
UCTB:时空人群流动预测工具箱
2022-04-13 02:40:26陈李越王乐业
计算机与生活 2022年4期
陈李越,柴 迪,王乐业+
1.高可信软件技术教育部重点实验室(北京大学),北京100871
2.北京大学 信息科学技术学院 计算机科学技术系,北京100871
3.香港科技大学 计算机科学与工程系,香港999077
人群流动预测是城市计算中的关键问题,在城市资源调度、城市规划与安全预警等场景有着诸多应用,人群流动预测技术对优化社会资源作用明显,对社会稳定与繁荣的意义重大。与此同时,传感器网络、移动智能终端的普及和位置获取技术的发展带来了海量具有时间和地理信息的数据,例如车速、供需强度与人群流量数据等,这些具有时间和空间属性的数据被称为时空数据。大量丰富的时空数据为预测人群的流动提供了良好的数据基础。
人群流动预测应用范围广泛,如预先调度空闲车辆至热点需求区域、预测地铁站峰值人流等。事实上,城市范围内与人群的迁移、流动相关的应用问题都可以被称为人群流动预测问题。人群流动预测问题因具有非线性、受多种因素影响等特点,难以实现精准的预测。
历经多年的研究与发展,国内外学者在时空人群流动预测领域做了大量的努力。早期研究将人群流动预测问题作为经典的时间序列预测问题,如整合移动平均自回归模型(autoregressive integrated moving average,ARIMA)和历史均值法(historical mean,HM)。线性模型ARIMA 和HM 不能很好地建模人群流动的非线性特性。后来有许多非线性算法被运用在时空人群流动预测问题上,如马尔可夫随机场(Markov random field,MRF)、决策树方法等。随着深度学习技术的发展,深度学习技术被广泛运用于交通流量的预测,循环神经网络(recurrent neural network,RNN)及其变种,主要包括LSTM(long shortterm memory)与GRU(gated recurrent network),因其具有良好的捕获序列信息的能力,被广泛运用于交通预测中。然而上述模型通常只考虑了预测值与过去值在时间维度上的依赖性,并没有很好地利用空间依赖。
空间跨度上的依赖也是人群流动的一大特性,例如相邻的站点更可能具有相似的流量,具有相似功能的站点的流量模式相似等。卷积神经网络(convolutional neural network,CNN)在人脸识别、目标检测等领域大放异彩,已被证实能够很好地提取欧式数据(例如图像)的特征,学者们将城市划分大小为×的图像,然后使用CNN 捕获空间依赖,CNN 可以通过残差单元(residual unit)被堆叠得十分深,进而能够捕获长距离依赖。对于社交网络等非欧式数据,CNN 无法直接使用,图卷积神经网络(graph convolutional network,GCN)应运而生,许多基于GCN 的时空模型被应用于交通流量预测。例如DCRNN(diffusion convolution recurrent neural network)将图卷积视作双向图上的扩散过程,以捕获交流流量的空间依赖。ST-MGCN(spatio-temporal multi-graph convolution network)将多种空间知识与循环神经网络结合起来捕获流量特征。随着注意力机制的发展,越来越多的基于注意力机制的模型被提出,许多带有自注意力(self-attention)与多端注意力机制(multi-head attention mechanism)的模型也被用于预测人群流动,例如Liang 等人利用多层次注意力机制捕获传感器网络的时空依赖,Wang等人利用图注意网络捕获流量的空间依赖,同时使用transformer模型捕获长期时间依赖。
