
结合语法信息的BG-CNN用于方面级情感分类
2022-04-09 07:03魏素华
计算机工程与应用 2022年5期
郑 诚,魏素华,曹 源
安徽大学 计算机科学与技术学院,合肥 230601
文本情感分析作为自然语言处理(NLP)的主要研究方向之一,是对带有不同情感表达的文本进行情绪分类。其中细粒度的情绪分析任务,即方面级情感分析(ABSA),是通过寻找某一特定方面的评价词(又称意见术语)来判断一个句子中特定方面的情感极性。常见的为情感三分类(即积极、消极或中立)。ABSA任务表示如图1所示:在句子“The sushi is fresh,but the board is too small.”中,两个方面词“sushi”和“board”分别由不同的意见术语“fresh”和“small”来传达它们的情感极性。
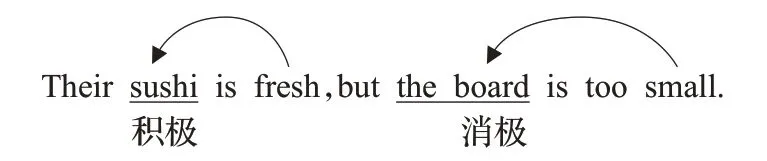
图1 方面级文本情感分析示例Fig.1 Example of aspect based sentiment analysis
方面级情感分类方案包括经典的基于情感词典的方案和近几年流行的基于深度学习算法的方案[1-3]。长短期记忆网络(LSTM)[4]被提出以来,因在NLP相关领域中表现良好备受关注。在ABSA任务上,LSTM至今被认为是效果最好的模型。近年来,随着门控循环单元(GRU)的提出,双向门控循环单元(Bi-GRU)被多次用于上下文信息的提取。卷积神经网络(CNN)可以通过卷积和池化实现重点信息提取。其可并行化的特点使得在模型训练时消耗更少的时间。它包含的池化操作可以获取输入数据的重点内容。
对于英语单词中一词多义的现象,语法层面信息中的词性信息有助于模型得到正确的词义表达。同时,语法层面信息中的句法依存树(Stanford-parser平台,https://nlp.stanford.edu/software/lex-parser.html)通过提供句子结构信息(Stanford依存关系,https://www.cnblogs.com/weilen/p/8284411.html)可以帮助模型捕获句子中特定方面的意见术语。因而可以将语法层面信息用到文本情感分析任务。据本文所知,以往的研究工作很少使用语法层面信息。
本文将文本序列与词性信息结合,送入Bi-GRU与CNN的联合模型,提出了具有可解释性的BG-CNN。经过Bi-GRU得到结合上下文信息表达的矩阵H,进一步经过卷积操作和最大池化提取核心信息。这一系列过程可解释为模拟人类理解句子信息并提取重点内容的行为。BG-CNN学到的句法结构信息并不足以很好地支持包含多个方面词句子的细粒度文本情感分类,因此提出将句法依存树作为辅助信息的DT-BG-CNN模型,实现更好的分类效果。此外结合注意力机制(Attention)捕获影响权重来作为辅助信息,提出了A-BG-CNN,用于模型对比。
