
基于深度学习的牙齿嵌塞自动判别方法
2022-04-18 10:57:06王志江秦品乐程一彤
计算机工程 2022年4期
王志江,秦品乐,柴 锐,武 峰,程一彤,史 玥
(1.中北大学大数据学院 山西省生物医学成像与影像大数据重点实验室,太原 030051;2.山西医科大学口腔医院 修复科,太原 030012)
0 概述
食物嵌塞是影响人类口腔健康的常见因素,容易引发局部牙龈红肿,溢脓、龋齿、异味等口腔问题,进一步发展还可能会引起牙齿的松动和脱落[1],给患者的日常生活带来极大的痛苦和不便。
医学上常用锥形束CT(Cone Beam Computed Tomography,CBCT)对牙齿扫描进行重建,并测量牙齿的相关参数以判断是否塞牙。但锥形束CT 精确度有限,且牙齿形态不规则,难以准确测量牙齿嵌塞的相关参数及在临床实现精确判断。随着3D 扫描技术的发展,先进的口腔内扫描术能够直接重建牙列的数字表面模型,由于其效率和安全性高而得到广泛的应用,但该技术仍然需要借助三维测量软件且需耗费大量时间。因此,一种可以自动测量相关参数并判断牙齿是否嵌塞的方法对临床上治疗食物嵌塞有重要意义。
医学上的大量实验表明,邻接线长度、邻接面面积、舌外展隙角度、颊外展隙角度及牙合外展隙角度对食物嵌塞情况的判断具有统计学意义,且塞牙常发生于第1 磨牙和第2 磨牙之间[2]。目前临床上并没有可以根据牙齿三维模型直接测量出相关嵌塞特征的方法。
为准确得出牙齿是否嵌塞的结论,本文基于U-Net提出一种点云分割网络,通过增加输入采样点特征维度,增强模型对细粒度语义特征的检测,提高模型的分割准确率。在此基础上,使用图割法对分割好的点云模型进行处理,优化分割结果,以便于下一步对牙齿嵌塞特征的求解。同时,设计一种在牙齿三维点云上求相关嵌塞特征的方法,并对牙齿是否嵌塞做出判断。
1 相关工作
三维牙齿模型的分割一直是研究的热点,传统的牙齿分割算法是基于计算机图形或视觉的算法,主要分为二维投影和曲率分析2 种方法。二维投影法是将三维网格投影到一个或多个二维平面上,应用传统的计算机视觉算法对平面进行分割,并将处理后的数据投影回三维空间。例如,KONDO 等[3]提出梯度方向分析,GRZEGORZEK 等[4]利用多层深度图像进行分割,WONGWAEN 等[5]在二维投影全景深度图上利用边界分析来寻找牙齿边界,但是二维图像的分割无法准确表达牙齿的真实形态。曲率分析是指对三维牙齿模型进行区域分析,并根据曲面的最小曲率对区域进行分类的方法。例如KUMAR 等[6]首先利用曲率分析和漫水填充算法探测牙齿和牙龈的分割边界,然后探测此边界上的角点以获取牙缝分割边界。但是使用曲率分析需要用户设置合适的曲率阈值,且分割速度较慢。
