
基于注意力机制的人体姿态估计网络
2022-04-20 09:19:24缪宁杰张如宏刘晓泽王佳敏罗文东
机械设计与制造工程 2022年3期
方 芹,缪宁杰,张如宏,刘晓泽,王佳敏,罗文东,周 霖
(1.国网浙江省电力有限公司双创中心,浙江 杭州 310051)(2.国网浙江省电力有限公司杭州供电公司,浙江 杭州 310009)(3.浙江光珀智能科技有限公司,浙江 杭州 311100)(4.杭州致成电子科技有限公司,浙江 杭州 310051)(5.北京大道合创科技有限责任公司,北京 100085)
二维人体姿态估计是计算机视觉中一个基础且具有挑战性的问题,目的是对图像中的人进行关节点(如手腕、手肘等)的检测定位。其应用领域非常广,可应用于动作识别、动作检测、人体跟踪、虚拟现实和自动驾驶等[1-5]。随着近几年卷积神经网络的快速发展,许多计算机视觉任务(如图像分割、物体检测等)因此受益,性能得到飞速提升。人体姿态识别也从中获益,目前主流的姿态识别网络分为两大类:自下而上和自顶向下的方法[6]。
自下而上的方法,首先直接预测每个关节点,然后把关节点组装成人。Pishchulin等[7]将区分图像中不同人的问题转换为整数线性规划(integer linear program)问题,并将部分检测候选划分为人员聚类,然后将聚类结果与标记的身体部分相结合,得到最终的预测结果。Insafutdinov等[8]使用了更深层次的ResNet[9]来改善区分图像中不同人的问题转换为整数线性规划问题的性能。Cao等[10]将关节点之间的关系映射到了部分亲和场,并将检测到的关键点组装成不同人的姿态。Newell等[11]增加了网络的输出,同时得到每个人的分数图和对应的像素级嵌入,然后将关键点分组到不同的人,以获得多人的姿态估计。
自顶向下的方法,将检测关节点分为两步,首先从图像中定位和裁剪所有的人,然后对每个单独的人进行姿态估计。Papandreou等[12]同时预测关节热图和标签热图对预测热图的偏移量,将两者相加得到最终的预测热图。He等[13]首先预测人类包围盒,然后根据相应的人类包围盒的特征映射来预测人类关节点。Tompson等[14]提出了级联网络,通过由粗到细的方式来预测关节点位置。Carreira等[15]提出了迭代误差反馈,通过多阶段的训练来细化每个阶段的预测结果。Xiao 等[16]使用3个反卷积模块,逐步生成高分辨的预测热图。由于首先要找到图中人的位置才能对其进行关节点预测,因此使用一个好的检测网络对于姿态识别任务是十分重要的。
