
融合图嵌入和注意力机制的代码搜索
2022-04-13 02:40:26黄思远赵宇海梁燚铭
计算机与生活 2022年4期
黄思远,赵宇海,梁燚铭
东北大学 计算机科学与工程学院,沈阳110169
随着人们对软件的需求越来越多样化和复杂化,程序开发人员往往要实现很多复杂的功能来满足用户的要求。然而在程序的开发过程当中会发现许多功能在以往的开发过程当中都被实现过,因此如何利用现有的源代码来实现新的功能对于软件开发是至关重要的,在一定程度上影响着整个项目的开发进度。据相关调查表明,程序开发人员在互联网上搜索相关问题解决办法的时间大约占整个开发过程的1/5。程序开发人员在网络上搜索相关代码的动机主要包括对现存在的开源代码的重复使用、代码的漏洞修复与检测以及相关代码片段的理解。与此同时,随着计算机的不断发展,在互联网中积累了越来越多的开源代码库,为软件工程的研究提供了大量可依靠的数据。根据Github 在2018 年的年度报告显示,Github 中开源的项目数量已达到9 600 万,与2017 年相比增加40%。大规模且快速增长的开源代码库为代码检索任务提供了大量可复用的高质量代码,使代码检索任务有了很好的数据支撑。
代码检索是指将自然语言作为查询语句,在代码仓库中搜索满足查询要求的相关代码片段来实现代码的复用。在软件工程领域,一个高效的代码检索工具可以极大地提高软件的开发效率,从而来达到满足用户日益增长的需求的目的。与此同时,无论是程序初学者,还是经验熟练的软件开发者,都希望可以利用现有的开源代码来实现重复的功能,从而节省自己在程序开发过程中在网上查找相关解决方案所浪费的时间。为了方便理解代码检索任务的流程,图1 详细地描述了代码检索任务的框架结构。代码检索框架结构主要包括线下数据处理和模型训练,以及线上用户查询等相关过程。
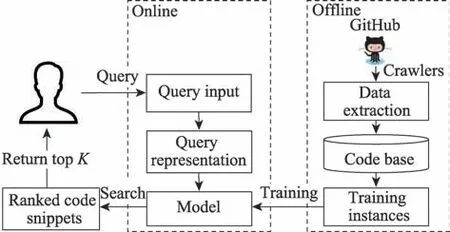
图1 代码检索任务框架Fig.1 Code retrieval task framework
代码搜索对于提高程序员编码效率有着显著性的提高,因为直接搜索符合要求的代码片段比阅读各种开源应用程序接口(application programming interface,API)的原始说明文档要有效得多。甚至很多开发人员可能甚至不知道要查找哪些API,只需要以自然语言的形式进行查询即可找到符合要求的代码片段。在软件开发过程中,程序员会遇到各种各样的问题,例如“如何解析纯文本数据”。在遇到问题的时候大多数程序员都会选择在百度上去查找相关问题的答案,但是百度的检索结果主要是依赖关键词匹配等信息检索技术。如果查询语句中不存在与代码相关的关键词信息,则百度检索返回的结果是十分糟糕的。另一个受欢迎的程序问答网站是Stack Overflow,它主要以问答的形式来呈现各种问题的解决答案。当某人在网站上以自然语言的形式提出一个编程相关问题,会有很多人在提问下方提供各种各样的解决方案,并且利用投票机制对解决方案进行排序来将大多数人认同的答案呈现在顶部,它为软件开发人员和初学者提供了很大的便利。当程序开发人员想在Stack Overflow 查找“如何解析纯文本数据”这一问题的解决办法,可能在Stack Overflow 上已经有人问过和回答过同样的问题,程序员分析和理解其他人对这个问题的解决办法来完成自己的任务。尽管Stack Overflow 资源丰富,但它并不包含每个问题的答案。与此同时,Stack Overflow中不讨论特定于某个公司专有代码和API 的问题,针对特定领域或者公司的内部相关编程问题,无法提供相应解决办法。
传统的基于信息检索的源代码检索算法,不能充分理解自然语言查询语句的语义信息。因此,构建一个充分理解自然语言查询语义的源代码检索算法来获取相关代码片段,实现代码的复用对软件的开发是十分有意义的。针对上述存在的问题,本文提出融合图嵌入与注意力机制的代码检索算法GraphCS。GraphCS 算法的创新在于不仅考虑代码片段的纯文本语义信息,也考虑代码片段复杂逻辑结构信息,将语义特征与结构特征相融合作为代码片段特征表示。为了更好地捕捉代码片段中包含的信息,融入注意力机制来更好地学习代码片段表示。与CODEnn算法相比,GraphCS 算法在Frank、MRR、Precision@1/5/10 以及SuccessRate@1/5/10 指标上有一定提升。
1 相关工作
1.1 基于信息检索的代码检索算法
