
基于SAE-OCSVM的伪芯片检测研究
2022-04-08 00:13李雄伟刘俊延张阳陈开颜刘林云
湖南大学学报·自然科学版 2022年2期
关键词:集成电路
李雄伟 刘俊延 张阳 陈开颜 刘林云








摘要:针对传统芯片检测方法存在检测效率低、要求高、适用性差等问题,提出了基于电磁旁路信号和机器学习方法的伪芯片检测框架.首先,在持有正品芯片的基础上通过引入神经网络和多种特征提取方法提取特征向量,并将正样本的指令信号作为模板库;然后,对待测芯片近场电磁信号进行加窗分帧,并对每帧信号进行特征提取;最后,将特征向量输入改进核函数的一类支持向量机进行扫描式匹配,从而达到芯片检测的目的.实验结果表明,该方法能够适用于以次充好重标记类型的伪芯片检测.
关键词:集成电路;伪芯片检测;旁路分析;自动编码器;一类支持向量机
中图分类号:TN407
文献标志码:A
随着半导体行业的迅猛发展,集成电路芯片广泛应用于各领域中,并发挥着十分重要的作用.中国是集成电路芯片的最大市场,随着新基建大力建设,2020年芯片需求与上年相比增长3%.由于芯片的广泛应用和工业终端设备的特殊应用需求,对芯片的稳定性、可靠性、安全性、大规模一致性、寿命等提出极高的要求.在极其复杂的应用环境下,要求产品能够7*24小时连续稳定运行,寿命达十年以上.然而,集成电路芯片产业链涵盖设计、生产、分销等众多环节,且需由众多厂商分别完成,无法保证每一环节的可信性[1].在此过程中,芯片设计可能被仿制、芯片生产可能被篡改、芯片分销可能会存在以假充真、以次充好、以旧充新等情况,这些都是典型的伪芯片问题[2],对芯片的可靠性及其应用安全性造成严重威胁.这些芯片一旦被部署在关键的电子系统或设备中,运行过程中出现故障,将造成不可预估的损失和严重后果.因此,确保芯片的真实和可靠至关重要.
伪芯片通常包括重标记、过量生产、不合格、克隆等类型[3].本文主要针对以次充好、以假充真等重标记类型的伪芯片进行检测.传统的检测方法主要分为物理检测和电气检测[3]两大类.物理检测包括:封装分析、芯片开封、材料分析等方法.其中封装分析和芯片开封会对芯片造成破坏,一般适用于抽样检测;材料分析的方法通过X射线或红外光谱进行检测,检测时间长效率低.电气检测包括:参数测试、功能测试、结构测试等方法.虽然这些方法成本较低,对芯片也不会造成损坏,但对检测人员要求高,过分依赖人为的规范操作,并且当芯片中的电气参数相差较大时,很难断定其究竟是伪芯片还是由工艺或环境的干扰所致.
近年来,旁路分析[4]逐渐成为密钥攻击、硬件木马检测的主流方法,并在实践中证明了该方法的有效性[5-6].因此,本文希望通过对芯片的电磁旁路信号进行分析,从而达到检测伪芯片的目的.
1相关工作
現代集成电路中包含了数十亿的载流金属线和电子元件,通过电磁探针能够有效的采集到芯片运行时的近场电磁信号[7].该信号受到许多电路参数影响,例如技术、布局和布线、代码、内部滤波、封装、温度、老化等,对这些参数进行任何修改都将导致磁场发生变化.不同级别的差异在旁路信号中以不同的量级体现出来,相似而不同芯片之间的差异可能体现在其中很微小的部分.由于集成电路的硬件特性,可以认为其工作状态下的电磁信号是相对稳定的.因此,业内普遍认为基于旁路分析的检测技术是一种较为有效的检测手段.
Huang等人较早提出了利用“电磁指纹”实现对集成芯片检测的思想[8],并展开了利用电磁信号区分真实设备和不同设备的第一次探索性实验,以证实该方法的可行性.作者讨论和研究了两种数据分析方法并通过实验表明:当对原始设计实施某些修改或进行加速老化测试时,将引起电路电磁指纹的变化.并且采用近场测量方法对其他电路进行的几次并行测试也得出了相同的结果.但该方法要求条件比较严苛,需保证测量环境完全相同,且其测量的精度和速度也并不可观.Andrew stern等人提出了一种基于电磁信号的芯片检测框架,用于检测标记和克隆的伪造芯片[9].作者演示了该框架在有参考和无参考情况下的分类方法,并通过在所有IC上执行非监督(主成分分析)和监督(线性判别分析)的机器学习方法,从而确定不同厂商和相同厂商所生产同系列芯片的相似性.作者采用了多种认证的手段,能够减小错分的可能性,但受限于仅启用芯片的时钟网络,未考虑芯片实际应用场景,适用性较差.在文献[10]中,作者同样提出了基于芯片辐射的物联网设备检测方案(CREBAD),首先用快速傅里叶变换对芯片的电磁信号进行时频转换,再利用遗传算法和近似熵等理论对旁路信号进行特征提取和选择后进行分类.该文献在特征提取方面做了充足的考虑,并且一分类的方法能够适用于更加复杂的场景.但是该文献没有考虑近场电磁信号不稳定的问题.文献[11-12]中,作者通过分析密码芯片旁路信号,从而获得程序执行的指令代码,这为伪芯片的检测提供了新的思路.JungminPark等人利用KL散度和PCA等方法提取特征并降维,再结合机器学习算法来确定在设备上执行的指令.该方法能够以较高的准确率来实现旁路反汇编,但是其算法在提取特征过程中效率较低.
