
基于Attention机制的LSTM股价预测模型
2022-04-08 09:28朱小栋
重庆工商大学学报(自然科学版) 2022年2期
林 昕, 朱小栋
(上海理工大学 管理学院, 上海 200093)
0 引 言
股价波动可以反映市场和经济的变化情况,但由于股价的波动性,预测股价一直是研究的热点和难点之一。对股价预测,最为常见的就是时间序列分析方法,比如吴玉霞等[1]建立ARIMA模型对华泰证券收盘价变动的趋势和规律进行了预测;Lin Z[2]利用GRACH模型对股票波动率进行建模;张贵生等[3]在ARMA-GRACH模型中融入股价滞后值的近似微分信息,提高了预测准确度。但是这些方法存在局限性,要求数据满足的约束条件高,对于长期预测的效果不是太好,并且对于非线性非平稳序列,一般都需要经过对数化或者差分等前期处理。
现今随着机器学习的发展,越来越多的人将神经网络应用于股票研究中。崔文喆等[4]采用GARCH模型和BP神经网络(Back Propagation)模型,利用上海A股30支股票分别进行短期、中期和长期预测,实验发现BP神经网络模型的每日与一周总体预测效果均优于GARCH模型,且总体差异具有高度统计学意义。Larry O O等[5]对34个包括新兴市场和发达国家的股票数据,比较BP和浅层神经网络结构,发现股票数据集越大越复杂,BP的表现越优于浅层神经网络结构。綦方中等[6]在BP神经网络中引入主成分分析法和果蝇算法,提高了上证指数股价的预测效果。
BP神经网络虽然相较时间序列分析方法有比较优异的性能,但学者们普遍认为BP神经网络可以实现的功能是有限的。因为股价受到多种因素影响,而这些因素之间彼此又会互相作用,信息长度各种各样且时时刻刻都在变化,故BP模型在学习复杂多变的股价波动规律时表现匮乏。学者们主要从两方面改进这一问题。
一方面是改进模型,长短期记忆网络是一种时间递归神经网络,是在循环神经网络(RNN,Recurrent Neural Netwrok)的基础上发展来的。RNN近年来文本翻译和序列预测问题中具有广泛应用,但其在训练网络过深时,容易产生梯度消失和梯度爆炸现象。LSTM在解决这一问题的基础上,对长期信息记忆更加有效,故将它应用在时间序列预测上,预测准确度将会得到提高。彭燕等[7]搭建不同层次的LSTM模型,将股价预测准确度提高了约30%。冯宇旭等[8]将LSTM用于沪深300指数的预测,相比SVR和Adaboost准确度更高。
但LSTM在学习输入序列的过程中,通常将其编码为固定长度的向量,当输入序列较长时,会限制模型的性能。Attention Mechanism(注意力机制)通过保留LSTM对输入序列的中间输出结果,然后训练一个模型对这些输入进行选择性的学习以解决这一问题。基于Attention机制的LSTM模型已经在多个领域被证实具有更优的性能,如Youru L等[9]在时间序列领域,将基于Attention机制的LSTM模型用于多个时间序列数据集做预测,实证结果证实模型比其他基准模型有更优的预测表现;胡荣磊等[10]在文本分类实验中,在LSTM和CNN的基础上加入了Attention机制,分类结果比未加入的有所提高;Dzmitry B[11]在机器翻译中引入注意力机制,以LSTM作为编码器和解码器,提升了机器翻译的准确度。因此本文通过将基于Attention机制的LSTM模型(AM-LSTM)用于预测股价的第二日最高价,并将其预测结果与MLP(Multilayer Perceptron,多层感知机),RNN和LSTM做出对比。