在软件工程领域,针对代码检索的相关研究还处于初级阶段,现阶段的研究主要基于信息检索和自然语言处理相关技术。Krugle(http://www.krugle.com/)和Ohloh(https://code.ohloh.net/)采用基于关键字匹配的信息检索方法,在商业中被广泛应用,但是算法的检索结果大多情况下不符合程序开发人员的要求。Lucene(https://lucene.apache.org/)是一个传统的文本搜索引擎,而Sourcerer是基于Lucene 实现的代码检索工具,将代码属性和代码的受欢迎程度相结合作为评价推荐代码质量的评估指标来检索相关代码片段。Reiss提出基于源代码语义和语法相结合的源代码检索算法,它要求用户不仅要提供自然语言查询语句,还要提供其他规范约束,但不考虑自然语言查询语句的语义信息。如果缺少对相关代码语义和语法信息的理解,则检索结果的准确性会降低,对于初学者和大多数程序员来说存在一定的困难。SNIFF分析相关代码片段的API 文档信息,并为代码片段添加注释信息,并建立相关索引,来进行代码检索。Portfolio给定一个自然语言查询语句,根据自然语言查询语句来查找用户与任务相匹配的函数定义与相关用法。Reformu以WordNet 生成的同义词来扩展查询语句中的单词使其与源代码中具有类似语义的单词相同,从而提高代码搜索结果的准确性。INQRES考虑源代码中单词之间的关系,交互式地重新构造搜索查询,以优化查询质量。SWIM算法对给定API 的自然语言查询语句进行分析,利用从开源代码库中学习到程序编码模式来合成相关的代码片段。CodeHow算法提取与用户查询相关的潜在API,并使用检索到的API 信息来增强原始查询语句,使用集成扩展的布尔模型来实现精确的代码检索结果。
1.2 基于深度学习的代码检索算法
基于信息检索和自然语言技术的代码检索不能充分理解自然语言查询语句的语义信息,当代码库中没有与查询语句中的关键词相关的代码片段时,会严重影响代码的检索结果。最近提出的基于深度学习的语义代码检索算法,以自然语言的形式来查找符合查询语句语义信息的代码片段。NCS以无监督的方式在大规模语料库上训练,获取代码片段和自然语言注释部分的固定长度的嵌入向量表示。在自然语言查询部分以向量均值来表示,而代码片段部分则以TF-IDF 权重的方式获取相应的均值表示,以余弦相似度来判断两个向量的相似程度。UNIF以注意力机制来组合代码片段中每个令牌的嵌入,并生成嵌入整个代码片段的嵌入向量表示。自然语言查询语句嵌入是通过对查询嵌入以词嵌入相加求均值向量进行表示。以NCS 中学习的嵌入矩阵为初始值,并在训练期间以高质量的有监督数据进一步微调。SCS基于代码到自然语言注释序列的网络的部分编码器来嵌入代码令牌序列。并以一个语言模型来嵌入查询标记序列。在推理和学习过程中将代码片段部分嵌入转换为查询嵌入。CODEnn以一个端到端的方式训练一个代码检索模型。从代码片段中提取方法名序列、API序列和令牌来表示代码片段的特征。以双向长短期记忆单元(bi-directional long short-term memory,Bi-LSTM)模型来提取API序列、方法名序列和自然语言注释部分特征来获取相应的向量表示,以余弦相似度的方法来判断代码片段特征向量和自然语言特征向量的相似性程度。CoaCor利用代码总结模型的方式来生成代码检索任务的自然语言注释,并且以一个代码检索模型来查询相关代码片段。
2 融合图嵌入和注意力机制代码搜索算法
2.1 数据提取
本文提出的融合图嵌入和注意力机制的代码搜索算法(GraphCS)在代码纯文本信息基础上考虑代码片段的逻辑图结构信息,虽然CODEnn 算法提供了千万级别的代码片段和注释数据对,但是数据都是经过预处理的,并不能从已处理的数据集中提取代码片段的逻辑图结构信息。因此,为了从源程序中提取可用于图嵌入的数据,从开源代码库中爬取2016—2019 年的Java 开源项目,并对数据集进行清洗操作。首先,移除包含非英文的代码注释数据对;其次,移除注释为非Javadoc格式代码注释数据对;然后,移除行数小于指定阈值和超过指定阈值的代码注释数据对;最后,移除类的构造方法以及类中其他相应的初始化方法。表1 详细地对源代码检索任务的数据集规模以及格式进行相关概述。原始数据集由3 564 213 条方法体和注释数据对组成,经过清洗后的数据为2 141 921条方法体和注释数据对。为了模拟真实的代码检索,从开源代码仓库上提取1 569 525条只包含方法体的代码片段作为代码检索数据库。