上述研究广泛地探究了人群流动的时间和空间依赖(也被称为时空先验知识),这些知识能够帮助模型更好地捕获人群的流动模式,但时空知识种类繁多,全面地利用这些知识是一件十分困难的事情。另一方面,许多新颖的模型都被冠以“先进”的标签,证实这一点最直接的方法就是与其他基准模型进行对比,但对这些模型进行复现是一件费时而困难的事情。虽然深度学习社区一直在倡导着开源,也有许多相关的源代码被开源出来(https://github.com/lehaifeng/T-GCN,https://github.com/xiaochus/TrafficFlowPrediction),但这些代码通常较为分散,只包含了一种或少许几种模型,且不同作者在深度学习框架的选择上与数据的组织上各不相同,因此,很难直接利用这些开源代码在同一个环境下进行实验。针对上述痛点,本文基于TensorFlow实现了一款面向时空人群流动预测应用的工具箱(urban computing tool box,UCTB),旨在为研究、从业人员提供如下便利:
(1)工具箱集成了时空人群流动领域常用的时空知识,提供了统一的数据处理接口以便利用不同类型的时空先验知识。同时由于数据接口的统一,工具箱内集成的各类模型能够直接进行比较。
(2)工具箱既集成了经典预测模型,也集成了先进的深度学习模型,以便快速复现各类模型,同时工具箱还提供了许多可复用的高级模型层,以加速用户对新模型的开发。
(3)为了便于用户快速上手,还编写了详细易懂的配套文档,所有的模型与自定义模块均有示例以供参考。UCTB 工具箱的网址是https://github.com/uctb/UCTB,配套文档的网址是https://uctb.github.io/UCTB/。
1 框架设计
机器学习算法执行的一般流程是:读取与预处理数据、构建模型、训练以及评估模型。与这一基本思路相对应,UCTB 工具箱由数据处理、模型构建、模型训练与评估三大模块组成(见图1)。
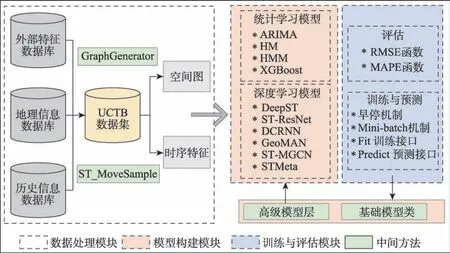
图1 UCTB 整体框架Fig.1 Framework of UCTB
在数据处理模块中,定义了一种可被运用于各类人群流动预测应用的通用数据集。基于通用数据集,利用时空先验知识设计了时空特征提取接口;在模型构建模块当中,对经典的人群流动预测模型进行了实现,同时解耦了一些可被复用的高级的模型层;在训练与评估模块,对UCTB 中的训练与评估机制进行了介绍。
1.1 数据处理
UCTB 工具箱对原始数据的处理分为两大阶段完成:第一阶段将不同的原始数据转化为UCTB 通用数据集格式;第二阶段基于时空先验知识从通用数据集中提取不同类型的时空特征。
人群流动的原始数据来源于种类繁多的传感器,例如地铁站的闸机记录了进出站数据,公路上的速度传感器记录了当前车流速度,来自于多种应用场景的数据处理过程无法统一。针对这一问题,本文设计了一种统一的数据集格式,作为原始数据和特征的“中间件”,用户只需要先将不同数据处理成该格式,进而能够利用UCTB 工具箱提取不同特征。UCTB 通用数据集是原始数据与特征的“中间件”,以键值对(key-value pair)的形式通过pickle 协议(https://docs.python.org/3/library/pickle.html)存储,主要的键值对信息列于表1。
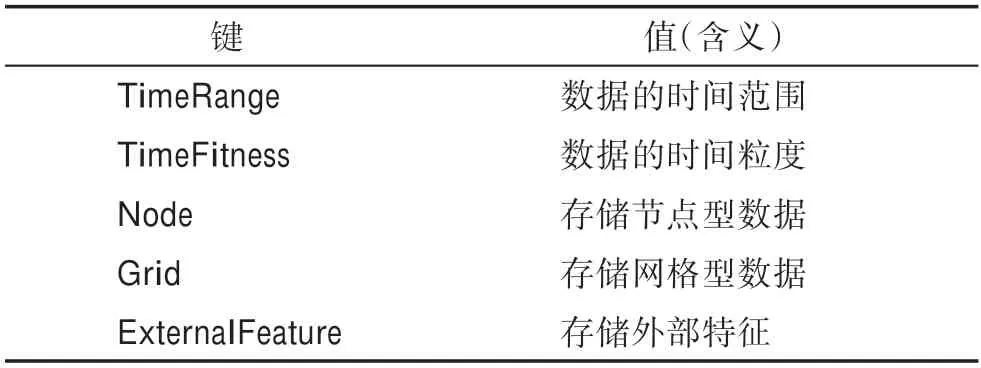
表1 UCTB 通用数据集格式Table 1 Datasets format in UCTB
特征提取是利用先验知识将流量转化为各种特征,使得预测模型能够更好地捕获人群流量的各种模式,这些专家知识主要包括时间知识和空间知识。时间知识从不同视角反映了未来的流量值与过去哪些时刻的流量值相关,按照不同的时间知识对数据按照不同时间间隔进行采样便能提取出时间特征(见图2)。
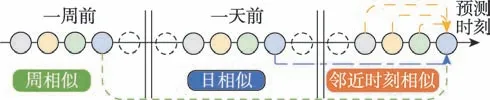
