
PPTM:一种面向异构系统的主动式任务映射方法①
2022-04-08 05:58龚施俊鄢贵海李晓维
高技术通讯 2022年2期
龚施俊 鄢贵海 李晓维
(*中国科学院计算技术研究所计算机体系结构国家重点实验室 北京100190)
(**中国科学院大学 北京100049)
0 引言
随着半导体芯片制程工艺发展,晶体管尺寸不断逼近物理极限,摩尔定律逐步放缓[1-4],实现性能提升愈发依赖于新的体系结构设计方法。领域专用体系结构(domain-specific architecture,DSA)针对特定问题域定制体系结构,具有显著的性能和能效优势。DSA 通常被称为“加速器”,因为与通用CPU上执行整个应用程序相比,它们只会加速某些应用程序。典型加速器有GPU、TPU[4-5]和用于软件定义网络(software define network,SDN)的处理器[6]等。
类似于通用CPU 需要操作系统驱动,之前的工作中,针对不同的加速场景或加速器涌现了许多成熟高效的异构加速系统或者框架,如OpenCL[7-8]、CUDA[9]、基于OpenVX[10]的AMDOVX[11]以及TensorFlow[12]等。这些系统运行时将识别加速可行性并决定如何利用加速器的责任转移给程序员,这对程序员提出了更高的要求,需要程序员熟悉加速器的底层实现细节。这导致程序员水平的个体差异对程序性能的影响巨大,差别甚至达到数千倍[1],其主要原因是异构系统环境下的任务映射的差异。
为实现在异构系统中高效的任务映射,之前的工作提出了很多基于任务在不同处理上的执行性能和如何最小任务之间的通信开销等的调度算法[13-18]。这些工作一般采用计算流图来表示应用,每个节点代表一个计算任务,然后将这些任务在满足某些限制条件下,如最小化通信开销、最小化执行时间等,将其调度到加速器上执行。但是,我们发现针对某些应用场景,基于执行时间快慢来进行任务调度无法摊销计算节点之间的通信开销,同时在特地处理数据规模时,相比于CPU 加速器对计算核能带来的加速比有限。在这种情况下,将计算节点映射到加速器上执行带来的性能增益将因整个应用程序存在主机端(HOST)与加速器设备端的通信开销而被部分抵消掉,大幅降低了预期的性能提升。
为了解决上述问题,本文提出了一种基于预测的主动式任务映射算法(prediction-based proactive task mapping algorithm,PPTM)。首先,通过预测算法动态调整计算节点的运行时属性,包括不同计算平台的执行时间和平台之间的通信开销等。然后,基于计算节点的性能增益和额外开销数据来设计任务映射算法,完成计算流图中任务节点在异构平台上的映射。最后,通过一个案例研究来验证该算法的有效性。
本文的主要贡献包括以下4 个方面。
(1)提出了一种面向异构加速系统的高效任务映射方法。该算法可以精确捕捉任务运行时特征来完成应用程序在异构加速平台上的任务映射,从而提高应用整体性能。
(2)发现在一个应用程序的计算流图中,虽然将计算节点映射到加速器上执行能带来较大的加速比,但是需要根据整个应用程序的计算流图来考虑其映射行为,否则可能无法带来性能增益。
(3)发现针对整个应用程序,并不是降低的通信开销越多,性能提升就越大,而是需要针对特定应用以及运行时数据来权衡。
(4)案例研究。本文以面向流式应用的加速器为例,来评估PPTM 及其他映射算法的性能。这一案例研究的结论也可以推广到面向其他应用领域的加速器上。