表1 数据集介绍Table 1 Dataset introduction
为了学习程序语言丰富的语义和语法信息,从不同的角度来提取代码片段的特征。代码片段特征提取部分是以方法体为单位来做特征提取,它不仅包含丰富的文本语义信息,同时也包含复杂的逻辑结构信息。因此,从代码片段中提取文本语义特征包括方法名序列和令牌信息,而提取的逻辑图结构特征为方法体对应的程序依赖图(program dependency graph,PDG)信息。自然语言部分则为方法体对应的注释序列信息。其中,代码检索任务数据提取流程如图2 所示。

图2 数据处理Fig.2 Data processing
方法名提取:提取每个Java 方法片段的函数名,并以驼峰规则将函数名拆分成多个词语的组合。例如,方法名readXmlFiles 将会被拆分为read、xml 以及files。
令牌提取:为了提取令牌信息,提取数据集中每个Java 方法体内部的全部令牌信息,并以驼峰规则对每个令牌进行单词拆分,以此作为相应的分词方法。针对分词后的语料,移除令牌数据中重复单词、常用的停用词以及Java关键字。
自然语言提取:通过Eclipse JDT 工具将Java 方法转换为抽象语法树,并从抽象语法树中提取JavaDoc注释部分第一行语句作为自然语言描述。
程序图嵌入提取:为了提取源代码中每一个方法体的逻辑图结构信息,首先,提取Java 代码片段的控制流图,在控制流图的基础上引入图中节点之间的数据依赖关系类以及控制依赖关系,从而为代码片段构建出更加复杂的程序依赖图。其次,以WL(Weisfeiler-Lehman)重标签算法为程序依赖图中的每个节点进行重标签,并提取每个程序依赖图中的子图结构信息。最终,以Doc2Vec 的思想将子图结构作为上下文信息从而来获取每个方法体对应的程序依赖图的向量嵌入表示。程序依赖图特征向量提取过程如图3 所示。
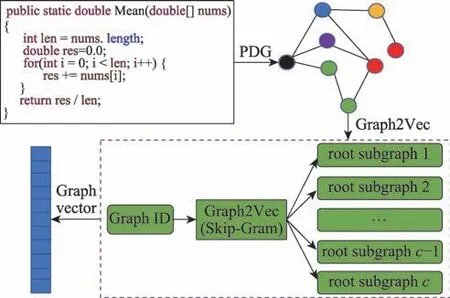
图3 PDG 向量提取过程Fig.3 PDG vector extraction process
2.2 WL 重标签算法提取子图信息
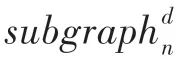
假设给定图,并设定图4 中每个节点的初始化标签为{1,1,2,3,1}。考虑迭代一次时,WL 算法聚合每个中心节点的邻域节点的标签。例如,图中节点的邻域节点为和,则聚合邻域之后的标签为1-1,2。根据新的标签对标签进行排序和压缩,压缩后的标签代表对应的子树模式。假设图4 中标签为7 的节点,则存在一个高度为1 的子树模式,其中根节点标签1,它的邻居有标签1 和3。以WL 算法来提取子图信息的算法流程如算法1 所示。

