
分布式存储系统读写一致性算法性能优化研究综述*
2022-04-21 04:43沈佳杰卢修文赵泽宇
计算机工程与科学 2022年4期
沈佳杰,卢修文,2,3,向 望,赵泽宇,王 新,2,3
(1.复旦大学校园信息化办公室,上海 200433;2.复旦大学计算机科学技术学院,上海 200433;3.复旦大学上海市智能信息处理重点实验室,上海 200433)
1 引言
分布式存储系统[1]广泛使用读写一致性算法来保证数据可用性。通过使用特定的协议,分布式存储系统保证了用户读写数据的一致性。经典拜占庭问题[2]存在数据篡改[3]的情况,而读写一致性问题假定所有节点都会遵守通信协议传输用户数据[4]。与此同时,通过部署读写一致性算法,分布式存储系统能避免在部分节点失效情况下出现服务中断的问题,从而有效提升存储数据的可用性[5]。
然而,读写一致性算法通常会带来较大的网络通信和存储开销[4],并降低分布式存储系统中用户数据访问的能力。开发人员研发分布式存储系统的过程中需部署满足存储应用场景需求的读写一致性算法,并调整该算法执行机制。但是,根据应用场景选择适用的读写一致性算法依然具有很大的挑战性。
首先,各种读写一致性算法通常采用不同实现机制,需要综合分析在目标应用场景中部署特定算法的合理性。其次,由于读写一致性算法的数据写入操作性能受到数据量和网络状态等多种因素的影响,需适应目标应用场景的读写请求特性和网络条件。最后,部署读写一致性算法的过程中需要充分了解不同应用场景的特点,并相应地调整算法的执行机制。
为了帮助开发人员选择适合特定应用场景的读写一致性算法,本文总结了主流读写一致性算法实现方案,综述了分布式存储系统中读写一致性算法的实现机制,分析了这些实现机制对数据读写操作性能的影响,总结了在各种存储应用场景中部署读写一致性算法需注意的要点,主要包括以下内容:
(1)介绍了读写一致性算法常见的实现机制。本文总结了读写一致性算法主要的实现方案,并归纳了这些实现方案的优缺点,总结了这些算法适用的应用场景。在此基础上,本文分析了分布式存储系统中部署读写一致性算法的关键问题,总结了分布式存储系统中读写一致性算法对这些问题的解决方法。
(2)综述了读写一致性算法性能优化工作。由于副本和纠删码作为主要的数据可靠性保障机制被广泛部署到分布式存储系统,本文综述了针对这2种存储机制构建的读写一致性算法,比较了这些算法的存储开销、容错性能和存储机制等特性。
(3)总结了在不同数据存储应用场景中部署读写一致性算法需注意的要点。在综述算法实现方案的基础上,本文分析了单数据中心分布式存储系统和跨数据中心云际存储系统2种经典应用场景中制约执行效率的因素,展望了未来分布式存储系统中读写一致性算法性能优化工作的研究方向,给出了可能的解决方案。
2 读写一致性问题及挑战
本节将介绍读写一致性问题、部署读写一致性算法的目标和面临的挑战。
2.1 读写一致性问题
分布式存储系统广泛存在节点失效和网络故障,读写一致性算法需要保证在部分节点和网络功能失效的情况下数据的可用性。不同于拜占庭问题[2]存在数据篡改[3]的情况,读写一致性问题假设分布式存储系统满足以下条件:
(1)所有的存储节点都有可能出现节点失效和通信故障,无法保证及时回复通信消息。
(2)所有在线存储节点的通信信息都遵守读写一致性协议的规定。
图1展示了一个包含4个存储节点和3个用户的读写一致性问题示例[4]。

Figure 1 Consensus problem between multiple storage nodes
由于网络可能无法保证所有节点的连通性,在图1中,当存储节点断开连接后,用户1和用户2分别向2个存储节点返回了更新值x=A和x=B。当用户3需要读取变量x的值时,该用户将无法确定其当前值。
2.2 读写一致性算法的目标
为了避免读写数据不一致的情况,需要部署读写一致性算法来保证数据的可用性。具体来说,读写一致性算法需要满足以下特性:
(1)可靠性:在存储节点未出现拜占庭错误的情况下,分布式存储系统不能回复错误信息。
