
基于VGG 网络与深层字典的低剂量CT 图像去噪算法
2022-04-18 10:56:44周博超韩雨男桂志国李郁峰
计算机工程 2022年4期
周博超,韩雨男,桂志国,2,李郁峰,张 权,2
(1.中北大学电子测试技术国家重点实验室,太原 030051;2.中北大学生物医学成像与影像大数据山西省重点实验室,太原 030051;3.中北大学 军民融合协同创新研究院,太原 030051)
0 概述
计算机断层扫描(Computed Tomography,CT)成像技术是现代临床医疗影像学诊断的常用手段。然而,常规X 射线CT 扫描的放射性较高,会对人体造成一定的危害。低剂量CT(Low-Dose CT,LDCT)[1]通过降低X 射线管电压或管电流,以减弱放射性造成的伤害,但同时也降低成像质量。如何改善LDCT 的成像质量成为医学影像处理的研究热点。
目前,改善LDCT 图像质量的研究方法主要分为投影域去噪算法、改进重建算法和图像域去噪算法[2]。其中图像域去噪算法是基于稀疏表示的K-SVD(K-Singular Value Decomposition)算法[3-4],在去除轻度噪声伪影方面取得了良好的效果,但是基于质量退化严重的LDCT 图像学习到的字典原子中包含较多的噪声原子,无法有效地去除噪声[5]。针对上述问题,文献[6]提出分类字典的概念,通过对字典原子进行区分,提升K-SVD 算法的去噪性能。文献[7]提出一种基于正则化方法的K-SVD 算法,通过在字典原子更新时引入正则项,改善去噪效果。文献[8]提出一种深层字典学习算法,能够更好地保留图像边缘和细节信息,但在去除噪声伪影方面表现一般。文献[9]提出一种基于卷积神经网络的LDCT 图像去噪方法,通过学习LDCT 图像与其噪声图像之间的映射关系,从而改进去噪效果。然而,LDCT 图像与正常剂量的CT 图像难以对应。
为改善LDCT 图像质量,本文将改进的VGG[10-12]网络与深层字典相结合,提出一种LDCT 图像去噪算法。构建适合字典原子分类的VGG 网络模型,并将其应用于学习到深层字典的第一层字典原子中,同时根据分类结果将稀疏矩阵中噪声原子对应的元素设置为零,从而降低噪声原子对图像去噪效果的影响。
