
基于奇异值分解的大型社交网络差分隐私算法
2022-04-02 02:55杨立聪
计算机技术与发展 2022年3期
郑 剑,杨立聪
(江西理工大学 信息工程学院,江西 赣州 341000)
0 引 言
目前运用于社交网络的差分隐私保护方法主要是关于小型社交网络。尽管这些隐私保护方法可以抵御背景知识攻击来达到保护社交网络的目的,但是随着大数据时代的降临,用户量增大、用户属性增多,这些方法都需要加入大量噪声,导致数据可用性变差。当某网络拥有n个社交用户时,需发布n×n的大型矩阵,导致计算和存储成本过高,因此如何提高大型社交网络发布数据的数据可用性显得尤为重要。针对这一思路,该文提出了一种基于奇异值分解的大型社交网络差分隐私保护算法(random projection-singular value decomposition and differential privacy,RP-SVD-DP),RP-SVD-DP算法利用随机投影将高维社交网络数据映射到低维空间,再对降维后的矩阵进行奇异值分解,在奇异值中加入少量差分隐私噪声保护用户隐私,提高发布数据在基于欧氏距离数据挖掘中的数据可用性。
1 相关工作
该文利用差分隐私对社交网络实现隐私保护,因此相关的已有工作包括:黄海平等[1]提出了一种基于非交互的差分隐私保护模型实现对边权的保护。周艺华等[2]提出了基于聚类的社交网络隐私保护方法。朱勇华等[3]提出一种差分隐私保护模型的扰动策略。王丹等[4]提出一种权重社交网络隐私保护算法。刘爽英等[5]提出一种满足差分隐私保护模型的边权重保护策略。Wang Dan等[6]通过对原始的加权社交网络进行分割,然后在每个子网络利用差分隐私算法来减少噪声的加入量。Li Xiaoye等[7]提出了一种两步差分私有方法来释放群体间聚类系数的分布。Liu Peng等[8]提出了一个保留社区结构信息的局部差异隐私模型。但是将这些方法运用到社交网络,需要很高的计算和储存空间,且当用户量大时需要添加大量噪声,影响数据可用性。
随着大数据时代来临,社交网络用户数量庞大且属性值多,兰丽辉等[9]通过重构分割后的社交网络子图并用向量集来表示,构建满足Johnson-Lindestrauss定理的映射函数,利用随机投影技术对高维向量集进行降维得到待发布向量集。王婷婷等[10]提出一种基于随机投影的社交网络隐私保护。综上所述,如何能够针对大型社交网络进行隐私保护的算法还相对较少,对高维复杂的社交网络数据进行降维并实现隐私保护,同时保证数据的高可用性,仍然具有挑战性。
针对王婷婷等[10]提出的隐私保护算法中存在对降维数据直接添加噪声导致基于欧氏距离数据挖掘中数据可用性较差的问题,结合随机投影、奇异值分解和差分隐私,提出一种基于奇异值分解的大型社交网络差分隐私保护算法。RP-SVD-DP算法第一步利用随机投影对高维社交网络图的数据进行降维,第二步对降维后的数据进行奇异值分解并对奇异值加入高斯噪声,最后通过奇异值分解逆运算生成待发布矩阵。利用奇异值矩阵是一个仅有主对角线上有值的矩阵,值的个数为矩阵的秩,与对降维后的数据直接添加高斯噪声相比,对奇异值矩阵中的值添加高斯噪声能有效地降低噪声的加入量。设计基于欧氏距离差实验和基于谱聚类实验对RP-SVD-DP算法和基于随机投影社交网络差分隐私算法的数据可用性进行对比分析。