(2)鲁棒性:在大部分存储节点正常在线并能相互通信的情况下,通过读写一致性算法,能保证用户正常读写数据。
在此基础上,开发人员需要根据存储应用场景的需求部署相应的读写一致性算法来保证数据读写操作的性能。
2.3 部署读写一致性算法面临的挑战
虽然读写一致性算法能够保证数据读写操作的正确性,研究人员依然需要根据应用场景选择合适的读写一致性策略。具体来说,部署读写一致性算法时将面临以下挑战:
(1)为了保证用户从节点中读写数据的正确性,读写一致性算法通常要求分布式存储系统执行多次数据传输操作,以确定存储节点的状态[3]。这些传输操作往往会带来较大的数据读写时延,影响其上在线应用对用户的服务质量。
(2)读写一致性算法通常需要复杂通信协议。例如,Raft算法[6]需要选举主节点来协调存储节点共同完成数据读写操作。在跨数据中心场景中,在分布式存储系统选举出的主节点网络状态较差的情况下,主节点的通信时延会严重影响读写用户数据的性能[7]。
(3)读写一致性算法需要保证存储数据的可靠性。在出现部分存储节点失效的情况下,读写一致性算法需要保证分布式存储系统能完成数据读写操作[5]。因此,读写一致性算法需要设计一定的冗余机制,保证分布式存储系统可以稳定地向用户端设备提供存储服务。
3 读写一致性算法的实现机制
本节简述3种类型读写一致性算法实现机制。
3.1 基于中心控制的读写一致性算法
基于中心控制的读写一致性算法[1]部署额外的控制节点来保证读写数据的正确性。由于实现较为简单,该类算法被广泛部署于分布式存储系统。例如,HDFS(Hadoop Distributed File System)[1]使用名字节点(Name Node)和数据节点(Data Node)组成主从结构。
为了保证读写一致性,控制节点定义主副本(Primacy Replica)和备用副本(Backup Replica)。分布式存储系统可以根据主副本所存储内容来确定当前值。即使主副本失效,控制节点依然能根据多个备用副本数据确定当前值,定义新的主副本,保证数据可用性。图2展示了HDFS存储系统中3副本数据写入过程[1]。

Figure 2 Write process for three replicas in HDFS
在数据写入过程中,用户优先写入元数据到控制节点,再更新数据节点中副本内容。分布式存储系统读取主副本来确定当前存储数据的值。当数据失效时,通过读取备用副本信息和版本信息能够恢复出失效的主副本数据。
基于中心控制的读写一致性算法被广泛应用于早期分布式存储系统,以保证数据读写一致性,如HDFS[1]和GFS(Google File System)[8]。由于数据读写过程需要访问控制节点存储的元数据,控制节点失效往往会严重影响存储服务的可用性。
虽然基于中心控制的读写一致性算法能够保证读写数据的正确性,但是主副本的存储节点往往会成为性能瓶颈,为了保证数据写入的性能,读写一致性算法需要引入相应的机制。
此外,基于中心控制的读写一致性算法主要通过控制节点协调其他参与节点来完成数据读写操作[1],包括两阶段提交协议2PC(Two-Phase Commit)[9]和三阶段提交协议3PC(Three-Phase Commit)[10]。基于中心控制的读写一致性算法依然需要在控制节点失效时保证分布式存储系统能够正确地执行数据读写操作。
3.2 基于消息传递的读写一致性算法
为了在控制节点失效的情况下保证分布式存储系统依然可以有效地完成数据读写操作,基于消息传递的读写一致性算法[5]采用存储节点投票的方式来将用户数据写入存储节点。
基于消息传递的读写一致性算法包括3种类型的节点:提案节点(Proposer)、仲裁节点(Acceptor)和学习节点(Learner)。通过满足以下3个条件,Paxos算法[5]能保证所有遵守通信协议的提案(Proposal)执行结果的正确性。
(1)所有提案有唯一的编号。
(2)任意2个提案P1和P2至少有1个相同的仲裁者。
