
基于生成对抗网络的知识蒸馏数据增强
2022-04-18 10:56鲁统伟徐子昕
计算机工程 2022年4期
鲁统伟,徐子昕,闵 锋
(1.武汉工程大学 计算机科学与工程学院,武汉 430205;2.智能机器人湖北省重点实验室,武汉 430205)
0 概述
随着深度卷积神经网络(Deep Convolutional Neural Network,DCNN)[1-2]的不断改进和发展,其在图像分类[3-5]、目标检测[6-7]、语义分割[8-9]、视频分析[10-11]等计算机视觉任务中得到广泛应用并取得重要研究成果。为进一步提高DCNN 分类器训练效果,研究人员提出了数据增强[12]、正则化[13-14]等一系列方法,并且设计区域丢弃算法(dropout),将dropout 用于删除隐藏的激活层,防止卷积神经网络(Convolutional Neural Network,CNN)过于关注图像中某块的小区域特征。dropout 算法还可以直接应用在输入数据样本中,通过随机丢弃部分像素区域得到新样本,现已被证明可使模型注意力不局限于样本的局部区域,更好地学习样本特征的整体分布,提高分类器的训练准确率[15]。由于dropout 算法去除的区域通常被简单地归零或填充随机噪声,因此对于小尺寸的图像,减少了训练图像上特征像素的比例,不利于进一步分类与定位。在基于工业视觉的语义分割任务中,直接采用dropout 算法会产生两方面的问题。一方面,由于工业零部件正负样本区别小,在人工标注时会产生错误标签,因此直接采用dropout 算法会忽略错误标签对模型的误导[16-17]。另一方面,工业零部件的训练集样本具有重复性与相似性[18],现有的填充策略和图像融合策略会引入非信息噪声,降低样本信噪比[19-20]。
DEVRIES 等[21]提出Cutout 数据增强算法,对原样本图像使用掩模遮挡一个矩形区域以得到新样本图像,新样本图像标签采用原始标签。YUN 等[22]在此基础上提出CutMix 数据增强算法。该算法与Cutout 算法相似,不同之处在于CutMix 使用其他样本的随机区域进行填充,并先分别按照两个样本的原始标签进行损失计算,再将两者求和得到最终损失值。这两种数据增强方法在提高分类器训练效率上取得了较好的结果,但仅对原标签做简单的线性变化或直接使用原标签作为新样本标签的方法是无法表示标签中离散信息的,这会导致网络模型无法将离散信息也作为一种特征进行学习。为解决上述问题,本文提出一种基于生成对抗网络(Generation Adversarial Network,GAN)的知识蒸馏数据增强方法。对区域丢弃算法中的丢弃运算进行改进,在生成对抗网络[23]的基础上,对其生成器和判别器结构进行优化,设计一种补丁生成网络。补丁生成网络通过学习原样本的像素分布生成填充补丁,以减少随机噪声。同时,在区域丢弃算法中引入基于知识蒸馏的标签生成算法,通过教师网络获得Soft-lable并辅助学生网络进行训练[24]。Soft-lable 比普通的One-Hot 标签具有更高的信息熵,能有效辅助学生网络学习不同类别间的类间差距,减少错误标签对模型的影响,提高分类器的精度。
1 区域丢弃算法
区域丢弃算法作为一种正则化方法被广泛应用于防止神经网络过拟合,通过在网络的前向传播过程中按照一定比例舍弃节点的激活值的方式增强网络分类器的训练效率。与全连接层相比,区域丢弃算法在卷积层中的效果较差,这是由于卷积层使用了卷积核,使得卷积层的参数量远少于全连接层,因此在解空间中对正则化的要求更少,并且在卷积层中特征图的相邻像素信息相似,舍弃掉的像素信息又存在于其他的像素中,继续向后传递。
为提高区域丢弃策略在卷积层中的正则化效果,将卷积层中的丢弃操作设置到输入层。通过直接移除输入图像的连续区域迫使网络去学习全局信息,而不仅关注于局部区域。在许多视觉任务中常常存在目标物体被遮挡的情况,区域丢弃算法也可以看作是对遮挡的模拟,定义如下:

其中:x∈RW×H×C表示原始样本,W表示原始图像的宽度、H为图像高度、C为图像通道数;表示生成的新样本,采用原始样本标签y作为新样本的标签;M∈{0,1}W×H表示一个尺寸为ssize×ssize的矩形二值掩模。掩模M的中心位置是随机生成的,像素坐标(x,y)范围如式(2)所示:
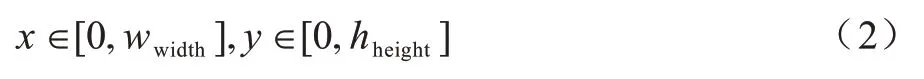
其中:wwidth表示图像宽度;hheight表示图像高度。
掩模左上角(x1,y1)、左下角(x1,y2)、右上角(x2,y1)、右下角(x2,y2)这4 个角点坐标与中心坐标的关系如式(3)所示:
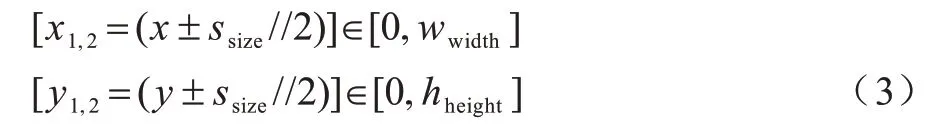
对分类任务常用的CIFAR-10 数据集使用区域丢弃算法后的样本效果见图1。