图2 时序特征采样示意图Fig.2 Schematic diagram of generating temporal features by sampling time serials data
常用的时间知识主要有以下三类。
(1)邻近时刻相似:相邻时刻的流量一般而言不会发生太大的突变,也即过去若干个时刻的流量值与未来的预测值是相关的。
(2)日相似:未来的流量值通常与前几天同一时刻的值相关,这对应了人类活动的日周期性。
(3)周相似:本周六的流量与本周五和上周六相比,流量会与后者更为相似,周相似与日相似只是时间间隔有区别。
人群流动还有着空间上的相关性,空间知识反映了预测站点和其他站点流量的关系。在基于深度学习的人群流量预测模型中,对不同类型的数据的空间特征提取技术不同。对于网格型数据,通常使用卷积技术提取空间依赖(如ST-ResNet);对于节点型数据,通常基于先验知识构建出不同的邻接图,使用图卷积技术提取空间依赖。图卷积技术主要分为频域方法(如ChebNet)和空域方法(如DCRNN)。不同类型的邻接图反映了不同类型的空间知识,例如基于地理位置构建出距离图,根据流量的相似程度构建出区域功能图等。
除了时空特征,人群流动还受外部因素的影响,例如气温会影响共享单车的使用,暴雨和大风会减少出租车的需求。外部特征通常需要收集额外的气候、节假日数据集得到,UCTB 通用数据集中的键值对被用于存储外部特征。
在数据处理阶段,UCTB 工具箱除了能够提取数据集的时空特征之外,还会对数据进行归一化(normalization)和划分训练集、验证集与测试集等操作,便于后续接口的调用。UCTB 提供了对应的数据预处理接口,细节见2.1 节。
1.2 通用模型的设计
UCTB 工具箱需要集成许多经典的模型,主要包括统计学习模型和深度学习模型两大类。统计学习模型和深度学习模型的构建与训练过程存在区别,但为了便于用户使用,UCTB 为不同的模型进行了封装,并提供了相似的使用接口。例如在UCTB 集成的各模型内部均实现了训练方法fit和预测方法predict。
值得注意的是,在实现深度学习模型时,一些训练和预测以及模型的存储接口是相似的,为了尽可能地复用代码,UCTB 中设计了基础模型类,该类集成了训练、预测、断点续训等功能,具体的深度学习模型只需继承这一基础类,然后定义自己的模型结构并设置相应的特征输入函数即可。
1.3 模型的训练与评估
统计学习模型的训练较为简单,不多赘述。在训练深度学习模型时,通常会将训练数据分为若干个批次(batch),然后选取小批次(mini batch)数据用于更新梯度进行训练,UCTB 工具箱也集成了这种机制。在训练过程中,UCTB 还会根据验证集误差评估模型的收敛性以确定是否训练完成,即UCTB 在模型训练中融入了早停机制(early stopping)。
当模型训练和预测完成后,还需要对测试结果进行相应的评估。评估是将真实值与预测值进行比较,在时空人群流动预测问题中,均方根误差(root mean square error,RMSE)和平均绝对百分比误差(mean absolute percentage error,MAPE)都是常用的评估函数,UCTB 也提供了相应的评估接口。
2 框架实现与接口参数
上述介绍了UCTB 数据处理、模型构建和训练及预测三大模块的基本功能,本章主要对UCTB 工具箱中的三大模块的实现和相关接口进行介绍。
2.1 数据处理接口
UCTB 提供了对通用数据集的处理接口(表2)。其中GridTrafficLoader 和NodeTrafficLoader 接口根据输入的数据集相关参数(如数据集名称、数据合并参数、训练集/测试集划分比例和归一化等)分别用于读取网格型和节点型数据,然后根据时空先验知识提取出不同的特征。ST_MoveSample 接口按照不同的时间间隔对流量数据进行采样得到不同的时间特征。GraphGenerator 接口产生不同类型的空间图得到不同类型的空间特征。

