
基于改进YOLO v3的肉牛多目标骨架提取方法
2022-04-07 13:56张宏鸣李永恒周利香李书琴王红艳
农业机械学报 2022年3期
张宏鸣 李永恒 周利香 汪 润 李书琴 王红艳
(1.西北农林科技大学信息工程学院, 陕西杨凌 712100; 2.宁夏智慧农业产业技术协同创新中心, 银川 750004;3.西部电子商务股份有限公司, 银川 750004)
0 引言
牛的行为影响着牛的健康和产出[1-4]。通过骨架提取可以获知牛的姿态,为牛的反刍、运动、进食、站立、卧倒等行为识别[5-10]提供信息支持。基于养殖场的监控视频进行的多牛骨架提取,对大型肉牛养殖场的精细化管理与精准化饲喂具有重要意义。
多目标骨架提取[11-12]是多牛姿态信息获取的重要方法。基于深度学习的多目标骨架提取方法[13-14]分为自上而下和自下而上两类[15-16]。自上而下包括:CHEN等[17]在目标检测器后连接基于GlobalNet和RefineNet的级联金字塔网络(Cascaded pyramid network,CPN)模型进行多目标骨架提取;FANG等[18]提出了一种由SSTN(Symmetric spatial transformer network)、NMS(Non-maximum-suppression)和PGPG(Pose-guided proposals generator)组成的RMPE(Regional multi-person pose estimation)框架用于多目标骨架提取;PAPANDREOU等[19]以Faster RCNN作为目标检测器,使用ResNet检测目标的热图和偏移量,最后将二者融合得到关键点位置。
自下而上包括:CAO等[20]提出了PAFs(Part affinity fields)方法学习身体部位和对应个体之间的关联用于多人骨架提取;CHENG等[21]提出了HigherHRNet方法进行人体多目标骨架提取,缓解了传统的自下向上方法对于小尺度人体骨架提取错误率较高问题;PISHCHULIN等[22]提出的DeepCut方法首先提取关键点候选区域,对关键点进行分类,在人体多目标骨架提取任务中表现良好。
人体的多目标骨架提取技术已经相当成熟[23-24],但对于大型动物如肉牛的多目标骨架提取技术报道相对少见。在大型动物的多目标骨架提取方面,宋怀波等[25]基于自下而上的思路,提出了基于PAFs的奶牛骨架提取模型。该模型的置信度在单目标方面为78.90%;双目标方面为67.94%;3个及以上目标方面为48.59%。该模型在多目标方面的骨架提取精度较低,有待进一步改进。