图1 区域丢弃后的CIFAR-10 数据集样本Fig.1 CIFAR-10 dataset sample after dropout
区域丢弃算法虽然能通过单样本进行数据增强,并提高网络训练效率,但是直接应用于工业摄像机获取到的工业数据集还存在如下问题:1)在使用二值掩模对原样本进行遮挡时,会引入二值噪声,需要对所有样本的所有像素值进行归一化操作,这会增加额外的计算量;2)使用原样本的标签进行网络损失计算,这对于图像分类任务和语义分割任务都是不合适的,在图像分类任务中每张图像仅对应一个标签,原标签无法体现出不同类别之间的差异信息,在语义分割任务中每一个像素点都对应一个One-Hot 标签,丢弃的像素点被二值填充,此时仍采用像素点的原始标签是不合理的。针对以上问题,本文对区域丢弃算法在标签生成方式上进行改进和优化。
2 基于GAN 的知识蒸馏数据增强算法
本文主要从非监督单样本数据增强方式和新标签生成方式2 个方面对区域丢弃算法进行改进。
2.1 改进的数据增强算法
为进一步提高数据增强算法的生成样本质量,引入补丁填充算法。补丁填充算法被使用在CutMix算法中,能减少丢弃像素导致的信息缺失、训练困难问题。受补丁填充算法的启发,构造一种补丁生成网络,并将其应用在区域丢弃算法中。
补丁生成网络整体采用常规GAN 模型中的生成器-判别器结构作为网络骨架,受到PATHK 等[25-26]在图像修复任务中的启发,本文算法将生成器G 设计为一个编码器-解码器(Encoder-Decoder)结构。对于生成器G 输入一张512×512 大小的三通道图片,设置区域丢弃使用的掩模尺寸为128×128,即生成器需要生成一个128×128 大小的补丁。输入图片经过4 次卷积池化下采样为32×32 大小的512 维特征,再经过2 次上采样(UpSampling)恢复尺寸得到最终的三通道128×128 的填充补丁。补丁生成网络生成器G 和常规GAN 生成器G 结构见图2。
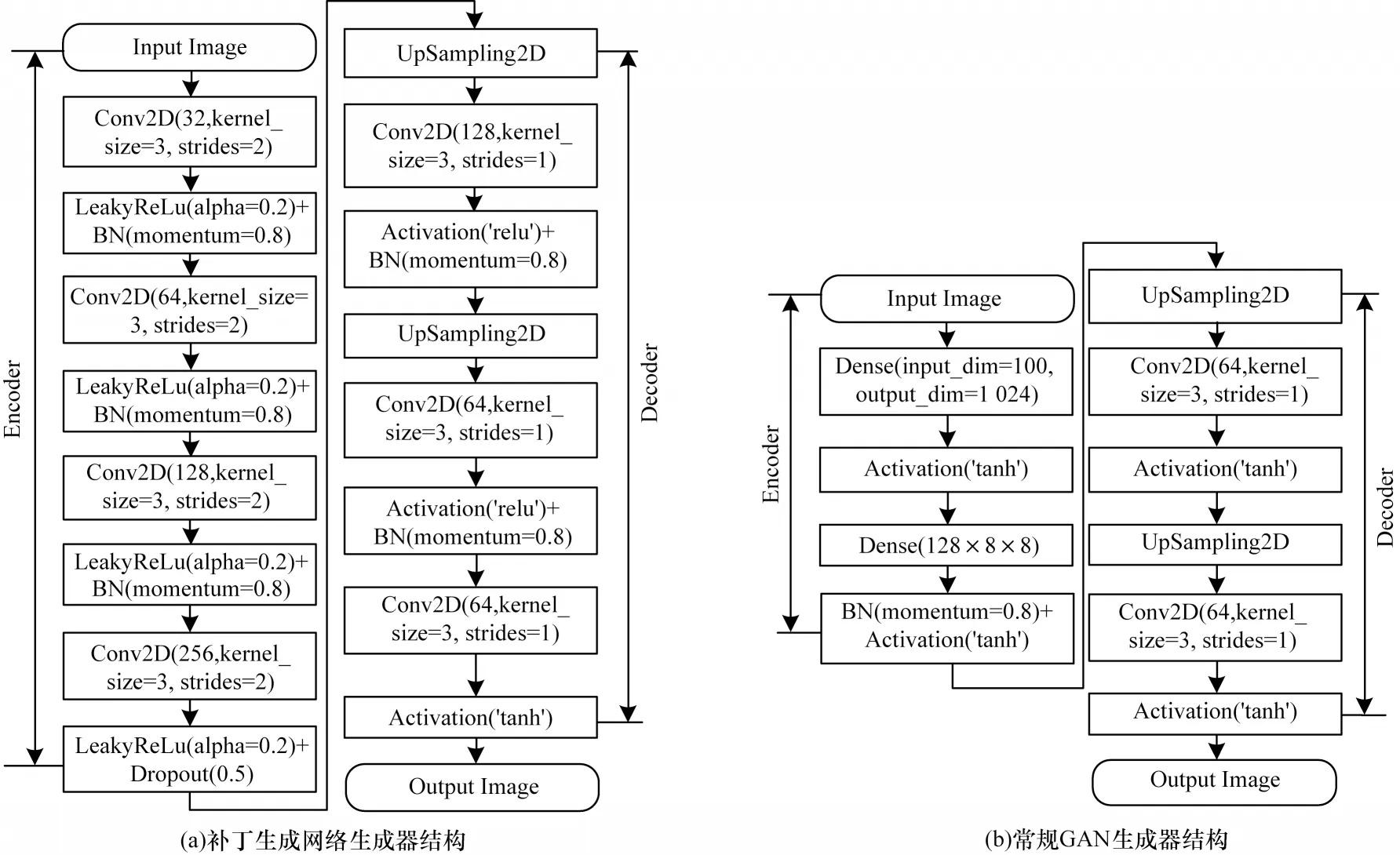
图2 补丁生成网络生成器与常规GAN 生成器结构Fig.2 Structure of patch generation network generator and conventional GAN generator
从图2 可以看出,与常规GAN 生成器相比,补丁生成网络将编码器中的全连接层替换为卷积层,在解码器中增加了上采样层以控制最终获得的补丁尺寸。同时,在激活函数选择上,改用系数为0.2 的LeakyReLu 激活函数替代tanh 激活函数,以防止在训练过程中的梯度震荡问题。