这项工作的主要贡献点在于将词性信息应用到ABSA任务中,提出了具有模型可解释性的BG-CNN,以及结合句法依存树的DT-BG-CNN,同时提出了优化模型训练的增强损失函数,通过实验验证了它们的有效性。
1 相关工作
方面级情感分析针对特定方面进行情感分类,因其能精确地捕获特定方面的情感极性而备受关注。近年来相关研究工作中,基于深度学习的模型非常多。它们使用词嵌入将句子中单词进行语义表达后通过模型训练得到情感划分。Wang等[5]引入Attention,提出AE-LSTM、AT-LSTM、ATAE-LSTM三个模型,根据输入的特定目标调整句子的注意力。对比于传统模型取得了不错的效果。Tang等[6]将记忆网络的思想用于方面级的情感分析,提出了MemNet模型。通过上下文信息构建记忆,通过Attention机制捕获影响不同方面上的情感倾向的信息。Chen等[7]不仅学习MemNet使用多层注意力网络,同时创新式引入了记忆模块来解决长距离方面词信息有效识别,提出RAM模型。将目标方面词赋予了位置信息,实现了对分类效果的影响。Li等[8]提出TNet模型。用到了一种“上下文保留”机制,可将带有上下文信息的特征和变换之后的特征结合起来,将其应用卷积提取进行情感分类。Wang等[9]意识到标准的Attention不能完美模拟句子中的句法结构信息,因此提出了一层模拟条件随机场(CRF)结构来解决这个问题,提出了SA-LSTM-P模型。Song等[10]提出AEN模型,设计了一个注意编码网络来绘制目标词和上下文词之间的隐藏状态和语义交互,并提出标签不可靠性问题,在损失函数中加入了一个有效的标签平滑正则化项。Zhang等[11]认为以往研究工作通常忽略了方面与其上下文词之间的句法关系,因此提出接近加权卷积网络PWCN。按照依赖接近以及距离接近赋予权重。
这些工作仅考虑到特定方面与句子之间的结合以获取其针对性的情感极性,缺失了对语法层面信息的利用,使得他们只能提出结构复杂的模型来获得更好的分类效果。这些工作均使用Attention机制捕获句子整体对情感分类影响权重,从某种意义上可以看作在模拟句法依存树对语义表达产生的影响。Attention机制在很多领域中具有非常好的表现,但在方面级情感分析中,语法层面信息的使用有取代它的可能性。此外,LSTM模型是所有工作中不可或缺的一部分,验证了其在方面级情感分析中的重要地位。
2 结合依存树的BG-CNN模型
模型主要包括文本序列与词性数据结合的词嵌入层、用于获得单词唯一词义的Bi-GRU层,以及用于整合单词信息获取语意并提取重点信息的CNN层。将句法依存树进行同样的词嵌入和卷积处理后的数据进行拼接,经过一层全连接网络处理得到极性三元组PoL=(s1,s2,s3),分别代表情绪的正、负和无极性。整体上可以视为句意信息提取部分和句法依存树信息提取部分,使用本文提出增强损失函数进行模型训练。整体模型架构如图2所示。