2 相关知识
本章主要介绍差分隐私、社交网络图、随机投影、奇异值分解和RP-DP算法的基本概念及相关知识。
2.1 差分隐私
差分隐私[11]是Dwork等在2006年针对数据库数据隐私保护的问题提出的一种新型隐私保护模型,该模型将随机噪声注入到真实数据集中进行扰乱,达到隐私保护的效果,且数据的整体属性保持不变,扰乱后的数据仍可用于数据挖掘等操作。
定义1 (ε,δ)-差分隐私[12]:给定一个随机查询算法К,对于任意邻近数据集D和D',若К在数据集D和D'查询下得到的结果满足式(1),则称随机查询算法К满足(ε,δ)-差分隐私。
Pr[К(D)∈S]≤eε×Pr[К(D')∈S]+δ
(1)
其中,Pr[·]表示若应用随机查询算法M数据可能被泄露的风险;ε表示随机查询算法К所能够提供的隐私保护水平;δ表示允许每个目标数据都会存在δ大小的概率隐私会泄露,δ的取值通常是很小的常数。
定义2 高斯机制[12]:对于给定数据集D,有查询函数f:D→Rd,如果有c2>2ln(1.25/δ),σ≥Δ2(f)/ε,并且N(0,σ2)独立同分布,则算法A满足(ε,δ)差分隐私。
A(D)=f(D)+N(0,σ2)
(2)
定义3 敏感度[12]:数据集D和D'至多相差一条数据集,假设Δ2(f)是随机查询函数f的敏感度,则:
(3)
2.2 社交网络图
社交网络包括用户以及用户之间的关系,通常用图来表示,图1是一个简单的社交网络图。其中顶点表示用户,边表示图中两个用户之间的关系。
对社交网络图G=(V,E)进行差分隐私保护可以转化成对图的邻接矩阵A∈{0,1}n×n进行差分隐私保护。其中节点i和节点j若存在关系则Aij=1,否则Aij=0。图1社交网络图对应的邻接矩阵为:
2.3 随机投影
随机投影是一种比较有效的降维方法,具有无需考虑原始数据本身固有结构、计算负载低、运行效率高等特点。随机投影的理论依据是Johnson-Lindestrauss定理[13]。
定义4 Johnson-Lindestrauss定理(简称J-L定理):对给定的失真率ε(0<ε<1)和任意正整数d,令整数k=O(log(n)/ε2),那么对于任意Rd空间中的n个点构成的集合V,始终存在一个映射f:Rd→Rk使得所有的x,y∈V,有:
(4)
2.4 奇异值分解
奇异值分解(singular value decomposition,SVD)属于线性代数中的一种矩阵分解,广泛应用于机器学习的领域中。
定义5 奇异值分解[14]:设m×n阶矩阵A,且m≥n≥0。令A的秩为r,则存在酉矩阵U、V使得:
(5)
其中,Σ=diag[υ1,υ2,…,υr]为对角矩阵,|Σ|=r,υi为A的奇异值,且υ1≥υ2≥…≥υr≥0,U、V分别为A的左右奇异向量。