很多学者倾向于使用复杂的网络结构来处理这些情况,这在提高精度的同时也加大了计算量和运行内存,更重要的是,复杂的网络结构加大了读者对算法理解和分析的难度。基于上述分析,本文将通道注意力机制融入到编码网络中,通过一维卷积来实现无降维通道之间的信息交互,提高了网络对重要特征的提取能力。
1 本文算法
本文提出的人体姿态识别网络如图1所示,输入一张图片,网络检测出关节点所在的像素位置。该网络由简单的编解码结构组成,为了使编码层提取的特征更具代表性,本文在编码层中加入了注意力卷积模块。在得到深层次的特征图后,使用多个反卷积恢复特征图的分辨率,最终预测出关节点所在的位置。
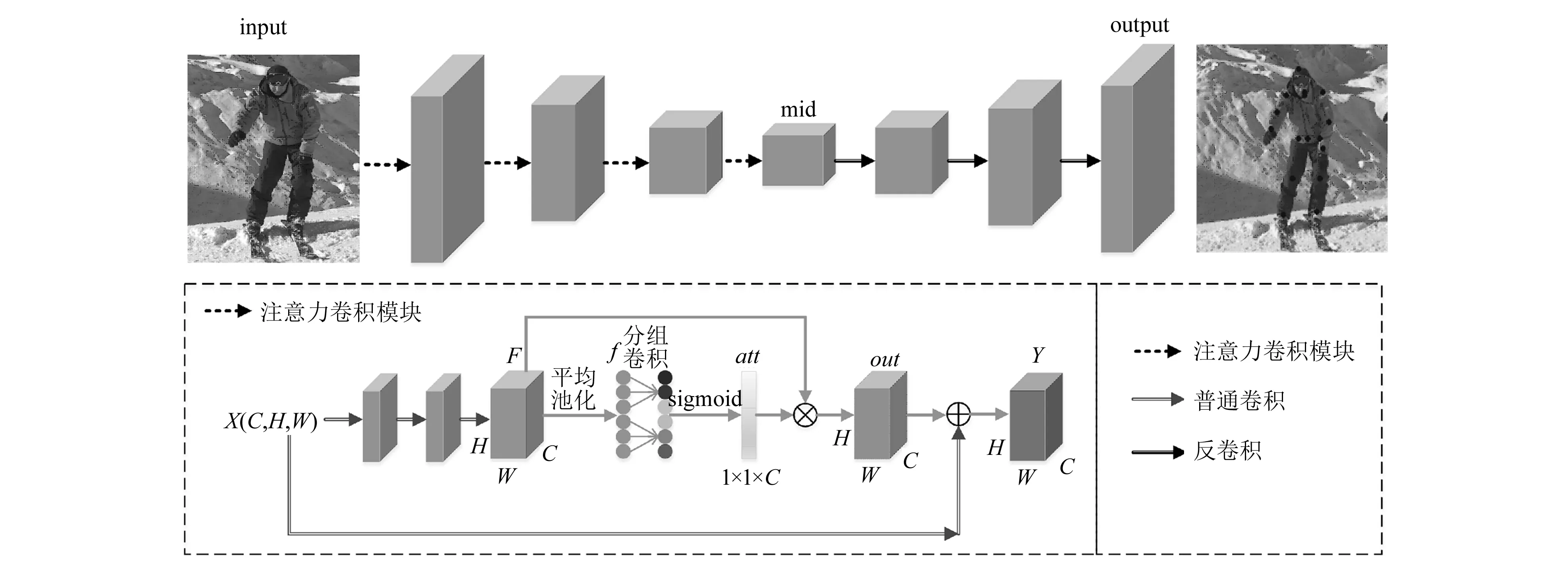
图1 网络框架
1.1 融入注意力机制的编码模块
由于人体姿态估计是一个难度大、高度非线性的任务,利用浅层网络直接预测出关节点的位置是不现实的,因此为了能够提取更具有代表性的深度特征,且易于网络的训练与搭建,本文采用预训练好的ResNet[9]系列(ResNet50/101/152)作为编码器的主干网络。受ECA-Net[17]的启发,本文在每个ResNet块之后嵌入注意力卷积模块来实现通道之间信息的交互,进而提升编码器对重要特征提取的能力,其结构如图2所示。

图2 融入注意力卷积模块的ResNet50残差块示意图
注意力卷积模块的详细结构如图1所示,假定X∈C×H×W,为网络的输入变量,其中C为特征通道数,H和W为特征图的高和宽。首先通过3个卷积层得到正方形卷积核的边长F,本文假定输入输出的维度是一样的,但在实际操作中会根据情况降低特征图的分辨率。紧接着,对F在特征图维度进行全局平均池化得到向量f:
f=avg(F)
(1)
式中:f∈C×H×W。为了节省计算资源,采用了分组卷积,先把特征图分成不同的组,然后再对每个组分别进行卷积,在不增加模型复杂度的情况下大大降低了运算成本。文献[17]通过实验证明自适应确定的卷积核大小通常要优于固定的卷积核大小,因此在分组卷积中本文采用自适应计算得到核的大小。本文使用sigmoid函数把f归一化到0和1之间,其值可以表征不同通道的重要性程度。
att=sigmoid(conv(f))
(2)
式中:att为通道注意力权重。
接着把前面得到的特征图F和通道注意力权重att按通道相乘,得到注意力感知的特征图out:
out=F⊗att
(3)
最后把输入端X和注意力感知的特征图out相加得到该模块的输出结果。
1.2 解码模块
在解码端,本文使用了3个简单的反卷积模块来得到最终的预测结果,其中卷积核大小为4×4,卷积核个数为256。注意,本文设计的网络并没有使用与UNet[18]类似的跳跃连接,因为这会加大模型的计算量。本文的目标是设计一个结构简单并且有效的人体姿态估计网络,加入一些额外的方法虽然会提升预测精度,但这会与本文的目的背道而驰。