1 相关工作
1.1 异构加速系统与任务映射
在数据高速增长的背景下,异构计算是满足新兴应用不断提高算力需求的有效途径[19]。为了更好地发挥专用加速器的性能以及给用户提供更加优化的编程接口,涌现了很多成熟高效的异构加速系统。OpenCL 提出了面向异构设备上编程的行业标准,通过它可以将应用程序的计算密集型部分卸载到加速设备上从而提高应用程序性能,它的目的是为异构系统提供统一的开发平台[20]。OpenCL 将主机与加速设备的交互方式进行了统一的抽象,并提供统一的编程语言。用户可以在程序池中选择由设备商实现的kernel 程序来完成对加速设备的调用,然后在主机或设备上创建存储单元,通过主机端与设备端的数据复制来完成设备端程序与主机端程序之间的数据交互,从而实现对底层加速器的透明化管理。CUDA 作为英伟达的商业化异构加速系统,其最终目的是支持面向通用计算的GPU(generalpurpose computing on graphics processing units,GPGPU)。CUDA 提供统一的开发套件,并封装实现了很多高效计算库(cuFFT、cuBLAS 等)以及提供了统一的高效成熟的NVCC 编译器,相比于OpenCL 依赖于设备商的驱动实现,对用户更加友好[9]。TensorFlow[21]作为Google 开源的数据流图科学计算库,主要用于机器学习等人工智能领域。通过提供众多机器学习领域抽象核函数实现,用户可以选择其构建特定的机器学习算法,降低了机器学习算法的设计门槛。在底层可以对接CUDA 等加速器运行时系统,来支持异构计算[15]。
在之前的异构加速系统中,程序员的主要工作是将一个应用程序划分成不同的计算任务,调用异构加速系统提供的核函数来实现特定的计算任务,并通过在加速器上执行来提高整个应用程序的性能。因此,一个应用程序在异构平台上如何高效地进行任务映射就显得至关重要,这关系到整个应用程序的实际性能,对程序员提出了更大的挑战。
之前的工作中,涌现了诸多针对异构多处理器的任务调度优化算法。文献[15]根据异构处理器的任务执行时间,提出了2 种启发式算法来最小化应用程序在异构平台上的执行时间。而文献[17]和[14]则为了能最小化任务之间的通信开销提出了相关的任务映射算法。当然,还有很多调度算法[16,22-29],但是这些工作通常是考虑不同应用在加速器设备上的差异表现来决定最合适的任务映射方式,这与本文提出的在特定的应用程序中有些任务被映射到加速器上会降低应用程序整体性能还是有所差异的。
1.2 计算流图
计算流图通常是一个有向无环图,其中的每一个节点都类似于一个函数调用,代表一个计算核,节点间的有向边代表了数据的输入输出关系[2]。其定义如下:
定义1 计算流图由二元组G=(V,E)表示,其中V为节点或顶点的有限集合,每个节点表示一个计算核;E为有向边的有限集合,边表示计算核之间通信或依赖关系。每条边是一个有序二元组e=(v1,v2),其中v1,v2∈V。如果e=(v1,v2) ∈E,则边e从v1指向v2,且称v1是v2的依赖。
通过将应用表达成计算流图,可以方便地描述计算之间的依赖关系,然后通过合适的调度算法可以大幅减少加速器中的控制,还可以提高计算并行度。因此在之前的异构多处理器任务映射算法研究中,基于计算流图的计算任务表示方式被大量运用。此外,在成熟的异构加速系统TensorFlow 中也使用计算流图作为计算任务的表达形式。在本文的算法设计中,将基于计算流图来表达应用程序中的计算任务,并基于此来优化调度。
