
结合马氏距离与自编码器的网络流量异常检测方法
2022-04-18 10:56李贝贝戴菲菲
计算机工程 2022年4期
李贝贝,彭 力,戴菲菲
(1.江南大学 物联网工程学院,江苏 无锡 214122;2.台州市产品质量安全检测研究院,浙江 台州 318000)
0 概述
随着“互联网+”时代的到来,网络技术被广泛应用于金融、教育、军事、治安等领域。但网络技术是把双刃剑,一些不法分子利用网络技术中各种协议和应用程序的漏洞违法犯罪,不仅影响了网络基础设施的稳定运行,还造成人民群众的经济损失,甚至威胁到了国家安全[1]。互联网中的信息交流和传输以网络流量为载体,及时发现异常的网络流量并采取针对性措施,对于抵御网络攻击、维护网络安全、增强网络稳定性等均具有重要意义。
网络流量异常检测是一种有效的网络防护手段,异常网络流量是指对网络的正常使用造成不良影响的流量,与正常流量差别较大[2]。异常网络流量可分为两类[3]:一是由于网络结构不合理或者网络使用不当造成的异常流量;二是由DDoS、蠕虫病毒等网络攻击行为造成的异常流量。
传统的网络流量异常检测方法包括基于端口、基于统计、基于聚类、基于信息论等方法[2]。其中基于端口的方法异常检测准确度较低,而基于统计、聚类、信息论的方法使许多机器学习算法能用于网络流量异常检测,如K 近邻算法(K-Nearest Neighbor,KNN)、孤立森林算法(Isolation Forest,iForest)、支持向量机(Support Vector Machine,SVM)等。如今,网络流量规模越来越大,数据维度越来越高,对异常检测的要求更高,但传统的机器学习算法存在训练效率低、特征提取繁琐、相关参数过多、检测准确度较低等问题。
深度神经网络(Deep Neural Network,DNN)可自适应地进行数据特征提取,具有传统机器学习无法比拟的优越性,在图像识别、故障诊断、数据分类等领域得到广泛应用[4]。自编码器(AutoEncoder,AE)是一种用于无监督学习的深度神经网络,最早由RUMELHARD等[5]提出,BOURLARD 等[6]对其进行了更加详细的阐述。随后,NG 等[7]提出具有更强特征提取能力的稀疏自编码器。基于自编码器的改进模型被陆续提出,并应用于各种研究领域。在网络流量等数据异常检测问题上,自编码器因其优越的重建数据和特征提取能力得到了广泛的关注[8]。
目前网络流量监控和数据采集系统较为完善,但采集到的网络流量数据往往规模较大,降低了自编码器和神经网络的训练效率且无法有效提高网络的训练效果[9]。由于网络流量数据特征较多、维度较高,且计算机网络的基本原理、网络基础设施、网络流量数据特征之间的相关性不可忽视,因此考虑数据特征相关性的马氏距离(Mahalanobis distance)[10]更适合用于网络流量数据之间的距离表达。
本文提出一种结合马氏距离和自编码器的检测方法,通过实验得到马氏距离倒数的判别阈值,并根据马氏距离及判别阈值快速检测出部分正常网络流量,以提高网络流量异常检测的效率。在此基础上,将马氏距离度量项加入自编码器的代价函数中,提高自编码器对网络流量数据的特征学习能力。此外,将自编码器和Sigmoid 分类器相结合,构建用于网络流量异常检测的自编码神经网络,以避免网络陷入局部最优[9]。另外,调整自编码神经网络交叉熵损失函数中各项的权重,从而增强自编码神经网络对数据分布不均衡网络流量数据集的训练效果,提高异常检测的准确性。
1 相关概念
1.1 自编码器
自编码器的结构模型如图1 所示,主要包括编码层、隐层和输出层,分为编码和解码两个阶段。将输入层数据编码为隐层表达,将隐层表达解码为输出层数据,其目标为重构输入数据,最小化重构误差使输出层数据尽可能等于相对应的输入数据以获得最佳的隐层表达[13]。
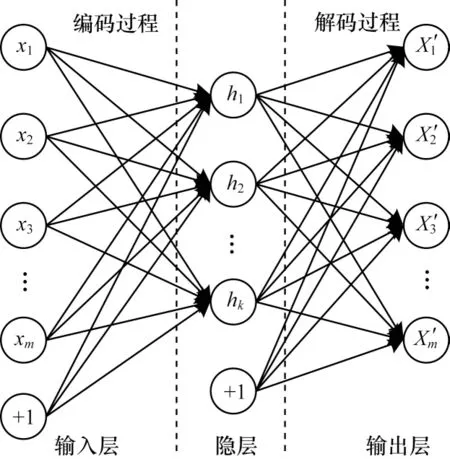
图1 自编码器结构Fig.1 Autoencoder structure
将输入数据表示为X=(X1,X2,…,Xn),其中Xi∈Rm(i=1,2,…,n),数据个数为n,维度为m。输出数据记为X′i。自编码器的编码和解码过程如下:

其中:W为编码阶段权重;W′为解码阶段权重;b为编码阶段偏置;b′为解码阶段偏置;σe和σd为激活函数,较为常用的激活函数有Relu、Tanh、Sigmoid 等[9]。
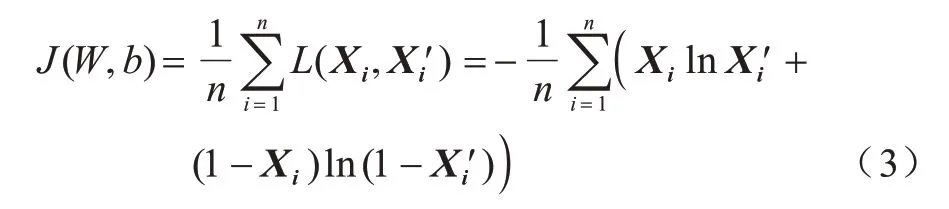
其中:L为单个数据的损失函数,本文使用的是交叉熵损失函数。网络流量的异常检测任务为二分类任务,对于最终分类网络的激活函数选择Sigmoid 函数较为合适。均方误差损失函数存在权重更新过慢的问题,但交叉熵损失函数可以完美解决以上问题,其具有误差大但权重更新快,误差小但权重更新慢的优势[15]。所以,当使用Sigmoid 函数作为激活函数时,交叉熵损失函数更加适合。另外在常用代价函数中添加L2 正则化项[15]可避免过拟合,λ为L2 正则化项的惩罚因子,常用代价函数如下:
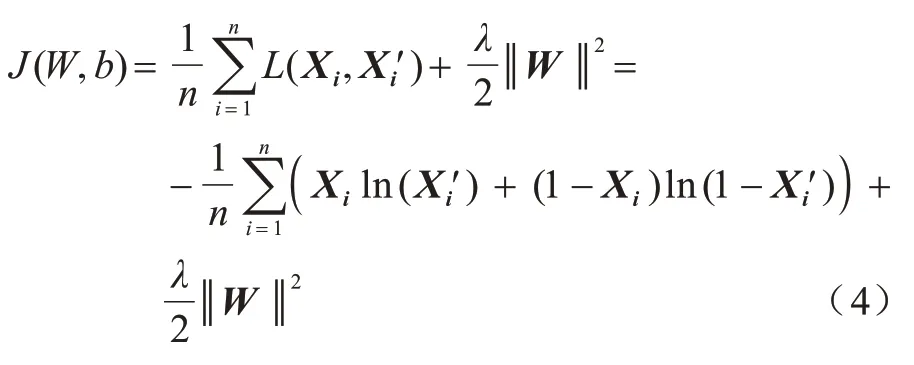
1.2 马氏距离
马氏距离由印度统计学家Mahalanobis 提出,其利用向量间的协方差矩阵表示距离,考虑了各变量之间的相关性,因此在诸多领域具有一定的优越性[10]。
设有一均值为μ=(μ1,μ2,…,μm)T,协方差矩阵为Σ的数据集X=(X1,X2,…,Xn),n为数据个数,m为数据维度,其中一个数据表示为x=(x1,x2,…,xm)T,则其马氏距离表示为:
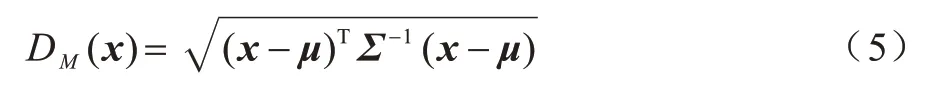
其中:Σ-1为Σ的逆矩阵。马氏距离的计算公式使用了协方差矩阵,其最大优势在于考虑了数据特征之间的相关性[10]。
文献[11]使用方差分析、方差阈值等方法提取网络流量数据的特征,并结合多个聚类算法进行联合异常检测,在聚类算法中使用欧式距离进行聚类,实验效果对特征的选择依赖性较大,需要多种聚类算法融合才能提升效果,因此使用欧式距离进行网络流量数据的距离计算的效果一般,不具有优越性。文献[12]利用KL 距离进行网络流量异常检测,利用指数加权移动平均模型建立滑动窗口机制,获取数据的KL 距离预测值并得到自适应阈值范围。此外,通过判断数据的KL 距离是否在此范围内进行网络流量的异常检测。该方法具有一定优越性,然而更适用于动态变化的网络环境,需要不断变换阈值,对于数据规模较大的网络流量数据异常检测时,网络流量数据的KL 距离并没有明显的不同。
综上所述,本文选用马氏距离进行网络流量数据间的距离表达。
由式(5)可知,在数据集中,数据的马氏距离越小,说明其与数据集均值越接近。若一数据为正常数据,则其通过式(5)计算得到的马氏距离应符合正常数据马氏距离分布,否则该数据更可能为异常数据,所以网络流量数据的马氏距离是其正常与否的一个重要判别依据。
2 网络流量异常检测方法
2.1 数据判别
将数据维度为m的网络流量数据集记为X=(X1,X2,…,Xn),n为数据个数。利用其中一部分正常数据集,计算其均值并记为μN=(μ1,μ2,…,μm)T,其协方差矩阵记为ΣN。由式(5)可知,马氏距离的计算使用了数据集的均值,而均值受每个数据的影响,所以马氏距离放大了少量数据的影响[10]。为避免此影响,本文在对所有数据计算其马氏距离时,采用不受数据变化影响的独立正常数据集的均值μN和协方差矩阵ΣN。所以数据Xi的马氏距离表示为:

根据式(6)计算网络流量数据集中数据的马氏距离,将数据的马氏距离集记为:
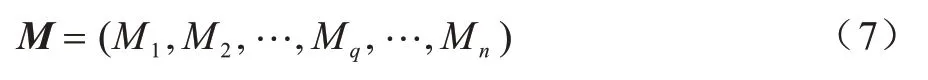
其中:Mq表示在数据集中第q个数据的马氏距离。
如果某一数据为正常数据,利用μN和ΣN,通过式(6)计算得到的马氏距离应符合正常数据的马氏距离分布;如果该数据为异常数据,则通过式(6)计算得到的马氏距离可能不符合正常数据的马氏距离分布。在实验过程中发现,正常与异常数据通过式(6)计算得到的马氏距离分布不同,尤其正常与异常数据的马氏距离倒数的分布相差较大,相关分布图在4.1 节给出。将数据的马氏距离倒数集记为:
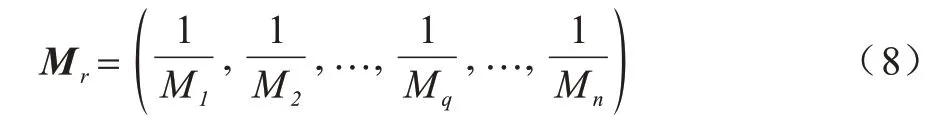
通过实验观察Mr的分布,发现正常与异常数据的马氏距离倒数的分布之间存在一个阈值,记为T。在实验中,若网络流量数据Xi的马氏距离倒数≥T,则数据Xi为正常数据,否则判定该数据为未确定数据,并进入自编码神经网络进行判断。
此判别阈值T需要通过实验分析确定合适的数值以保证数据判别的正确性。通过实验可知,超过此阈值的均为正常数据。将未超过此判别阈值的数据判定为未确定数据,将未确定数据集作为训练数据用于自编码器和分类网络的训练。如此可快速判别出部分正常数据,将其余的未确定数据作为接下来网络的训练数据,大幅缩减了训练数据规模。在实际检测时,通过数据马氏距离及判别阈值可快速判别是否为正常数据,提高了检测效率。
2.2 改进自编码器的构建
为使自编码器获得更好的隐层表达及进一步提高其提取特征的能力,利用KL 散度对隐层神经元输出进行约束并将其添加到代价函数中,从而抑制隐层神经元的输出,使网络达到稀疏效果,并构成稀疏自编码器[7]。稀疏自编码器代价函数表示如下:

其中:稀疏惩罚项为KL 散度即KL(ρ‖);k为隐层神经元数量;β控制稀疏惩罚项的权重;ρ为稀疏常数为隐层神经元上的平均激活量。
KL 散度[13]表示如下:
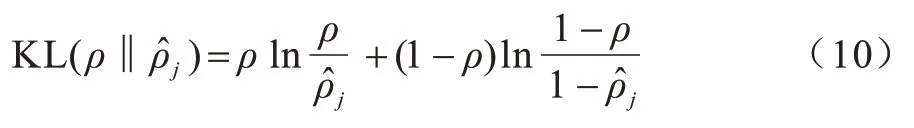
如上所述,数据的马氏距离可以作为该数据是否为异常数据的判断依据,因此考虑在自编码器的代价函数中添加一个马氏距离度量项,使自编码器在训练过程中,输出与输入的马氏距离尽量接近,从而使自编码器更好地学习数据特征,提升异常检测效果。本文提出的改进自编码器代价函数表示如下:
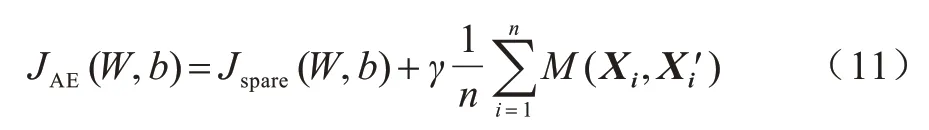
其中:γ为马氏距离度量项权重;为马氏距离度量项。
马氏距离表示如下:
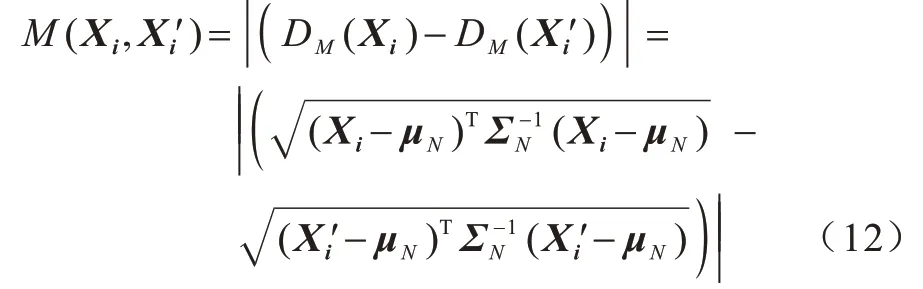
在式(12)中,计算输入与输出马氏距离时仍然使用2.1 节中得到的正常数据集的均值μN和协方差矩阵ΣN。本文构建的改进自编码器如图2 所示。
图2 改进自编码器的结构Fig.2 Structure of the improved autoencoder
由于本文主要关注马氏距离度量项对自编码器的影响,因此构建了最简单的3 层自编码器结构,其代价函数如式(11)所示,自编码器训练时通过无监督贪婪算法[15]最小化代价函数,使用未确定数据集进行自编码器的训练,最终得到隐层表达hk。
2.3 自编码器与分类器的结合
上述自编码器训练完成后,将隐层结合分类器构建成自编码神经网络。将得到的合适权值W和偏置b参数作为分类网络的初始化参数,避免了传统网络参数随机初始化可能会使网络陷入局部最优的风险,提高了分类网络的稳定性。如图3 所示,将hk作为Sigmoid 分类层S的输入,输出分类结果Xo,同时,输入带有标签的未确定数据以完成有监督的训练及参数微调[16]。
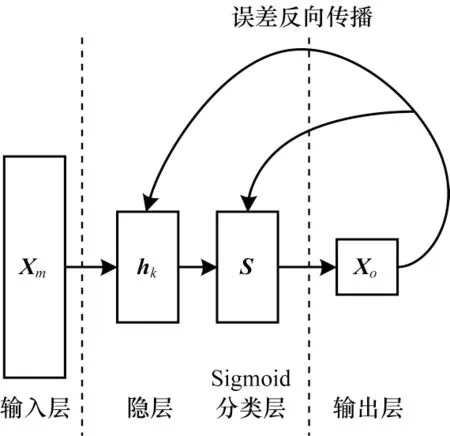
图3 参数微调Fig.3 Parameter fine-tuning
自编码神经网络的代价函数为交叉熵损失函数:
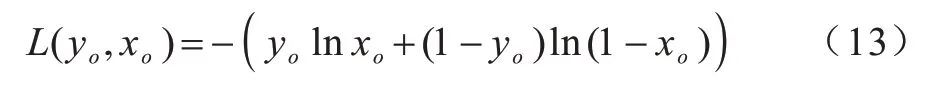
其 中:xο为神经网络输出结果;yο为该数据真实标签,yο∈(0,1)。
在网络流量的采集过程中,若不处理网络流量数据集,则大多数数据为正常数据,异常数据占比较小,数据分布不均衡。使用这种不均衡的数据集进行神经网络训练时,可能会让神经网络倾向于将所有的样本都预测为正常数据,于是本文使用调整交叉熵损失函数中各项权重的方式来缓解此问题。
在进行实验时,将正常数据的标签标记为0、异常数据的标签标记为1。令W0表示用于训练的未确定数据集中正常数据占总数据量的比重,W1表示异常数据占总数据量的比重,改进该自编码神经网络的代价函数如式(14)所示:
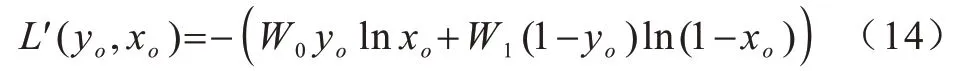
由于W0>W1,因此当占比较少的异常数据(标签为1)被错误预判为正常数据(即预判为0)时,代价就非常大。而一旦占比较多的正常数据(标签为0)被错误预判为异常数据(即预判为1)时,代价较小,对网络训练的影响也较小。
因此,通过对自编码神经网络代价函数改进,一定程度上解决了数据分布不均衡对网络训练的影响,提高了自编码神经网络的训练效果,有利于网络流量的异常检测。
3 实验准备
实验使用Windows10 操作系统,计算机CPU 为Intel Core i5-6500 3.20 GHz、8 GB RAM,基于Keras框架使用python3.6 实现。
3.1 实验数据
本文使用的数据集为CICIDS2017 数据集[17]和NSL-KDD 数据集[18],这两个数据集在网络异常检测研究中被广泛应用。
CICIDS2017 数据集是加拿大网络安全研究所于2017 年采集并公开的网络流量数据集,该数据集包含周一到周五采集的5 天网络流量数据,其中包含了正常流量与常见攻击导致的异常流量。进行的攻击包括暴力文件传输协议(FTP)、暴力安全外壳协议(SSH)、拒绝服务(DoS)等,本文只进行网络流量的异常检测研究,故将这些攻击导致的网络流量数据定义为异常网络流量。该数据集共包含2 830 743 条数据,其样本分布如表1 所示。