定义6 Mirsky定理[15]:令X与X'为具有相同奇异值数的两个矩阵,且:
(6)
那么对于任意的酉不变范数‖·‖,有:
(7)
定义7 矩阵2-范数[16]:对于矩阵A(m×n),Aij为A中对应位置的元素,则它的2-范数为:
(8)
其中,λ1为ATA的最大特征值。
2.5 RP-DP算法
基于随机投影的社交网络差分隐私算法(random projection and differential privacy,RP-DP)是王婷婷等[10]针对有n个用户的社交网络数据,结合随机投影提出的差分隐私算法。该算法通过对原始社交网络图的邻接矩阵利用随机投影进行降维,再对降维矩阵加入高斯噪声,最后发布经过混淆的矩阵。算法的步骤如下:
输入:具有n个用户的社交网络G
(1)生成社交网络图G的邻接矩阵A;
(2)生成投影矩阵P;
(3)利用随机投影生成低维矩阵Ap=A×P;
(4)生成噪声矩阵Δ~N(0,σ2);
RP-DP算法利用随机投影将原始社交网络从n×n维高维矩阵A转化为m×n低维矩阵Ap,其中m≪n,简化了算法的计算复杂性。但RP-DP算法存在一个问题,在步骤4中生成的噪声矩阵Δ∈Rn×m仍是m×n维的,所带来的噪声对数据的可用性破坏仍是十分巨大的。在RP-DP算法中,对数据集中任意两个用户x,y,记两个用户之间的原始距离为dist(x,y)=‖x-y‖2。经过RP-DP算法输出后可得x'=xP+Δ1,y'=yP+Δ2,则用户之间的欧氏距离为:
dist(x',y')=‖x'-y'‖2=
‖(x-y)P+Δ1+Δ2‖2
(9)
其中经RP-DP算法扰动后用户之间距离平方的期望为:
(10)
根据期望公式可知,原始数据中任意两个用户之间扰动后距离的平方比原始距离的平方的期望值多一个定值2mσ2。因此减少加入噪声矩阵的维度m可以减少加入的噪声量,使扰动后的期望值更低。因此引入奇异值分解,对投影后的矩阵进行奇异值分解,对奇异值添加高斯噪声,添加更少的噪声,提高数据可用性。
3 RP-SVD-DP算法
考虑到RP-DP算法中存在将高维数据降低至低维数据中直接添加高斯噪声会产生较大噪声量的问题,该文提出一种基于奇异值分解的社交网络差分隐私算法。
3.1 算法概述
RP-SVD-DP算法将随机投影、奇异值分解相结合解决了RP-DP算法中加入噪声量较大的问题。RP-SVD-DP算法首先生成社交网络的邻接矩阵,利用随机投影将高维矩阵转化为低维矩阵,然后对低维矩阵进行奇异值分解,分解成左奇异矩阵、右奇异矩阵和奇异值矩阵,最后对奇异值矩阵添加高斯噪声,根据奇异值分解逆运算生成待发布矩阵。
RP-SVD-DP算法对奇异值矩阵添加噪声,因为奇异值矩阵只有主对角线上有值,并且值的个数为矩阵的秩,相比于RP-DP算法中的m×n维的噪声矩阵Δ,有效地减小了算法对数据集添加的噪声量。
3.2 算法流程
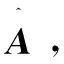
