
基于LDA的隐式标签协同过滤推荐算法
2022-04-07 03:22:38文勇军何环晶唐立军
计算机与现代化 2022年3期
文勇军,何环晶,唐立军
(1.长沙理工大学物理与电子科学学院,湖南 长沙 410114;2.长沙理工大学近地空间电磁环境监测与建模湖南省普通高校重点实验室,湖南 长沙 410114)
0 引 言
随着互联网的发展,各社交媒体网站等信息平台都出现了信息过载的问题[1],为有效提高过载信息的利用率,目前已有十几种主流的推荐算法[2],如基于内容的推荐算法[3]、基于位置的推荐算法[4]、协同过滤推荐算法[5-6]、聚类推荐算法[7]和基于社交网络的推荐算法[8]等。协同过滤推荐算法是最流行的推荐算法之一,该算法成为了广大研究者的研究热点,针对协同过滤推荐算法存在数据稀疏性、推荐实时性、扩展性、计算量大和冷启动[9-10]等问题,许多学者开展了大量的研究工作[11-13],对协同过滤推荐算法进行了有效改进,但大部分研究与其他算法融合不够。王全民等人[14]提出了一种交替奇异值分解算法(ASVD),即结合协同过滤和隐语义分析的混合推荐算法。唐泽坤等人[15]融合聚类算法和协同过滤推荐算法,取得了一定效果。高娜等人[16-19]将标签因子和协同过滤推荐算法结合研究缓解了数据稀疏问题,但这种固定标签的形式主要依靠人工标记,扩展性不强,主观因素多。
本文探索一种基于LDA的隐式标签协同过滤推荐算法(User Based LDA Tag Collaborative Filtering, UBLTCF),在固定标签协同过滤算法的基础上,结合隐式标签与用户评分数据,研究隐式标签的生成及隐式标签与协同过滤推荐算法的融合方法,为解决评分矩阵稀疏性带来的用户邻域计算不准确的问题提供一种有效的算法。
1 UBLTCF推荐算法原理
1.1 固定标签的协同过滤推荐算法
基于用户的协同过滤推荐算法利用用户评分数据计算用户之间的相似性,固定标签的协同过滤推荐算法通过结合用户对项目评分行为和项目的标签特征来计算用户之间的相似性,取相似度最高的前N个用户作为邻域,根据邻域内用户的喜好程度相似性特征来推断目标用户对未访问过项目的喜好程度,以此完成对目标用户的项目推荐。设目标用户为u,未访问的项目为i,邻居数为N,推荐数为K,固定标签的协同过滤推荐算法包括以下4个部分:
1)用户-标签和项目-标签矩阵。
假设有S个标签,M个用户,W个项目,结合用户对项目评过分的历史行为和项目被标签的标记次数获取用户标记标签的行为次数矩阵UTM×S和项目被标签标记的行为次数矩阵ITW×S。用户-标签矩阵UTM×S如式(1)所示,项目-标签ITW×S如式(2)所示。
(1)
(2)
2)用户对项目的喜好向量。
通过式(1)中用户标记标签的次数获取用户基于标签的兴趣特征,通过式(2)中项目被标签标记的次数获取项目基于标签的特征表示,计算公式分别如式(3)、式(4):
(3)
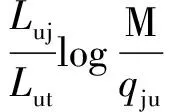
(4)
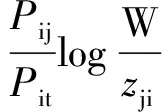
(5)
3)产生推荐。
选取适合的相似度测量因子可以使邻域判断更为准确,从而提升推荐质量。通过皮尔森相关系数对用户-标签矩阵UTM×S进行计算,构建用户相似度矩阵sim(u,v),取与用户u相似度最高的前N个用户作为目标用户u的邻域。假设目标用户u对项目i未评分,通过式(5)中u邻域内的用户对项目i的偏好贡献得到目标用户对所有未评分项的预测偏好值,取前Top-K个进行推荐。
1.2 固定标签的协同过滤推荐算法改进
从以上推荐过程可以看出,固定标签的协同过滤推荐算法将人工标签因子引入协同过滤推荐算法的方法中,能有效缓解数据稀疏性,但是标签受人工主观因素影响大,且未考虑用户评分隐藏的用户喜好。为进一步解决标签质量和标签语义歧义问题,本文在固定标签的协同过滤推荐算法基础上,提出一种隐式标签协同过滤推荐算法。
1.2.1 隐式标签
LDA主题模型也称隐迪利克雷分配模型[20],是一种文档主题生成的3层贝叶斯概率模型,属于无监督学习算法,主要应用于文本挖掘领域中文本主题识别、文本分类和文本相似度计算等方面,能把文档集中每篇文档的主题以概率分布的形式表示出来。本文通过对项目内容组成的文本集进行分词、去停用词等预处理,对预处理后的文本集进行主题模型训练,根据算法性能优化的要求选择主题数量,主题以一定的概率表示文本的特征,可作为文档的隐式标签因子,通过模型训练可得到项目-标签特征权重矩阵。隐式标签与固定标签比起来,能有效地扩展标签的多样化,解决人为标注标签导致的标签语义歧义、标签种类单一等问题,通过挖掘项目语义特征自动生成的标签集,更深层次地挖掘了项目之间的内在联系。
