
面向深度学习目标检测模型训练不平衡研究
2022-04-09 07:03:56贺宇哲梁煜博刘晓晓
计算机工程与应用 2022年5期
贺宇哲,何 宁,张 人,梁煜博,刘晓晓
1.北京联合大学 北京市信息服务工程重点实验室,北京 100101
2.北京联合大学 智慧城市学院,北京 100101
本文针对基于深度学习的目标检测模型在训练过程中存在的不平衡问题进行了研究。目标检测作为人工智能领域的一个重要分支,广泛应用于机器人导航、智能视频监控、工业检测等领域[1]。随着深度学习技术的迅速发展,目标检测模型层出不穷,如YOLO[2]、Faster R-CNN[3]、Mask R-CNN[4]等。虽然它们的模型架构各不相同,但训练基本遵从区域采样、提取特征、根据目标函数进行分类和回归的过程。但在此训练过程中存在不平衡问题导致模型不能达到最佳效果[5]。这种不平衡问题其中包括两个方面:特征图层次的不平衡和目标函数层次的不平衡,而引起这两方面不平衡的原因分别是提取的特征没有被充分利用;目标函数并不是最佳。
特征图层次的不平衡:在网络中,high-level特征中语义信息比较丰富,但是目标位置比较粗略,而lowlevel特征中语义信息比较少,但是目标位置准确。Lin等人[6]提出Feature Pyramid networks利用同一张图片相邻层级之间的特征进行融合,得到的feature maps供给下个阶段进行预测以得到更好的结果,但是只限于相邻层级。Pang等人[7]提出Balanced Feature Pyramid在Feature Pyramid networks进行了改进,以实现对于不相邻层级的特征也能进行关联,达到对特征的充分利用。
目标函数层次的不平衡:检测器需要执行分类和回归两个任务,因此,在目标函数中也包括了这两项。如果它们没有有效地进行平衡,或者其中一个出现偏差,则会导致整个检测性能的降低[8]。因此,要重新对分类和回归这两项进行平衡,以实现目标函数的最佳收敛。
为了有效地改进如上所述模型训练中的不平衡问题,利用Pang等人[7]提出Libra R-CNN的Balanced Feature Pyramid改进FPN以得到更好的特征图,用来解决特征图层次的不平衡。利用Balanced L1Loss[7]作为回归损失,有效调节目标函数层次的不平衡。为了解决Faster R-CNN在训练过程中存在的不平衡问题,本文将上述两个模块加入基于FPN的Faster R-CNN模型中,达到AP是38.5%的结果,并进行了消融实验,同时对各模块逐一进行验证。
1 相关工作
1.1 Faster R-CNN模型
基于深度学习的目标检测方法根据模型训练方式可分为两种类型:One stage目标检测算法和Two stage目标检测算法。Two stage首次由Girshick等人[9]所提出的R-CNN引入,之后He等人[10]在R-CNN的基础上提出SSP-NET。由于R-CNN在候选区域上进行特征提取时存在大量重复性计算,为了解决这个问题,Girshick等人[11]提出了Fast R-CNN。SSP-NET和Fast R-CNN都需要单独生成候选区域,该步骤的计算量非常大,并且难以用GPU进行加速。针对这个问题,2015年,Ren等人[3]在Fast R-CNN的基础上提出了Faster R-CNN。之后在Faster R-CNN加入了FPN[6],使得相邻层级之间的特征进行融合。