利用深度学习对三维牙齿模型进行分割是一个新的热点,自从PointNet[7]模型在三维点云处理方面提供了更高效更灵活的方式,一大批使用深度学习对牙齿点云进行分割的方法也随之出现。XU 等[8]在每个牙齿模型的网格面上提取多维特征,直接通过三维卷积对提出的特征进行分类,TIAN 等[9]使用三维卷积和稀疏体素八叉树对牙齿进行分割,LIAN等[10-11]使用一系列图约束学习模块分层抽取多尺度上下文特征,并进行牙齿模型的自动分割。CHEN等[12]使用两阶段模型,通过牙齿质心预测和质心距离投票方法对牙齿进行分割。然而,上述方法大部分在分割前有复杂的预处理步骤,分割网络并没有使用点云分割中最新的研究成果。
基于深度学习对点云分割的方法主要分为两类:基于体素的方法和基于点的方法。基于体素的方法[13-14]在多个3D 模型数据集上可获得最佳性能,但需要大量的内存资源。基于点的方法减少了信息损失,从而以较少的计算复杂度实现了较高的精度。该类方法通常可以分为4 类:相邻特征池[15]、图构造[16]、基于注意力的聚合[17]和基于核的卷积[18]。在所有的基于点的方法中,KPConv[19]得到了三维物体分割的较好性能。因此,本文采用KPConv 来构建本文的牙齿分割网络。
2 本文方法
本文提出一种能够自动求解牙齿嵌塞特征并根据相关特征判断是否塞牙的方法,具体流程如图1所示。
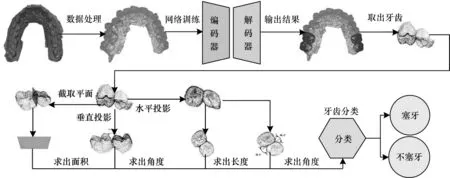
图1 牙齿嵌塞特征求解流程Fig.1 Solution process of tooth impaction features
如图1 所示,牙齿嵌塞特征求解的流程主要分为3 个阶段:
1)牙齿分割阶段。输入三维牙齿stl 模型,以提取三维牙齿点云。使用本文设计的牙齿分割网络,对三维牙齿点云进行分割,并对分割结果使用图割算法进一步优化,得到最终分割好的牙齿三维点云。
2)嵌塞特征计算阶段。从分割好的牙齿结果点云中取出左侧或右侧第1、2 颗磨牙点云,对取出的牙齿点云进行嵌塞特征计算。首先在水平方向上使用平面拟合的方法将牙齿投影到平面上,求出邻接线长度、舌外展隙角度和颊外展隙角度,然后在垂直方向上将牙齿投影到平面上,求出牙合外展隙角度,最后在垂直平面上将第6、7 颗磨牙进行分割,求出邻接面面面积。
3)嵌塞牙齿判断阶段,使用求出的5 种嵌塞牙齿特征,并通过训练好的SVM 模型得出牙齿是否塞牙的结论。
3 牙齿分割
3.1 点云采样
本文首先将牙齿stl 模型直接转化为点云模型,转化后的牙齿点云点数过多,每个牙齿表面大约包含140 000 个点。受到硬件条件的限制,当数据量过大时,点云直接输入网络会导致内存溢出,且计算量太大会减慢训练速度,所以在训练网络时首先要对点云进行采样,这与常用的点云采样方法、随机采样方法和均匀采样方法均不同。为了能更加准确地得到牙齿的嵌塞特征,同时考虑到牙齿嵌塞特征与牙齿表面曲率的关系,以及牙齿表面曲率较大的位置包含牙齿嵌塞特征的概率也越大,本文采用几何采样对牙齿表面的点进行采样。