1.2.2 UBLTCF算法构建
本文将隐式标签因子引入协同过滤推荐算法中,利用LDA主题模型构建项目-标签概率矩阵,深度挖掘项目的特征联系,针对固定标签协同过滤推荐算法中未考虑用户评分值在一定程度上能反映用户喜好的问题,本文将用户对项目的评分与项目-标签矩阵结合构建用户对标签的喜好矩阵,通过用户对标签的喜好进行相似度的计算得到用户的邻域,计算邻居用户评分值的贡献,得到每个用户对未评分项目的预测评分值,取前K个项目进行推荐,该算法能有效缓解评分数据稀疏性问题,提高推荐准确度。
推荐算法的具体描述如下:
Step1获取项目文本,对项目组成的文本集进行分词和去停用词等预处理。
Step2在预处理后的文档集上利用LDA主题模型对W个项目文本生成S个主题,由此得到“文档-主题”概率分布θW×S,即项目-标签分布矩阵ITW×S。
Step3结合用户User对物品Item的评分和项目-标签分布矩阵ITW×S得到用户对标签的偏好矩阵UTM×S。
Step4利用皮尔森相似度在标签的偏好矩阵UTM×S上计算目标用户u和其他所有用户的相似度大小sim(u,v)。
Step5取相似度最高的前N个用户作为u的邻域,根据邻域用户的评分计算目标用户u未评分项目的预测评分值,根据预测评分值取前Top-K个项目进行推荐。
算法原理图如图1所示。
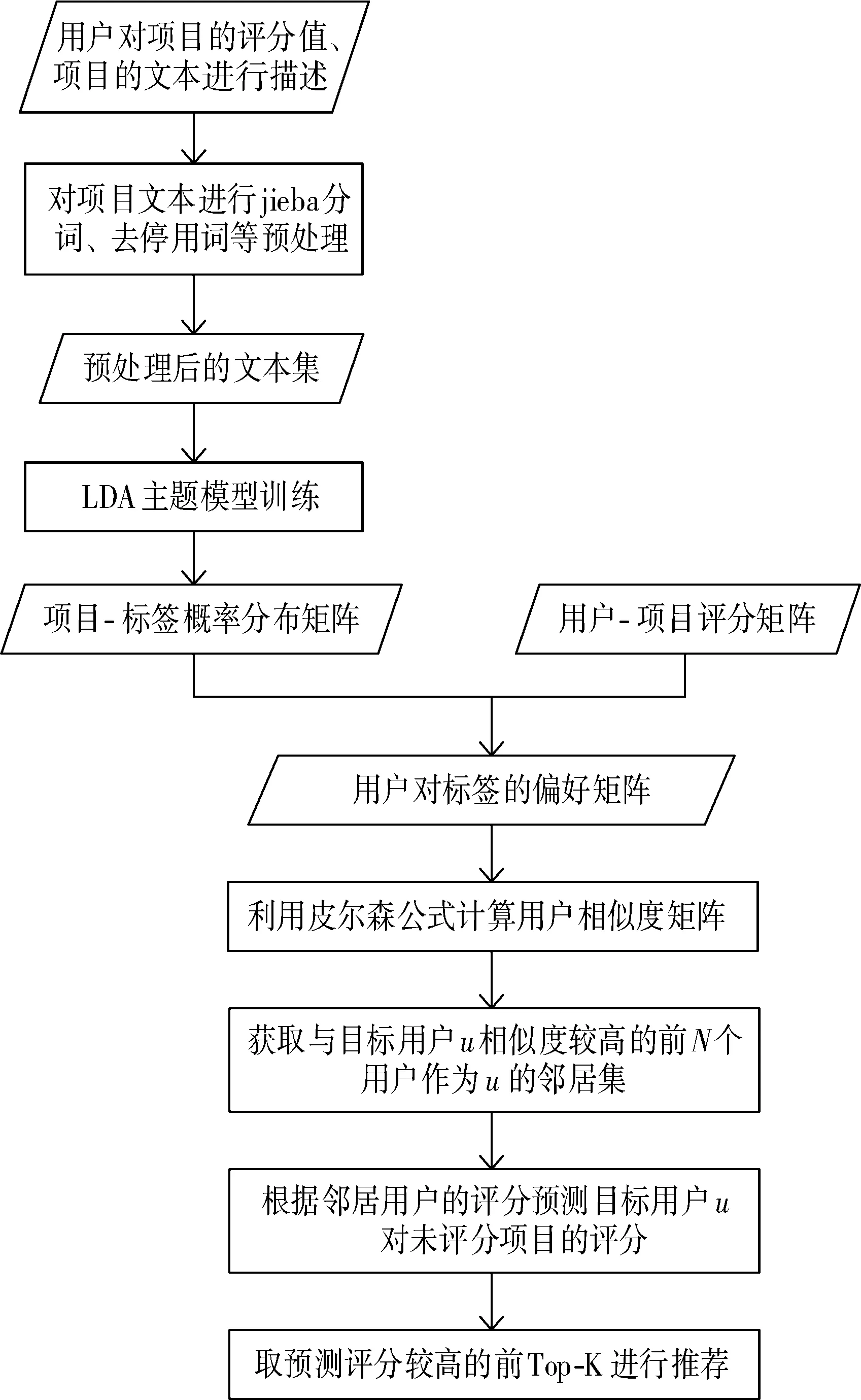
图1 算法原理图
2 UBLTCF推荐算法
2.1 隐式标签的生成
人工参与的数据集标签,容易受外部因素影响,不同的个体对标签有不同的理解,主观因素影响较大,本文尝试摒弃数据集已有的固定标签,把每个项目的文本看成一篇文档,对文档集进行分词和去停用词等预处理后再放入LDA模型进行训练,生成的主题作为项目的标签因子,利用LDA模型[21]自动挖掘项目的隐式标签,找到项目对隐式标签的权重分布,其中主题数可通过训练不断拟合达到最优。
1)数据预处理。
输入W个项目的文本,用I={I1,I2,…,Ii,…,IW}表示,其中i=1,2,…,W,Ii对应一篇文档内容,对W篇文档采用结巴分词和去停用词等方法进行数据预处理。