1 K-SVD 算法
K-SVD 算法是在最优方向算法(MOD)[13]的基础上提出的。MOD 算法的目标函数如式(1)所示:
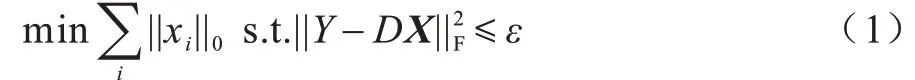
其中:D为字典原子;Y为样本数据集;X={xi}为字典D对应的稀疏矩阵;ε为稀疏度,即稀疏表示系数中非零元素的个数。
MOD 算法通过实现表征误差最小化来更新字典,即在公式两端对D求偏导。整个字典的更新过程如式(2)所示:
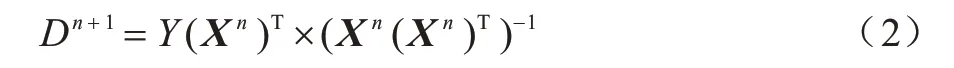
该运算需要对矩阵求逆,会耗费大量的计算资源。K-SVD 算法每次只更新一个字典原子和对应的稀疏编码向量,直至更新完所有的字典原子。本文假设图像Y可以描述为Y=DX,其中D∈RN×M,X为D对应的稀疏矩阵。K-SVD 算法分为以下两个阶段:
1)稀疏编码阶段
稀疏编码阶段可以描述为求解模型,其过程如式(3)所示:
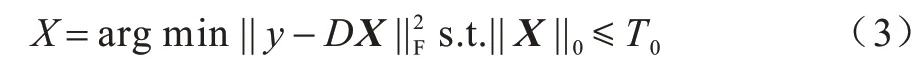
其中:||X||0是l0范数,为X中非零元素的个数;T0为非零元素个数的最大值。字典D可以初始化为一个离散余弦变换(Discrete Cosine Transform,DCT)字典[14],通过正交匹配追踪(Orthogonal Matching Pursuit,OMP)[15]算法计算得到稀疏编码矩阵X。
2)字典学习阶段
字典学习阶段主要是根据稀疏矩阵X迭代更新字典D中的原子。字典学习过程可以描述为求解模型,其过程如式(4)和式(5)所示:
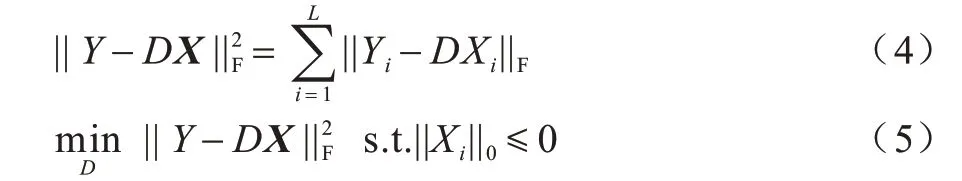
其中:||Xi||0是Xi的l0范数。K-SVD 算法的主要原理是先固定字典D,利用OMP 算法求解稀疏矩阵X,然后再固定X,根据X更新字典D,如此交替进行,直到求出字典D和稀疏矩阵X的最优解。
2 基于改进VGG 网络的字典原子分类模型
2.1 VGG 网络
深度学习[16]已发展出众多网络模型,其中适用于图像识别与分类的卷积神经网络是一种专门用来处理具有相似网格结构数据的神经网络[17-18]。VGG-16 网络结构如图1 所示。