几何采样在点云曲率越大的地方,采样点个数越多,具体方法定义如下:输入牙齿点云,将目标采样数定义为S,曲率采样比例定义为U,采样结果定义为G。首先对点云进行曲率计算,在每个点的k邻域上求法线,然后计算每个点到邻域上的法线的夹角值。曲率越大,则夹角值越大。
设置一个角度阈值,将数据分为大于角度阈值和小于角度阈值2 部分,在这2 部分中分别采样,采样数分别为S×(1-U)和S×U。最终的采样结果G为:

3.2 分割网络结构
本文基于KPConv 卷积核来构建分割网络模型,网络模型类似于U-Net[20]模型,由编码器和解码器2 个部分组成,是一种对称的语义分割模型。网络从最深层特征经过5 次上采样得到最终的分割结果。由于只采用深层特征上采样得到分割标签会丢失浅层特征信息,而浅层特征包含的是空间位置信息,因此通过学习这些浅层特征有助于在分割时更精准地进行定位。在编码器路径上生成的每一组特征映射均被连接到解码器路径上的对应特征映射,多层次特征融合能够关注到点云局部的细节信息,具有更强的语义信息,能够更加精确地进行分类。
网络结构如图2 所示,网络输入的大小为N×6,其中N为采样后点云的10 240 个点,6 维向量由点云的空间坐标及法线信息2 个方面组成。网络输出为N×n的向量。
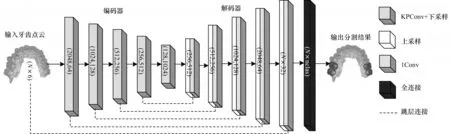
图2 牙齿分割网络结构Fig.2 Dental segmentation network structure
下面介绍每层的具体实现:
1)编码器。编码器共有5 层,每层之间通过下采样减少点数,使用KPConv 卷积提取点集信息,为增大特征维度,KPConv 卷积核大小设置为13。为了防止过拟合和加快收敛速度,每层卷积之间均有批归一化(Batch Normalization,BN)和Leaky ReLu 激活函数。
2)解码器。解码器也是5 层结构,但是与编码器不同的是,解码器每一层均采用最邻近插值法的上采样来增加点数,并采用一元卷积来减少特征维度。跳层链接通过连接编码器和解码器来传递网络的浅层特征,每层网络之间也有批归一化(BN)和Leaky ReLu 激活函数。
3)输出。全连接层的输出通过softmax 分类函数对每个点的语义进行预测。网络输出的结果点数为10 240,与输入相同。
3.3 图割法后处理
本文网络分割后的结果可能会产生孤立的错误预测或非光滑的边界,但基于图的后处理可以对结果进行有效细化[21],例如LIAN 等[22]将图割方法应用到牙齿分割后处理中,获得了较好的效果。图割方法是一种可以用于n维图像数据的边界优化和区域分割的分割技术,本文在后处理中使用图割,并加入包围盒和边缘曲率2 个先验特征对分割结果进行优化。包围盒的大小对于每个牙齿来说相对固定,但分割边缘的曲率大小在每个牙齿边缘和牙齿表面有很大不同,因此加入2 个先验条件对分割结果进行优化很有必要。
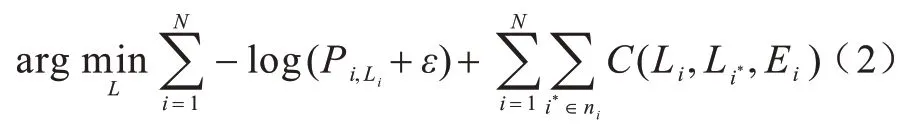
