
混部数据中心在线离线服务特征分析
2022-04-13 02:40:22陈圣蕾裘翼滔蒋从锋张纪林林江彬闫龙川任祖杰
计算机与生活 2022年4期
陈圣蕾,裘翼滔,蒋从锋+,张纪林,俞 俊,林江彬,闫龙川,任祖杰,万 健
1.杭州电子科技大学 计算机学院,杭州310018
2.阿里云计算有限公司,杭州311121
3.国网电力信息通信有限公司,北京100053
4.之江实验室,杭州311121
5.浙江科技学院 信息与电子工程学院,杭州310023
随着云计算技术的日益发展和云服务能力的进一步提升,越来越多的企业倾向于将自已的业务部署到云平台上。然而,最近的一些研究显示大多数商业化集群的资源利用率都较低。根据盖特纳和麦肯锡的研究数据,从全球范围来看,服务器利用率仅达到6%~12%。即使通过服务聚合技术进行优化,服务器的利用率仍然只有7%~17%。因此如何有效地对各类资源进行管理,保证资源的高利用率和服务的高可用性成为了云平台管理者的一大挑战。
为了进一步提高资源利用率,可以通过更加细粒度的资源调度以及借助虚拟机和容器等虚拟化技术将不同的服务实例整合在一起(比如将在线服务和离线任务进行混合部署),使得工作负载分布的密度更高。但是这种模式可能会对在线服务产生重大影响,例如由于在线服务和离线任务之间共享资源,高密度部署会引起严重的资源竞争,从而增加在线服务的延迟,尤其是长尾请求的延迟。因此分析数据中心中服务器真实的资源利用率和各类工作负载实际的运行状况有助于更好地了解各类资源的分配情况,还可以对目前的调度算法提供有效的改进建议。
本文深入分析了阿里巴巴数据中心中某一个含有4 034 台服务器的集群在8 天时间内所有服务器的资源利用情况以及在线服务和离线任务的运行状况。通过对该数据集的分析,主要贡献有:
(1)通过对整个集群中所有在线任务以及离线任务资源使用情况的分析,总结了工作负载资源使用的一些特点,包括:①从在线服务的运行情况来看,所有容器的平均CPU 利用率存在周期性变化,从每天的早8 点到晚9 点维持在一个较高水平,并且在每天凌晨4 点回落到最低点;②对离线任务来说,发现除去第一天和第八天,剩下6 天中任务提交峰值都集中在每天的同一时刻。其次95%实例的运行时间都在199 s以内,但是有0.052%的实例运行时间在1 h以上甚至会持续几天。
(2)对集群中的批处理作业和在线服务进行了聚类分析,并确定工作负载模式,发现相对高资源利用率的容器占了所有容器的绝大部分,而低资源利用率、短执行时间的实例则占了总实例的绝大部分。首先选择有效的特征指标作为聚类的维度,然后使用-means 算法识别每个维度的聚类边界,并对其进行聚类分析。
1 背景介绍
1.1 阿里巴巴任务调度体系
如图1所示,阿里巴巴通过两个调度器Sigma和Fuxi来调度集群中的在线服务和离线任务,其中Sigma负责在线服务的调度,Fuxi负责离线任务的调度。
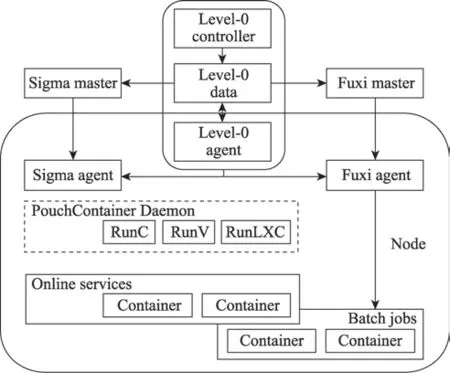
图1 混部集群架构Fig.1 Mixed cluster architecture
阿里巴巴的在线服务都由其自建的Pouch容器进行托管并由Sigma 负责Pouch 容器的部署决策。这些在线服务都是面向用户的,因此要求满足低延迟和高性能的需求。通过阿里巴巴内部几年的实践以及多次双十一流量高峰的考验,Sigma 已经证明了其大规模容器调度的能力。
