
中医药院校“互联网+”创新创业项目培育策略分析
2022-04-19 07:44:22蒋旭东杨莉舒启江刘红杏张美娜赵林波
创新创业理论研究与实践 2022年5期
蒋旭东,杨莉,舒启江,刘红杏,张美娜,赵林波
(云南中医药大学信息学院,昆明云南 650500)
随着大数据和人工智能时代的到来[1],“互联网+”大学生创新创业的浪潮已经势不可挡,全面深化高等医学院校创新创业教育改革势在必行[2]。教育部等多个部门联合举办的“互联网+”大学生创新创业大赛能够为高校创新创业教育改革提供新的载体[3]。大赛作品涉及各个行业、各个领域,国家对中医药信息化极其重视,中医药院校便是中医药信息化改革的重要阵地,各高校需要总结大赛经验,有针对性地培养中医药院校学生的“双创”能力,不断明确高校大学生创新创业的发展方向,促使中医药创新创业得以改革和发展。
“互联网+”大学生创新创业大赛自创办以来,全国高校、事业单位、个人都积极报名参加,每年都有越来越多的团队参加比赛,同时针对比赛的相关研究也日益增加,关注度也日益提高。 目前关于国内“互联网+”大学生创新创业大赛的相关研究报告越来越多,研究的问题主要集中在以下几个方面: 一是集中在“互联网+”大学生创新创业大赛的人才培养、教育模式和思路的研究,通过对创新创业大赛的分析总结,对高等医学院校大学生创新创业能力培养进行探究[4];针对四届“互联网+”大学生创新创业大赛参与情况的分析,提出构建高职院校“以赛促教、以赛促学”创新创业教学模式的建议[5]。 二是集中在比赛团队建设方面的研究。 针对大赛中存在的问题,探讨大学生创新创业大赛项目的团队建设[6];从互联网背景、大学生创新创业的优势和存在的问题等方面,对大学生创业团队建设进行简要的分析,为大学生团队创业建设提供思路[7]。 三是集中在比赛的意义和作用的研究,通过对四届创新创业大赛及国内外创新创业教育状况的分析,归纳“互联网+”大学生创新创业大赛在创业实践及创新创业教育实践中的作用,提出“教学—科研—竞赛—创新—就业”的良性循环模式[8]。
