
双损失估计下强化学习型图像匹配方法
2022-04-09 07:05:50谌钟毓谢剑斌熊风光况立群
计算机工程与应用 2022年5期
谌钟毓,韩 燮,谢剑斌,2,熊风光,况立群
1.中北大学 大数据学院,太原 030051
2.国防科技大学 电子科学学院,长沙 410073
如何对多幅图像进行精确匹配是计算机视觉中的一个重要问题,最近邻匹配[1]是一种常见的匹配方法,并且产生了不少的改进算法。然而,这类匹配方法通常需要检索较多的邻近点并从中求解出最优的匹配块,导致匹配量大,计算复杂度高。因此,以稀疏特征点来代替像素块进行图像匹配成为提升计算效率的一个重要手段。特征检测算法可以从二维图像集中创建相似的匹配特征点,然后通过更高层次的视觉管道,完成三维建模、目标检测及物体识别等任务。特征检测算法在计算机视觉研究中受到了极大关注,涌现了诸多经典算法,如SIFT[2]特征检测器、Harris[3]角点检测器、ORB[4]检测器、SURF[5]特征点检测器等。SIFT和SURF虽然检测特征点的准确度较高,但算法运算量大,对边缘光滑的目标无法准确提取特征,而Harris和ORB也有检测精度不够和不具有旋转不变性等问题。近些年来,随着深度学习的出现,一些学者采用神经网络来替代传统方法中自己制作检测器的过程,以训练网络的形式来逐步完成对特征点检测的优化[6]。其中,LIFT[7]检测器按照SIFT的流程对神经网络进行了重构;SuperPoint[8]检测器建立了自监督学习框架,适用于大规模多视图像的特征点检测与描述;DELF[9]检测器则用在图像检索的检测和描述上。这些学习型方法通常是通过提升低层视觉的匹配准确率来进行启发式学习,从而训练得到神经网络的各项参数,性能上常常优于传统自制的检测器。然而,在高级视觉任务中,低层图像匹配准确率的提升未必就能带来更佳性能。例如,SuperPoint检测器在估算图像对的基础矩阵时性能低于传统的SIFT检测器[10],同样,LIFT检测器在三维结构重建方面亦不如SIFT[11]。
针对学习型检测器在高级视觉任务中存在的检测精度不高的问题,本文提出一种双损失误差策略下的强化学习方法,利用端到端的训练方式从两方面联合计算损失效果,从而优化完整神经网络的可学习参数,达到在低级和高级视觉任务中同时提升匹配性能的目标。
1 算法原理
本文提出了双损失估计下强化学习型图像匹配算法,该算法流程如图1所示。首先,对于输入的一对原始图像,采用学习型特征检测器LIFT获得每幅图像的特征点。其次,对特征检测器网络所输出的特征点和描述符赋予其概率上的意义,建立概率上的特征匹配关系。然后,为了提升高级视觉任务的性能,从图像姿态损失和关键点损失误差两个方面设计损失函数,一方面是图像间真实的相对位姿T*与通过管道之后计算所得的相对位姿T′之间的损失差值,另一方面是在图像上利用几何约束关系,计算要查询的点和所预测匹配的关键点之间的损失误差。最后,产生的联合损失误差用于强化学习关键点及其匹配概率,通过多轮强化学习迭代,优化得到可学习网络参数w,最终提高图像间稀疏特征点的匹配精度。