Faster R-CNN分为四个部分:首先通过CNN[12]提取原始图片的feature maps,供之后的RPN和全连接层使用。其次,RPN网络通过softmax判断锚点属于物体还是背景,再通过bounding box regression重新调整锚点以获得更加准确的proposals。再次,Roi Pooling通过前面提供的feature maps和proposals,提取proposal feature maps,输入全连接层。最后,利用proposal feature maps判定所属类别,并再次通过bounding box regression获得最终的检测框位置。
相比于Fast R-CNN,Faster R-CNN的所有任务都统一在单一的深度学习框架之下,计算速度大幅度提升。
1.2 训练不平衡问题的解决方法
解决目标检测训练过程中的不平衡问题对于实现最佳训练并充分利用模型架构的潜力至关重要[7]。对于特征图层次的不平衡问题,FPN通过提出横向连接的理念,与相邻层级的特征图进行融合,从而可以丰富low-level的语义信息。之后,Liu等人[13]在FPN的基础上提出了PANet,通过自下而上的方式,从而实现highlevel中能够拥有更加丰富的low-level语义信息。Kong等人[14]提出了一种基于SSD的新型高效金字塔,在当前的主流特征金字塔方法上将特征金字塔转为特征的重组合,通过高度非线性结构使high-level和low-level特征进行融合。Pang等人[7]提出Libra R-CNN的Balanced Feature Pyramid与上述方法观念均不相同,而是利用集成的平衡语义特征来增强原始特征。通过这种方式,金字塔中的每个层级都可以获得来自不同层级的等量语义信息,以此来平衡信息使特征更具区分性。
对于目标函数层次的不平衡问题,Kendall等人[15]已经证明,在基于多任务学习模型中,各个任务的相对权重,对模型的性能产生很大影响。以前的大部分方法注重的是如何提高模型的目标识别能力。而Libra RCNN提出的Balanced L1Loss[7]通过对各个任务进行平衡实现更好的结果。
2 本文方法
由于Faster R-CNN模型在训练过程中会存在明显的不平衡问题,导致目标检测器无法被充分利用。本文主要解决模型在训练过程中的特征图层次不平衡和目标函数层次不平衡。通过Balanced Feature Pyramid进行特征的融合和增强解决特征图层次的不平衡,再通过Balanced L1Loss平衡各任务的损失解决目标函数层次的不平衡。Faster R-CNN[3]在目标检测任务时被广泛应用,并达到了非常好的性能。因此,本文选用Faster R-CNN作为基础检测网络。ResNet网络通过残差块解决网络退化和梯度爆炸问题,如图1所示,首先选用ResNet50作为模型的backbone用来提取图片的feature maps,其中ResNet50结构如表1所示。