表1 CICIDS2017 数据集样本分布Table 1 CICIDS2017 data set sample distribution
NSL-KDD 是研究人员为解决KDDCup99 数据集的缺陷而开发的网络流量数据集[18],该数据集由KDDCup99 数据集改进,其不包含冗余数据和重复数据,数据分布更加平衡,更能体现异常检测效果。该数据集包含正常数据及拒绝服务攻击、监视、探测、非法访问等异常攻击或操作造成的异常网络流量数据,共包含125 972 条数据,该数据集样本分布如表2 所示。

表2 NSL-KDD 数据集样本分布Table 2 NSL-KDD data set sample distribution
3.2 实验流程
实验主要使用CICIDS2017 数据集,然后使用NSL-KDD 进行相关对比实验,并进一步观察所提方法的异常检测效果。实验步骤如下:
步骤1由于数据集中某些特征为离散型特征,因此需要对实验数据集进行预处理,将这些特征值处理为数值型。为保证离散型特征值的无序性,本文采用One-Hot 编码[19]处理离散型特征,随后对数据进行归一化处理。
步骤2训练数据集为实验数据集随机采样的80%数据,测试数据集为剩余的20%数据。
步骤3通过训练数据集中的正常数据集得到式(6)中的 均值μN、协 方差矩 阵ΣN及,并 根据式(6)计算训练数据集中所有数据的马氏距离,再计算数据的马氏距离倒数,得到训练数据的马氏距离倒数集Mr。根据实验观察Mr中正常数据与异常数据的马氏距离倒数分布,确定判别阈值T的值。
步骤4将Mr中超过阈值T的数据判定为正常数据,未超过阈值T的数据判定为未确定数据,将未确定数据集作为自编码器和分类网络的训练数据。
步骤5构建如图2 所示的改进自编码器,代价函数为添加马氏距离度量项的式(11),并通过未确定数据训练自编码器,得到最佳隐层表达hk。
步骤6确定正常数据占未确定数据量的比重W0、异常数据占未确定数据量的比重W1,构建如图3 所示的以式(14)为代价函数的改进自编码神经网络。将hk作为Sigmoid 分类器的输入,通过带标签的未确定数据进行有监督地微调完成整个自编码神经网络的训练。
步骤7使用测试数据集进行测试实验。使用步骤3 中确定的μN和计算得到测试数据的马氏距离,并计算其马氏距离倒数。若数据马氏距离倒数超过阈值T,则将该数据判定为正常数据;若数据马氏距离倒数未超过阈值T,将其判定为未确定数据。随后将该数据输入进训练完成的自编码神经网络中并输出其判定结果。通过测试实验,观察所提方法的异常检测效果。本文提出的网络流量异常检测模型如图4 所示。

图4 异常检测模型Fig.4 Anomaly detection model
3.3 评价标准
本文实验的评价指标混淆矩阵[20]如表3 所示。

表3 评价指标混淆矩阵Table 3 Confusion matrix of evaluation indicators
本文使用如下指标评价异常检测效果:
准确率(Accuracy)表示分类正确的样本占全部样本的比重,其表达如下:

精确率(Precision)表示正确分类为正样本的数据量占全部分类为正样本数据量的比重,其表达如下:

召回率(Recall)表示正确分类为正样本的数据量占全部实际为正样本的数据量的比重,其表达如下:

F1 值(F1)能有效地说明异常检测效果,其为精确率和召回率的综合考量,表达如下:
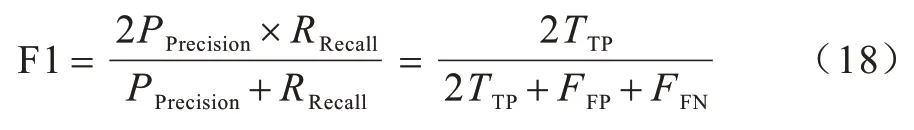
若实验异常检测效果越好,则上述4 个指标越接近1[19]。
4 实验过程
本文首先使用CICIDS2017 数据集进行实验,由于CICIDS2017 数据集的数据量较大,为提高实验效率,本实验随机选取CICIDS2017 数据集的20%数据作为实验数据集,该实验数据集共包含566 149 条数据。CICIDS2017 实验数据集样本分布如表4 所示,经过预处理后,该实验数据集中网络流量数据包含70个特征。

表4 CICIDS2017 实验数据集样本分布Table 4 CICIDS2017 experimental data set sample distribution
本实验首先随机选取CICIDS2017 实验数据集的80%数据作为训练数据,剩余20%作为测试数据。训练数据集样本分布如表5 所示,测试数据集样本分布如表6 所示。
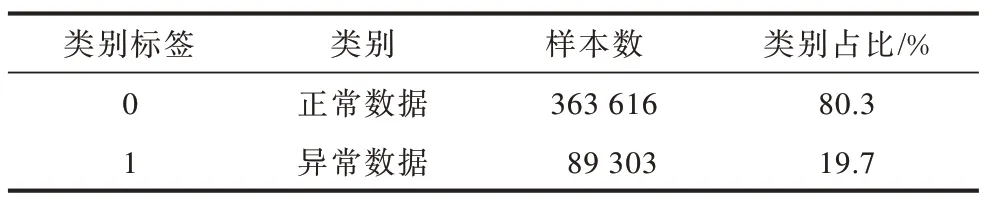
表5 CICIDS2017 训练数据集样本分布Table 5 CICIDS2017 training data set sample distribution