2 问题描述
在异构加速系统中,通过计算流图表达的应用程序,往往存在一些计算节点无法在加速器上执行。因为加速器通常是领域专用的,只会加速整个应用程序中的一部分。这导致在整个计算流图中存在“栅栏”[30-31]节点。所谓栅栏节点,就是在计算流图中,当前节点与其依赖节点支持运行的平台不同。这里只考虑主机(HOST)和加速器(设备)两种计算平台,因此,栅栏节点表示这些计算核节点没法在加速器上执行,而其他节点表示既可以在CPU 上也可以在加速器上执行。所以,栅栏节点致使HOST 和加速器设备被迫进行数据交互,从而带来通信开销,导致整个应用程序性能下降。在一些特殊应用场景中,计算流图中存在的栅栏节点可能会导致其依赖节点或者被依赖节点映射到加速器上执行反而无法带来性能增益。为了更清晰地说明这个问题,本文设计了如图1 所示的计算流图。

图1 计算流图示例
图中给出了一个基于由10 个计算核节点组成的有向无环图来表达的应用程序,并用黑色标识栅栏节点。如图1 所示,v1和v5是栅栏节点,并且将是任务映射时需要特别考虑的点。因为,栅栏节点与其依赖节点存在HOST 与加速器设备的数据交互,同时由于依赖关系,必须等待依赖节点执行完成才能开始下一步的计算,这将带来额外的通信开销从而降低整个应用程序的性能。为了降低栅栏节点对整个应用带来的性能影响,对其依赖节点完成高效的任务映射将是至关重要的。
用C表示计算流图中2 个依赖节点之间的通信延迟的有限集合,如果c1∈C,则称c1是计算核节点v1与被依赖节点之间的通信开销。假设,如果2 个依赖节点映射的计算平台相同,则它们之间的通信延迟为零。用S表示计算核节点运行在加速器上时相对于CPU 能够带来的性能增益的有限集合,如果s5∈S,则称s5代表节点v5的性能增益。由于其无法在加速器上执行,令其等于零,即无性能增益。在图1 中,v9节点如果要调度到加速器上执行,需要将结果数据从加速器上读回(假设待处理数据已经提前在平台准备好),这将带来额外的通信开销。很容易可以得出,如果s9<c9,节点v9并不适合调度到加速器上执行。基于以上观察,首先,假设在计算流图中调度节点到加速器上执行带来的通信开销用Φ表示,节点在加速器上执行带来的增益用X表示。然后,给出如下推论:
在计算流图中,将节点映射到加速器上执行并不总能带来性能增益,假设只考虑通信开销,需要满足条件,即在加速器上执行的增益能够覆盖通信开销,即X≥Φ。
图1 中,在处理特定数据大小时,CPU 完全可以把处理数据全部放到内存中,访存不会成为CPU的性能瓶颈而导致CPU 处理性能降低。因此,在接下来的讨论中,假设整个应用程序处理的数据规模是能全部装载到主机的内存中的。计算核节点v9,由于其被依赖节点v5不能在加速器上执行,如果整个通信开销超过了加速器能够带来的性能增益,在执行调度的时候,如果能将v9调度到CPU 上来执行,对于提升应用的整体性能将是更优的调度策略。
在现有的异构加速系统中,运行时系统将识别加速可行性和决定如何利用加速器的责任转移给程序员,如OpenCL 需要实现专门的计算核,CUDA 和TensorFlow 提供了核函数库供用户调用,这对程序员提出了更高的要求。为了获得更高的性能需要,程序员需要了解加速器的底层细节,如加速器的存储体系和处理性能等。除此之外,这些特性都会随着应用运行时动态地改变,这极大地增加了调度优化的复杂度。