本文提出一种基于YOLO v3[26-28]和SH(Stacked Hourglass)[29]的自上而下肉牛多目标骨架提取算法,解决在一定目标数量范围内随着目标数量的增加模型精度急剧降低的问题。利用真实大型牛场监控视频,提取关键帧构建目标检测数据集和骨架提取数据集;设计16个关键点全面标识肉牛姿态情况;使用改进YOLO v3算法构建目标检测模型并结合骨架提取模型实现肉牛的多目标骨架提取,将为肉牛的精准化养殖提供技术支持。
1 材料和方法
1.1 材料
(1)实验数据
选用某肉牛养殖场棚内和场外两种不同环境下的西门塔尔牛和安格斯牛实际监控视频为实验数据,摄像头位于养殖大棚上,以斜向下角度拍摄,拍摄范围为整个肉牛场地。每段肉牛视频长35 min,格式为mp4,分辨率为1 920像素×1 080像素,帧率为24 f/s。
(2)实验环境
本文使用CentOS 7系统服务器,其硬件配置为Intel Xeon E5-2650 v4 CPU 2.20 GHz处理器和NVIDIA Corporation GP100GL[Tesla P100 PCIe 16GB] (rev a1)显卡,软件配置为Python 3.7.5编程语言、Pytorch 1.2.0深度学习框架和Cuda 10.0加速程序。
1.2 方法
本研究旨在使用深度学习的方法,通过处理肉牛监控视频获得肉牛骨架,加以分析进而对肉牛的站立和卧倒两种行为进行识别。技术路线如图1所示,包括4个环节:①数据集构建。从采集的视频中提取关键帧,对关键帧进行标注和剪裁,构建目标检测、骨架提取和多目标骨架提取数据集。②目标检测模型训练。利用目标检测数据集训练YOLO v3和NC-YOLO v3模型,进行评估对比。③骨架提取模型训练。利用骨架提取数据集正常训练和多尺度训练骨架提取模型,进行评估对比。④多目标骨架提取模型构建。结合目标检测和骨架提取最优模型,实现肉牛的多目标骨架提取。
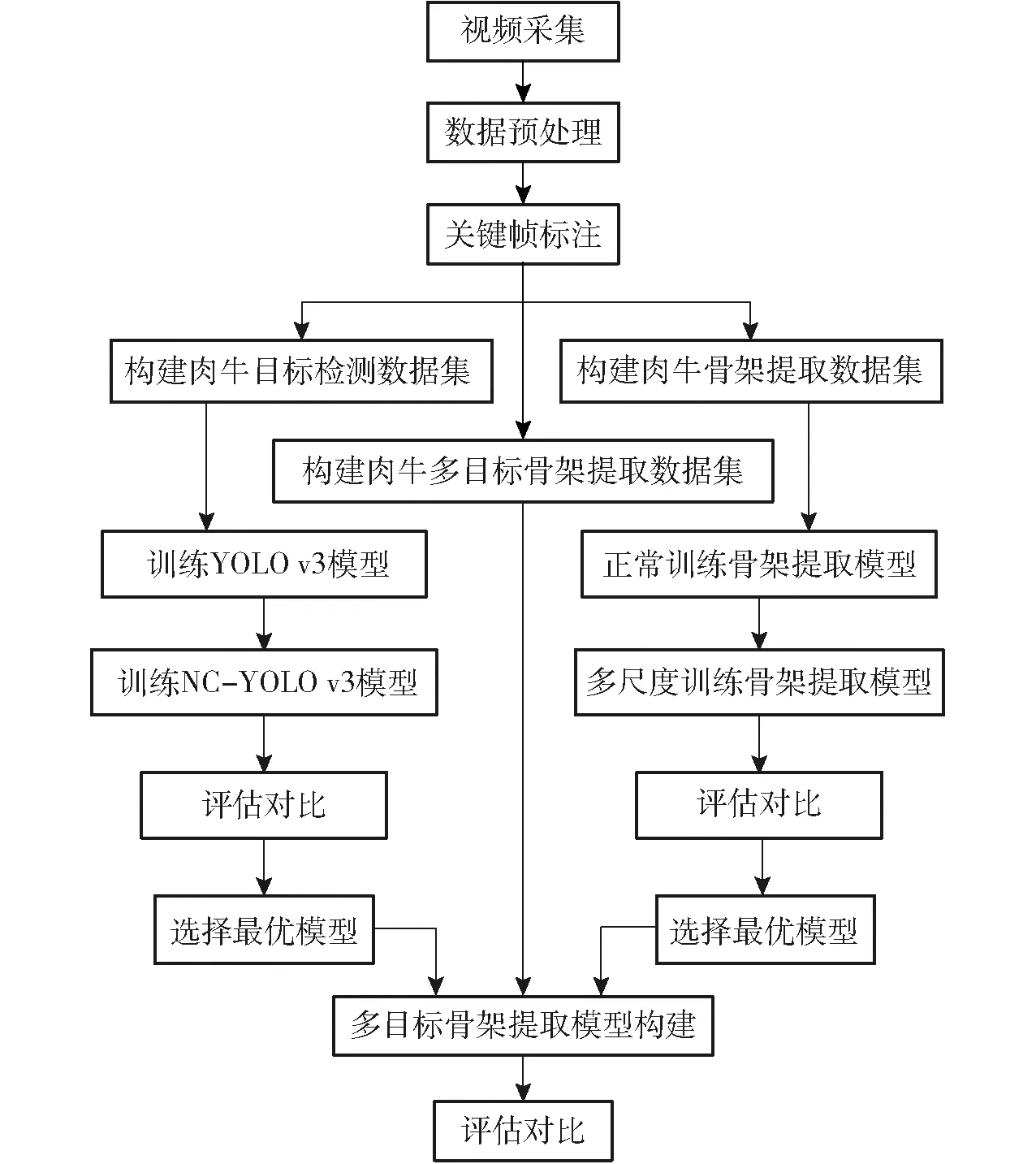
图1 技术路线图Fig.1 Technology road map
1.2.1数据集构建
(1)数据预处理
对视频进行筛选,去掉夜间、无牛等情况的视频。由于视频中相邻帧具有很高的重合度,为避免数据的重复性,提取出视频中较为清晰、目标分明、内容差异较大的帧。最后共形成10 804幅肉牛图像。
(2)肉牛体框标注
对9 786幅图像中所有需要检测的肉牛标注覆盖全身的体框,如图2a所示。

图2 数据标注Fig.2 Data annotations
(3)肉牛体框和关键点标注
对1 018幅图像标注肉牛体框,对标注出体框的每头肉牛进行关键点标注(图2b)。考虑到肉牛的头部、四肢和脊椎位置是肉牛姿态情况的重要组成部分,本研究着重对这3部分进行标注。在肉牛头部于脖子、眉间设置2个关键点,在肢体部分3个关节设置3个关键点,在脊椎的椎首和椎尾设置2个关键点,共计16个关键点表示肉牛姿态情况。具体关键点标注如图3所示。