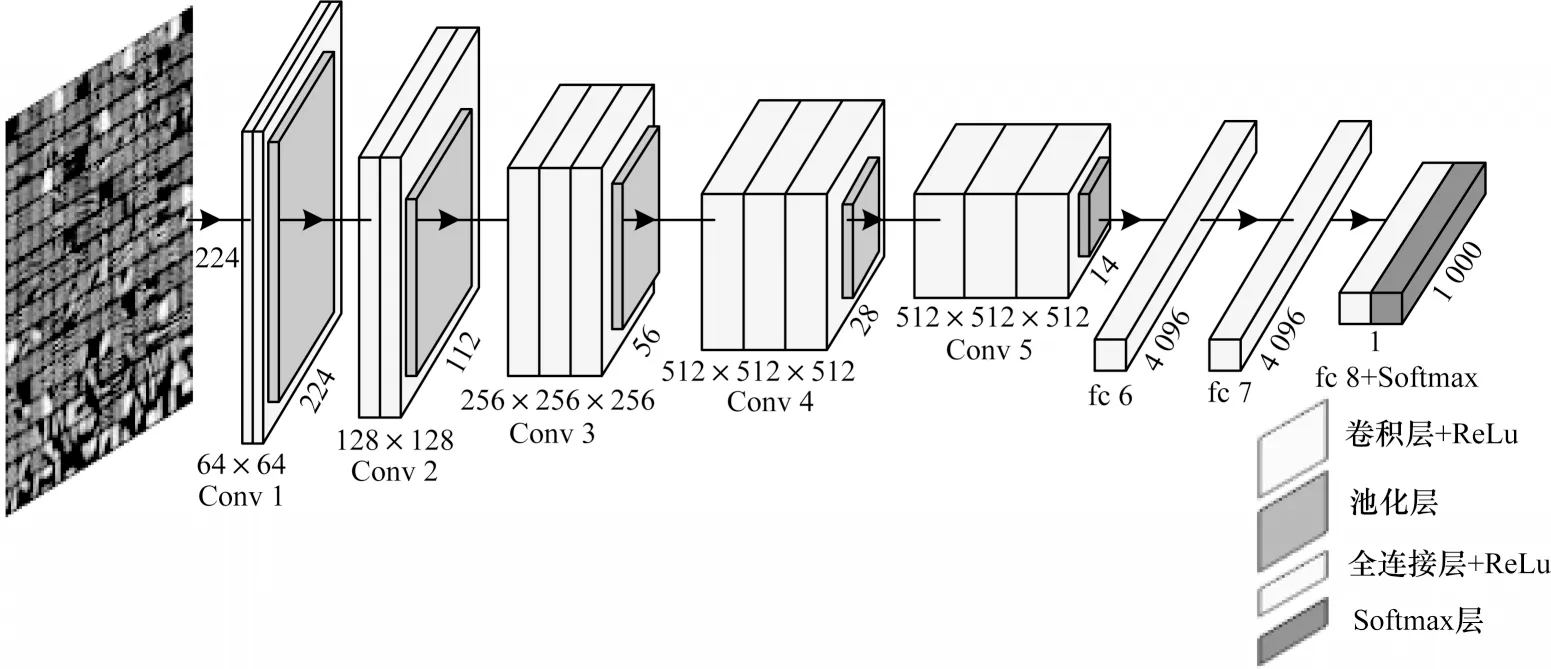
图1 VGG-16 网络结构Fig.1 Structure of VGG-16 network
VGG 网络是轻量级卷积神经网络中分类性能表现较优的网络模型之一。与AlexNet[19]网络相比,VGG网络最主要的特点是采用多个堆叠的3×3 卷积核代替AlexNet 网络中较大的单个卷积核,如5×5、7×7、11×11。对于相同的感受野,相比单个大卷积核,VGG网络采用堆叠的小卷积核,能够以更小的参数代价获得更优的非线性。VGG 网络全部采用相同大小的卷积核(3×3)和最大池化层(2×2),保证网络结构的简洁性,同时通过对VGG 网络的不同层数进行比较分析,验证了加深网络层数可以提高网络性能的有效性。随着网络层数的加深,需要求解的参数数目也随之增加,其中大部分参数来自于全连接层。
2.2 改进VGG 网络
本文在VGG-16 网络的基础上,通过去掉池化层和部分全连接层,并引入直连通道[20]构建区分噪声原子和信息原子的网络模型,如图2 所示。

图2 改进的VGG 网络结构Fig.2 Structure of improved VGG network
该模型主要包含5 个卷积段、1 个全连接层以及2 个标签的Softmax 层。5 个卷积段总共包含13 个卷积层,卷积核尺寸均为3×3,每段内卷积核数量一致,越靠后段的卷积核数量越多,分别为64、128、256、512、512,滑动步长为1,采用边界填充确保前后数据维数相同,激活函数采用ReLu。由于字典原子图像仅为8×8 像素,因此去除全部池化层。经典VGG 网络是为1 000 个分类类别设计的,而本文只有2 个分类类别,且需要求解的参数大部分来自于全连接层,因此仅保留1 个全连接层。同时在经典VGG 网络的基础上加入直连通道,将原始输入的信息直接传入到后面的网络层中,以抑制梯度消失且加快网络收敛速度。本文考虑到改进的VGG 网络共有13 个卷积层,并且过多的直连通道会增加网络的复杂度,因此分别在卷积层的第1 层和第4 层、第5层和 第7 层、第8 层和第10 层、第11 层和第13 层设置直连通道。
3 改进的深层字典
3.1 深层字典
