
面向进制转换和克隆进化的帝国竞争改进算法
2022-04-09 07:04:58黄起彬
计算机工程与应用 2022年5期
李 斌,黄起彬
1.福建工程学院 机械与汽车工程学院,福州 350118
2.福建工程学院 交通运输学院,福州 350118
受自然系统启发的随机性优化算法被称作元启发式算法。根据算法的启发方式,可被分为三类:进化算法、物理算法和群体智能算法[1]。进化算法指灵感来自于大自然生物进化的元启发式算法,例如著名的遗传算法[2]和进化策略算法[3];物理算法指受物理规则或化学现象启发创建的元启发式算法,如Nuclear Reaction Optimization[4]和Flow Regime Algorithm[5];群体智能算法是模仿动物群体行为或人类社会行为的元启发式算法,典型的有蚁群算法[6]和粒子群算法[7]等。此外,不同的元启发式算法之间相互借鉴或融合生成的混合型优化算法,如基于灰狼优化的反向学习粒子群算法[8]和融合猫群算法的动态分组蚁群算法[9],也是现代优化算法中的重要组成部分。
帝国竞争算法(imperialist competitive algorithm,ICA)是一种受历史上帝国殖民主义产生的社会现象启发的群体智能优化算法,由Atashpaz-Gargari和Lucas在2007年提出[10]。ICA主要模拟的社会现象,是帝国主义国家对殖民地社会文化、政治和经济发展的影响和帝国之间的竞争[11]。相比于其他典型优化算法,ICA有着出色的收敛速度和局部挖掘能力,现已被广泛地应用于诸多领域的实际问题中,如医学病理[12]、能源传输[13]、计算机智能[14]、生产调度[15]等,且都取得了较好的成果。然而,面对高维度的复杂问题时,ICA算法极易出现因过早收敛而陷入局部最优的缺陷。
针对上述不足,国内外众多学者在改进ICA方面进行了大量的工作,改进方向主要可分为完善原有机制和融入新机制两种。经典ICA中的同化机制是最有改进潜力的部分:裴小兵等[16]将帝国同化信息记录于概率矩阵模型中,利用区块挖掘和竞争实现殖民地的同化行为;Bahrami等[17]设计了四种混沌映射来改变殖民地向其殖民国家同化时的运动角度,以增强算法对局部最优陷阱的逃逸能力。
通过融合新机制来提高ICA的优化性能是近些年更为热门的改进方向,具体探讨可分为三类。一是受历史真实事件启发所延伸出的新互动机制。基于历史中帝国发现新殖民地而引发的一系列行为,Ardeh等[18]引入探索者和保留策略的概念,使得算法中帝国有机会获得全新的优秀殖民地;Korhan等[19]为算法注入国际主义思想,提出地区统治政策,在算法迭代过程中不断生成一个球形区域,各帝国对区域内部的新国家通过民主协商的方式获得统治权,以此提高算法的搜索能力。二是直接针对算法对象的特性进行新机制的引入。如Xu等[20]发现随着算法的执行,帝国主义国家减少,殖民地也越来越集中,群体多样性降低,故引入高斯变异、柯西变异和莱维变异等变异算子来改变帝国主义者的行为,避免算法陷入停滞。三是混合其他优化算法。Kaveh等[11]将勘探能力较强、但挖掘能力较弱的哈里斯老鹰优化器[17](Harris hawks optimizer,HHO)与局部挖掘能力强、收敛快的ICA结合,实现了一种新的混合算法ICHHO。
尽管以往研究从多个角度改进了ICA的性能,为智能优化算法的改进提供了有益的尝试,但仍然存在一些可以继续改进的空间:
(1)可否着眼于算法机制本身的局限,改进算法收敛过快而陷入停滞的问题。在ICA原有机制下,资源集聚的速度远远高过资源分流的速度,这是ICA的优势所在,也是造成算法收敛过快的主要原因。仅改变单一对象的行为或是增加群体生物多样性是难以打破现有状况的,这就需要从算法框架本身出发,找到克服早熟的演化策略。
(2)现有绝大多数研究主要从单个或少数方面进行改进。算法机制的改进可以是多方面、多元化的。对多种优化目的不同的改进机制进行综合性探讨,有望为ICA的改进提供新的思路。
(3)基于ICA本身的运行特性,以同时提高算法勘探和挖掘能力为目的进行改进。ICA是通过帝国内部以及帝国之间的多种互动行为实现优化,其中能直接影响ICA求解能力的个体对象是帝国主义国家[21]。因此,将有利于提高勘探能力或挖掘能力的改进方法作用于帝国主义国家有望产生较好的改进效果。
上述思想正是本文所提改进算法的理论原点。在ICA的基础上,本文所提的面向进制转换和克隆进化的帝国竞争改进算法(decimal-binary conversion and clonal evolution oriented improved imperialist competitive algorithm,DCCE-IICA)更加注重利用演化种群中各群体的特性,针对现有问题进行改进,其引入和应用的核心改进机制如下:
(1)引入基于进制编码转换的克隆进化策略。DCCEIICA最主要的改进机制是结合二进制基因变异理论[22]与克隆选择算法[23]的优化思想,引入一种基于二进制与十进制编码转换的克隆进化策略。该策略可用于部分解决ICA停滞于局部最优的问题,通过周期性地为演化种群提供一个强大的新发展途径,提高殖民地群体基因多样性的同时,利用帝国主义国家对其附属殖民地的引导能力跳出局部,并通过调整帝国之间的强弱关系来平衡算法资源的流向,延长算法的活力。
(2)将帝国分裂机制[24]融入新算法中。帝国分裂机制在现有研究成果中,有着较好地缓解ICA执行过程中收敛过早结束的能力,并且对改进算法的适用性强,因此将其作为辅助机制融入DCCE-IICA中。
(3)设计了一个较为有效的出界点替换策略。同化机制执行过程中,存在殖民地向其宗主国方向移动后可能超出搜索边界的问题。DCCE-IICA的替换策略能更好地保证群体的多样性。
为了系统性地验证DCCE-IICA的改进有效性与可信性,本文选择经典函数测试集、CEC2017测试集[25]以及CEC2020测试集[26]进行优化实验,面向多个维度下不同类型的函数优化问题来测试和检验DCCE-IICA的寻优能力。在此基础上,将DCCE-IICA在CEC系列测试集上的实验结果,与13个国际前沿算法进行比较,包括2017年进化算法大赛冠军算法LSHADE-SPACMA的变体,来充分证明本文所提算法求解复杂函数时的求解精度、收敛状况和鲁棒性。
1 帝国竞争算法
ICA将D维搜索空间内的任一演化个体当作一个国家,每个个体的函数值被称为国家的成本值(Cost),成本值越小的国家势力越强。每个国家都是对应问题的一个可行解,其位置信息可表示为Country=(x1,x2,…,xD)。ICA的主要执行步骤包括初始化帝国、殖民地同化、殖民地革命、帝国合并、帝国竞争与帝国统一[10,24],相关描述如下:
步骤1初始化帝国。在搜索区域内随机生成一定数量的国家,势力最强的Nimp个国家为帝国主义国家,即殖民国家,然后根据成本值大小瓜分其余的Ncol个国家作为它们的附属殖民地国家,形成最初的帝国格局。
步骤2殖民地同化。殖民地国家向其宗主国所在位置的大致方向靠近。移动距离由下式给出:

其中,yi表示殖民地国家在第i维向量上移动的直线距离;U(a,b)为均匀分布函数;β为同化系数,取值一般大于1;di代表第i维向量上殖民地与所属殖民国家之间的距离。
步骤3殖民地革命。根据概率,一定数量的殖民地可以自主地进行位置上的更新。在同化和革命行为结束后,若帝国主义国家落后于其所属帝国内部的某个殖民地,则该殖民地与殖民国家地位互换。
步骤4帝国合并。当两个帝国过于接近时,更强一方将另一帝国完全吸收,变为自己的殖民地。
步骤5帝国竞争。根据帝国总成本值TC(total cost),最弱帝国的最弱殖民地成为其余帝国抢夺的对象,势力越强的帝国将其占有的概率越大。若帝国失去所有殖民地,则该帝国宣布灭亡,同时作为新的殖民地附属于此次竞争中夺得殖民地的帝国。
步骤6帝国统一。算法在多次的迭代中重复执行步骤2至步骤5,帝国将相继灭亡。当场上只存在一个帝国时,算法结束。
2 面向进制转换和克隆进化的帝国竞争改进算法
DCCE-IICA旨在保留原始ICA局部收敛能力的同时,均衡演化群体的深度挖掘与全面勘探能力,同时具备避免停滞于局部最优解的进化机制,从而提高算法对复杂问题的适用性。相较于传统的ICA,DCCE-IICA的关键改进主要有三点,分别是基于进制编码转换的克隆进化机制、帝国分裂机制和新的出界点替换策略。DCCE-IICA首先引入一种基于进制编码转换的克隆进化机制,周期性地为殖民地国家和较弱的帝国主义国家提供一个新的上升渠道,重塑殖民地国家的基因多样性,同时帝国间也会因为新的势力强弱形势而改变资源转移方向,维持算法活力,避免因帝国的快速消亡与资源的快速集聚而导致算法勘探能力的削弱,帮助算法持续向全局最优解逼近;其次,引入帝国分裂机制,当环境中只剩一个帝国时分裂出新的帝国,让算法持续运行下去;最后,设计了一种更有效的出界点替换策略来弥补经典ICA设计上的漏洞,更有效地保证算法执行过程中演化种群不会因为移动出搜索区域而造成个体多样性的降低。帝国分裂机制和新的出界点替换策略旨在确保个体多样性,两者的引入并不能令算法的收敛能力有很明显的提高[24,27],但可以较好地为DCCE-IICA引入的基于进制编码转换的克隆进化机制提供良好的演化环境。下面对DCCE-IICA的改进进行详细论述。
2.1 DCCE-IICA算法的核心改进机制
2.1.1 基于进制编码转换的克隆进化机制
基于进制编码转换的克隆进化机制,是先对被选中的演化个体二进制化,再进行包含克隆、变异、交叉、选择四个步骤[23]的克隆进化。该思想类似于早期的二进制基因遗传算法。有研究表明,模拟二进制基因的交叉变异方法具有更显著的优化效果[22]。对二进制基因来说,只需要简单的0-1变换便能实现数字上的突变,因此二进制数字串的变异粒度相比十进制更为精细,能产生更多样化的变异个体[27]。目前,模拟二进制基因已在进化算法领域得到了广泛应用[28-29]。DCCE-IICA之所以选择克隆进化算子,是因为克隆进化能高效地用数量较少的帝国主义国家变异出足够多的新个体。这些变异个体能在后续的机制执行中帮助算法提高种群多样性和平衡计算资源的分配。该改进机制的具体步骤如下:
步骤1进制转换。对帝国主义国家每一个维度上的坐标值,从一个十进制数字转变为一条长度固定的二进制数字串。本文计算实验的搜索区域为(-100,100),因此长度为21的二进制数字串基本可以满足本文实验需要的所有变异可能性:除开正负号,整数部分变换后的二进制数字串长度为7,等于规定搜索范围的上限值转换为二进制后的数字串长度;而小数部分的长度则设定为整数部分的两倍。如下是某个国家第i维向量上的坐标值二进制化后的数学表达形式:

其中,xi为某一国家第i维向量上的坐标值,xi,1,xi,2,…,xi,21分别对应二进制数字串的21位数字。
步骤2克隆。各帝国主义国家在完成十进制至二进制的编码转换后,对其进行克隆。各帝国主义国家克隆体数量的计算公式如下:

其中,NCi为第i个帝国的克隆体数量;λ为克隆系数,本文取值0.8;Ncoli为第i个帝国所有的殖民地数量;floor()为向下取整函数。
步骤3变异。对所有克隆体每一维度的数字串,随机选择其中1/3的数字,进行0-1变换。
步骤4交叉。将每一个帝国主义国家对应的所有克隆变异个体视为一个变异族群,族群内部进行高频交叉。高频交叉的方式如下:
(1)根据族群内部的个体数量,随机从内部取出n个变异体作为一组。由下式确定:

(2)每一组按照公式(6)、(7)进行交叉,最终得到新的变异体Cro:

其中,Muti为第i个帝国的变异族群;k为存储数值的临时参数;r1,r2,…,rn用以表示组内不同的个体;下标j表示二进制数字串中第j位数字。
步骤5选择。先将所有的Mut和Cro合并为一个克隆变异群体,再逐个解码回十进制并计算成本值,随后进行下述两个步骤的选择工作:
(1)若当前帝国数大于2,则从克隆变异群体中选出两个最优个体,替换掉两个最弱的帝国主义国家;若此时帝国个数为2,则仅选择一个最优克隆变异体替换较弱的帝国主义国家。ICA算法中的竞争机制令本就发展落后的帝国不断被更强帝国蚕食资源,使得弱帝国更难超越强帝国,算法资源不断单向汇聚,进而陷入局部最优。所以,用优秀的变异个体替换较弱帝国主义国家能够调节各帝国之间的势力分布,实现算法资源真正意义上的互相流通,避免算法因资源的快速集聚而过早地陷于局部最优。同时,此措施也能通过变动较弱帝国的宗主国的所在位置,帮助该帝国全体成员前往开发新的区域,提高算法全局寻优和跳出局部的能力。
(2)克隆变异群体中余下的个体,与环境上所有殖民地一起按成本值从小到大排序,从中选出与所有现存殖民地国家个数相等的最优个体,替换掉所有殖民地国家,并按原先的殖民地分配情况随机性地分配给各个帝国。因为殖民地国家在同化机制的作用下会被不断地汇集至帝国主义国家周边,所以定时重置殖民地国家能够恢复种群的基因多样性,重新布局已过度集中的算法资源。这同样有助于算法避免早熟、向全局最优解逼近。
2.1.2 帝国分裂机制的应用
帝国分裂机制是郭婉青[24]模拟历史上帝国内部不断发展强大的殖民地与殖民国家发生冲突导致帝国分裂的现象,该机制的设计初衷就是为了缓解ICA因过早收敛而陷入局部最优的缺陷。在DCCE-IICA中,帝国分裂机制主要用于维持帝国个数不为一,算法能够多轮持续进化,故此处简化了触发分裂的条件,即在克隆进化机制执行前,帝国数少于2便触发帝国分裂机制。具体步骤如下:
步骤1找出帝国中势力最强的殖民地,将其晋升为帝国主义国家。
步骤2根据新帝国与旧帝国成本值的比值,随机地将旧帝国相应个数的殖民地分配给新帝国。新帝国分走的殖民地个数由下式决定:

其中,Cost()为国家势力值的求取函数,NCnew表示新帝国拥有的殖民地个数,NCall表示现存殖民地的总数。
2.1.3 出界点的新型替换策略
DCCE-IICA借鉴Lin等于2013年提出的扰动ICA[30]中对超出搜索范围的坐标值进行策略性替换的思想,在其改进基础上提出一种新的替换策略,利用出界坐标点与边界的距离,按比率将出界个体映射回搜索空间内部。公式如下:

其中,U和L分别是搜索区域的上下界,M表示搜索范围的中值,xi是同化后殖民地国家第i维的坐标值,//为取余符号。
2.2 算法的设计与实现
DCCE-IICA在实现与执行中遵循如下规则:
(1)以150次迭代为间隔周期,执行基于进制转换的克隆进化机制。此举的目的是给更新了帝国主义国家位置的帝国足够的挖掘时间,充分发挥算法的局部收敛能力。
(2)将最大迭代数(FEsmax)作为算法唯一的结束条件。因为帝国分裂机制的加入,算法收敛的结束与否已不再受到帝国数量的限制。
于是,DCCE-IICA的详细流程如算法1所示。
算法1DCCE-IICA

2.3 算法特性分析
2.3.1 时间复杂度分析
计算成本是限制优化算法应用的一个重要因素。假设国家总数为n,帝国主义国家个数为n1,殖民地国家个数为n2,克隆体个数为λn2。在D维搜索空间内,DCCE-IICA各项机制在单次迭代中的时间复杂度如表1所示。

表1 时间复杂度Table 1 Time complexity
本文中λ取值为0.8,且帝国主义国家的数量远远小于国家总数,故DCCE-IICA单次迭代的时间复杂度为O(11.5nD),略大于基本ICA算法的时间复杂度O(2nD),但并无根本性的增加。表2为多种同类型典型优化算法与DCCE-IICA的时间复杂度对比。
从表2中可以看出,与类似算法对比,DCCE-IICA的时间计算成本较为合理,具有典型的线性时间复杂度,故当算法面向不同规模的优化问题时,具有较好的可用性、适应性与鲁棒性,这对于将DCCE-IICA应用到工程实践问题中至关重要。

表2 多种典型算法的时间复杂度对比Table 2 Time complexity of several algorithm
2.3.2 局部与全局寻优能力及平衡性分析
经典ICA具有较强的局部寻优能力,而DCCE-IICA是在原算法的基础上,周期性地对近乎停滞的演化群体执行克隆进化机制,较好地继承了原算法的局部挖掘能力和求解效率。同时,克隆进化机制也能直接利用较优解群体帮助算法收敛,是DCCE-IICA算法隐含的一个有效收敛模式。
全局寻优侧重的是算法的广度搜索能力,而这正是原始ICA的短板所在。经基于进制转换的克隆进化机制重置后的殖民地国家能够尽可能广泛地遍布搜索空间,并且,克隆进化机制会赋予较弱帝国更强的势力并引导其开采新的区域,原本较强的帝国会变得弱势,进而在下一个克隆进化执行时间点被重置,最终所有帝国都会依次完成从局部跃迁至新区域进行探索和开发的行为,实现全局寻优。
综上所述,DCCE-IICA在提高算法深度挖掘能力的同时,更多地注重修正原始ICA在全局勘探能力上的不足,令局部寻优和全局探索二者在改进后的算法中的获得更加合理的平衡与互补,从而使得DCCE-IICA面对不同类型的解空间时都具有全面、持续和高效的寻优探索能力。
3 计算实验与性能评估
3.1 实验设计
本节的主要目标是通过全面且完整的多个函数测试集来验证和评判DCCE-IICA的优缺点。因此,选择了10个经典测试函数及更具有挑战性的CEC2017和CEC2020三个测试集50个复杂函数进行计算实验,并通过与多种不同类型的前沿优化算法进行对比,来对其性能进行全面评估。
本文所选的10个经典测试函数(详情见表3),除Levy函数(F9)外,全为原点最优问题(即在原点处取到理论最优解),是相对较为易解的一类函数问题。本文将展示30、50和100维三个维度下独立运行100次的实验结果,及与一种在该测试集上表现优异的改进智能算法进行对比。此外,经典测试函数的搜索范围将与CEC测试集一致,将其投射至(-100,100),投射公式如下:

表3 经典测试函数Table 3 Classic benchmark functions

其中,l为经典测试函数原本的搜索上界,x和x*分别为映射前后的坐标位置。
CEC相关数据集通过对测试函数的旋转和偏移将其变为非原点最优问题,大幅提高了求解难度,尤其是在高维情况下。CEC2017测试集中的30个基准测试函数和CEC2020测试集中的10个基准测试函数,都被划为单峰函数、简单多峰函数、混合函数、组合函数四类,如表4所示,更加详细的函数测试集信息请见参考文献[25]和[26]。CEC2017和CEC2020为DCCE-IICA的性能评估提供了一个全面的框架。

表4 CEC2017和CEC2020的基准测试函数分类情况Table 4 Classification of benchmark functions in CEC2017 and CEC2020
基于CEC2017测试集,本节将展示30、50和100维三个维度下DCCE-IICA的执行结果(每一个测试函数独立计算51次),并与7种先进算法的实验结果对比;基于CEC2020测试集,计算实验与结果对比的问题维度则为10、15和20维(每一个测试函数独立计算31次),并与其他6种典型算法的实验结果对比。此外,CEC相关数据集中指定每一次独立运行的最大迭代数随着计算维度的增大而增大,而DCCE-IICA因其收敛速度相对较快,在较少迭代下便能得到较优的收敛精度,故暂将最大迭代数设为固定的10 000次。
数据统计部分,经典函数测试集相关的实验数据为DCCE-IICA所求的实际值;而CEC2017与CEC2020测试集记录的数据为测试函数的全局最优值与算法所求值之间的误差值,若误差值小于10-8,按CEC测试集的要求可直接将其记录为0,默认此时已收敛至全局最优解(以下各统计表格均按照上述规定)。统计实验数据后得到的最优值(Best)、平均值(Mean)和方差(Std)如下所示:DCCE-IICA对经典函数测试集的实验数据见表5,对CEC2017测试集的实验数据见表6,对CEC2020测试集的实验数据见表7。

表5 经典测试函数的求解结果Table 5 Solving results for classic benchmark functions
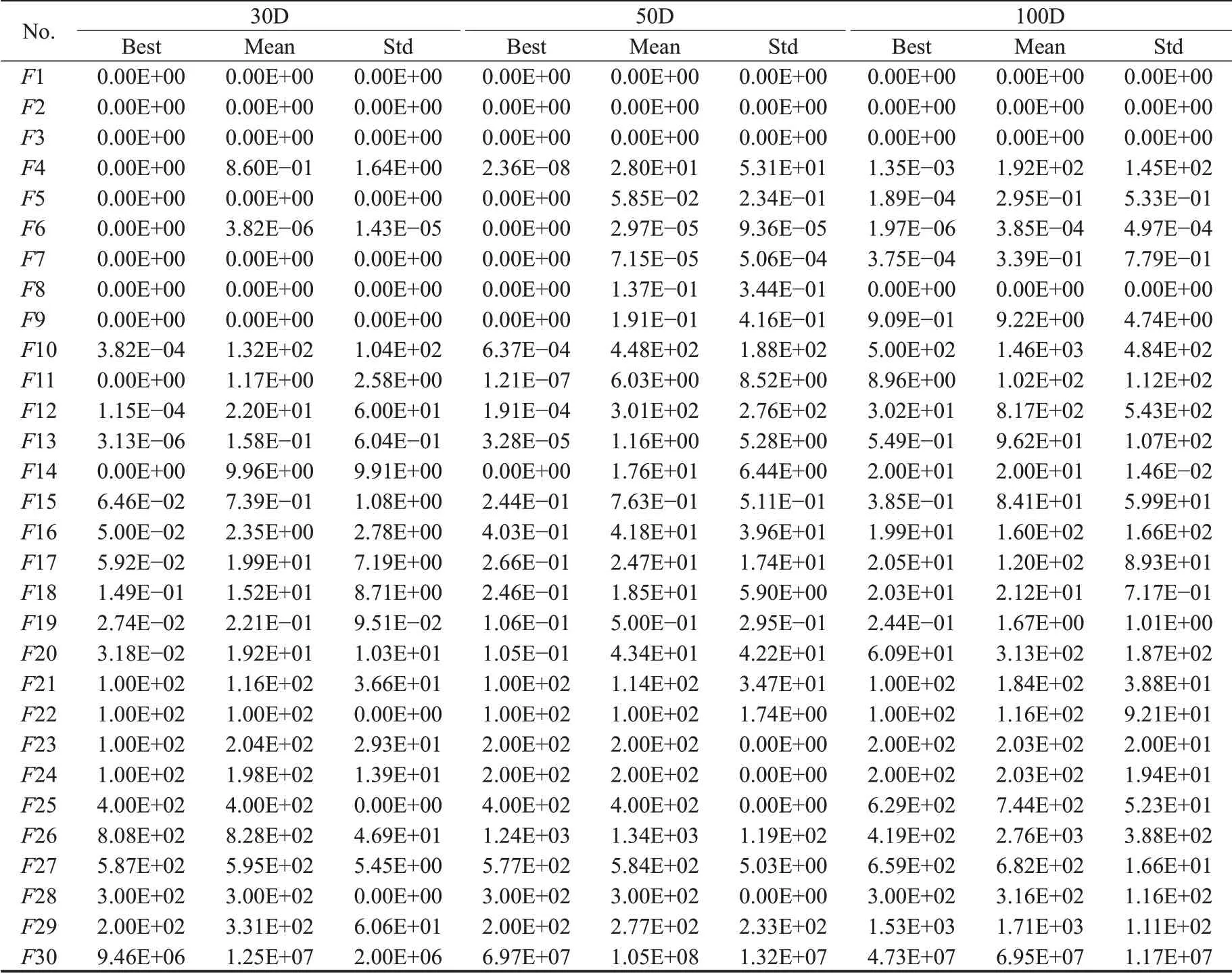
表6 CEC2017测试函数的求解结果Table 6 Solving results for benchmark functions in CEC2017 test set