图4 G 上的WL 重标签Fig.4 WL relabeling for graph G
WLSubGraph(,,)


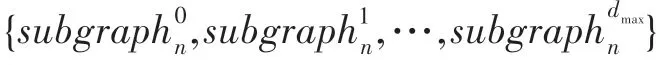
2.3 GraphCS 模型
自然语言与代码片段从词的分布的角度来考虑是不同的,因此二者是异构数据。源代码检索任务考虑将代码片段和自然语言两个异构数据嵌入到同一个向量空间,从而使语义相似的代码片段和自然语言在向量空间距离较近。
源代码片段中不仅包含大量纯文本语义信息,也包含丰富的逻辑结构信息。因此基于图嵌入算法在提取代码片段的特征时,不仅考虑代码的纯文本语义信息(方法名和令牌),也考虑了代码的逻辑结构信息(程序依赖图信息)。
为了更深层次捕捉代码序列的语义信息,以双向LSTM 来学习序列的相关特征表示。其中,LSTM网络结构如图5 所示。
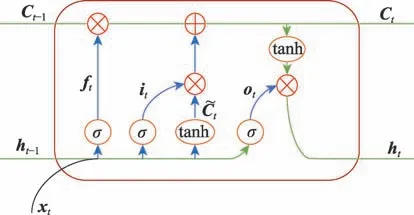
图5 LSTM 网络结构Fig.5 LSTM network structure
LSTM 是为了解决RNN 中存在的梯度爆炸和梯度消失的问题而提出来的更高效的序列语义特征提取模型。LSTM 主要引入遗忘门、输入门以及输出门来达到门控的目的,并以高速网络的方式充分保留上一时刻的细胞状态来更好地捕捉序列的语义表示。LSTM 神经网络的迭代公式如下:
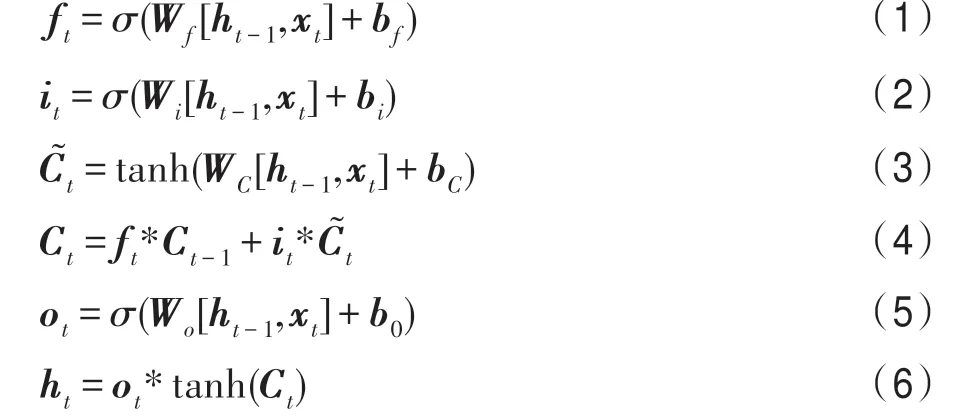
为了更好地提取语句的特征向量表示,引入双向LSTM 时序网络模型。双向LSTM 考虑正反两个方向上下文信息,将正反两个方向的特征向量进行拼接,从而达到更好捕捉语义信息的目的。
方法名序列,,…,name为以驼峰规则对方法名进行分词获取的长度为的方法名序列,以双向LSTM 来提取方法名序列的各个时刻隐藏层的特征表示。