SNIGDHA 等通过将字典学习和深度学习的概念相结合,基于K-SVD 算法提出了深层字典学习的概念。但是,单层字典的收敛条件并不适用于深层字典,并且在学习深层字典时,需要求解的参数增多,由于训练数据有限,会导致过拟合现象。为此,深层字典采用贪婪方式[21]学习字典,并将第1 层学习到的特征作为第2 层的输入。字典的求解可以是稠密或者稀疏的,稠密求解模型如式(6)所示:

其中:Y为输入图像;D为学到的 字典;X为字典D对应的稀疏矩阵。式(6)可以采用交替最小化[22]的方法求解,如式(7)所示:
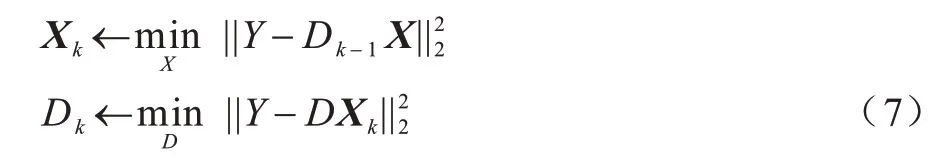
其中:k为深层字典的层数,k=1,2,…,n。在稀疏求解中需加入L1 范数进行正则化,即求解如式(8)所示:

式(8)也可以通过交替最小化来求解,如式(9)所示:

若字典层数为N层,求解如 式(10)~式(13)所示:

此时Y可以表示为:

其中:Dk、Xk为第k层学习到的字典及对应的稀疏矩阵,k=0,1,…,N。
深层字典通过学习多层字典来提取数据的特征,但对于LDCT 图像而言,深层字典无法区分图像中的结构信息和噪声信息。因此,深层字典学习到的字典原子中仍含有较多的噪声原子,导致深层字典在处理LDCT 图像时,虽然能够较好地保留图像的结构信息,但是无法有效抑制噪声对LDCT 图像质量的影响。
3.2 改进的深层字典学习算法
尽管深层字典可以学习到更多的图像细节信息,但深层字典的去噪能力较差,而LDCT 图像通常噪声强度较高。为提高深层字典的去噪性能和改善LDCT图像质量,本文通过改进的VGG 网络对深层字典学习算法进行相应的改进,算法结构如图3 所示。
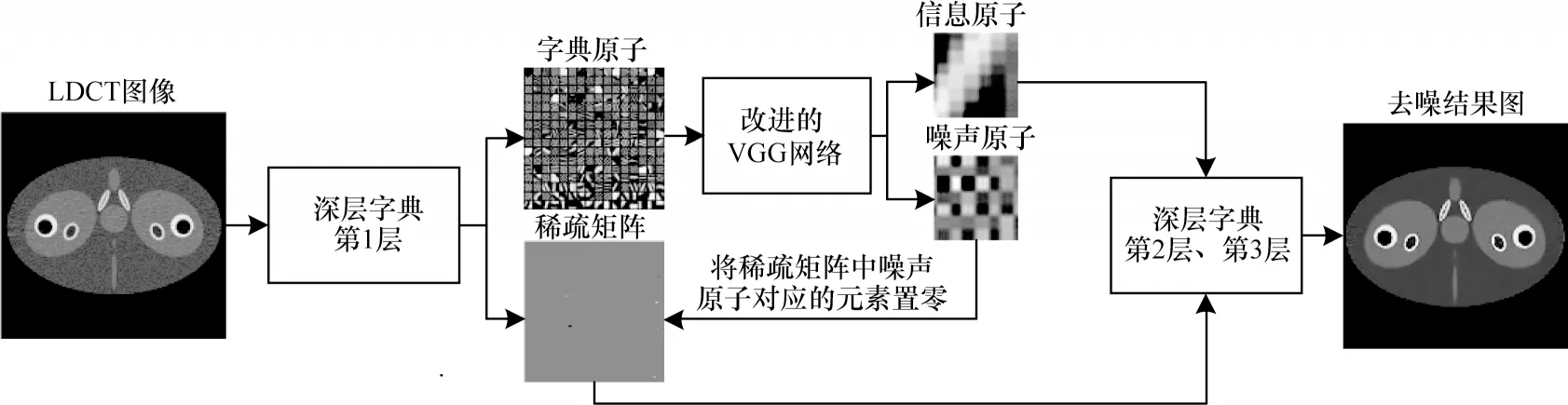
图3 改进的深层字典学习算法结构Fig.3 Structure of improved deep dictionary learning algorithm
本文所提的算法采用3 层结构。第1 层采用稀疏求解,字典大小设置为64×144,稀疏度为1,利用改进的VGG 网络将学习到的第1 层字典D1中的字典原子区分为噪声原子和信息原子,如图4 所示,并将稀疏矩阵中噪声原子所对应的元素设置为0,降低噪声原子对图像去噪效果的影响,得到一个新的稀疏矩阵X′1,如图5 所示。