(3)对于任意提案P,如果提案P的投票节点在之前的提案中同意更新变量值,那么提案P设定的变量值,需要和最近被投过赞成票的提案变量值保持一致。
根据上述3个条件,Paxos算法可以构建一个读写一致性的提案集合。这里使用单个变量实现一个案例来说明Paxos算法的投票过程。
假设存储系统中存在5个仲裁节点A、B、C、D和E接收到来自存储系统中提案节点的5条提案,提案编号为1,6,13,25和31。
图3展示了由5个仲裁节点参与的Paxos投票过程[5]。其中,用黑体字标注的节点为回复数据值成功执行的存储节点。这5个节点需要在2个值中选择1个值,并将其保存到所有节点。
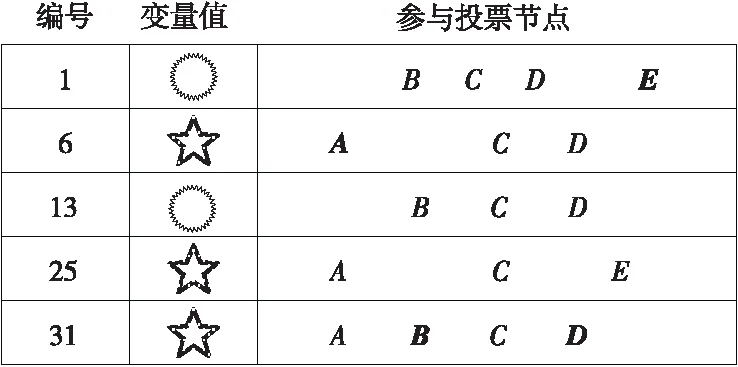
Figure 3 Message delivery-based consensus algorithms
提案1:第1个提案虽然有4个节点参与了提案的投票过程,但仅有节点E确认了提案信息。因此,提案1未成功通过仲裁阶段,无法更新存储节点的变量值。
提案6:由于投票的节点在之前没有投过赞成票,提案6可以选择不同的变量值。但是,只有节点A确认了提案信息,少于半数以上(即3票),提案6依然没有通过。
提案13:由于节点B、C和D之前提案没有更新过变量值,提案13可以将变量值更新为任意值。本轮节点B和节点D确认了该提案,但赞成的票数依然少于半数,提案13未通过。
提案25:由于提案节点收到3个节点A、C和D的确认信息,提案25是唯一更新变量值成功的提案。其中,节点A和节点E分别在提案6和提案1上更新了数值且提案6的编号更接近提案25的。提案25更新的变量值应当与提案6所更新的变量值相同。
提案31:为了保证所有节点存储的变量值都相同,存储节点需要与其他节点同步变量值。提案31将已经更新的变量值同步到另外2个节点。
在上述例子中,通过满足3个读写一致性条件,分布式存储系统可以实现全局提案集合的读写一致性。在实际存储系统中,提案节点需要根据生成的提案编号,保证所有的存储节点可以高效地完成相应的数据更新操作。
为了简化数据写入过程,Paxos算法采用以下步骤来完成数据写入过程:
(1)准备阶段:提案节点生成全局唯一的提案编号,向所有的仲裁节点发送该编号。仲裁节点根据收到的编号信息,判断是否接受这条提案,相应的处理结果回复给提案节点。
(2)仲裁阶段:提案节点向仲裁节点发送提案变量值,仲裁节点接收变量值后返回确认信息。当收到大部分仲裁节点对变量值更新的确认消息后,提案节点标记该提案已通过。
(3)学习阶段:提案节点将更新的变量值发送到没有参与到仲裁过程的其他的学习节点,从而完成所有存储节点变量值的更新操作。
通过上述步骤,Paxos算法保证了分布式存储系统读写数据的正确性。由于读写过程中任一节点都能够作为提案节点发起写入操作,Paxos算法能够有效地避免单个节点成为性能瓶颈,从而提升数据读写操作的性能。
图4展示了Paxos算法执行过程示意图[12]。
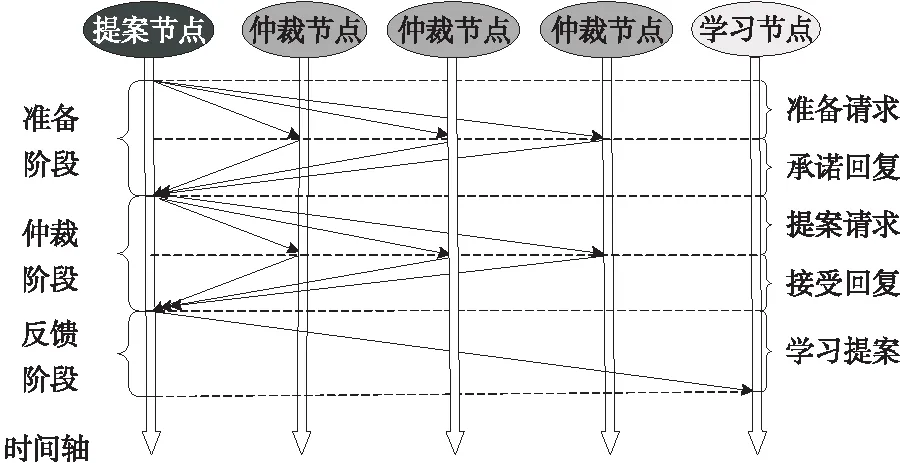
Figure 4 Transmission process with Paxos
为了保证全局提案编号的唯一性和有序性,当仲裁节点收到编号为ir的准备请求后,仲裁节点将针对接收到的提案作出以下2个承诺:
(1)仲裁节点不再接收提案编号ip小于或等于当前提案编号的提案请求。
(2)仲裁节点不再接收提案编号i′r小于当前提案编号ir的准备请求。
虽然基于消息传递的读写一致性算法可以从理论上保证数据读写操作的正确性,但是基于消息传递的读写一致性算法需要较为复杂的通信规则,往往会增加实现算法的难度,难以保证存储数据的可靠性。因此,如何降低Paxos算法实现的复杂度,成为了保证数据读写操作可靠性的关键问题。
3.3 基于选举的读写一致性算法
基于选举的读写一致性算法[6]通过在在线节点中确定主节点的方式来实现在保证读写数据正确性的前提下降低算法复杂性。这里使用Raft算法[6]作为示例来介绍基于选举的读写一致性算法的执行过程。通过从在线从节点中选举出主节点,Raft算法能够保证主从节点之间的读写数据一致性。