图3 关键点设置Fig.3 Key point setting1.眉间 2.脖子 3.椎首 4.椎尾 5.前左腿根 6.前左膝 7.前左蹄 8.后左腿根 9.后左膝 10.后左蹄 11.前右腿根 12.前右膝 13.前右蹄 14.后右腿根 15.后右膝 16.后右蹄
(4)标注数据的处理
将仅标注体框的肉牛图像制作为COCO格式的目标检测数据集,训练目标检测模型。将918幅标注体框和关键点的肉牛图像进行裁剪,制作为共有3 414幅单牛图像的骨架提取数据集,训练骨架提取模型。将100幅标注体框和关键点的肉牛图像制作为多目标骨架提取数据集,进行多目标骨架提取模型的评估。为了验证目标数量对检测精度的影响,制作20幅单牛、双牛、4牛、6牛、10牛和15牛及以上数量的多目标骨架提取数据集,多目标骨架提取数据集共220幅。3种数据集名称、图像数量等如表1所示。
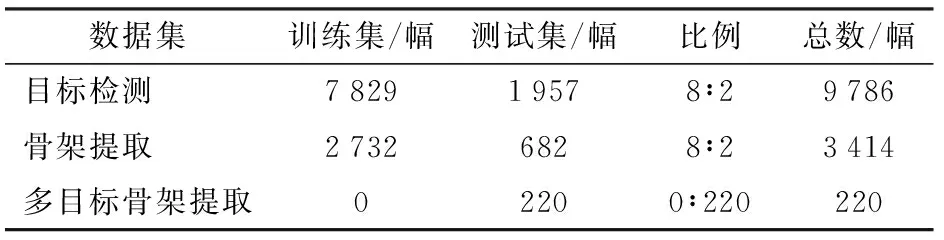
表1 数据集图像数量分布Tab.1 Data set image distribution
1.2.2目标检测模型训练
本研究选用YOLO v3算法作为目标检测器。YOLO v3是一步产生目标位置坐标和类别概率的单阶段目标检测算法,使用Darknet53深度神经网络作为主干部分,提取尺寸为Y×Y的特征图。特征图中每个单元格负责检测落于此位置目标的A个体框坐标和类别概率。体框坐标是5维向量(x,y,w,h,conf),其中,x、y、w、h、conf分别对应体框中心点x坐标、y坐标、体框宽度、体框高度和物体置信度。类别概率是介于0与1之间的n(类别总数)维向量,因此特征图维度为A×Y×Y×(5+n)。Darknet53输出3种不同尺寸的特征图,利用3个YOLO层分别处理,实现图像的多尺度检测,具有优秀的检测能力和准确度。由于养殖场肉牛数量密集互相遮挡,某些肉牛身体部分被遮挡导致露出部分较为分散,且监控画面中某些肉牛因距离摄像头太近而尺寸太大,模型感受野不足将会导致检测未被完全遮挡和太大尺寸肉牛的效果较差。传统的目标检测具有提取目标位置和对目标分类两种功能,而养殖场通常只存在一种养殖动物,因此,本文所用目标检测器可以不必对目标进行分类。为了加强模型的感受野和特征提取能力,同时提高目标检测效率和减小网络参数量,对YOLO v3模型做了如下改进:
(1)在Darknet53后引入RFB模块[30]。RFB通过模拟人类视觉的感受野以扩大模型的感受野,提高对部分遮挡和较大尺寸肉牛的检测精度。RFB由多分支卷积和空洞卷积构成,基于SSD提出的RFBNet的平均精度均值(mAP)达到82.20%。 RFB模块如图4所示。

图4 RFB结构图Fig.4 RFB structure diagram
(2)去除网络分类功能提高目标检测效率,减小网络参数量。
