
基于BERT和层次化Attention的微博情感分析研究
2022-04-09 07:03傅兆阳
计算机工程与应用 2022年5期
赵 宏,傅兆阳,赵 凡
1.兰州理工大学 计算机与通信学院,兰州 730050
2.甘肃省科学技术情报研究所,兰州 730000
随着互联网的迅猛发展,Twitter、微信、微博等社交网络正潜移默化地改变着人们的生活方式。越来越多的人愿意在网上表达自己的态度与观点,使得互联网用户逐渐由信息接收者转变为信息创造者,并由此迸发出海量带有情绪色彩的文本数据,尤其是微博,已经成为广大网民发表观点和交流信息的热门平台。分析微博评论中蕴含的情感可以获取网民对某一特定话题的观点和看法,实现网络舆情的实时监测。例如:通过分析网民对二胎政策、退休年龄等热门话题的评论,可以帮助政府了解民意,掌握民众情绪;通过分析网民对一些负面消息的评论,可以帮助政府制定相应的引导策略,维护社会的长治久安。
相较普通文本,微博文本更简短、更口语化,网络流行语、表情符层出不穷,呈现稀疏、不规则的特点,使得微博文本情感分析更具挑战性。因此,如何能够快速准确地提取出微博文本中蕴含的情感,对网络舆情的实时监测具有重要的意义[1-2]。
文本情感分析自2004年由Pang等[3]提出后,受到高度关注。早期的研究主要基于规则和基于传统机器学习算法[4]。基于规则的方法主要依靠人工构建情感词典,对文本进行情感词的规则匹配,通过计算情感得分得到文本的情感倾向。该方法实现简单,但受限于情感词典的质量,需要语言学家针对某个领域构建高质量词典,工作量大,且对新词的扩展性差。基于传统机器学习的方法需要人工构造十分复杂的特征,利用支持向量机(support vector machine,SVM)、朴素贝叶斯(Naïve Bayes,NB)、最大熵(maximum entropy,ME)等分类器进行有监督学习,然后,对文本蕴含情感的极性做出判断[5]。基于传统机器学习在小规模数据集上取得了较好的效果,但随着数据量的增大和各种特殊情景的出现,该方法的准确率快速下降,影响使用。
近年来,深度学习快速发展,被研究人员广泛应用于文本情感分析领域[6]。深度学习通过模拟人脑神经系统来构造网络模型对文本进行学习,从原始数据中自动提取特征,无需手工设计特征,面对海量数据的处理,在建模、迁移、优化等方面比机器学习的优势更为明显。常见的深度学习模型有卷积神经网络(convolutional neural network,CNN)和循环神经网络(recurrent neural network,RNN)等。Kim[7]最早提出将CNN用于文本情感分析,在预训练的词向量上使用不同大小卷积核的CNN提取特征,在句子级的分类上较传统机器学习算法有明显提升。刘龙飞等[8]分别将字级别词向量和词级别词向量作为原始特征,采用CNN进行特征提取,在COAE2014语料上提高了准确率。但CNN只能提取局部特征,无法捕获长距离依赖。Mikolov等[9]提出将RNN应用到文本情感分析中。相比CNN,RNN更擅于捕获长距离依赖。RNN每个节点都能利用到之前节点的信息,因此更适用于序列信息建模。但随着输入的增加,RNN对早期输入的感知能力下降,产生梯度弥散或梯度爆炸问题。随着研究的深入,长短期记忆网络(long short-term memory,LSTM)[10]和循环门控单元(gated recurrent unit,GRU)[11]等RNN的变体被提出。田竹[12]将CNN与双向GRU结合,用于篇章级的文本情感分析,提高了模型的鲁棒性。Tang等[13]为了挖掘句子间的关系,提出采用层次化RNN模型对篇章级文本进行建模。