在生成器中的编码器Encoder 设计为一个典型的卷积结构,共使用4 层卷积层,这4 个卷积层分别使用32 个步长为2 的3×3 卷积核、64 个步长为2 的3×3 卷积核、128 个步长为2 的3×3 卷积核和512 个步长为2 的1×1 卷积核。输入图像经过4 次卷积层后,特征图的尺寸缩小为原图的1/16。生成器中的解码器Decoder 通过两次上采样恢复特征图尺寸。在上采样的具体实现中,直接采用反卷积(Deconv)层虽然更简单,但其存在棋盘效应,必须人为设计卷积核尺寸才能整除步长。为了减少网络设计的难度,通过2 次叠加使用上采样层和卷积层实现上采样操作。第1 次使用上采样层与128 个步长为1 的3×3 卷积层将32×32×512 的特征图扩大为64×64×128,第2 次使用上采样层与64 个步长为1 的3×3 卷积层将64×64×128 的特征图继续扩大为128×128×64,之后通过一个卷积层将特征图的尺寸调整为128×128×3。仅进行两次上采样操作的原因为:与常规GAN 的解码器需要将特征图尺寸还原到原图大小不同,补丁生成网络仅需要将特征图尺寸还原到与补丁相同的大小(原图大小的1/4)。
在判别器的设计上,常规GAN 判别器结构与补丁生成网络判别器结构见图3。
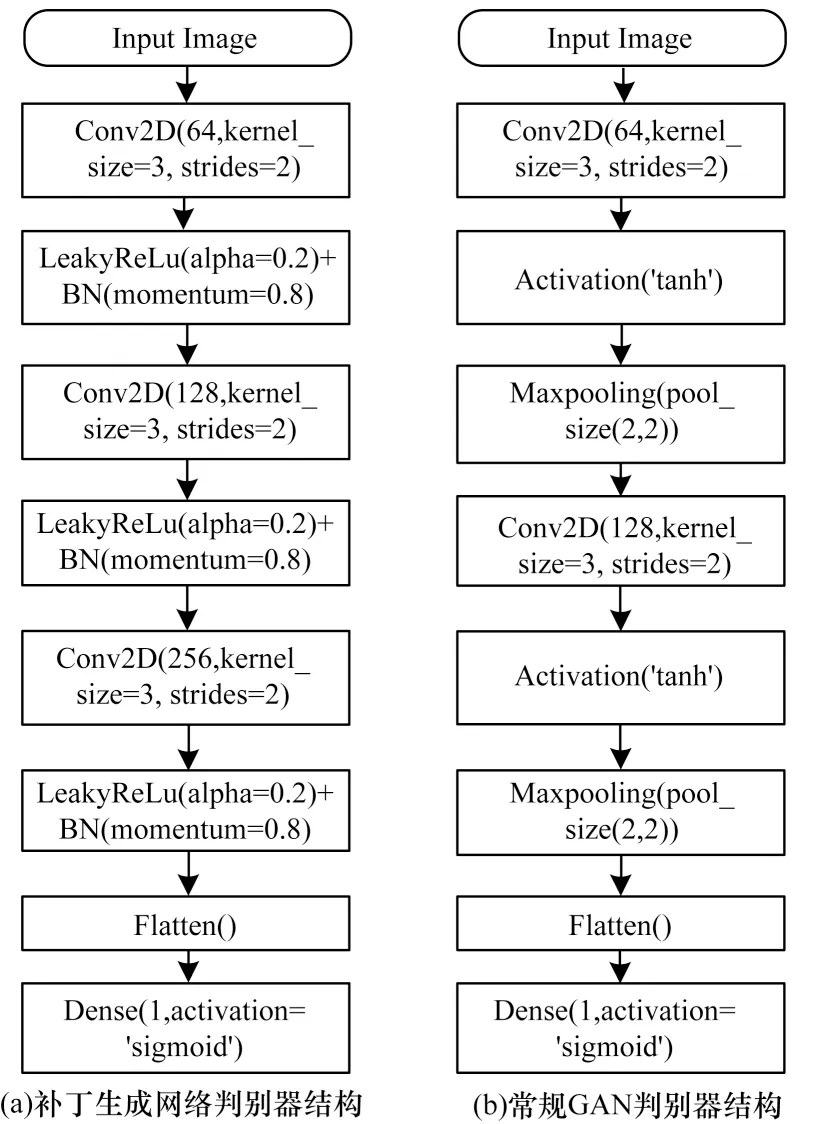
图3 补丁生成网络判别器与常规GAN 判别器结构Fig.3 Structure of patch generation network discriminator and conventional GAN discriminator
从图3 可以看出,补丁生成网络判别器的设计参考常规GAN 判别器的结构,但在卷积层后没有再使用最大池化层,而是将这些信息最后直接平化(Flatten)输入到全连接层中。在经过激活函数后,补丁生成网络判别器还加入了BN 层加快收敛速度。
判别器的输入为生成器生成的128×128×3 尺寸的补丁,经过3 个卷积层和1 个平化层,最后输出1 个一维概率值。3 个卷积层分别使用64 个步长为2 的3×3卷积核、128 个步长为2 的3×3 卷积核和256 个步长为1 的3×3 卷积核。加入平化层是将32×32×256 的特征一维化成26 244个一维向量,使卷积层与全连接(Dense)层进行过度。最终通过sigmoid 激活函数输出一个表示该补丁是否为真的一维概率值。
基于生成对抗网络的补丁填充算法定义如下:

其中:X表示新样本;新样本的标签Y先使用原始样本标签y,本节仅讨论图像的非监督数据增强变化规则,在下节中将会对样本标签的生成方式进行详细讨论;M∈{0,1}W×H表示区域丢弃算法中使用的二值掩模;E(M·x)表示将区域丢弃样本作为编码器的输入;D(E(M·x))表示解码器生成的填充补丁。
对图像分类数据集和语义分割数据集分别使用补丁填充算法后的样本效果见图4。考虑到生成像素分布完全拟合的样本需要大量的时间,为方便讨论,本文设置epoch 为1 000,batch_size 大小为8 以提高补丁生成效率。从图4(a)、图4(b)、图4(c)和图4(d)中可以看出补丁像素会随着迭代次数的增加,逐渐接近原样本像素分布。同时,本文算法生成的补丁并非仅还原原样本图,而是与原样本的低尺度图像像素分布接近,这样在一个mini-batch 中还能够增加多尺度信息。但在CIFAR-10 数据集中,考虑到样本尺寸过小,生成低尺度图像意义不大,本文将补丁的拟合对象调整为全局图像,见图4(e)。

图4 填充补丁后的图像样本Fig.4 Image sample after padding patch
2.2 改进的标签生成算法
知识蒸馏是一种模型压缩方法,目的是将知识从性能好、参数量大的高精度网络转移到易于部署、参数量小的模型中。这种训练模式也被称为教师-学生模式。教师模型是由一个或者多个网络组成的复杂模型,学生模型是一个网络结构简单、易于调整参数的模型。教师模型在训练中给予学生模型的指导称为知识,知识的定义如下:

其中:j表示样本集合;z表示教师模型最后一层的输出;T表示蒸馏所采取的温度,同时反映了标签的软化程度,在知识蒸馏过程中取T为1。
引入知识蒸馏算法生成数据增强样本的标签,将其与标签平滑方法相融合,提出一种基于知识蒸馏的标签生成算法。基于知识蒸馏的标签生成算法流程见图5。

图5 基于知识蒸馏的标签生成算法流程Fig.5 Procedure of label generation algorithm based on knowledge distillation
改进的基于知识蒸馏的标签生成算法引入了标签融合模块,见图5 中的虚线框。将教师网络训练学习到的知识通过与真实标签混合的方式传递给学生网络,设教师网络由N个复杂CNN 组成,则传递的知识共有N个。相较于直接使用未采取知识蒸馏的One-Hot 离散标签,使用经过蒸馏的知识对学生网络进行训练可以学习到不同类别间的相似度信息,从而提高分类与分割任务的精度。同时,在语义分割数据集的数据清洗过程中,通常发现人工标定错误的样本,通过标签混合的方式也能减少错误的标签信息所占的权重比例,降低训练过程中错误标签对模型产生的误导。
基于知识蒸馏的标签生成算法定义如下:

其中:生成的标签L由Ltrue与Lsoft按比例混合得到,Ltrue表示人工标注的真实标签,Lsoft表示通过教师网络获取到的知识,为保证Ltrue真实标签的所占比例更高,两者按照Beta 分布取值,约束两者之和为1;α与β表示混合系数,取α为0.3、β为0.7;pi表示教师网络对第i个样本的预测值;N表示样本数量。
3 实验结果与分析
3.1 数据集
为验证本文数据增强算法和标签生成算法的有效性,分别在图像分类和语义分割两个任务上进行实验。对于图像分类任务采用CIFAR-10 和CIFAR-100 数据集[27]。CIFAR-10 数据集是一个被图像分类任务广泛使用的数据集,包含10 个类别的32×32 大小的三通道RGB 图像,每个类别包括50 000 张训练样本和10 000 张测试样本,部分样本见图6。

图6 CIFAR-10 数据集部分样本Fig.6 Partial sample of CIFAR-10 dataset
CIFAR-100 数据集是在CIFAR-10 数据集的基础上进行扩充得到,包含20 个父类(superclass),每个父类又包含5 个子类(classes),即100 个类别的32×32 大小的三通道RGB 图像,其中每个子类包含500 个训练样本和100 个测试样本。CIFAR-10 和CIFAR-100 数据集的每个样本按照固定的命名格式进行命名,每张图像的标签为其名字的首个数字,例如样本名“2_403.jpg”表示样本的标签为2。
由于目前没有用于语义分割的工业数据集,因此语义分割任务采用汽车转向器轴承数据集,该数据集由轴承装配线上的工业相机拍摄得到,共2 020张样本图像,训练集共1 212 张样本图像,测试集和验证集分别为404 张样本图像。汽车转向器轴承数据集中正负样本的4 种不同位姿见图7,凹槽用圆圈标出,非凹槽用矩形标出。汽车转向器分为内侧与外侧,当且仅当内侧与外侧均为凹槽时才是正样本,见图7(a),其余位姿均为负样本见图7(b)、图7(c)和图7(d)。该数据集包括正样本和负样本2 个类别,其中负样本存在3 种位姿,正样本存在1 种位姿。

图7 汽车转向器轴承数据集样本Fig.7 Sample of automobile steering gear bearing dataset
汽车转向器轴承数据集全部由手工标注,数据集标注示例见图8(a),示例图像对应的json 文件见图8(b),其中,label 表示标签名,points 表示识别目标的像素点坐标。

图8 数据集标注示例Fig.8 Example of dataset annotation
3.2 评价指标
通过以下指标[28]评价基于生成对抗网络的知识蒸馏数据增强算法的性能:
1)最低k错误率(Top-kError)。Top-kError 表示对每一类最终预测结果中最大的k个值不包含真实标签的概率。Top-kError 越小表示分类精度越高。
2)特征曲线下面积(Area Under the Receiver Operating Characteristic,AUROC)。AUROC 表示模型随机预测到的正样本次数比负样本次数多时的数学期望,其大小为以假正例率(False Positive Rate,FPR)为横坐标、真正例率(True Positive Rate,TPR)为纵坐标的ROC 曲线下的面积。TPR 与FPR 计算公式如式(7)所示:

其中:TTP表示预测为正样本、实际为正样本的样本个数;FFN表示预测为负样本、实际为正样本的样本个数;TTN表示预测为负样本、实际为负样本的样本个数;FFP表示预测为正样本、实际为负样本的样本个数。在实际统计中,TTP、FFN、TTN和FFP均由混淆矩阵获得。AUROC 越大表示分类器的精度越高,效果越好。
3)平均交并比(mean Intersection over Union,mIoU)。mIoU 表示预测值与真实值的平均交并比。mIoU 越大,表示两者重叠越多,分割精度越高,计算公式如式(8)所示:
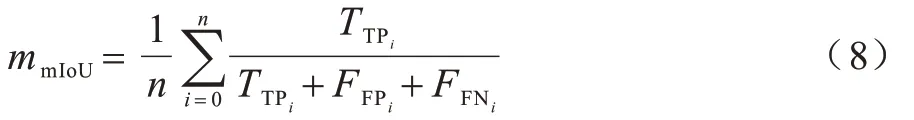
其中:n表示测试样本数;设第i个样本的预测像素点连通域为Pi、真实标签像素连通域为Ti,表示Pi⊆Ti时的Pi均表示Pi为非Ti子集时预测面积与真实标签的非重合面积。
虽然mIoU 是像素级别的评估标准,但是在实际检测任务中可能存在mIoU 值大,但分割不准确的情况,见图9,彩色效果见《计算机工程》官网HTML 版。在图9 中,background 为模型预测存在凹槽的区域,target 为真实标签区域。对于测试样本2,虽然模型对所有凹槽预测正确,但预测区域面积远大于真实标签面积。对于测试样本3,虽然仅预测出一个凹槽,但预测错误的像素面积极小。然而,测试样本3的mIoU 甚至比测试样本2 的mIoU 更大,这对于检测任务显然是不合理的。

图9 语义分割示意图Fig.9 Schematic diagram of semantic segmentation
为更直观地分析模型检测效果,针对图像级别的转向器凹槽识别任务对式(8)进行修改,得到适用于本文任务的凹槽识别率评估指标。凹槽识别率定义如式(9)所示:
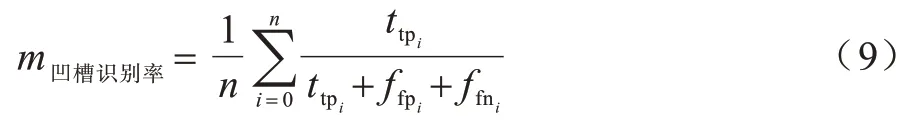
设第i个样本实际凹槽连通域像素点集为Ti,i∈(1,2,…,n),模型预测的像素连通域点集为Pi。当Pi⊆Ti时,预测凹槽区域正确增加1。当Pi的部分像素属于Ti的非真子集时,代表部分凹槽预测正确也增加1。当Pi为非Ti子集时,代表预测区域全部为非凹槽区域,预测全部错误增加1。
3.3 结果分析
在PyCharm 中编程实现本文算法,编程语言为Python3.6.10,深度学习框架为PyTorch1.0.0,实验硬件平台包括Intel®CoreTMi7-7700HQ CPU@ 2.80 GHz处理器,以及GeForce GTX 1070 GPU 用于加速模型训练。
在教师模型Net-T 的选择上,仅使用一个网络模型作为教师模型Net-T。学生模型Net-S 使用与教师模型相同的数据集训练,采用五折交叉检验方式来训练教师模型Net-T。将数据集随机分为等量的5 份,其中,4 份作为训练集,1 份作为测试集,重复5 次上述过程训练得到教师模型。这样的目的是促使模型从多方面学习样本,避免得到局部最优值。将Net-T 每次对数据集的Softmax 预测值作为知识蒸馏得到的软标签(Soft-label),将软标签与真实标签(True-label)进行混合获得训练学生模型Net-S 使用的标签。生成的软标签保存至csv 文件中,部分CIFAR-10 数据集软标签csv 文件见图10。

图10 教师网络生成的软标签Fig.10 Soft-label generated by Net-T
从图10 可以看出,软标签学习到离散标签所没有体现的类间距离信息。例如,在图10 中image_id为Train_0_0 的样本,该样本在轿车(automobile)上的最大预测值为0.515,在卡车(truck)上的第二大预测值为0.288,说明该样本最有可能为轿车,同时该样本与卡车的特征最接近。可见,通过知识蒸馏可以为学生网络Net-S 提供原标签中所没有的知识。
学生模型在训练中不对数据集划分,直接使用完整的数据集训练。教师网络训练流程见图11。