Sigma由Alikenel、SigmaSlave、SigmaMaster三层大脑联动协作。其中,Alikenel 部署在每一台物理机上,它能够增强内核,在资源分配和时间片分配上按优先级以及分配策略进行灵活调整。SigmaSlave 可以在本机对容器进行CPU 分配、应急场景处理等。本机Slave会对时延敏感型任务的干扰快速做出决策和响应,从而避免因全局决策处理时间延长带来的业务损失。SigmaMaster 是一个中心大脑,负责统揽全局,能够为大量物理机上容器部署进行资源的调度和分配以及算法的优化决策。
Fuxi 负责管理非容器化的离线任务,而离线任务主要是复杂的大规模计算类应用程序,因此Fuxi采用数据驱动的多级流水线并行计算框架,与Map-Reduce、Map-Reduce-Merge等批处理编程模型兼容。
最终,整个系统通过Level-0 策略机制来协调和管理两种类型的工作负载,使其能够尽可能合理地部署在同一集群中。
1.2 数据集基本介绍
cluster-trace-v2018 数据集记录了4 034 台服务器在8 天时间内的运行状况。在后续计算中假设该数据采集时间从每一天的0 点开始。该数据集一共由6个文件组成(大约270 GB),具体信息如表1所示。
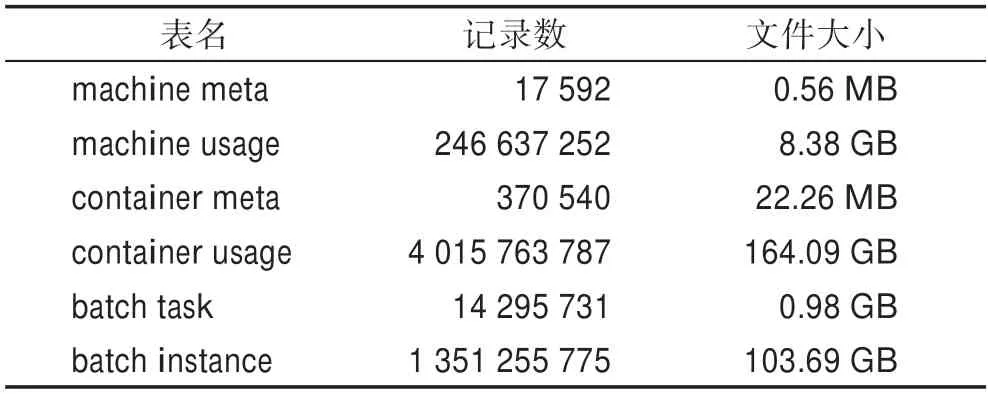
表1 阿里巴巴数据集记录行数Table 1 Alibaba dataset record line number
该数据集主要记录了服务器、在线服务和离线任务的资源配置以及资源使用情况,每个计算节点都配置了一定的资源,监控程序每过60 s 就会采样一次实际的资源使用情况,最后将300 s 内采样值的平均值作为实际值记录到数据文件中。从这些文件介绍中可以得知,对离线任务而言,一个批处理作业就代表一个离线任务,每个批处理作业都运行在物理机上,离线任务上的三级任务模式关系图如图2 所示,每个批处理作业(job)由多个任务(task)构成,而每个任务由多个实例(instance)构成,每个实例都配有一定数量的资源(例如CPU、内存等)。实例是批处理作业的最小调度单位并在某一个特定节点上运行。每个实例的资源配置和实际运行情况都会在数据文件中有相应的记录,例如开始时间、结束时间、运行状态(成功或者失败)、平均CPU 使用核数和最大CPU 使用核数等。对在线服务而言,其应用程序都是运行在容器中,因此可以通过容器的资源使用情况来分析应用程序的性能。容器的数据包括请求的资源量、实际的资源使用率、cpi 和mpki 等。分析这份数据将有助于解决大型IDC 所面临的在线服务和离线任务混合部署的问题,同时还可以对在线服务和离线任务之间的协同调度提供合理的建议。
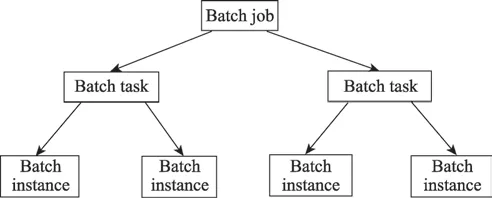
图2 离线任务上三级任务模式关系图Fig.2 Three-level task mode relationship diagram on offline tasks
2 在线任务基本情况
2.1 服务器上容器基本分配情况
首先根据container_meta.csv 文件统计了每台服务器上容器数量的分布情况。container_meta.csv 中显示有4 005 台服务器部署了容器,整个集群中所有服务器一共部署了71 476 个容器。具体统计信息如图3、图4 所示,在一台服务器上最多部署35 个容器,最少只部署1 个容器,80%的服务器部署的容器数量在23 个以内,大部分服务器部署的容器数量集中在8~25。