传统深度学习模型将所有特征赋予相同的权重进行训练,无法区分不同特征对分类的贡献度,Attention机制通过聚焦重要特征从而很好地解决了这一问题。Bahdanau等[14]将Attention机制用于机器翻译任务,通过Attention机制建立源语言端的词与翻译端要预测的词之间的对齐关系,较传统深度学习模型在准确率上有了较大提升。Luong等[15]提出全局和局部两种Attention机制,在英语到德语的翻译上取得了很好的效果。Yang等[16]提出层次化Attention用于情感分析任务,进一步证明了Attention机制的有效性。
以上CNN与RNN以及Attention机制相结合的混合模型虽然取得了很好的效果,但大多使用Word2Vector或GloVe等静态词向量方法,不能很好地解决一词多义问题。同一个词在不同的上下文语境中往往表达出不同的情感,例如“这款手机的待机时间很长”和“这款手机的开机时间很长”两句评论中的“很长”分别表示积极和消极的评价。2019年,Devlin等[17]提出BERT(bidirectional encoder representations from transformers)预训练语言模型。该模型通过双向Transformer编码器对海量语料进行训练,得到动态词向量,即同一个词在不同的上下文语境中生成不同的向量表征,大大提升了词向量的表达能力。
综上,在词向量表征层面,现有微博情感分析模型一般使用分词技术结合Word2Vector或GloVe生成静态词向量,不能很好地解决一词多义问题,且分词固化了汉字间的组合形式,容易产生歧义,例如“高大上海鲜餐厅”会被分词为“高大/上海/鲜/餐厅”。为解决此问题,本文采用BERT预训练语言模型,对微博文本逐字切割,生成动态字向量,不仅避免了分词可能造成的歧义,同时能够结合上下文语境解决一词多义问题;在特征提取层面,现有微博情感分析模型普遍使用单一的词语层Attention机制,未能充分考虑文本层次结构的重要性。本文认为Attention机制不应该只关注文本中重要的词语,还应该区分不同句子间的重要性。例如一段文本整体表达的是消极情感,模型应该给包含积极情感词语的句子赋予较低的权重,从而区分不同句子对整体情感倾向的影响。因此,本文采用层次化Attention机制,从字和句子两个层面综合判断微博文本的情感倾向。
针对以上问题,本文提出BERT-HAN(bidirectional encoder representations from transformers-hierarchical attention networks)模型用于微博情感分析,该模型首先通过BERT预训练语言模型生成蕴含上下文语意的动态字向量,然后通过两层BiGRU(bi-directional gated recurrent unit)分别得到句子表示和篇章表示,在句子表示层引入局部Attention机制捕获每句话中重要的字,在篇章表示层引入全局Attention机制区分不同句子的重要性,最后,通过Softmax对情感进行分类。
1 模型设计
1.1 BERT预训练语言模型
BERT是Google的Devlin等[17]于2018年10月提出的预训练语言模型,一举刷新了11个NLP任务的榜单。如图1所示,该模型采用双向Transformer编码器获取文本的特征表示。其中E1,E2,…,EN表示输入字符,经过多层双向Transformer训练后生成相应的向量表征T1,T2,…,TN。