表2 UCTB 中的数据处理接口Table 2 Data processing interface in UCTB
与1.1.2 小节中提及的三种时间先验相对应,ST_MoveSample 的采样间隔主要有三种,分别代表了不同间隔时间特征的采样数目。例如邻近相似为6,日相似为7,周相似为4 表示将预测时刻的前6 个时刻,预测时刻最近7 天同时刻的和最近4 周的同时刻的流量共同作为时间特征。
GraphGenerator 接口接收图名称并根据相应的图阈值生成图的邻接矩阵和拉普拉斯矩阵。例如距离图的阈值参数可被设置为6 500 m,GraphGenerator会根据各站点的欧式距离生成邻接矩阵,然后将距离小于阈值6 500 m 的站点在邻接矩阵中置为1,大于阈值6 500 m 的站点置为0,也即大于阈值的站点没有关联,小于阈值的站点有关联。阈值选取的好坏也决定了空间知识能否被很好地提取。根据实验经验,较好的阈值一般能使得每个节点平均与其他20%的节点有联系。
2.2 模型接口
UCTB 工具箱提供了两类模型接口:第一类是完整的模型,这类接口是对人群流动预测模型的复现;第二类接口是可复用的模型层,这一类接口是人群流动预测领域常使用到的高级模型层,用户能够利用可复用的模型层快速实现自定义的新模型。
UCTB内实现了很多经典模型,如ARIMA、HM、XGBoost(extreme gradient Boosting)、ST-ResNet、DCRNN、ST-MGCN和STMeta等(表3),这些模型均被封装成了模型类,类内部实现了训练函数fit和预测函数predict。表3 同时还列出了这些模型所考虑到的时空先验知识。

表3 UCTB 中集成的模型Table 3 Implemented models in UCTB
在统计学习方法中,ARIMA 是被广泛使用的时间序列预测模型,主要考虑了最近几个时刻的流量值;历史均值HM 使用过去若干时刻流量的平均值作为未来的预测值,历史均值不仅仅考虑最近几个时刻的流量值,最近几天相同时刻和最近几周相同时刻的流量值也会被考虑;GBRT(gradient boosted regression trees)利用过去的流量值作为特征,UCTB实现GBRT 时也利用了多种时间知识,例如邻近时刻相似、日相似和周相似;XGBoost 与GBRT 相似,具有更高的执行效率。
在深度学习方法中,DCRNN是先进的深度图模型之一。DCRNN 将扩散卷积和RNN 结合,用以同时捕获时间和空间特征,原始DCRNN 模型只利用了邻近时刻相似特征和空间距离图;ST-MGCN 利用图卷积技术去捕获多种空间特征,同时将不同的时间特征连接到一个序列向量中以利用多种时间特征;STMeta 是一种可以整合时间和空间特征的预测框架,其利用时空建模单元同时捕获不同类型的时空特征(常用的时空建模单元包括GCLSTM和DCGRU),然后利用时空聚合单元将不同类型的时空特征聚合起来(常用的时空聚合单元有图注意层和特征连接),最终得到时空特征的隐表示。
UCTB 中实现的第二类高级模型层见表4,其中DCGRU 与GCLSTM 均为时空建模单元,其主体架构分别为GRU 和LSTM,内部将乘积更新操作替换成了图卷积操作,时空建模单元能够同时捕获时间和空间特征。ChebNet基于图拉普拉斯矩阵使用切比雪夫多项式进行图卷积操作。图注意层(graph attention layer,GAL)对图中的节点使用注意力机制进行更新,常用于聚合多图特征。

表4 UCTB 中的高级模型层Table 4 High-level layers in UCTB
2.3 训练与评估接口