图11 教师网络训练流程Fig.11 Procedure of Net-T training
设置mini-batch 为32,max_iter 为1 000,训练周期(epoch)为350。为系统地评估本文算法,使ImageNet2017 分类竞赛中的最佳网络SE-ResNet50作为骨架网络,该网络模型具有25M 的参数量,采用交叉熵函数作为损失函数。
为防止数据集在训练过程中存在过拟合现象,同时为减少模型训练中复杂的调参步骤,采用余弦退火和热重启[29]算法作为学习率调整算法,学习率计算公式如式(10)所示:
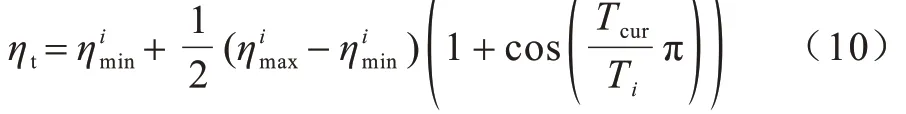
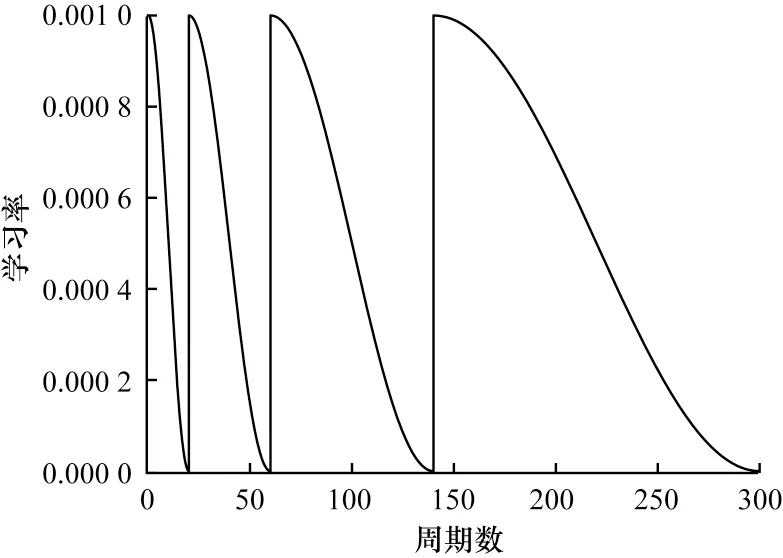
图12 学习率曲线Fig.12 Learning rate curve
3.3.1 本文算法与区域丢弃算法的对比
区域丢弃算法与本文算法在CIFAR-100 数据集上的损失对比见图13。从图13 可以看出,在训练初期采用本文算法的损失值会大于区域丢弃算法,这是因为在训练初期生成补丁的像素分布不能很好地与原数据集像素拟合。但随着迭代次数的增加,像素分布越来越接近真实分布,在训练结束时,采用本文算法能得到更低的损失值,并且能更快地达到收敛。总体而言,本文算法能在一定程度上提高网络的训练效率。
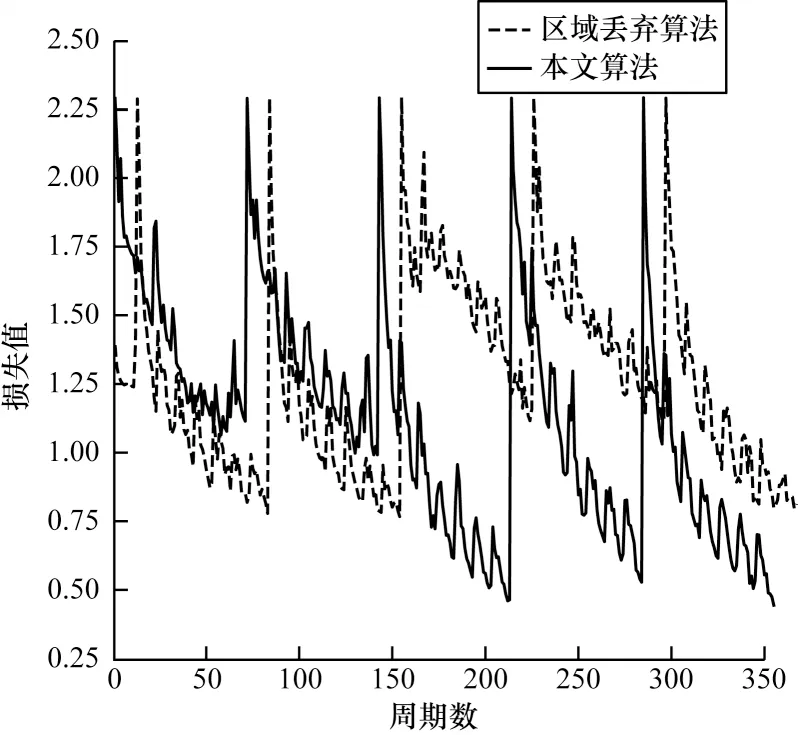
图13 区域丢弃算法与本文算法的损失对比Fig.13 Comparison of loss between dropout algorithm and the proposed algorithm
为更直观地对检测结果进行比较,图14 给出了采用3 种不同数据增强算法的热力图。从图14 可以看出,对于测试图片的凹槽检测,本文算法和区域丢弃算法均能正确识别内侧凹槽,但在识别准确率上,特别是对于汽车转向器轴承的外侧区域,仅使用原始数据集而未采用任何数据增强方式的检测效果最差,将转向器外侧凸起和其他区域均错误识别为凹槽。区域丢弃算法会受到背景的影响,将转向器其他区域也识别为凹槽。可见,本文算法的检测效果明显优于区域丢弃算法。