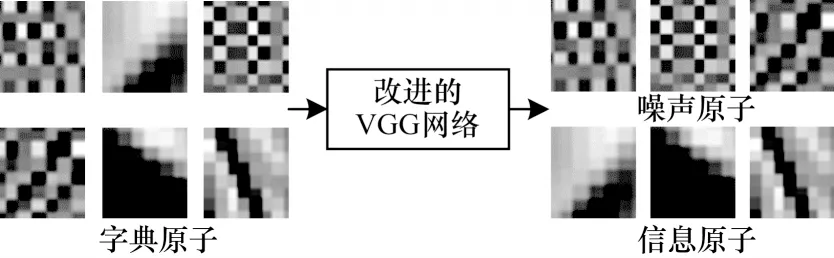
图4 区分字典原子示意图Fig.4 Schematic diagram of distinguishing dictionary atomic
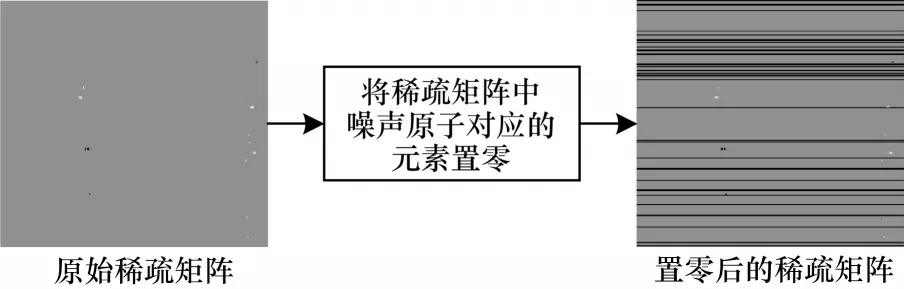
图5 稀疏矩阵中噪声原子所对应元素置零示意图Fig.5 Schematic diagram of zeroing elements corresponding to noise atoms in sparse matrix
这个过程如式(15)所示:

为保留图像中更多结构和边缘信息,字典的第2层和第3 层均采用稠密求解,字典大小分别设置为144×256、256×441,如式(16)和式(17)所示:

本文算法主要分为以下7 个步骤:
1)输入原始LDCT 图像Y;
2)利用式(7)得到字典D1和稀疏矩阵X1;
3)利用改进的VGG 网络将字典D1中的字典原子区分为噪声原子和信息原子;
4)将稀疏矩阵X1中噪声原子所对应的元素置零,得到新的稀疏矩阵
5)利用式(16)得到字典D2和稀疏矩阵X2;
6)利用式(17)得到字典D3和稀疏矩阵X3;
7)利用式(18)输出去噪图像Y。
4 实验结果与分析
4.1 数据集
本文采用的数据集是原始LDCT 仿真图像,通过K-SVD 算法学习字典原子图像块,字典大小设置为64×256,稀疏度设置为1。一幅原始LDCT 仿真图像可以得到256 幅8×8 像素的单个字典原子图像块,并利用labelme 软件进行标注。利用20 幅原始LDCT 仿真图像得到5 120 幅字典原子图像块组成的数据集。为保证数据集中正负样本数的一致性,本文筛选5 000 幅字典原子图像块,并经过镜像、翻转操作扩展至10 000 幅。
4.2 实验结果分析