在全国大力发展中医药信息化的背景下,针对“互联网+” 创新创业大赛的探讨和研究越来越受到重视,国内外通过针对创新创业大赛的分析来对高等中医药院校的人才培养路径和创新创业教育的研究越来越多,但是这些研究都只是通过研究创新创业大赛的特点和问题,探讨大学生的创新创业教育体系和团队建设存在的不足,并提出相应的解决措施等。几乎还没有人对创新创业大赛作品进行研究而总结其发展方向,中医药方面的更是没有。 本文主要通过对创新创业大赛中中医相关获奖作品进行分析,探讨中医药创新创业大赛的发展方向以及项目团队人数的合理性,并为高等中医药院校大学生“双创”能力的培养提供策略。
1 主要技术介绍
中文分词,一种把文本信息进行切分的基础环节,在文本挖掘中应用非常多,最常用的基于规则分词的方法是最大正向匹配算法,该方法用于词库建立。本文将历届获奖“互联网+”创新创业项目题目作为文本,进行分词,并建立中医项目分词库。
文本挖掘(Text Mining)是抽取有效、新颖、有用、可理解的、散布在大规模文本库中的有价值知识,进而利用这些知识更好地整合信息的过程,往往处理一些非结构化的文本数据,其研究逐步形成数据库、人工智能和数理统计三大领域,应用非常广泛。本文应用文本挖掘技术来分析历届获奖“互联网+”创新创业项目题目的医学、中医项目信息。
Jieba 分词库技术,该库是支持Python 语言的第三方库,支持三种分词模式:精确模式、全模式和搜索引擎模式。
TF-IDF 模型是一个统计方法,用来评估一个词语对一个文件集或一个语料库中的一份文件的重要程度。 TF 指的是某一个给定的词语在该文件中出现的次数,IDF 的主要思想是: 如果包含词条h 的文档越少,也就是文档数p 越小,IDF 越大,则说明词条h 具有很好的类别区分能力。 本文利用该模型进行词语分类和统计。
2 基于文本挖掘构建创新创业项目培育策略统计分析框架
根据文本挖掘等相关理论,要完成中医药院校在校大学生“双创”项目培养策略的分析,必须对大量已收集整理完毕的“双创”项目进行中文分词、词频统计、可视化分析,基本实现框架如图1所示:

图1 文本挖掘框架
2.1 文本分词[9-13]
文本分词主要包括原始数据格式转换、分类、筛选所需内容等活动,利用Jieba 第三方中文分词库及隐马尔科夫链模型[14](HMM)进行中文分词。 核心算法思想描述如下:
BEGIN:
①令j=0,当前指针pi 指向输入字串的初始位置;
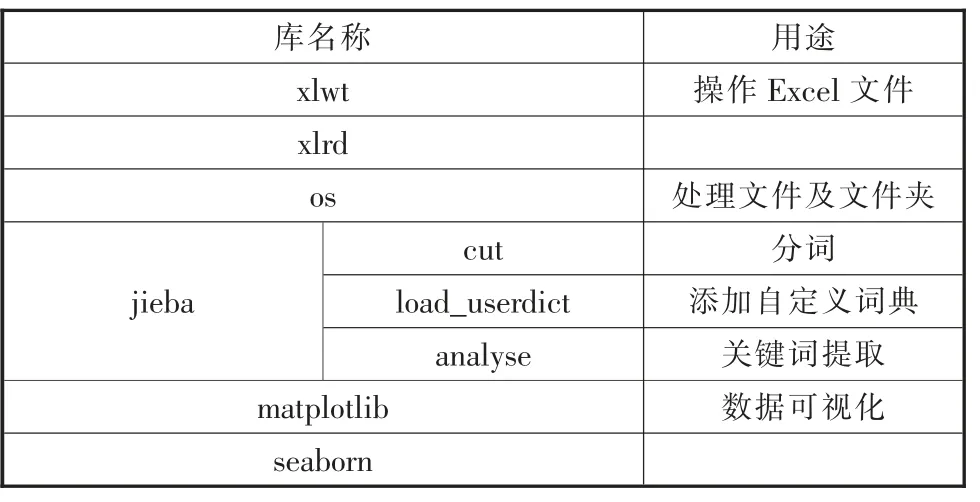
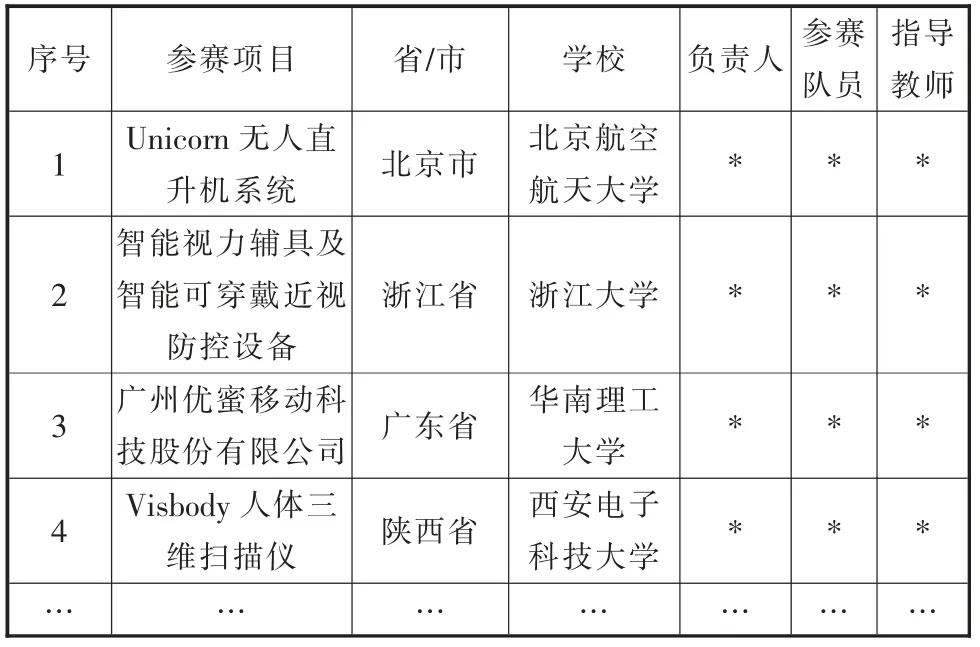