表7 CEC2020测试函数的求解结果Table 7 Solving results for benchmark functions in CEC2020 test set
DCCE-IICA具有良好的适应性,对硬件平台要求较低。所有计算实验均在同一环境下完成:计算机CPU 2.20 GHz Intel Core i7-10870H、内存16 GB、操作系统为64位Windows 10,编程语言采用Python 3.7。
3.2 DCCE-IICA的参数设置
智能进化算法在解决不同问题时,适当地调整参数是常见且必要的[33]。经过大量实验验证,发现DCCEIICA中只有同化系数β具有较强的敏感性。因此面对不同函数问题时,DCCE-IICA需要对同化系数的取值进行适当的调整。DCCE-IICA的常量参数设置情况为:初始帝国数Nimp为15,初始殖民地总数Ncol为130,克隆系数λ为0.8。同化系数β的取值见表8至表10。
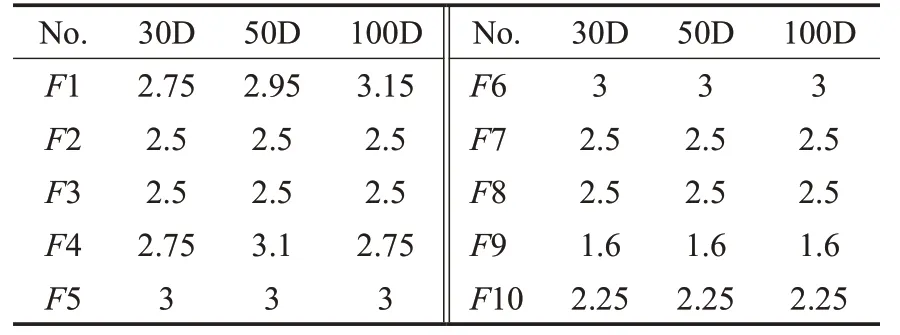
表8 经典函数测试集中同化系数β的取值Table 8 Setting of assimilation coefficientβin classic benchmark functions set
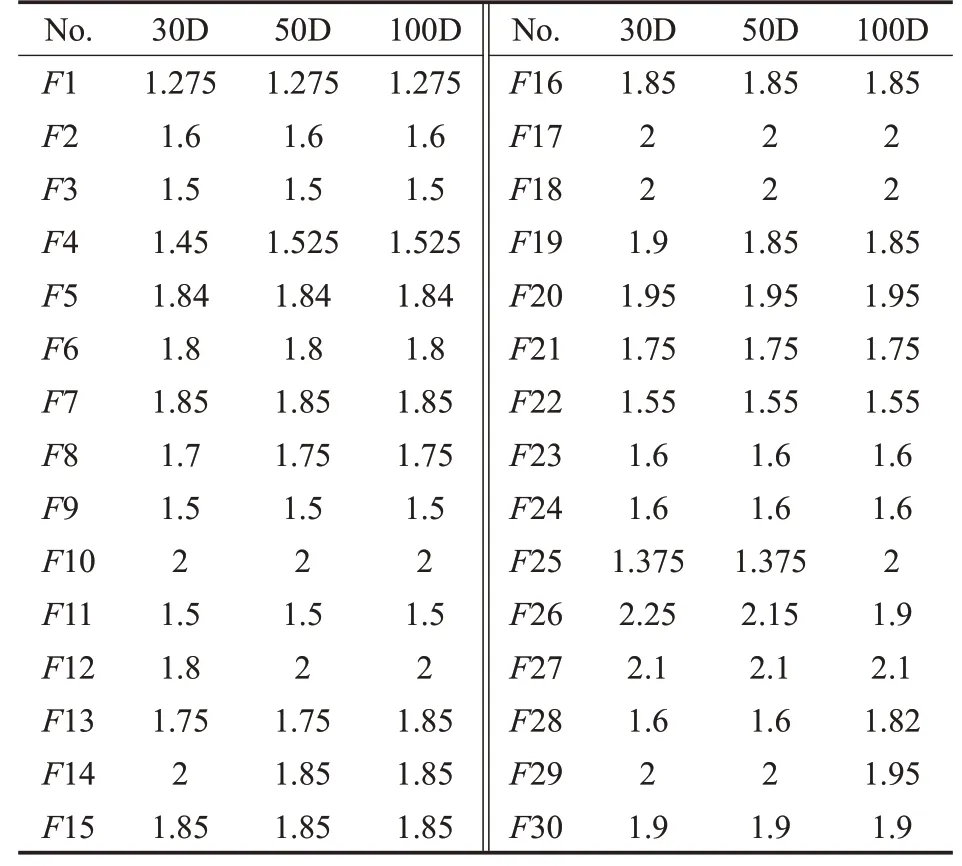
表9 CEC2017测试集中同化系数β的取值Table 9 Setting of assimilation coefficientβ in CEC2017 test set
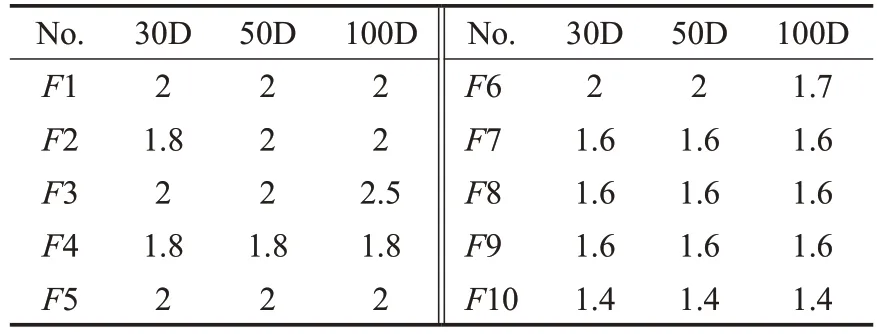
表10 CEC2020测试集中同化系数β的取值Table 10 Setting of assimilation coefficientβ in CEC2020 test set
3.3 基于经典测试函数的算法对比分析
从表5中DCCE-IICA对10个经典测试函数的收敛结果中可以知道,在30维下的收敛精度较为稳定,且大部分函数都能稳定地收敛至全局最优解,但50维和100维下的求解平均值显示出的收敛精度波动较大。对此,表11统计了DCCE-IICA对这10个经典测试函数的寻优率,即在三个维度下的100次独立运行中取得全局最优值的比例。