表6 CICIDS2017 测试数据集样本分布Table 6 CICIDS2017 test data set sample distribution
4.1 数据判别
选取训练数据集中的正常数据集,从而计算得到正常数据集的均值μN和协方差矩阵ΣN,根据式(6)计算所有训练数据的马氏距离,训练数据的马氏距离分布如图5 所示。
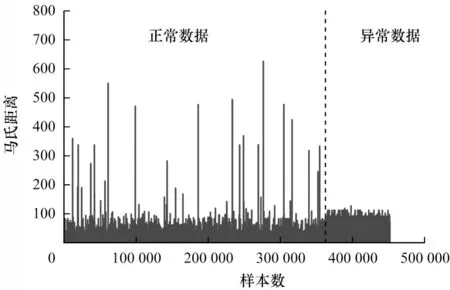
图5 训练数据集的马氏距离分布Fig.5 Mahalanobis distance of training data set
由图5 可知,在训练数据集中,正常与异常数据通过式(6)得出的马氏距离分布不同,接下来计算得到训练数据集的马氏距离倒数,观察其马氏距离倒数的分布,如图6 所示。
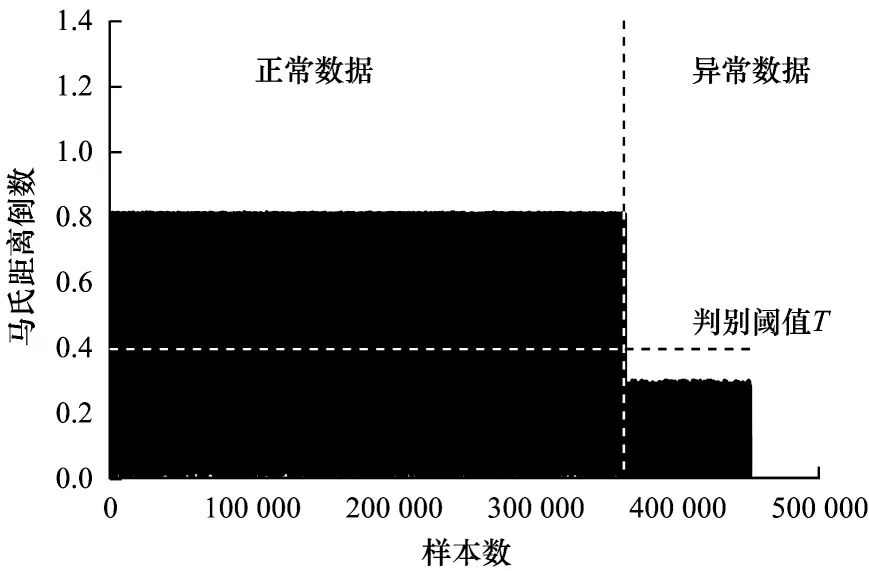
图6 训练数据集的马氏距离倒数分布及判别阈值Fig.6 Inverse distribution of Mahalanobis distance and discrimination threshold of training data set
由图6 可知,训练数据集中数据的马氏距离倒数分布差异较为明显。根据图6 可确定判别阈值T,为保证检测准确性,需确保超过判别阈值的均为正常数据,异常数据均未超过判别阈值,本实验确定判别阈值T的值为0.4,已在图6 中标示。
如图6 所示,将马氏距离倒数超过判别阈值T的数据判定为正常数据,未超过判别阈值T的判定为未确定数据。经过实验证明,马氏距离倒数超过判别阈值而被判定为正常数据的数据实际均为正常数据,接下来将未超过判别阈值的未确定数据集作为训练数据用于自编码器和分类网络的训练,未确定数据集包含318 400 条数据,其样本分布如表7所示。