如图1所示,假设输入解码层的特征mid∈C′×H′×W′,经过多个反卷积层后得到预测热图output,output∈num_joints×Hin/4×Win/4,其中num_joints为实验数据集中人的关节点数,Hin和Win分别为输入图片input的宽和高,为了减小计算量,网络最终预测得到的热图大小为输入图片的1/4,例如在COCO数据集上,本文设置的输入大小为(256,256),最终输出的热图尺寸即为(64,64)。最后,在解码器的输出端把预测到的关节点按比例放到原图中,即得到带有关键点标记的图片。
1.3 训练细节
本文使用Pytorch 1.3.7深度学习框架,编码模块使用基于ImageNet[19]预训练的ResNet网络进行初始化。训练使用ADAM优化器,基础学习率为0.01,并分别在90和120个训练周期时降低学习率,一共训练140个周期,批量大小为32。
与大部分姿态估计网络[11,16]相同,本文使用通用均方差损失来监督网络,将预测生成的热图和标签热图进行比较。为了提高预测精度,在把热图转换回图像原始坐标之前,将最终的预测坐标取热图上响应最高的点往响应第二高的点偏移1/4处的坐标。
2 实验分析
2.1 数据集
MPⅡ[20]数据集中包括人类活动的不同姿态图像,以及一系列具有挑战性的、有遮挡的姿势。MPⅡ数据集大约由25 000张图片组成,包含了大约40 000个人的姿态标签(其中28 000用于训练,11 000用于测试),每个人体标注16个关节点。由于官方并没有提供测试图片的姿态标签,所以本文将训练数据中的一部分用来训练网络,将没有参与训练的图片作为测试集,并报告了在该测试集上的实验结果。
COCO[21]数据集要求在不受控制的条件下定位多人的关节点。COCO数据集包含大约200 000张图像,250 000个带有17个关键点的人。该数据集被分为57 000张训练集、5 000张验证集和20 000张测试集。网络在训练集上进行训练,本文报告了在验证集上的实验结果。
由于MPⅡ和COCO数据集输入图片中包含多个人,直接对所有人进行姿势识别是困难的,因此首先根据标签数据把每个人单独裁剪出来,然后输入网络进行姿态识别。本文使用了与文献[16]相同的数据增强措施,对于一张图片,首先根据标签数据把整个人裁剪出来,然后将其调整到256×256大小(默认分辨率),接着对该图片进行随机旋转(-30°~30°)和缩放(0.75~1.25)得到最终网络的输入数据。