表11 30、50和100维下经典测试函数的寻优率Table 11 Optimization rate for classic benchmark functions in 30D,50D and 100D %
表11显示,除了F10和100维下的F9外,DCCE-IICA都能够较好地收敛至全局最优解,且都能将寻优率保持在一个较高水平。为了验证本文算法是否能有效应对F10,选择与王贵林等[34]受春秋战国史实启发而提出的SAICA进行对比。SAICA在函数F10上的收敛表现胜过了SaDE(differential evolution algorithm with strategy adaptation)、SE(spherical evolution)、COA(coyote optimization algorithm)与HCOAG(hybrid COA with GWO)、DMS-PSO-EL(dynamic multi-swarm particle swarm optimization based on an elite learning strategy),以及EDA-M/D(estimation distribution algorithm based on multiple elites sampling and individuals differential search)这6种现代算法。表12记录了SAICA与DCCEIICA的对比数据。

表12 SAICA与DCCE-IICA求解F10的实验结果Table 12 Performances for SAICA and DCCE-IICA on F10
表12显示,在三个维度下,DCCE-IICA对函数F10的收敛表现都优于SAICA。综上可知,DCCE-IICA对经典测试函数有着较好的寻优精度和稳定性。
3.4 基于CEC2017测试集的算法对比分析
在本节,著名算法LSHAD的三个变种LSHADE-RSP[35]、LSHADE-SPACMA[36]和jSO[37],及MLS-EDA[33]、RB-IPOPCMA-ES[38]、PPSO[39]和D-YYPO[40]共7种改进算法,将会与DCCE-IICA进行实验数据对比。上述算法的实验数据均来自于已公开发表的文献,并主要用误差平均值(Mean)和方差(Std)来比较不同算法对同一函数求解能力的优劣。平均值能同时体现算法对某一函数的收敛精度和稳定性[33],所以用平均值作为主要的对比参数。表13至表15分别统计了8种算法在30、50和100维的实验数据。
从表13可知,30维下,DCCE-IICA在22个函数上有着众算法中最小的误差值,分别是单峰函数F1、F2和F3,简单多峰函数中的F5、F7、F8、F9和F10,混合函数中的F11、F13、F14、F16、F17、F18、F19和F20,及组合函数中的F21、F22、F23、F24、F28和F29;其中,有多种算法对函数F1、F2、F3、F9和F22也求得了最优值;对其余8个函数,DCCE-IICA的表现不如LSHADE-SPACMA、LSHADE-RSP和MLS-EDA等算法出色。从表14可知,50维下,DCCE-IICA在23个函数上取得了9个算法中最好的成绩,与30维的情况相比,新增了F12、F15和F25,少了F9和F29。但值得注意的是,随着维度升高,DCCE-IICA在本就劣势的F4、F6、F9、F26、和F27上的求解表现与LSHADE-SPACMA和MLS-EDA的差距更大了。并且,表15显示,在100维下DCCE-IICA的优势函数为18个,和50维的情况相比少了F9、F11、F13和F20。

表13 8种算法求解30维CEC2017测试集的实验数据(MeanStd)Table 13 Solving results of 8 algorithms for 30D CEC2017 test set(MeanStd)

表14 8种算法求解50维CEC2017测试集的实验数据(MeanStd)Table 14 Solving results of 8 algorithms for 50D CEC2017 test set(MeanStd)
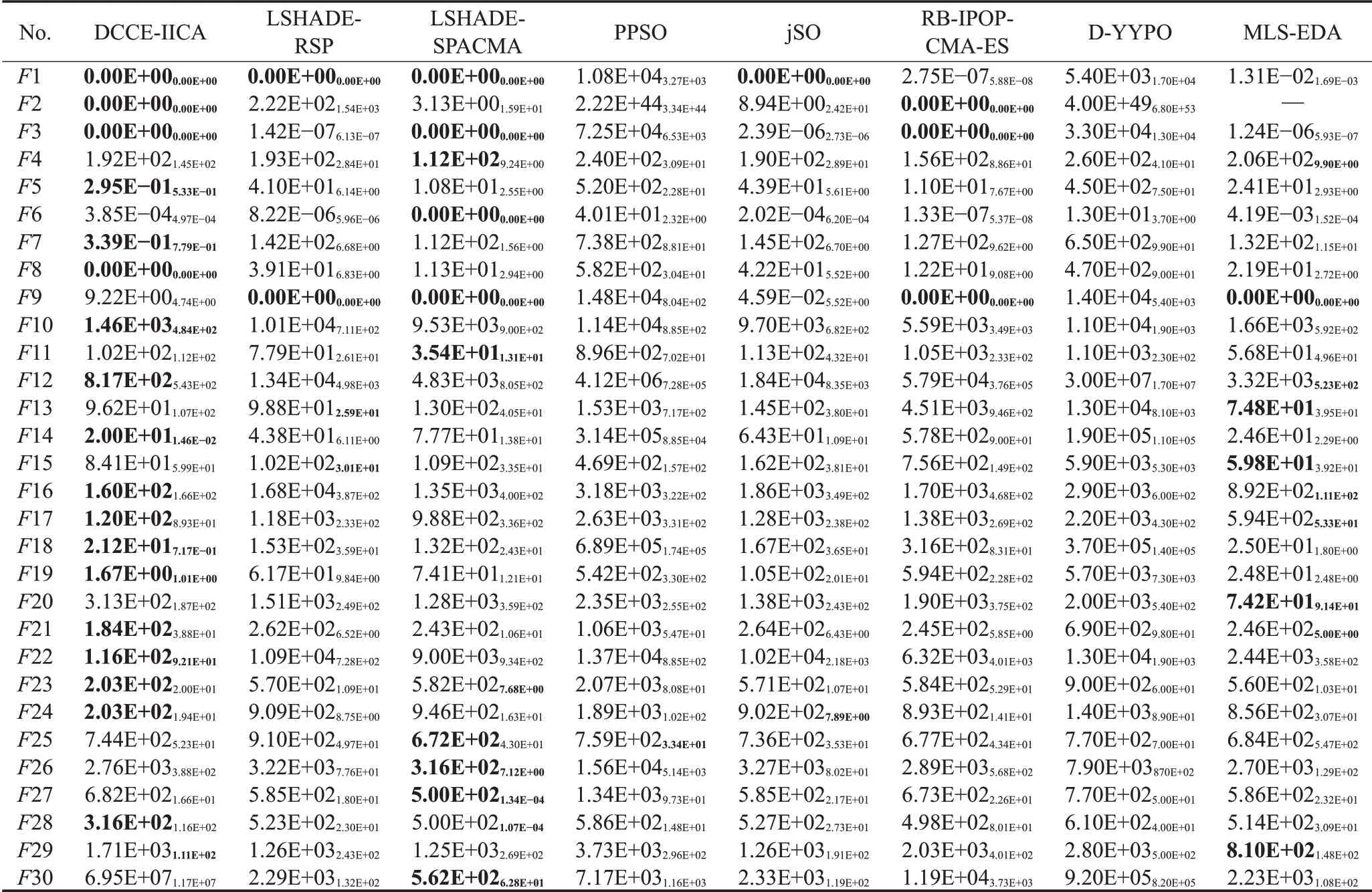
表15 8种算法求解100维CEC2017测试集的实验数据(MeanStd)Table 15 Solving results of 8 algorithms for 100D CEC2017 test set(MeanStd)
为了从实验数据上获得算法性能更加直观的对比结果,这里采用Wilcoxon符号秩检验[41]。在优化算法领域,Wilcoxon符号秩检验被广泛用于多测试集下算法间的两两比较[42]。利用IBM SPSS Statistics 26软件,表16统计了置信度α为0.05时DCCE-IICA与其他8个算法的Wilcoxon符号秩检验结果。
表16中,“+”表示DCCE-IICA在30个测试函数中强过竞争对手的函数个数;“-”则与“+”相反;“≈”表示两算法实验结果相近的函数个数。“R+”与“R-”分别表示优势函数个数获得的秩和与劣势函数个数获得的秩和;当p值低于置信度时,可认为算法取得了显著的优势。表16的数据显示,30和50维下,DCCE-IICA全面优于其他算法;在100维时,DCCE-IICA仅对LSHADESPACMA和MLS-EDA的优势不甚显著。