针对存在的问题,本文提出了基于预测的主动式任务映射算法,即通过预测算法动态调整计算节点的运行时属性,完成计算流图中任务在异构平台的映射。
3 PPTM 算法设计
在之前的工作中,面向多处理器的计算流图调度优化通常会考虑任务在处理器上的执行时间和通信开销[14-15],如果是实时任务还会考虑如何满足延迟要求,在此基础上来最大化应用程序性能。文算法设计只考虑计算核节点在加速器上执行所能带来的性能增益,用X表示,以及为此需要付出的额外开销。这些开销可以是数据通过PCIe 在主机端和设备端的传输延迟以及程序额外编译时间等,统称为通信开销并用Φ表示。因此,PPTM 算法主要解决的问题可以抽象成,对于给定的应用程序A所表达的计算流图G=(V,E),根据节点在加速器上性能增益X和为了在加速器上执行所带来的通信开销Φ,求得一个最优的图节点在异构平台上的映射方案G′,也即图节点的最优调度序列(v′1,v′2,…,v′n) ∈V,可以表示为
G′i=(v′i1,v′i2,…,v′in)=f(G,X,Φ),使得P(G′i)=max(P(G′i)),其中G′i∈G′i,在这里,使用P函数去表示求一个计算流图的性能,f函数表示根据给定的限制条件获得一个映射方案G′。
同时,参考之前的工作,针对多处理器的任务映射问题通常是基于给定的处理器性能数据。然而,不管是处理器性能还是通信开销,这些都会随着任务的不同,而在运行时动态地变化。如果调度算法只根据历史给定的数据来进行任务映射,将无法适应实际的应用场景,如加速器性能在实际场景中没法全部发挥、PCIe 带宽实际上没有那么高等。因此,本文基于一元线性回归模型,针对计算节点在CPU 和加速器上的执行时间以及节点之间的通信开销,分别实现了对应的预测模块。首先通过线性拟合给定的历史数据得到一个初步预测模型,然后会根据运行时节点性能数据,不断调整整个预测模型。相关模型如下:
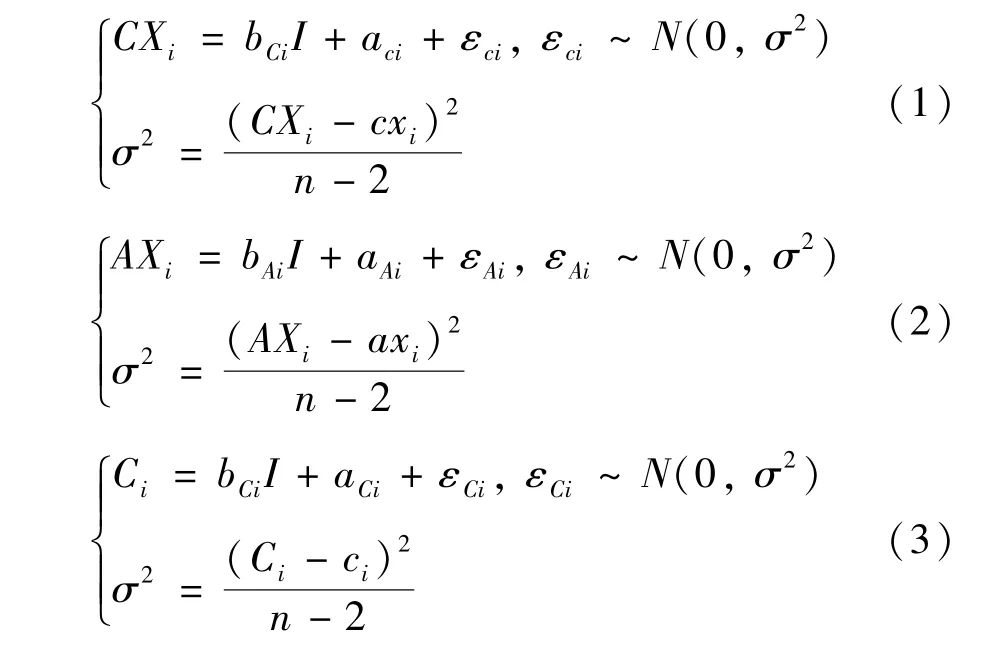
其中,CXi代表计算核节点i在CPU 上执行时的预测时间。假设节点i能在加速器上执行,则AXi代表其在加速器上执行时的预测时间,相应的cxi和axi表示实际的节点在CPU 和加速器上的执行时间的测量值。I代表节点处理数据的规模。Ci则表示节点与依赖节点的通信开销的预测值,对应的ci则为实际测量值。因此,对于计算节点在加速器上的性能增益,可以简单地表示为Xi=AXi -CXi。
求解该问题的难点在于,修改某个节点的调度行为之后,会影响到其依赖与被依赖节点的性能,从而产生调度的传播性影响,因此获取一个最优的任务映射方案,将是一个NP 问题。对此,本文给出一个基于性能增益传递的启发式的求解算法,也就是在决定节点是否映射到加速器上执行时,不只是根据当前节点的性能增益,而是累计其相关子节点的性能增益来判断性能增益是否能覆盖通信开销。如果性能增益能覆盖通信开销则将其映射到加速器上执行,否则映射到CPU 上执行。如果将其映射到CPU 上执行,则接着需要递归重新调度其相关子节点。当然,如果在计算流图中,节点的输入是栅栏节点,在计算性能增益时将会考虑相关的通信开销。虽然,本文提出的求解算法是局部优化的,但是在考虑的应用中,栅栏节点作为一个分界点,栅栏节点上下游数据肯定来源于CPU。因此,只考虑其父节点是否是栅栏节点,然后再来递归修改子节点的任务映射算法,也能求出一个比较全局优化的映射方案。