2)LDA主题模型训练。
将预处理后的文档集放入LDA主题模型进行训练。LDA主题模型如图2所示。
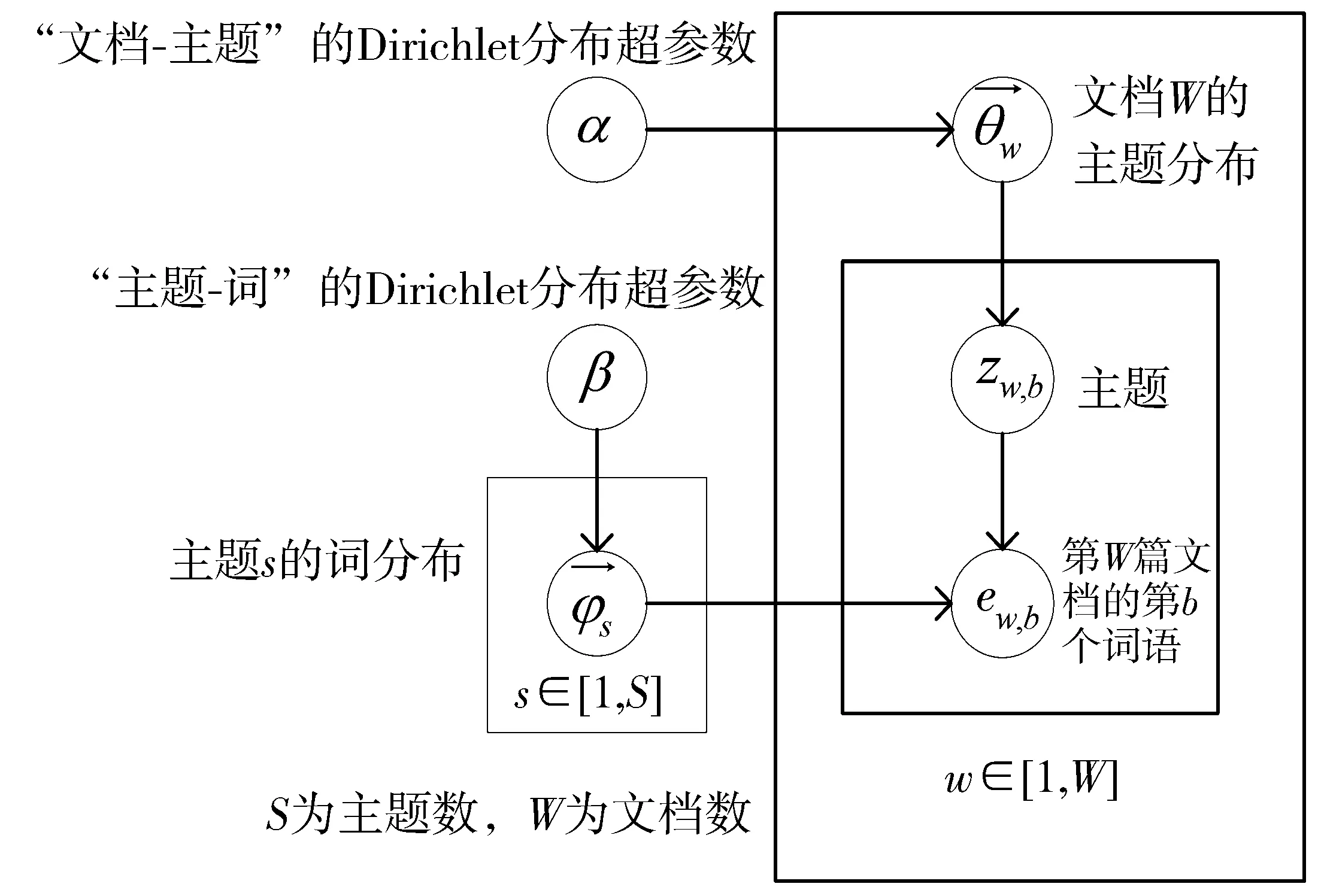
图2 LDA主题模型
图2中,θw和φs分别代表文档w下的主题分布和主题s下的词分布,一篇文档的生成可看作是以一定概率选择主题,再以一定概率从主题中选择词的过程,主题的提取是文档生成的逆过程[22],即计算文档-主题概率分布矩阵θ,其近似求解可用变分推断、期望传播、极大似然法和吉布斯采样[23]等方法,本文通过吉布斯(Gibbs)采样逆推θ,具体步骤如下:
①选择合适的主题数K、超参α、β,对所有文档的每一个词,随机赋予一个主题编号。
②遍历所有文档中的词,对于每一个词,利用Gibbs采样更新它的主题编号。
③重复步骤2的Gibbs采样,直到Gibbs采样收敛。
④统计文档中各个词的主题,按式(6)计算文档-主题分布θ:
(6)
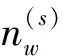
3)输出文档-主题概率分布θW×S。
主题作为项目的隐式标签,θW×S作为项目-标签的分布矩阵。
2.2 UBLTCF推荐算法设计
基于隐式标签的协同过滤推荐算法首先构建用户-项目-标签三维关系,如图3所示,User表示用户,Item表示项目,Rfi表示用户Userf对物品Itemi的评分,评分越高表明用户Userf对物品Itemi越喜欢,Tag是将项目的文本描述通过LDA主题模型生成的主题,其数量可以根据需要选取,Pij是利用LDA主题模型训练得到的项目-标签概率分布,Pij越大代表项目Itemi具有Tagj这个特征属性的权重越大;再通过项目-标签分布矩阵与评分数据相结合得到用户对标签的偏好程度,基于用户对标签的偏好矩阵计算用户间的相似性;最后根据用户相似性进行项目推荐。
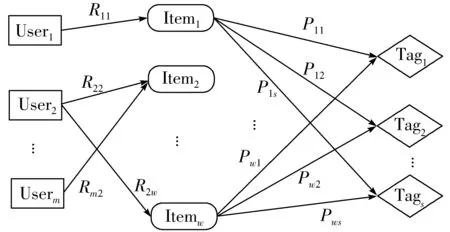
图3 用户-项目-标签三维关系
2.2.1 项目-标签矩阵