为了更深层次地学习方法名的语义特征表示,将正反LSTM 的隐藏层向量进行拼接,并以最大池化方法来对各个隐藏层的状态进行压缩,并作为方法名序列特征的最终向量表示。
令牌信息,,…,token为对方法体内的代码片段以驼峰规则拆分代码语句后,并移除重复项、常用停用词以及Java 关键字获取到的长度为的代码片段。在提取令牌特征时,并未考虑代码的语序关系,故以多层感知机(multi-layer perceptron,MLP)方式来学习令牌的特征向量表示。

式中,emdtk是令牌中在位置处单词的初始化嵌入向量表示,而W是全连接层中的参数矩阵。,,…,htoken为学习后令牌的嵌入向量表示,并以最大池化方法对全部令牌的向量表示进行压缩,作为令牌片段特征的最终向量表示。
在提取程序依赖图特征时,提取Java 代码片段的控制流图,在控制流图的基础上引入数据依赖关系类以及控制依赖关系,从而构建出代码片段的程序依赖图。以WL 算法从程序依赖图中提取每个节点对应的子图集合作为每个图的上下文信息,并以Skip-Gram 的方式学习图的向量表示。在GraphCS算法中以多个卷积核的方式对图特征向量以一维卷积来提取不同的子特征,获取程序依赖图的最终向量表示。
在特征融合部分,以注意力的方式为方法名特征向量、令牌特征向量以及程序依赖图特征向量分配不同的权重系数。代码片段的不同特征以不同的权重进行融合,来学习最终的代码片段向量表示。
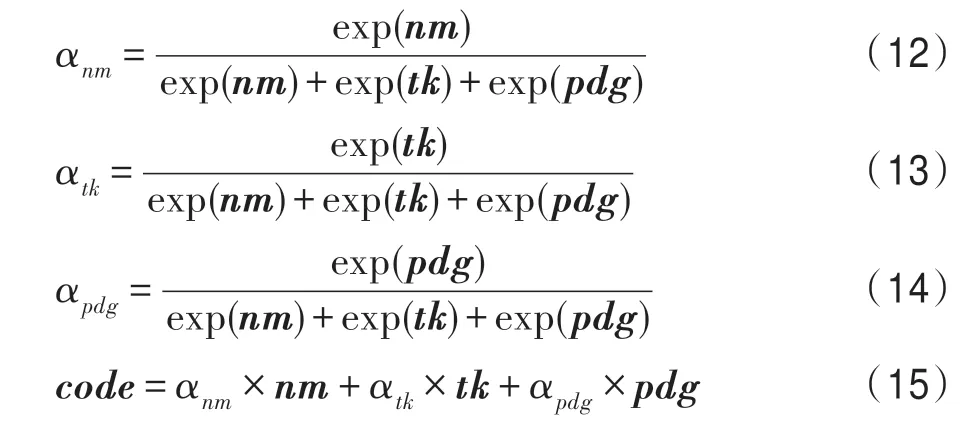
为了与自然语言特征向量表示维度一致,会以全连接的方式将代码片段的特征向量映射到与自然语言片段特征向量相等的维度。在自然语言描述部分,通过双向时序神经网络来学习自然语言描述中所包含的语义特征表示。考虑自然语言注释序列,,…,desc是存在语序关系的,故以双向LSTM 来提取各个时刻隐藏层的特征表示。