图2 给出了PPTM 算法的流程图,图中使用的性能数据来自于预测模块,为简洁起见图中没有画出预测模块。

图2 PPTM 算法流程图
如图2 所示,从应用程序计算流图的非栅栏节点的加速器可执行的叶子节点开始遍历整个图节点。首先判断节点是否有父节点,如果没有,则说明调度来到了根节点,进入调度流程。否则,判断其父节点是否是栅栏节点,如果不是栅栏节点,将根据预测得到的加速器性能增益累加到其父节点的性能增益上,然后接着遍历图节点。否则,接着判断节点与父节点的通信开销是否高于性能增益,如果是,将节点映射到CPU 上执行,并将其相关的子节点重新加入到节点遍历池中进行重新映射。否则,将节点映射到加速器上执行,接着判断是否整个图已经遍历完成,如果遍历完成则结束算法,否则继续算法执行。算法1 给出了PPTM的伪代码实现。

4 示例研究
为了验证算法设计的有效性,并为将来面向加速器的运行时系统设计提供参考,本文将针对之前的工作,面向流式应用的加速器平台ShuntFlow[3],也即面向计算核的处理器(kernel processing unit,KPU),设计和实现运行时系统(kernel operating system,KOS),并实现本文提出的任务映射方法。首先介绍ShuntFlow 加速器的硬件结构,然后介绍整个KOS的架构以及相关实现细节。
4.1 核处理器KPU
图3 给出了ShuntFlow(KPU)架构图[32]。KPU加速器主要加速实现了一系列流式应用中的聚合算子,这些算子在流式数据挖掘、金融风控等领域被广泛应用[33],可以被看成是多个计算核,从而可以将KPU 抽象成由多个计算核组成的加速器平台。表1给出了一个KPU 加速器实现的计算核的相关信息。
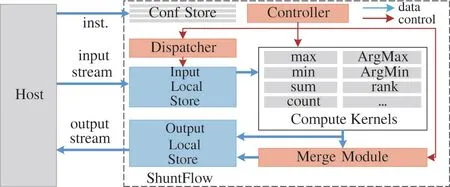
图3 ShuntFlow(KPU)加速器架构图

表1 KPU 计算核实现信息
在本文的实例中,KPU 总共实现了6 类计算核,其中加速比是对比CPU 不考虑数据传输延迟时,KPU 能够带来性能的提升,同时可以看出不同计算核能够实现的加速比是不一样的。输入数代表计算核需要几个输入数据,包括参数在内。
4.2 KOS 实现
首先,给出KOS 针对KPU 加速器的架构,在这里只给出支持KPU 和CPU 两个平台的实现,多平台的实现可以很方便地进行扩展。然后,将详细介绍针对KPU 加速器怎么实现PPTM 算法进行性能优化。最后,介绍了一些应用,用于下一节的测评。
图4 给出了KOS 针对KPU的架构图,接下来,将简单介绍一些模块的功能。

图4 KOS 架构图
KOS API主要包括计算流图构建、数据注册、计算核注册以及加速器相关属性注册等接口。针对KPU 需要注册的硬件属性,包括特定数据大小传输开销和硬件上计算核实现信息(见表1)等。
Memory Master采用BFC 算法来完成KOS内存管理,统一管理KOS 中的内存分配,回收内存碎片,降低内存分配开销。
Kernel Master主要负责接收注册的计算核信息,并提供给计算流图构建模块计算流图,并对节点进行标识。
Graph Master主要负责计算核节点的创建和释放,并根据计算核节点负责管理计算流图。
Hardware Resource Master提供加速器资源以及性能数据配置接口,并负责对加速器资源的分配和释放以及为性能预测器提供性能数据。