在总结分析相关工作基础上,本文提出了一种基于SAE-OCSVM(Sparse Autoencoder-One Class SupportVectorM achines)的伪芯片检测框架,主要贡献有以下几个方面:
1)提出了基于操作指令的芯片检测方法,并采用滑窗搜索的策略匹配模板指令,从而实现芯片运行时的无损在线检测.
2)提出了神经网络结合人工提取特征的方法,实现高效、表征性强的特征提取.
3)采用一类支持向量机对特征向量进行分类并对算法中高斯核函数做了一定改进,以适应融合特征向量中不同量纲的特征.
2伪芯片检测框架
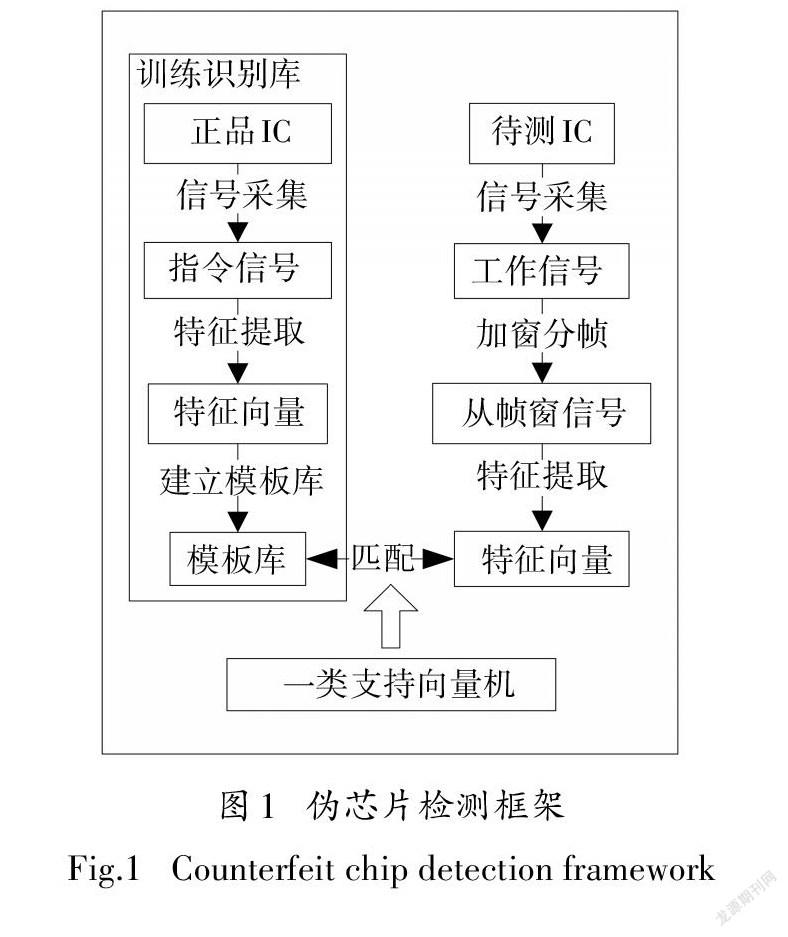
本文提出的伪芯片检测框架建立在持有受信任来源的正品芯片基础之上,其核心思想是通过现有的正品芯片对有限的汇编指令信号进行特征提取并训练为模板库,这些模板作为后续识别待测芯片的依据.将待测芯片的采集信号加窗分帧并进一步识别,从而将杂乱无章的信号反汇编,实现与模板信号的匹配识别.伪芯片检测框架如图1所示.
1)信号采集.获取正品芯片在执行不同汇编指令时泄露的旁路信号,可以在其内部添加电压触发信号以采集到更加准确的信号模板.将采样信号模数转换为离散的采样点,用于后续的特征提取和检测.采样频率越高,信号还原度越高,但增加了数据的计算量;采样频率越低,可能损失的信息量越多,比如丢失极值点的情况.对于已经封装好的芯片,电磁探针应当紧贴芯片正中位置的上方采集近场信号(远场信号微弱,干扰信号较多).由于近場信号随空间距离变化快,电磁探针的信号采集位置不应有较大变化,否则将影响识别准确率,可以将待测设备固定在微动平台上确保探针位置的精准放置.