通过LDA主题模型生成文档-主题分布θW×S,文档是项目的文本属性,每篇文档代表一个项目,共有W个项目。主题能充分体现项目的特征表示,可看作项目对应的标签,θW×S可作为项目-标签矩阵ITW×S使用。标签集T=(T1,T2,…,TS),其中S为生成的主题个数,即标签个数,可通过不断训练拟合到最优值。项目-标签矩阵如式(7):
(7)
其中,Pij=θij,代表第i篇文档属于主题j的概率,即项目Ii对应标签Tj的概率,对于同一个项目Ii,Pij越大表明项目Ii拥有特征Tj的权重越大,特征Tj越能代表这个项目。
2.2.2 用户-标签偏好矩阵
评分数据能反映用户对项目的偏好程度,而项目-标签矩阵隐含了项目之间的关联,两者结合可以得到用户对不同标签的偏好向量。定义用户集合U=(u1,u2,…uf,…,uM),其中uf代表用户f,f=1,2,…,M,用户对项目的评分可用矩阵UIM×W表示:
(8)
通过式(9)计算出用户对标签的偏好矩阵UTM×S,用户-标签矩阵计算公式如式(10):
UTM×S=UIM×W×ITW×S
(9)
(10)
其中,Lfj的计算公式如式(11):
(11)
其中,Rfi表示用户uf对项目Ii的评分,Pij表示项目Ii对应标签Tj的特征权重,通过两者的结合计算用户uf对标签Tj的特征偏好,j=1,2,…,S。Lfj表示用户uf对标签Tj的偏好程度,Lfj越大表示用户uf越喜爱标签Tj。由于用户评分数据非常稀疏,通过结合项目-标签的特征权重矩阵得到的用户-标签偏好矩阵既达到降维的效果,又能缓解数据稀疏问题。
2.2.3 用户相似度计算
用户相似度的计算决定了目标用户邻域的选取,邻域的选取对推荐算法的准确性而言尤其重要。本文采用皮尔森相似度,在用户对标签的偏好矩阵UTM×S上计算求得用户间的相似度sim(u,v),相似度计算公式如式(12)所示。
(12)
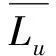
2.2.4 预测评分值计算
在用户相似度矩阵sim(u,v)的基础上得到某个用户相似度较高的Top-N个用户作为其邻域,通过邻域用户对目标用户未评分物品的评分值来预测目标用户可能评分值。用户u对未评分项目i的预测评分用Pred(u,i)表示,计算公式如式(13):
(13)