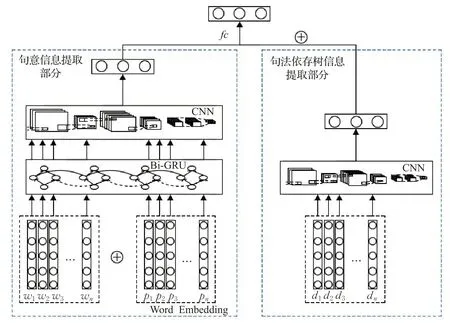
图2 DT-BG-CNN整体架构图Fig.2 Overall structure of DT-BG-CNN
2.1 词嵌入层
词嵌入层主要任务是三种不同数据的词嵌入,包括文本序列的词嵌入处理、文本词性序列的词嵌入和句法依存树的词嵌入,Levy等[12]给出了词嵌入能有效表达单词含义的解释。
将文本序列W={w1,w2,…,wn}低维词嵌入处理得到EW={ew1,ew2,…,ewn},EW∈Rb×l×dm,将词性序列P={p1,p2,…,pn}进行低维词嵌入得到Ep={ep1,ep2,…,epn},Ep∈Rb×l×dimop。将句法依存树序列D={d1,d2,…,dn}经过词嵌入得到Ed={ed1,ed2,…,edn},Ed∈Rb×l×dimod。其中l是文本序列中句子长度,b为单次训练数目,dim、dimod和dimop均为词嵌入维度。
2.2 句意信息提取部分
该部分由词嵌入层、Bi-GRU层和CNN层组成,即提出的BG-CNN模型。人类进行细粒度文本情感分类,首先获取句子中单词的正确词义,在此基础上整合获取句意信息,最终提取核心信息用于分类。该模型模拟人类阅读理解时提取信息的行为流程进行方面级情感分类。Bi-GRU层获取句子中每个单词联系上下文信息后得到的具体词义,经过CNN中卷积层加权处理整合单词获取整体句意信息,再由池化层提取句意中重点信息,最后经过一层全连接网络得到目标情感分类。下面分别对三个主要组成部分流程进行进一步说明。
一词多义使得一个句子中单词的具体词义由其上下文信息来决定。将模型在词嵌入层得到的Ew和Ep拼接操作得到Ex={ex1,ex2,…,ext},Ex∈Rb×l×(dimod+dim),送入Bi-GRU层,经GRU中重置门和更新门两个门控机制处理,输出Vout={v1,v2,…,vn},Vout∈Rb×l×2dim。把v看作是结合了上下文信息的单词从多义中选择出真正的词义。这一过程模拟人类理解单词,即获取唯一词义过程。语法层面中词性信息的使用有利于筛选掉单词的错误词义,使单词获取正确的词义表达。
模型中GRU前向传播公式如下,式中[#,#]表示两个向量相连,*表示矩阵的乘积,σ代表sigmoid函数激活,Wr、Wz、Wh~和Wo均为权重矩阵。
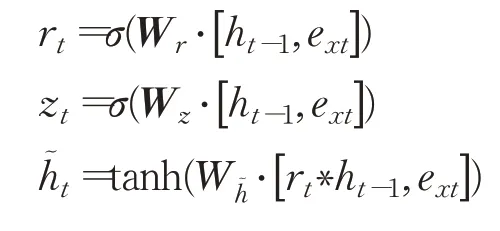

Bi-GRU是方向相反的两个GRU的联合使用,公式表示如下,其中GRU为GRU单元前向传播过程。
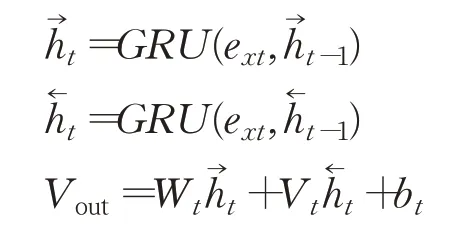
卷积公式如下,k( )m,n为卷积核参数,h为输入数据,得到ec为得到的句意信息的表示。
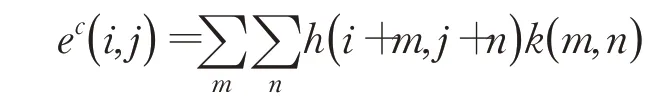