2)特征提取.由于原始信号内含有大量无关的冗余信息,因此需要建立多特征融合的模型来表述该信号.自动编码器作为一种无监督学习的深度神经网络结构[13],一般用于降噪、特征提取和降维.通过损失函数(1)最小化重构误差达到自动学习输入数据中隐含特征的∑目的:
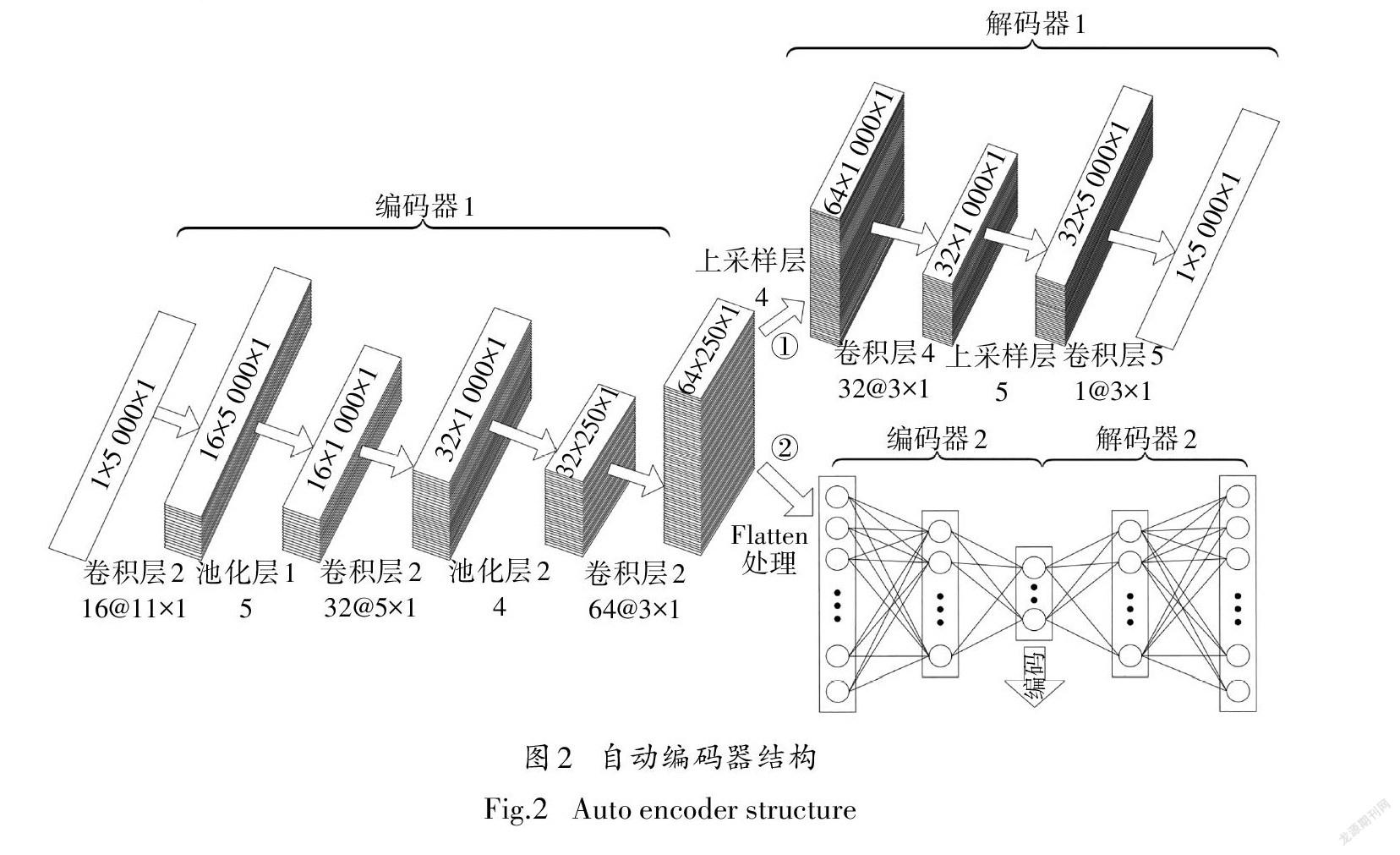
式中:h为编码器的映射函数,g为解码器的映射函数,l为训练样本数,θ和θ′为编码器和解码器的训练参数.本文构建的自动编码器特征提取分为两个步骤:首先利用卷积层、池化层和上采样层代替传统的全连接层,构建卷积自动编码器对电磁辐射这样的时间序列信号进行特征提取,能够有效避免序列信息丢失并解决采样信号不对齐的问题.然后利用只含全连接层的自动编码器对卷积自动编码器提取出的特征进一步降维.通过该方法能够自动提取信号中的隐含特征,其结构如图2所示.
为解决梯度消失和过拟合等问题,目前激活函数主流使用Relu函数.在第一步的卷积自动编码器中,由于原始电磁信号的幅值在-1到1之间,所以最
后一层卷积核的激活函数采用Tanh函数,这样能够在输出层实现信号的重构.并且实验中发现,在损失函数∑中加入稀疏惩罚项能够提高识别的准确度:
式中:ρ为稀疏参数,ρ̂j为编码层神经元的活跃度.它能将编码层的平均激活度控制在一个比较小的值,通过这种神经元的稀疏性表达[14]可有助于提取特征,由于引用了稀疏惩罚项,编码层的卷积核采用Sigmoid激活函数,而不能用Relu,否则会导致ρ̂j出现大于1的可能.
卷积自动编码器所提取的特征主要是与时间序列相关等一些抽象的特征信息,它对信号的描述相对来说比较宏观,难以对信号细节差异部分进行有效的描述,当两条差异很小的信号作为自动编码机的输入,它们可能提取出相同的特征向量并把这些细微差异当作噪声滤掉.因此,需进一步人工提取原始信号的特征∑f′(cext,cvar):
式(3)中的e为信号中的各极值点.在大量的测试实验中发现,不同汇编指令对应的信号差异体现在各极值点处明显,并且在密码分析的公共数据集中,原始信号被处理成了只含有极值点的数据集[15].式(4)是信号离散程度的度量,近场的电磁强度随距离的变换较大,在这个空间内磁场十分不均匀,电磁探针在空间上的细微偏差容易导致采集的信号在幅值上不稳定,与均值作商能够一定程度上消除这种影响.
3)待测芯片旁路信号采集.与模板信号采集不同,待测芯片的旁路信号是在线采集的,它可以在芯片执行任何操作时采集任意时间段的旁路信号.事实上,许多芯片也作为模块化设计中的组成部件已经焊接完成,无法进行拆解检测.
在实验中发现:连续两条汇编指令之间会互相产生一定的影响,可以采用Hamming窗或者长度略小于指令周期的矩形窗.信号采集时长大于4个机器周期(51单片机),这样能够保证采集到的信号至少包含一条完整的指令信息.通过对采集的信号加窗分帧,并对每帧加窗信号进行上述的特征提取步骤:
x为每帧窗信号Y中离散点,W为加窗函数,将人工提取的特征f′与自动编码器提取的特征hθ(W⋅Y)融合成特征向量f作为支持向量机的输入.