其中:第1 项是数据拟合项,目的是得到最大分割能量;第2 项定义牙齿点云边缘和标签空间的局部平滑性,ε是一个小标量(1×10-4),以确保数值稳定性;考虑到牙齿表面上和牙龈之间的边界通常是凹的,本文采用C(Li,Li*,Ei)定义局部标签一致性,表达式如式(3)所示:
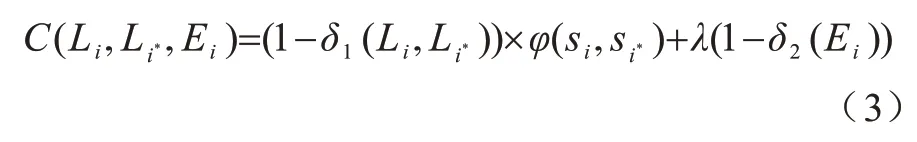
其中:δ1函数是一个狄拉克函数,且当时值为1。等式右边第2 项表示包围框大小的约束,这一项是对网络预测出包围框大小结果的修正。参数λ平衡2 项的贡献,在本文实验中,将λ值设置为20。约束函数的表达式如式(4)所示:

4 嵌塞特征求解
4.1 平面拟合
分割牙齿模型后提取出第6、第7 颗牙齿,可以得到三维空间中的2 颗牙齿。针对在三维空间中直接求解嵌塞特征、长度、角度等信息时会受到遮挡,以及寻找线段端点困难等问题,本文将三维空间中的2 颗牙齿投影到二维平面上进行求解,投影时采用平面拟合来确定投影面。
本文中平面拟合的方法定义:使用法向量n=[a,b,c]T和距离d来描述一个平面,这样对于点p=[x,y,z]T在平面n×p+d=0 可以写为:

其中:a、b、c分别为平面方程系数;d为常数项;x、y、z表示点的坐标。
假设c=1,求解a、b、d,矩阵形式如式(6)所示:

根据克莱默法则可以求得:
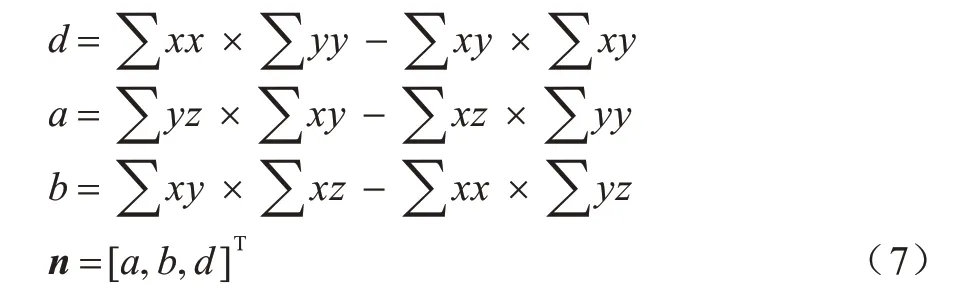
最终可以求出牙齿点云投影到一个平面上的平面方程。
4.2 嵌塞特征求解
本文采用SVM[23]求解牙齿邻接线长度,并且采用SVM 对求出的特征进行分类,SVM 是一种按监督学习方式对数据进行二元分类的广义线性分类器,可以使用超平面将小数据量的两类数据分割开。
将牙齿在水平方向投影,并将牙齿压缩到二维上,以便求解邻接线长度。求解步骤是首先求出可以分割2 个牙齿的最佳分界线,在分界线上找到最远的2 个点作为牙齿邻接线的2 个端点。在分类上采用SVM 对两类牙齿进行分类,SVM 对噪声不敏感,并且泛化能力强,可以找到一个超平面,使其能正确地将2 个样本进行分类。
对分割后取出牙齿中点的定义为:(X1,y1),(X2,y2),…,(Xn,yn),其中:Xi是含有d个元素的列向量,即Xi∈Rd;yi是标量,当yi=+1 时表示正类别,当yi=-1 时表示负类别,为了找到一个超平面,可以使2 个牙齿分割开。对超平面的定义如式(8)所示:

其中:W和b分别代表超平面的法向量和截距。
求出分界线后,以分界线的2 个端点向外延长一固定长度,在延长线上向牙齿两侧做垂线得到2 个距离延长线最近的2 个点,3 个点组成的角度就是本文提到的舌外展隙角度和颊外展隙角度。将取出的2 个牙齿在垂直方向投影,可以得到牙齿垂直方向上的二维点云,同上述求舌外展隙角度的方法一样,可以求出牙合外展隙角度。同时,在将垂直方向上的牙齿分割平面取出,得到邻接面面积。