其中,Rv,i为用户v对项目i的评分,用户v为邻域N中的一个用户,sim(u,v)为用户u,v之间的皮尔森相似度。通过邻域用户对项目的评分贡献得到目标用户u对项目i的预测评分值,预测评分值越高表明用户喜欢该项目的可能性越高,将预测值较高的前Top-K个项目推荐给目标用户。
3 验证与分析
本文实验采用美国GroupLens站点提供的MovieLens 100 K数据集,该数据集包含943个用户,1682部电影,100000个评分数据和19个标签属性,每个用户至少评分了20部电影,评分值为1~5之间的整数[24],该数据集没有电影内容简介。本文通过网络爬虫抓取每部电影的中文内容简介作为项目的文档。由于用户对项目有过评分不能代表用户喜欢该项目,本文选取用户评分不小于3的数据作为测试集。
3.1 算法评判指标
不同需求下推荐算法的评判指标各不相同,根据推荐项目和用户实际偏好的项目进行比较来评判算法性能,可用准确率、召回率和综合评价指标F1值。准确率(Precision)也为查准率,表示推荐项目列表中命中测试数据集中项目的比率[25];召回率(Recall)为查全率,表示用户真正喜欢的项目数中推荐正确数量的占比;由于准确率和召回率相互制约,故引进F1-measure值进行调和[26],3个评判指标越高越好。假设A为推荐正确的样本数,B为训练集中得出的推荐样本数,C为测试集中的样本数。3个指标计算公式如下:
(14)
(15)
(16)
当a=1时为最常见的综合测评指标F1-measure,即:
(17)
3.2 对比算法
1)UBTCF算法。文献[19]提出的基于固定标签的协同过滤推荐算法。
2)UBCF算法。基于用户的协同过滤推荐算法。
3)IBTFCF算法。基于TF-IDF的协同过滤推荐算法,取每篇文本对应TF-IDF值最高的前10个词作为特征词,构建特征词集合,得到所有文本对应词集合的TF-IDF矩阵,计算项目间的余弦相似度,生成基于内容的协同过滤推荐。
4)UBTFTCF算法。基于UBLTCF算法,将TF-IDF算法代替LDA主题模型构建项目-标签矩阵,与用户评分数据结合产生推荐。
3.3 实验与结果分析
为了验证和比较本文提出的UBLTCF算法的有效性,设计以下3组实验进行对比。
