
基于Python的网页数据爬取与可视化分析
2022-04-09 12:56田雪丽郭志斌刘梦贤
电脑知识与技术 2022年6期
田雪丽 郭志斌 刘梦贤



摘要:基于Python的网页数据爬取与可视化分析是Python爬虫的应用及Python数据分析的应用实战。该文首先介绍了有关Python网络爬虫的相关知识,其次运用Requests和BeautifulSoup爬取旅游景点信息,并运用Excel和Tableau对数据进行分析,将分析结果进行可视化呈现,得出有关旅游景点价格、销量、地区分布等方面的结论,为用户合理选择相关景点提供了建议。
关键词:Python;网络爬虫;可视化分析
中图分类号:G642 文献标识码:A
文章编号:1009-3044(2022)06-0024-03
开放科学(资源服务)标识码(OSID):
1 概述
随着互联网的快速发展,人们能够利用网络获取各种各样的信息,使得学习与生活更加便捷,但是互联网数据爆炸性地增长,导致我们会受到若干无效信息的干扰,对有效数据的收集显得尤为困难,网络爬虫技术则可以有效地获取关键数据信息,实现对信息的准确挖掘,达到对庞大信息精确检索的目的,优化用户的网络体验,节约时间与精力[1]。
2 相关概念
2.1Python语言
Python语言作为一种高级程序设计语言,既面向过程又面向对象,它拥有的高级数据结构、动态类型、解释型语言促使其成为多数平台上编写脚本和快速开发应用的编程语言,具有简单易学、免费开源、可移植、可嵌入等特点[2],目前全国有多所高校都开设了Python程序设计课程。
2.2 爬虫技术
网络爬虫又称网络蜘蛛、网络机器人,是一种按照一定的规则,自动抓取万维网信息的程序或者脚本[3],它可以爬取的内容包括文本、图片、音频等数据。其工作原理是:向客户端发送HTTP 请求,将URL提交给服务器端,服务器端根据URL的信息进行逻辑处理,并将需要的数据返回给客户端。爬虫的类别包括通用型、聚焦型、增量型、Deep Web型等。
2.3 可视化分析
可视化分析是基于分析理论,利用计算机图形学和图像处理技术,将科学数据转换成图形图像,实现用户与数据的交互,它具有增强理解、增强审视、简单化等优势,我们常见的可视化表现形式有直方图、饼图、散点图等。
3 数据获取
数据获取是指利用一种装置,将来自各种数据源的数据自动收集到一个装置中,本文基于去哪儿网站,通过Python的爬虫技术获取相应数据,数据获取的过程为:发起请求、获取地址、分析网页、提取数据、存储数据。
3.1 发起请求
数据爬取主要是通过Python爬虫技术实现的,通过对指定的网站发起请求,获得服务器响应的数据,解析之后存入到Excel中。此次爬取数据使用的是Requests库,Requests库作为Python的第三方数据库,能自动解码来自服务器的内容并基于HTTP头部对相应的编码做出有根据性的推测,它对指定的URL发起请求,获取想要爬取的数据页面的响应信息。爬取网页数据最常使用的是通用爬取框架,它最大的作用就是让用户有效、稳定、可靠地爬取网页上的内容[4]。
3.2 获取地址