改进后的网络结构如图5所示。训练改进前的YOLO v3和改进后的NC-YOLO v3目标检测模型,学习率均为1×10-5,数据处理批次均为16,均采用多尺度训练。
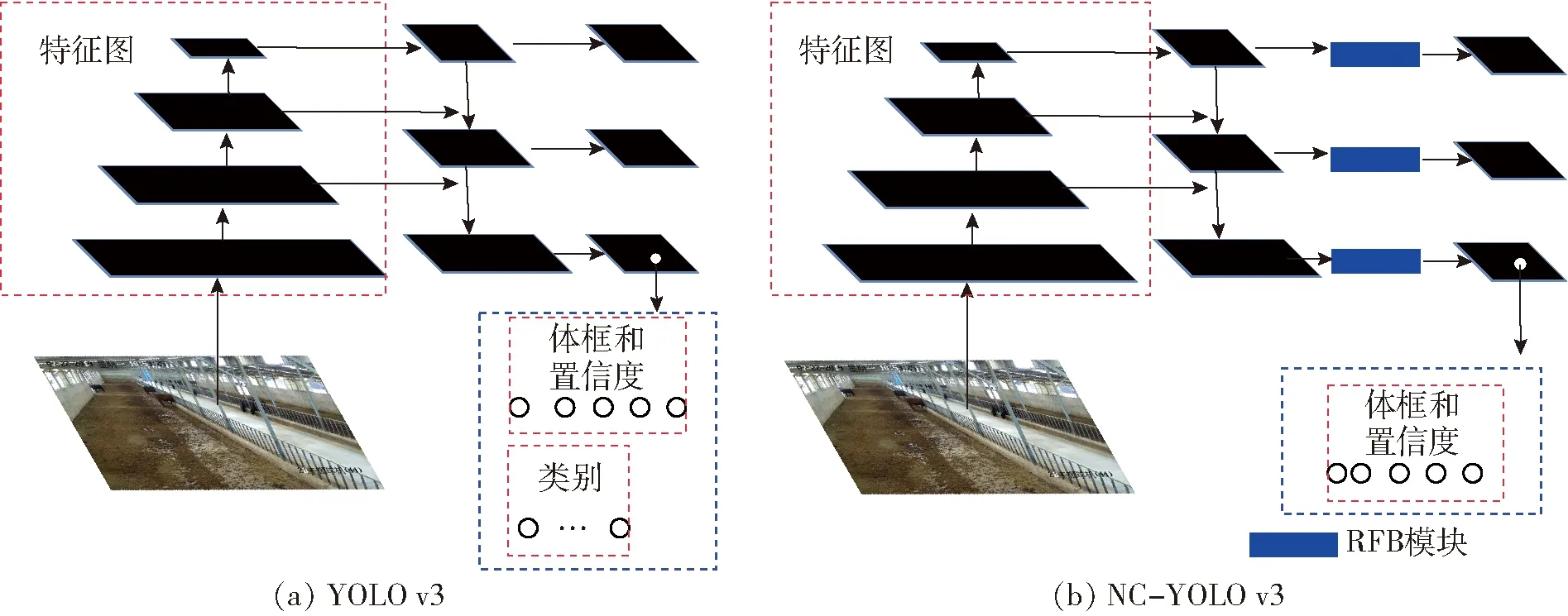
图5 YOLO v3改进前、后结构图Fig.5 Structure diagrams before and after improvement of YOLO v3
目标检测模型参数设置如下:非最大性抑制阈值设为0.5,物体置信度设为0.5,数据处理批次设为1,图像尺寸设为416像素×416像素。通过训练过程中的损失、平均精度变化情况和目标检测多种评价指标,对YOLO v3和NC-YOLO v3模型进行评估对比。
1.2.3骨架提取模型训练
骨架提取是通过检测目标身体关键点,然后将关键点依序连接进而形成骨架信息。本研究选用SH算法作为关键点检测器。SH算法在MPII数据集上的正确关键点比例(Percentage of correct key points,PCK)达到99.00%,基于头部长度的正确关键点比例(Percentage of correct key points based on
head length,PCKh)达到90.90%,在单目标关键点检测方面的准确度较高。其由全卷积网络构成,初级模块为残差网络,具有高效的特征提取能力。SH可由多个Hourglass网络堆叠而成,前一个Hourglass的输出作为后一个的输入,可以对关键点相对位置特征进行提取。由于肉牛的毛色复杂多样、所处环境复杂多变、四肢高度相似、遮挡严重,数量较少的堆叠Hourglass网络对于细节特征感知能力较差,通过单牛图像预测关键点位置较为困难。本文采用8层堆叠的Hourglass(8SH)网络进行关键点检测,构建骨架提取模型。其模型结构如图6所示。

图6 8SH结构图Fig.6 8SH structure diagram
设置滤除置信度滤除最大置信度较小的关键点。模型输出热图中的最大值大于此置信度,则表示该热图所预测的关键点可见,反之,则其不可见,并将其滤除。
正常训练和多尺度训练骨架提取模型。训练所用数据处理批次为4,学习率为1×10-5。正常训练所用图像尺寸为256像素×256像素,多尺度训练每个数据处理批次图像尺寸不同,从192像素×192像素、256像素×256像素、320像素×320像素3种尺寸中随机选择。
骨架提取模型参数设置如下:数据处理批次设为1,关键点滤除置信度设为0.5,图像尺寸设为256像素×256像素。通过训练过程中的损失变化情况和骨架提取评价指标对2种不同训练方式下训练的模型进行评估对比。
1.2.4多目标骨架提取模型构建