4)采用一类支持向量机对融合特征向量进行训练和分类.一类支持向量机是指训练数据中只含有一种类别的数据(Positive or Negative),能够通过调整参数控制学习样本的边界,把异类数据排除在边界之外.支持向量机中核函数的选取非常关键[16],核函数通过隐式地改变样本向量到特征空间的映射,进而影响分类的效果.传统的一类支持向量机核函数有线性核函数和非线性核函数,非线性核函数以高斯核函数最为著名,高斯核函数等非线性核函数2通常采用欧氏距离x1-x2来描述样本之间的相似性,但采用欧氏距离时会导致在分类过程中把不同量纲的特征元素等同的看待.因此,本文在高斯核函数基础上,将计算欧式距离的绝对差改用相对差来描述,以适应提取的融合特征:
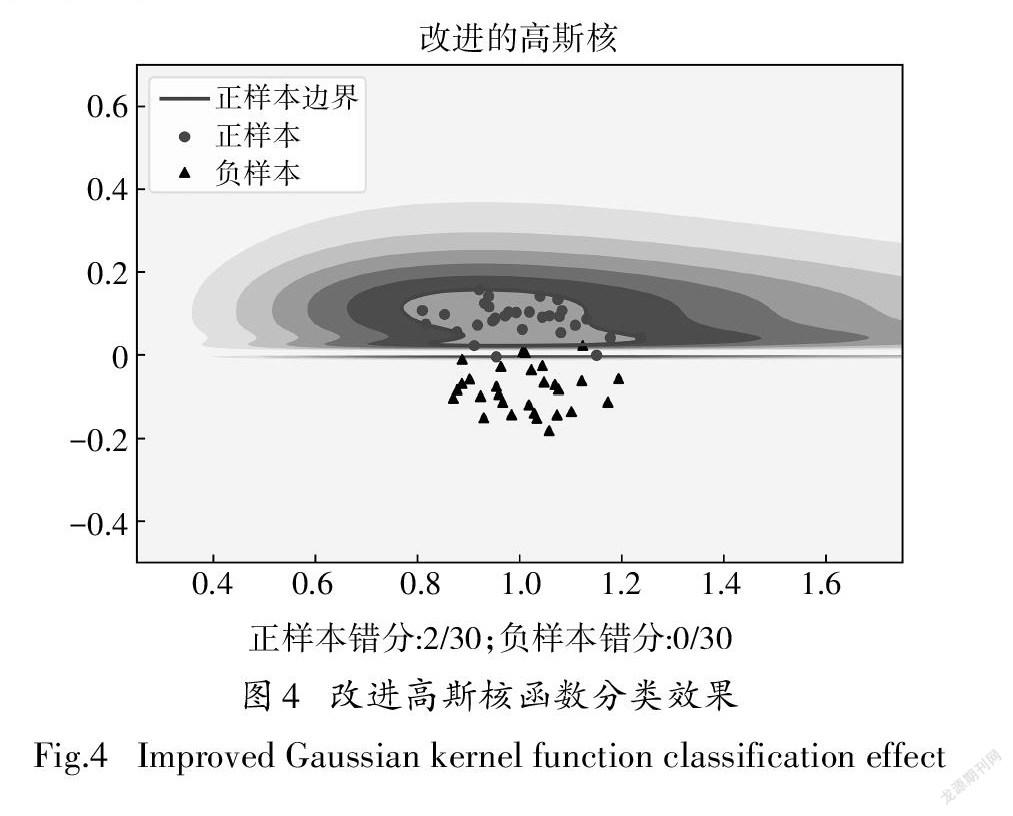
式中:x1为待测样本,x2为正样本;m为特征向量的维度,算法外推能力随着参数σ的增大而变弱.为了直观的观察核函数改进后的优越性,选取二维的特征向量进行实验模拟上述情况,按照正态分布随机生成30个正样本点和30个负样本点,第一维度按照正态分布的随机性是第二维度的数倍,决策边界划分结果如图3所示.
从图3能够看出,在只有正样本作为训练集的情况下,线性核函数(例如Linear、Poly、Sigmoid等核函数)无法适应一分类的情况.而基于欧氏距离的高斯核函数分类效果也不太理想,许多负样本被误判为正样本.按照上述思想对高斯核函数进行修改,实验结果如图4所示.
高斯核函数改进,能够有效的应对此类情况;一类支持向量机的核函数能够将数据映射到高维特征空间,通过假定坐标原点为唯一的一个异常样本,在聚集性的特征空间中划出一个参数为ω,ρ的最优的超平面并将目标数据和坐∑标原点最大分离:
式中:ςi为松弛变量,调整参数υ允许在分界面和坐标原点之间存在少部分的样本.与二分类的SVM不同但又相似,能够在训练数据集只有正样本的时候通过计算距离和决策边界的范围判断其正负.当待测设备中未匹配到模板中的任何信号,推断该芯片存在问题.
伪芯片检测框架的算法流程描述如下:1:建立模板库输入:正品芯片执行各指令的旁路信号X(离散信号);
输出:特征向量模板库L,自动编码器神经网络模型model;
1model←modeltraining(X)
2whileThetemplatehasnotbeenestablisheddo
3feature1←mode(lX)I
4feature2←artificialfeatures(X)I
5L[I]←(feature1,feature2)
6I←i+1
7end
8returnL,model
2:待测芯片检测
输入:特征向量模板库L,自动编码器神经网络模型model,待测芯片工作状态下旁路信号X′(离散信号);
输出:芯片检测结果
1frame signal←window-framing(X′)
2for j←0 tooNumber of framesdo
3Feature vector1←model(framesignal)
4Featurevector2←artificialfeatures(framesigna)l
5Featurevector←(Featurevector1,Featurevecto)r6Resul[tj]←OCSVM(L,Feature vector)
7end
8return Result
3实验与分析
3.1实验设计
本实验选用8051系列中STC89C52RC40I-PDIP40作为正品芯片,并选取了具有非常相似功能特性的AT89S52、STC89C51RC40I(工业级)、STC89C52RC40C(商业级)芯片模拟伪芯片的存在,因为其指令集架构、工作电压和封装类型都是相同的.将40枚正品芯片的指令信号进行训练,另外10枚正品芯片与假定伪芯片(每种各10枚)混合在一起模拟芯片工作状态下的检测.其中AT芯片模拟“以假充真”的情形,该芯片不论是在整体布线上还是其它参数上都与正品芯片有着较大的差异;STC芯片模拟“以次充好”的情形.其中STC89C52RC40C在材料和工艺上相比于工业级芯片存在一定的差异,但正常环境使用时与工业级芯片几乎没有区别;STC89C51RC40I芯片与正品芯片之间的差异仅仅体现在存储器上,其电磁辐射与正品芯片之间的差异极小.