图1 BERT模型结构Fig.1 BERT model structure
Transformer编码器是一个基于Self-Attention机制的Seq2Seq(sequence to sequence)模型[18],模型采用Encoder-Decoder结构,摒弃了传统的CNN和RNN,仅使用Self-Attention机制来挖掘词语间的关系,兼顾并行计算能力的同时,极大地提升了长距离特征的捕获能力。BERT仅采用Transformer的Encoder部分,其结构如图2所示。由于Self-Attention机制并不具备对输入序列的位置信息进行建模的能力,而位置信息体现了序列的逻辑结构,在计算中起着至关重要的作用,因此在输入层加入位置编码。融合了位置信息的向量首先经过多头注意力(Multi-Head-Attention)机制层,实质是将Self-Attention重复多次操作,从不同角度学习信息,达到丰富语义的目的。之后将结果输入前馈神经网络层,增加非线性变化,最终得到向量表示。Transformer还引入残差连接和层规范化[19],残差连接用于规避信息传递中出现的记忆偏差,层规范化用于加速模型的收敛。

图2 Transformer Encoder模型结构Fig.2 Transformer Encoder model structure
BERT的输入由字嵌入(token embedding)、段嵌入(segment embedding)和位置嵌入(position embedding)三部分相加构成,每句话用CLS和SEP作为开头和结尾的标记。BERT采用遮挡语言模型(masked language model,MLM)和下一句预测(next sentence prediction,NSP)来进行训练。MLM随机遮挡一定比例的字,强迫模型通过全局上下文来学习被遮挡的字,从而达到双向编码的效果。NSP可以看作是句子级的二分类问题,通过判断后一个句子是不是前一个句子合理的下一句来挖掘句子间的逻辑关系。
1.2 BiGRU
GRU是RNN的变体,由Dey等[20]提出,其独特的门控结构解决了传统RNN梯度弥散和梯度爆炸的问题。GRU由更新门和重置门构成,前一时刻隐层输出对当前时刻隐层状态的重要程度由更新门控制,更新门的值越小代表前一时刻的输出对当前的输入影响越小;重置门用于控制前一时刻隐层状态被忽略的程度,重置门的值越大代表前一时刻信息被遗忘越少,具体结构如图3所示。

图3 GRU网络模型Fig.3 GRU network model
其中,xt表示t时刻的输入;zt表示t时刻的更新门;rt表示t时刻的重置门;ht-1表示上一时刻隐层的输出;σ表示Sigmoid函数;表示t时刻的候选隐层状态;ht表示t时刻的隐层状态。具体计算过程如式(1)~式(5)所示:

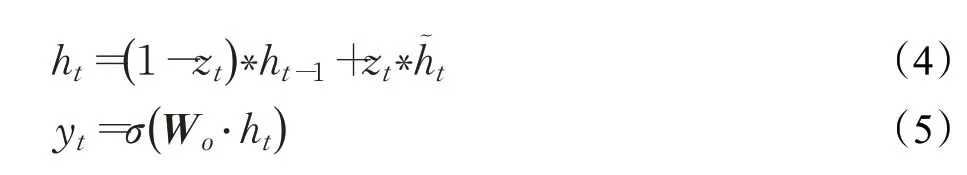
其中,Wz是更新门的权重矩阵;Wr是重置门的权重矩阵;Wo是输出门的权重矩阵;Wh~是候选隐层状态的权重矩阵;·表示矩阵相乘。
BiGRU由向前和向后的GRU组合而成,可以同时捕获正向和逆向的语义信息,结合上下文来深层次提取文本所蕴含的情感特征。
1.3 Attention机制
Attention机制就是一种在关键信息上分配足够的关注度,聚焦重要信息,淡化其他不重要信息的机制。它通过模拟大脑的注意力资源分配机制,计算出不同特征向量的权重,实现更高质量的特征提取。Attention机制的基本结构如图4所示。