2.3 句法依存树信息提取部分
依存树作为句子中单词间依存关系的表示,在一个句子中以不同单词作为根节点会得到不同的依存树。通常情况下通过依存解析器(如Stanford的句法解析器)解析得到的是根节点不是基于特定方面词的句法结构。借助句法依存树作为辅助信息需要的是基于特定方面词的句法依存树。可以使用不同的方案实现将依存树转换为以特定方面词为根节点的依存树。Zheng等[13]从方面项中的第一个单词遍历到依存树中的每个单词,同时通过翻转一些边的方向来实现遍历。该操作使方面项中第一个单词成为了根节点,同时一些边的方向发生反向转变。这些发生转变的边信息通过特殊的标记来记录,表示可能具有不同的性质。如原本的未转换边被标记为“obj”,在转换后标记为“rev#obj”。以上操作处理得到了基于特定方面词为根节点的依存树数据,本文提出的模型中直接使用了该数据。以方面词为根节点的依存树示例如图3,图中大致指出了句子中的句法依存信息。其中“ROOT”代表根节点,即该成分不依赖于其他成分,也是该句子中的特定方面项中第一个单词;“amod”是“adjectival modifier”的缩写,代表该成分是形容词修饰语;“conj”是“conjunct”的缩写,代表该成分作用是连接两个并列的词;“dep”是“dependent”的缩写,代表该成分与根节点是依赖关系;“rev#obj”代表该成分为宾语;“aux”是“auxiliary”的缩写,代表该成分为非主要助词;“subj”代表该成分角色为主语;“compound”代表该成分为多单词组成短语;“shakira”是方面词。
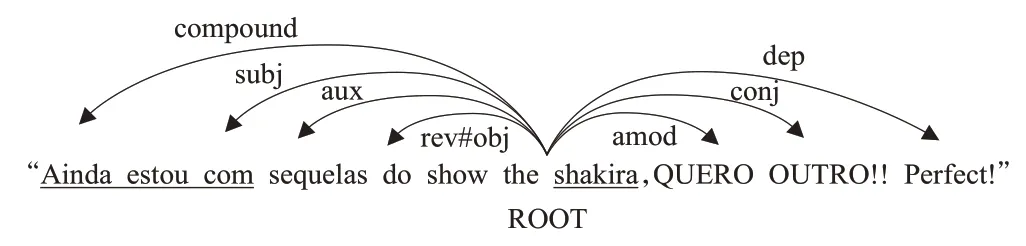
图3 句法依存树示意图Fig.3 Schematic diagram of syntactic dependency tree

输出层中,将两部分得到的Pol和Pod进行拼接后经过一层全连接网络处理,得到最终分类结果PoL=(s1,s2,s3)。
2.4 增强损失函数
将情绪标签极性三分类,错误分类情况不同损失程度不同。如将积极情绪错误分类为消极情绪和将其错误分类为无极性损失不同。因此本文提出了结合标签预测错误程度的增强损失函数。当标签错误预测为相反的情绪,给予更大的代价值。提出的增强损失函数包括三部分。第一部分为错误分类的损失l0,第二部分为增强惩罚的损失l1,第三部分为L2正则项:

式中,Cl为情感分类数目;yi为真实情感分类;为预测情感分类;λ为超参数,取值范围[0,1];wn为非错误分类为无极性情感个数;wa为总体错误分类个数。
3 实验及结果分析
3.1 实验数据
为了验证模型的有效性,本文在三个常用基准数据集上进行了实验。实验数据如表1所示,分别是来自SemEval 2014,Pontiki等[14]的Laptop和Restaurant数据集(Rest14),以及Dong等[15]在Twitter上抓取并处理的数据。涉及到对句法依存树数据的处理,本文使用Zheng等[13]中实验所用数据来证明所提模型的有效性。