图1 算法流程Fig.1 Algorithm flow chart
本文算法的一个重点是从两个方面来联合设计损失函数,以期在高级视觉任务中取得良好性能,下面分别阐述这两个损失估计策略的技术路线。
首先,通过所在网络中输入的两幅图像I和I′,得到各自关键点的匹配和描述子。将它们放入鲁棒估计器,如RANSAC[12]和五点求解器[13]等,以寻找一个合适的基础矩阵,然后再分解基础矩阵,从而得到一个相对变换的估计T′。本文将上述得到相对变换的估计T′过程理解为一个黑盒,不必关注具体实现细节,以端到端的形式去实现,通过比较真实值T*与估计值T′之间的损失来对网络可学习参数w进行优化。因为所得到的损失不能传回特征检测器用来优化网络参数,所以通过强化学习的方式,即,选择一个关键点或两个关键点匹配为概率动作,利用概率的形式优化网络参数w,并且以抽样的方式采集部分匹配点,以期剔除一些不可靠的关键点,最后,将它们运用在后面估算相对姿态T′的黑盒中。
其次,将图像对间的相对位姿(I,I′,T*)转换为图像对间的极限约束。核心思想是利用相对位姿和相机的固有特性,引入极线损失Lp和返回损失Lr两个概念,计算关键点与极线之间的误差,从而起到优化描述子的作用。
算法的另一个重点是如何概率化关键点和描述符,并通过二者优化可学习网络参数w,从而达到提高匹配精度的效果,该部分内容将在下章详细阐述。
2 概率化描述符和关键点
2.1 概率化描述符
许多研究通过最近邻匹配[14]来建立关键点之间的对应关系,然而这是一个不可微的操作,因此本文将关键点的匹配以概率的形式表现,并以梯度下降的方式来优化所设置的参数。
给定一个网络所预测的描述符F(x;w),其中w表示与特征检测和描述相关的可学习参数。设mij为图像I上的一个关键点xi与另一幅图像上的关键点x′j所对应的匹配。X={xi}为一幅图像的所有关键点的集合。通过描述符之间距离以概率的形式表现,得到了一个图像I中某一点xi与I′上的某一点x′j匹配的概率,这个概率可以表示为公式(1):

2.2 概率化关键点

2.3 损失估计
2.3.1 相对位姿损失估计
这部分算法主要计算出相对位姿真实值T*与通过黑盒管道计算所得值T′之间的误差损失l(M),因此,只需要计算出损失值的本身而不是它的梯度。本文的训练目标是减少采样关键点时的预期任务损失,并根据可学习参数w参数化的概率分布进行匹配,如公式(5):

由上述公式,梯度更新可学习参数w,遵循Williams[15]的经典的强化学习算法如公式(6)所示:

在梯度计算中通过抽样来近似期望,来分别计算关键点和匹配的期望。
2.3.2 几何约束损失估计
几何约束损失估计利用了匹配图像上特征点的极线约束关系。极线约束可以表示为1=0,Fx1可以表示为在I′中与x1对应的极线。将x1作为确定点,x2作为在另一幅图像中与x1最匹配的预测点。此部分是使用概率的方式计算两个损失:极线损失Lp和返回损失Lr,如图2所示。

图2 极线损失和返回损失Fig.2 Epipolar loss and return loss

至此,本文设计出了关键点损失函数。在真实的训练过程中,一个确定点在另一幅图像中是否存在真的对应点还未可知(可能由于遮挡或者裁剪而丢失),因此一味减少这些点的损失会导致错误的训练结果。针对该问题,通过计算总方差重新加权每个点的损失,从而得到最终的加权损失函数,见公式(9):

其中,n为两幅图像中匹配点的数目,α为返回损失函数在整个损失函数中所占的权重。为避免返回损失过大而降低了极线损失的影响,实验中α取值0.7。同时,权值1/σ2(xi)被归一化,使得和为1。这种加权策略削弱了不可匹配训练点的效果,对快速收敛至关重要。
2.3.3 累计损失
估计累积损失可以使用平均绝对误差或者均方根误差,进行损失的累积计算。通过2.3.1小节和2.3.2小节计算出相对位姿和图像几何约束的损失,本文对其平均绝对误差进行相加,并引入几何约束损失所对应的权重δ,以扩大或者缩小该部分对整体的影响,联合损失误差函数如公式(10)所示:

再按照2.3.1节所述的强化学习梯度更新算法,对w进行优化。
3 实验结果分析
实验中使用H-Patches数据集作为验证与测试,部分图像样本如图3中的第1行所示。该数据集包含116个不同场景下的图像,其中57个场景进行了光照变换,另外59个场景进行了视角变换。此外,本文进一步按照特定方法[16]制作了6个室外和3个室内视频数据集,作为训练集使用,部分样本如图3中的第2行所示。