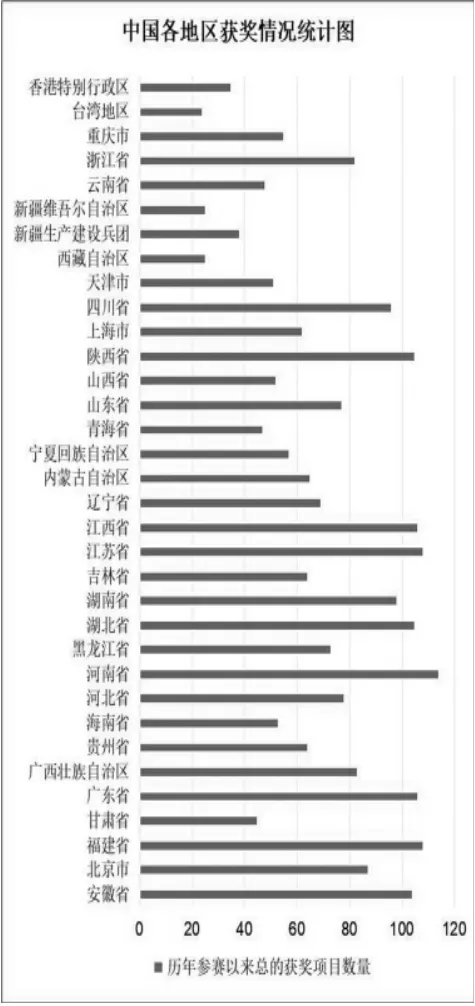
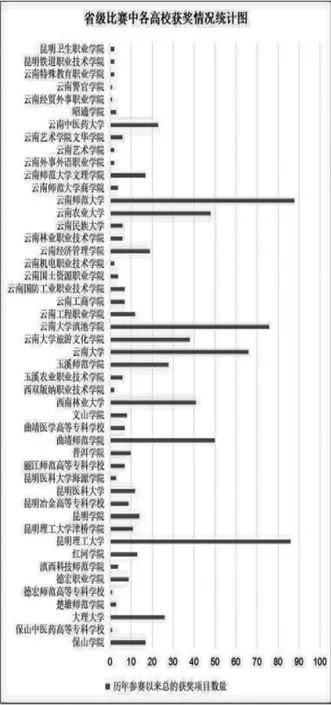
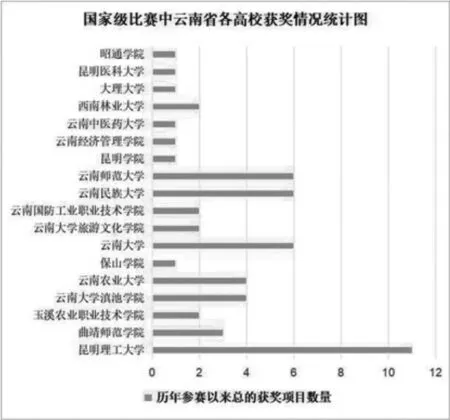
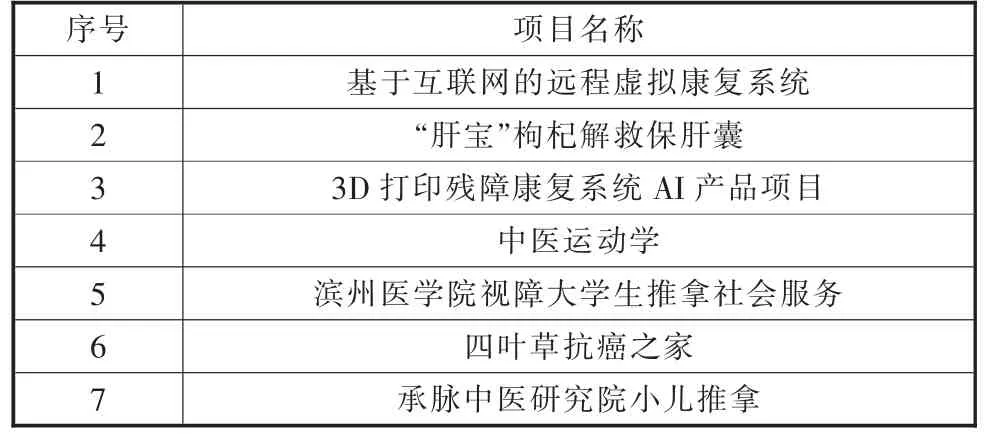
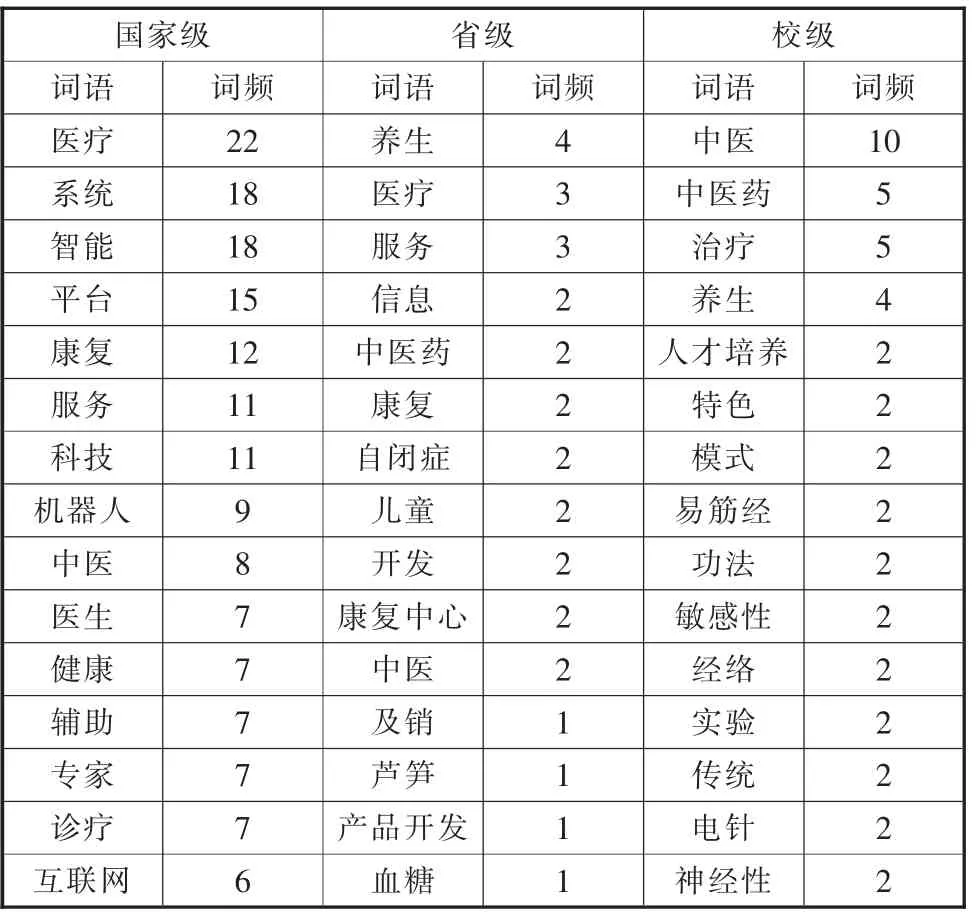
②计算当前指针pi 到字串末端的字数(即未被切分字串的长度)n,如果n=1,转④步,结束算法,否则,令m=w(词典中最长单词的字数),如果n ③从当前pi 起取m 个汉字作为词qi,判断: a.如果qi 确实是词典中的词,则在qi 后添加一个切分标志,转c 步; b.如果qi 不是词典中的词且qi 的长度大于1,将qi从右端去掉一个字,转a 步;否则(qi 的长度等于1),在qi 后添加一个切分标志(单字),执行c 步; c.根据qi 的长度修改指针pi 的位置,如果pi 指向字串末端,转④,否则j=j+1,返回②; ④输出切分结果。 END 通过TF-IDF 算法进行词频统计,实现对文本数据自动化处理[15],主要用到Python 的库,如表1所示。 表1 主要库表 本文主要利用Python 中的数据分析核心库pandas 来进行统计分析,且采用基于WordCloud 库的词云图显示文本热词。 本文所选取的数据是国家级、省级、校级第四届“互联网+”大学生创新创业大赛获奖名单,国家级获奖项目包括国际赛道、“红旅赛道”和主赛道,项目字段有参赛项目名称、所属省/市、学校、项目负责人、参赛人员、指导教师及分类,爬取到的数据部分展示如表2所示。 表2 中国“互联网+”大学生创新创业大赛部分获奖名单 3.2.1 数据预处理步骤 本文的原始数据通过以下几个步骤进行处理,以满足实验所需的数据要求: (1) 部分原始数据是图片格式的,通过手动方式进行数据的录入,将图片类型的数据选取实验所需的具体字段,手动输入到Excel 表格中,输入完成后进行比对,确保实验数据的误差降低到最小且不影响数据分析的效果。 (2) 按分析需求维度整理数据,以便使用。 (3) 统一原始数据中的数据格式,如比赛项目中名字存在英文、繁体、缩写等情况,会影响分词效果,分类有误差,所以必须进行相应处理。