
Metric Learning for Semantic⁃Based Clothes Retrieval
2022-04-19 01:13YANGBoGUOCailiLIZheng
ZTE Communications 2022年1期
YANG Bo ,GUO Caili,2 ,LI Zheng
(1.Beijing Laboratory of Advanced Information Networks,Beijing Uni⁃versity of Posts and Telecommunications,Beijing 100876,China;2.Beijing Key Laboratory of Network System Architecture and Conver⁃gence,Beijing University of Posts and Telecommunications,Beijing 100876,China)
Abstract:Existing clothes retrieval methods mostly adopt binary supervision in metric learning.For each iteration,only the clothes belonging to the same instance are positive samples,and all other clothes are“indistinguishable”negative samples,which causes the following problem.The relevance between the query and candidates is only treated as relevant or irrelevant,which makes the model difficult to learn the continu‑ous semantic similarities between clothes.Clothes that do not belong to the same instance are completely considered irrelevant and are uni‑formly pushed away from the query by an equal margin in the embedding space,which is not consistent with the ideal retrieval results.Moti‑vated by this,we propose a novel method called semantic-based clothes retrieval (SCR).In SCR,we measure the semantic similarities be‑tween clothes and design a new adaptive loss based on these similarities.The margin in the proposed adaptive loss can vary with different se‑mantic similarities between the anchor and negative samples.In this way,more coherent embedding space can be learned,where candidates with higher semantic similarities are mapped closer to the query than those with lower ones.We use Recall@K and normalized Discounted Cu‑mulative Gain(nDCG)as evaluation metrics to conduct experiments on the DeepFashion dataset and have achieved better performance.
Keywords:clothes retrieval;metric learning;semantic-based retrieval
1 Introduction
Clothes retrieval,commonly associated with visual search,has received a lot of attention recently,which is also an interesting challenge from both commercial and academic perspectives.The task of clothing re‑trieval is to find the exact or very similar products from the gallery to the given query image.It mainly has two scenarios,namely,in-shop clothes retrieval and consumer-to-shop clothes retrieval.In the former case,query and gallery come from the same domain while it is opposite in the latter case.In consumer-to-shop clothes retrieval,photos in the gallery usually only contain a single product and are taken by profes‑sionals using high-quality equipment.On the contrary,the photos taken by the user are usually of low quality,possibly with cluttered backgrounds and multiple unrelated objects[1].
The above uncertain factors have brought great challenges to consumer-to-shop clothes retrieval.In this complex sce‑nario,only the model which can discover the differences be‑tween clothes from a semantic point of view will not be af‑fected by environmental factors,so as to obtain better retrieval results.However,most of the current clothing retrieval works belong to instance-based retrieval,and they are all based on the following assumptions:Only the clothes belonging to the same instance are considered relevant,while all the other clothes are irrelevant.However,this assumption appears con‑flicted with our common sense.For example,as shown in Fig.1,the semantic similarity between clothes is more than relevant or irrelevant.Instead,it shows a continuous decreasing trend.From a category point of view,when we use a polo shirt as a query,except for the same polo shirt,the other polo shirts should theoretically be the most similar.Ordinary shortsleeved and long-sleeved may follow next,and finally it comes to other different categories such as pants and skirts.How‑ever,under the premise of the above assumption,models are more likely to learn the ranking relationship among clothes,rather than their semantic similarities[2].Moreover,the learned embedding space appears not continuous either,which may lead to worse user experience.
In order to address the above mentioned problems,Refs]2-4] propose several metric learning methods using data with continuous labels,which is called semantic-based re‑trieval.Our work is inspired by and completed based on the research in these fields.In this paper,we propose a new method called Semantic-Based Clothes Retrieval (SCR) to measure the semantic similarity between clothes,and these similarities can guide the learning process of continuous em‑bedding space.In this way,we realize the semantic-based clothes retrieval eventually.

▲Figure 1.Ideal relationship between clothes in different categories
Our contributions can be summarized as follows.
• We expose the problem in the instance-based clothes re‑trieval.The relationship between clothes is simply regarded as relevant or irrelevant,which is not consistent with the actual situation.