想要获取去哪儿网站上的西安旅游景点数据,就需要获取相应数据的URL链接,以此来发起请求。打开去哪儿网的网站,我们会发现景点数据被分为了49页,每页的URL都不相同,所以需要寻找到每页URL之间的关系。通过翻页对比发现除了第一页以外,每页的URL都在最后有一个page=参数发生变化,即从1开始,每页页码对应着该数字,因此可以构建一个for循环,用于请求网址。
3.3 分析网页
获取每页的URL后,再发起请求,获取响应,对响应进行解析。Python中有许多解析库,通过对网页数据进行观察,选择BeautifulSoup库来对该响应进行解析是最方便的。BeautifulSoup库将响应转化为一个树结构,每一个结点都可以成为它的一个标签对象[5],然后通过它的.text属性提取该标签对应的数据。查找单个标签可以使用find()方法,查找多个标签可以使用find_all()方法,其中最关键的是对标签进行精确定位,在()中用语句来实现。
3.4 提取数据
对页面进行解析之后,就要对解析后的响应进行数据提取。我们使用正则表达式和BeautifulSoup来对解析后的网页进行数据的定位和提取。正则表达式是对字符串操作的一种逻辑公式,可以通过一个特定的组合,从复杂烦琐的字符串中快速提取符合条件的字符子串。而BeautifulSoup则更加方便,它可以通过css选择器对元素进行定位,通过树形结构依次访问目标数据标签,具有方便、快捷等特性,因此它是爬虫程序中定位标签位置的首选。
3.5 存储数据
本文采用Excel对数据进行存储,Excel的功能是高度集成化的,操作比较简单,并且Python中有一个Openpyxl库,是专门用来操作Excel的,使得两者可以无缝衔接,同时因为数据较少,用Excel来进行管理远比数据库来进行管理更加高效。爬虫程序在爬取数据时,将爬取的数据构建成一个列表,通过append()方法,将景点名称、地区、热度、地址、价格、月销量、月销额、经纬度等数据依次加入Excel表中。
4 数据可视化
数据可视化首先对数据进行一定的处理,包括统计、去重、整理等,然后以图形化的形式呈现,便于我们更好对其进行识别、判断[6]。数据可视化过程包括数据处理、可视化、词云分析、热度分析、价格分析、月销量与月销额分析、地区分析。
4.1 数据处理
当景点数据获取并存储后,需要对这些数据进行处理,将其不满足可视化需求的数据剔除。首先是对数据去重,Excel中自带去重功能,所以可以通过Excel进行数据去重操作。对去重后的数据再次进行检查,发现它符合分析需求,不需要再進行其他数据处理操作。
4.2 可视化
当数据处理完毕后,需要对这些数据进行可视化分析,通过图表的形式将数据中隐藏的信息展现出来。数据可视化分析可以用Excel和Tableau实现。Excel中自带图表,图表随着数据的变化而变化,呈现的形式多种多样,可以生成各种高质量的图片。Tableau是一款可视化分析工具,能够帮助我们快速做出可视化的图片,同时它的操作简单、易学,用户体验良好。
本文分别采用了这两种软件来生成不同的图表,其中景点价格、景点地区分布图是用Excel呈现的,词云图、景点热度、月销量与月销额是用Tableau呈现的。
4.3 词云分析