为了更深层次地学习自然语言的语义特征表示,将正反LSTM 的隐藏层向量进行拼接,并以最大池化方法将LSTM 的各个隐藏状态向量表示压缩成一个固定维度的向量作为自然语言片段特征的最终向量表示。
通过代码嵌入网络和自然语言网络将代码片段特征和自然语言描述分别映射成相等维度的向量表示和。将代码片段向量表示和自然语言部分向量表示映射到同一个向量空间,并以余弦相似度的方式衡量两个向量的相似程度。

在同一个向量空间中,代码片段向量与自然语言向量的余弦相似度的值越高,则代码片段和自然语言描述之间的语义越相近。如果代码片段与自然语言描述语义很相近,它们在向量空间距离较近。自然语言与代码片段在同一向量空间的映射如图6所示。
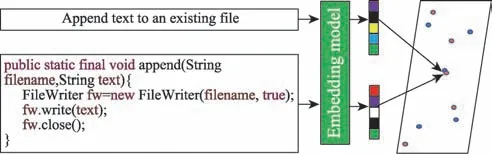
图6 向量空间映射Fig.6 Vector space mapping
图6 中的自然语言查询语句为append text to an existing file,在代码库中检索到的相似度较高的代码片段为方法名为append 的函数。自然语言与代码片段在语义上相似性较高,因此在特征空间中二者距离较近。
假设给定代码片段C,以及代码片段对应的自然语言描述,为每个代码片段随机分配一个负样本。在训练网络模型时,构建<,>和<,>训练语料,并考虑最小化排名损失。

式中,为网络模型参数,在训练过程中被设置为0.398 6。排名损失会促使代码片段与其正确描述之间的余弦相似度上升,而代码片段与错误描述之间的余弦相似度下降。
根据代码片段和自然语言片段的特征提取方法,构建基于GraphCS 的代码检索算法模型网络结构如图7 所示。

图7 GraphCS 模型网络结构Fig.7 GraphCS model network structure
3 实验
3.1 性能指标
本文采用源代码检索任务中公认的评估指标Frank、SuccessRate@、Precision@以及MRR 来验证代码检索的有效性。
Frank 是指在指定大小(=10)的返回结果列表中第一次出现的符合要求的结果。Frank 指标的结果符合浏览信息从上而下的准则,较小的Frank 意味着为找到所需结果所需的检查工作量较小。Frank 值越小,则说明检索结果越靠前。因此Frank 可以衡量单个代码搜索查询的有效性。
MRR 表示每一个自然语言查询语句query 检索返回结果中指定大小(=10)的Frank 值的倒数的累加和,并对求和结果进行均值化,在很大程度上可以衡量检索结果的好坏。MRR 值越高,则说明检索性能越优越。MRR 值越低,则说明检索性能越差。

其中,||代表查询语句的数量,代表查询语句集合中的每个查询语句,Frank代表查询语句对应的Frank 值。
SuccessRate@(=1,5,10)衡量在返回的相似度排名的结果中排在前的结果中可能存在多个正确结果的查询的百分比。

其中,函数定义为当判断语句为真时返回结果1,否则返回0。SuccessRate@评估指标对于检索任务来说至关重要,因为性能优越的代码检索应允许从较少的返回结果来发现所需的代码。并且Success-Rate@度量值越高,则代码搜索性能好。
Precision@(=1,5,10)指标用来衡量每个自然语言查询返回的结果中的排在前的相关结果的百分比。