•We propose a novel method called SCR to measure the se‑mantic similarity between clothes and design a new adaptive loss based on these similarities.As a result,clothes in a gal‑lery are ranked by their similarity to the query,making mul‑tiple clothes relevant.
• We use Recall@k and normalized discounted cumulative gain (nDCG) as the evaluation metrics and conduct experi‑ments on the DeepFashion dataset,and have achieved better results.
2 Related Work
2.1 Instance-Based Clothes Retrieval
Pioneer works[5-8]in clothing retrieval utilized traditional features like the scale invariant feature transform (SIFT).Later,due to the wide application of deep neural networks,the development of computer vision was greatly promoted.In Refs]9-16],these methods usually extracted both global fea‑tures and local features,combining them for similarity calcula‑tion and matching.Recently,the authors in Ref]17]have pro‑posed a graph reasoning network (GRNet),which first repre‑sented the multi-scale regional similarities and their relation‑ships as a graph and then performed graph convolutional neu‑ral network (CNN) based reasoning over the graph to adap‑tively adjust both the local and global similarities.
All the aforementioned methods focus on the feature extrac‑tion stage of instance-based clothes retrieval.Closest to our work,Ref]1] transferred the leading ReID model called the ReID strong baseline (RST)[18]to fashion retrieval task,signifi‑cantly outperforming previous state-of-the-art results despite a much simpler architecture.In this paper,we use this ReID model as our backbone for subsequent semantic-based clothes retrieval.
2.2 Metric Learning for Instance-Based Clothes Retrieval
Metric learning attempts to map data to an embedding space,where similar data are close together while dissimilar data are far apart[1].In general,metric learning can be achieved by means of embedding and classification losses,and both of them are often utilized at the same time in most re‑trieval methods.Many state-of-the-art methods combine ID and triplet losses to constrain the same featuref.Combining these two losses always makes the model achieve better perfor‑mance[18].
The contrastive loss[19]and the triplet loss[20],as two typical embedding losses,provide the foundation of metric learning.Given an image pair,the contrastive loss minimizes their dis‑tance in the embedding space if their classes are the same,and separates them with a fixed margin away otherwise.The triplet loss takes triplets of anchor,positive,and negative im‑ages,and enforces the distance between the anchor and the positive to be smaller than that between the anchor and the negative image.A wide variety of losses has since been built on these fundamental concepts such as quadruplet loss,n-pair loss,and lifted structured loss.
Although the above mentioned losses substantially improve the quality of the learned embedding space,they are com‑monly based on binary relations between image pairs,thus they are not directly applicable for metric learning in semantic-based retrieval.
2.3 Metric Learning for Semantic-Based Retrieval Using Continuous Labels
There have been several metric learning methods for semantic-based retrieval using data with continuous labels in some research areas such as image caption[21],place recogni‑tion[22]and camera relocalization[23].
Similar to our work,KIM et al.[2]propose a log-ratio loss to learn embedding space in image retrieval.Their work primar‑ily focuses on human poses,in which they use the distance be‑tween joints to rank images.They also explore within-modal image retrieval using word mover’s distance,as a proxy for se‑mantic similarity.For cross-modal retrieval,ZHOU et al.[3]propose to measure the relevance degree among images and sentences and design a ladder loss to learn coherent embed‑ding space.In the ladder loss,these relevance degree values are divided into several levels,but the relevance in each level is still formulated as a binary variable.WRAY et al.[4]propose the task of semantic similarity video retrieval (SVR),which al‑lows multiple captions to be relevant to a video and viceversa,and defines non-binary similarity among items.In addi‑tion,they also propose several proxies to estimate semantic similarities and introduce nDCG as the evaluation metric.
The above methods all implement semantic-based retrieval by metric learning with continuous labels,and the premise is that the dataset provides continuous labels,or the similarity can be measured by well-designed proxies.While,in the field of clothing retrieval,it is difficult to measure the semantic similarities among clothes because of the semantic gap be‑tween visual similarity and semantic similarity.Therefore,semantic-based clothing retrieval has not been realized so far.