实验1 为测试利用LDA模型生成的主题数量对UBLTCF算法的影响,实验中固定邻居数N为50,推荐数K为20,主题数S从5到100,间隔为5,比较不同主题数下UBLTCF算法中Precision、Recall及F1值的变化情况,实验结果如图4所示。
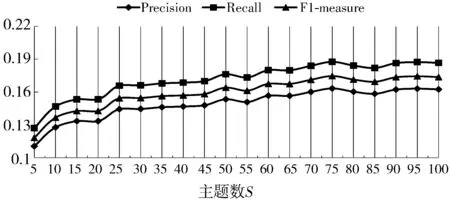
图4 不同主题S值下的Precision、Recall、F1值
由图4可以看出,推荐效果随着主题数的增加整体呈缓慢上升趋势,当主题数为50时,Precision为0.153446,Recall为0.176281,F1值为0.164073,当主题数大于50时,评价指标曲线趋向于平滑稳定,由此可以看出当主题数量S大于这个阈值时对推荐效果的影响不大,因为主题数量增大了以后,部分主题的概率分布趋近于0,对算法性能指标提升没有贡献。在具体的应用场景,应根据算法性能优化的要求选择合适的主题数量。
实验2 测试邻居数N的选取对UBLTCF算法性能的影响,该组实验用于寻找UBLTCF算法邻居数N的最佳值,固定推荐数K为20,主题数S为50,邻居数N从1到60选取,间隔为2,实验结果如图5所示。
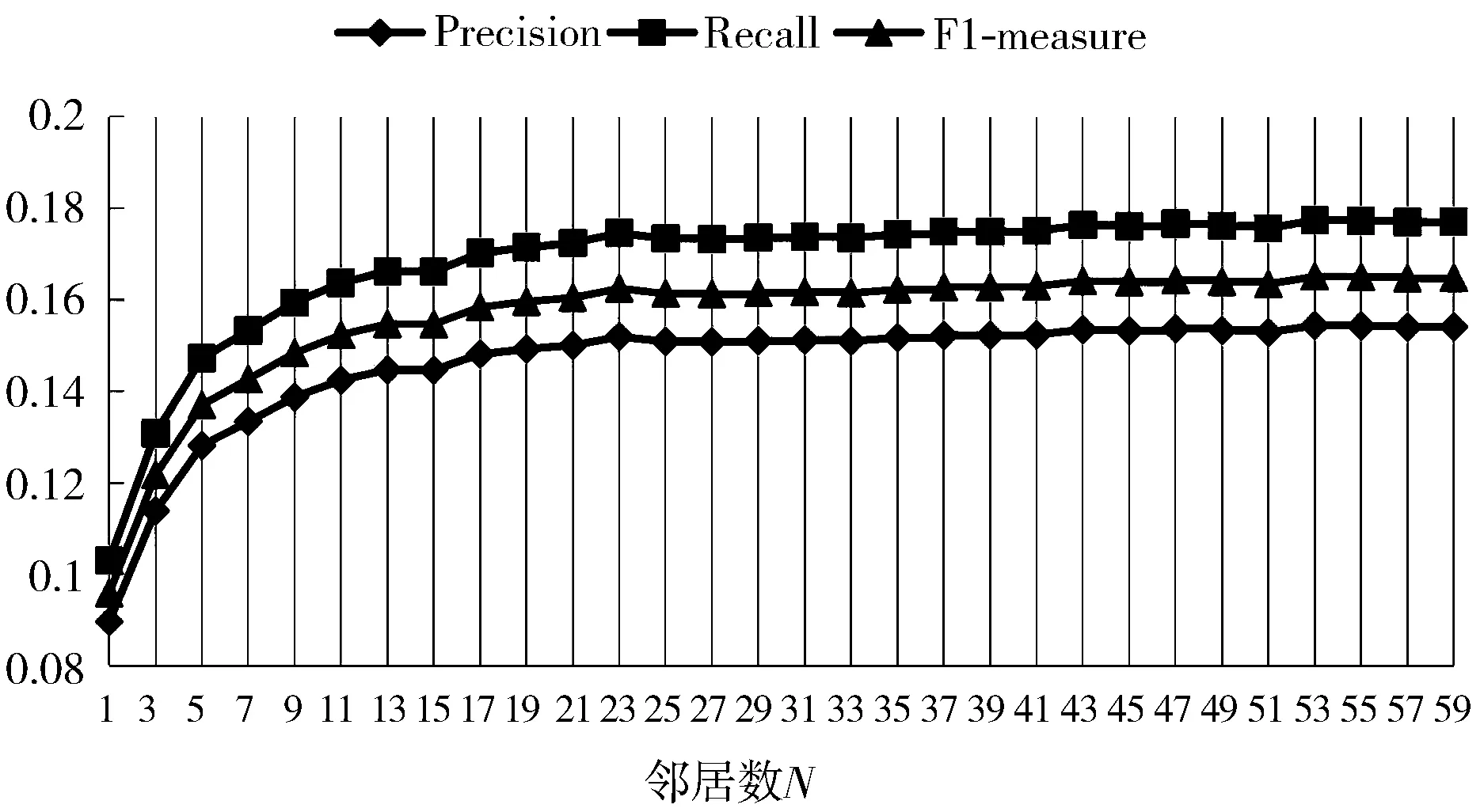
图5 不同N值下UBLTCF的变化情况
由图5可见,当邻居数N取得19时Precision为0.149258,Recall为0.171469,F1值为0.159594,算法性能趋向于稳定,随着邻居数的增加,算法的Precision、Recall和F值整体呈缓慢上升趋势,但是变化幅度不大,由此可以看出当邻居数N大于这个阈值时对推荐效果的影响不大,因为邻居数增大了以后,增加部分的邻居与目标用户相似度很低,导致对算法性能指标提升没有贡献。
实验3 测试推荐数K对算法的影响,比较不同算法的性能指标差异。固定邻居数N取19,UBLTCF算法中主题数取50,比较本文提出的UBLTCF算法、UBTCF[19]、基于用户的协同过滤(UBCF)推荐算法、基于TF-IDF的协同过滤(IBTFCF)推荐算法和基于TF-IDF的用户协同过滤(UBTFTCF)推荐算法,在不同的推荐数目K时的性能指标变化,推荐数由4到100依次递增,间隔为2,实验结果如图6~图8所示。

图6 不同K值下的Precision值