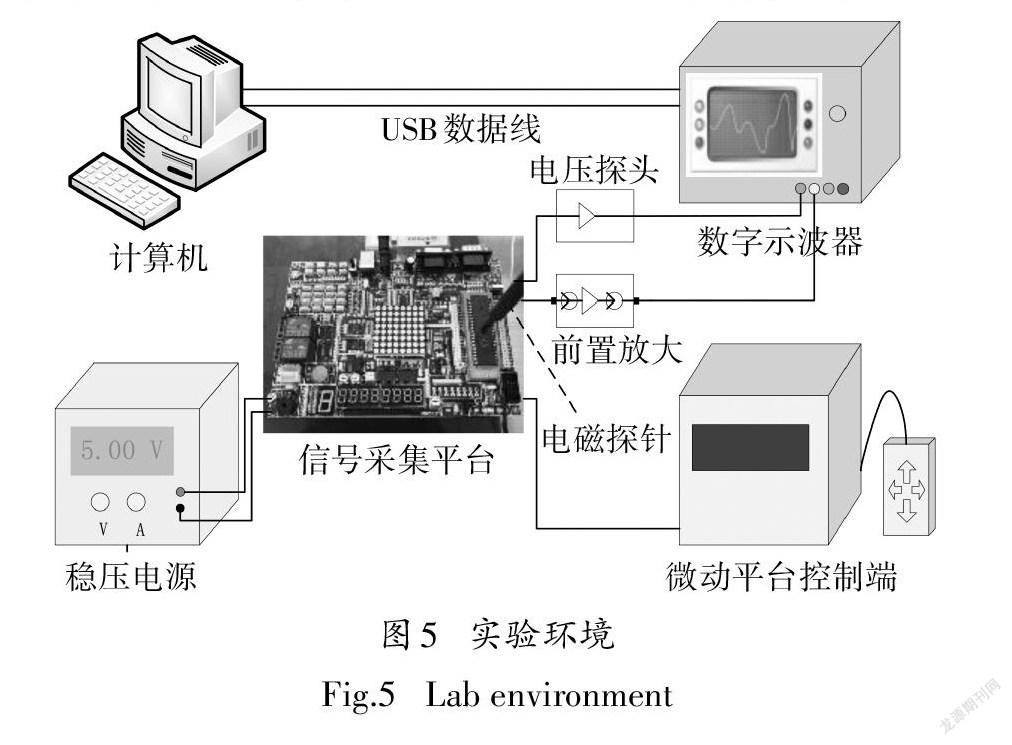
实验环境搭建如图5所示,将待测设备固定在微米级微动平台(KOHZU)上,采用单路稳压稳流电源(DH1719A-3)供电.电磁探针(LANGERRF-B3-2)将采集到的电磁信号传送给示波器(TektronixDPO-4104),并通过数据线传送到计算机存储,信号采集过程通过计算机上的LabVIEW软件控制.
3.2实验步骤
1)验证实验
为证实汇编指令和旁路信号的相关性,选取STC89C52RC40I芯片进行一项验证性实验.通过对芯片在连续执行3条汇编指令期间的信号进行分析.实验分两次按照1、2、3和2、1、3先后顺序的情况执行这三条指令.该系列芯片的1个机器周期等于12个时钟周期(振荡周期),当晶振为12MHz的时候,周期即为1μs.图6所示芯片在执行指令时,其时间按指令周期对应分别为两个2周期指令和一个1周期指令,情况1和情况2的三条汇编指令的Pearson相关系数分别达到了0.99894、0.99914和0.99952,充分证明了依靠旁路信号与指令相关性对芯片进行检测识别的可行性.如果执行相同操作时采用不同数据,其差异主要体现在信号部分拐点处,且数量级远小于指令操作级别的差异.与不同操作数据的差异体现方式不同,指令之间的信号差异体现在信号波峰处,而通过合理的参数调整控制决策边界或者给予大量的训练数据集仍然能够将其正确的识别出来.
2)信号的采集
51单片机一共有111条汇编指令,由于篇幅限制,在实验环境中仅选用MOVA,#DATA指令作为识别的模板并进行训练.训练样本在3次不同的时间和环境下通过电压触发信号采集.电压触发信号下降沿至上升沿期间,正样本执行MOV指令.信号采集窗口如图7所示.