本文基于自上而下的思路实现肉牛的多目标骨架提取。训练目标检测和骨架提取模型后,经过选择得到两个最优模型,进而基于最优模型构建多目标骨架提取模型。多目标骨架提取模型主要包含4个步骤,模型流程如图7所示。①通过目标检测模型检测输入图像肉牛体框。②从原图中根据肉牛体框裁剪出单牛图像。③通过骨架提取模型检测单牛图像的关键点。④将单牛图像关键点映射至原图像所在位置,依序连接关键点进而形成多牛骨架。

图7 多目标骨架提取模型流程图Fig.7 Flow chart of multi-target skeleton extraction model
使用多目标骨架提取数据集,对以最优YOLO v3模型构建的多目标骨架提取模型和以最优NC-YOLO v3模型构建的多目标骨架提取模型根据评价指标进行对比。根据单牛、双牛、4牛、6牛、10牛和15牛及以上数量的数据对最优多目标骨架提取模型按照评价指标进行对比。采用非最大性抑制阈值0.5、物体置信度0.5、数据处理批次1和图像尺寸416像素×416像素进行目标检测。采用数据处理批次1、关键点滤除置信度0.5和图像尺寸256像素×256像素进行骨架提取。
2 评价指标
2.1 目标检测评价指标
衡量一个目标检测算法,通常根据其目标检测的准确度、分类的正确率和检测的目标数量进行评估。本文所用目标检测模型不需要进行分类,因此只需依据其目标检测的准确度和检测目标数量进行评估。
模型的输出为一系列的目标体框坐标,需要将其与真实坐标进行对比,得到其准确率。使用计算模型输出的体框坐标与真实体框坐标的交并比(Intersection over union, IoU)评价两者之间的相似程度。利用交并比判断模型检测结果的正确性。本文在评估目标检测模型时,设置交并比阈值为0.5,即交并比大于0.5的预测结果认为是正确预测,反之,则认为是错误的预测结果。精度(Precision,P)即为正确的预测占所有预测的百分比,值越大说明输出越准确。召回率(Recall,R)即为正确的预测占所有真实框的百分比,值越大说明检测覆盖程度越好。
使用Precision-recall(PR)曲线计算平均精度(Average precision,AP)。AP即PR曲线与坐标轴所围的面积。AP调和了准确率和召回率,对目标检测模型进行综合衡量。在此,不需要计算目标检测的mAP。mAP为多个类别AP的平均值,本文所使用目标检测模块已经剔除了分类功能。
将目标检测模型的运行时间和模型参数文件所占存储空间作为评价指标。
2.2 单牛骨架提取评价指标
骨架提取模型的评估主要是评估关键点的相似度。本文中的骨架提取模型输出16幅热图,经过处理后得到16个关键点坐标,将其与真实坐标进行对比,评估骨架提取模型的效果。物体关键点相似度(Object key point similarity,OKS)是常用的骨骼关键点检测算法的评估指标。其计算公式为