另一方面是选择更多与股价波动相关的特征或改进特征处理方式,以提升数据质量。在特征选择方面,近年来行为金融学的发展,学者们开始将投资者情绪加入股价数据来提升模型的预测性能。一些学者将人所处的环境,如光照、云层、温度等[12-13]纳入影响因素进行考虑。其中部分国内外研究发现空气污染会通过引发投资者情绪进而影响股票市场的走势[14-16],但总体上关于两者之间的研究并不多见。在改进特征处理方式方面,Cheong D等[17]提出了一种基于K-means的投资组合优化方案,通过对投资者信息的聚类分析确定投资组合;陈佳等[18]在对纳斯达克和标普500指数预测完成特征选取后,分别应用系统聚类法进行特征分类、主成分分析法进行特征降维,提高了预测准确度和速度;李文星等[19]提出一种附有引力影响因子的半监督K-means核函数聚类算法,将其应用于多因子选股中,在选出较优的股票组合中具有优势。本文的目的在于预测上市污染企业和上市环保企业的股价波动趋势,故将与环境有关的指数加入预测模型,并利用Attention机制学习更重要的特征。
学者们将神经网络应用于股价波动趋势预测,取得了比时间序列方法更优的表现,但神经网络的固定编码向量长度会对其性能有所限制,故本文在神经网络中引入了注意力机制。现有文献探究了多种与股价波动相关的特征,拓宽了影响股价波动的研究思路,但分类研究不同类型股票的文献较少,本文对污染企业和环保企业的股价波动进行了分类研究。
在以往文献的基础上,主要做出了以下贡献:通过将基于Attention机制的LSTM模型用于股价预测,提升了预测性能;分别以上证工业指数作为上市污染企业的代表,上证环保指数作为上市环保企业的代表,分类研究不同类型股票价格预测的准确度;将空气质量指数、温度和湿度纳入模型特征,提高污染和环保企业股价的预测能力。
1 LSTM模型设计
介绍了LSTM结构和Attention Mechanism,并将Attention机制引入LSTM模型(AM-LSTM模型),通过将基于Attention机制的LSTM模型用于股价预测,提升预测准确度。
1.1 LSTM
LSTM是循环神经网络的一种变形,标准循环神经网络RNN相较于传统的BP神经网络,尽管可以利用时间序列的信息,但RNN在长距离传输下,容易发生梯度消失或梯度爆炸现象,导致反向传播过程中,神经网络无法训练权重,使得RNN难以学习长距离的信息。为解决这一问题,Hochreiter & Schmidhuber于1997年提出了LSTM[20],通过增加了一个细胞单元和3种门机制,来控制信息流和避免长期依赖问题。
如图1所示,贯穿于顶部的水平线称为细胞状态,信息可以沿着这条线不变的流动,以解决对长距离信息学习不足的问题。3种不同的门分别为输入门,遗忘门和输出门。遗忘门决定信息的丢弃,输入门决定信息的更新,输出门决定细胞状态的信息输出。通过门结构来保存重要的信息,遗忘不必要的信息,以提高对长时间序列的记忆。LSTM各个门的计算如式(1)—式(5)所示:
it=σ(Wi*[ht-1,xt]+bi)
(1)
ft=σ(Wf*[ht-1,xt]+bf)
(2)
ot=σ(Wo*[ht-1,xt]+bo)
(3)
Ct=ft⊗Ct-1+it⊗(Wc*[ht-1,xt]+bg)