图3 每台服务器包含的容器数量Fig.3 Container amount of server

图4 不同的容器数量对应的服务器数量Fig.4 The number of servers corresponding to different container number
实际上像Sigma 这样的在线任务调度系统在为长时间运行的容器执行调度时需要考虑多种因素,包括应用程序的优先级,应用程序是否能容忍资源超额分配等,这种多约束多目标优化会导致容器数量在整个集群中不均匀分布。
container_meta.csv 文件中记录的容器有4 个状态,分别是started、allocated、stopped 以及unknow,经统计,有71 342 个容器在这8 天内只出现过一种状态,其中70 903 个容器在8 天里始终保持started 状态,有133 个容器出现过两种状态,并且这些容器都出现过started 状态,只有id 为c_13222 的容器出现过三种状态。具体统计数据如表2~表4 所示。

表2 只出现一种状态的容器数量Table 2 Container amount with only one state

表3 出现过两种状态的容器数量Table 3 Container amount with two states

表4 出现过三种状态的容器数量Table 4 Container amount with three states
总体来看,数据集中绝大多数容器在8 天内始终处于started 状态,可以得出:绝大多数容器的生命周期大于8 天,而且可能会在更长一段时间内继续存活。并且在这期间,新容器部署的频率较低,说明新上线的服务和容器出现故障的几率较低。8 天时间里只有5 台服务器上出现过不明状态的容器,而且不明状态的容器数量均分布在不同服务器上而且数量都为1,这表明大多数容器在8 天时间里都是在稳定状态下运行的。
还统计了容器的内存请求量的分布情况,如图5所示,容器的内存请求量共有23 种情况,且内存请求量的值都已经过归一化处理,其中容器的最大内存请求量为25,最小为0;内存请求量为1.56 的容器数量最多,有54 397 个,其次是内存请求量为3.13,容器数量有13 022 个,这两个内存值对应的容器数量共占总容器数量的94.3%,说明大部分容器请求的内存为1.56 和3.13。

图5 不同内存请求量对应的容器数量Fig.5 Container amount corresponding to different memory requests
2.2 容器资源使用情况
根据container_usage.csv 文件统计显示,在第一天中并没有容器资源使用情况的数据,故统计的是第2 天到第9 天这8 天内容器资源利用率的分布情况,结果如图6 所示。
根据统计分析得到以下结论:(1)8 天时间里在每天凌晨4 点,在线任务的平均CPU 利用率都达到一天内的最小值,说明这个时间对在线任务的访问量较低;(2)大部分在线任务的内存利用率较高而CPU利用率和磁盘利用率较低。
以小时为单位统计了所有容器的资源利用率的最大值、平均值、最小值随时间的分布情况,图6 清楚地反映了在第2 天至第9 天时间内容器运行时的资源特征。从图6 中可以看出在线任务的平均CPU 利用率随时间呈现周期性变化,并且根据统计数据,平均CPU 利用率在5%~13%,在时间戳为28、52、76、100、124、148、172、196 时,平均CPU 利用率都处在波谷的位置,即在每天凌晨4 点,在线任务的平均CPU利用率都达到一天中的最小值。而在每天的早上9点至晚上9 点,容器的平均CPU 利用率都处在一个较高的阶段。平均内存利用率随时间变化的趋势比较平缓,在79%~83%上下波动,而平均磁盘利用率则波动幅度相对较大,在5%~19%变化,且没有明显的规律性。对于资源利用率的最大值、最小值分布,发现CPU、内存和磁盘利用率的最大值、最小值都是一个极端值,分别是100%和0%。
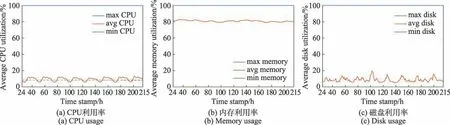
图6 在线任务的资源利用率随时间变化情况(第2 天至第9 天)Fig.6 Resource usage of online tasks changes over time(Day 2—9)
为了进一步展现在线任务资源利用的差异性,统计分析了容器在不同资源利用率下的数量分布情况,结果如图7 所示。发现绝大部分容器都有内存利用率较高而CPU 以及磁盘利用率较低的特性。并且CPU 和内存利用率分布图符合指数分布,磁盘利用率分布图符合高斯分布。
图7(a)~(c)分别是在线任务不同平均CPU 利用率、平均内存利用率和平均磁盘利用率对应的容器数量分布以及拟合曲线,横坐标为平均资源利用率,纵坐标为对应的容器数量。
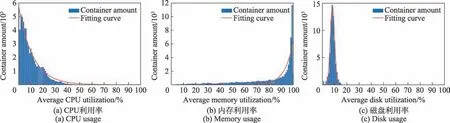
图7 不同平均资源利用率的容器数量分布Fig.7 Distribution of the number of containers with different average resource usage
具体信息统计显示:最大的平均CPU 利用率为100%,最小的平均CPU 利用率为0,平均CPU 利用率的中位值是6.787%,80%容器的平均CPU 利用率在0%~16%。最大的平均内存利用率为100%,最小的平均内存利用率是1%,内存平均利用率的中位值是91.89%,有54%容器的平均内存利用率在90%以上。最大的平均磁盘利用率是99%,最小平均磁盘利用率是0%,磁盘平均利用率的中位值是8.203%,有88%容器的平均磁盘利用率在6%~12%。同时,还对上述3 幅图的分布进行曲线拟合,结果发现图7(a)和图7(b)的分布符合指数分布,且图7(a)的分布其拟合度达到了97.7%,而图7(c)的分布则是符合高斯分布,拟合度达到了99%,具体拟合函数及其参数如表5 所示。