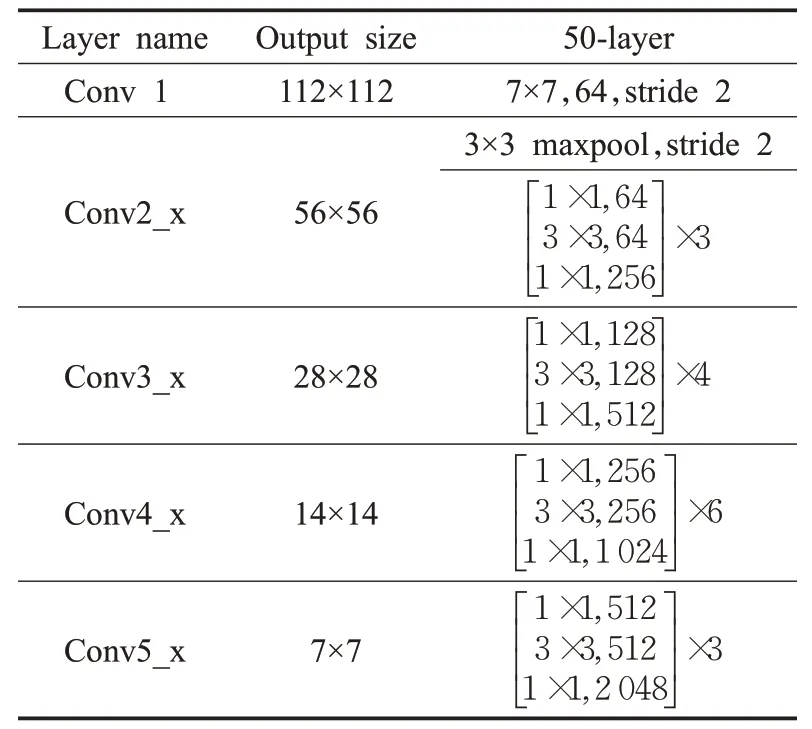
表1 ResNet50网络结构Table 1 ResNet50 network structure
首先通过7×7步长为2的卷积和3×3步长为2的最大池化,这一步极大减小了存储所需大小。之后经过个数分别为3、4、6、3的残差块堆叠,其中1×1卷积对通道数进行降维和复原,有效降低运算复杂度。得到通道数分别为256、512、1 024、2 048,之后接到FPN[6]生成多维度特征表达,输出特征层数为5,通道数为256,但其只在相邻层级上进行特征融合,所以在FPN后接入Balanced Feature Pyramid,如图1(a)所示,通过集成平衡语义使金字塔各层级都可以获得来自不同层级的等量语义信息,从而解决特征图层次的不平衡问题。接着进入RPN网络通过3×3的滑框在特征图上滑动生成由面积128×128、256×256、512×512和长宽比为2∶1、1∶1、1∶2组合成的9个锚框,在5个特征层上的步长分别为4、8、16、32、64。再通过两个全连接层后利用softmax判断锚点属于物体还是背景后,利用bounding box regression重新调整锚点以获得更加准确的proposals。然后进行RoIAlign,输出尺寸为7,通道数为256;最后进入Box Head进行分类和边界框回归,全连接层数为2,输出结果为1×1×1 024;通过softmax计算分类损失,分类器类别数量设置为81,对应COCO数据集的80个类别和背景;将Faster R-CNN中的SmoothL1Loss替换为BalancedL1Loss用来进行回归损失,如图1(b)所示,通过对分类和回归任务的损失进行平衡,解决目标函数层次的不平衡问题。

图1 整体结构图Fig.1 Overall structure diagram
2.1 Balanced Feature Pyramid
由于特征图层级的不平衡表现在高低层级特征的利用上,为了能够利用不同分辨率的特征,如图2所示,将其分为了四步:尺度变换、集成、改进、增强。使用此方法,可以同时融合从low-level到high-level的特征。
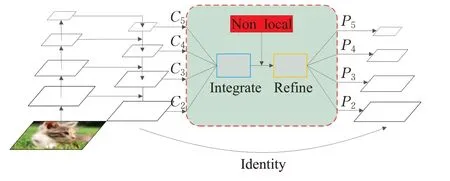
图2 Balanced Feature Pyramid结构图Fig.2 Balanced Feature Pyramid structure diagram
2.1.1 尺度变换、集成、增强
分辨率级别为l的特征表示为Cl,L表示特征层级数量,涉及的最低和最高分辨率层级的索引分别表示为lmin和lmax。为了集成多层级特征并同时保留其语义信息,如图2所示,特征金字塔特征用{C2,C3,C4,C5}表示,它们的分辨率依次减小,而这些特征中的表达存在差异,利用图2的结构将这些特征进行整合,从而起到丰富与平衡特征的目的。首先进行尺度变换,将多级特征{C2,C3,C4,C5}调整为中间大小,即与C4相同,那么对其他的层进行插值与最大值池化归一化到C4对应的尺寸,为集成做准备。再用公式(1)做相加取平均操作获得语义信息进行集成:

集成后得到特征拥有来自{C2,C3,C4,C5}等量的语义信息。最后将集成后的特征进行尺度变换,得到{P2,P3,P4,P5}实现对原始特征{C2,C3,C4,C5}进行增强。这样,每个级别分辨率都能获得来自不同分辨率等量的语义信息,并且在整个过程中没有任何参数的引入。
2.1.2 卷积局部性改进
由于卷积具有局部性,集成后的特征并不是最佳。为了使集成的特征更加具有区分性,采用non-local模块[16]的方式对其进行改进,如图2所示。在此使用了其中的embedded Gaussian non-local attention来改善集成后的特征,non-local方法如公式(2)所示:
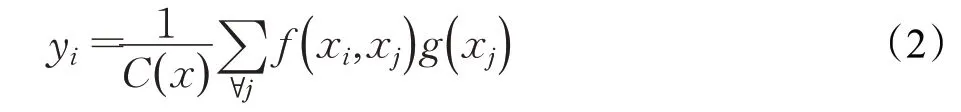
x表示输入信号,y表示输出信号,通过f(xi,xj)表示位置i和所有与之可能关联的位置j的关系,f值与位置j对位置i的影响成正比,如公式(3):


图3 嵌入式高斯非局部块Fig.3 Embedded Gaussian non-local block
输入信号x通过三个1×1卷积将通道数减半来降低计算量分别得到θ(xi)、φ(xj)、g(xj),将维度进行转换以便相乘操作。相乘得到θ(xi)Tφ(xj)进行softmax后与g(xj)相乘得到yi,再将维度转换为H×W×C/2。为了与xi进行相加,通过1×1卷积使yi和xi通道数保持一致,相加后得到公式(5),其中Wz为可学习权重矩阵。

通过这种残差结构可以克服普通卷积的局限性,使所有产生位置关联的特征点都能被利用,将此方法作用于集成的特征图,改进后的特征更加具有区分性,如图4所示。
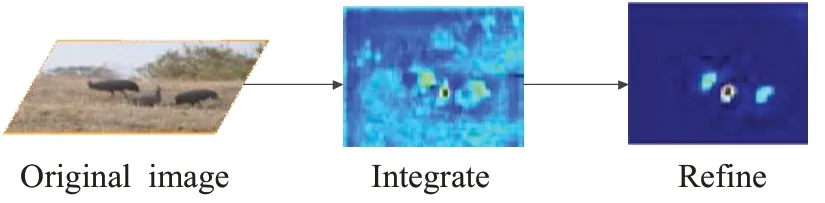
图4 改进前后特征图对比Fig.4 Comparison of feature maps before and after improvement
2.2 Balanced L1 Loss
在检测网络中网络的损失由两个部分组成:分类损失、边界框损失,它们通过参数λ进行调整,一般来讲分类的损失是大于边界的损失的。为了平衡,比较直观的方法就是调整λ的值,但是这会使模型对于异常值变得更为敏感,导致不平衡问题的发生。所以,本文将损失大于等于1的定义为outliers,其将会产生较大的梯度值,会对训练过程造成不平衡,而损失小于1的定义为inliers,其梯度值相对贡献较小。平衡后的L1损失记为Lb。
BalancedL1Loss通过对SmoothL1Loss基础上设置转折点( )loss=1.0区分inliers和outliers。并将outliers的最大梯度值设定上限,将inliers的梯度线变得平滑,这样可以控制outliers的梯度不会太大,同时促进inliers梯度的增长,从而来平衡所涉及的样本,对不同任务的损失进行了平衡,达到对模型更好的训练。BalancedL1Loss改进的边界损失Lloc如公式(6):
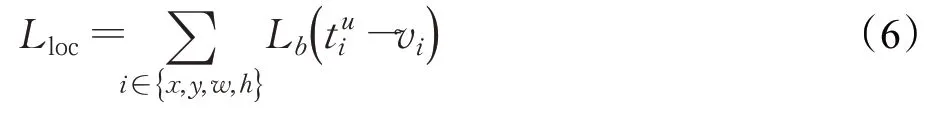
其中,x、y、w、h分别表示锚点i预测的Bounding Box的横坐标、纵坐标、宽和高;表示属于类别u的锚点i预测Bounding Box参数化坐标;vi表示锚点i的Ground Truth参数化坐标。梯度计算遵循公式(7):

