
基于卷积网络加速器的FPGA数据处理研究
2022-04-18 10:00李政清穆继亮
计算机仿真 2022年3期
李政清,穆继亮
(1. 三亚学院理工学院,海南 三亚 570200;2. 中北大学仪器与电子学院,山西 太原 030000
1 引言
在机器视觉与人工智能的嵌入式应用场景中,需要完成大量的数据计算分析。对于复杂算法,采用CPU的实现方式普遍存在效率低下,实时性较差的缺点;采用CPU的实现的方式则会导致功耗和成本的增加。于是,越来越多的研究采取FPGA作为数据处理硬件加速器[1]。
由于卷积神经网络(CNN)在图像、语音识别方面表现出的良好学习特征,很多研究人员欲将其引入人工智能的嵌入式领域。CNN除了具有多层学习能力,还自带并发计算特征[2],恰好与FPGA的并发处理相互照应。同时,FPGA具有的可编程能力能够有效适应CNN的网络变化。但是,经典CNN的结构和参数过于复杂,对于资源受限的嵌入式系统而言,难以直接进行使用[3]。于是,一些学者致力于CNN与嵌入式系统的融合,从而提高嵌入式系统上的数据处理性能。文献[4]在CNN中采用了快速滤波来降低计算复杂度,同时设计了适用于FPGA的算法架构,从而获得较好的有效算力。文献[5]通过滑窗的并行来对卷积操作进行加速,并采取8bit的定点量化处理,从而减少FPGA资源消耗,并获取较高的处理精度。文献[6]基于CNN稀疏特征,将其转换成矩阵乘积处理,并在FPGA上进行实现,该方法实现简单,容易在嵌入式系统上移植。此外,文献[7]设计了VGG网络加速器,并且具备完整的卷积与连接过程;文献[8]设计了U-Net网络加速器,具备卷积与逆向卷积过程。
基于当前研究,本文设计了一种卷积网络加速器,通过对各层的优化来改善网络的收敛性和适应性,以及神经元增长对权值处理效率的影响。针对FPGA应用设计了相应的加速器实现架构,包括数据处理和缓存机制,并通过资源分析来调整网络架构。最后,利用与不同平台与不同加速器的比较,对基于卷积网络加速器的FPGA数据处理性能进行验证。
2 卷积网络加速器
2.1 CNN模型
CNN一般由卷积、池化,以及连接多个层构成,其模型描述如图1所示。对于任意输入,利用卷积层对其进行特征的分析提取。该过程中首先需要将特征图与卷积核相乘,再通过ReLU函数与卷积处理确定最终的特征图,采用ReLU函数有利于加速收敛,其表达式描述如下
ReLU:y=max(0,x)
(1)

图1 CNN模型
利用上层卷积处理输出下层特征图,同时卷积核对应变量就是计算权值,卷积过程描述如下
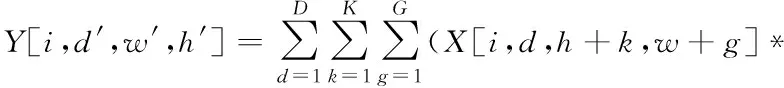
L[d,d,k,g])+P
(2)
其中,i代表上级特征图的层数;d′,w′,h′分别代表下级特征图对应的深度、宽度和高度;D代表上级特征图深度;K,G代表卷积核大小;P代表偏置。
池化层主要用于完成抽样处理,通常采取与卷积层交叉的方式。利用抽样处理,有利于提高网络的适应性。这里采取平均池化策略,公式描述如下
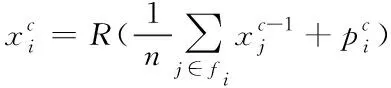
(3)