图5展示了Raft算法主从节点的示意图[6]。

Figure 5 Leader and followers node in Raft
Raft算法包括以下3种类型的节点:从节点、候选节点和主节点。
通过在存储节点中维护本地状态机,Raft算法使用选举机制来实现每个存储节点在从节点、候选节点和主节点3种类型节点之间的状态转换操作。分布式存储系统需要周期性地执行选举操作来确定主节点,以协调数据读写操作,从而保证提供持续的数据存储服务。
图6展示了Raft算法选举过程的状态机[6]。

Figure 6 State machine of Raft algorithm selection process
由图6可知,Raft算法中的存储节点通过以下状态转移规则切换其状态类型。
(1)从节点:在分布式存储系统上线时,所有在线节点以从节点状态等待进入选举过程。当新的选举周期开始时,从节点将成为候选节点参与读写一致性算法主节点投票选举过程。
(2)候选节点:候选节点收到大多数节点的支持票后将成为主节点。当发现分布式存储系统中已经存在主节点或选举周期过期时,候选节点将回退成为从节点等待下一个选举周期,再次参与主节点选举过程。
(3)主节点:在收到大多数节点的支持票时,候选节点会将自己的状态设置为主节点。为了保证分布式存储系统主节点的唯一性,当主节点在通信过程中发现存在更高优先级的主节点后,会将自己的状态设为从节点。
每隔一定周期后,分布式存储系统会重新选举主节点,负责协调存储节点处理用户端发出的数据读写请求。
图7展示了Raft算法周期示意图[6]。

Figure 7 Terms of selection process in Raft algorithm
虽然Raft算法可以通过选举过程确定主节点来解决读写一致性问题,分布式存储系统依然需要通过读写主节点存储的内容来确定保存在分布式存储系统中的各个变量的当前值。
Raft算法使用复制状态机来保证所有的主从节点数据的一致性。图8展示了Raft算法日志数据提交过程[6],包括3个存储节点和2个变量,变量x和变量y。每一个日志项包括2部分内容,提交时的周期值和变量的改变值。这里将3个节点分别记为主节点、从节点1和从节点2。

Figure 8 Submission process of Raft algorithm log data
在图8中,使用深浅不同的颜色表示在各个周期中用户端设备提交的数据写入请求。为了提升Raft算法的执行效率,不同于经典的两阶段提交算法,状态机复制过程中不要求所有在线节点存储的日志数据都为当前最新版本,仅需保证多数节点确认数据写入,即认为存储系统已提交了变量值。在用户访问主节点存在较大时延的情况下,主节点会成为整个分布式存储系统数据读写操作的性能瓶颈。
3.4 读写一致性算法实现机制比较
在部署分布式存储系统的过程中,开发人员需要根据应用场景选择适合的读写一致性算法和性能优化方案,调整读写一致性算法的存储和通信机制来保证数据读写操作的性能。表1比较了3种类型读写一致性算法的实现难度、算法机制和容错性方面的特点。

Table 1 Comparison of the mechanism of different consensus algorithms
4 读写一致性算法性能优化方案
本节主要综述使用副本和纠删码2种常见的数据存储方案的情况下,读写一致性算法的实现机制和性能优化方案。
4.1 分布式存储系统的数据存储机制
为了适应不同应用场景的存储需求,分布式存储系统往往采用副本和纠删码2种数据存储机制来保证存储数据的可靠性。
(1)副本存储方案:通过将用户数据的多个副本存储到多个存储节点来保证数据可靠性。
(2)纠删码存储方案:将用户数据切片生成数据分片,编码数据分片生成多个检验分片,并将这些分片存储到多个存储节点,从而保证分布式存储系统的数据可靠性。
4.2 基于副本的读写一致性算法性能优化