基于以上公式,改进的梯度公式如公式(8):

这样,一个很小的α因子即可增加inliers的梯度值,并且对outliers的梯度值没有影响。γ控制总体的提升倍数,以调整回归误差的上限,这可以帮助目标函数更好地平衡所涉及的任务。通过这种方式,达到更好的平衡训练。α=0.5,λ=1.5作为BalancedL1Loss梯度曲线的参数设定,α控制inliers梯度增长,γ控制outliers梯度上限,梯度图像如图5所示,与SmoothL1Loss相比,inliers的梯度有明显提升。
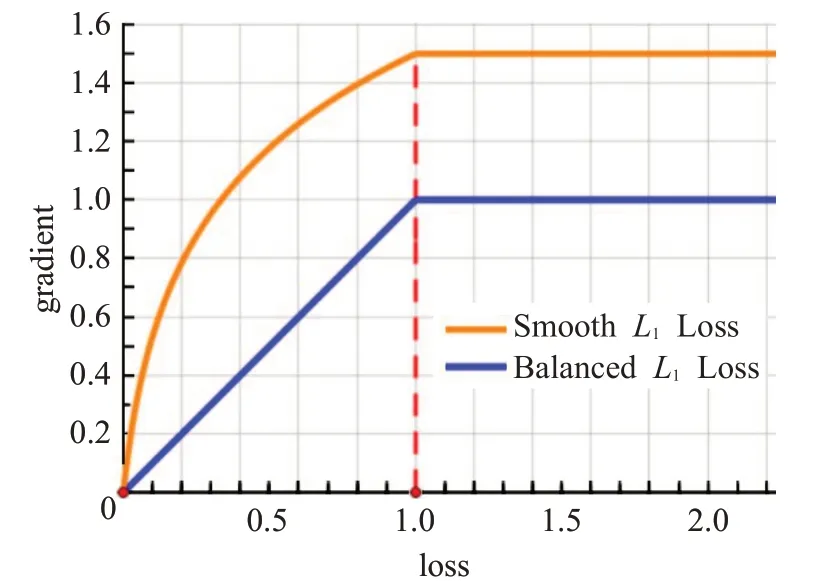
图5 Balanced L1 Loss和Smooth L1 Loss梯度曲线Fig.5 Balanced L1 Loss and Smooth L1 Loss gradient curves
根据公式(8),可以反求出BalancedL1Loss如公式(9):

Lb(x)由公式(8)对x求积分得到。通过b来控制Lb在x=1时具有相同值使分段函数连续。其中常数C由公式(9)在x=1处连续可知C=γ÷b-α,Lb()x通过设置拐点区分inliers和outliers,并且有效促进inliers部分重要梯度的增长,并控制outliers梯度上限,使训练中的分类和回归任务更均衡。由公式(8)函数在x=1处连续可知参数γ、α和b的关系满足公式(10):

本文实验参数设置为α=0.5和γ=1.5。
3 实验结果与分析
3.1 数据集
本文实验统一在MS COCO数据集[17]上进行验证。其中包括用于训练的11.5万张图像(train-2017)和用于验证的5 000张图像(val-2017)。MSCOCO数据集是一个大型的、丰富的目标检测,分割和字幕数据集。图像包括91类目标,328 000影像和2 500 000个label,是目前为止有语义分割的最大数据集,提供的类别有80类,有超过33万张图片,其中20万张有标注,整个数据集中个体的数目超过150万个。在train-2017上对模型进行训练,并且在val-2017上测试最终结果。
3.2 评估标准
评估标准采用MSCOCO的AP值作为指标,默认为各个类别的平均精度值(mAP),包括AP(平均精度)、AP50(IOU阈值为50%的精度)、AP75(IOU阈值为75%的精度)、APS(小目标的精度)、APM(中等目标的精度)、APL(大目标的精度)。评估指标AP的计算方式如公式(11)~(13)所示。其中Precision=在一张图片上类别C识别正确的个数/一张图片上类别C的总个数。

AP=每张图片上的Precision求和/含有类别C的图片数目。
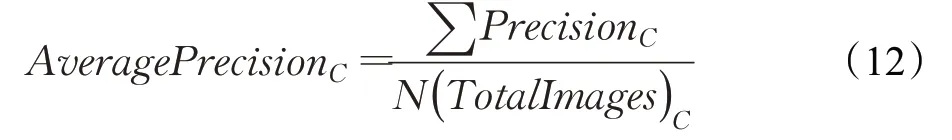
mAP=上一步计算的所有类别的AP和/总类别数目。相当于所有类别AP的平均值。

AP50只计算IOU大于0.5的部分,AP75计算IOU大于0.75的部分,APS计算像素小于32×32的目标,APM计算像素在32×32到96×96之间的目标,APL计算像素大于96×96的目标。其中IOU表示预测的BBox与GroundTruth的交并比,如公式(14)所示:
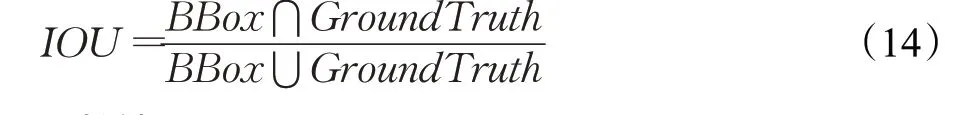
3.3 训练
实验基于PyTorch[18]、CUDA 10.1和mmdetection2.0目标检测库下进行,以基于ResNet-50-FPN[19]的Faster R-CNN[3]为baseline,在单个NVIDIA RTX2070S(一次处理2张图片)上进行12个epochs的训练,使用SGD随机梯度下降法进行模型训练,起初learning rate设为0.002 5,并在第8和第11个epochs后将其降低十分之一,动量因子为0.9,权重衰减因子为0.000 1,防止模型过拟合。输入图片尺寸最大边为1 333,最小边为800,选择ResNet 50作为预训练权重。
3.4 实验结果
将模型与表1中的其他目标检测模型在MSCOCO数据集的val-2017下5 000张图片测试的结果进行比较。实验表明,在相同条件下,本文模型在基于ResNet-50-FPN下AP达到38.5%,比Faster R-CNN结果提高1.1个百分点,比单阶段的RetinaNet提高2.0个百分点,比Mask R-CNN提高0.3个百分点,如表2所示。在对Faster R-CNN进行特征层次和目标函数层次平衡后可以看到结果有明显提升,说明模型在训练过程中存在提取特征未能充分被利用,分类和回归任务之间存在不平衡的问题导致损失函数无法最佳收敛,影响模型达到更好效果,导致最终结果的降低。将模型的检测结果图像与Faster R-CNN进行对比,本文模型能够达到更为精准的检测效果,如图6所示。

图6 检测效果对比图Fig.6 Comparison chart of detection effect

表2 各模型在COCO val-2017上的结果Table 2 Results of each model on COCO val-2017
模型的收敛曲线如图7所示,黄色曲线表示回归损失,蓝色曲线表示分类损失。在训练过程中,损失值都在缓慢下降,并且非常平滑。在经过12个epochs的训练后最终达收敛,收敛的分类损失和回归损失值在0.2附近。
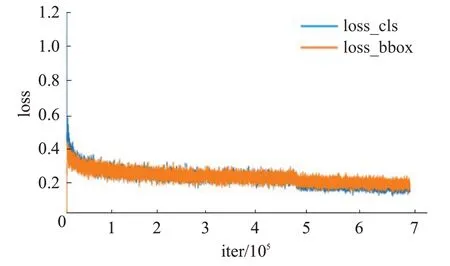
图7 本文模型的收敛曲线Fig.7 Convergence curve of the model in this paper
3.5 消融实验
为了验证Balanced Feature Pyramid和BalancedL1Loss的提升效果,做了以下消融实验。
(1)Balanced Feature Pyramid
为了验证Balanced Feature Pyramid的提升效果,将该方法单独加入基于ResNet-50-FPN的Faster R-CNN中,并且与同样使用特征金字塔作为基础来解决特征图层次不平衡的PAFPN进行对比,如表3所示。在相同的条件下,加入Balanced Feature Pyramid后AP可在MSCOCO数据集上达到38.4%,比baseline高了1.0个百分点,比PAFPN高了0.9个百分点。这说明BFP(balanced feature pyramid)利用集成的平衡语义特征来增强原始特征的方式可以获得更好的feature maps,达到更高的训练结果。