UCTB 集成的训练与评估接口见表5。在训练深度学习模型时,通常训练数据较大,无法一次性读入内存,UCTB会依次从全部数据中取mini-batch大小的数据用于更新梯度,并执行多轮(epoch)。MiniBatch-FeedDict接口具体实现了这一功能,该类通过不断调用内部的get_batch 方法产生批数据用于训练。
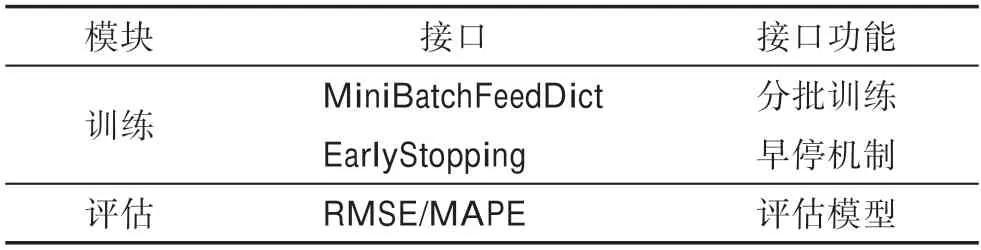
表5 UCTB 中的训练与评估接口Table 5 Training and evaluating interface in UCTB
UCTB 中实现了两种早停机制,分别是朴素方法和检验方法(t-test),朴素方法能够容忍若干步没有获得更低的验证集误差;t-test 方法将最近的2轮的验证集误差等分为两组独立样本,每组个,并执行独立样本的t-test 方法。原假设是这两个样本的均值是相同的,当假设检验的值小于阈值(通常是0.10或0.05),表示拒绝两分布的均值相等的假设,也即模型还没有达到收敛标准,反之则代表模型收敛,停止训练。UCTB 中还集成了两种人群流量预测中最为常见的评估函数,分别是RMSE 和MAPE。
3 案例研究
为了展示UCTB 工具箱的效果,收集了4 个场景8 个城市的真实数据集,利用UCTB 中集成的模型进行相应的实验,所有的实验代码均已开源。原始记录分别被处理成30 min与60 min粒度的数据集,目标是预测下一个时刻的流量。将这些数据集按照时间顺序以8∶1∶1的比例划分为训练集、验证集和测试集。
3.1 实验数据
共享单车数据集来源于美国开放数据网站,包含了纽约(https://www.citibikenyc.com/system-data)、华盛顿特区和芝加哥3 个城市的数据。原始数据的时间范围超过了4 年,每条有效数据都包含了开始站点、开始时间、停止站点、停止时间等信息。预测的值是每个站点下一个时刻共享单车的需求数量。
网约车数据集来自滴滴出行“盖亚”数据开放计划(https://outreach.didichuxing.com/app-vue/),包含了西安市和成都市两个月的网约车记录。每条网约车记录都包含开始位置、开始时间、结束位置和结束时间等信息。由于开始和结束位置包含了经纬度,将整个城市划分成了16×16 的网格,每个网格的大小都是0.5 km×0.5 km,预测目标是每个网格下一时刻的需求值。
地铁数据集包含了上海市和重庆市的地铁人群流量数据,时间跨度是3 个月,每个地铁记录都包含了进站时间、进站站名、出站时间和出站站名。同样收集了各个地铁站点的地理信息数据。预测目标是每个站点下一时刻的进站人数。
电动汽车充电站数据集是北京充电站的使用情况数据,原始数据来源于国内最大的充电桩公司之一。数据集的时间跨度是6 个月,有效的记录数超过100 万。预测目标是每个充电站点下一时刻充电桩的使用数量。
3.2 部分模型调用过程
分别展示统计学习模型ARIMA(过程1)和深度学习模型STMeta(过程2)的完整调用代码。
ARIMA是经典的时间序列模型,其收敛较快,对于每个站点使用单独的ARIMA 模型,值得注意的是,并不是所有站点的数据都具有平稳特性,对于不具有平稳性的站点,UCTB 会使用前一时刻的值作为预测值。
STMeta 是一种元框架模型,其利用了多种时空先验知识,STMeta 会将时空知识两两组合,然后使用时空建模单元捕获不同类型的时空依赖,接着利用时空聚合单元将不同类型的时空特征聚合起来,最后将聚合后的特征表示通过全连接层输出预测目标。
ARIMA 模型的示例调用过程


其余模型运行代码与ARIMA 或STMeta 的运行代码相似。上述实例代码的执行顺序和结构与在第1 章框架设计阶段所预设的“数据的读取与处理、模型的定义、模型的训练及评估”三大模块相吻合。
STMeta模型的示例调用过程


3.3 实验结果