连接层位于网络输出侧,包含众多权值计算。在网络拓扑结构增加的情况下,由于层数与神经元数量的增加,将会使得权值数量急剧增长,进而严重影响数据处理效率。为降低权值数量,将特征图先与1×1卷积核进行运算,再依次与1×1、3×3卷积核进行运算。利用3×3卷积把特征图采取压缩,这样就能够在一个层中达到并行计算的目的。同时,池化层与连接层可以看作是特殊情况下的卷积层,可以采用同样的策略。
2.2 FPGA处理模块设计
处理模块的核心任务是卷积操作,并得到最终的特征图。由于特征图包含多个方向,且要在各个方向上采取并行计算,这就需要有多个处理模块共同参与。对于一个l×l大小的特征图,处理模块会将特征和权值派发给l×l个处理单元,最终处理模块将要进行m×l×l次乘加操作,其中m代表通道数量。
处理单元在接收到派发数据后,根据比较器的结果确定输入数据的有效性。同时局部计数器将对有效数据进行计数。然后判定器对有效数据的权值索引和计数等参数采取验证,充分保证权值与特征图的有效,其中索引被标记为log2m位宽定点数dl,l。对于比较器i的输出,判定器的验证过程可以表示如下
check=i&(dl,l>>count)
(4)
其中,count代表有效数据计数。
验证结果将会被传递至控制单元,进而控制验证通过的数据参与乘加操作。乘加操作涉及的计算量较大,交给FPGA的片上DSP处理,通过若干DSP并行的方式提高计算效率。DSP的使用情况可以采用以下公式进行估算:
RDSP=NDSP×NPU×l×l
(5)
其中,NDSP代表占用的DSP模块数量;NPU代表处理模块数量;l×l为计算单元数量。
2.3 FPGA缓存模块设计
在计算过程中,产生的与特征图与权值相关变量均采取BRAM缓存。对于并行变量,应该确保它们存放在不同的BRAM分区上。对于存储区域,应该从横向、纵向,以及深度方面分别采取分配。假定处理模块阵列描述为Pw×Ph×Pd,Pw,Ph,Pd分别表示在横向、纵向和深度方面的处理模块数量。在输入数据的横向上,处理模块将会得到Pw+l-1个变量及其相应的计算,根据变量与计算的数量,将数据分配至Pw+l-1个BRAM。同理,在纵向上分配Ph+l-1个BRAM,深度上分配NDSP个BRAM。输出数据在横向上分配Pw个BRAM;纵向上分配Ph个BRAM;深度上分配NPU个BRAM。权值在横向和纵向上均分配l个BRAM;输入深度上分配NDSP个BRAM;输出深度上分配NPU个BRAM。
除了缓存的分配,还应关注复用情况,良好的复用设计能够缓解数据交换过程中的资源损耗。处理单元每一轮分配的BRAM数量为RDSP,在本轮执行过后,如果将其间的变量保留下来,便可以在后续操作时快速获取参数值,并避免重复计算。尤其是当滑动窗口发生移动,可以直接从缓存得到所需变量。假定输入、输出和权值对应的复用系数分别为λ1,λ2,λ3,则BRAM的使用情况可以表示为
RBRAM=λ1((Pw+l-1)×(Ph+l-1)×NDSP)+
λ2(Pw×Ph×NPU)+λ3(l×l×NDSP×NPU)
(6)
3 FPGA资源分析
卷积网络加速器在对输入数据进行处理的过程中,可以采用并行方式进行操作。而FPGA在利用片上DSP实现卷积操作时,也可以采用并行方式实现网络计算。该过程中,计算并行程度受输出特征图影响,卷积核并行程度则受FPGA影响。由于卷积操作的所有乘法计算都是基于DSP的,因此在卷积核并行计算时,乘法器与DSP应该满足如下关系
CP×DP×Mi≤DSPtotal
(7)
其中,CP代表计算并行程度;DP代表卷积核并行程度;Mi代表处理i×i卷积时的乘法器数量;DSPtotal代表FPGA内部的DSP模块数量。
在基于卷积网络加速器的FPGA数据处理过程中,不仅是对DSP资源的占用,还有对存储资源的占用。BRAM需要完成特征图与中间结果的缓存,于是存储资源应该满足如下关系

(8)

在考虑资源占用的同时,还应该分析数据处理过程中FPGA的执行时间。在固定时钟周期Tclk情况下,数据输入的时间受特征图的大小、通道,以及硬件架构影响,公式表示为
Tin=Tclk×η1×win×hin×din
(9)
其中,η1代表传递效率。
权值变量受卷积操作影响,其时间表示为:
Tw=Tclk×j×j×DP×din
(10)
数据在卷积网络的中间计算时间除了与特征图大小有关外,主要受并行性能和计算效率影响,公式表示为

(11)
其中,η2代表计算效率;Nc代表卷积量。
结果输出时间与并行行性能有关,表示为

(12)
通过求解Tin,Tw,Tc,Tout的总和,便可以得到一层网络的执行时间,再根据网络层数,就可以计算得到FPGA的累计需要时间。
4 仿真与结果分析
4.1 仿真架构
实验平台选择Xinlinx VC709,其上搭载的是VC709 FPGA,实现环境是Xinlinx Vivado 2017。该FPGA的片上资源包括3600 DSP Slice,1470 BRAM,以及433200LUT。仿真数据集选择ImageNet,在初始化阶段,通过归一化操作将像素映射到[-1,1]范围内。卷积网络加速器阵列规模设置为128×16,特征图与权值在BRAM的缓冲深度均设置成2048。基于卷积网络加速器实现的FPGA数据处理架构如图2所示。

图2 FPGA数据处理架构
为了形成性能对比,分别选择一款CPU与GPU体系架构。CPU型号为Intel core i5 2500K,主频3.3GHz;GPU型号NVIDIA GeForce GTX 960。除了对体系结构进行比较外,还采用VGG[6]、U-Net[7]和HCNN[8]的方法,在相同的FPGA体系结构中进行性能的对比分析,同时,实验过程中将本文所提加速器标记为NCNN。
4.2 实验结果
通过测试得到基于卷积网络加速器的FPGA数据处理时的资源使用状况,如表1所示。该表描述了所提加速器在并行计算最优情况下时对FPGA各类资源的利用。DSP的利用率达到89.20%,DSP的主要功能是进行复杂的卷积计算,其利用率高说明了加速器能够有效利用DSP的计算性能,改善计算效率与并行性。此外,BRAM和LUT资源的利用率也比较理想,表明所提方案在FPGA资源利用方面的合理性。