为了保证存储在多个节点副本数据的一致性,研究人员提出了基于消息传递的读写一致性算法。如Lamport[5]提出了Paxos算法,以保证存储节点数据的读写一致性。文献[12]介绍了Paxos算法的运行机制。Chandra等[13]讨论了证明Paxos算法代码正确的方法。Lamport[14]提出了异步Paxos算法,通过并行化读写数据来减小读写操作时延。类似工作还有Fast-Paxos[15]、Vertical Paxos[16]、Cheap-Paxos[17]、DPaxos[18]、Flexible Paxos[19]和EPaxos[20]。然而,这些算法需要使用较为复杂的读写一致性协议,通常会产生额外的数据传输开销,降低分布式存储系统数据读写操作的性能。
为了提升分布式存储系统读写一致性算法的执行效率,研究人员提出了多种读写一致性算法性能优化方案。如Junqueira等[22]提出的ZAB(Zookeeper Atomic Broadcasts)协议通过广播机制来保证读写性能。读写一致性系统组件ZooKeeper[23]使用ZAB协议来提升读写操作的性能[24]。Brenner等[25]提出了SecureKeeper框架,引入因特尔SGX (Software Guard eXtensions)指令集提升ZAB协议的安全性。Frommgen等[26]提出在ZooKeeper运行过程中切换读写一致性算法来保证服务质量。史博轩等[27]使用ZooKeeper构建统一信任锚模型。Gray等[28]提出了租约机制Leases方案来提升缓存服务的性能。Moraru等[29]使用Go语言实现了分布式租约机制[30]。Decandia等[31]提出了Dynamo存储系统,部署了NWR算法[32]来调整读写一致性算法执行过程中副本数量n、写入副本数量w和读取副本数量r等参数来适应不同的分布式存储系统应用场景。王华进等[32]分析了NWR算法在不同参数情况下队列解析开销和数据写入时延。Huang等[33]使用排队论分析可能导致Cassandra数据库短时间数据不一致的原因。朱涛等[34]总结了读写一致性算法和数据可用性的关系。Wang等[35]通过测试HBase[36]和Cassandra[37]2种常用数据库系统来分析副本数据对数据读写操作性能的影响。类似工作还有Scatter[38]、ZooNet[39]、COPS(Clusters of Order-Preserving Servers)[40]、WPaxos[41]、Spanner-RSS(Spanner Regular Sequential Serializability)[42]、PaxosLease[43]和Volume leases[44]等。
为了提升存储系统软件的可靠性,研究人员使用多种方法来降低基于消息传递的读写一致性算法的实现复杂度。如Lamport等[45]使用了可重设置状态机来实现读写一致性算法,并证明了其算法的正确性。Ongaro等[6]提出了Raft算法来实现主节点选举和主从节点数据同步过程。Lampson[4]分别总结了Paxos在经典读写一致性问题、磁盘读写一致性问题和拜占庭读写一致性问题场景的案例。这些读写一致性机制也被部署到了ZooKeeper[23]和Chubby[46]等分布式读写一致性管理系统中。
在此基础上,研究人员针对各种分布式存储系统应用场景提出了相应的读写一致性算法性能优化方案。如Li等[47]提出了NOPaxos(Network Ordered Paxos),使用网络层广播协议来减少读写一致性算法执行过程的数据传输开销。Mahmoud等[48]提出了Replicated Commit来提升跨数据中心通信性能。Nawab等[49]推导出了跨数据中心数据提交过程消耗时间下限。Guo等[50]设计了面向SQL语义的读写一致性方案来提升并行化事务处理性能。类似工作还有Dynamo[31]、Cassandra[37]、MegaStore[51]、Spanner[52]、FSS (File Storage Service)[53]、Volley[54]、Harp[55]、Mencius[56]、etcd[57]和MDCC(Multi-Data Center Consistency)[58]等。虽然能保证读写数据的一致性,基于副本的读写一致性算法在执行过程中需要传输大量的用户数据,会带来较大的数据传输开销。为了保障数据读写操作的执行效率,纠删码作为一种能减少传输开销的机制被用于减少读写过程中的传输开销。