Data Master负责管理源数据和结果数据,同时提供接口,可以在不同节点或者平台之间完成数据格式的转换。
Distributed Manager主要负责根据平台信息等完成计算流图的调度,同时为了优化调度实现性能预测器。针对KPU,需要满足KPU 能够支持的最大计算核并行执行的资源限制,同时能够根据注册的通信开销、计算核加速比等信息,针对应用不同的数据大小等完成性能预测。
Dataflow Executor实现记分板算法,完成最小调度单位,计算流子图在不同平台的执行。
CPU&GPU Executor负责针对特定的平台完成子图的解析,然后根据子图的依赖关系,并行或者串行调度计算核节点到特定平台完成计算并返回计算结果。
YCC&CFD针对特定加速器平台KPU 实现的编译器和驱动层,主要负责将计算核节点解析成平台二进制指令,然后通过特定的传输协议完成与加速器的交互。
4.2.1 性能优化——PPTM 算法实现
如前面PPTM 算法的设计所述,PPTM 算法要完成计算节点的执行时间预测,不仅需要初始的性能配置数据,同时还需要获取任务的特定属性,如输入输出数据大小等,然后根据任务的运行时数据,才能提高性能预测的精度。因此,本文首先根据任务的输入数据大小,通过最小二乘法在初始的性能数据上,训练得到一个初始的节点性能预测模型。类似于执行时间预测,根据节点输出数据大小,在初始的通信开销数据上,训练得到一个初始的节点通信开销预测模型。然后,这些模型会在运行时,根据实际预测的测量值,不断调整整个模型来提高预测的精度。
基于以上获取的执行时间,根据之前描述的性能增益求取模型,可以很容易计算出计算节点的性能增益数据。然后,基于性能增益和通信延迟数据,KOS 将很容易实现PPTM 算法,完成任务映射。首先,基于深度优先遍历获得一个节点栈,方便从计算流图中的叶子节点开始遍历整个图。然后,得到应用程序的计算流图G的一份拷贝G′,作为映射算法的输入。最后,实现之前给出的PPTM 算法的伪代码,得到优化的计算流图G″。
4.2.2 应用示例
本文选取金融量化投资领域的一些实际应用作为示例应用程序,当然这些计算核在风险控制以及流式数据聚合中也被广泛使用[34]。同时,使用现实世界的股票的股价(price)、每日开盘价(open)、收盘价(close)、交易量(volume)以及回报率(returns)作为数据源,通过调用相关计算核可以实现对股票的量化交易因子挖掘。参考量化投资领域中因子挖掘算法[32],构造了如下5 个应用。
以上的5 个应用,是本文通过抽取量化投资领域中因子挖掘算法[32]的常见操作,然后抽象成计算核,最后对计算核进行随机组合而成。其中AVG 是求平均数,在加速器上没有实现,本文会在CPU 上给出其实现,因而其是栅栏节点。根据KOS 计算流图的定义,图5 和图6 给出了应用(4)和应用(5)的计算流图形式,其他应用的计算流图可以很容易类比得到。
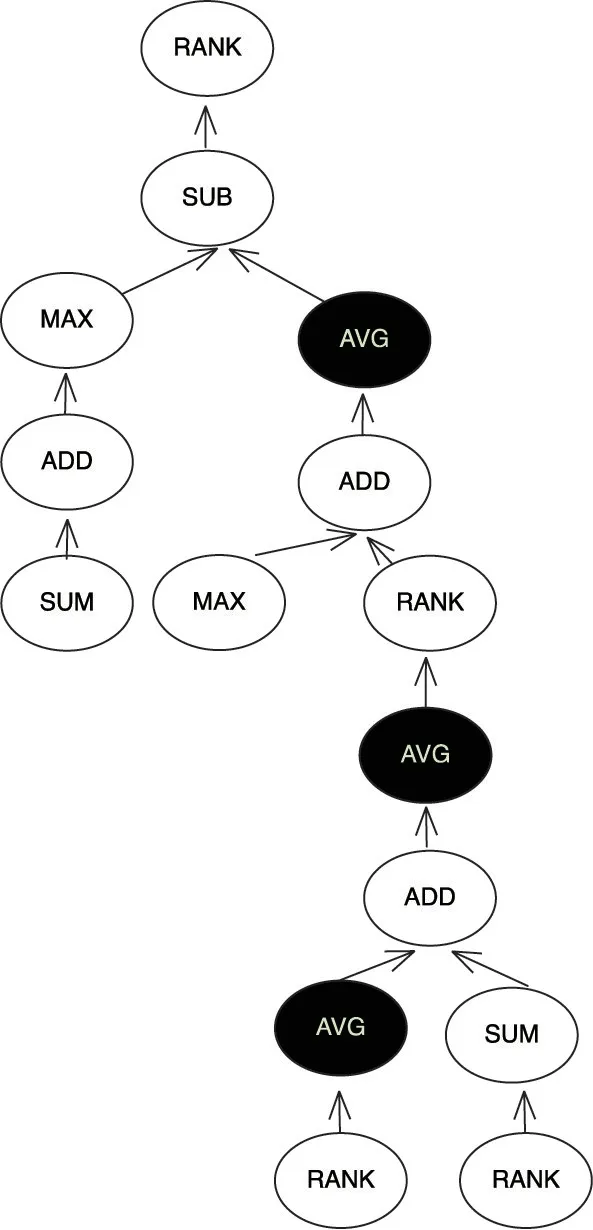
图5 应用(4)KOS 计算流图

图6 应用(5)计算流图
如图中所示,由于AVG 无法在加速器上加速,显示为黑色节点。限于篇幅,这里只给出了5 个应用示例,来证明本文系统的高效性。具体的分析将在下一节进行详细描述,其结论可以简单地推广到其他应用中。
5 测评与分析
5.1 测试环境与测试方案
5.1.1 测试环境