3)建立識别信号的模板
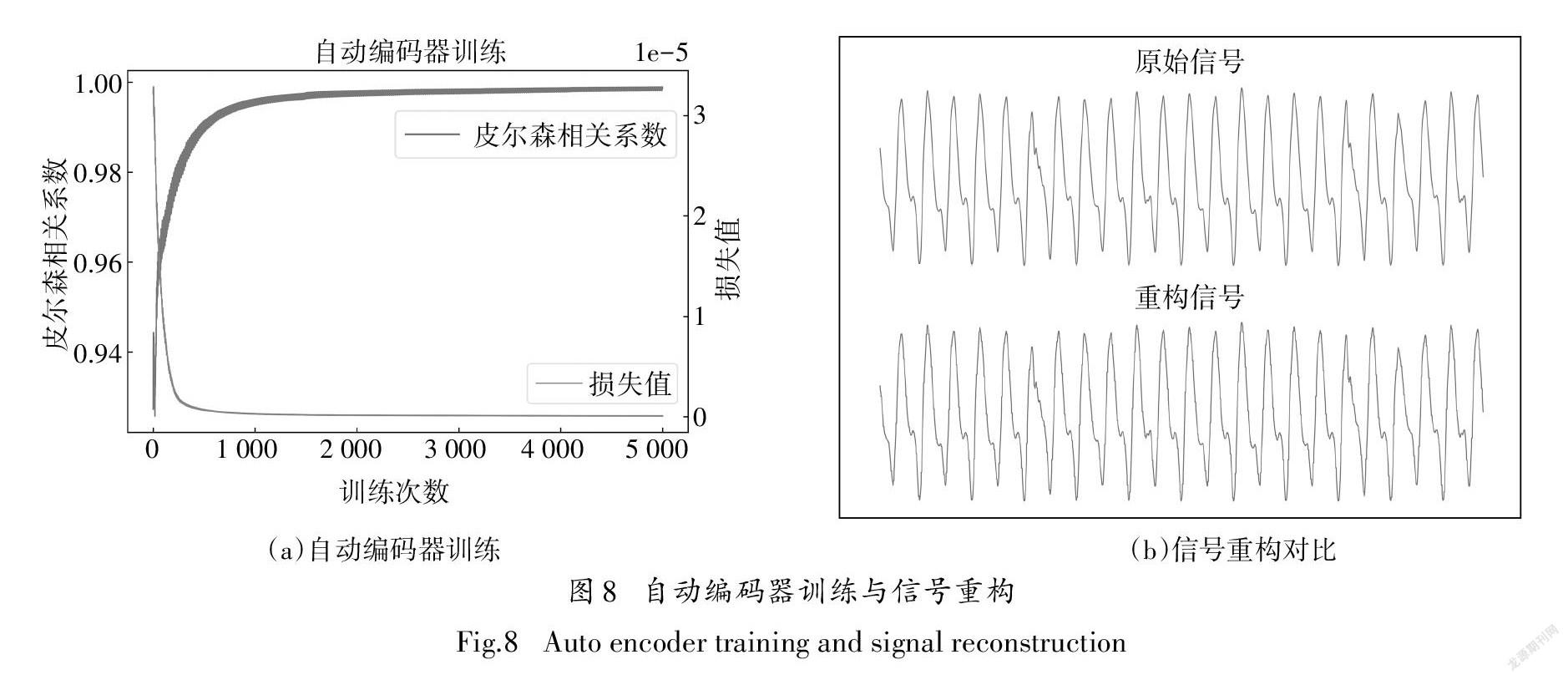
将正样本执行MOVA,#DATA指令时采集到的400条离散信号分批量送入自动编码器中训练.随着训练迭代次数的增加,损失函数逐渐收敛,同时重构信号与原始输入信号的相关系数在接近1处趋于平稳,此时自动编码器训练完成,见图8.
取编码层的输出数据作为自动编码器学习到的特征,融合人工提取的特征为最终提取到的特征向量,把400条正样本的特征向量作为一类支持向量机的正样本训练.
4)待测芯片检测
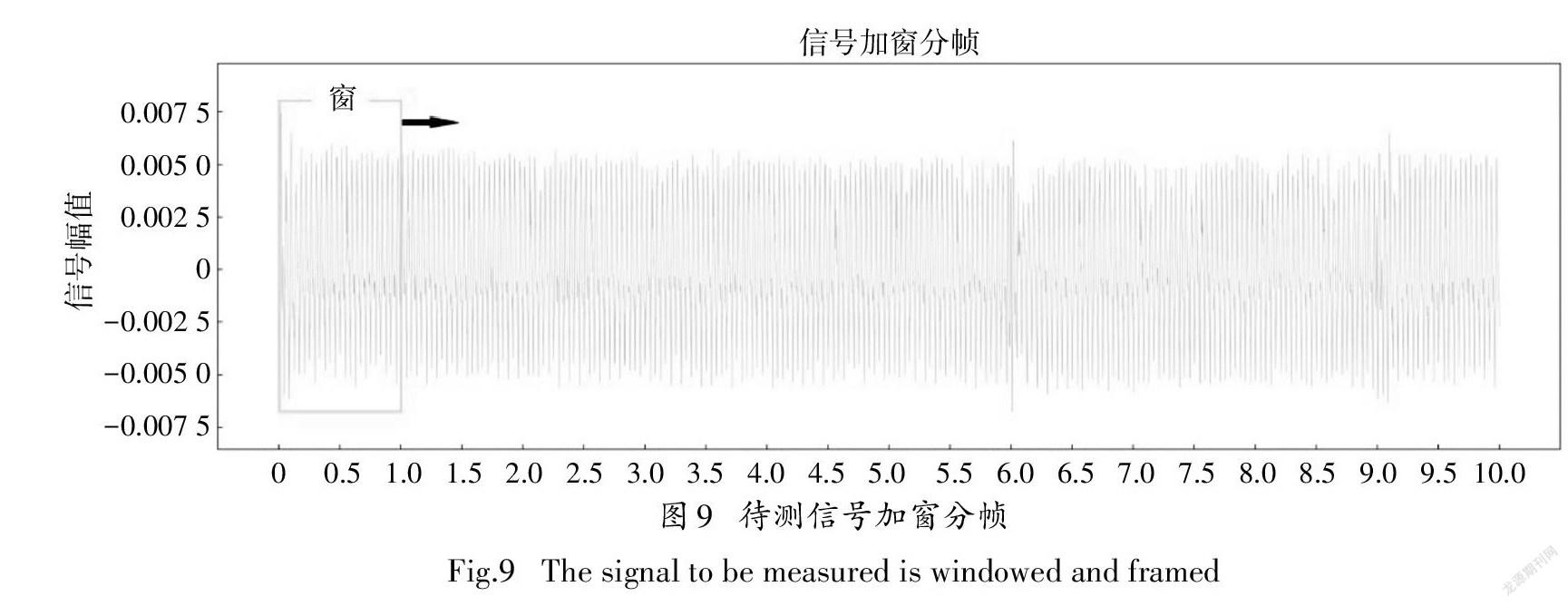
待测芯片的信号采样频率应当与训练样本保持一致,若采样频率不同,可以利用实现相同的采样频率.将采集到的信号加窗分帧,本文采用矩形窗,窗口大小取1μs,窗口移动的步长为1个采样点(1ns),如图9所示,将信号分为数帧的窗口信号.