根据流程图可知,算法大致可以分为7个步骤:
(1)对原始社交网络图进行预处理,计算其邻接矩阵A,A∈Rn×n;
(2)生成一个随机高斯矩阵P,矩阵P中的随机数服从高斯分布N(0,1/m);
(3)利用随机高斯矩阵P计算投影后矩阵AP=A×P,AP∈Rn×m;
(5)对奇异值υ添加高斯噪声Δ~N(0,σ2)得到υ';
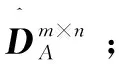
3.3 算法伪代码
算法1:RP-SVP-DP算法。
Input:Original social network GraphG
(1)adjacency matrixA←G,A∈Rn×n
(3)Dimension reductionAp=A×P
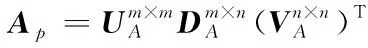
(5)Add noise Σ'=Σ+Δ~N(0,σ2)
3.4 算法隐私性分析
首先计算经随机投影降到m维后的矩阵多维奇异值查询函数的全局敏感度。令查询函数f:D→Rd,输入为图G(含n的节点),整数m(1≤m≤n),输出为图G经随机投影降维后矩阵的奇异值组成的向量。
不失一般性,在原图G中对节点v与u之间的边权重改变1,作为D'。令图G的邻接矩阵为A,则有‖A-A'‖2=1。令经过随机投影降维后的矩阵为Ap,则有:
(11)
其中,Pi,j是服从N(0,1/m)的正态分布。
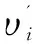
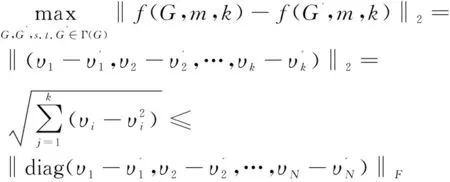
由定义7可知:
(12)
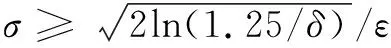
3.5 数据可用性保障
本节分析原始数据经过RP-SVD-DP算法保护后,任意两个用户之间的欧几里得距离的平方在期望值相对不变,即保证原始社交网络数据在基于欧氏距离分析挖掘中的数据可用性。
对数据中任意两个用户x,y,记两个用户之间的原始距离为dist(x,y)=‖x-y‖2。经RP-SVD-DP算法输出后,则有dist(x',y')=‖x'-y'‖2‖(x-y)P+Δ1+Δ2‖2。
令Δ=Δ1+Δ2,因为Δ1,Δ2~N(0,σ2),所以Δ~N(0,2σ2)。则有:
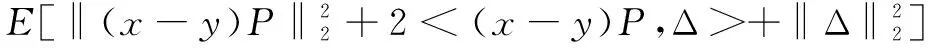
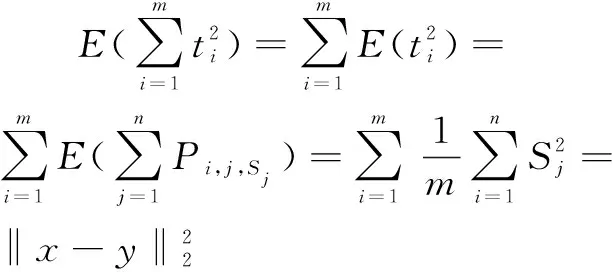

综上所述:
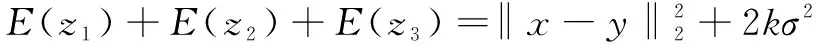
4 实验设计与结果分析
4.1 实验环境与实验设计
硬件环境:Intel(R) Xeon(R) CPU E5-2680 v3 @ 2.50 GHz;32 G内存;1 T硬盘。
软件环境:Windows 10,64位操作系统;Python3。
实验数据采用了斯坦福大学公开数据集SNAP Social network中的Bitcoin OTC子集(含5 881个节点35 592条边)。