KOS的测试是在一台服务器上完成的,加速器KPU 通过PCIex8 接口连接。加速器实现在DE5a-Net的FPGA 板卡上,综合频率为150 MHz。服务器的配置如表2 所示。KOS的测试用例采用前面描述的5 个应用。

表2 测试环境参数表
5.1.2 测试方案
PPTM的设计目的是通过运用提出的主动式任务映射算法,能够根据系统的运行时数据动态地调整计算流图中计算节点的映射关系,从而提高整个应用程序在异构加速系统中的性能。因此,本文总共实现了3 种执行模式,如下所述。
Accelerator-Free(A-Free)模式应用程序不使用加速器进行加速,而是直接将计算流图中的所有节点全部映射到CPU 上执行,做为基础的对比数据。
DirectMapping(D-Map)模式采用传统的任务映射方法,即在映射应用程序计算流图中节点时采用加速器优先映射,也就是只要加速器支持的计算节点都映射到加速器上执行,来做为主要的对比算法实现。
PPTM 模式将运用提出的任务映射算法,来调度计算流图在异构加速系统中的执行方式。
基于以上的3 种执行模式,在不同的浮点数据集(data1-32M,data2-320M)上对不同的应用进行了多次实验,并统计了相关性能数据。
5.2 数据分析
5.2.1 性能分析
表3 和表4 分别给出了在不同数据集上,5 个应用在不同执行模式下的性能数据。

表3 数据集1 下应用性能数据

表4 数据集2 下应用性能数据
从表中可以看出,在数据集1 上,通过D-Map映射方式,将计算流图中的节点调度到加速器上执行可以带来巨大的性能增益,5 个应用平均性能提升了26.41%。但是在数据集2 上时,随着数据规模的加大,主机与加速设备的通信开销变大,采用D-Map的任务映射方法,对某些应用,带来性能增益有所下降,特别是对应用(5)。从图5 中可以看到,应用(5)中左子树上的栅栏节点AVG 所依赖的子节点,将其映射到加速器上执行,根据提出的算法,其累积的性能收益相比于其他栅栏节点偏少,如果将其调度到加速器上执行,带来的性能增益甚至不能抵消通信开销,从而导致整个应用程序性能增益下降。本文实验中,在数据集2 上,5 个应用通过DMap 映射方法在异构加速平台上带来的平均性能增益不足7%。
从表中可以看到,通过PPTM 任务映射算法,在不同的数据规模时,对比D-Map 映射方式都能带来性能增益。在数据集1 上,通信延迟还比较小,因此对于大多数应用通过D-Map 映射方法就能够带来很好的性能增益。本文提出的PPTM 算法,相比于D-Map 模式,带来了2.37%~14.06%的性能提升。而在数据集2 时,随着通信延迟的增加,PPTM 任务映射算法,相比于D-Map 映射方式,平均能够带来13.8%的性能提升。特别是针对应用(4),从图4可以看到,栅栏节点存在于叶子节点到根节点的关键路径上,尤其是最下面的2 个栅栏节点之间只隔了1 个节点。如果按照D-Map的任务映射方法,将这个节点调度到加速器上执行,将导致主机与加速设备之间反复进行数据通信,从而带来严重的通信开销。因此,通过PPTM 任务映射算法,将其映射到CPU 上执行,反而带来了24.85%的性能提升。
通过以上的数据分析可以看出,针对不同的应用程序,并不是将其计算流图中加速器支持的所有节点全部调度到加速器上执行,就一定能获得最佳的性能。因为针对某些应用,如果直接把节点映射到加速器上,会导致无法摊销的主机与加速设备之间的数据交互,从而带来严重的通信开销,反而无法提升整个应用程序的性能。因此,需要根据特定性能数据,合理地进行任务映射,才能最大化应用程序在异构加速系统上的性能。为了进一步分析通信开销对性能的影响,接下来,将对应用在不同的数据集上的通信开销数据进行分析。