表5 容器资源利用率分布拟合函数以及参数Table 5 Fitting function and parameter value of container resource usage distribution
3 离线任务基本情况
根据batch_task.csv 和batch_instance.csv 这两份文件的记录,总共有4 201 014 个批处理作业被提交,这些批处理作业被划分为14 295 731 个批处理任务,而这些任务最终由1 350 473 907 个实例负责执行。每一个批处理任务至少含有一个实例,并且有一部分大型批处理任务含有的实例数目达到了上亿个。95%的服务器在8 天时间里运行的实例数量在400 000 以内,其中服务器m_2335 运行的实例数量达到了483 998,为所有服务器之最。对集群中所有批处理实例的资源使用情况以及实例的运行时间进行了统计分析,结果如图8~图10 所示。
图8 描述了所有实例在执行过程中所使用的CPU 核数情况,其中横坐标每100 代表一个CPU核。由结果可知95%的实例使用的CPU 核数都在1.1 以内,然而少数实例占用的平均CPU 核数达到了6 以上。由于分配给同一任务中的每个实例的CPU资源是固定的,导致每个实例的CPU 利用率很低。
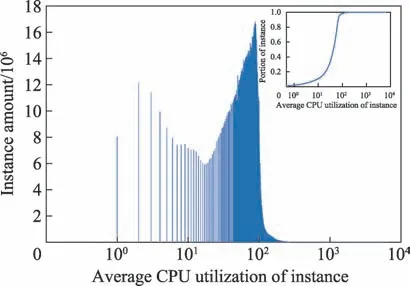
图8 实例的平均CPU 核数使用个数分布图Fig.8 Distribution of average number of CPU cores used by instance
图9 是所有实例的平均内存利用率分布图以及CDF(cumulative distribution function)图,其中横坐标代表的平均内存利用率是经过归一化后的值,纵坐标是对应的实例数量。从图中可以看出,99%实例的平均内存利用率在30%以下,值得注意的是有少部分实例的内存利用率超过100%,说明预分配给该部分实例的内存资源是不合理的。综合图8 和图9 来看,为了提高实例的CPU 利用率以及减少内存抢占情况的发生,调度系统可以在给实例分配资源前使用一些资源预测算法来提高资源分配的精确度。
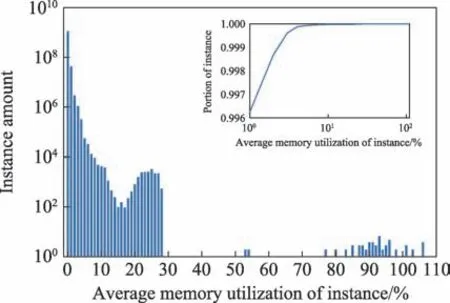
图9 实例的平均内存利用率Fig.9 Average memory usage of instance