2.2 评价指标
MPⅡ使用的评价指标是关节点正确估计的比例PCK[22](percentage of correct keypoints),该指标表示标签归一化距离内的预测百分比,也就是预测关节点与标签关节点的距离小于阈值的百分比,阈值是头部大小的1/2,因此该指标也称为PCKh@0.5,其值越接近1越好。
COCO数据集采用的度量指标是关键点相似度OKS(object keypoint similarity ),与目标检测中的交并比IOU(intersection over union)类似,OKS表示标注关节点和预测关节点的重合程度,其值越接近1越好。
(4)
式中:i为关节点序号;di为标注关节点和预测关节点的欧氏距离;vi为关节点可见性;s为这个人所占的面积大小;ki为第i个关节点的归一化因子,这个因子是通过对数据集进行标准差计算得到的,反映出当前骨骼点对整体的影响程度。后续实验报告了平均的精确度AP0.5(指IOU的值取0.5),AP0.75(指IOU的值取0.75),AP(平均精度,使用积分的方式来计算PR曲线与坐标轴围成的面积),APM(指IOU的值取中间值),APL(指IOU的值取较大)。
2.3 实验结果
首先在MPⅡ数据集上对本文提出的网络进行了验证,实验结果见表1。由表可知本文的算法精度最精确,在手肘、手腕、膝盖、脚踝等关节处分别比文献[16]提高1.25%、2.7%、2.2%和2.67%,平均提高了1.37%。注意,表1中平均值并不是把前面几列值平均计算得到的,还需要把颈部、头顶的预测结果加上才是最终的平均值,由于文献[7]、[14]、[16]都没有列出颈部和头顶的预测结果,为了方便与它们进行比较,所以本文也采取一样的方式,仅列出部分重要关节处的指标。除了定量分析,本文同样进行了定性分析,预测结果可视化。图3第一行是网络预测的不同关节的热图,第二行是标签热图,图4展示了把所有关节点热图回归到原图上的结果,由图可知,本文提出的网络能够很好地预测出人的关节点。

图3 MPⅡ预测热图可视化

图4 MPⅡ实验结果可视化
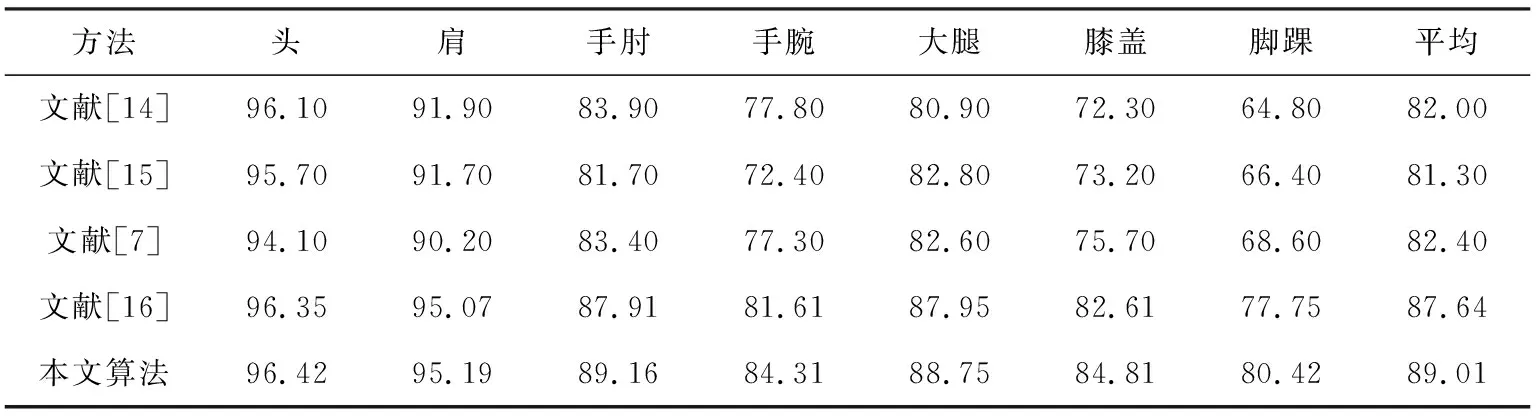
表1 MPⅡ数据集上不同方法的比较(PCKh@0.5) %
与大多数视觉任务一样,更深层次的网络具有更好的性能。在表2中,加大了残差网络的深度,实验结果表明,更深层次的网络能够有效地提升预测精度,这也说明了姿态识别是一个高度非线性的任务,使用浅层网络无法对关节进行有效的预测。

表2 MPⅡ数据集上不同深度网络的预测精度(PCKh@0.5) %