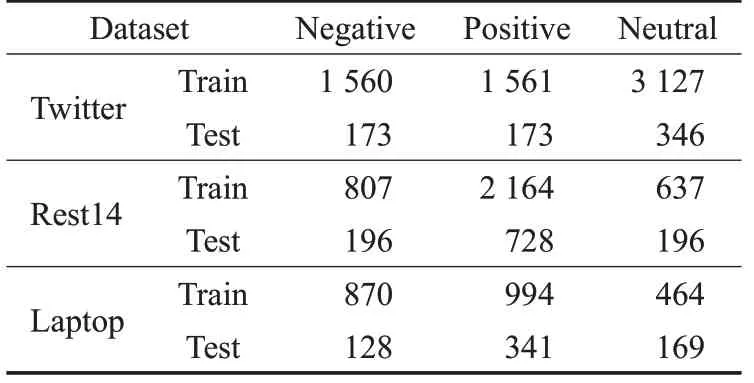
表1 数据集统计表Table 1 Data set statistics
3.2 实验参数设置
本文中涉及的模型均使用基于Glove预训练词向量,采用glove.840B.300d进行预训练。同时采用Adam优化器,并将批次处理设置为64。同大部分工作一样[16-19],本文中提出的所有模型均选择文本序列词嵌入维度为300。学习率η及过拟合参数ε根据不同数据集取值如表2所示,使用精度(Acc)和F1分数值衡量模型效果。
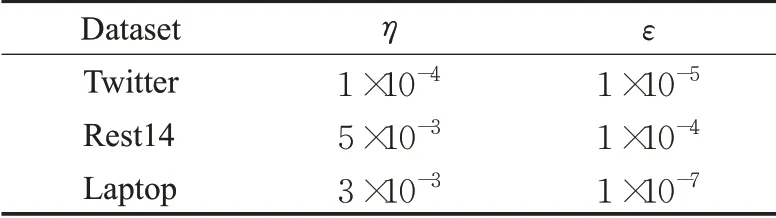
表2 不同数据集的参数设置Table 2 Parameter setting of different data set
3.3 模型对比实验及分析
将本文的工作与其他模型在这三个基准实验数据上进行了对比。这些研究工作主要包括:
(1)TD-LSTM(2016)[20]:Tang等在2016年将LSTM用于方面级情感分析,实验结果验证其效果明显优于传统的机器学习SVM模型。该工作考虑到了上下文之间的关联,这点在之后的研究工作中屡被借鉴。
(2)ATAE-LSTM(2016):将Attention机制引入到该领域,将方面词与上下文之间的关联赋予了权重,使模型的效果得到提升。
(3)MemNet(2016):作者指出将Attention用于捕获方面与上下文间的关联是比较好的思路,以往的一些工作也验证了其有效性。但如果能获取更多的记忆信息,会更好地满足情感分类需求。因此借鉴Facebook提出的MemN2N来解决神经网络长程记忆困难的问题。
(4)RAM(2017):使用Attention利用相对位置关系,提出了位置信息权重记忆方式加入目标信息。多重Attention能够捕获更长距离的情感特征。同时将捕获的结果与RNN非线性组合以提取更加复杂的特征信息。
(5)TNet(2018):认为用Attention去捕获文本序列和方面词之间的语义相关性存在一定的缺陷,如对于一些复杂的短语方面术语下却有可能会引入噪声。因此提出了一个特征变换组件结合CNN来解决这一问题。
(6)SA-LSTM-P(2018):认为在复杂的句子中,以往单纯的Attention机制会产生一定的错误。因此引入了类似条件随机场(CRF)的一层结构来更好地获取句子结构信息。
(7)AEN(2019):模型引入了注意力编码网络,主要包括内部注意力模块和整体注意。论文还提出了标签不可信问题,引入了标签平滑正则项。
(8)PWCN(2019):认为现有的方法在一定程度上忽略了方面术语在句子中的句法依赖性。提出邻近加权卷积网络来提供一个特定方面的语法感知的上下文表示。