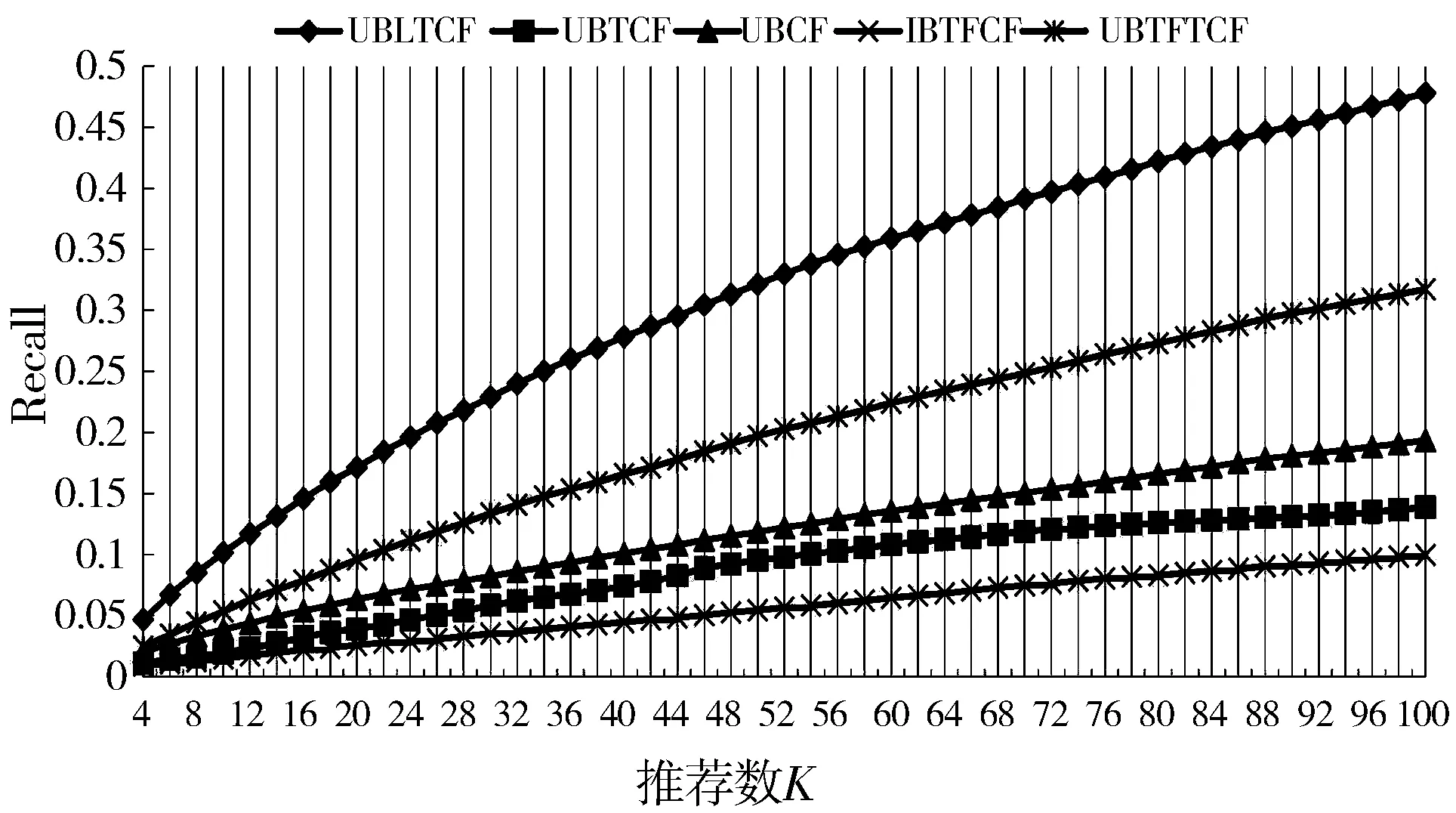
图7 不同K值下的Recall值
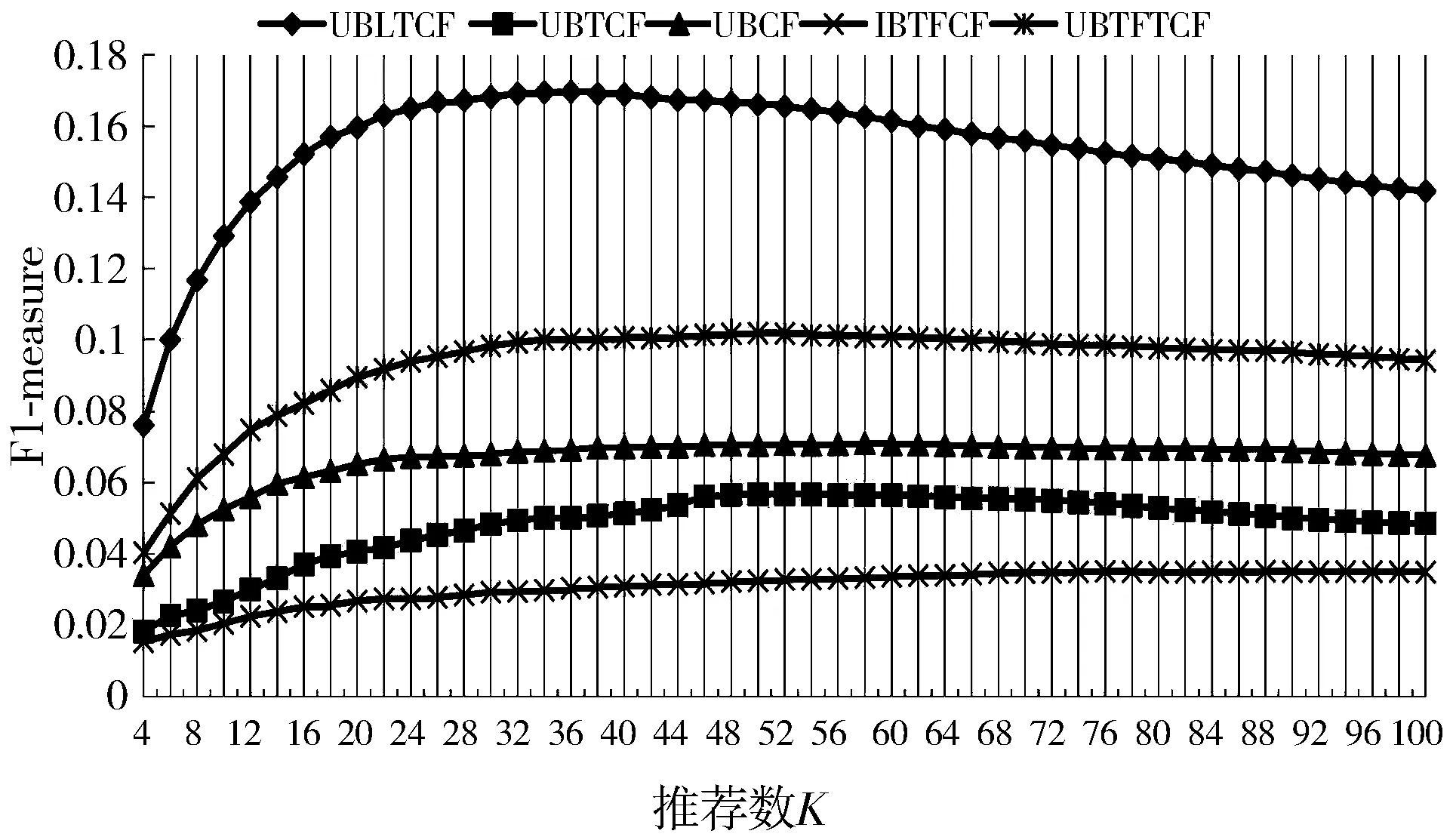
图8 不同K值下的F1-measure值
由图6~图8可以看出,UBLTCF算法的准确率,召回率和F1值始终高于UBTCF算法[19]、UBCF算法、IBTFCF算法和UBTFTCF算法,算法性能指标得到明显改善。当推荐数K达到36时,UBLTCF算法的Precision为0.12584,Recall为0.260218,F1值为0.169642,综合评价指标F值达到峰值,当K值继续增加时,推荐效果随着推荐数量的增加而降低。在具体的应用场景,可根据需要在这个阈值附近选择推荐数。
4 结束语
本文研究了固定标签的协同过滤算法改进方法,提出了一种深度挖掘项目内部特征联系的UBLTCF改进算法,该算法通过LDA主题模型挖掘项目之间的内在关联,生成数量可控且具有代表性的标签因子,将项目生成的隐式标签与用户评分数据相互融合,既弥补了传统协同过滤推荐算法中只利用评分数据表达用户偏好的缺陷,也克服了基于标签的协同过滤算法中只利用标签行为次数和标签单一类等问题。本文设计了3个实验,分别选取UBLTCF算法主题数和邻居数最优值,通过改变推荐数与其他算法进行对比,对算法进行了验证,实验结果表明UBLTCF推荐算法的准确率、召回率和F1值较对比算法均有显著提升。
猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
车迷(2018年11期)2018-08-30 03:20:32
自动化学报(2018年7期)2018-08-20 02:59:04
海峡姐妹(2018年3期)2018-05-09 08:21:02
信息安全研究(2016年4期)2016-12-01 06:06:54
周口师范学院学报(2016年5期)2016-10-17 06:36:47
公民与法治(2016年10期)2016-05-17 04:12:58
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机工程(2015年8期)2015-07-03 12:20:27