(4)
ht=ot⊗tanh(Ct)
(5)
其中σ是sigmoid激活函数,it,ft,ot,ht分别为t时刻下各个门的状态,细胞状态和输出。

图1 LSTM结构图
1.2 Attention机制
股票价格随着市场因素、环境因素等的变化而不断波动,不同时间点的因素变动对当前股价的影响程度也不同。距离当前时间点更近的信息,由于时间间隔短,对股价波动的影响越大;随着距离当前时间点的间隔越远,这种影响逐渐减弱。
Attention机制可以很好地捕捉到股价变动的这一特征,它改变了传统的encoder-decoder结构,传统的解码器对每一个输入都赋予相同的权重,但现实中不同的输入重要性往往不同。Attention通过在解码过程中,利用评分函数计算不同输入对预测值的影响程度,为其赋予不同的权重来解决这一问题。其本质通过计算当前的输入序列和输出向量的差异,差异越小就说明注意力应该在此处应该赋予更大的权重。Attention机制如图2所示。
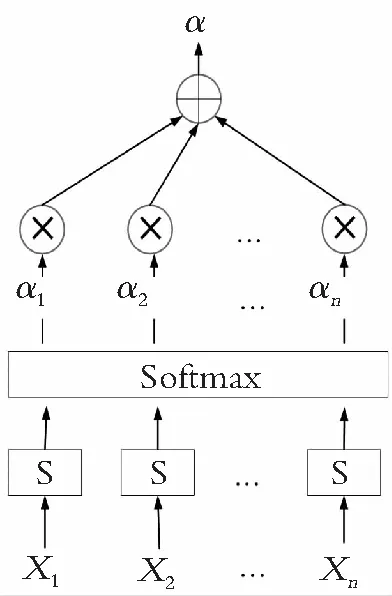
图2 Attention结构图
1.3 AM-LSTM模型
通过输入历史时间序列数据(X1,X2,…,Xn)学习特征,对第n+k天的最高股价进行拟合。预测第二日的最高股价,即设置k=1。图3展示了AM-LSTM模型对股价预测的总体结构,共包括4个部分:数据预处理、LSTM层、Attention层和全连接层。

图3 AM-LSTM模型结构图
1.3.1 数据预处理
预处理后的数据存储在CSV文件中,由于样本数据各自的量纲不同,为了提高实验的可信度,需要对数据进行归一化处理,归一化公式如式(6)所示:
(6)
其中,Xnew是归一化后的数据,X是原始数据,Xmin,Xmax分别是原始数据的最小值和最大值。
1.3.2 LSTM层
LSTM在时间序列数据的分类和预测中都有很好的表现,故用于学习预处理后数据的深层特征。通过LSTM层的训练,可以更充分地学习时间序列数据的长期关系。LSTM当前的隐藏层状态由当前输入Xt和(t-1)时刻的隐藏层状态Ht-1共同决定。输入第j时刻的序列信息Xj,LSTM层的输出结果如式(7)所示:
Hj=LSTM(Xj,Hj-1)
(7)
1.3.3 Attention层
Attention层输入为上一层LSTM的输出,首先通过编码器(Encoder)进行编码,然后通过Attention对编码向量计算对应的权值(α1,α2,…,αN),用计算的权值对编码向量进行加权作为解码器(Decoder)的输入,最后经过解码器得到输出。通过不断学习优化相应的权值,突出输入特征中的关键信息,进一步深度挖掘变量之间的非线性特征。Attention层相似度的计算如式(8)所示,分数越高说明关注度越高,注意力机制就会给其分配更大的权重:
uj=tanh(WiHj+bi)
(8)
其中Wi是权重系数,bi是偏置量,将uj输入softmax函数中,进行归一化,如式(9)所示,得到归一化后的权重αj:
(9)
其中,uw是随机初始化的注意力权重矩阵,Attention机制的S是不同权重与对应各个隐藏层状态的乘积的累加和,计算如式(10)所示:
(10)
最终得到了各个变量被赋予了不同关注度的Attention层的输出,如式(11)所示:
Fj=H(S,Hj)
(11)
1.3.4 全连接层