表7 未确定数据集样本分布Table 7 Uncertain data set sample distribution
通过判别阈值共判别出134 519 条正常数据,占训练数据集中正常数据量的37.0%,占训练数据集总数据量的29.7%,明显减少了训练数据量。在实际网络流量异常检测中利用判别阈值可快速判别数据是否为正常数据,提高了检测效率。
4.2 改进自编码器的构建
本实验构建的自编码器在稀疏自编码器的基础上加入马氏距离度量项,其代价函数为式(11)。由于在隐层中加入了稀疏性限制,式(9)中的稀疏惩罚项的权重β和稀疏常数ρ需要通过实验确定合适的数值,同时隐层的维度k也需要通过实验确定。在这些参数的确定过程中,本实验将自编码器训练次数设为50,单次训练选取样本数为1 000,观察这些参数的变化对自编码器训练损失的影响,每个参数进行5 次实验取平均训练损失。
图7 所示为自编码器训练损失随隐层维度k的变化,可知维度设为28 时训练损失最低。图8 所示为自编码器训练损失随β的变化,图9 所示为自编码器训练损失随ρ的变化,由此可知β和ρ分别设为0.1和0.04 时训练损失最低。表8 所示为改进自编码器的参数设置。
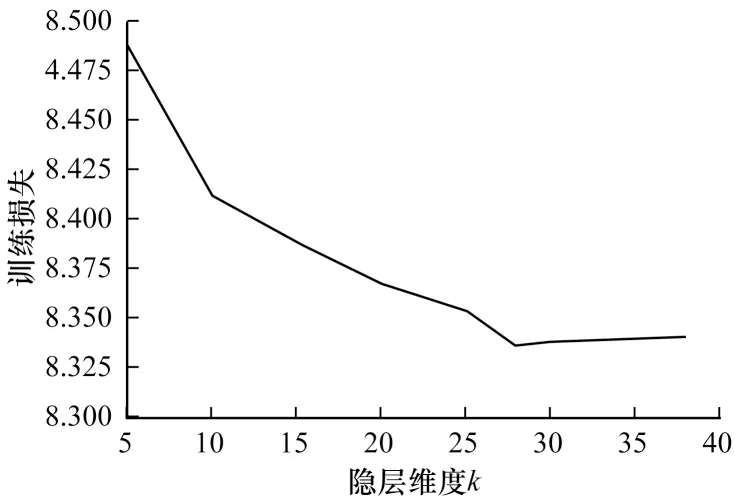
图7 自编码器训练损失随k 的变化Fig.7 Training loss of autoencoder changes with k
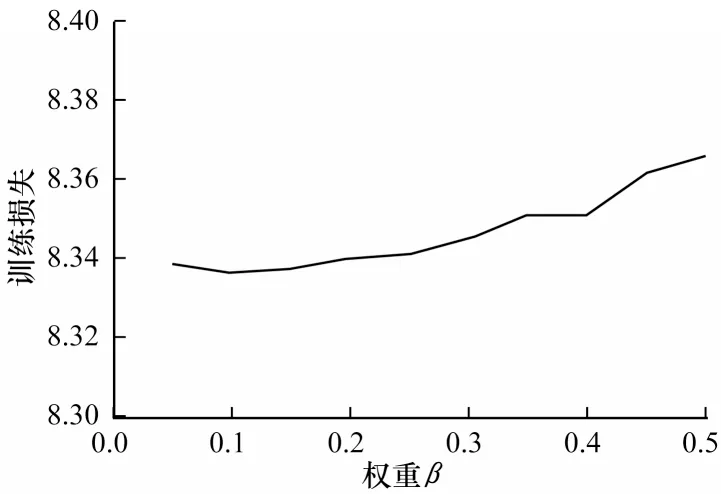
图8 自编码器训练损失随权重β 的变化Fig.8 Training loss of autoencoder changes with weignt β
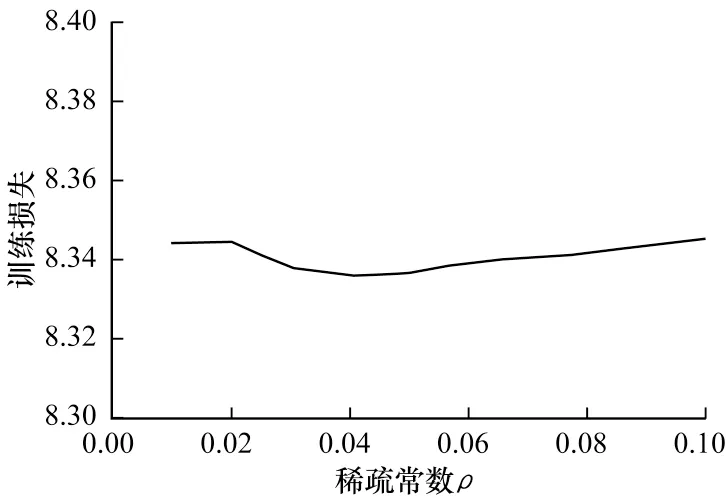
图9 自编码器训练损失随稀疏常数ρ 的变化Fig.9 Training loss of autoencoder changes with sparse constanti ρ
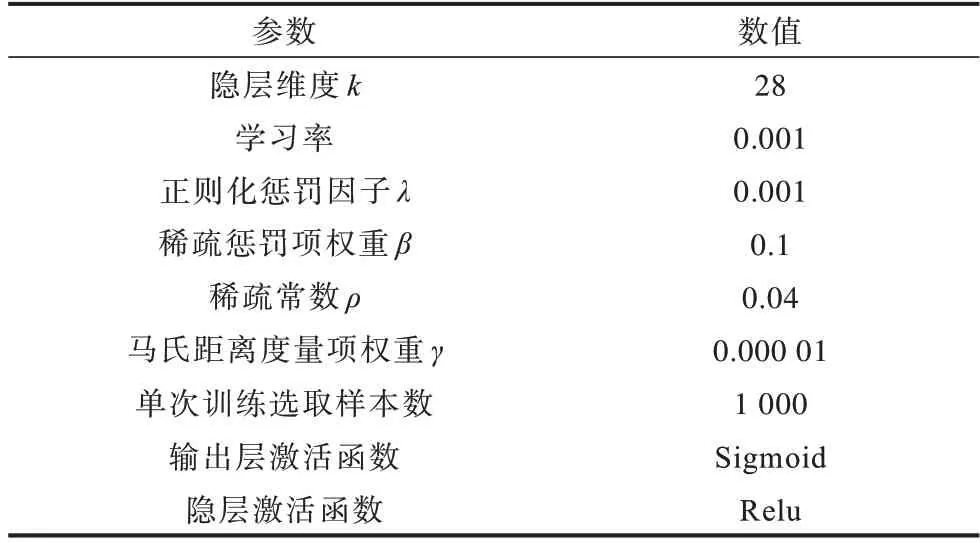
表8 改进自编码器的参数设置Table 8 Parameters setting of improved autoencoder
构建的改进自编码器在训练次数为100、单次训练选取样本数为1 000 的情况下训练损失曲线如图10 所示,可以看到改进自编码器具有良好的收敛性。
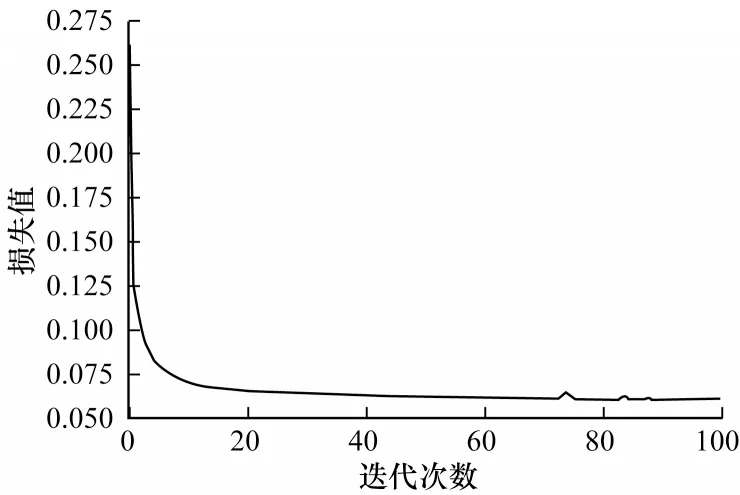
图10 改进自编码器的训练损失Fig.10 Improved autoencoder training loss
4.3 改进自编码神经网络的构建
将训练完成的自编码器的隐层连接Sigmoid 分类层,构建如图3 所示的改进自编码神经网络。通过自编码器训练获得的最优权值W和偏置b参数作为分类网络的初始参数。该自编码神经网络的代价函数为式(14),通过得到的用于训练的未确定数据集计算得知,其中正常数据占未确定数据量的比重W0为0.72、异常数据占未确定数据量的比重W1为0.28。
通过输入带标签的未确定数据集对改进自编码神经网络进行有监督的微调,训练次数为100,单次训练选取样本数为1 000,其训练损失曲线如图11 所示。可看到其损失曲线呈连续下降趋势,说明通过将自编码器的W和b参数作为初始参数使网络具有较好的收敛性,避免了网络陷入局部最优的风险;并且通过调整交叉熵损失函数中两项的权重,使自编码神经网络的损失下降较快,有利于取得更好的训练效果。
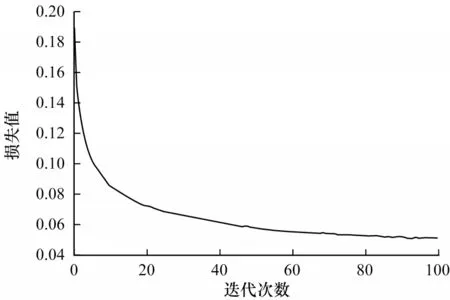
图11 改进自编码神经网络的训练损失Fig.11 Improved autoencoder neural network training loss
4.4 测试实验
使用测试数据测试本文提出的结合马氏距离和自编码器的网络流量异常检测方法的异常检测效果。通过式(6)计算测试数据的马氏距离再得到其马氏距离倒数,经过判别阈值T首先判别出一部分正常数据,再将剩余数据放入训练完成的改进自编码神经网络中得到其预测结果。
为增强实验的可靠性和准确性,采用5 折交叉验证方式[7]进行实验:将实验数据集随机均匀分为5 份,轮流将其中1 份作为测试数据,剩余4 份作为训练数据,共进行5 次实验,将5 次实验结果取均值作为最终实验结果。实验结果如表9 所示,可见本文提出的网络流量异常检测方法具有较好的效果。