表1 FPGA资源利用状况
表2描述了最优卷积网络加速器的分层框架与性能。可以看出,前三层操作数量与卷积核都在不断攀升,在第四层卷积操作达到峰值,对应的GOPS也较高。整体来看,整个网络的计算时间为15.406ms,GOPS为148.88。
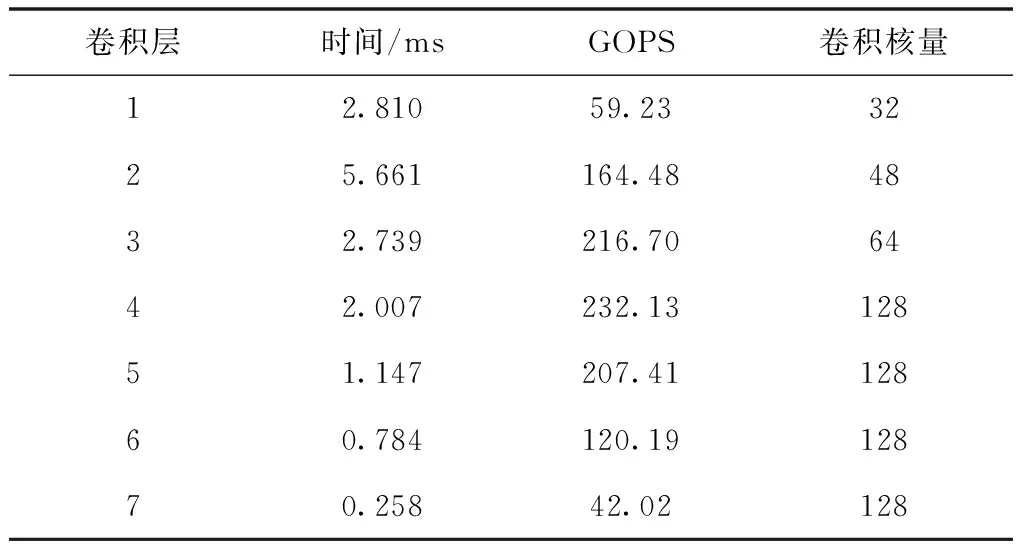
表2 最优卷积网络加速器的分层数据
基于不同的平台,得到各自对应的性能对比,结果如表3所示。经比较可知,在图像计算时间上,FPGA平台所需时间仅为GPU的15.7%,为CPU的5.0%。有效算力则是GPU的2.3倍,是的CPU的8.1倍。此外,功耗也有所降低,比GPU少37.9W,比CPU少57.69W。通过各项数据比较,所提加速器表现出明显的性能收益。

表3 不同平台性能比较
基于FPGA实验环境,测试不同加速器的帧速,结果如图3所示。经比较可以发现,在相同的时钟频率情况下,本文所提加速器的帧速明显高于对比方法,约为VGG的5.31倍,为U-Net的2.50倍,为HCNN的1.23倍。在推断加速的同时,其功耗也没有明显的增加,维持在较为良好的功耗状态。

图3 不同加速器的性能比较
基于FPGA实验环境,测试不同加速器的资源利用状况,结果如图4所示。通过结果比较可知,所提加速器对DSP与LUT资源的使用最多,这是因为加速器需要最大程度利用DSP资源来提高并行计算效率。对BRAM资源的使用则不是最高的,这是因为所提加速器为了提高数据利用率与查找效率,会对一些中间变量采取缓存,但是并没有对过多数据进行缓存,缓存数据过多将会导致存储效率和查找速度降低。
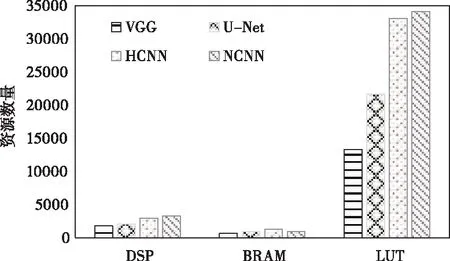
图4 不同加速器的资源比较
5 结束语
本文设计了一种能够在FPGA上运行的卷积网络加速器,用以提高FPGA在数据处理时的并行效率。方案对卷积网络采取优化加速,并基于加速器设计了FPGA的处理和缓存架构。通过与不同平台的对比实验,证明了所提方案可以有效利用FPGA资源,在处理时间、GOPS和功耗方面都优于GPU和CPU。另外,通过与不同方案的对比实验,证明了所提方案具有良好的加速性能与合理的资源利用率。
猜你喜欢
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
现代仪器与医疗(2022年3期)2022-08-12
心理学报(2022年4期)2022-04-12
科技创新导报(2021年33期)2021-04-17
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子技术与软件工程(2016年24期)2017-02-23
科技视界(2016年1期)2016-03-30
物联网技术(2015年7期)2015-07-21