本文实验将256×252 像素的骨盆体模LDCT仿真图像作为输入图像,将处理结果与K-SVD 算法、正则化K-SVD 算法、深层字典学习算法的处理结果进行对比分析。为定量评价各算法的处理结果,本文选用结构相似性(Structural Similarity,SSIM)、峰值信噪比(Peak Signal to Noise Ratio,PSNR)、平均绝对误差(Mean Absolute Error,MAE)作为客观评价指标。
图6 为在迭代训练100 次时,改进VGG 网络模型在训练集和验证集上的损失值和准确率的变化,最终在字典原子数据集上的准确率达到97.7%。
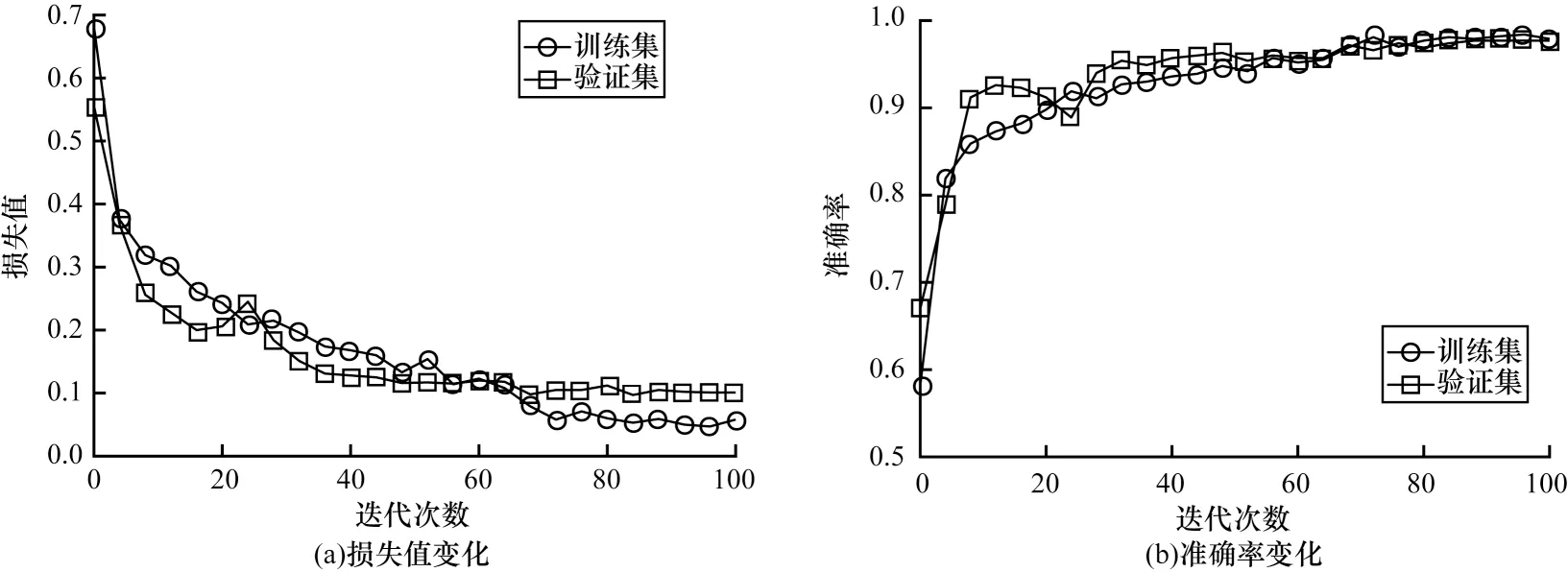
图6 在训练集和验证集上改进VGG 网络的损失值和准确率变化Fig.6 Change of loss value and accuracy rate of improved VGG network on training set and validation set
图7从直观上给出了改进的VGG网络模型对字典原子的分类结果,如图中箭头所示,只有个别字典原子分类错误。

图7 改进VGG 网络对字典原子分类结果Fig.7 Classification result of improved VGG network to the dictionary atomic
图8 为不同算法的去噪结果图及局部放大图。从图中可以看出,传统的K-SVD 算法在处理LDCT图像时,仍残留较多的噪声伪影,同时损失了边缘和细节信息。正则化K-SVD 算法虽然提高了去噪性能,但与传统K-SVD 算法相似,损失了较多的细节和边缘信息。传统的深层字典学习算法能够保留较多的细节信息,但仍含有明显的噪声伪影。本文算法在提高去噪性能的同时保留了更多的边缘和细节信息。因此,本文算法在视觉效果上明显优于其他同类算法。

图8 不同算法的去噪结果及局部放大图Fig.8 Denoising results of different algorithms and local enlargement images
表1 为不同算法处理LDCT 图像后的评价指标对比。从表中可以看出,本文算法在结构相似性、峰值信噪比和平均绝对误差方面均优于其他同类对比算法。
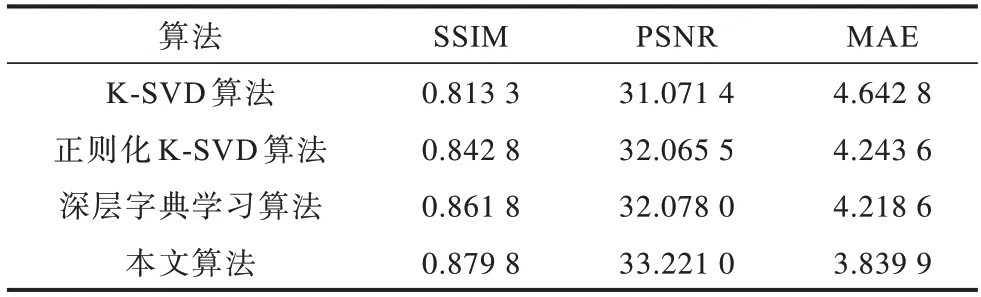