(1)
式中Oks——骨架提取中关键点相似度
δ——关键点的可见程度,0表示不可见,1表示可见
S——单目标图像像素面积,像素
di——关键点i真实坐标与预测坐标的欧氏距离
σi——关键点i的归一化因子
将测试集输入模型后计算OKS,得到所有图像的OKS,人工给定一个阈值,计算出AP。
给AP设置不同阈值,得到多个AP,对多个AP求平均,最终获得mAP。
2.3 多牛骨架提取评价指标
使用OKS计算的mAP衡量肉牛多目标骨架提取模型,mAP从关键点的相似度和召回率综合评价多目标骨架提取模型的精度水平。
假设一幅图像中共有M头牛,多牛骨架提取模型预测出N头牛。将M头牛与预测出的N头牛计算关键点相似度,得到了一个M×N的OKS矩阵。找出矩阵中每一行的最大值作为当前真实肉牛关键点的OKS,最终每一头真实肉牛都会得到一个OKS,设置不同阈值计算AP,最后得出mAP。
3 实验与结果分析
3.1 目标检测模型结果分析与评估
在测试数据集上,取IoU为0.5,YOLO v3与NC-YOLO v3在评价指标上的对比如表2所示。
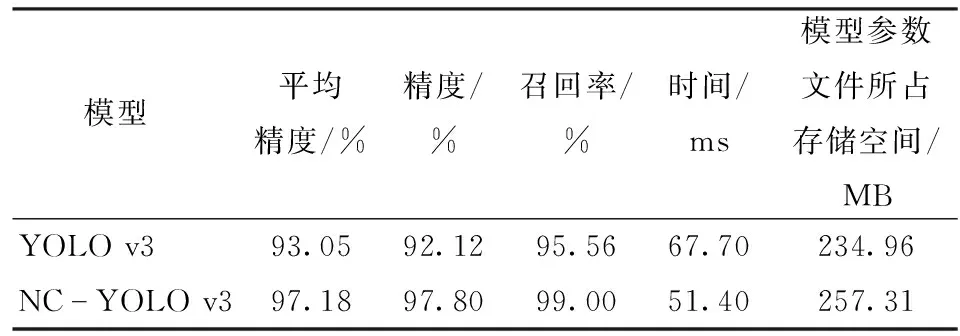
表2 不同目标检测算法效果对比Tab.2 Comparison of different target detection algorithms
NC-YOLO v3的平均精度、精度、召回率分别比YOLO v3高4.13、5.68、3.44个百分点,时间比YOLO v3短16.30 ms,召回率可达99.00%,精度可达97.80%,平均精度可达97.18%。本文提出的NC-YOLO v3算法比YOLO v3算法效果更好。
由于添加了RFB模块,导致改进后模型参数量增加。改进前后模型参数量如表3所示。去除模型的分类功能后可使模型参数量减小13.81 MB,便于模型的存储。

表3 改进前后模型参数量Tab.3 Model parameters before and after improvement
损失值和平均精度变化曲线如图8所示。由图8a可知,NC-YOLO v3的损失值收敛速度快于YOLO v3,并且收敛后的损失值小于YOLO v3。由图8b可知,NC-YOLO v3的平均精度收敛值高于YOLO v3。
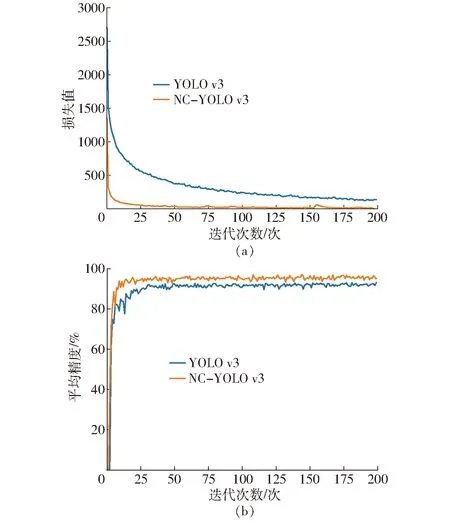
图8 目标检测损失值和平均精度变化曲线Fig.8 Target detection loss curves and average precision curves
实验结果表明,NC-YOLO v3在YOLO v3的基础上提高了检测精度和检测效率,并减小了网络参数量,适合作为本文的多目标骨架提取算法的目标检测模型。
3.2 骨架提取模型结果分析与评估