图10 所有实例的运行时间Fig.10 Duration of instances
图10是所有实例的运行时间分布图以及CDF图。统计结果显示所有实例中最长运行时间为479 737 s(133.26 h),最短运行时间不到1 s,95%实例的运行时间在199 s以内,99%实例的运行时间在628 s以内,因此大多数批处理作业都是短期作业,但是还有0.052%实例运行时间超过1 h,这部分实例可能会成为整个批处理作业最终完成时间的瓶颈,即整个批处理作业会出现长尾延迟。
图11 显示了整个集群中每小时到达的批处理作业数量分布情况,从图中可以直观看到每小时到达的批处理作业数量存在较大的差异。除了第一天和第四天运行的批处理作业数量较少外,其他6 天每天执行的最大批处理作业数量都保持在68 000 左右,并且在每天凌晨3 点达到该波峰值,而在这个时间戳在线任务的平均CPU 利用率则是接近一天中的波谷值,说明离线任务的急剧增加会影响在线任务的运作。更值得注意的是,在时间戳为116 h 时,批处理作业数目出现了异常的增加,可能是由于该时间段的负载压力测试导致的。因此从批处理作业数量的峰值来看,阿里巴巴的分布式离线任务调度系统Fuxi应当具备相当大的吞吐量,从而能够应对平常时期处于万级的批处理作业数量以及异常时期十万级以上的批处理作业数量。
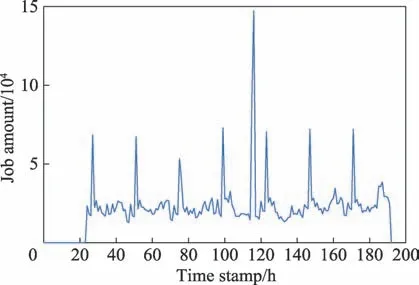
图11 每小时内到达的批处理作业数量Fig.11 Number of jobs arriving in an hour
4 服务器、容器及实例特征聚类分析
-means 聚类算法是机器学习中常用的聚类算法之一,通常用于工作负载聚类,有如下优点:(1)-means 算法是解决聚类问题的经典算法,算法简单,实现容易,收敛速度快;(2)对于处理大型数据集,该算法保持可伸缩性和高效性,复杂度为(),其中是所有对象的数量,是聚类数量,是迭代次数(通常≪);(3)-means 算法的可解释度比较强。因此采用此算法分别对整个集群中所有服务器、在线任务以及离线任务进行聚类分析。
4.1 服务器聚类分析
根据跟踪数据集,在整个集群中一共有4 034 台服务器,服务器的资源利用率在0~100%,-1 和101 是一些无效的值。因此需要对原始数据进行处理,剔除掉无效的数据,最终采用-means 聚类算法对4 021台服务器进行聚类。首先确定以CPU 利用率、内存利用率和磁盘利用率这三种资源利用率作为聚类的特征指标,并采用Calinski-Harabasz Index作为评估标准,Calinski-Harabasz分数值的数学计算公式如下:

其中,为训练集样本数,为类别数,B为类别之间的协方差矩阵,W为类别内部数据的协方差矩阵,tr 为矩阵的迹。评价分数越高,聚类效果越好,服务器在不同聚类数下的评价分数分布情况如图12所示。由图12 可以看出,当评估CPU 利用率、内存利用率和磁盘利用率这3 个特征指标的聚类效果时,值为6 对应的评价分数最高,即将服务器分为6 类效果最好。三维聚类效果图如图13 所示。
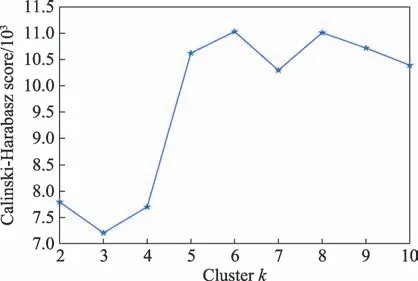
图12 服务器在不同分类数下的评价分数Fig.12 Evaluation score of servers under different classification number
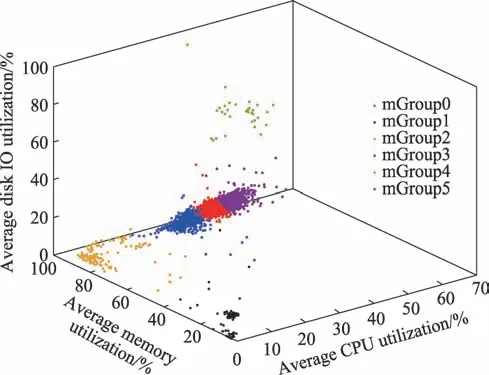
图13 服务器三维聚类效果图Fig.13 3D clustering rendering of servers
分类边界数据如表6 所示。采用-means 聚类算法根据服务器的资源利用情况将4 021 台服务器分为6 类,每一类对应的服务器数量如图14 所示。mGroup0 的服务器数量最多,有1 711 台,mGroup0、mGroup3 和mGroup5 这3 组的服务器数量占总数量的90%以上,mGroup4的服务器数量最少,只有32台。