全连接层的输入为Attention层的输出。全连接层对该层的输入进行计算,得到股价的预测结果。与真实的股价值相减,返回损失函数。通过损失函数的反向传播,不断地修正权重和预测结果,如图3所示。
2 数据描述和评估指标
2.1 股价波动数据
受文献[15]的启示,选取上证工业指数代表污染企业的发展,上证环保指数代表环保企业的发展。由于自2014年以来,雾霾问题的爆发以及人们对环境问题关注度的上升,故选取两种指数从2014-01-02—2020-09-22日的每日数据,共1 642笔数据,数据均来自于Wind。涉及的基本特征包括开盘价、最高价、收盘价、最低价、成交量、成交额这6个变量,以此数据进行训练与测试,通过前一天的信息预测第二日的最高价。
2.2 空气质量数据
He等[22]认为上海是中国的金融中心,拥有中国最大的股票交易量,其天气情况对中国股票市场的影响最显著;在Levy等[14]的论文中,其实验数据也证实了He等[22]所提出的观点。故选取上海市的空气质量数据建立预测模型。AQI是世界范围通用的衡量空气质量的综合指标,囊括了PM2.5,CO,SO2等污染物的监测,通常被划分为0~50,51~100,101~150,151~200,201~300以及大于300六个阶段,分别代表空气质量优、良、轻度污染、中度污染、重度污染和严重污染。故选取上海市的AQI,温度和湿度数据作为空气质量的衡量指标。与股价数据相对应,AQI,温度和湿度数据也选取了2014-01-01—2020-09-22日的日度最大值,并剔除了周末及节假日等非交易日数据,以使空气质量数据周期与股价波动数据周期保持一致。相关数据来源于中国气象局。
2.3 评估指标
为保证对比实验的一致性,在实验过程中,所有的对比模型均将数据按85%:15%划分为训练集和测试集。1 640个交易日的数据,共划分训练集1 394笔数据,测试集246笔数据。并采用均方根误差(Root Mean Square Error,RMSE)用作模型的评价指标,RMSE值(fRMSE)越小,表明模型预测越准确。RMSE计算公式如式(12)所示:
(12)
其中,ypre是预测值,yact是实际值。
3 实验结果与分析
3.1 AM-LSTM模型验证
为了验证AM-LSTM模型的性能,将AM-LSTM模型与3种基准模型进行了比较。参数设置如表1所示。

表1 模型参数设置
实验过程中,为了保证实验的准确和客观,将每种模型在同一训练集和测试集上均进行了10次实验,取RMSE的平均值作为模型最终结果。实验结果如表2所示。
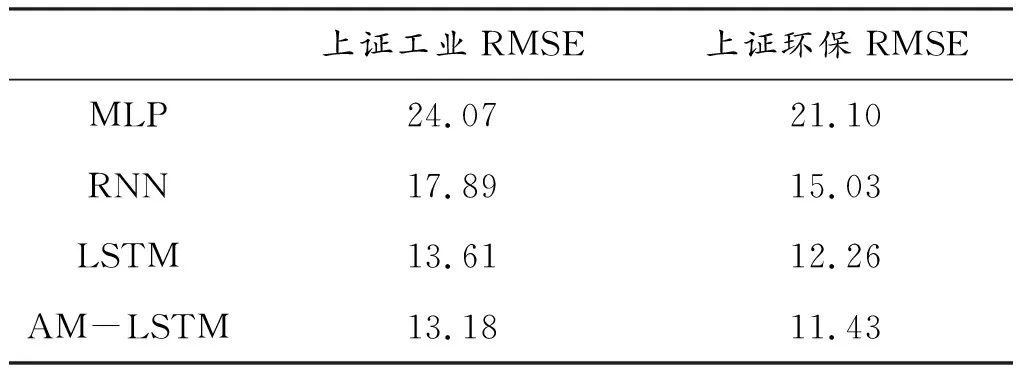
表2 不同模型结果对比
从表2可见,循环神经网络的表现均优于前馈神经网络,主要原因是其能够更好地捕捉时间序列特征。LSTM和AM-LSTM的RMSE值低于RNN,其原因是LSTM在学习远距离信息时表现更优。基于AM-LSTM模型的RMSE值在上证工业指数和上证环保指数的预测中均低于其余基准模型,其原因主要为该模型集成了LSTM记忆机制在处理时序模型方面以及Attention在赋予特征权重方面的优势。此外,4种模型在测试集上对上证环保指数的预测误差均小于上证工业指数,说明模型对上证环保指数的特征具有更好的学习能力。