3 Semantic-Based Clothes Retrieval
In this section,we propose to move beyond instance-based clothes retrieval towards that uses semantic similarity among clothes.In our proposed SCR,we first measure the semantic similarity for clothes in Section 3.1.And then we modify clas‑sic triplet loss to adaptive loss for clothes retrieval using se‑mantic similarity in Section 3.2.In this way,coherent embed‑ding space can be learned,where candidates with higher se‑mantic similarities are mapped closer to the query than those with lower semantic similarities.
3.1 Semantic Similarity for Clothes
The semantic gap exists between the raw image and the full semantic understanding of the image’s content.In our method,we take full advantage of annotation information in DeepFashion to bridge the gap.
Various tags of clothes are labeled in the DeepFashion data‑set,in addition to categories,bounding boxes,key points,and the attributes of clothes.Taking the consumer-to-shop bench‑mark as an example,each piece of clothing has 303 attribute tags.These attribute tags are attached to 18 categories,includ‑ing clothing length,thickness,material,style and other catego‑ries.According to these attributes,clothing can be described from multiple points of view.Previous works used these attri‑bute annotations as supervision for the multi-label classifica‑tion task,and combined clothing classification and retrieval loss to jointly train a neural network.However,due to the com‑plexity and diversity of attribute tags,the multi-label classifi‑cation task is considered an extraordinary challenge.In order to fully utilize the semantic information hidden in the anno‑tated labels,we do not use attribute labels as the supervision for attribute classification,but directly use them to guide the learning process of the embedding space.
Specifically,given a set of clothes instancesC,we letcibe a clothes instance.We use a 303-dimensional vector of 0 or 1 to represent the attribute vector ofci,denoted bysi.The simi‑larity betweensiand other clothessjcan be measured by the inner product of two vectors,

That is to say,if the corresponding position ofsiandsjis 1,which means two clothes both have a certain attribute,and af‑ter accumulation of all positions,the final value is used to rep‑resent the semantic similarity between them.The inner prod‑uct of the vector and itself is always the largest,which is con‑sistent with“clothing is always the most similar to itself”.Be‑sides,the attribute labels are characterized by fine granularity as well as high accuracy,so they are able to quantitatively measure the semantic similarities between clothes.We use the calculated similarities to guide the follow-up learning process of embedding space as well as evaluate the performance of the retrieval model.
3.2 Adaptive Loss
The classic triplet loss takes a triplet of an anchor,a posi‑tive,and a negative image as input.It is designed to penalize triplets violating the rank constraint.The distance between the anchor and the positive images must be smaller than that be‑tween the anchor and the negative images in the embedding space.The loss is formulated as:
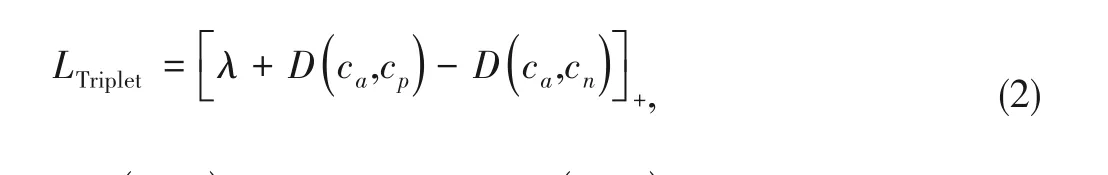
where(ca,cp)is the positive pair,(ca,cn)is the negative pair for a query,D(·)means the squared Euclidean distance of the em‑bedding vector,λis a fixed margin,and[·]+denotes the hinge function.Note that the embedding vectors should be L2 nor‑malized since their magnitudes tend to diverge and the margin becomes trivial without such a normalization.For the RST model used in clothes retrieval[1],the mining strategy selects the most difficult positive and negative samples,that is the far‑thest positive sample and the closest negative sample in em‑bedding space.