4.3 基于纠删码的读写一致性算法性能优化
纠删码作为一种常见的数据可靠性保障机制被广泛部署到了分布式存储系统中来保存用户数据。如Reed等[59]提出了RS(Reed-Solomon)编码来保证数据可靠性。Dimakis等[60]提出了再生码来减少数据修复操作的网络传输开销。Shum等[61]提出了合作再生编码来减少多节点失效时数据修复操作的网络传输开销。Huang等[62]提出了LRC (Local Reconstruction Codes)来减少单存储节点数据失效情况下数据修复操作的网络开销。Shen等[63]使用网络编码来加速云际存储系统数据写入操作的性能。类似的工作还有Core[64]、CaCo(Cauchy Coding)[65]、PUSH[66]、AONT-RS(All-Or-Nothing Transform with Reed-Solomon coding)[67]、CAONT-RS(Convergent AONT-RS)[68]、CDStore[69]、UniDrive[70]和RDOR(Row-Diagonal Optimal Recovery)[71]等。
为了保证数据读写操作的执行效率,研究人员提出了基于纠删码的读写一致性算法来减少数据读写过程中传输的数据量。如Mu等[72]提出了RS-Paxos算法,引入了纠删码机制来减少Paxos算法执行过程中数据传输量。Wang等[73]提出了CRaft算法来将Raft算法部署到纠删码存储系统中。由于基于选举的读写一致性算法需要通过主节点读写数据,会降低网络传输性能,Uluyol等[7]提出了Pando方案来高效部署Paxos算法,优化纠删码存储系统跨数据中心的数据读写时延,且已被应用到了联邦学习[74]等场景中。通过传输编码后的用户数据,基于纠删码的读写一致性算法能够有效减少执行数据读写操作过程中网络带宽资源的消耗量。然而,纠删码也带来了数据修复操作带宽消耗量大和数据读写操作消耗时间长等一系列问题[75]。
为了保证数据可靠性,提升用户读写数据的效率,研究人员提出了多种性能优化方案提升在各个应用场景中纠删码存储系统执行数据修复操作和数据读写操作的性能。Chen等[76]提出了Giza来保证跨数据中心的纠删码对象存储系统的数据读写一致性。Chen等[77]提出了副本和纠删码混合存储方案来提升内存对象存储系统的数据读写操作性能。Sathiamoorthy等[75]将再生码部署到HDFS存储系统中,以减少数据修复操作的网络传输开销。Shen等[78]提出了跨机架的路由方案来加速多个存储节点的数据写入过程。Shi等[79]设计了UMR-EC(Unified and Multi-Rail Erasure Coding)编码架构优化数据读写操作的执行过程。Renesse等[80]综述了Paxos算法相关读写一致性算法。
4.4 读写一致性算法性能比较
为了满足应用场景的存储需求,开发人员需要了解读写一致性算法的系统开销和相应的实现机制。本节将分析各种读写一致性算法的存储空间和容错性能。本节将容错节点数量定义为在执行数据读写操作过程中容忍失效节点的数量,该参数越大说明读写一致性算法可以在越多节点失效的情况下执行读写操作。
表2比较了主要读写一致性算法的存储开销、容错节点数量及其实现机制。表2中,存储开销代表存储数据所消耗磁盘空间大小,n为存储节点的数量,r为设定读取节点的数量,k为数据节点的数量。假设用户将数据量为M字节的文件保存到n个存储节点中。分布式存储系统能够使用副本和纠删码机制通过以下步骤完成数据读写操作:
在副本存储情况下,每一个节点的数据量为M字节。由于存在n个节点,分布式存储系统共存储了n*M字节数据。由于所有节点都保存和传输重复数据,副本机制通常会消耗大量存储空间和网络带宽,影响数据读写操作的性能。在纠删码存储情况下,用户端设备将文件分成k个数据分片,将数据分片编码生成m个校验分片,并存储到n=k+m个存储节点中。其中,每一个存储节点将保存M/k字节数据,所以n个存储节点共保存(n*M)/k字节数据。

Table 2 Comparison of performance of different consensus algorithms
由于纠删码机制将数据编码保存到多个存储节点,相较于副本机制,分布存储系统能够在消耗更小的存储空间的前提下保存相同的数据内容。然而,基于纠删码的读写一致性算法需要更多在线节点和更大计算开销才能正确地完成数据读写操作,降低了存储数据的可用性。
5 应用场景对读写性能的影响
本节将比较2种应用场景(即单数据中心分布式存储系统和跨数据中心云际存储系统)中影响读写一致性算法性能的因素。
5.1 读写一致性算法的应用场景
开发人员需要充分了解各种算法的性能,才能选择适合当前存储应用场景的读写一致性算法。具体来说,读写一致性算法部署在以下2种分布式存储应用场景:
(1)单数据中心分布式存储系统:在写入数据量较大的情况下,前端服务器数据写入和数据同步过程消耗的时间占数据写入时间的很大一部分[8]。为了保证读写数据的性能,开发人员需要优化读写操作执行流程,以减少数据读写过程中的网络通信开销。
(2)跨数据中心云际存储系统:为了避免单数据中心可能出现的数据泄露和丢失等问题,跨数据中心云际存储系统将数据存储在多个数据中心。由于数据被存储在不同地理位置的云存储节点,需要充分考虑各个云存储节点之间的传输时延。
5.2 单数据中心分布式存储系统
由于单数据中心需要运行多种业务,存储节点之间的可用带宽通常非常有限。图9展示了包括1个用户和4个存储节点的分布式存储系统的数据写入操作的执行过程:
在图9a中,不同的存储节点之间带宽具有较大的差异性,需要充分利用用户端设备和存储节点之间的带宽资源。
图9b展示了传统数据写入方案的路由。由于用户端设备直接将数据写入到存储节点,写入过程通常会受到瓶颈链路带宽的限制。
在图9c中,通过合理设计数据传输路由,分布式存储系统可以有效避开网络拓扑的瓶颈链路,保证数据写入操作的性能。
5.3 跨数据中心云际存储系统
为了保证在跨数据中心场景中数据读写操作的性能,部署读写一致性算法时,存储系统设计人员需要注意以下要点:
(1)为了保证用户访问的性能,前端服务器应当尽量靠近存储节点,减少网络传输时延。
(2)任意2个前端服务器至少需要访问1个公共的存储节点来保证数据一致性。
图10展示了跨数据中心数据读写过程。

Figure 9 Example of the route strategies for the write operations in distributed storage systems
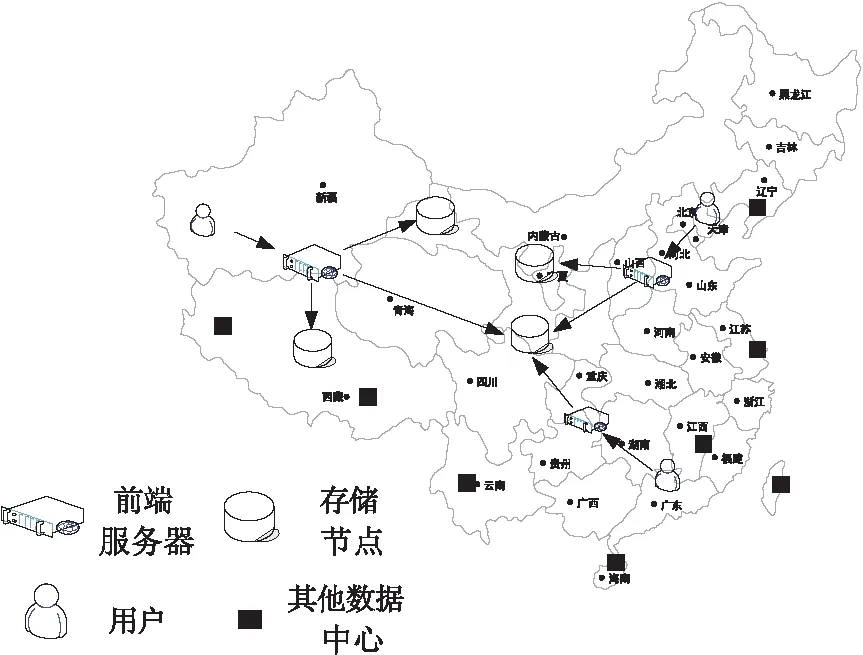
Figure 10 I/O process of the consensus algorithms between multiple data centers
在实际的云际存储系统中,前端服务器访问保存在不同存储节点的数据的传输时延往往存在着较大差异性,因此,前端服务器需要选择访问传输时延较小的存储节点,以保证对用户数据访问操作的服务质量。
6 读写一致性算法部署建议和展望
本节将总结部署读写一致性算法需注意的要点以及学术研究和工业领域亟需解决的问题。
6.1读写一致性算法部署建议
在实际的生产系统中,开发人员在部署读写一致性算法时应当注意以下方面:
(1)根据应用场景中数据写入请求数据量大小的差异,开发人员需要分析读写一致性算法中各个阶段在数据读写操作中的时间占比。为了保证数据读写操作的执行效率,分布式存储系统需要根据数据读写操作的特征部署合适的读写一致性策略和性能优化方案。