5 实验结果和分析
5.1 数据和预处理
本文采用由山西省医科大学口腔医院提供的通过3Shape 扫描仪获取的120 例患者数据,剔除掉显示不清晰及形态损伤较大的牙齿数据,对所有牙齿进行标注,令0~4 依次为牙龈和4 颗磨牙。
将样本集随机划分为训练集和测试集。由于上牙和下牙在形态上有一定区别,本文将上下牙分开来训练。
为了增加数据及提高泛化能力,本文采用3 种方式对牙齿数据进行增广:
1)随机旋转。令模型绕x轴、y轴、z轴随机旋转。
2)随机平移。令模型随机进行上下左右的小范围平移。
3)对数据集添加人工噪声以及从数据中随机删除少量点。最终,得到3 600 例牙齿数据。
5.2 网络学习结果
5.2.1 评价指标
为评估本文实验的有效性,采用均交并比(Mean Intersection over Union,MIoU)的评估方式验证牙齿分割结果的准确性,MIoU 是计算预测值和标注数据(Ground Truth,GT)间的交集和并集之比。MIoU 的表达式如式(9)所示:
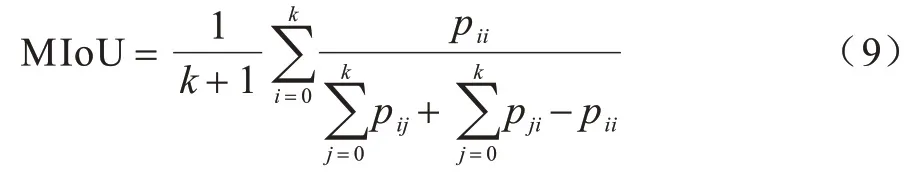
其中:K代表分类个数;pij表示某个点分类属于j类的概率;pii表示正确样本的数量;pji表示错误样本的数量。
5.2.2 对比实验
本文将分割好的点云结果映射到stl模型上并进行可视化,用不同的颜色对牙齿进行标注。由图3 可知,仅仅使用深度学习方法对牙齿整体进行分割的结果较好,但是在一些复杂的牙齿表面上,由于牙齿表面曲率变化较大,可能会出现错误的分割。为了提高分割结果的准确率以及后续求嵌塞特征的准确率,本文采用图割法及最小化图割能量函数来优化分割结果。由图3(b)可知,经过图割法处理后,齿间接触区的边缘更加光滑,且错误的分割结果也被改正,这有助于提高本文后期对牙齿嵌塞特征的求解精度。
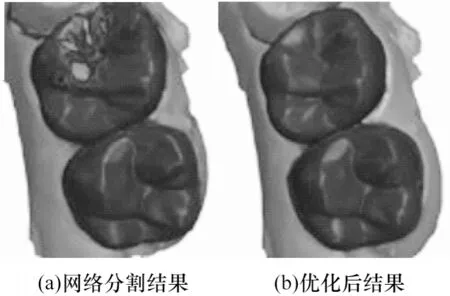
图3 图割法优化结果Fig.3 Graph cutting optimization results
本文在测试集中随机选择了3 个牙齿进行可视化对比,实验结果如图4 所示。将本文模型与2 个具有代表性的点云语义分割深度学习模型PointNet 和KPConv 进行对比,经图割法优化后,从可视化结果可知,PointNet 模型在2 个磨牙的相邻处出现过分割现象,无法将2 颗牙完美地分割出来,并且出现了错误分割牙齿的情况。而KPConv 模型没有出现错误分割牙齿的情况,但每颗牙齿与相邻牙齿间的分割并不光滑,也会出现过分割现象。总体来说,本文网络在分割上表现良好,没有出现错分和边缘模糊,与真实结果很接近,而PointNet 模型和KPConv 模型均出现了不同程度上的牙齿错分和边缘模糊现象。使用本文模型生成的结果在可视化表现上可以满足后续对牙齿嵌塞特征求解的需要。
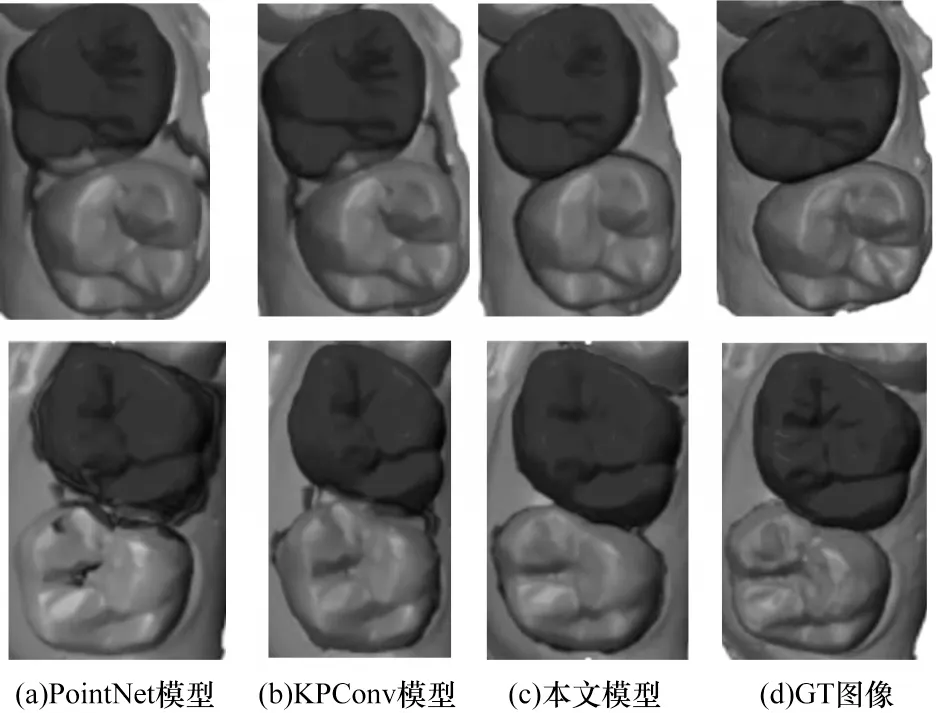