表1 不同算法处理LDCT 图像后的评价指标Table 1 Evaluation indexes of LDCT images processed with different algorithms
表2 为本文算法在稀疏度为1,字典原子图像块大小为8×8 的情况下,不同字典大小对实验结果的影响,其中ki表示深层字典第i层字典大小,i=1,2,…,n。从表2 可以看出,当字典尺寸较大时,算法的去噪效果较好,其主要原因是字典尺寸越大,能够包含的图像信息越多,有利于对噪声图像进行稀疏重构。但是当字典尺寸过大时,去噪效果反而下降了,这是因为LDCT 图像包含较多的噪声伪影信息,字典尺寸过大时,会将较多的噪声伪影信息引入字典中,从而导致去噪效果下降。本文所采用的字典大小是经过多次实验得到的,但这种方法选取的字典大小为经验值,而非最优解。

表2 不同字典大小对实验结果的影响Table 2 Influence of different dictionary sizes on experimental results
5 结束语
为提高LDCT 图像质量,本文提出一种基于VGG网络和深层字典的去噪算法,通过改进的VGG 网络将深层字典的第一层字典原子区分为信息原子和噪声原子,并将稀疏矩阵中噪声原子所对应的元素置零,从而弥补深层字典学习算法去噪能力的不足。实验结果表明,相比K-SVD、正则化K-SVD 和深层字典学习算法,本文算法在提高图像去噪能力的同时保留了较多的边缘和细节信息。后续将通过自适应选取字典大小的最优解,进一步提高算法的去噪效果。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 21:27:59
少儿科学周刊·儿童版(2021年22期)2021-12-11 06:42:32
水利规划与设计(2020年1期)2020-05-25 08:01:34
铁道通信信号(2018年1期)2018-06-06 02:27:37
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
读者(2016年14期)2016-06-29 17:25:50
中国卫生(2015年1期)2015-11-16 01:05:58