此外,为了进一步探讨AM-LSTM相较于其他3种模型对于预测误差的降低程度,基于测试集的结果提出了相对误差,计算如式(13)所示,式(13)中i为第i种股价指数。表3为相对误差的结果。由表3可见,AM-LSTM相较于MLP,对两种指数预测准确度的提升幅度均超过了45%;相较于RNN,也均超过了20%;对比LSTM也有小幅的提升,进一步说明本文提出的模型在预测多变量时间序列问题中更具有针对性。

(13)
3.2 样本纳入空气质量数据验证
图4和图5为4种模型加入AQI、温度和湿度特征前后,上证环保指数和上证工业指数测试集的RMSE值对比结果。可以看出,在纳入AQI,温度和湿度特征后,4种模型的RMSE值均有不同程度的降低。
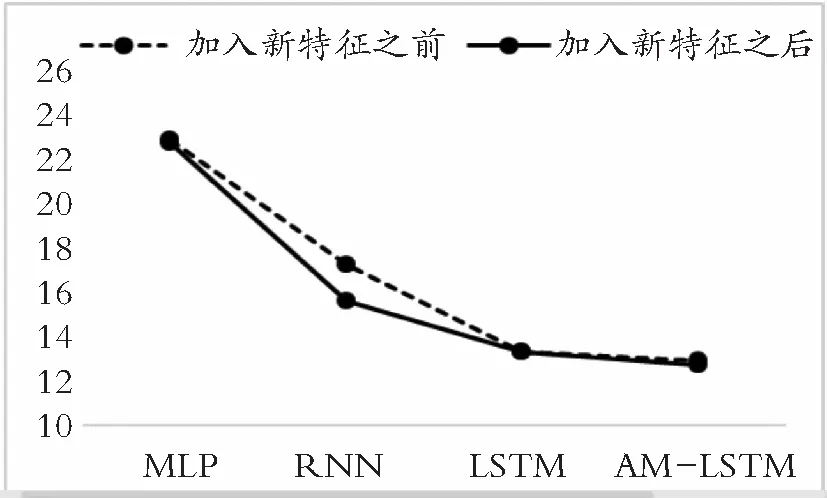
图4 上证工业指数对比图

图5 上证环保指数对比图
在上证工业指数中,LSTM和AM-LSTM的RMSE值约下降了0.7%,RNN的RMSE值下降幅度略高于前两者,为1%。这可能是由于LSTM和AM-LSTM在未纳入该特征前,相对于RNN已经学习更多的信息,表现更优,所以在加入特征后,RMSE值的下降幅度小于RNN。
在上证环保指数中,4个模型的RMSE值表现出了与上证工业指数相似的变化趋势。LSTM和AM-LSTM的RMSE值的下降幅度接近1%,RNN的RMSE值下降幅度高于前两者,略高于1%。
实验结果表明:将空气质量有关数据纳入模型特征,对提升两种股价的预测准确度有一定作用。这一结果也是符合投资者心理预期的,上证环保指数代表了环保企业的表现,空气质量的优劣一定程度上会向投资者释放这些企业经营状况的信号;而工业行业的生产均会产生被纳入空气质量指标的有害气体;即这些指数对空气质量的变化较敏感,因此空气质量的变化也会传递能被模型学习的特征。
4 结 论
以上证工业指数代表污染企业,上证环保指数代表环保企业,通过将基于Attention机制的LSTM用于预测股价的第二日最高价。并将AQI、温度和湿度作为新的特征纳入模型,得结论:
(1) 通过对比MLP、RNN、LSTM和AM-LSTM模型,AM-LSTM的预测准确度最高,表明其在处理多维非线性问题时,具有更好的预测性能。且说明不同变量对股价预测的重要性不同,未来可以进一步探讨哪些变量具有更高价值的信息。
(2) 将AQI,温度和湿度纳入模型特征,模型的RMSE值进一步降低,表明空气质量的变化能够传达出上市污染企业和上市环保企业经营的信号。其中对环保指数预测准确度高于工业指数。
(3) 虽然将Attention机制引入LSTM,模型的预测性能进一步提升,但仅仅增加了AQI、温度和湿度进行实验,在股价受到多种因素影响的情况下,准确度提高的并不显著,未来可以考虑尽可能地将其他多种因素纳入模型中,并结合聚类、分类等多种特征处理的方法,进行更深入的探讨。
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
农业灾害研究(2022年2期)2022-05-31
中国教育信息化·高教职教(2022年4期)2022-05-13
科海故事博览·下旬刊(2022年4期)2022-05-07
煤气与热力(2022年2期)2022-03-09
软件(2017年6期)2017-09-23
价值工程(2016年32期)2016-12-20
考试周刊(2016年34期)2016-05-28
中小企业管理与科技·中旬刊(2014年10期)2015-02-03