(2)根据分布式存储系统的数据存储机制,开发人员需要选择合适的读写一致性算法来满足存储应用的性能需求。由于副本和纠删码存储机制有较大的差异,分布式存储系统需要部署对应的读写一致性算法来适应各种存储机制下数据读写操作的性能。
(3)根据应用网络环境的特性,包括传输时延和网络带宽,开发人员需要优化读写一致性算法的通信机制来减小数据传输带来的开销。针对不同的存储应用场景,分布式存储系统需要引入相应的传输策略来减小读写一致性算法数据读写操作的传输开销。
6.2 读写一致性算法研究工作展望
虽然当前读写一致性算法能保证数据读写操作的性能,但是当前读写一致性算法依然存在诸多问题,如网络适应能力弱和难以适应不同大小的数据读写请求。为了满足用户读写性能需求,需要部署以下优化方案:
(1)高自适应存储机制:随着承载服务类型的增加,业务系统通常提供多种不同的在线服务。由于单独使用副本机制和纠删码机制适合的应用场景有限,分布式存储系统需部署多种存储机制融合的读写一致性算法,动态调整其存储机制,以适应日益复杂的应用场景。
(2)动态调整网络路由策略:由于存储节点之间的网络通常存在较大异构性,读写一致性算法需要根据分布式存储系统的网络状态调整存储节点之间的网络路由策略,以保证分布式存储系统数据读写操作的性能。
(3)构建智能读写一致性算法:在执行当前读写一致性算法过程中,存储节点通常使用固定通信协议来保证读写操作的正确性,难以满足服务质量需求。通过引入人工智能方案分析过往的用户行为和存储集群状态,智能读写一致性算法能够有效提升数据读写操作的性能。
6.3 工业界读写一致性算法性能优化展望
虽然当前工业界已广泛部署了读写一致性组件库(如ZooKeeper[23])来保证分布式存储系统执行数据读写操作的正确性,但是这些组件库存在应用场景单一和读写开销较大等问题,依然有以下值得进一步开展研究的方向:
(1)测试读写一致性算法性能: 虽然研究人员已开展了大量的读写一致性算法性能优化工作,但现有研究中依然缺少对读写一致性算法的性能定量测试比较工作。根据读写一致性算法的实现机制,亟需构建大量定量系统性实验来充分测量读写一致性算法的性能,便于开发人员选择适合存储应用场景的读写一致性算法。
(2)构建副本和编码混合读写一致性机制:由于不同存储机制适用的应用场景具有较大的差异,现有适用单一存储机制的读写一致性算法难以满足多种用户的数据读写需求,设计副本和编码混合的读写一致性算法将会有效扩大读写一致性算法的适用范围。
(3)引入新硬件设备减少读写开销:随着新的时钟硬件(如铯原子钟[81])在数据中心的应用,存储节点可精确地获取当前时间,更容易实现时钟同步操作。如何构建适应新存储硬件设备的读写一致性方案也将成为提升读写操作性能的重要研究方向。
7 结束语
本文综述了分布式存储系统中的读写一致性算法的实现机制,并分析了这些算法适宜的应用场景,从而为开发人员部署读写一致性算法提供了相应的理论依据。在总结读写一致性算法挑战性的基础上,还总结了读写一致性算法主要的实现方案,综述了相关的性能优化工作。在此基础上,本文分析了单数据中心分布式存储系统和多数据中心云际存储系统2种应用场景中各种参数对读写一致性算法数据写入操作性能的影响,并给出了在这些应用场景中部署读写一致性算法需注意的要点,展望了未来可能的性能优化方案。
猜你喜欢
教学考试(高考物理)(2021年5期)2021-11-08
历史教学问题(2021年4期)2021-11-05
中医眼耳鼻喉杂志(2021年1期)2021-07-22
哈尔滨轴承(2020年2期)2020-11-06
网络安全和信息化(2019年8期)2019-08-28
计算机系统应用(2019年2期)2019-04-10
发明与创新·大科技(2019年12期)2019-03-17
小型微型计算机系统(2018年3期)2018-03-27
燕山大学学报(2015年4期)2015-12-25
弹箭与制导学报(2015年1期)2015-03-11
