.mem);
⑦tcn←sum(availableResource.core);
⑧for(j=0 toptnumi-1)
⑨ptSizeij←getsize(i,j);
⑩ (kid,ksize)←partitionij(keyid,keysize);
4.3 数据倾斜修正算法
根据3.2节定理2可知,当节点产生数据倾斜时,为了尽可能地减少内存溢出,需要对数据倾斜且内存需求超过内存的键值进行拆分。倾斜修正算法的主要目的是利用分区函数将数据倾斜且明显大于需求内存的键值进行重新划分,进而划分到不同的分区中去,在分配之后去掉添加的前缀,恢复成原本的键值,再重新执行一个Reduce操作。
数据倾斜修正算法的主要步骤如下所示:

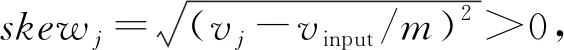
(4)将所有拆分sk_id的拆分个数统计求和,记录为tskn;
(6)此时将默认数据桶数量修改为修正并行度Pa1=stagei.Pa0+tskn;
(7)通过计算hash(key) mod (Pa0+tskn)获得写入数据的数据桶编号,将数据存入相应数据桶;
(8)数据桶则暂不建立映射关系,交由后续异构节点任务分配算法进行操作。
数据倾斜修正算法如算法2所示。
算法2数据倾斜修正算法
输入:当前执行阶段stagei,总元组数vinput,键值的个数m,可用内存总容量tms,可用核心总数tcn,初始并行度Pa0。
初始化:vj+=Get(keyj_size);
//获取按键值划分的数据量
①forkeyjinstagei(j=0 tom-1)
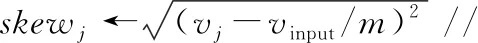
③if(skewj>0 andvj>tms/tcn)then
④sk_id[l2]←kj(key_id);
⑤l2++;
⑥svl2←sk_id[l2].size;
⑧tskn+←svnl2;
⑨for(k=0 tosvnl2)
⑩key[n2]←addPrefix(sk_id[k]);
4.4 异构节点任务分配算法
数据桶填充完毕之后,需要将桶映射到节点相应的Reducer中,桶的数量与Reducer个数相同,系统默认方式是根据编号直接建立映射关系,由于此时未考虑节点CPU计算能力和内存大小的差异,因此不能有效地平衡节点计算能力和任务量之间的关系。异构节点任务分配算法根据节点计算能力进行排序,将各数据桶数据量大小进行排序,尽可能将符合节点计算要求的数据桶分配到相应的节点中。异构节点任务分配算法主要过程如下所示:
(1)将并行度Pa1扩展至Pa2=α×tcn,其中α为正整数且(α-1)×tcn≤Pa1≤α×tcn,α≥1;
(2)同时,将Pa1个数据桶划分为α轮进行分配,其中前α-1轮,每轮分配tcn个数据桶,第α轮分配Pa1-(α-1)×tcn个数据桶;
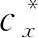
(4)将bucket[Pa1]根据数据量大小进行排序存入数组bs;
(5)从第1轮到第α-1轮中,每轮从bs[(round-1)×tcn]到bs[round×tcn-1]开始选择,将bs[(round-1) ×tcn]到bs[round×tcn-1]一一映射到reducer1到reducertcn;
(6)第α轮,将bs[(α-1)×tcn]至bs[Pa1-1]一一映射到节点计算能力较强的Reducer上,即Pa1-(α-1)×tcn到reducertcn。
异构节点任务分配算法如算法3所示。
算法3异构节点任务分配算法
输入:当前执行阶段stagei,可用核心总数tcn,修正并行度Pa1。
初始化:k←1;q1←1;

//将节点根据计算能力排序
③bs[e]←descendBy(vbucket[e]);
//将数据桶根据数据量大小排序
④for(round=1 toα-1)
⑤for(u=round-1)*tcntotcn)