图3 数据集样本图Fig.3 Sample images of dataset
为了评估本文算法的有效性和可行性,本文与现有的一些主流描述符探测器进行性能评估及对比分析。实验硬件环境为Intel®Core™i7-9700 CPU@3.00 GHz处理器、16 GB内存和NIVIDIA GeForce RTX 2070 SUPER显卡。实验软件为:使用pytorch(版本2.7)对LIFT进行训练,并利用openCV对相对姿态和匹配精度进行估计。
3.1 相对姿态误差比较
实验中选取了当前两种主流的、准确度较高的探测器,包括传统RANSAC[12]估计器和基于深度学习的RANSAC(NG-RANSAC)[17]估计器,并对所得出相对姿态误差的AUC指标进行比较。传统RANSAC估计器的实验结果如图4所示,可以看出本文算法的估计精度显著高于传统特征检测器SIFT,以及学习型特征检测器LIFT和SuperPoint。

图4 基于RANSAC的相对姿态精度估计Fig.4 Relative pose accuracy estimation based on RANSAC
由于本文算法为学习型特征检测器,为了充分发挥其自学习的优势,进一步采用学习型估计器NGRANSAC进行相同实验,并加入两个基于CNN的图像匹配方法[18-19]进行对比,实验结果如图5所示。实验结果显示本文算法显著提高了LIFT[7]的相对位姿估计精度,同时其估计精度也略高于SuperPoint[8]、CNN[18]和RCNN[19]。由于SIFT为传统型特征检测器,不支持神经网络引导的估计器NG-RANSAC,故图5中无SIFT实验结果。

图5 基于NG-RANSAC的相对姿态精度估计Fig.5 Relative pose accuracy estimation based on NG-RANSAC
与图4相对比,图5中本文算法精度有了显著提升,为了验证是否是NG-RANSAC对本文的网络改进产生了影响,进一步进行了消融研究,结果如图6所示。在端到端的训练中,要么只更新文中算法,要么只更新NG-RANSAC,要么两者都更新,图6中ours(init)和ours(e2e)分别表示本文算法原始参数值和端对端训练后参数值;而NR(init)和NR(e2e)则分别表示NG-RANSAC估计器的原始参数值和端对端训练后参数值。实验结果表明,在逐步更新探测器参数的同时,AUC的精度也在逐渐提高,说明NG-RANSAC在整个训练过程中适应本文网络并影响着整个网络。

图6 消融实验Fig.6 Ablation study
3.2 匹配性能比较
在H-Patches数据集上对本文算法进行了图像匹配的测试,如表1所示。实验中选取了传统方法和深度学习方法共七种特征检测器,并比较它们在匹配性能上的差异。

表1 图像匹配性能比较Table 1 Image matching performance comparison
由表1可知,在传统方法中,SIFT虽然检测到的匹配点较多,但其匹配精度不高(只有80.5%)且匹配时间较长;而ORB检测到的匹配点少,但运行时间较短,适合使用在需要实时检测的情况下。同时,如表1所示,使用深度学习的特征检测器无论是在匹配精度和运算时间上的效果都比传统方法性能上要优良一些。此外,本文算法将LIFT匹配精度提高了约5个百分点,为高级视觉任务提供了强有力的支撑。
随后,进一步使用LIFT所得的特征匹配点与本文改进算法进行分析比较,实验结果如图7~9所示。在图7中,左图为LIFT所检测到的特征点,右图为本文算法所检测到的特征点。文中的算法为了提高匹配的精度而剔除了一些不合适的关键点,相应地调整了部分剩下的关键点位置,可以达到提高低级视觉任务的准确度从而达到改善更高水平视觉任务的效果。

图7 特征点比较Fig.6 Feature point comparison
部分图像(图3中第2行第1幅图以及第1行前3幅图)的匹配效果对比如图8和图9所示。图8为LIFT算法匹配效果,图9为本文算法匹配效果。从效果图可知,图8中LIFT算法还存在较多不正确的匹配点,且检测到的特征点也较多,加大了探测时间和服务器运行压力,不利于后续在其他视觉任务中的处理。图9中本文算法剔除了一些不利于匹配的关键点,不仅减少了关键点检测时间,还必将改善后续的三维重建等高级视觉任务。