(9)ASGCN(2019)[21]:使用了图卷积神经网络(GCN)与句法依存树。GCN因其结构更适用于非欧几里德结构数据,在细粒度的文本情感分析方向比较少见,作者成功地将它应用在该研究中。但词性信息的缺失使得效果并没有很好的提升。
此外,本文还做了提出的增强损失函数和句法依存树作为辅助信息的消融实验。实验结果如表3所示。由实验结果可以看出,本文模型的句意信息提取部分(BG-CNN)模拟人类情感信息提取效果明显。与BG-CNN对比,结合模型的句法依存树信息提取模型(DT-BG-CNN)分类效果有明显提升,验证了依存树对任务有明显的积极影响。在模型模拟人类进行信息提取时,依存树有着类似于增强权重的作用。增强函数的消融实验与DT-BG-CNN的对比,验证了本文提出的增强损失函数的有效性。
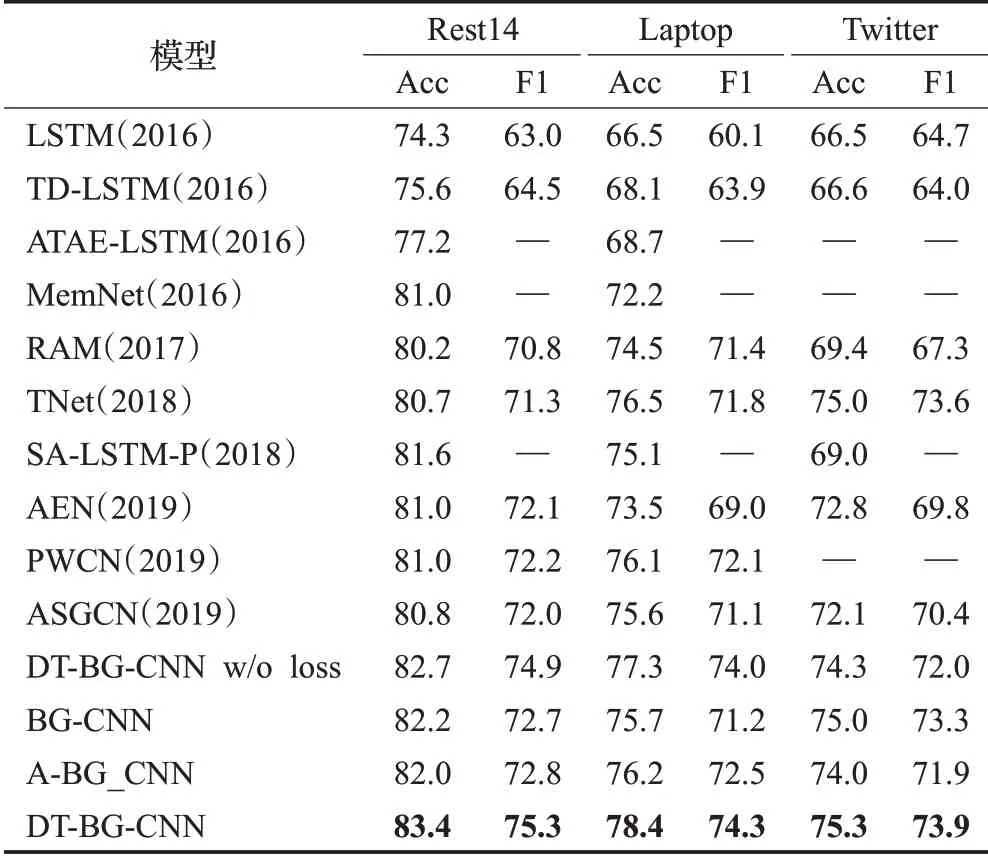
表3 模型实验结果对比表Table 3 Table of model experiment comparison results
为了讨论使用依存树作为辅助信息替换掉Attention获取目标方面词与上下文间关系权重是否取得更好的效果,将模型句法依存树信息提取部分替换为Attention机制,即A-BG-CNN模型,总体架构如图4。通过表3中数据对比可以很清晰地看出,依存树作为辅助信息能更好地掌控上下文对目标方面的影响。分析认为,使用Attention机制是通过对句法依存树的某一层面或全方面的模拟来实现辅助方面级情感分类任务,因此分类效果差于直接使用句法依存树。
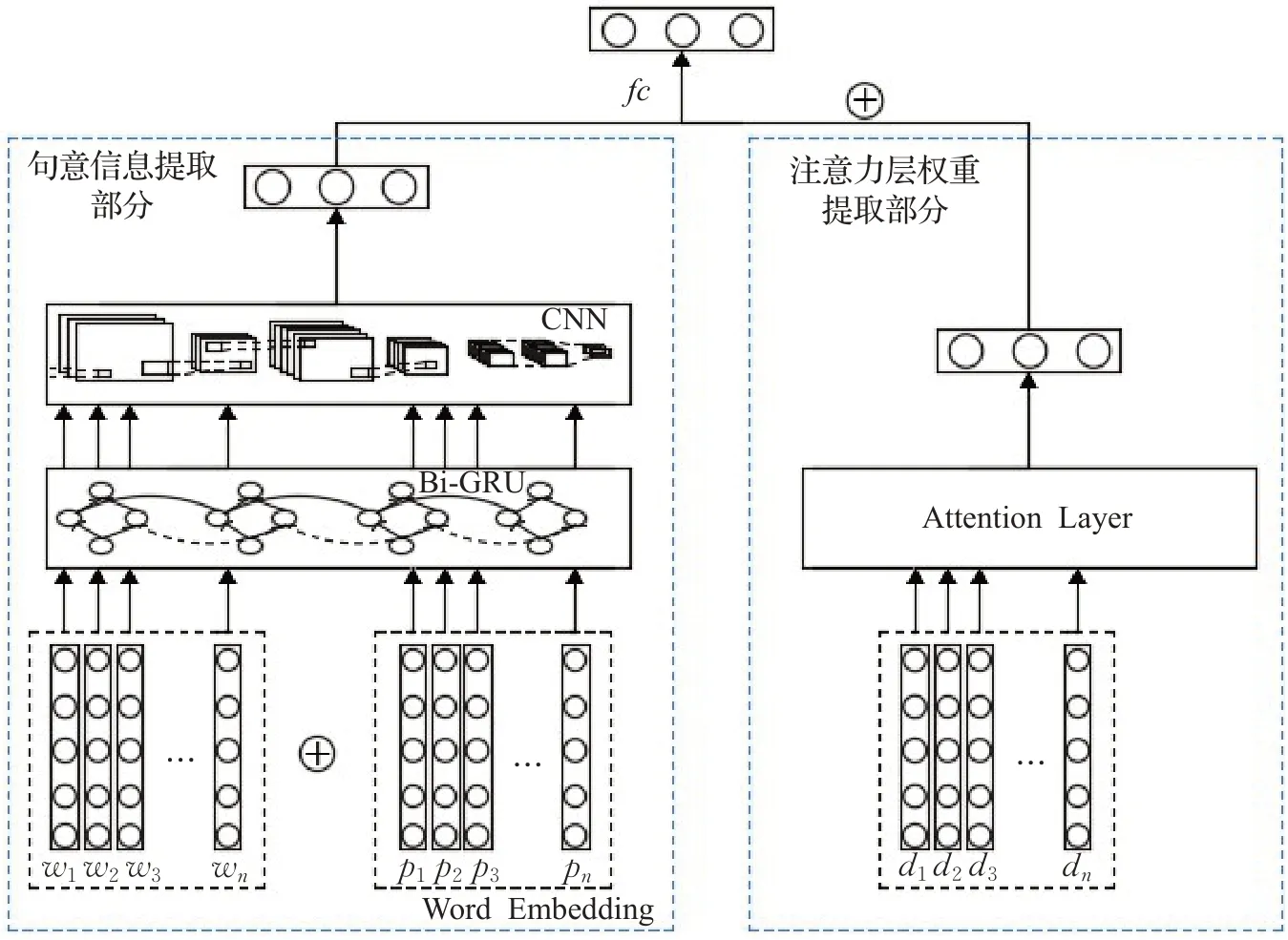
图4 A-BG-CNN整体架构图Fig.4 Overall structure of A-BG-CNN
为了验证DT-BG-CNN在得到单词词义正确表达方面的有效性,本文将其与当前的一些预训练模型进行了对比。它们分别是常用于该任务预训练的BERT和最近在NLP领域表现突出的XLNet语言模型。将它们在Laptop和Rest14数据集上的实验结果[22]进行对比,结果如表4所示。可以看出,DT-BG-CNN在Rest14数据集效果上优于BERT和XLNet,在Laptop数据集上与XLNet语言模型效果相近,优于BERT。
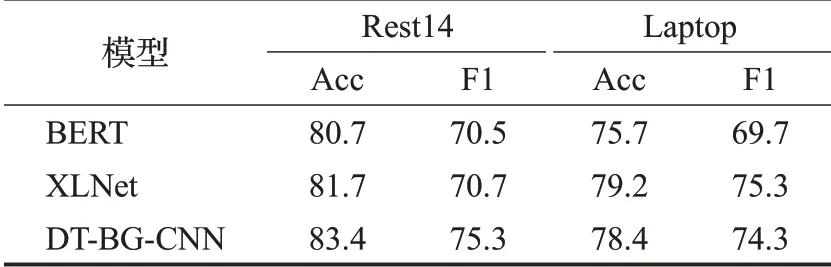
表4 与预训练模型实验结果对比表Table 4 Comparison with experimental results of pretraining model
3.4 模型实验及分析
本文从模型可解释性、句法依存树作为权重的有效性、增强损失函数参数λ取值对模型训练效果的影响和模型轻巧性,分别做了下面四个扩充实验。