Precision@可以反映查询结果中于目标相符合的结果的个数,可以很好地提供不同用法的多种结果以学习,可以降低不相关结果出现的次数。因此Precision@度量值越高,则代表代码搜索性能越好。
3.2 实验参数
为了对模型进行训练,将训练数据进行随机打乱并将批次大小设置为64。统计各个特征语料,构建相应的词汇表。将词汇表的大小设置正10 000 的时候,对语料库的单词覆盖率达到95%以上,可以有效地学习词汇的语义表示。针对不同的代码特征,设置相应的最大长度。当序列的长度大于最大长度时,对序列进行截断。当序列的长度小于最大长度时,以数值0 进行填充。在特征提取部分将LSTM 和嵌入向量维度设置成256,而将MLP 部分的嵌入向量维度设置成512。为了使模型有更好的泛化能力,在模型中添加Dropout 机制,将参数设置为0.25。详细参数设置如表2 所示。

表2 参数介绍Table 2 Parameter introduction
3.3 实验结果
CODEnn 算法是第一个基于深度学习的学习自然语言查询语句语义信息的代码检索算法,在一定程度上取得了不错的效果。但是CODEnn 算法只考虑源代码的纯文本信息,而忽略了代码中存在的逻辑结构信息,不能充分理解程序语言丰富的语义和语法信息。GraphCS 算法不仅考虑代码的纯文本信息,还考虑了代码中的逻辑结构信息,并且融入注意力机制来更深层次地进行代码片段语义和语法特征的融合。为了验证GraphCS算法的有效性,与CODEnn算法进行对比。为了更直观地展现检索效果的高效性,以Frank 作为评估标准,GraphCS 算法和CODEnn算法检索的Frank 值如表3 所示。

表3 在Frank 上的评估结果Table 3 Evaluation results on Frank
GraphCS 不仅考虑代码结构特征中丰富的文本信息,也考虑代码片段的逻辑结构信息。CODEnn 中未检索到结果个数为17个,而GraphCS中未检索到结果个数为13 个,GraphCS 成功检索到相关代码片段明显高于CODEnn。GraphCS算法返回的检索结果中在Top 1 处为符合要求的代码片段个数比CODEnn返回的结果有一定的提升。并且从整体上分析,GraphCS算法大多数检索的结果的Frank 值比CODEnn 靠前,Frank 的值越小,说明返回结果越靠前,符合自上而下的检索方式。例如,考虑查询语句check if file exists。从表3 知GraphCS 算法的Frank 值为3,则意味着在返回结果列表中第3 个代码片段符合查询要求;而CODEnn 算法的Frank 值为6,则意味着在返回结果列表中第6 个代码片段符合查询要求。大多数人在搜索问题的过程中,都只会关注靠前的内容,后面的结果关注较少。综上所述,从Frank 评估指标结果分析可知GraphCS 与CODEnn 相比有较好的提升,可以提供更加符合查询要求的代码片段。
本文不仅在Frank 上验证GraphCS 算法的有效性,还在SuccessRate@、Precision@、MRR 指标以及时间性能上对GraphCS 和CODEnn 进行系统评估。其中,SuccessRate@、Precision@、MRR 统计结果如表4 所示,时间性能对比结果如表5 所示。