表16 面向CEC2017测试集的Wilcoxon符号秩检验对比结果(α=0.05)Table 16 Comparison results of Wilcoxon signed rank test for CEC2017 test set(α=0.05)
通过上述数据的比对和分析,可以发现DCCE-IICA算法无法全面取得优势的主要原因,是其对多个组合函数领域的连续优化问题求解效果不佳。为了进一步验证这一论点,将本文算法对CEC2017中30个测试函数的收敛曲线绘制于图1,其中横坐标为迭代数,纵坐标为收敛误差值的自然对数形式,纵轴值至-20即表示误差值已低于10-8。图1中各函数的收敛曲线呈现如下三种趋势:
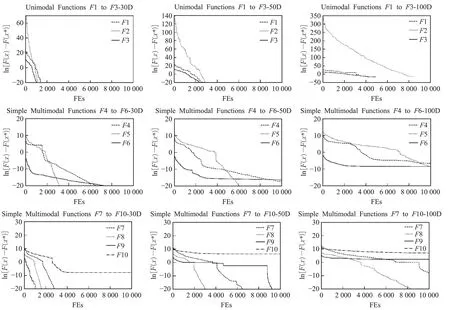
图1 DCCE-IICA求解CEC2017测试集的收敛表现图Fig.1 Convergence performance graph of DCCE-IICA solving CEC2017 test set

图1(续)
(1)曲线在较少迭代内快速下降至X轴。多出现在单峰函数F1~F3和低维度的多峰函数上。
(2)曲线呈不规则的阶梯状持续下降。这印证了新机制能有效地工作,能帮助算法在收敛停滞时跳出瓶颈。这一现象多出现在混合函数和高维的多峰函数收敛过程中。
(3)曲线在前期快速下降,随后便陷入停滞,不再向下探索。组合函数的收敛过程基本都符合这一趋势。
组合函数是由多种函数拼接而成,其每一个局部最优解都被不同特性的搜索区域围绕着[25]。在DCCEIICA算法求解表现不及其他算法的组合函数F25、F26、F27、F29和F30的构成中,都包含了本文所提算法同样求解效果不佳的简单多峰函数F4或F6。F4和F6的特性是局部最优解的数量繁多,十分考验算法的深度挖掘能力,即算法寻得理论最优值的能力。从图1中也可以发现,50和100维下F4和F6的收敛曲线同样呈现出上述的第三种趋势,说明DCCE-IICA在该问题领域上没能获得较为理想的优化效果。
总的来说,DCCE-IICA算法擅长于求解绝大多数单峰、简单多峰和混合类函数问题及部分组合函数问题,但对于具有庞大数量局部最优解的函数问题,容易出现过早陷入局部最优解的现象,因此对该类领域函数问题的适用性还较为有限。
3.5 基于CEC2020测试集的算法对比分析
本节选择了另外6种先进算法与DCCE-IICA进行对比,分别是CSsin[43]、RASP-SHADE[44]、GADE[45]、MP-EEH[46]、AGSK[47]和IMODE[48]。以上算法实验数据同样都来自于已公开发布的文献,且对比流程与规则都同3.4节一致。表17至表19分别统计了7种典型智能算法求解10、15和20维CEC2020数据集的实验结果。
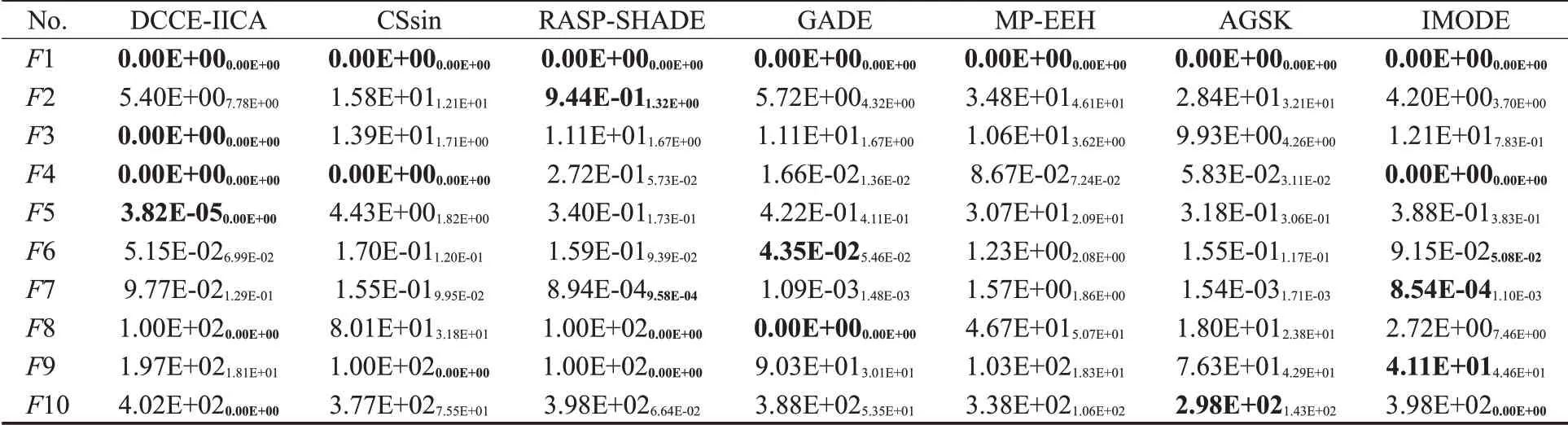
表17 7种算法求解10维CEC2020测试集的实验数据(MeanStd)Table 17 Solving results of 7 algorithms for 10D CEC2020 test set(MeanStd)