图14 每个分类中服务器的数量Fig.14 Servers amount in each group
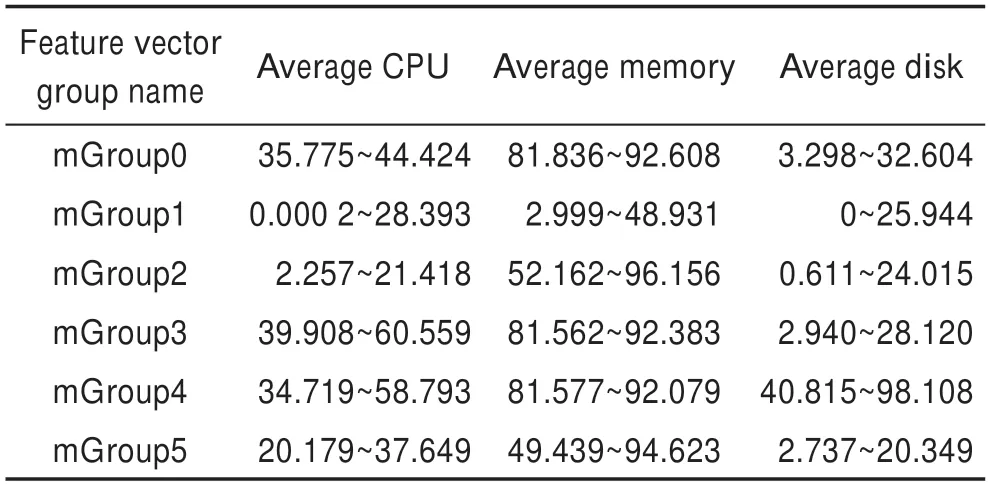
表6 所有服务器特征指标的边界Table 6 Boundaries of feature vectors for servers
使用了CDF 图来描述所有服务器的资源利用率的变化,一种颜色的曲线代表一组服务器的资源使用情况,如图15 所示,横坐标是平均资源利用率,纵坐标是对应服务器数量的比例。由图15(a)可以看出,这6个组在CPU利用分布上都有一定的差异,其中mGroup1和mGroup2相对来说比较近似。由图15(b)可以看出,除了mGroup1,其他组在内存分布上都比较相似,其中mGroup0、mGroup3、mGroup4 这3 个组的内存分布几乎是重合的,而mGroup1 的内存利用率则普遍较低。由图15(c)可以看出,mGroup4 的磁盘利用率特别高,大多数的利用率都在50%~60%,而其他组的磁盘利用率与mGroup4 相差甚大,且这些组的分布比较相近,都集中在15%以内。由图15 可以得到mGroup4 的资源利用率相比较其他组来说较高,而mGroup1 的资源利用率相较其他组较低。
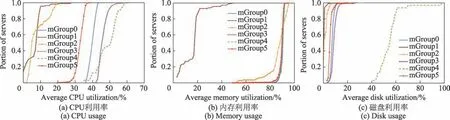
图15 服务器每个分类的平均资源利用率Fig.15 Average resource usage for server groups
通过数据分析可以得到:只有部分服务器存在比较明显的资源使用特征,如mGroup1 中的116 台服务器资源利用率普遍偏低,而mGroup4 中的32 台服务器资源利用率则是较高的。
4.2 容器聚类分析
根据跟踪数据集,整个集群中一共有71 476 个容器,通过对数据的处理,除去资源利用率无效的数据,最终对67 232 个容器进行聚类分析。同样,将平均CPU 利用率、平均内存利用率和平均磁盘利用率作为聚类的3 个特征指标,评估这3 个特征向量在不同值下的评价分数,评价分数分布图如图16 所示。由图16 可以看出,在值为2 时评价分数最高,说明将容器聚类为2 类时聚类效果最好。三维聚类效果图如图17 所示。
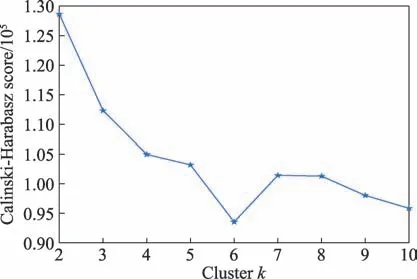
图16 容器在不同分类数下的评价分数Fig.16 Evaluation scores of containers under different classification number
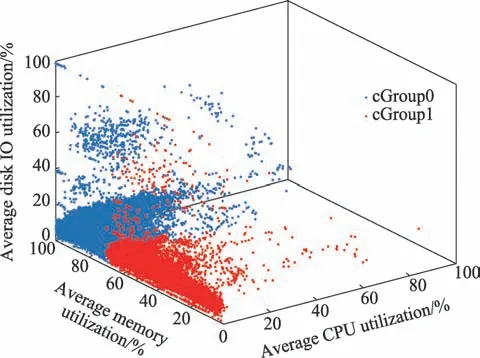
图17 容器三维聚类效果图Fig.17 3D clustering rendering of containers
分类边界数据如表7 所示。采用-means 聚类算法根据容器的资源利用情况将67 232 个容器分为两类,cGroup0 的容器数量为50 533,占了总容器数量的75.2%,cGroup1 的容器数量为16 699。