图4 不同模型的可视化对比Fig.4 Visual comparison of different models
为进一步验证本文所提分割模型的有效性,与上文提到的三维分割模型分割结果准确率进行对比。实验结果表1 所示,表中加粗数字表示该组数据的最大值。从表1 可知,本文模型对所有磨牙的分割效果提高较为明显,与PointNet 模型、KPConv模型相比,本文模型的分割准确率分别提高了约13和6 个百分点。

表1 不同模型的分割准确率对比Table 1 Accuracy of network segmentation
5.2.3 关键参数选取
本文共使用了2 个核心超参数,分别是KPConv卷积核数量及图割方法的λ值。为分析这些超参数对本文模型分割结果的影响,本文在不同的参数设置下进行了2 次实验。
为了选择合适的KPConv卷积核数量,本文探究了卷积核数量与分割准确率之间的关系,结果如图5(a)所示。可以发现,随着卷积核数量的不断增长,网络分割准确率也在不断提升。但在卷积核数量达到13 之后,准确率增长的速度明显下降,这是因为过大的卷积核会造成参数量的增加,使得训练难度加大,因此本文选用13 作为本文模型中卷积核的大小。图割方法使用λ值来平衡分割2 项能量函数,图5(b)为不同的λ值对应的模型分割准确率,可以发现当λ值为20 时,本文模型达到最佳分割准确率。
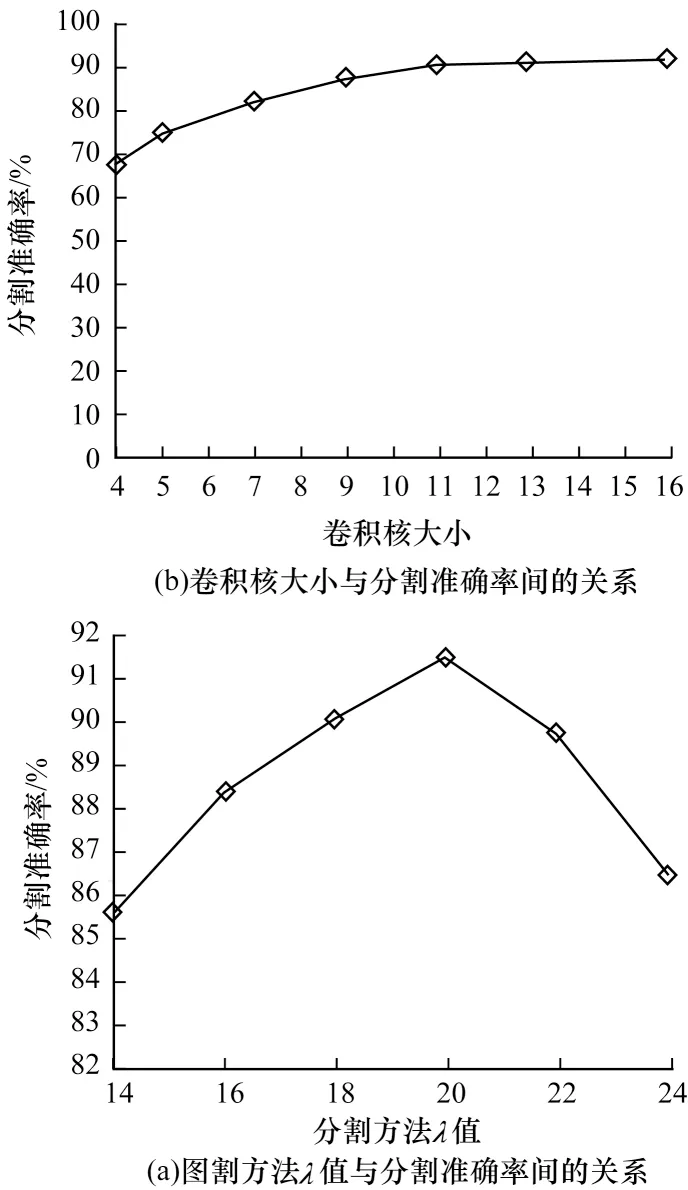
图5 关键参数对本文模型分割准确率的影响Fig.5 Influence of key parameters on the segmentation accuracy of model in this paper
5.2.4 消融实验
为验证本文模型的有效性,通过对网络输入不同的点云维度和选取不同的采样方法来进行消融实验,以观察维度和采样方法对网络模型的影响。其中N×3 代表网络输入维度为3,输入为点云的3 维坐标,N×6 代表网络输入的维度为6,输入为点云的3 维坐标和点云的法向量。实验结果如表2 所示。

表2 消融实验Table 2 Ablation study
由表2 可知,与基础网络相比,加入几何采样和法向量信息后,网络分割准确率分别提升了2 和7 个百分点。可以看出,法向量信息对分割结果的影响较大。原因可能是法向量可以反映某个点的领域点集的几何结构,对于三维牙齿模型分割起到了很大的作用。本文通过将几何采样和点云法向量信息进行叠加达到了最佳分割效果。
5.3 嵌塞牙齿判断