表18 7种算法求解15维CEC2020测试集的实验数据(MeanStd)Table 18 Solving results of 7 algorithms for 15D CEC2020 test set(MeanStd)
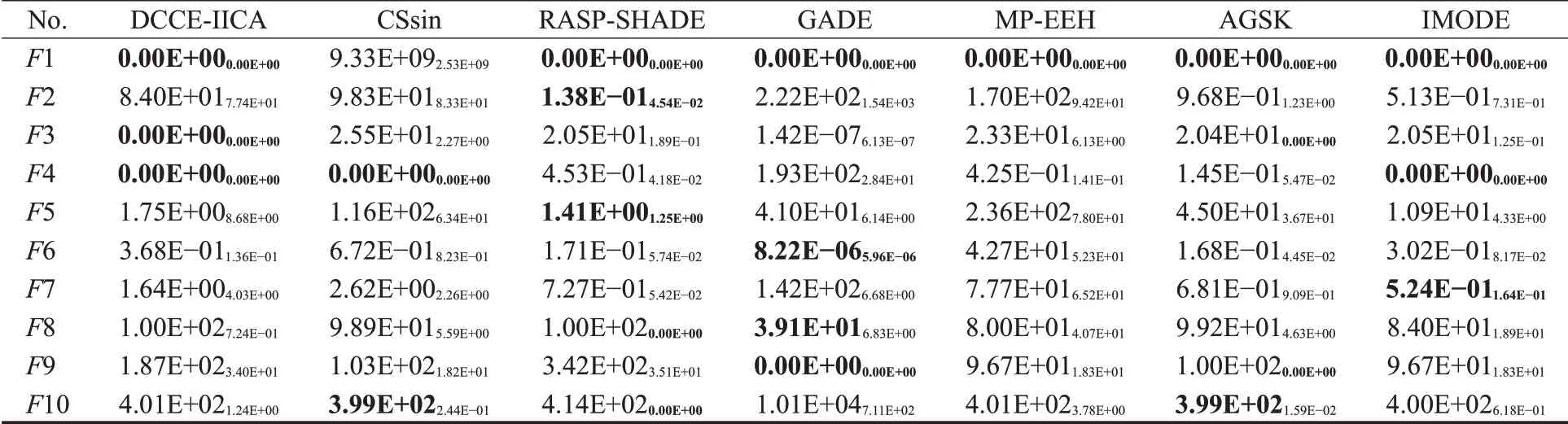
表19 7种算法求解20维CEC2020测试集的实验数据(MeanStd)Table 19 Solving results of 7 algorithms for 20D CEC2020 test set(MeanStd)
由表17至表19可知,DCCE-IICA在三个维度下的收敛表现十分相似:DCCE-IICA在单峰函数F1、简单多峰函数F3、F4和混合函数F5上取得了众算法中较为优异的收敛精度;然而对于其余函数,DCCE-IICA的表现较为一般,且多是差分进化(DE)算法的三个变种RASPSHADE、GADE和IMODE占据优势。
接着,同样使用Wilcoxon符号秩检验来成对比较DCCE-IICA与另外6个算法两两间的性能差异。表20为DCCE-IICA与其他6种算法面向CEC2020测试集的Wilcoxon符号秩检验结果。结果显示,DCCE-IICA在整体上都未能体现出与其他6种典型算法的明显优越性,进一步指出了DCCE-IICA的局限性。
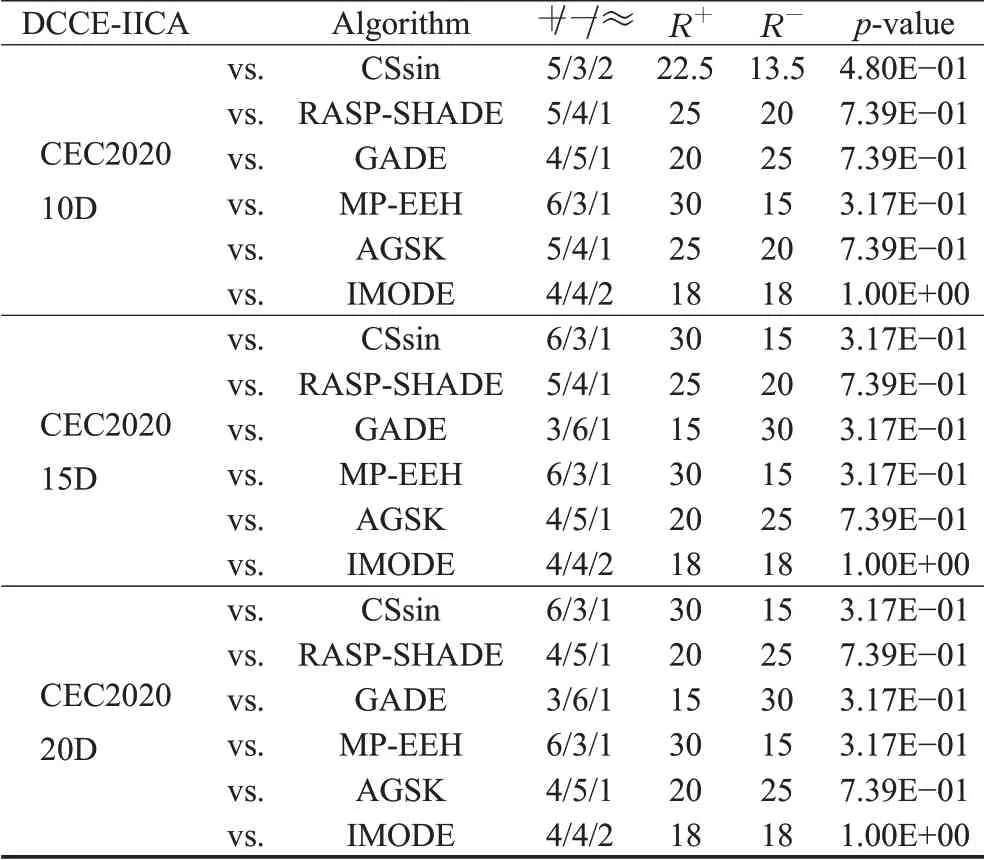
表20 面向CEC2020测试集的Wilcoxon符号秩检验对比结果(α=0.05)Table 20 Comparison results of Wilcoxon signed rank test for CEC2020 testing set(α=0.05)
从上述对比结果中可以发现,DCCE-IICA并没有因为问题维度的下降而提高对组合函数问题的收敛精度,同时,对函数F2、F6和F7的求解表现也是DCCE-IICA无法在Wilcoxon符号秩检验取得优势的主要原因。根据CEC2020数据集里的描述,F2具有局部最优的数量很大、且全局第二优解与全局最优解相距甚远的特性,而混合函数F6、F7和组合函数F8~F10的组成成分中皆包含了F2或CEC2017测试集中的F4[26]。这里依旧用各函数的收敛曲线图作进一步验证。图2为DCCE-IICA求解CEC2020测试集的收敛曲线图。
图2中展现的DCCE-IICA收敛情况基本符合图1总结出的特点和趋势。并且,本节中求解不佳的函数都呈现出3.4节描述的第三种收敛曲线发展趋势,即收敛过早停滞,陷入早熟。
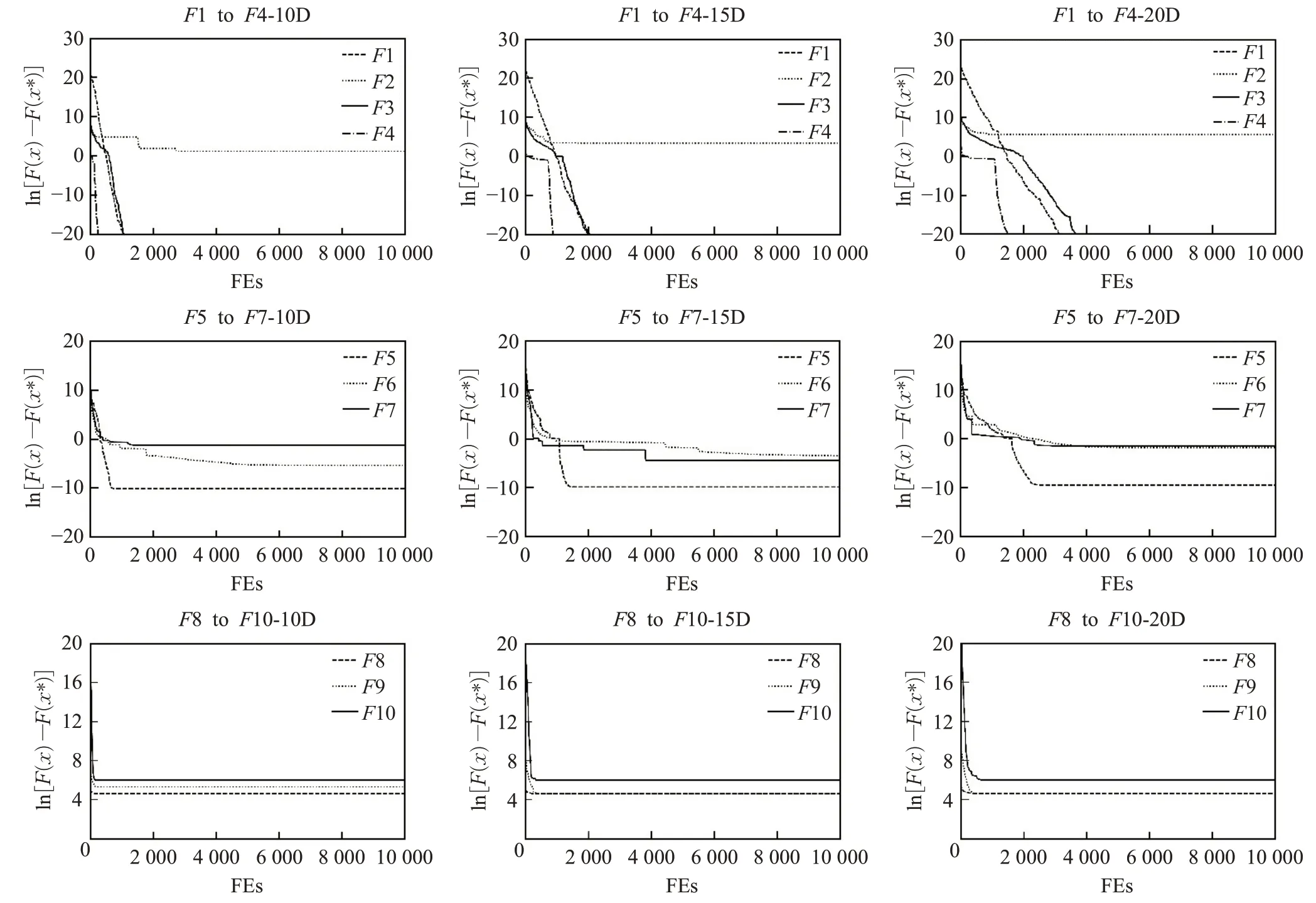
图2 DCCE-IICA求解CEC2020测试集的收敛表现图Fig.2 Convergence performance graph of DCCE-IICA solving CEC2020 test set
从总体看,DCCE-IICA通过基于进制转换的克隆进化机制对殖民地国家定期重置、对帝国势力分布周期性地变动,及在算法近乎陷入停滞时将弱势帝国从局部移至新领域进行开发的措施和策略,确实较好地改善了原算法在全局寻优能力上的不足,使得DCCE-IICA对多数单峰、简单多峰和混合类型的函数问题,甚至包括部分组合函数问题,有着不亚于多种国际著名现代优化算法的深度挖掘能力。
然而,以整个帝国为载体来拓展算法的勘探能力存在着两个问题:一是帝国数量稀少,二是帝国内的个体具有集聚、趋同的特性。这就使得DCCE-IICA对局部最优解数量过多、欺骗性高的多峰搜索空间进行的勘探工作不够全面和细致,进而导致其对搜索空间各区域的探索尝试不足。最终造成了DCCE-IICA对局部最优解数量巨大的函数及包含了该特性的组合函数的优化能力不足。
3.6 DCCE-IICA算法的收敛效率分析
前述的实验分析和结论,实际上都是基于DCCE-IICA对各种函数问题的收敛精度得出的。因此,本节将探讨DCCE-IICA对各函数问题的收敛效率。表21至表23为DCCE-IICA算法对经典函数测试集、CEC2017测试集和CEC2020测试集中各函数收敛至最优解所花费的迭代数。当求得全局最优解或收敛结果不再更新时便可认为算法已完成收敛,并统计多次独立运行中完成收敛所花费的迭代数,记录其算数平均值。