5.2.2 通信延迟分析
图7 和图8 分别给出了D-Map 模式和PPTM 模式在不同的数据集下,应用由于存在主机和加速器端的数据交互而带来的通信开销数据。图中,D-Map-C代表应用在D-Map 模式下的通信开销,PPTM-C 则代表应用在PPTM 模式下的通信开销。

图7 数据集1 下应用通信开销数据对比
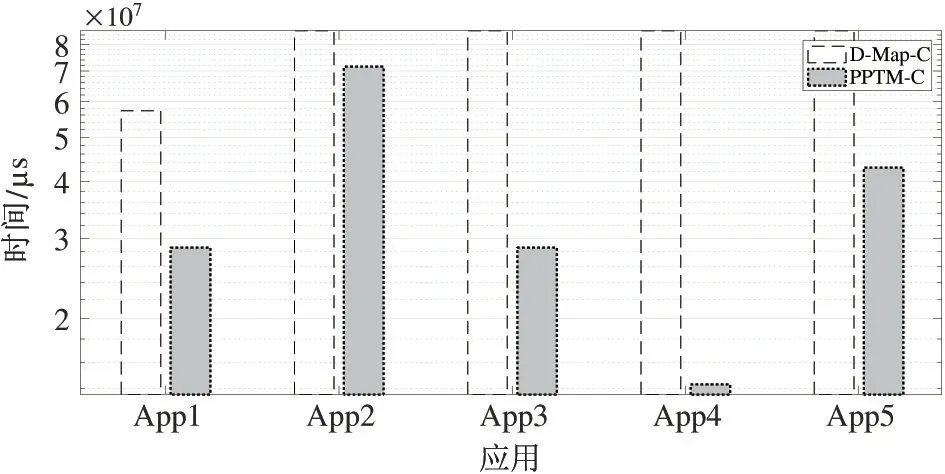
图8 数据集2 下应用通信开销数据对比
从图中可以看到,PPTM 任务映射算法,在不同的数据集上,其通信开销相比于D-Map 映射方法都要低。而在本文的假设中,通信开销只存在于栅栏节点的上下节点需要数据交互时。因此,必然是PPTM 任务映射算法改变了与栅栏节点相连的某些节点的映射方式。
从图7 中可以看到,在数据集1 上,PPTM 算法相比于D-Map,平均降低了24.9%的通信开销。但是,从之前的性能分析可知,其带来的性能增益平均不到6%。因为PPTM 虽然降低了应用程序的整体通信开销,但同时也会失去将某些节点映射到加速器上执行带来的性能增益,这需要根据应用的运行时数据做出权衡。
从图8 可以看出,当在数据集2 上时,PPTM 算法相比于D-Map,平均降低了53.3%的通信开销。同时,之前的性能分析表明,PPTM 带来了平均13.8%的性能增益,特别是应用(4),带来了24.85%的性能提升。从图7 中可以看到,针对应用(4),PPTM 算法对比于D-Map,降低了将近83%的通信开销。然而,对于应用(3),PPTM 算法降低了66.67%的通信开销,但性能增益微乎其微。
通过上面的分析可以看到,PPTM 算法通过改变栅栏节点子节点的映射方式必然会降低整个应用程序的通信开销,但并不是通信开销降低得越多带来的性能增益越高。除了因为改变节点映射方式后无法受益于加速器带来的性能增益,性能增益还跟具体的应用存在很强的关联性。
6 结论
现有异构加速系统中,将计算通过加速设备来加速,在需要与主机端进行交互的应用场景中会带来相应的通信开销。如果无法合理地摊销主机与设备端的通信开销,在特定的数据规模时(CPU 性能瓶颈不在访存时),针对不同的应用,并不是将其计算流图中的加速器支持的所有节点全部调度到加速器上执行,就一定能获得最佳的性能。通过引入PPTM 算法,在运行时动态地感知应用中计算节点的性能变化,实现更加高效的任务映射,能够提高应用程序的整体性能。最终测试充分验证了,针对不同的应用程序,本文提出的任务映射算法,能够实现更加高效的任务调度,从而提高应用程序性能。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
现代装饰(2022年5期)2022-10-13
小哥白尼(趣味科学)(2022年5期)2022-08-15
小学教学研究(2022年5期)2022-04-28
少先队活动(2021年6期)2021-07-22
北京航空航天大学学报(2021年6期)2021-07-20
电子制作(2019年19期)2019-11-23
电子制作(2019年14期)2019-08-20
商周刊(2019年1期)2019-01-31
电子制作(2018年19期)2018-11-14