将带英文的数据和带繁体字的数据,转换为对应的简体中文,使其原有意思在最大程度上保持原有的真实性,不能转换的数据进行剔除或直接重新分为一类,确保不改变数据本身。 3.2.2 国家、省、校获奖分析 通过对原始数据预处理后的统计分析,形成国家级比赛中各省市获奖分布、 省级比赛中云南省各高校获奖分布、 国家级比赛中云南省各高校获奖分布以及校级比赛中各学院获奖分布情况。 图2 国家级比赛中各省市获奖分布 图3 省级比赛中云南省各高校获奖分布 图4 国家级比赛中云南省各高校获奖分布 图5 校级比赛中各学院获奖分布 从分析结果可以看出:在国家级比赛中,获奖较多的地区分别为河南省、陕西省、江西省等省份,而云南省的参赛项目获奖相对较少;在云南省举办的大赛中,昆明理工大学、云南师范大学获奖项目的数量最多,云南中医药大学的获奖项目处于平均水平; 在国家级比赛中,昆明理工大学是获奖项目最多的; 在校级大赛中,中药学院获奖项目最多,针灸推拿康复学院其次,其他专业的都较少。云南中医药大学在国家级、省级比赛中获奖数目都不多,还需进一步加强对学生“双创”能力、“双创”项目的培育。 分词的准确性依靠的是分词所需要的词库,本文实验利用Python 第三方库Jieba 进行中文分词。 3.3.1 词库建立 为筛选出与医学相关的获奖项目,建立表3所示词库。 表3 词库表 3.3.2 各级比赛中与医学、中医相关项目分析 各级比赛总项目数量以及筛选出的医学相关、中医相关项目数量统计如表4所示。 表4 各级总项目以及医学相关、中医相关项目数量统计表 从表4分析结果可以明显看出: 国家级和省级的获奖项目中医学相关项目较少,中医相关项目占比更小。而校级项目中医学相关项目都是中医相关的,占比也少。依据词库分词大致筛选出医学相关的项目,部分项目如表5所示。 表5 医学相关部分项目 医学中,西医和中医部分内容相互涵盖,自动分类界限较模糊,且筛选出来的中医相关项目占比不大,因此采用人工手动分类出医学项目中中医相关项目的数量,结果如表6所示。 表6 中医相关部分项目 3.3.3 词频分析 对筛选出来的中医相关项目通过Jieba 分词,并进行词频统计,各级词频分析如表7所示。 