步长越大能够减少检测时间,步长越小能够提高检测的准确度.
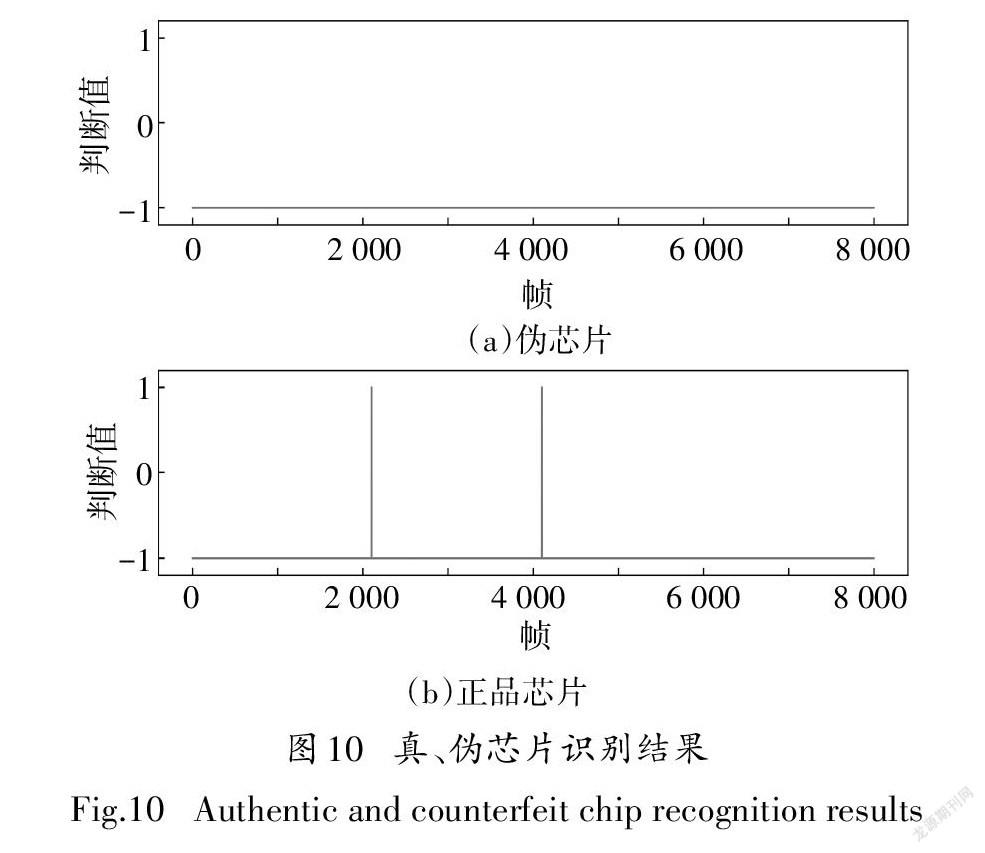
加窗信号按照上述方案进一步提取特征:通过自动编码器的编码层得到的10维特征再加上人工提取的两个特征值组成12维的特征向量.把每一帧的特征向量放入支持向量机与正样本信号进行扫描式的匹配,匹配到正样本模板信号输出1,未匹配到则输出-1.根据匹配到模板指令的频率来判定芯片真伪.图10为两种识别结果示例.
3.3结果与分析
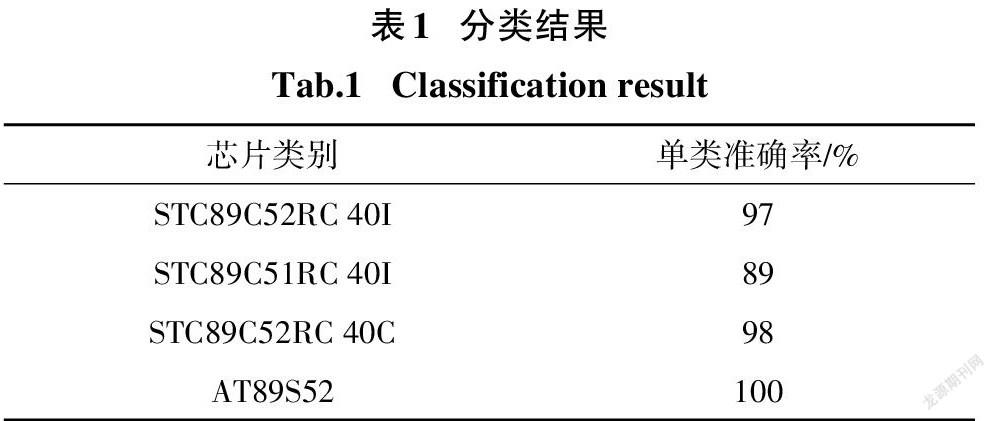
核函数中参数σ和υ对支持向量机的决策边界影响较大.σ越小,支持向量越少,σ越大,支持向量越多.υ决定了训练误差分数的上界和支持向量分数的下界.考虑到高精准的把负样本识别出来,而又不把正样本排除在决策边界外,经过多次对不同的参数进行试验,σ和υ分别取0.1和0.42,实验结果数据如表1所示.