图3 中的4 幅子图分别展示了3 种模型HM、XGBoost 和STMeta 在上海地铁与西安网约车30 min和60 min 粒度数据集的预测结果。上海地铁数据集中的12 号站点和西安网约车252 号站点均为数据集中流量最大的站点。图3 中蓝线代表了预测时刻的真实值(ground truth),橙线代表的HM 模型和真实值相差较大,绿色代表的STMeta 模型较HM 与XGBoost而言更为接近真实值。

图3 HM、STMeta、XGBoost在不同数据集上的预测结果Fig.3 Prediction results of HM,STMeta,XGBoost on different datasets
还在其他数据集以及其他粒度进行了大量的实验。从方法上来说,统计学习方法(ARIMA、HM、XGBoost、GBRT)在各数据集上的最佳准确率不优于深度学习方法(ST-ResNet、ST-MGCN 与STMeta 等)。这主要有两大原因:一方面是因为深度学习模型对时空特征的建模能力较强,另一方面是因为深度学习方法通常融合了更多的特征知识,统计学习方法通常只考虑模型的时间特征,而深度学习方法通常会融合时空特征。
将图3 中30 min 粒度与60 min 粒度的结果进行对比,不难发现时间粒度越小,深度学习方法相较于统计学习方法的优势就越小。这是因为当时间粒度越小时,时间特征相较于空间特征就更为重要,因此仅考虑时间特征的统计学习系列方法与同时建模时空特征的深度学习系列方法的差距便越小。
以上展示了目前UCTB 中集成的模型的测试结果,基于这些结果,观察出了一些有价值的结论。未来,相关的研究、从业人员能够利用本文提出的工具箱,发掘出更多有关人群流动的规律,最终能快速地将新颖的想法转化为实际的模型。
3.4 可视化接口
为了便于用户深层次地了解数据集与实验结果,设计了两类可视化接口。第一类是数据集站点可视化接口,用于显示各站点的空间位置,在数据接口NodeTrafficLoader 和GridTrafficLoader 中集成了这一功能,通过调用其中的st_map 方法展示,效果如图4(a)。第二类是实验结果可视化接口,主要用于展示不同模型实验运行的结果,本文基于HTML(hypertext markup language)和JavaScript 实现了这一功能,效果如图4(b)。目前可视化接口功能尚不完善,主要存在功能分散、交互体验不够友好等问题,未来将聚焦这些问题,进一步优化。
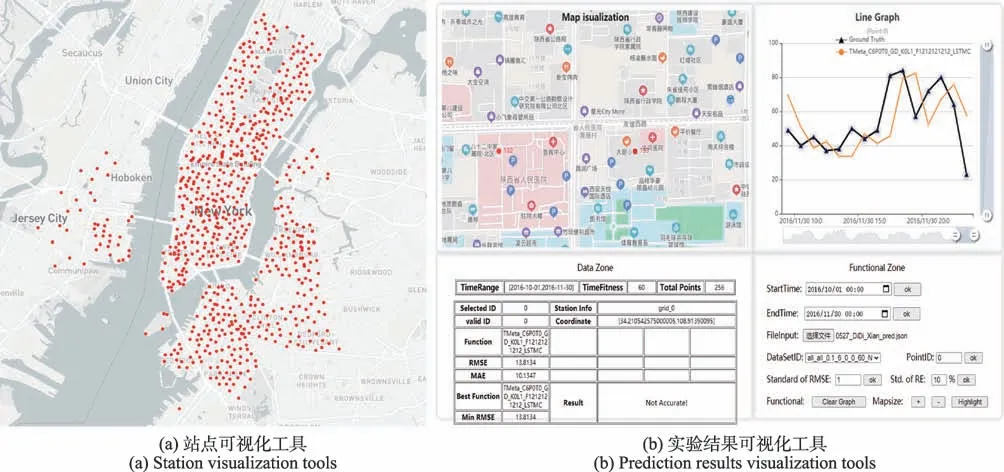
图4 UCTB 中的可视化工具Fig.4 Visualization tools in UCTB
4 结束语
为加速相关研究、从业人员对时空人群流动预测领域时空先验知识的利用,快速地进行复现或实现模型,基于TensorFlow 设计并实现了时空人群流动预测工具箱UCTB。该工具箱集成了大量时空人群流动预测领域的研究和多种经典模型,能够被广泛用于人群流动相关的场景。UCTB 相关代码及文档已完全开源,供研究、从业人员使用。同时,也期待着用户们在使用后提出宝贵意见,将及时跟进,持续改进UCTB 工具箱。
猜你喜欢
四川党的建设(2022年8期)2022-04-28 21:29:35
小学生学习指导(低年级)(2020年11期)2020-12-14 07:28:10
电子制作(2019年14期)2019-08-20 05:43:42
国际呼吸杂志(2019年1期)2019-01-28 09:37:02
作文大王·低年级(2018年10期)2018-12-06 06:22:44
中国自行车(2017年1期)2017-04-16 02:53:52
故事会(2016年21期)2016-11-10 21:15:15
小猕猴智力画刊(2016年5期)2016-05-14 09:21:39
水利科技与经济(2016年7期)2016-04-25 13:03:12
计算机与网络(2014年1期)2014-03-25 10:56:56