图8 LIFT算法匹配效果Fig.8 Image matching effect of LIFT algorithm

图9 本文算法匹配效果Fig.9 Matching effect of our algorithm
3.3 光照影响
本文数据集中包含了不同光照条件下的图像,整体匹配效果较好。对于低照度情况下的图像匹配问题,有些文献专门进行了研究分析[20],因此,本文就此开展相关实验。一方面,在H-Patches中选取多张不同光暗条件下的同一幅图像验证本文算法。另一方面,使用与表1所做实验相同的图像集和探测器,仅将图像修改为低照度情况,然后分析各探测器匹配性能,实验结果如表2所示。本文算法在不同低照度情况下匹配效果如图10所示。
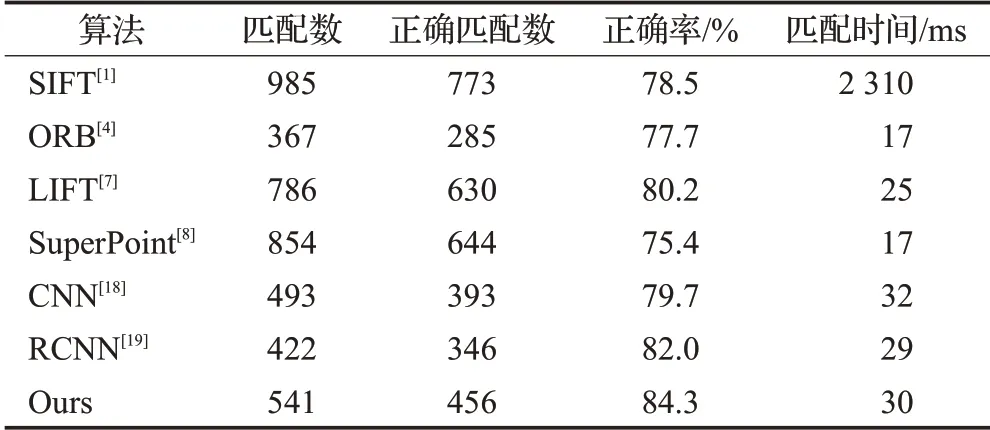
表2 低照度下匹配性能比较Table 2 Comparison of matching performance under low illumination

图10 不同光照下的匹配效果Fig.10 Matching effect under different illumination
从表2和图10中可以看出,由于描述子大多与像素值有关,所以光线较暗情况下各算法的匹配性能都受到了一定程度的影响,但是在不同照度条件下图像上所检测到关键点的个数基本保持不变,匹配对个数随照度的降低逐渐减少,匹配的准确率都略微有所下降,总体上,本文算法在低照度情况下具有较强的鲁棒性,匹配效果依然保持良好。
4 结语
本文提出了一种基于双损失估计策略的强化学习的方法,将特征点以概率方式进行描述与配对,并从相对位姿损失和几何约束损失两个方面来联合训练特征检测器内的可学习参数,增强了神经网络的鲁棒性。同时,训练中通过移除不可靠的关键点和细化关键点位置,提高了配对特征点的配准精度。下一步,将进一步扩展本文工作,将配对关键点应用于基于图像集合的三维模型重建研究。
猜你喜欢
江西教育·职教版(2022年9期)2022-04-29 00:44:03
中学生数理化·中考版(2022年12期)2022-02-16 07:36:56
今日农业(2021年8期)2021-11-28 05:07:50
数学小灵通·3-4年级(2021年5期)2021-07-16 07:46:32
今日农业(2019年15期)2019-01-03 12:11:33
中国交通信息化(2017年9期)2017-06-06 07:14:57
工业设计(2016年11期)2016-04-16 02:49:43
广西民族大学学报(自然科学版)(2015年3期)2015-12-07 00:56:05
中国卫生(2014年2期)2014-11-12 13:00:16
语文知识(2014年7期)2014-02-28 22:00:26