The triplet loss tends to treat the relevance between query and candidates in a bipolar way:for a queryca,only the ex‑actly same clothescpare regarded as relevant,and other clothescnare all regarded as irrelevant.Therefore,onlycpis pulled closed toca,while others are pushed away by a fixed margin equally.However,as mentioned in Section 1,the se‑mantic similarity between samples should not be a binary variable.
In ideal embedding space,the difference in distance be‑tween positive/negative samples and anchor should be propor‑tional to the difference in semantic similarities between them.In other words,a negative pair with lower semantic similarity should be pulled farther apart.Therefore,it is beneficial to in‑troduce the semantic similarities to determine how far nega‑tive samples will be pushed away.We design a novel adaptive loss for clothes retrieval based on a classic triplet loss as fol‑lows:
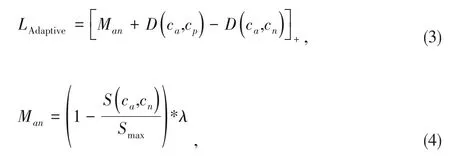
whereSmaxis a normalization factor to guarantee that the maximum value of semantic similarity is 1.1 minus the nor‑malized value,as the coefficient ofλ,can allow those nega‑tive samples that are very similar to the anchor to be pushed away by a small margin.On the contrary,those negative samples that are not similar to the anchor will be pushed away by a large margin.
In the proposed adaptive loss,the margin between the an‑chor and the corresponding negative sample is no longer a fixed value,but a dynamic distance varying with semantic similarity computed in Eq.(1).In this way,a model is trained under metric learning beyond binary supervision and a coher‑ent embedding space is learned as a result.
4 Experiments
4.1 Dataset and Experiment Settings
We evaluate our loss on the consumer-to-shop clothes re‑trieval benchmark of DeepFashion[11].This benchmark aims at matching consumer-taken photos with their shop counterparts.It contains 33 881 clothing items,239 557 consumer/shop clothes images,195 540 cross-domain pairs,and each image is annotated by the bounding box,clothing type and source type.In our experiments,we use 96 708 images for testing and the remaining for training.
In this section,we select the RST model[1]that has obtained the best performance in clothes retrieval as the backbone net‑work for the following experiments.Our loss function consists of two parts,which are obtained by adding the classification loss and the ranking loss (adaptive loss).We keep the identity loss in the original RST model and use it as the classification loss.As for the adaptive loss,we first select the closest nega‑tive sample to the anchor and the farthest positive sample in a batch,and then use the dynamic margin calculated by the se‑mantic similarity between the negative sample and anchor to replace the fixedλin the triplet.The adaptive loss we pro‑posed can be used as an improved version of triplet loss in any backbone.In this paper,RST with the original classic triplet loss is considered as a comparison method.
Except for the loss function,several variants of the RST model were proposed in Ref]1],and we select one with ResNet50-IBN-A backbone,320×320 input image size,and no re-ranking setting as our baseline.We follow the warmup learning rate strategy proposed in the original RST model[18].Models are trained using Adam for 120 epochs,with a batch size of 64.Hyper-parameters are set asλ=0.3,andϵ=0.1.
For instance-based retrieval,we use the Recall@K (R@K)as the evaluation metric for the task.R@K indicates the per‑centage of queries for which the model returns the correct item in its topKresults.