表9 测试实验结果Table 9 Results of the test experiment
5 实验结果
为更进一步考察本文所提方法的异常检测效果,设计4 组不同对比实验:1)一般自编码器与加入马氏距离度量项的改进自编码器的实验效果对比;2)一般自编码神经网络与调整交叉熵损失函数的改进自编码神经网络的实验效果对比;3)本节提出的网络流量异常检测方法与其他网络流量异常检测方法的对比;4)使用NSL-KDD 数据集进行实验,观察其异常检测效果。
5.1 一般自编码器与改进自编码器的对比
为了观察在自编码器代价函数中加入马氏距离度量项的影响,本实验构建了一个未加入马氏距离度量项的,以式(9)为代价函数的一般自编码器,并与4.2 节构建的加入马氏距离度量项的改进自编码器进行对比,两个自编码器除代价函数外,参数和结构完全与4.2 节构建的改进自编码器相同。
使用得到的未确定数据集分别对两个自编码器进行训练,训练次数均为100,单次训练所选样本数均为1 000,两者的训练损失对比如图12 所示。由图12 可知,两个自编码器的训练损失相差较小,改进自编码器由于添加了马氏距离度量项,训练损失下降较慢,其最终训练损失值较一般自编码器稍大。随后,分别使用两个自编码器构建如图3 所示的自编码神经网络,通过未确定数据进行有监督的微调以完成整个自编码神经网络的训练。仍然采用5 折交叉验证方式进行4.4 节中描述的测试实验,测试实验结果如表10 所示,可知改进自编码器组成的自编码神经网络具有更好的异常检测效果,说明改进自编码器对于网络流量数据具有更好的特征学习能力,能够获得更佳的隐层,有利于自编码神经网络的网络流量异常检测。
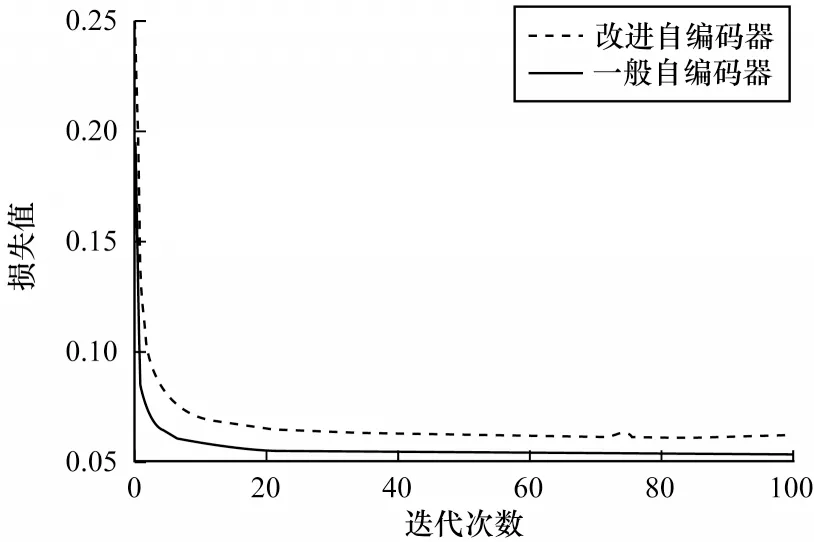
图12 自编码器训练损失比较Fig.12 Comparison of autoencoder training loss

表10 两个自编码器测试实验结果对比Table 10 Comparison of test experiment results of two autoencoders
5.2 一般自编码神经网络与改进自编码神经网络的对比
为观察调整自编码神经网络的交叉熵损失函数中各项权重对自编码神经网络训练及异常检测效果的影响,本实验使用4.2 节中训练完成的改进自编码器构建如图3 所示的自编码神经网络,其代价函数为普通交叉熵损失函数如式(13)所示,记为一般自编码神经网络。使用带标签的未确定数据对一般自编码神经网络进行训练,与4.3 节中构建并训练的改进自编码神经网络进行对比,两个自编码神经网络除代价函数外,参数及结构与4.3节中构建的改进自编码神经网络完全相同。
两个自编码神经网络的训练次数均为100,单次训练所选样本数均为1 000,两个自编码神经网络的训练损失对比如图13 所示。可知改进自编码神经网络收敛速度更快、训练损失更小,具有更好的收敛性。
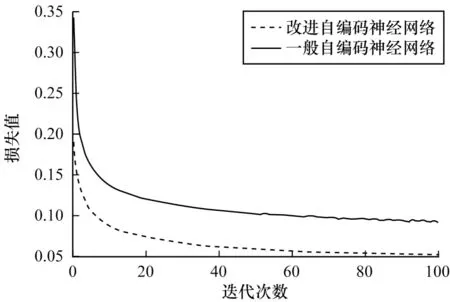
图13 自编码神经网络训练损失比较Fig.13 Comparison of autoencoder neural network training loss
两个自编码神经网络完成训练后,按照5 折交叉验证方式进行4.4节中描述的测试实验,实验结果如表11所示。可知通过调整交叉熵损失函数中各项权重,对于数据分布不均衡的CICIDS2017 数据集,改进自编码神经网络具有更好的训练效果,能够提高其网络异常检测效果。