图14 语义分割热力图Fig.14 Semantic segmentation heatmap
3.3.2 本文算法与其他数据增强算法的对比
为进一步验证本文算法的有效性,将本文算法与Cutout 和CutMix 这两种数据增强算法进行比较,在CIFAR-100 数据集上的分类结果见表1。选择常用的Top-1 Err 和Top-5 Err 作为Top-kErr 评价标准,Top-1 Err 和Top-5 Err 越小代表分类效果越好。由表1 可以看出,无论采用何种算法,Top-1 Err 均比Top-5 Err 高约20 个百分点,这是因为预测概率最大的1 个结果即为真实标签的情况要少于预测最大的5 个结果中包含真实标签的情况。本文算法在CIFAR-100 数据集上取得了较好的分类效果,与Cutout 算法相比,Top-1 Err 降低了1 个 百分点,Top-5 Err 降低了0.4 个百分点。与CutMix 算法相比,Top-1 Err 虽然提高了1 个百分点,但Top-5 Err 降低了0.1 个百分点。
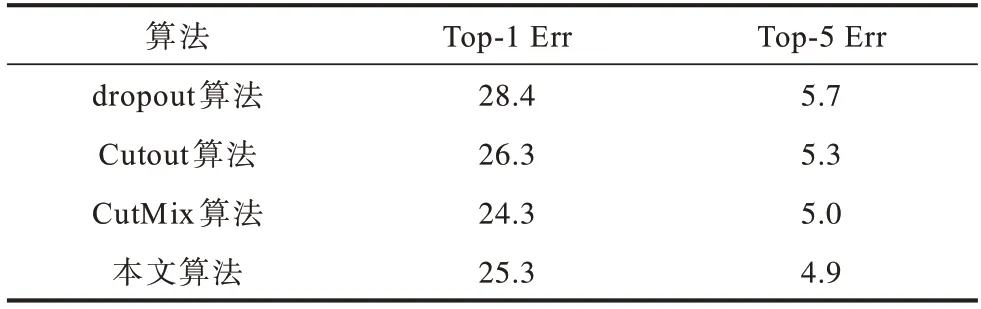
表1 在CIFAR-100 数据集上的分类结果比较Table 1 Comparison of classification results on the CIFAR-100 dataset %
在CIFRA-10 数据集上的分类结果见表2。从表2可以看出,本文算法在CIFAR-10 数据集上也具有一定的有效性,相较于dropout算法在Top-1 Err 和Top-5 Err上分别降低了0.5 和0.6 个百分点,相较于Cutout 算法在Top-1 Err 和Top-5 Err 上分别降 低了0.2 和0.5 个百分点,但与CutMix 算法相比,在Top-5 Err 上虽然降低了0.3 个百分点,但在Top-1 Err 上却增加了0.1 个百分点。
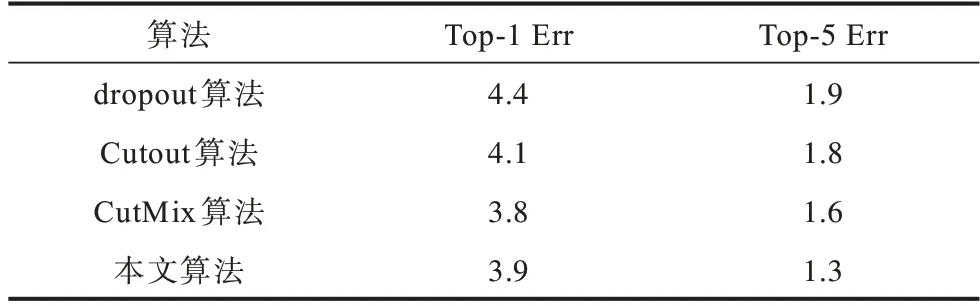
表2 在CIFAR-10 数据集上的分类结果比较Table 2 Comparison of classification results on the CIFAR-10 dataset %
导致CutMix 算法相较于本文算法在CIFAR-100和CIFAR-10 两个数据集上Top-1 Err 上更好的原因为:两个CIFAR 数据集的图像大小仅为32×32,图像特点为像素少而像素间包含的语义信息和特征信息多。本文算法不适用于此类特点的图像,因为通过拟合样本像素生成的“假”补丁所包含的特征信息远少于所丢弃的真实图像。CutMix 算法虽然丢弃了部分真实图像区域,但填充的补丁是数据集中其他样本图像的真实像素区域,避免了该问题。如果仅使用原样本标签,则生成的补丁与真实区域相比效果会略差。CutMix 算法与本文算法在汽车转向器轴承数据集样本上的应用效果见图15(a)~图15(c)。在CIFAR-10 数据集上,图15(d)中的真实补丁与图15(e)中本文算法生成的“假”补丁区别甚大,可以证实上述分析。

图15 填充补丁后的CutMix算法与本文算法样本应用效果对比Fig.15 Comparison of sample application effect of CutMix algorithm and the proposed algorithm after padding patch
除了在CIFAR-10 和CIFAR-100 两个数据集上,本文还在汽车转向器轴承数据集上进行数据增强算法性能对比,选用Google 提出的DeepLabv3+作为语义分割的骨架网络,该网络在多项指标中均获得最高分类精度[30],结果见表3。从表3 可以看出,本文算法在语义分割任务上具有较好的效果,相较于dropout、Cutout 或CutMix 算法在准确率 和mIoU 上均有一定的提升,相较于CutMix 算法在识别准确率和mIoU 上均提升了0.4 个百分点。这是因为在语义分割任务中,网络模型的预测是像素级别的,CIFAR-10与CIFAR-100 数据集中包含32×32 大小的图像,而汽车转向器轴承数据集中包含512×512 大小的图像,在分类数据集中生成的补丁像素对总像素的像素分布影响更大,所以在分类任务中本文算法较CutMix 算法的性能优势并不明显,但在语义分割任务中本文算法性能更优。
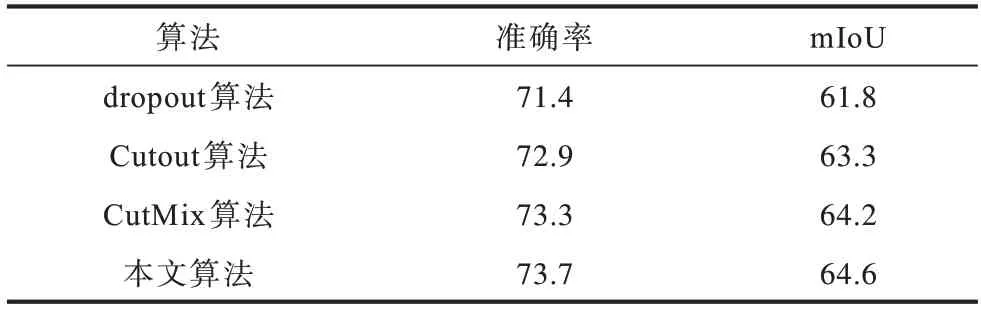
表3 在汽车转向器轴承数据集上的语义分割结果Table 3 Semantic segmentation results on the automobile steering gear bearing dataset %
3.3.3 消融实验结果与分析
为验证标签生成算法能提升数据增强算法在图像分类与语义分割任务中的精度,设置消融实验。将算法分为3 组进行训练:第1 组为原始区域丢弃算法;第2 组为将数据增强算法改为本文提出的基于生成对抗网络的数据增强算法;第3 组在第2 组的基础上增加了基于知识蒸馏的标签生成算法。在CIFAR-100 数据集上的消融实验结果见表4,其中,“√”表示包括该算法,“×”表示未包括该算法。从表4 可以看出:对于第1 组实验,仅使用原始CIFAR-100 数据,Top-1 Err 和Top-5 Err 分别为28.4% 和5.7%;对于第2 组实验,仅采用基于生成对抗网络的数据增强算法,Top-1 Err 和Top-5 Err 相较于第1 组实验提升了1.9 和0.5 个百分点,原因是补丁尺寸占整个像素面积过大,反而会降低信噪比;对于第3 组实验,同时使用本文提出的两种算法时却能提高准确率,Top-1 Err 和Top-5 Err 相较于第1 组实验分别降低了3.1 和0.8 个百分点,达到最优分类精度,这说明知识蒸馏提取到的Soft-label 对提高分类精度有一定的效果。