词云是由词条组成的类似云型的彩色图案,词条在词云中所占区域的大小代表了它出现频率的高低,从视觉上达到更加直观的效果。通过对西安景点简介进行词云图绘制分析,我们很容易发现西安的特色,文化、历史、博物馆等词的提及表明西安是一座典型的文化古城,休闲、娱乐、乐园等词的提及体现了西安旅游环境轻松且多样,景点词云分析如图1所示。
4.4 热度分析
景点热度是指在一定时间内,以用户的分享、广告的宣传等方式,使得该景点受人们关注的程度。一般而言,游客越多,该景点的热度值越高,热度Top10景点排名如图2所示。
4.5 價格分析
景点消费总价格受门票、餐饮、住宿等因素的影响,人们会依据自己的消费水平选择不同的旅游景点,从景点价格来看,去大雁塔音乐喷泉、滑翔机、直升机类的活动花销较大,价格Top10景点排名如图3所示。
4.6 月销量与月销额分析
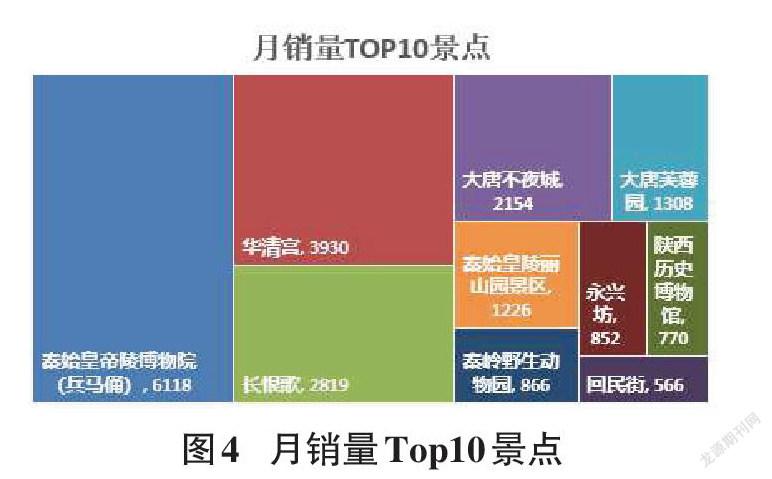
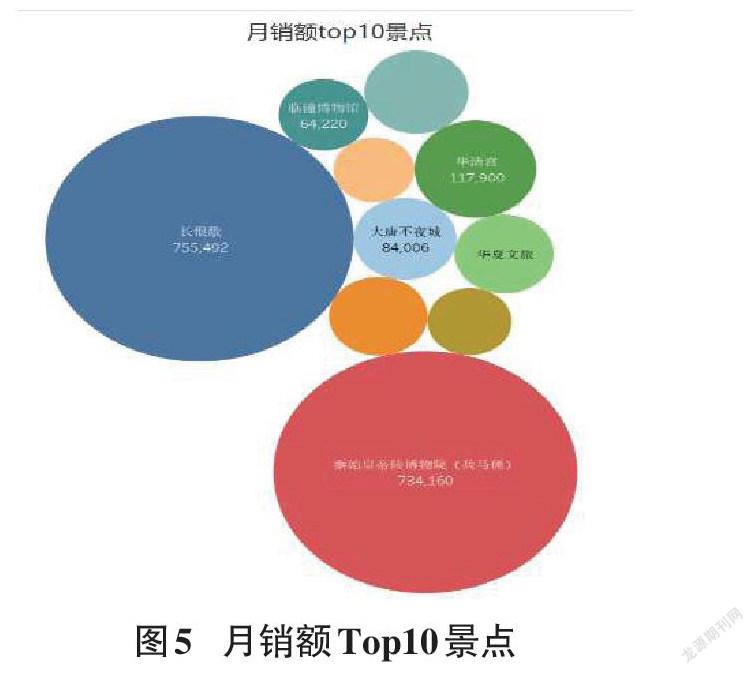
门票的月销量是指在一个月内售出的门票张数,月销额是指在一个月内售出的门票张数与单价的乘积,通过分析发现在月销量与月销额中,秦始皇帝陵博物院(兵马俑)居于首位,其次是华清宫和长恨歌。因此,月销额受月销量的影响较大,受价格的影响较小,月销量与月销额Top10景点排名如图4和图5所示。
4.7 地区分析
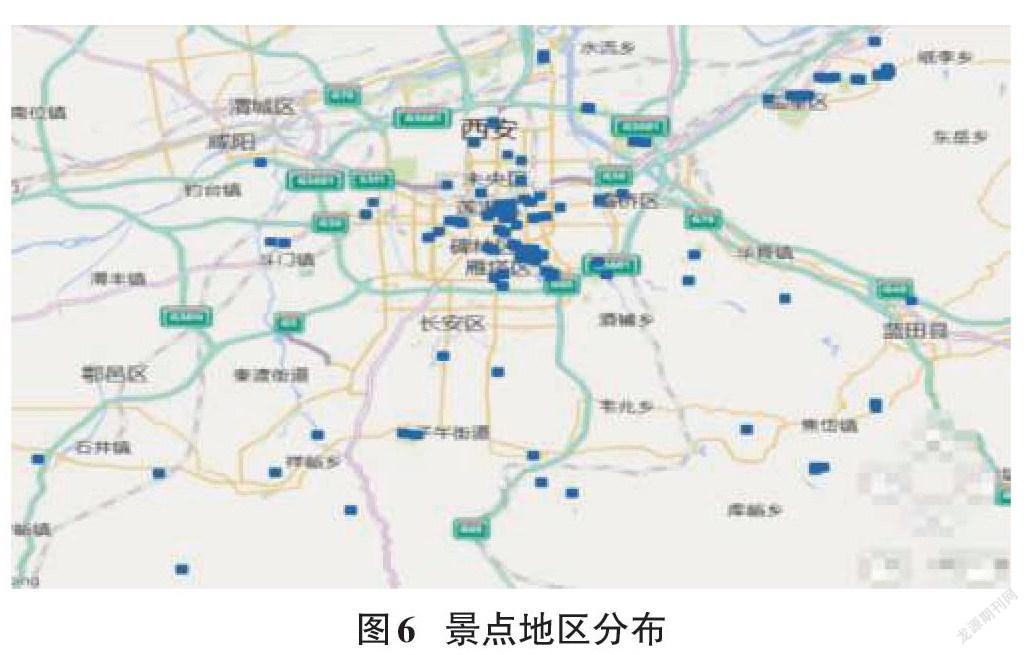
利用2016版的Excel进行平面地图的绘制,明确景区所处的地理位置,有助于提前做好规划,从图中我们可以发现景点主要集中在莲湖区、碑林区、雁塔区,景点地区分布如图6所示。
5 结论
随着大数据时代的到来,从海量的数据中获取自己所需的数据显得尤为重要,我们需要掌握必要的爬虫技术,快速抓取网页数据并对其进行可视化分析,帮助人们做出正确的选择。
本文利用Python的爬虫技术,以去哪儿网的陕西省西安市旅游景点信息为数据来源,利用Python爬虫框架获取数据,之后对数据进行处理、可视化分析,反映用户的真实体验。
参考文献:
[1] 徐志,金伟.Python爬虫技术的网页数据抓取与分析[J].数字技术与应用,2020,38(10):30-32.
[2] 张珩.Python的计算机软件应用技术探讨[J].电脑知识与技术,2020,16(32):96-97,102.
[3] CastilloC.EffectiveWebcrawling[J].ACMSIGIRForum,2005,39(1):55-56.
[4] 简悦,汪心瀛,杨明昕.基于Python的豆瓣网站数据爬取与分析[J].电脑知识与技术,2020,16(32):51-53.
[5] RyanMitchell.Python网络数据采集[M].北京:人民邮电出版社,2016.
[6] 曾诚.基于Python的网络爬虫及数据可视化和预测分析[J].信息与电脑(理论版),2020,32(9):167-169.
【通联编辑:王力】
猜你喜欢
职教论坛(2016年26期)2017-01-06
中国新通信(2016年21期)2017-01-06
科技传播(2016年19期)2016-12-27
现代情报(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