在本文模型分割好第1 磨牙和第2 磨牙后,使用本文所提分割网络对120 个牙齿进行分割,并取出分割好的第6、第7 磨牙。通过手工方法筛选出分割情况良好的牙齿数据,并得到383 组牙齿例子,包括213 个食物嵌塞和170 个非食物嵌塞。接着计算出邻接线长度、邻接面面积、舌外展隙角度、颊外展隙角度和牙合外展隙角度这5 个特征,并将数据分为70%的训练集和30%的测试集,使用SVM 对牙齿嵌塞情况进行训练。为提高结果准确率以及避免过拟合,本文在SVM 训练时采用非线性核函数,最终在测试集上的准确率可达81%。最终测试集分类结果如图6 所示,其中:当y=1 时,代表食物嵌塞;当y=0 时代表非食物嵌塞。由图6 可知,本文采用5 个特征进行嵌塞牙齿的分类,分割线能够将大多数嵌塞牙齿分类正确,为医生辅助诊断提供有效帮助,具有一定的应用价值。
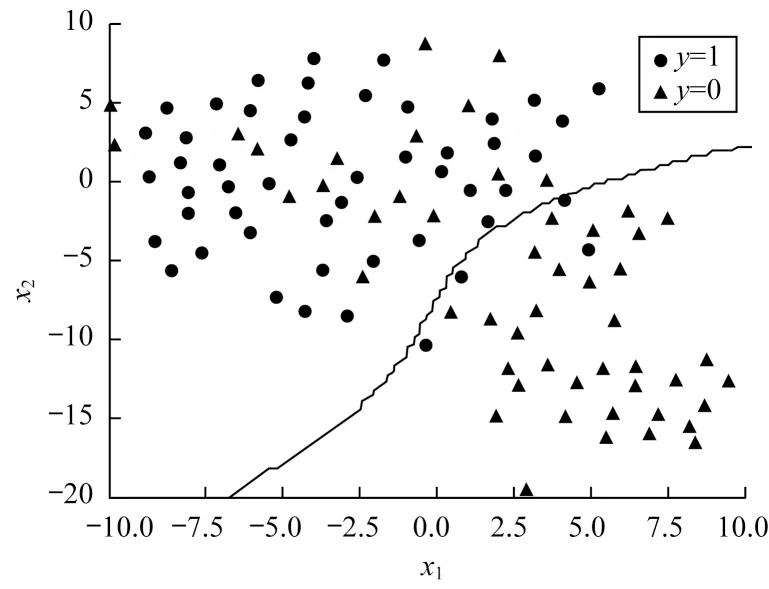
图6 牙齿嵌塞分类结果Fig.6 Results of tooth impaction classification
为验证图割优化处理对本文牙齿分类准确率的影响,分别使用本文模型与点云语义分割深度学习模型PointNet、KPConv 模型进行对比,以是否加入图割优化处理作为另一个变量,并使用上文训练好的分类模型对所得嵌塞特征进行分类,结果如表3 所示。由表3 可知,经过图割法优化后的本文模型可以达到最佳分类结果,与PointNet 模型、KPConv 模型相比,分类准确率分别提高了10 和7 个百分点。

表3 不同模型的分类准确率对比Table 3 Comparison of classification accuracy of different networks
6 结束语
本文提出一种对牙齿嵌塞进行自动检测的方法,通过基于KPConv 卷积核和U-Net 网络设计的三维牙齿分割模型对牙齿进行分割,求出牙齿嵌塞特征,并使用SVM 对牙齿嵌塞情况进行分类。此外,充分利用牙齿模型所具有的特殊几何结构,将模型中向量信息及位置信息输入网络模型及后处理步骤中,通过多阶段的特征融合得出分类结果。实验结果表明,本文模型对磨牙的分割准确率达92%,判断牙齿是否嵌塞的分类准确率为81%。下一步将针对缺牙、牙齿错位等情况的牙齿嵌塞,寻求分割的解决办法,拓宽本文方法的应用范围。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02 08:24:26
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
农业科技与信息(2021年2期)2021-03-27 07:27:38
电子制作(2019年11期)2019-07-04 00:34:38
中国交通信息化(2018年5期)2018-08-21 03:37:40
北京航空航天大学学报(2018年1期)2018-04-20 06:38:17
小天使·一年级语数英综合(2017年8期)2017-08-04 00:41:48
小天使·一年级语数英综合(2016年11期)2016-11-28 21:41:40
创新作文(1-2年级)(2015年11期)2015-11-28 20:10:20