表4 在CIFAR-100 数据集上的消融实验结果Table 4 Ablation experimental results on CIFAR-100 dataset
在CIFAR-10 数据集上的消融实验结果见表5。从表5 可以看出:对于第1 组实验,仅使用原始CIFAR-10 数据,Top-1 Err 和Top-5 Err 分别为4.4%和1.9%;对于第2 组实验,与CIFAR-100 数据集实验结果类似,由于两个数据集样本尺寸一样,因此仅采用基于生成对抗网络的数据增强算法对Top-1 Err 和Top-5 Err 的提升效果不明显,甚至会降低准确率;对于第3 组实验,同时采用本文提出的两种算法相较于第1 组实验分别在Top-1 Err 和Top-5 Err 上降低了0.5 和0.6 个百分点,达到最优分类精度。
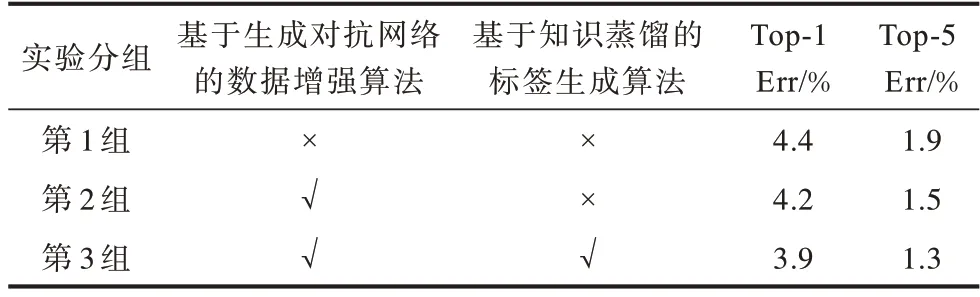
表5 在CIFAR-10 数据集上的消融实验结果Table 5 Ablation experimental results on CIFAR-10 dataset
针对表4 中的第2 组实验均会受到掩模尺寸影响,降低本文算法效果的问题,在CIFAR-100 数据集上分析丢弃区域所使用掩模M尺寸对实验结果的影响。使用与之前实验相同的基准网络与训练策略进行网络训练。评估掩模M的尺寸分别为0×0、4×4、8×8、16×16 时的Top-1 Err,其中0×0 表示直接采用原图训练,实验结果见图16。从图16 可以看出,选择掩模尺寸为4×4(即图像尺寸的1/8)时,Top-1 Err 取到最小值为25.5%,若继续扩大掩模尺寸为图像尺寸的1/4(即8×8)和1/2(即16×16)均会增加Top-1 Err,降低分类精度。这也证实了表4 中第2 组实验精度下降主要是由掩模尺寸导致。在后续实验的掩模尺寸上采用效果最好的4×4 掩模尺寸。

图16 掩模尺寸对Top-1 Err 的影响Fig.16 Influence of the size of the mask on Top-1 Err
通常而言,只要提供足够多的训练样本,神经网络的鲁棒性能就能得到极大提升,但当某个样本的特征在已知特征空间以外时,神经网络存在不能以较低的置信度表示没有学到的特征。为了验证本文算法与CutMix 和Cutout 两种数据增强算法的泛化性能,在OOD 样本[31]上对2 种数据增强算法与本文数据增强算法进行对比。使用CIFAR-100 预训练模型对CIFAR-100 数据集中的OOD 样本进行预测,通过预测结果来判断泛化性能。OOD 样本选取CIFAR-100 预训练模型预测的Top-1 Err 值与真实标签不同的样本。使用在CIFAR-100 上预训练的SE-ResNet50 模型,在1 000 个测试样本中选出283 个OOD 样本,然后分别采用基于CutMix 算法、Cutout算法和本文算法这3 种数据增强算法训练出的网络模型对283 个OOD 样本进行预测评估。网络模型采用与3.3 节中相同的网络模型训练参数和训练策略,预训练模型上的OOD 样本预测结果见表6。从表6可以看出,本文算法会受到样本尺寸的影响,AUROC 相较于CutMix 算法降低了0.9 个百分点,相较于Cutout 算法提高了1.3 个百分点。

表6 预训练模型上OOD 样本预测结果Table 6 OOD sample prediction results on the pre-trained model %
4 结束语
为解决图像分类任务中网络模型无法从离散的标签中学习到不同类别间的相似度信息以及工业视觉检测任务中存在正负样本难区分、样本量少等问题,本文改进区域丢弃算法,提出一种基于生成对抗网络的知识蒸馏数据增强算法,通过生成器-对抗器学习样本的像素分布,生成填充补丁,提高生成数据的信噪比。将知识蒸馏中的教师-学生模型应用到扩充样本的标签生成中,通过教师网络获得Soft-label对学生网络的训练进行指导,将离散的标签信息进行软化,使网络模型对样本的离散空间特征进行更充分的学习。实验结果表明,相较于区域丢弃算法,该算法在CIFAR-100 数据集和CIFAR-10 数据集的Top-1 Err上分别降低了3.1和0.5个百分点,在Top-5 Err上分别降低了0.8 和0.6 个百分点。在汽车转向器轴承数据集的语义分割任务中,相较于区域丢弃算法、CutMix 算法和Cutout 算法,该算法在mIoU 上分别提高了2.8、0.4 和1.3 个百分点,在识别准确率上分别提高了2.3、0.4 和0.8 个百分点。由于本文所选用数据集均来自理想光照环境,因此下一步将考虑光照变化等因素来改变数据生成方式,同时通过在原样本上增加滤波生成补丁等策略降低补丁生成耗时,提升数据生成质量和实时性。
猜你喜欢
诗选刊(2022年6期)2022-05-25
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
学与玩(2018年5期)2019-01-21
文苑(2018年18期)2018-11-08
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
CHIP新电脑(2016年3期)2016-03-10
中国诗歌(2015年12期)2015-11-17
Coco薇(2015年11期)2015-11-09