表3报告了在COCO数据集上实验的结果,本文使用ResNet50和ResNet101作为骨干网络。由表可知,使用ECA模块能够实现保持和原始网络几乎相同的模型复杂度以及单张图片的推理速度(即FLOPs、#.Param.和Speed),并且明显提高了网络的预测性能。例如在使用ResNet101作为骨干网络的情况下,使用ECA模块的AP0.5增加了3.3%,虽然使用CBA模块AP0.5也增加了3.3%,但是FLOPs、#.Param.和Speed 3个指标要明显高于使用ECA模块,尤其是Speed,使用ECA模块单张图片的推理速度仅需要4.70 ms,而使用CBA模块单张图片的推理速度却需要14.80 ms。总的来说,由于在编码层中加入了注意力机制,在保证网络不会丢失任何信息的情况下,使得网络可以提取更具代表性的全局特征,因此能够在重建后预测到更精确的关节点,从图5的可视化结果可以直观地看到预测的关键点十分准确。
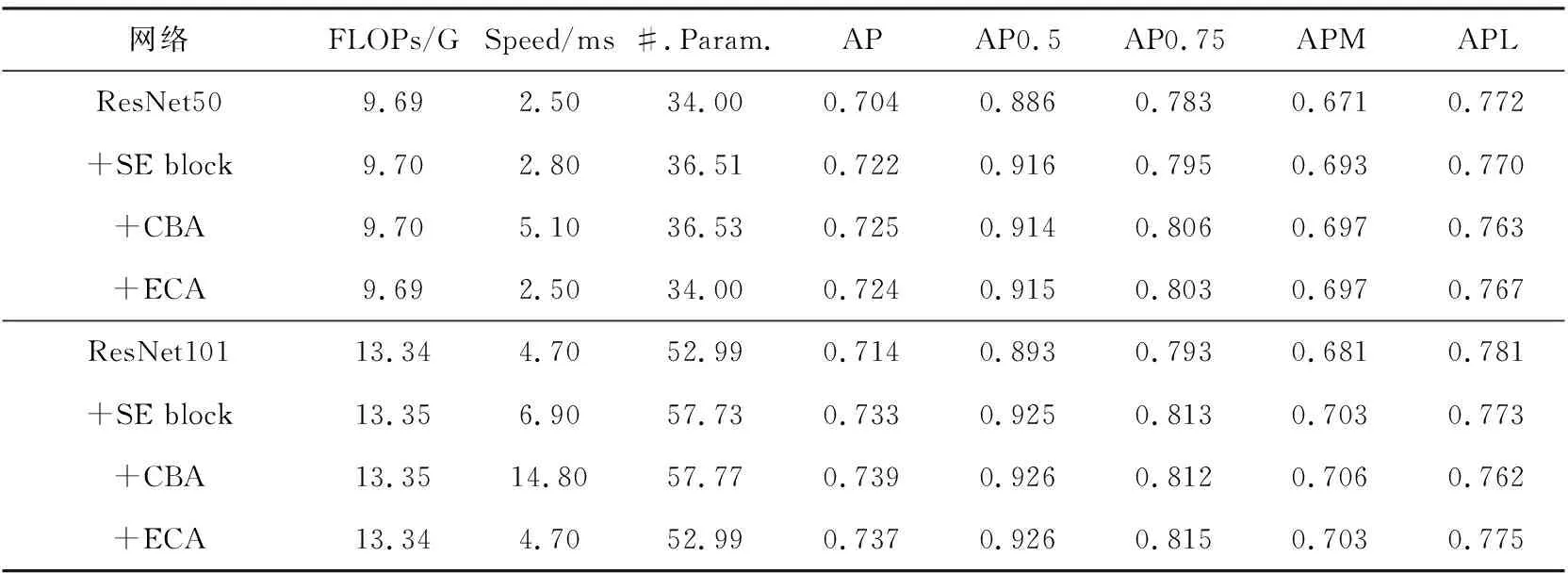
表3 COCO数据集上不同网络的比较

图5 COCO实验结果可视化
3 结束语
本文提出了一个有效的人体姿态估计网络,该网络仅由编码器、解码器两部分组成,其中编码器采用ResNet结构作为主干网络,解码器由3个反卷积模块构成。为了使编码层提取的全局特征更具代表性,本文在编码层融入了通道注意力结构。该结构通过全局平均池化和分组卷积得到特征图每个通道的注意力系数,然后将注意力系数和特征图相乘得到注意力感知的特征图,该操作在降低模型复杂度的同时使得提取到的特征更具有区分性和代表性。实验结果表明,本文提出的方法大大减少了网络模型参数量,降低了运算复杂度,并且能够有效识别出人体的关节点。
猜你喜欢
科学技术创新(2021年19期)2021-07-16 10:07:04
沈阳航空航天大学学报(2020年6期)2021-01-27 02:11:30
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
数学物理学报(2019年6期)2020-01-13 06:08:16
数学物理学报(2017年5期)2017-11-23 07:51:31
军营文化天地(2017年6期)2017-06-28 11:30:19
摄影之友(2016年12期)2017-02-27 14:13:20
家庭百事通(2016年10期)2016-10-11 20:13:59
摄影之友(2016年8期)2016-05-14 11:30:04
家庭百事通(2016年3期)2016-03-14 08:07:17