图4 Attention机制基本架构Fig.4 Attention mechanism basic structure
Attention机制的具体计算过程如式(6)~式(8)所示。
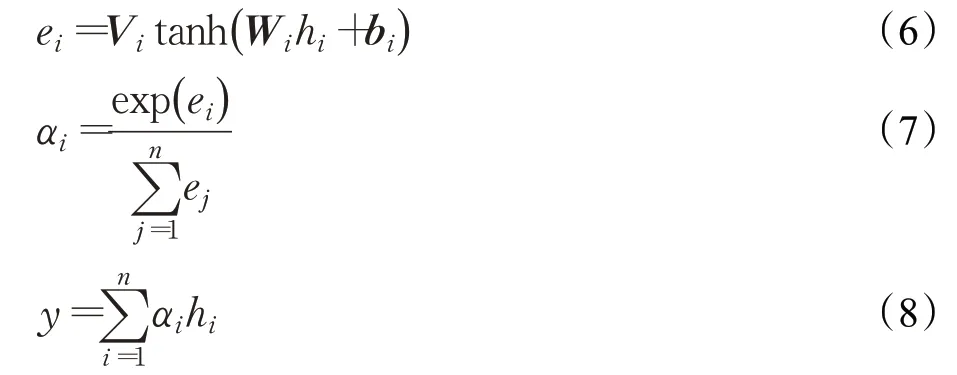
hi表示隐层初始状态,ei表示hi所具备的能量值;Vi、Wi表示权重系数矩阵;bi表示偏置向量;αi表示hi对应的权重。
1.4 模型结构
本文在上述基础上提出融合BERT和层次化Attention的BERT-HAN微博情感分析模型,如图5所示,主要由以下部分组成:
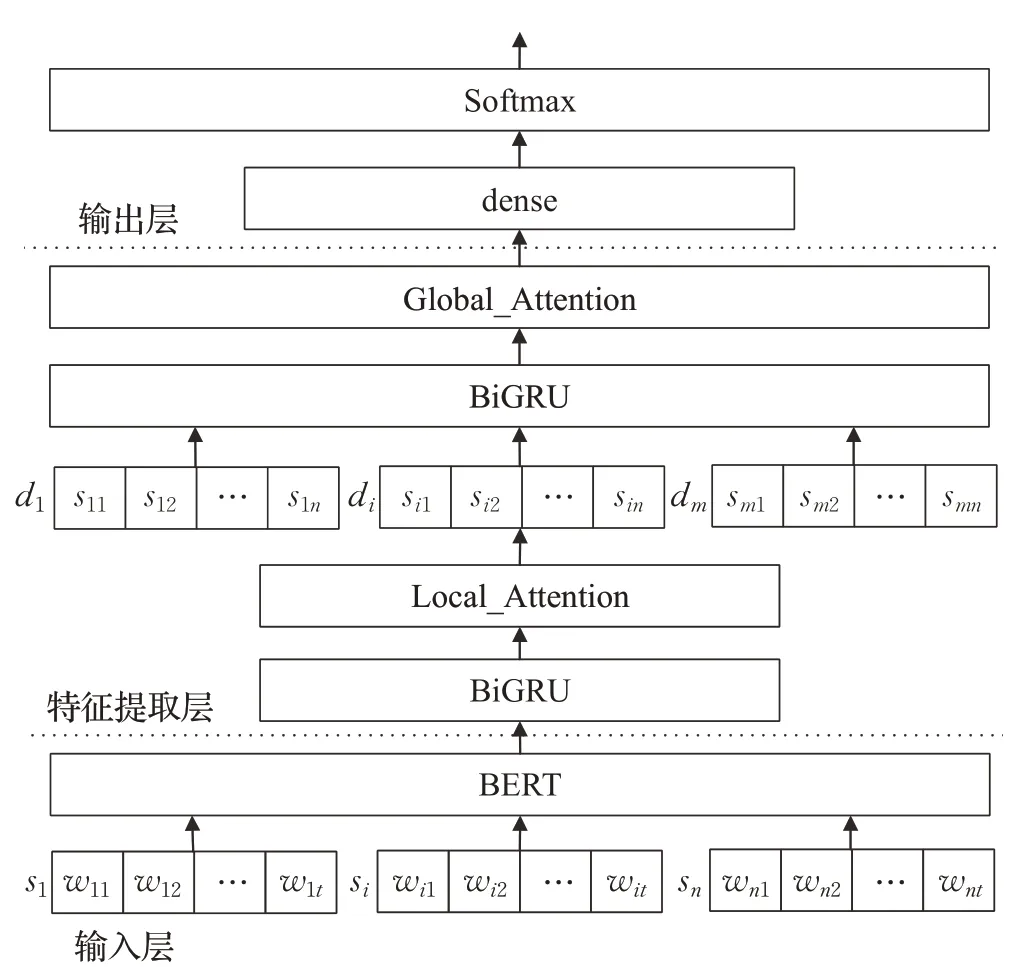
图5 BERT-HAN模型结构Fig.5 BERT-HAN model structure
(1)输入层。即文本向量化输入层,将微博文本转换成BiGRU能够接收并处理的序列向量。本文采用SMP2020微博情绪分类测评数据集,对其进行全角转半角、繁转简、去除url和email及@等预处理。另外数据集中存在以“[]”标记的文字表情符,具有明确的情感表达,需要保留该类型数据,结合上下文语义进行分析。考虑到微博书写较为随意,存在大量音似、形似错字,调用pycorrector中文文本纠错工具进一步优化数据集。文本d由n个句子组成,即d={s1,s2,…,sn},每个句子由t个字组成,第i个句子si可以表示为si={wi1,wi2,…,wit},其中w代表字。通过BERT预训练语言模型得到每个字的向量表示,即xit表示第i句话的第t个字。
(2)特征提取层。特征提取层的计算主要分四个步骤完成:
①将向量化的句子序列xi1,xi2,…,xit作为BiGRU的输入,进行深层次特征提取。BiGRU由正向GRU和反向GRU两部分组成,通过上文和下文更全面地对句子语义进行编码。计算过程如式(9)~式(11)所示:

②对上一层的输出施加局部Attention机制,目的是捕获一个句子中情感语义贡献较大的字。首先选取长度为L=[pi-D,pi+D]=1+2D的滑动窗口,其中pi表示中心字,D表示设定的上下文窗口大小,通过计算窗口内中心字与其余字的相似度得到每个字的权重αit,具体计算过程如式(12)~式(14)所示:
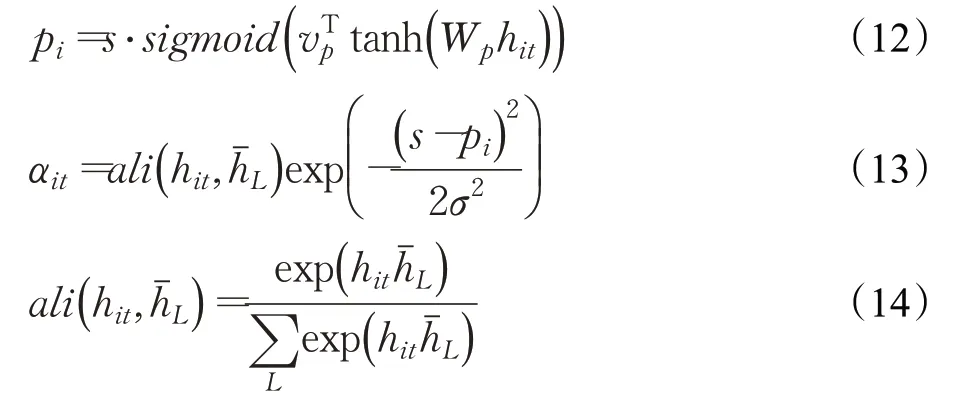
其中,s表示句子的长度,vp和Wp是用来预测位置的模型参数表示上下文窗口内除中心字外的隐层状态。最后,将每个字的向量表示hit和相应的权重αit加权求和得到最终的句子表示Si,具体计算过程如式(15)所示:

③篇章由句子构成,将句子向量Si输入BiGRU网络,深层次挖掘句子间的逻辑关联,实现整段文本信息的特征提取,计算过程如式(16)~式(18)所示:

④对上一层的输出施加全局Attention机制,目的是突出整段文本中重要的句子。首先由单层感知机得到Gi的隐含表示Hi,然后通过计算Hi和上下文向量Us的相似度得到每个句子的权重αi。上下文向量Us通过随机初始化得到,并作为模型的参数一起被训练。最后将每个句子的向量表示Si和相应的权重αi加权求和得到最终的篇章表示D,计算过程如式(19)~式(21)所示:

其中,Ws表示权重矩阵,bs表示偏置。
(3)输出层。通过Softmax函数进行情感分类,计算过程如式(22)所示:

其中,D表示特征提取层的输出向量,W表示权重矩阵,b表示偏置。
2 实验与分析
2.1 数据集
本文使用的数据集是由中国中文信息学会社会媒体处理专委会主办,哈尔滨工业大学承办的SMP2020微博情绪分类技术测评比赛提供的4.8万余条微博数据。该数据集包含两大类主题,分别是通用(usual)与疫情(virus),每个主题被标记为happy、angry、fear、sad、surprise和neutral六类情感。数据集分布如图6所示,其中happy、angry、neutral占数据的主要部分,其余类别数量较少。

图6 数据集分布Fig.6 Data set distribution
部分样例如图7所示。对原始数据整理、合并后,按8∶2划分训练集和测试集,使用五折交叉验证法进行多次实验,取平均值作为最终实验结果。

图7 部分样例数据Fig.7 Part of sample data
2.2 实验环境
实验环境如表1所示。

表1 实验环境Table 1 Experimental environment
2.3 参数设置与评价标准
本文模型BERT-HAN涉及众多参数设置。输入层采用Google发布的预训练好的中文模型“BERT-Base,Chinese”,该模型采用12层Transformer,隐层的维度为768,Multi-Head-Attention的参数为12,激活函数为Relu,模型总参数大小为110 MB。特征提取层主要由BiGRU和Attention构成,两个BiGRU的隐层节点数均为128,局部Attention机制的上下文窗口D取5。
模型训练方面,设置批次大小为32,学习率为1E-5,最大序列长度为140,优化器为Adam,防止过拟合的dropout率为0.6。
采用Macro F1和Micro F1作为模型评价标准。
2.4 实验分析与讨论
本文设计了2组对比实验来验证BERT-HAN模型的有效性。
第1组 不同词向量模型的对比实验。为了验证BERT预训练模型具有更好的向量表征能力,本文与其他三种词向量模型在相同的实验环境下以SMP2020作为数据集进行对比分析,实验结果如表2所示。