表4 性能对比Table 4 Performance comparison

表5 检索结果统计Table 5 Retrieval result statistics
GraphCS 算法在SuccessRate@5 值为0.56,则意味着存在56%的查询,可以在前5 个返回结果中找到相关的代码段。CODEnn 算法在MRR 上的值为0.31,其中Recall@1/5/10=0.20/0.42/0.66,Precision@1/5/10=0.20/0.24/0.23。相比之下,GraphCS 算法在MRR 上的值为0.39。其中Recall@1/5/10=0.28/0.56/0.74 和Precision@1/5/10=0.28/0.35/0.36。实验结果表明,GraphCS 算法与CODEnn 算法相比,GraphCS在MRR 上提高了25.8%,在Recall@1/5/10 上提高了40.0%/33.3%/12.1%,在Precision@1/5/10 上提高了40.0%/45.8%/56.5%。在时间性能对比分析中可知,CODEnn 算法在CPU 上训练和检索所花费时间分别为49.3 h 和157 s;GraphCS算法在CPU上训练和检索所花费时间分别为67.4 h 和164 s。从CPU 上的时间性能分析可知二者差距不大,当在GPU 中训练CODEnn 算法模型和GraphCS 算法模型时可以极大缩短训练和检索所花费的时间。因此,检索精度的提升可以忽略时间性能的不足。综上所述,可以证明引入逻辑图结构信息可以弥补纯文本信息的不足,在训练和检索时间性能差距不大的情况下可以在一定程度上提高代码检索的准确率。从实验数据中可知GraphCS 算法在上述4 个评估指标上获得更好的精度,比CODEnn 算法获取更多符合查询语义信息的代码片段。
大多数情况下,一个方法的方法名可以很直观地体现一个代码片段的功能。例如,一个函数方法的方法名为readXmlFiles,从方法名上可以很明显地确认方法所包含的功能为解析Xml 文件。为了验证GraphCS 算法检索结果的有效性,分别统计语义相关代码片段个数和方法名相关的代码片段个数,统计数据如表6 所示。GraphCS 算法检索结果中,语义相关的代码片段个数为37,其中24 个代码片段是方法名相关的。而CODEnn 算法检索结果中,语义相关的代码片段个数为33,其中18 个代码片段是方法名相关的。GraphCS 算法中方法名相关与语义相关的比值为0.649,而CODEnn 算法中方法名相关与语义相关的比值为0.545。相比之下GraphCS 检索的结果在语义和语法上都有较好的体现,且方法名相关得较多。例如,查询语句append text to an existing file 在GraphCS算法中的返回结果如图8所示,而在CODEnn算法中返回的结果如图9 所示。从返回结果可知,GraphCS 返回结果考虑得更加全面严谨且在方法名上更加相关,而CODEnn 返回的结果相对比较简略。

图8 GraphCS 检索结果Fig.8 GraphCS retrieval result

图9 CODEnn 检索结果Fig.9 CODEnn retrieval result

表6 检索结果统计Table 6 Retrieval result statistics
本文主要与CODEnn 算法进行了详细的对比,为了证明GraphCS 算法的有效性,与基于RNN 和NeuralBOW 的代码检索算法进行简单对比。其中,RNN和NeuralBOW 是代码检索任务中两个常用的基线模型,二者都是只对代码片段的文本信息进行编码,然后以余弦相似度的方式来计算代码片段与自然语言注释的语义相似度。在MRR、SuccessRate@指标上的实验结果如表7 所示。

表7 实验结果统计Table 7 Experimental result statistics
4 结束语
源代码的纯文本语句包含大量语义信息,但是不能充分地体现代码的逻辑结构信息。本文提出一种基于图嵌入的代码检索算法GraphCS。除了考虑源代码的纯文本信息之外,还考虑代码的逻辑结构特性,可以更深层次地学习源代码的语义表示。与CODEnn 对比,检索到更多符合语义的代码片段。
在未来的工作中,会考虑其他不同语言的数据集(C#或Python)进行全面的实验。为了克服代码的图结构大小不均衡而导致的图嵌入效果提升不明显问题,对代码图特征提取过程做进一步优化。
猜你喜欢
计算机仿真(2023年8期)2023-09-20 11:23:42
现代信息科技(2021年21期)2021-05-07 21:44:50
新世纪智能(语文备考)(2020年4期)2020-07-25 02:28:50
动漫星空(2018年11期)2018-10-26 02:24:02
动漫星空(2018年2期)2018-10-26 02:11:00
动漫星空(2018年9期)2018-10-26 01:16:48
动漫星空(2018年5期)2018-10-26 01:15:02
中国司法鉴定(2018年4期)2018-07-30 06:08:26
作文评点报·低幼版(2017年44期)2017-11-16 08:24:58
中国房地产业(2016年8期)2016-03-01 01:25:55