为了对RP-SVD-DP算法和RP-DP算法基于欧氏距离数据挖掘中的数据可用性进行对比分析,本节设计了两个实验。第一个实验为基于欧氏距离差的实验,通过计算经过RP-SVD-DP算法和RP-DP算法隐私保护后的待发布矩阵中用户间欧氏距离和原始社交网络图中用户之间的欧氏距离之差来衡量算法的数据可用性;第二个实验为基于谱聚类的实验,对经过RP-SVD-DP算法和RP-DP算法隐私保护后的待发布矩阵进行谱聚类,通过计算标准化互信息NMI来衡量算法的数据可用性。
4.2 欧氏距离差实验
为了对所提出的RP-SVD-DP算法和RP-DP算法添加的噪声量做统一的度量,用待发布矩阵用户间的欧氏距离和原始社交网络图中用户之间的欧氏距离之差来衡量算法的数据可用性,以此为评价依据衡量噪声加入量所带来数据可用性的变化。实验从Bitcoin OTC数据集中随机采样选取了600名用户(约为总体十分之一),并计算用户原始欧氏距离分别经RP-DP算法和RP-SVD-DP算法在相同隐私保护水平下扰动后的用户间欧氏距离差。在实验中,将原始数据集降至500维,即m=500,以及差分隐私保护水平分别设为ε=0.3,0.5.0.7.0.9,为了提高实验结果的准确性,在每个隐私预算下进行十次实验取平均值。实验结果如表1所示。
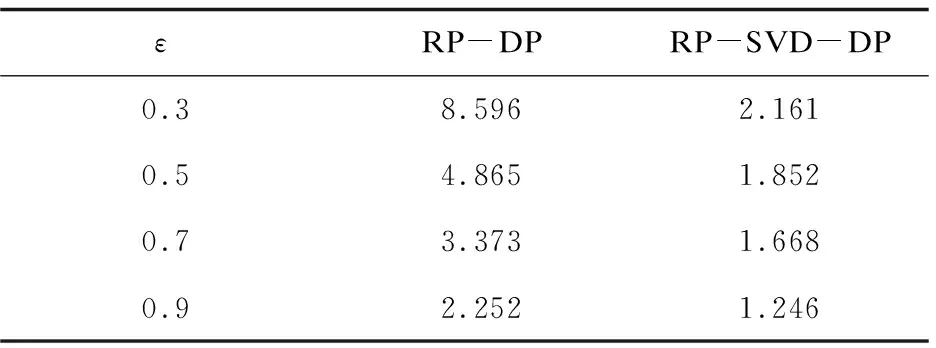
表1 不同隐私保护算法用户间欧氏距离差
分析表1数据可知,RP-DP算法和RP-SVD-DP算法的欧氏距离差不大,说明算法都满足J-L定理,且欧氏距离差随着隐私预算ε的变大而变小。在相同的隐私预算ε下,RP-SVD-DP算法的用户间欧氏距离差均小于RP-DP算法,且随着隐私预算不断减小,RP-SVD-DP算法欧氏距离差的增长幅度也小于RP-DP算法,说明RP-SVD-DP算法的数据可用性优于RP-DP算法。由实验结果得出,RP-SVD-DP算法加入的噪声量低于RP-DP算法。
4.3 谱聚类实验
为了对所提出的RP-SVD-DP算法和RP-DP算法发布的数据在基于欧氏距离数据挖掘中数据可用性做统一的度量,用标准化互信息NMI衡量算法的数据可用性,以此为评价依据衡量投影数量m和隐私预算参数ε所带来数据可用性的变化。
谱聚类实验分为两部分,分别改变随机投影数量m和差分隐私保护水平ε,对原始数据集进行聚类,通过计算不同隐私保护算法下的标准化互信息NMI来衡量发布数据集的数据可用性程度。
在改变随机投影数量m的对比实验中,将算法的差分隐私保护水平分别设为ε=0.5和ε=0.9。通过将原始数据集从高维数据转化为不同维数的低维数据,对比两算法NMI值的大小,从而分析算法数据可用性,实验结果如表2所示。
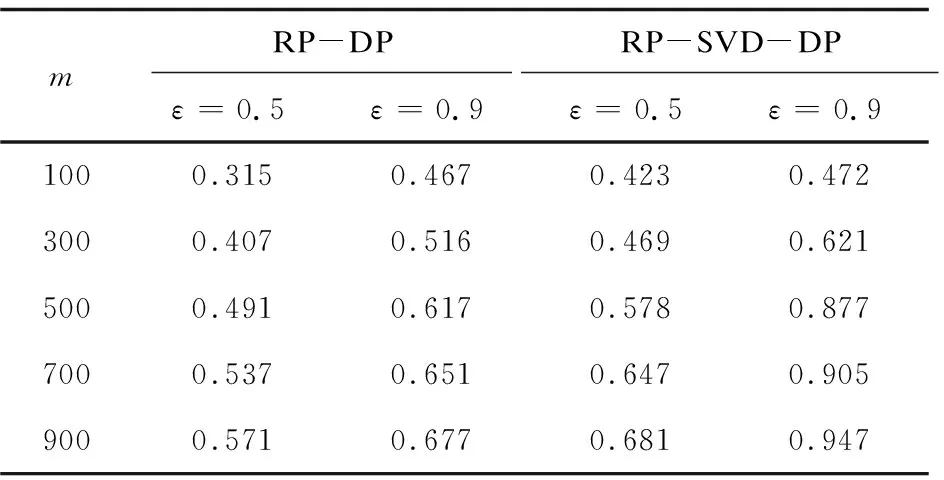
表2 不同随机投影数量m值,算法发布数据集谱聚类的NMI值对比