表2 不同词向量模型的性能对比Table 2 Performance comparison of different word embedding models %
从表2可以看出,相比随机Embedding、Word2Vec、GloVe,使用BERT预训练模型可以明显提高Macro F1和Micro F1值,分析其原因,BERT可以根据上下文语境动态地生成字向量,不仅解决了一词多义问题,还避免了分词可能造成的歧义,从而得到更符合原文语义的向量表征。
第2组 不同特征提取方法的对比实验。为了验证本文方法BERT-HAN在微博情感分析上的有效性,在相同的实验环境下以SMP2020作为数据集,与4个常见模型进行对比分析,实验结果如表3所示。

表3 不同模型的性能对比Table 3 Performance comparison of different models %
(1)BERT-LSTM:使用BERT生成字向量,送入LSTM网络提取特征,用Softmax进行情感分类。
(2)BERT-BiLSTM:使用BERT生成字向量,送入BiLSTM网络提取特征,用Softmax进行情感分类。
(3)BERT-BiGRU:使用BERT生成字向量,送入Bi GRU网络提取特征,用Softmax进行情感分类。
(4)BERT-BiGRU-Attention:使用BERT生成字向量,送入BiGRU网络提取特征,引入一层Attention机制对特征分配权重,用Softmax进行情感分类。
(5)BERT-HAN:使用BERT生成字向量,通过两层BiGRU分别得到句子表示和篇章表示,在句子表示层引入局部Attention机制,在篇章表示层引入全局Attention机制,最后,通过Softmax进行情感分类
从表3可以看出,本文提出的BERT-HAN模型在Macro F1和Micro F1上的表现均优于其他四种模型。对比实验1和2可以看出,BERT-BiLSTM模型较BERTLSTM模型的Macro F1和Micro F1分别提升了3.37个百分点和4.17个百分点,说明双向LSTM可以结合上文信息和下文信息进行特征提取,提升了分类效果。对比实验3和4可以看出,引入Attention机制可以对提取的特征进行权重分配,从而突出重要信息,进一步提升了模型的分类性能。对比实验4和5,层次化Attention机制较单一的词语层Attention机制,Macro F1和Micro F1分别提升了4.84个百分点和2.62个百分点。分析其原因,单一的词语层Attention机制只能捕获整段评论中的关键字,而层次化Attention机制加强了模型对文本层次结构的关注,不仅能够捕获每句话中的关键字,还能捕获整段评论中的关键句子,从字和句子两个层面综合判断文本的情感倾向,从而在微博情感分析上拥有更好的表现。对比各实验结果,本文提出的BERT-HAN模型在Macro F1和Micro F1两个评价指标上较其他模型分别平均提高8.71个百分点和7.08个百分点,具有较大的实用价值。
3 结束语
针对现有微博情感分析模型普遍采用分词技术结合Word2Vector或GloVe等静态词向量模型生成文本的向量表示,不能很好地解决一词多义问题,且未能充分考虑文本层次结构的重要性,提出一种基于BERT和层次化Attention的微博情感分析模型BERT-HAN。该模型首先通过BERT生成蕴含上下文语意的动态字向量,然后通过两层BiGRU分别得到句子表示和篇章表示,引入层次化Attention从字和句子两个层面综合判断微博文本的情感倾向。实验结果表明,相比其他词向量模型,BERT的向量表征能力更强大,且层次化Attention增强了模型对文本层次结构的捕获能力,进一步提升了微博情感分析的性能,具有较大的实用价值。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
浙江大学学报(理学版)(2022年4期)2022-07-25
复旦学报(自然科学版)(2022年1期)2022-06-16
吉林大学学报(信息科学版)(2022年1期)2022-01-14
电子制作(2019年15期)2019-08-27
人民珠江(2019年4期)2019-04-20
电子制作(2018年19期)2018-11-14
铁路计算机应用(2018年5期)2018-06-01
自动化学报(2017年11期)2017-04-04
中国生物医学工程学报(2017年6期)2017-02-10