⑥for(v=bs[(α-1)*tcntotcn)
⑦reducerk1←assign(bs[(round-1)*tcn+q1]);
⑧k1++;
⑨q1++;
⑩endfor/*将第1到α-1轮的数据桶映射到Reducer*/
5 实验与评价
本节将通过实验进行比较和评价,验证异构并行调度策略的有效性。
5.1 实验环境
本文的Spark集群共有10个节点,包括1个主节点与9个工作节点,各节点软硬件配置如表1所示。Spark集群为5个工作节点各分配4 GB内存和2个CPU核心,其余2个工作节点各分配2 GB内存和1个CPU核心,2个工作节点各分配8 GB内存和4个CPU核心,因此集群中共有40 GB内存以及20个CPU逻辑核心用于执行迭代应用。

Table 1 Configuration parameters of worker nodes
实验采用nmon来监控Spark集群的资源使用情况,由于主节点主要负责任务调度与资源分配,不需要实际执行任务,为方便起见,本文将主节点与监控服务器集成到一个节点,避免对集群计算性能造成影响。实验使用基准测试集BigDataBench[27]中多个作业,包括WordCount算法、TeraSort算法、k-means聚类算法和PageRank算法进行评估。
5.2 算法单独评估
实验采用数据密集型应用PageRank作业对提出的3个算法分别进行评估,数据选取SNAP(Stanford Network Analysis Project)提供的3个数据量差异较大的标准数据集,均为有向图,如表2所示。任务选用数据密集型算法PageRank,因为数据密集型算法对系统的并行度策略更加敏感,更有利于验证算法的有效性。为了明显体现并行度对内存溢出情况的显著影响可用节点数量调整为4个工作节点和1个主节点,将工作节点可用内存空间调整为1 GB,其中2个节点的可用核心数为2个,另外2个节点的可用核心数为4个。
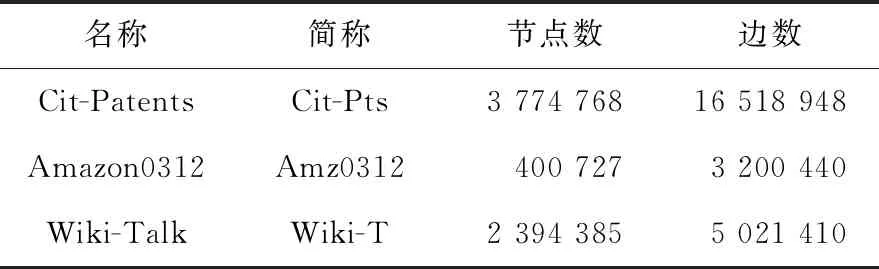
Table 2 Information of test datasets
(1)初始并行度生成算法。
利用PageRank作业进行10轮迭代,验证初始并行度生成算法的效率,与系统默认并行度设置为2×40=80的情况进行对比,实验结果如图1所示。其中,图1a为不同输入数据类型,利用动态并行度进行设置与默认固定并行度的执行时间对比;图1b为不同输入数据类型,利用动态并行度设置算法进行配置时,算法在不同计算阶段的并行度变化。
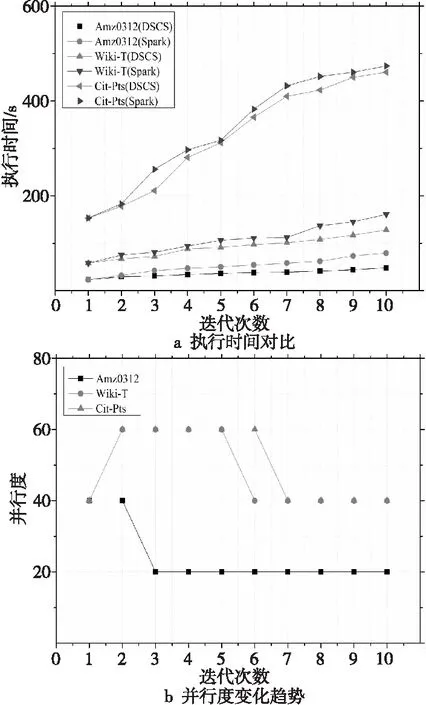
Figure 1 Parallelism prediction algorithm
由图1a可知,对3类数据类型而言,使用动态并行度都能够有效地缩短作业执行时间,不同的并行度对作业执行效率的影响很明显,不恰当的并行度可能会使得部分节点资源利用率较低,其余节点内存资源不足而溢出,从而增加任务执行时间,降低作业执行效率。其中Cit-Patents受到并行度影响更大,由于Cit-Patents具有较大的数据量,因此在执行过程中,需要占用的内存空间较大,更有可能发生溢写,因此选择合理的并行度能够更好地缩短作业执行时间。
结合图1b可知,各个阶段的并行度具有明显的变化,DSCS能够有效结合计算阶段的执行状态进行调整,随着并行度的变化,优化了阶段内任务的完成时间,最终缩短了作业总执行时间。
(2)数据倾斜修正算法。
使用PageRank作业3个不同数据集,验证数据倾斜修正算法效率,并与系统默认的数据桶划分算法进行对比。算法未修改的参数保持Spark系统默认,迭代次数为10,并行度固定设置为20,倾斜度分别设置为0.2,0.4,0.6和0.8。图2a为不同倾斜度时,数据倾斜修正算法与系统默认数据桶划分算法的执行时间对比;图2b为不同倾斜度时,3个数据集平均内存溢写情况的对比。