两种训练方式的损失值曲线如图9所示。
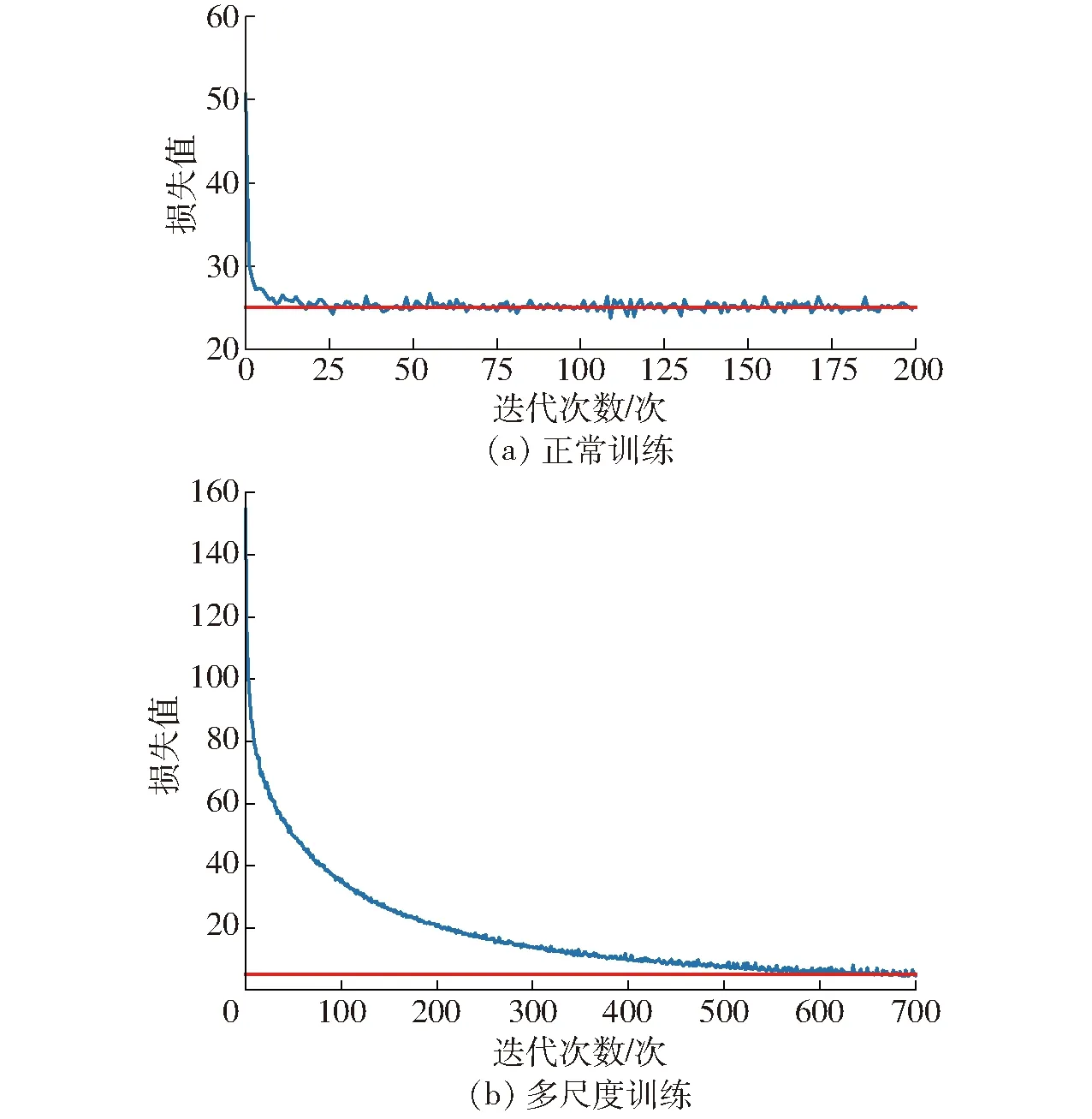
图9 骨架提取损失值变化曲线Fig.9 Skeleton extraction loss value change curves
由图9a可知,模型训练时在第25次迭代开始收敛,其收敛损失值维持在25左右。由图9b可知,模型训练在第600次才开始收敛,其收敛损失值维持在5左右,表明多尺度训练模型相对于正常训练模型具有较高的精度。
在骨架提取测试数据集上,取0.42~0.60之间共10个阈值,计算mAP,结果如表4所示。

表4 不同训练方式下模型的平均精度对比Tab.4 Comparison of model average precision under different training methods %
实验结果表明,多尺度训练下的模型,其mAP可达90.75%,高于正常训练下的模型。在测试集数据上取得了较好的结果,适合作为本文多目标骨架提取算法的单牛骨架提取模块。将一幅单牛图像输入骨架提取模型,结果如图10所示。

图10 单牛骨架提取结果Fig.10 Results of single cattle skeleton extraction
3.3 多牛骨架提取模型分析与评估
取0.42~0.60之间共10个阈值计算mAP,原始模型和改进模型对比结果如表5所示。

表5 不同模型的平均精度对比Tab.5 Comparison of model average precision of different algorithms %
NC-YOLO v3模型的mAP比YOLO v3提高了4.11个百分点,达到了66.05%。
在目标数量为1、2、4、6、10、大于等于15的情况下,NC-YOLO v3构建的多牛骨架提取模型平均精度均值分别为69.25%、70.45%、69.21%、68.49%、56.31%、49.02%。目标数量从1提升至6时,模型精度波动幅度较小,说明在这个区间内目标数量对模型精度影响较小。目标数量增至10头直至大于15头时,模型精度大幅降低,这是由目标太过密集导致遮挡严重、目标检测算法精度急剧下降所导致。
将相同的3幅图像用两种不同算法进行多目标骨架提取,结果如图11所示。白色方框代表误检,黄色方框代表漏检。由此可见,本文算法对于被遮挡目标的检测体框更容易覆盖全身(如图11a白色方框所示)且更逼近目标轮廓,漏检目标更少。因此本文算法更适用于肉牛多目标骨架提取。

图11 多目标骨架提取结果Fig.11 Multi-target skeleton extraction results
4 模型识别效果验证
对肉牛多目标骨架提取模型检测出的肉牛骨架数据进行分析,实现肉牛的卧倒和站立行为的识别。