For semantic-based retrieval,we use nDCG[24]as evaluation metrics.The nDCG has been used previously for information retrieval[25].It requires similarity scores among all items in the test set.We calculate discounted cumulative gain (DCG) for a queryqiand the set of itemsZ,ranked according to their dis‑tance fromqiin the learned embedding space:
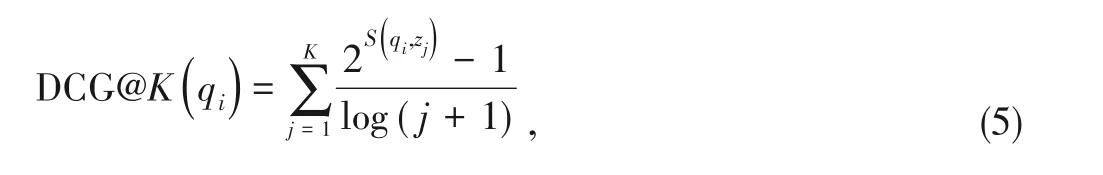
whereKis the length of the list returned by the retrieval sys‑tem.Note that this equation would give the same value when items of the same similaritySSare retrieved in any order.It also captures different levels of semantic similarity.The nDCG can then be calculated by normalizing the DCG score so that it lies in the range[0,1]:
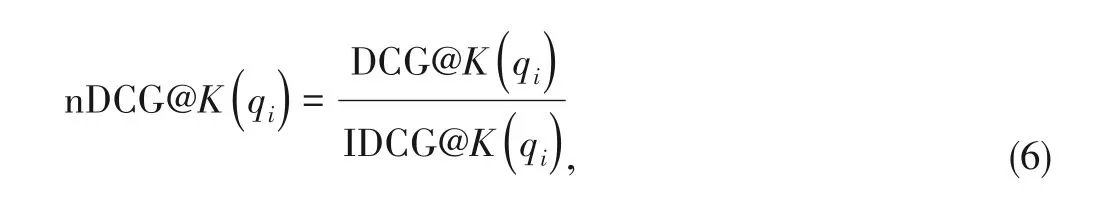
where IDCG@K(qi)is calculated fromDCGandZordered by relevance to the queryqi.
4.2 Analysis of Semantic Similarity
In this paper,we follow the method introduced in Section 3.1 to obtain the inner product of two attribute vectors as the semantic similarity among clothes.After statistics,the mini‑mum value of similarity is 0 and the maximum is 42,as shown in Fig.2,where the blue curve represents the frequency distri‑bution of different semantic similarity values and the sum of these values is 1;The orange line shows the cumulative fre‑quency distribution of less than or equal to the current value.In this range,the greater the similarity,the lower the fre‑quency of occurrence.Among them,the proportion of similar‑ity of 0 or 1 is 54%,and the proportion of similarity of less than or equal to 8 is as high as 99%.In other words,the simi‑larity among most clothes is generally very low,and the simi‑larity of only a few clothes can be close to or equal to their own similarity.Our goal is to use these high similarity samples to learn their common features from a semantic point of view,so as to optimize the learning quality of the embedding space.
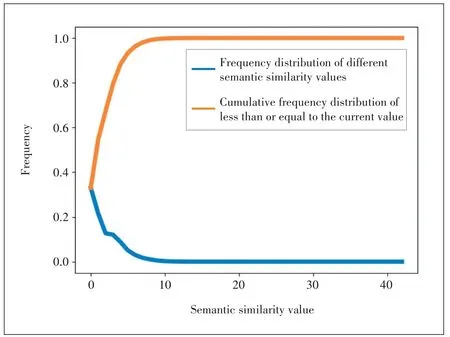
▲Figure 2.Frequency statistical graph of semantic similarity
Fig.3 shows the normalized semantic similarities calcu‑lated by the inner product of the 303-dimensional attribute vectors.Note that similarities here are normalized bySapin‑stead ofSmaxfor better understanding.If clothes possess all the attribute tags of anchor,their semantic similarity with anchor will come to 1.While,in the training process,we use the se‑mantic similarity normalized bySmaxto determine the distance that negative samples are pushed away from the query,that is,the lower the semantic similarity,the farther will be pushed away from the query.

▲Figure 3.Normalized semantic similarity visualization
4.3 Comparison with State-of-the-Art Methods
Table 1 compares the proposed SCR with state-of-the-art methods,including FashionNet[11],Visual Attention Model(VAM) and its variants (VAM+ImgDrop,VAM+Product,and VAM+Nonshared)[26],DREML[27],KPM[28]and GRNet[17].The proposed SCR obtains competitive results.Specifically,it ob‑tains an accuracy of 29.2,51.0 and 61.4 and outperforms the existing methods at R@1.
4.4 Comparison with Triplet Loss and Quadruplet Loss
Since the adaptive loss we proposed is an improved version of the triplet loss,in order to verify whether the proposed adap‑tive loss is effective,we compare it with the triplet loss in both instance-based and semantic-based retrieval.Moreover,a comparison with quadruplet loss is also revealed below.