表11 两个自编码神经网络测试实验结果对比Table 11 Comparison of test experiment results of two AE neural networks
5.3 与其他网络流量异常检测方法的对比
为进一步验证本文所提网络流量异常检测方法的效果,在CICIDS2017 数据集上将本文所提方法与其他网络流量异常检测方法和成果进行对比。同样采用5 折交叉验证方式进行实验,对比的方法包括DNN[1]、LSTM[21]、C-LSTM[21]、CWGAN-CSSAE[22]、GA-CNN[23]、CVAE[22]、IPC[24]等。实验结果如表12所示。
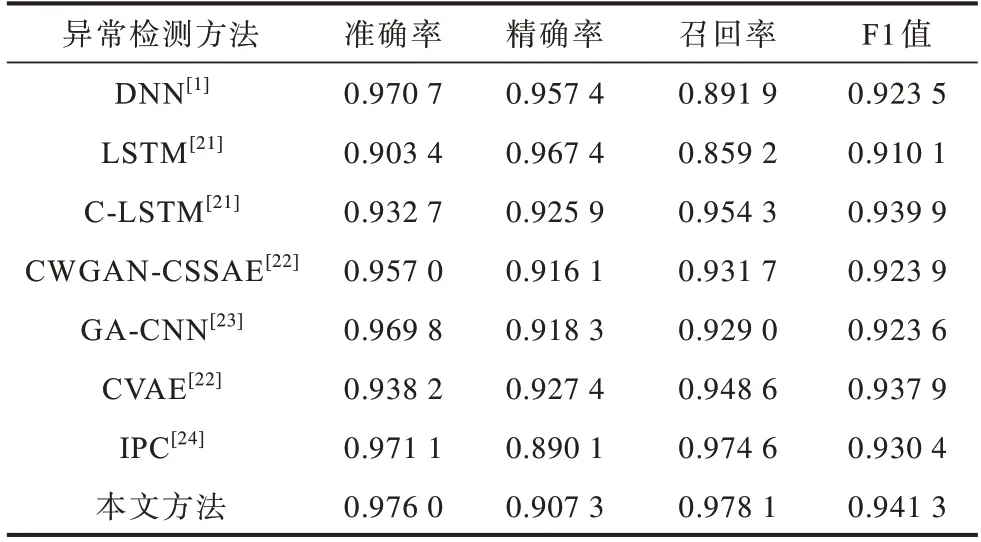
表12 与其他网络流量异常检测方法的对比Table 12 Comparison with other network traffic anomally detection methods
由表12 可知,本文所提方法在对网络流量异常检测的效果上优于其他方法。
文献[24]同样使用马氏距离代替传统的欧式距离,提出了一种基于马氏距离的增量可能聚类算法来检测异常网络流量,该算法逐渐选择离群点作为新的聚类中心并合并重叠的聚类中心,将不属于任何正常模型的数据视为异常数据,也证明了马氏距离较欧式距离的优越性。其虽然取得了不错的异常检测效果,但不适合实时的网络流量数据,是一种无监督的算法,需要将整个数据集作为输入,且分类效率较低,无法对单一网络流量数据做出判别。
5.4 NSL-KDD 数据集上的实验
为观察本文所提方法的泛化能力,使用同样被广泛应用于网络异常检测和分类研究中的NSL-KDD数据集进行实验。本实验仍然采用5 折交叉验证方式进行第4 节所述的实验过程。实验中训练数据的马氏距离倒数及判别阈值T如图14 所示,其中判别阈值T的值为0.6。训练数据共100 778 条数据,通过马氏距离倒数及判别阈值快速判别出15 509 条正常数据,占总数据量的15.39%。
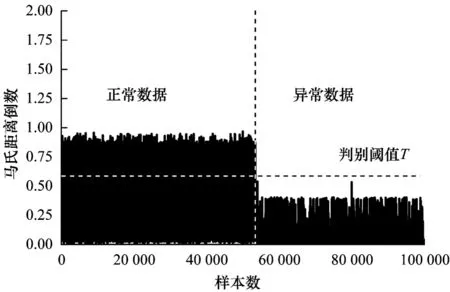
图14 NSL-KDD 训练数据集的马氏距离倒数分布及判别阈值Fig.14 Inverse Mahalanobis distrance distance and discrimination threshold of NSL-KDD training data set
构建改进自编码器和改进自编码神经网络,测试实验结果如表13 所示。由表13 可知,本文所提异常检测方法在NSL-KDD 数据集上仍然具有优秀的异常检测效果,对网络流量数据具有一定泛化能力。

表13 NSL-KDD 数据集测试实验结果Table 13 Results of the test experiment under NSL-KDD data set
6 结束语
本文从网络流量数据特征间具有相关性及数据量大的特点出发,提出一种结合马氏距离和自编码器的检测方法。通过马氏距离倒数及判别阈值快速检测出部分正常数据,减少自编码器和分类网络的训练数据量。将自编码器和Sigmoid 分类器相结合,以避免网络陷入局部最优。在自编码器代价函数中添加马氏距离度量项,增强自编码器对网络流量数据的特征学习能力。调整自编码神经网络交叉熵损失函数中各项的权重,从而提高自编码神经网络的训练效果。实验结果表明,本文方法具有一定泛化能力,且对网络流量具有较好的异常检测效果。
猜你喜欢
淮阴师范学院学报(自然科学版)(2022年3期)2022-09-22
网络安全与数据管理(2022年1期)2022-08-29
舰船科学技术(2022年10期)2022-06-17
科学技术创新(2021年5期)2021-03-17
——编码器
演艺科技(2020年7期)2020-08-13
微型电脑应用(2019年8期)2019-08-22
名作欣赏(2017年32期)2017-11-28
北京航空航天大学学报(2017年7期)2017-11-24
小小说月刊·下半月(2016年7期)2016-05-14
探测与控制学报(2015年4期)2015-12-15