表7 所有容器特征指标的边界Table 7 Boundaries of feature vectors for containers
图18 是容器每个分类的CPU、内存、磁盘使用情况的CDF 图。此图具体数据显示cGroup0、cGroup1这两组在内存利用率上相差较大,cGroup1 内存利用率主要在20%~60%,而cGroup0 则有70%以上的容器内存利用率在90%以上。然而,这两组的磁盘分布却及其相似,曲线分布几乎是重合的。由图18 可以得出,cGroup0 中容器资源利用率相对较高,而cGroup1 中容器的资源利用率相对较低。

图18 在线服务的平均资源利用率CDF 图Fig.18 CDF of average resource usage for online service groups
4.3 实例聚类分析
根据第3 章统计,batch_instance.csv 文件中一共记录了1 242 094 500 个实例的运行状况,由于实例数量比较庞大,为了方便分析,使用蓄水池抽样算法从所有实例中抽取了10 000 000 个样本进行聚类。蓄水池抽样算法是对一个长度很大(一般内存中放不下)的数据流进行数据采样的常用算法,它对数据流中每个数据只访问一次,并且保证所有数据被选中的概率相同。
与容器的聚类方法类似,将每个实例的平均CPU 使用核数、平均内存利用率和执行时间这3 个维度作为特征指标,并采用-means 算法对抽样的实例进行了聚类分析。如图19 所示,对抽样实例在不同聚类数下的聚类效果进行了评价,可以看到把所有实例分成两类后得到的评价结果最好,因此决定将采样实例分成两类。表8 展示了聚类后每个类中特征向量的边界。

表8 抽样实例特征指标的边界Table 8 Boundaries of feature vectors for instance
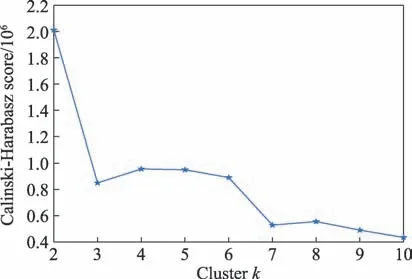
图19 抽样实例在不同聚类数下的评价Fig.19 Evaluation of sampling instances under different number of clusters
通过聚类,将抽样实例分为两类,其中iGroup0中实例数量为321 752 个,只占总数的3.2%,而iGroup1 中实例数量则占了总数的绝大部分。
图20 展示了两类实例在CPU 和内存资源使用以及执行时间上的差异。从图中可以看出,总体而言,iGroup0 中的实例无论在CPU 还是内存资源上的需求都要略大于iGroup1,并且iGroup0 中的实例的执行时间也要普遍大于iGroup1,iGroup1 中90%的实例运行时间都在101 s之内,而iGroup0 组中实例最短运行时间为271 s。

图20 两类实例的平均资源利用率CDF 图Fig.20 CDF of average resource usage for batch instance groups
4.4 各类容器和实例在每类服务器中的分布情况
根据本章前3 节,利用-means 聚类算法将所有服务器分为6 类,所有容器分为2 类,所有实例分为2 类。在本节中,统计了每类服务器中各类容器和实例的数量占比,并得出一些结论。结果如表9所示。