1)Instance-based retrieval results
As shown in Table 2,the adaptive loss has a significant im‑provement compared with a triplet loss function.This means that the information provided by the calculated semantic simi‑larity can improve the quality of the learned embedding space and performance better in the retrieval process.However,Re‑call@konly cares about the appearance of the firstkresults,and does not care about their sorting positions,so the measure‑ment results for our optimization based on semantic similarity are limited.
2)Semantic-based retrieval results
Table 3 summarizes the results evaluated by nDCG.The proposed loss function has an obvious improvement.In terms of nDCG@5,nDCG@10,and nDCG@50,the adaptive loss separately increases by 4.3%,7.6%,6.7%,compared with the classical triplet loss.Since the nDCG metric can simultane‑ously consider the relevance de‑gree and ranking position,it re‑flects semantic-based retrieval results more accurately.
Fig.4 shows the qualitative comparison between the triplet loss and adaptive loss on the consumer-to-shop benchmark using RST.For each retrieval,given an image query,we show the top-5 retrieved products.The correct retrieval items for each query are outlined in green boxes.Compared with the triplet loss,the correct query re‑sult ranks higher.Moreover,the search results based on the adaptive loss possess higher semantic similarity with the query.For example,in the first query results based on the adaptive loss,although the first two candidates are not consid‑ered ground truth,they are indeed indistinguishable from the query,which also proves that it is not in line with the actual retrieval requirements to only consider ground truth to be rel‑evant.
In addition,even if it is an incorrect query result,it will besemantically closer to the query.For example,in the third query result,when using a shirt with a distinctive pattern as a query,the network trained by the triplet loss pays too much at‑tention to the local similarity because four of the top five search results are pants with similar patterns.From the per‑spective of the clothing category,the search results are com‑pletely contrary to the user’s intention.The network trained by the adaptive loss focuses on the overall