由图2a可知,PageRank在数据量较大且产生数据倾斜时,数据倾斜修正算法对执行时间的影响较大;而在数据量较小时,即使产生数据倾斜,该算法的效果也不明显,因为不同任务之间数据倾斜的差异较小。由图2b可知,执行作业数据量越大、数据倾斜越严重,在默认数据桶划分算法的情况下,产生的磁盘溢写量就越大。
(3)异构节点任务分配算法。
利用PageRank作业验证异构节点任务分配算法的效率,并与系统默认任务分配一一映射的算法进行对比。图3a为异构节点任务分配算法与系统默认的节点分配算法的执行时间对比;图3b为利用异构节点任务分配算法进行设置时,3个数据作业在不同迭代次数时的高性能节点3的资源利用率情况。由图3a可知,PageRank在节点异构情况下,使用系统默认的数据桶分配算法与异构节点任务分配算法相比,执行时间相对略长。在各节点之间计算能力差异明显的情况下,随着数据倾斜度的增加,效率差异会更加显著。由图3b可知,PageRank算法在使用异构节点任务分配算法进行配置时,节点资源利用率得到了较好的均衡,表明充分利用了计算能力更强的节点。
5.3 算法综合评估
使用多个作业包括WordCount算法、TeraSort算法、k-means聚类算法和PageRank算法进行综合测试,将优化算法嵌在插件中,通过建立的Spark平台对DSCS策略进行验证和评估,对比优化前后的作业执行时间和内存利用率,实验结果如图4所示。其中WordCount算法输入集为Wiki,数据大小为7.8 GB;TeraSort算法输入数据大小为3.5 GB;k-means算法输入数据大小为16.4 GB;PageRank算法输入数据大小为1.2 GB。

Figure 4 Overall evaluation of algorithm
通过图4a和图4b可知,经过并行度优化策略的调整,4个作业的作业执行时间均得到降低,DSCS有效地提高了工作节点的平均内存利用率。对并行度预估算法而言,作业处理的数据量和工作节点的内存容量是评估并行度的重要依据,能够尽量减少工作节点内存溢出和频繁垃圾收集,缩短作业执行时间;对于数据倾斜修正算法,数据分布越倾斜,宽依赖的同步代价越大,延时也越大。数据倾斜修正算法能够将倾斜度较大的数据进行划分,为合理的分区映射提供依据;异构节点任务分配算法能够根据节点的计算能力分配数据块,解决节点计算能力不均衡的问题,提高工作节点资源利用率和计算效率。因此,从总体上来看,数据倾斜修正调度策略具有良好的优化效果。
6 结束语
现有的研究较少关注异构Spark系统设置中的并行度参数,往往根据经验进行设定,很难契合不同的作业类型和数据量大小,不能在作业各计算阶段的执行过程中发生变化。因此,本文根据作业的数据量、数据分布倾斜情况和节点的计算能力进行评估,提出了适应计算阶段状态变化的数据倾斜修正调度策略,其中包括并行度预估算法、数据倾斜修正算法和异构节点任务分配算法3个部分。计算细粒度任务的并行度并进行计算数据合理分配。实验表明,该策略能够较好地贴合作业类型、数据分布和节点计算能力,有效地提高了作业执行效率。下一步将针对于每阶段任务的具体操作,计划采用回归的方法,争取对数据的内存需求进行更精确的预估,从而实现作业执行效率更高级别的提升,并将研究内容延伸至流式计算平台的并行效率优化。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
小学教学研究(2022年5期)2022-04-28
北京大学学报(自然科学版)(2021年3期)2021-07-16
电脑爱好者(2020年19期)2020-10-20
电脑爱好者(2020年18期)2020-09-26
电子制作(2019年13期)2020-01-14
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
电脑爱好者(2017年9期)2017-06-01
网络与信息(2009年9期)2009-10-30