从实验结果看出:对于整体布线差异的芯片(STC89C52RC40C和AT89S52),信号区分度较高,其中不同厂家间的芯片(AT89S52)识别率能达到100%,对于局部差异的芯片(STC89C51RC40I),由于其信号差异非常的小,识别正确率与其它芯片相比较低.
该芯片检测框架可扩展性强,能根据特定应用场景结合不同特征提取和分类算法.例如在信号差异很小的同厂家生产芯片情况中,不同类型芯片的信号差异会被不同指令产生的信号差异所掩盖.此类情况下,可以根据实际需要提取出表征性强的特征来实现较高准确率.这一点在多数同类文献中都未体现出来,他们所采用的实验对象大多信号差异非常明显(由不同厂家生产).其次,该检测方法能够将芯片工作时辐射的旁路信号“语义分割”为指令信号,完成搜索匹配式的识别判断,无需事先为每一块待测芯片准备测试环境,只需要为该款芯片建立指令信号模板,就能实现芯片的无损在线检测,适用性强.
4结论
实验证明,本文提出的伪芯片检测框架能够有效检测以假充真、以次充好等情况的芯片,并且能够扩展适用于所有与正品芯片在工艺技术、布局布线等方面存在差异的伪芯片类型.本文采用卷积自动编码器能够自动高效的提取出电磁信号中的隐含特征,融合人工提取出的特征向量在一类支持向量机的判别下能够实现对伪芯片的在线检测.在指令模板建立好的情况下,通常数分钟就能完成一块待测芯片的检测.该伪芯片检测方法成本低、易于实施且可扩展性和适用性强,为伪芯片的检测提供了一个新颖的思路.未来工作中,应探寻电磁探针最佳的信号采集点,并提出更具代表性的人工特征提取方法以应对类似硬件木马等细微差异的伪芯片.
参考文献
[1]崔晓通.集成电路生产外包过程中的安全问题研究[D].重庆:重庆大学,2018.
[2]李雄伟,马佳巍,张阳,等.伪芯片防护研究进展及其挑战[J].火力与指挥控制,2020,45(6):177-183.
[3] TEHRANIPOOR M,SALMANI H,ZHANG X. Integrated Circuit Authentication:Hardware Trojans and Counterfeit Detection[M]. Berlin: Springer Publishing Company, Incorporated, 2013: 138-146.
[4] JIN S,KIM S,KIM H,et al.Recent advances in deep learning- based side-channel analysis[J].ETRI Journal,2020,42(2):292-304.
[5]张阳,全厚德,李雄伟,等.基于自差分分析的硬件木马检测研究[J].华中科技大学学报(自然科学版),2019,47(2):98-102.
[6]李浪,李仁发,邹祎,等.密码算法芯片抗功耗攻击能力量化模型研究[J].湖南大学学报(自然科学版),2010,37(3):73-76.
[7] AGRAWAL D,ARCHAMBEAULT B,RAO J R,et al.The EM side—channel(s)[M]//Cryptographic Hardware and Embedded Systems - CHES 2002.Berlin,Heidelberg:Springer Berlin Hei⁃d e l b e r g ,2 0 0 3 :2 9 - 4 5 .
[8] HUANG H,BOYER A,BEN DHIA S.Electronic counterfeit de⁃tection based on the measurement of electromagnetic fingerprint [J].Microelectronics Reliability,2015,55(9/10):2050-2054.
[9] STERN A,BOTERO U,RAHMAN F,et al.EMFORCED:EM- based fingerprinting framework for remarked and cloned counter⁃feit IC detection using machine learning classification[J].IEEE Transactions on Very Large Scale Integration(VLSI)Systems, 2 0 2 0 ,2 8( 2 ):3 6 3 - 3 7 5 .
[10]倪明涛,赵波,吴福生,等.CREBAD:基于芯片辐射的物联网设备异常检测方案[J].计算机研究与发展,2018,55(7):1451-1461.
[11] PARK J,XU X L,JIN Y E,et al. Power-based side-channel instruction-level disassembler[C]//2018 55th ACM/ESDA/IEEE Design Automation Conference (DAC). San Francisco,CA, U S A :I E E E ,2 0 1 8 :1 - 6 .
[12] YILMAZ B B,PRVULOVIC M,ZAJIĆ A. Electromagnetic side channel information leakage created by execution of series of in⁃structions in a computer processor[J].IEEE Transactions on In⁃formation Forensics and Security,2020,15:776-789.
[13] DENG J,ZHANG Z X,EYBEN F,et al.Autoencoder-based un⁃supervised domain adaptation for speech emotion recognition[J]. IEEE Signal Processing Letters,2014,21(9):1068-1072.
[14]練秋生,韩冬梅.基于卷积稀疏编码和K-SVD联合字典的稀疏表示[J].系统工程与电子技术,2012,34(7):1493-1498.
[15] BENADJILA R,PROUFF E,STRULLU R,et al. Deep learning for side-channel analysis and introduction to ASCAD database[J]. Journal of Cryptographic Engineering,2020,10(2):163-188.
[16]王振武,何关瑶.核函数选择方法研究[J].湖南大学学报(自然科学版),2018,45(10):155-160.
猜你喜欢
少儿科学周刊·少年版(2021年24期)2021-03-24
中国电子报(2020年88期)2020-12-29
中国电子报(2020年91期)2020-01-13
中国电子报(2019年41期)2019-10-24
科学与财富(2018年18期)2018-08-09
中国新通信(2016年17期)2016-11-17
上海企业(2015年12期)2015-12-16
股市动态分析(2015年24期)2015-09-10