(1)为了验证模型的可解释性,即该模型首先有效地从一词多义中选择出准确的词义,再对具有准确表达的句子进行重点信息的提取。将“Boot time is superfast,around anywhere from 35 seconds to 1 minute.”记为句子A,通过与四个具有相似含义或语境的句子进行句子间语义相关性实验。将句子“Boot time is fast”记为S1。S1近似人类识别句子A中重点信息的提取。将句子“35 seconds to 1 minute”记为S2。S2同S1,均为句子A中的单词组成,不同处在于,S2是人类进行方面情绪分析时去除的信息。将句子“The laptoplooks perfect”记为S3。S3和句子A不存在相同的单词,但“laptop”的词义和“Boot”在句子A中的词义具有较大的相关性。将S3作为选择的目的是为了验证该模型能够在多个词义中选择正确的表达。将句子“Restart the machine”记为S4。与S3相比,S4与A在句意上相关性更强。
实验首先使用未训练模型直接获得五个句子的向量表示,分别计算四个句子与A的语义相似度。与通过训练后模型获取的句子表达间语义相关性计算结果相对照。为了简洁直观显示A与四个句子经过模型训练前后的语义相关性,本文将结果以雷达图和示意图两种形式表现出来,如图5和图6所示。通过对比可以看出,训练前A与S1、S2的语义相关性没有明显差别,在训练后S2与A的语义相似度是最差的,验证了本文的模型能够模拟人类行为提取句子中的重点语义信息;句子S3、S4与A之间相关性大于A与S2间语义相关性,证明模型能够获取剧中单词真正的词义;从A与S4的相关性略优于A与S3之间的语义相关性,可以得知,模型获取词义精确度较高;从整体训练前和训练后A与四个句子间的语义相似度关系,可以看出训练后的模型能够更精确地表达出不同句子间相区别的信息和相关联的信息。
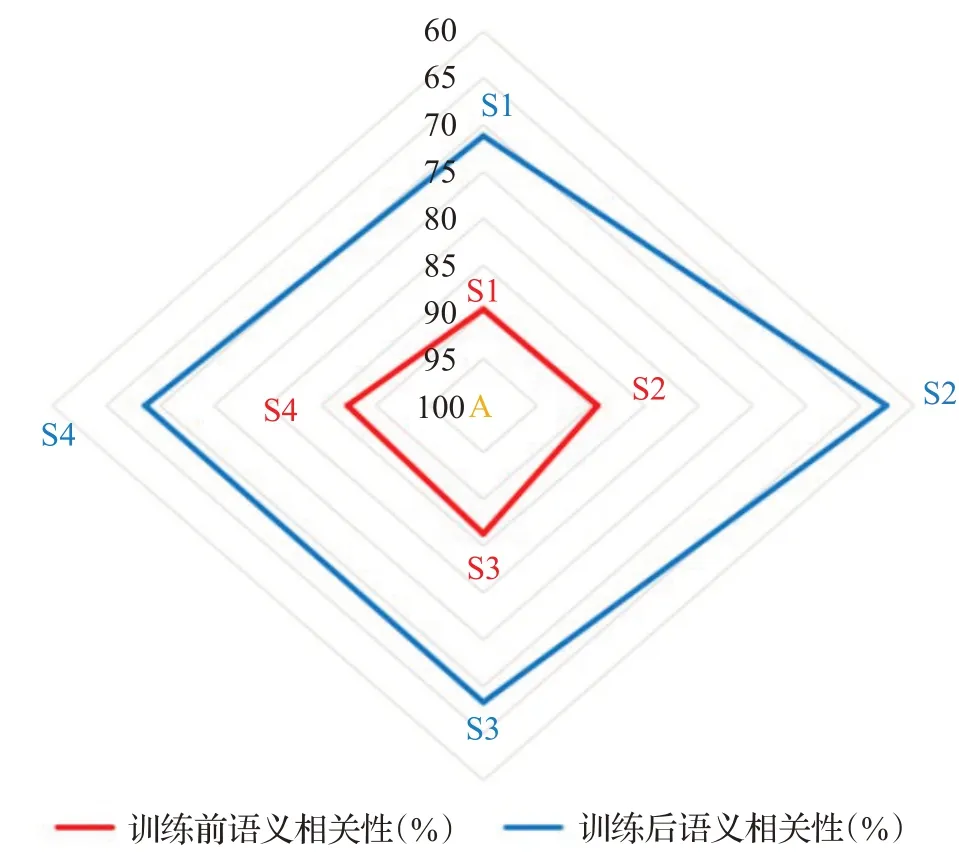
图5 A与四个句子的语义相关性雷达图Fig.5 Radar chart of semantic correlation between A and four sentences
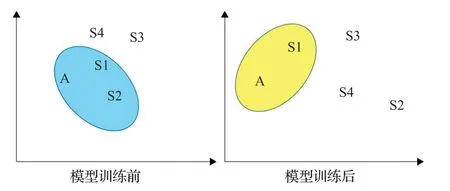
图6 A与四个句子的语义相关性示意图Fig.6 Schematic diagram of semantic relevance between A and four sentences
(2)句法依存树作为辅助信息,可以增强模型捕获重点信息的能力。为了体现句法依树的增强效果,仍以“Boot time is super fast,around anywhere from 35 seconds to 1 minute.”为例,做了实验。将句子经过卷积步骤处理后得到的Cd,进一步使用Softmax进行数据归一化处理,得到权重值。结合句子,绘制句法依存树对句子信息提取影响如图7所示。可以直观看出依存树可以增强对句子中重点单词信息的捕获。