表7 各级比赛获奖项目中医相关词频分析表 3.3.4 中医相关项目关注点通过词云方式可视化 利用词云,将分析得到的中医相关项目关注点可视化如图6所示。 图6 国家级-省级-校级中医相关项目关注点词云图 3.3.5 获奖项目团队构成分析 通过分析国家级、省级和校级比赛中获奖团队构成,为创新创业项目人员组成提供参考,分析结果如表8所示。 表8 各级比赛获奖项目成员构成分析表 本文通过对国家级、省级、校级历年来“互联网+”大学生创新创业大赛获奖作品进行统计、分析和挖掘,可以看出:目前,“互联网+”创新创业大赛中,医药相关项目主要关注点是中医药、养生、康复、智能、移动等主题。 国家级更多是中药与互联网技术、智能化的融合;而云南省级的关注点主要是中医药,特别是中医养生和康复治疗;中医药院校级的项目都是和中医相关,关注点是中医药学,侧重培养优秀的医学人才。 基于本文的统计、分析和挖掘结果,为中医药院校培育“互联网+”创新创业项目提供以下几点参考: (1) 培养中医药院校学生运用互联网技术、智能技术在中医药领域融合创新的思维、方法和技术。 (2) 优化项目团队配置。 团队成员专业配比要合理,相互弥补知识的短板;团队成员数要合适,根据本文的研究,团队成员数为5 到9 个最为合适。 (3) 跨领域、跨专业、跨学校联合培育项目。 不同领域、专业和学校,更容易结合中医药领域需求寻求到好的解决方案。2.2 词频统计
2.3 可视化分析
3 实证研究
3.1 数据采集
3.2 数据预处理

3.3 分词分析





4 结论与总结
猜你喜欢
现代临床医学(2021年3期)2021-07-16 07:36:44
中国民间疗法(2021年5期)2021-06-09 09:21:42
智富时代(2019年6期)2019-07-24 10:33:16
知识经济·中国直销(2017年7期)2017-07-24 14:12:41
高中生·天天向上(2016年9期)2016-11-22 09:10:34
中国卫生(2016年11期)2016-11-12 13:29:24
英语知识(2016年1期)2016-11-11 07:07:54
电脑迷(2014年14期)2014-04-29 00:44:03
青苹果·教育研究版(2013年2期)2013-04-29 00:44:03
电脑迷(2012年15期)2012-04-29 17:09:47