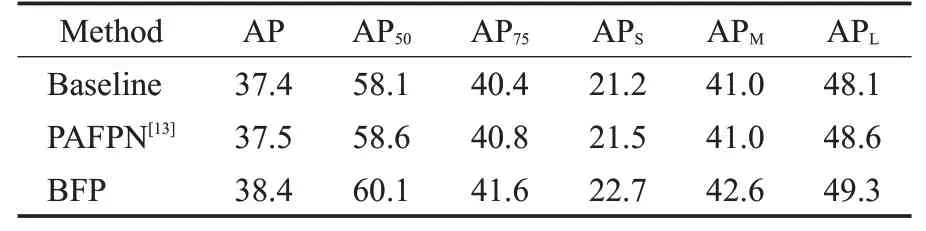
表3 Balanced Feature Pyramid在COCO val-2017上的消融研究Table 3 Ablation study of Balanced Feature Pyramid on COCO val-2017 %
(2)BalancedL1Loss
为了验证BalancedL1Loss的提升效果,将该方法单独加入了基于ResNet-50-FPN的Faster R-CNN中,并且与baseline的SmoothL1[11]函数和解决回归损失的基于IOU的损失函数进行对比,如表4所示。
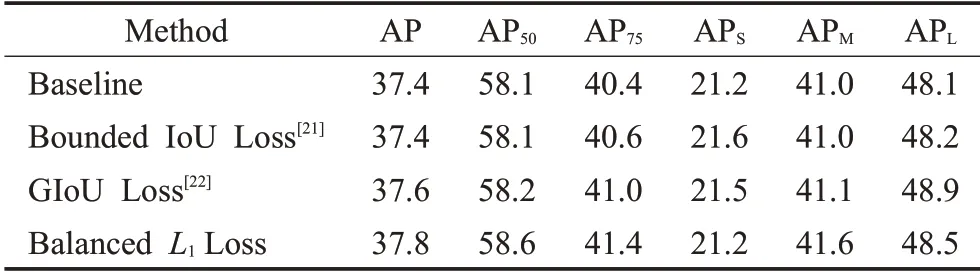
表4 Balanced L1 Loss在COCO val-2017上的消融研究Table 4 Ablation study of Balanced L1 Loss onCOCO val-2017%
在相同的条件下,加入BalancedL1Loss后AP可在MSCOCO数据集上达到37.8%,比baseline高出0.4个百分点。与基于IOU的损失函数解决目标函数不平衡的方法不同,BalancedL1Loss通过对不同任务的损失进行平衡,如图8所示,黄色为回归损失,蓝色为分类损失,通过将分类与回归的任务损失平衡以达到更好的训练效果。
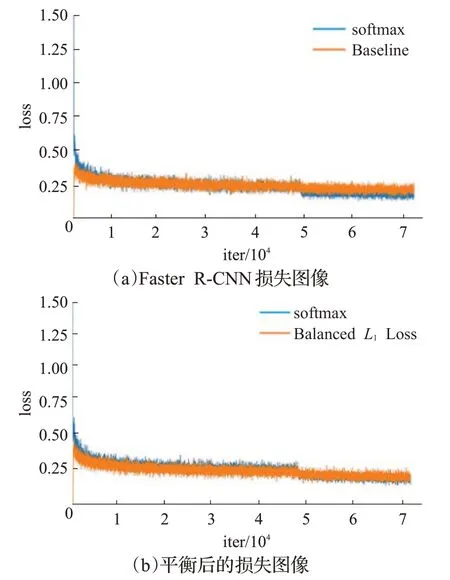
图8 平衡前后损失图像对比Fig.8 Loss image comparison before and after balance
4 结束语
本文针对模型在训练中存在的特征图层次和目标函数层次的不平衡问题,导致无法充分发挥目标检测器的潜力,提出将Balanced Feature Pyramid模块接入FPN,同时将SmoothL1Loss替换为BalancedL1Loss,对Faster R-CNN目标检测框架进行了在特征图层次和目标函数层次的平衡,并且在MSCOCO上验证了本文的实验,实验结果较Faster R-CNN有提升。
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
航天工业管理(2020年9期)2020-12-28 00:38:02
军事运筹与系统工程(2020年1期)2020-09-11 06:41:00
应用数学(2020年2期)2020-06-24 06:02:50
开放教育研究(2020年2期)2020-03-31 01:54:14
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
现代语文(2016年21期)2016-05-25 13:13:44
系统工程与电子技术(2016年2期)2016-04-16 05:17:09
大连民族大学学报(2015年2期)2015-02-27 08:28:11
河南科技(2014年3期)2014-02-27 14:05:45