图7 句法依存树对提取句子中重点信息的影响Fig.7 Influence of syntactic dependency tree on extracting key information from sentences
(3)为了研究增强损失函数中的超参数λ对精度和F1值的影响,对λ分别取值为( )0,0.25,0.5,0.75,1,在三个数据集上进行实验。实验结果如图8所示。可以发现在Rest14数据集上,λ对精度的影响不突出,而F1值随取值的增大有明显提升。λ取0.75时,在三个数据集上都能得到较好的结果。
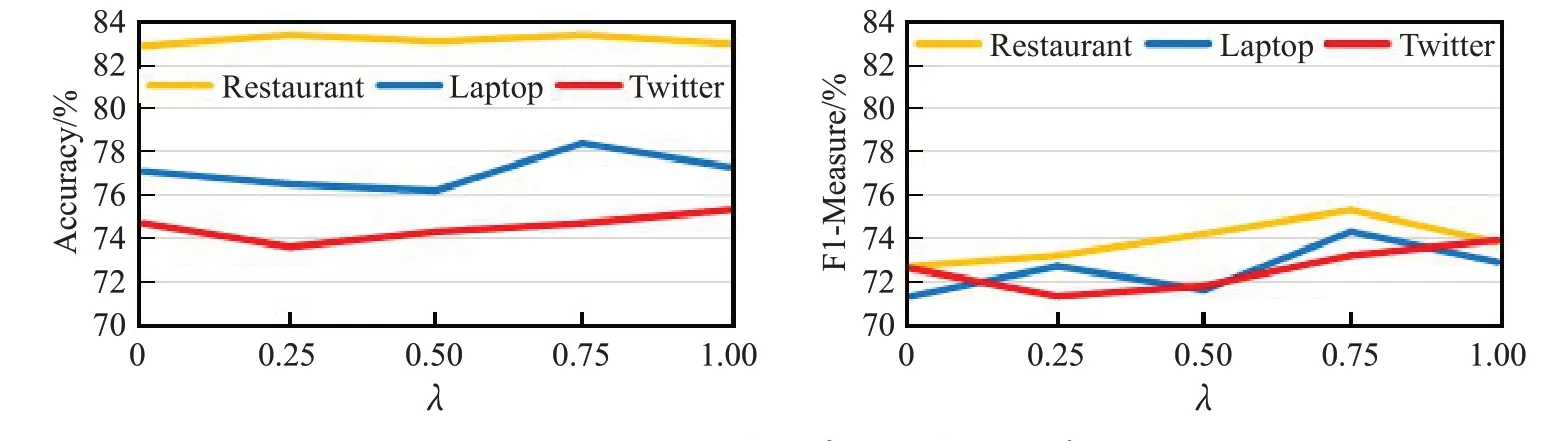
图8 λ对测试集精度及F1值的影响Fig.8 Influence ofλon test set’s precision and F1 value
(4)对本文提出的三个模型在同一硬件环境下运行。在训练参数、时间和空间内存消耗上作对比实验。运行时间及空间消耗采用多次测值取平均法,实验结果如表5所示。数据显示使用依存树只增加少量训练参数,运行时间和空间消耗均没有明显变化。一层Attention的使用在训练参数及时间消耗上劣势已经比较明显。在方面情绪分类领域,选择使用Attention往往要用到三层甚至更多层以达到分类效果的明显提升,这将带来非常巨大的运行时间消耗。
4 结语
模拟人类有效信息提取的操作流程,本文提出了具有很好模型可解释性的BG-CNN。将以特定方面为根节点的句法依存树作为辅助信息引用到细粒度文本情感分析,得到了模型DT-BG-CNN。与直接使用Attention用于获取权重的A-BG-CNN模型进行了实验对比,验证了使用依存树的优越性。此外结合该模型提出了增强损失函数。实验结果表明,借助Attention具有模拟句法结构的意义,但对比模型显示效果差于真正的句法依存树。不足之处在于,生成的句法依存树存在数据噪声,使得分类精度无法大幅度提升。因此后期研究的工作重点将放在依存树的去噪,以及如何更合理地使用句法依存树。
猜你喜欢
汉字汉语研究(2021年3期)2021-11-24
大连民族大学学报(2021年2期)2021-07-16
汉字汉语研究(2021年1期)2021-06-11
西夏研究(2020年1期)2020-04-01
新世纪智能(英语备考)(2019年11期)2020-01-18
阅读(快乐英语高年级)(2020年8期)2020-01-08
中华诗词(2018年3期)2018-08-01
智慧少年·故事叮当(2018年11期)2018-05-14
中华诗词(2018年11期)2018-03-26
小学生时代·大嘴英语(2014年9期)2014-11-04