表21 经典函数测试集的收敛迭代数Table 21 Convergent iteration number for classic benchmark function set

表23 CEC2020测试集的收敛迭代数Table 23 Convergent iteration number for CEC2020 test set
表21显示,DCCE-IICA对于F1~F8在不同维度下花费的收敛迭代数十分相近:30维下的收敛跌代数基本在区间(600,800)内;50维则为(700,1 000);100维则为(900,1 300)。与算法所设最大迭代数10 000相比,DCCEIICA对求解效果好的函数问题有着很好的收敛效率。对于非原点最优问题F9,算法在30和50维下求至最优解所花费的迭代数较F1~F8多,但与最大迭代数相比,F9的收敛效率也处于一个较为合适的水平。对于较难求解的F10和100维下的F9,DCCE-IICA能持续收敛至接近最大迭代数,虽说明算法对其的收敛速率慢,但同时也表示改进机制很好地发挥出了避免收敛过早停滞的作用,不断帮助算法持续向全局最优解逼近。
从表22和表23中可以看出,DCCE-IICA对30维及30以下维度的函数求解效率较高。并且,部分DCCEIICA求解效果较好的函数,如CEC2017测试集中的3个单峰函数和组合函数F21~F25,在中高维度下也有着明显较少的收敛迭代数。但从其他函数在中高维度下的收敛迭代数中可以看出,大部分非原点最优函数问题的全局最优解是较难求得的,因此对于此类函数更应该考察的是特定迭代数下的收敛精度,即前述3.3、3.4和3.5节的内容,而本节中的最大迭代数也是基于此设置的。

表22 CEC2017测试集的收敛迭代数Table 22 Convergent iteration number for CEC2017 test set
优化算法的相关研究终归是面向具体的实践应用,因此从算法的适用领域出发来评价一个优化算法的收敛效率更为合适。基于前面三个不同数据集的计算实验及与其他14种先进优化算法的收敛精度对比,确定了DCCE-IICA算法在大部分单峰、简单多峰和混合函数及部分组合函数的求解精度上具有显著优势。而本节的统计结果确切地显示出DCCE-IICA算法对优势领域有着较好的收敛效率,从另一个侧面说明DCCE-IICA对优势领域有着较好的应用潜力。
4 结束语
本文提出了一种面向进制转换和克隆进化机制改进、同时辅以帝国分裂机制和出界点替换策略的改进帝国竞争算法DCCE-IICA,从提高算法勘探和挖掘能力、避免过早收敛和维持个体多样性三个方面改进了经典ICA。DCCE-IICA本质是通过将生物进化机制与社会演变模式进行深度融合,以得出提高群集智能寻优性能的算法设计范式。通过特定维度下经典函数测试集、CEC2017测试集和CEC2020测试集内共50个基准测试函数的实验数据,及与其他14个前沿算法的对比结果,验证了DCCE-IICA较为突出的寻优效率和准确性,初步实现了DCCE-IICA的预期设计目标。
下一步,DCCE-IICA至少还有两个有待深入探讨的研究方向。首先,DCCE-IICA中引入的进制编码转换和克隆进化机制组合是一种兼具提高全局勘探和局部挖掘能力的改进方法,其也有望应用于提高其他群集智能优化算法的性能。其次,DCCE-IICA在优化部分局部最优解数量极其庞大的函数问题时所表现的有限的适用性和深度挖掘能力,亟需在未来的算法改进工作中解决。
猜你喜欢
小哥白尼(神奇星球)(2022年5期)2022-08-15 08:51:18
小哥白尼(神奇星球)(2022年4期)2022-06-06 07:52:32
小哥白尼(神奇星球)(2022年3期)2022-06-06 07:40:08
历史教学问题(2021年4期)2021-11-05 07:02:24
英美文学研究论丛(2021年2期)2021-02-16 00:38:20
辽宁省博物馆馆刊(2020年0期)2020-08-13 09:16:30
物联网技术(2017年5期)2017-06-03 10:16:31
上海理工大学学报(2016年2期)2016-06-02 09:22:25
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25 11:00:22
外国问题研究(2015年4期)2015-03-20 09:54:43