表9 每类服务器中两类容器及两类实例的数量占比Table 9 Proportion of two types of containers and instances in each type of server
具体统计数据显示:mGroup0 和mGroup1 中两类容器的分布占比接近1∶3,mGroup2、mGroup3 和mGroup4 中两类容器的分布占比接近1∶4,mGroup5中两类容器的分布占比近似于1∶2。从总体来看,容器对服务器没有明显的偏好性,每一类服务器上都有两类容器的存在,但是两类容器并没有均匀分布在所有服务器上,这将会增加各类资源管理的复杂度。
此外,可以看到两类实例在各类服务器上的分布较为均匀,每类服务器上两类实例的比值都在1∶24左右,由此推测Fuxi 在进行调度时会把每台服务器上已部署的实例数量纳入考虑范围之内。
综合容器和实例的聚类情况,得出以下结论:
(1)相对高资源利用率的容器占了所有容器的绝大部分,而低资源利用率、短执行时间的实例则占了总实例的绝大部分;
(2)容器和实例进行混合部署的算法,在防止部分服务器(例如mGroup4 中的服务器)成为热点方面,仍然有较大的改进空间。
5 相关工作
对于包括基础设施的设计、容量规划以及成本优化等多个目的的性能工程研究,了解工作负载的特性和行为是必不可少的,过去的许多工作已经对工作负载特性进行了多方面的研究。Shishira 等人对当前工作负载特性的研究方法进行了调查,他们根据处理模型、计算环境、资源利用率和应用程序等对单个工作负载进行分类继而分析工作负载的关键特征。
2011 年随着谷歌集群数据集的发布,许多研究人员对其进行了工作负载分析,寻求资源调度优化的方法。Reiss 等人研究了谷歌集群中工作负载的异构性和动态性。Fan 等人基于谷歌的数据集提出了一种基于功能的通用特征生成方法,可以从原始数据中生成新的特征以用于数据挖掘领域。Reiss 等人在分析了谷歌集群中工作负载多方面的特征后,揭示了谷歌集群在资源调度方面的一些不足之处。
2017 年阿里巴巴发布了他们的集群数据集,与Google 数据集不同之处在于阿里的数据集包含位于同一台服务器的多个容器信息和批处理作业工作负载信息,使得可以对混合部署的工作负载进行分析,了解它们之间的交互性和干扰性,从而提高云数据中心的资源利用率。许多研究人员已经对2017 年阿里巴巴发布的数据集进行了研究,提出了许多独特的见解。Lu 等人通过对阿里巴巴在2017 年年底发布的集群数据集的统计分析,揭示了云数据中心中资源利用率存在的多个不平衡性。Cheng 等人详细描述了阿里巴巴集群中存在的资源过度配置和过度承诺的情况。Deng 等人揭示了阿里巴巴数据集资源利用的一些重要特征。Liu 等人通过弹性和塑性角度揭示了阿里巴巴集群中工作负载有别于谷歌集群工作负载的运行特征。这些特征将有助于为云平台设计有效的资源管理方法,提高工作负载的资源利用率。
还有许多通过机器学习的方法对集群数据进行的研究。Chen 等人对Google 集群数据集进行了分析,根据数据集的时间行为提供了数据集的统计概要,研究发现每个作业具有不同的行为,并利用-means聚类方法对常见作业进行聚类分析,确定常见作业组。Alam 等人对Google 集群跟踪中的工作负载进行聚类和分析。Chen 等人基于阿里巴巴集群跟踪中工作负载的几个典型特征采用-means 聚类算法对在线作业和批处理作业进行聚类分析,典型特征包括CPU 利用率、内存利用率、磁盘利用率以及批处理作业运行持续时间。
本文的工作是阿里巴巴在2018 年年底发布的集群数据集的首批分析之一。从资源利用率、容器部署情况和常见作业聚类分析等多方面分析这个数据集,发现了阿里巴巴集群运行情况的一些规律。
6 结论
本文详细分析了阿里巴巴在2018 年发布的集群的云资源使用情况,并从整个集群服务器的资源使用情况、在线服务的资源使用情况、批处理实例的运行时间以及批处理作业与在线服务的区别等方面得出了一些重要结论。首先,对硬件资源使用情况进行分析,发现该集群中不同的硬件设备在资源利用率上存在显著的空间不平衡和时间不平衡,大部分服务器以及容器都有内存利用率较高而CPU 利用率和磁盘利用率较低的特性。由此,推测Sigma 在分配新的容器时会优先考虑服务器上的内存使用情况而非CPU 分配情况。其次,通过-means 机器学习算法分别对集群中所有服务器、在线任务以及批处理作业进行聚类分析,确定了常见的作业组,发现相对高资源利用率的容器占了所有容器的绝大部分,而低资源利用率、短执行时间的实例则占了总实例的绝大部分。本文提出的发现和见解可以帮助数据中心操作员更好地理解工作负载特性,从而通过优化调度算法提高资源利用率。
猜你喜欢
当代陕西(2019年13期)2019-08-20 03:54:22
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
电力工程技术(2014年5期)2014-03-20 14:19:36
测绘科学与工程(2014年5期)2014-02-27 07:06:14
计算机应用文摘·触控(2009年15期)2009-09-27 07:07:14
电脑爱好者(2009年13期)2009-07-07 09:52:52
计算机应用文摘(2009年15期)2009-04-29 02:58:20
计算机应用文摘(2009年17期)2009-04-29 00:44:03
计算机应用文摘(2005年21期)2005-04-29 00:44:03