分析表2可知,RP-SVD-DP算法和RP-DP算法的NMI值均随着随机投影数量m的增大而增大,说明将原始高维数据的维度降的越低,所丢失掉的信息越多,导致算法的数据可用性越差。在相同差分隐私保护水平的情况下,RP-SVD-DP算法的NMI值均高于RP-DP算法。当m=500,ε=0.9时,RP-SVD-DP算法的NMI值达到了0.947,而RP-DP算法的NMI值只有0.677;当m=500,ε=0.5时,RP-SVD-DP算法和RP-DP算法的NMI值分别为0.578和0.491。由实验结果得出,在相同的隐私预算下,将原始数据集降低至不同维度,RP-SVD-DP的数据可用性均优于RP-DP算法。
在改变差分隐私保护水平ε的对比实验中,将原始数据集通过随机投影降低至500维,即m=500,将差分隐私保护水平ε设为不同值,对比两算法的NMI值大小,分析算法数据可用性,实验结果如表3所示。
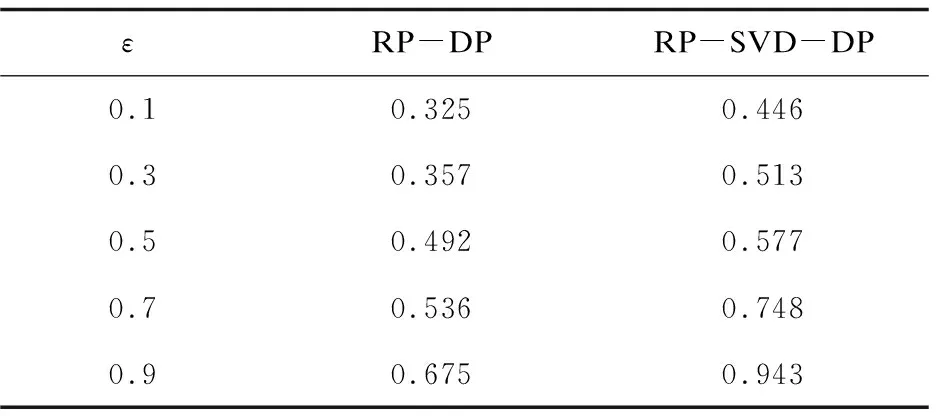
表3 不同隐私保护算法发布数据集相对原始数据集谱聚类的NMI对比(m=500)
分析表3可知,在相同的投影维度m=500的情况下,RP-SVD-DP算法和RP-DP算法的NMI值均随着隐私保护水平ε的增大而增大。由图中曲线可知,当隐私保护水平ε=0.3时,RP-SVD-DP算法的NMI值为0.513,而RP-DP算法的NMI值仅有0.357;当隐私保护水平ε=0.7时,RP-SVD-DP算法的NMI值大于0.748,而RP-DP算法的NMI值仅有0.536。由实验结果得出,把原始数据集降低至相同维度,在不同的隐私预算下RP-SVD-DP的数据可用性均优于RP-DP算法。
5 结束语
为解决RP-DP算法中因噪声过大导致数据可用性低的问题,提出了一种改进的RP-SVD-DP算法。在RP-SVD-DP算法中,先对原始数据利用随机投影进行降维;再对降维后的数据进行奇异值分解,对奇异值矩阵加入差分隐私噪声;最后发布加噪后的数据。实验表明,RP-SVD-DP算法在基于欧氏距离的实验中加入的噪声量更少,数据可用性优于RP-DP算法。提出的基于奇异值分解的社交网络差分隐私算法是一种非交互式隐私保护方法,无法做到数据的实时更新发布,在大数据时代,数据通常都是实时变化的,所以下一步要将该算法扩展至交互式,尽可能地保证数据的实时性。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
湘潭大学自然科学学报(2022年2期)2022-07-28
仪器仪表用户(2022年6期)2022-06-06
现代计算机(2021年14期)2021-11-20
大连民族大学学报(2021年3期)2021-10-15
中国科技纵横(2020年24期)2020-11-28
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
计算机应用(2016年10期)2017-05-12
延边大学学报(自然科学版)(2015年1期)2015-12-26