利用统计学方法,对卧倒与站立行为的肉牛关键点分布进行统计,共统计处于卧倒和站立行为肉牛各50头,统计数据如表6所示。
识别角度是肉牛身体关键点所对应的骨架夹角,从表6可以发现8个识别角度对肉牛的卧倒和站立行为的影响较大。由于模型检测存在一定误差,根据一个或几个识别角度判断肉牛行为,会导致误差扩大,因此设计如下步骤对肉牛行为进行识别:
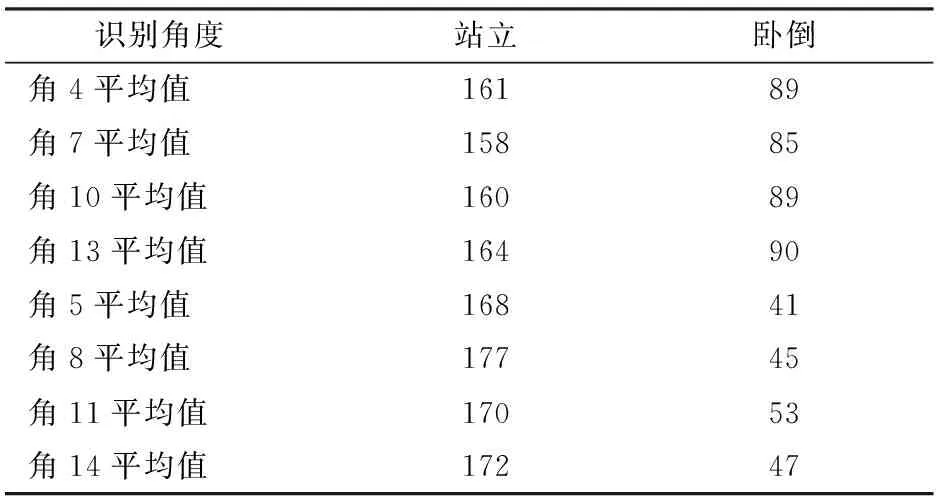
表6 关键点分布统计Tab.6 Key point distribution statistics (°)
①滤除由于相关关键点不存在而导致无法计算的识别角度。②计算识别角度,若不存在可计算的识别角度,则无法识别。③若识别角度大于或等于135°的关键点数目大于识别角度小于135°的数目,则认定肉牛处于站立行为,反之,则认定肉牛处于卧倒行为。
识别结果如图12所示,绿色方框表示肉牛处于站立状态,红色方框表示肉牛处于卧倒状态,黑色方框是由于多目标骨架提取模型检测出的关键点不足而导致无法通过此算法检测肉牛行为。由图12可知,通过分析多目标骨架提取模型检测出的肉牛骨架数据,可实现对肉牛站立与卧倒行为的识别。

图12 肉牛行为识别结果Fig.12 Results of beef cattle behavior recognition
5 结论
(1)利用养殖场监控视频,建立了肉牛目标检测数据集、肉牛单目标骨架提取数据集、肉牛多目标骨架提取测试数据集。通过对YOLO v3添加RFB、剔除分类功能,建立了NC-YOLO v3模型。实验结果表明,在肉牛目标检测数据集上,NC-YOLO v3比YOLO v3具有更高的检测精度。结合NC-YOLO v3模型与多尺度训练的8SH模型建立了肉牛多目标骨架提取模型。验证了本文模型在一定的目标数量内,随着目标数量的增多,模型精度不会大幅降低,而是小幅度波动。
(2)通过对肉牛关键点分布信息进行统计,得出了肉牛处于站立状态与卧倒状态下其识别角度的特征。通过肉牛多目标骨架提取模型检测出的肉牛骨架,计算识别角度,分析其特征进而可以识别其站立与卧倒行为。实验结果表明,本文模型可以为肉牛行为识别提供技术支持。
猜你喜欢
今日农业(2022年2期)2022-11-16
今日农业(2022年1期)2022-06-01
建材发展导向(2022年3期)2022-04-19
电子乐园·上旬刊(2022年5期)2022-04-09
电子乐园·上旬刊(2022年5期)2022-04-09
建材发展导向(2022年2期)2022-03-08
发明与创新·大科技(2020年6期)2020-06-22
农民致富之友(2020年6期)2020-04-08
农民致富之友(2018年9期)2018-06-27
广东教育·高中(2017年10期)2017-11-07