semantic similarity so the searching scope tends to be restricted to the same cat‑egory,which is crucial to the user experience.This benefits from the fact that the margin we use in the adaptive loss can adjust dynamically according to different samples.In this way,the model is easier to explore the semantic relationship among samples and finally a more semantic coherent embedding space is learned.
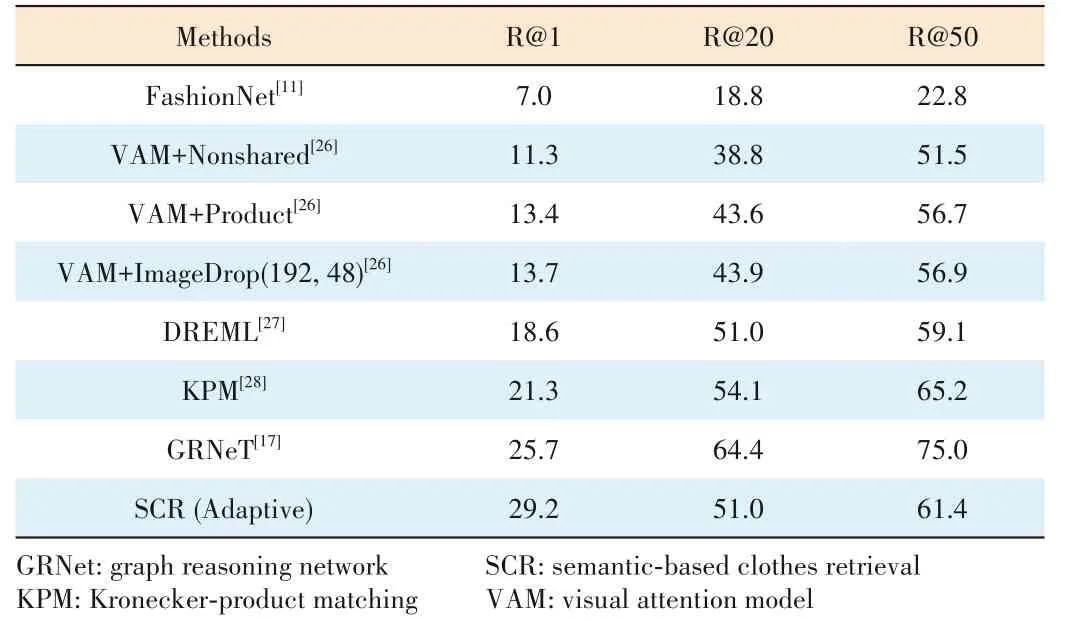
▼Table 1.Comparison with state-of-the-art methods on DeepFashion consumer-to-shop benchmark
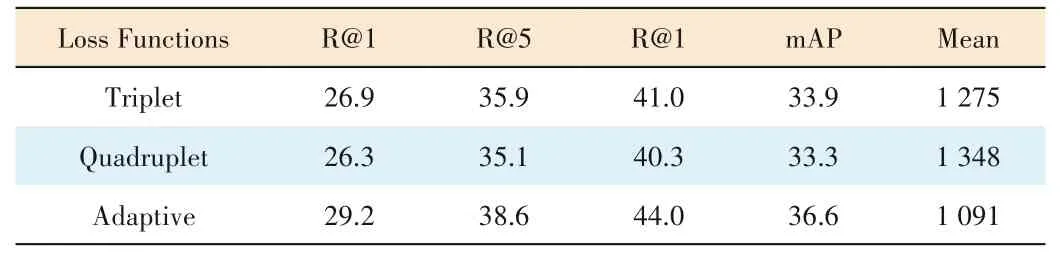
▼Table 2.Instance-based retrieval results on DeepFashion
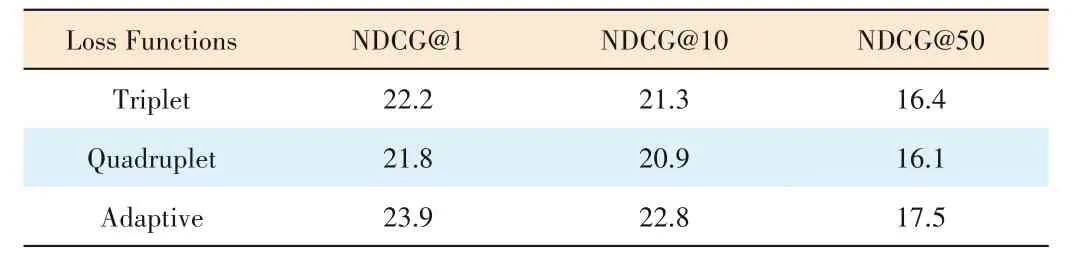
▼Table 3.Semantic-based retrieval results on DeepFashion
5 Conclusions
This paper focuses on semantic-based clothes retrieval and proposes a novel method called SCR to measure the semantic similarity between clothes.Motivated by metric learning with continuous labels in other research areas,we modify the clas‑sic triplet loss using semantic similarity and design an adap‑tive loss for clothes retrieval.As a result,more reasonable em‑bedding space is learned,where candidates with higher se‑mantic similarities are mapped closer to the query than those with lower similarities,which is more in line with the actual user experience of the retrieval system.Our method outper‑forms the baseline and obtains competitive semantic-based re‑trieval results on consumer-to-shop retrieval benchmarks of DeepFashion.
Acknowledgment
We would like to acknowledge LIU Xuean,HE Baolin,ZHANG Yuanjian from ZTE Corporation for their contribution to this paper.

▲Figure 4.Qualitative retrieval comparison between triplet loss and our adaptive loss on consumer-to-shop benchmark

- ZTE Communications的其它文章
- Editorial:Special Topic on Reconfigurable Intelligent Surface (RIS)
- Recent Progress in Research and Development of Reconfigurable Intelligent Surface
- Some Observations and Thoughts about Reconfigurable Intelligent Surface Application for 5G Evolution and 6G
- New Member of ZTE Communications Editorial Board
- Recent Developments of Transmissive Reconfigurable Intelligent Surfaces:A Review
- IRS⁃Enabled Spectrum Sharing:Interference Modeling,Channel Estimation and Robust Passive Beamforming