
基于GA-BP神经网络的尾砂浓密多目标精准预测*
2022-04-02 13:32杨莹吴爱祥王先成王国立刘伟涛
采矿技术 2022年2期
杨莹 ,吴爱祥,王先成,王国立,刘伟涛
(1.北京金诚信矿业管理股份有限公司, 北京 101500; 2.北京科技大学 土木与资源工程学院, 北京 100083)
0 引言
我国膏体充填站的建设发展迅猛,但膏体系统控制技术尚未达到智能化水平[1-2]。尾砂浓密工艺智能化不仅顺应矿业智能化的发展趋势,也能够解决该工艺的自身局限。尾砂浓密是充填技术的首要环节,尾砂浓密获得的底流是后续搅拌、输送和充填体强化的原料基础,为了保证充填质量,充填系统对尾砂浓密效果具有很高要求。然而,尾砂浓密由于自身工艺特点,受到多种因素影响,但却缺乏影响因素与浓密效果之间明确的映射关系;其次,由于尾砂浓密需要一定的压密时间,导致工艺调控具有很长的滞后性,一旦发生问题,恢复时间也很长,但该工艺却没有配备完备的预测和预警系统。
结合尾砂浓密工艺的特殊需求,我国的研究学者也在尾砂浓密智能化方面进行不断探索[3-5]。张钦礼等[6]以入料质量浓度、絮凝剂质量浓度和单耗作为输入因子,以沉降速度作为综合输出因子,建立尾砂浓密的支持向量机(SVM)回归预测模型;通过遗传算法(GA)对SVM模型参数进行优化,实现絮凝沉降参数的预测;王新民等[7]应用BP神经网络处理絮凝沉降正交试验数据,建立了料浆质量浓度、絮凝剂质量浓度及单耗与沉降速度和极限质量浓度的关系模型;QI等[8]收集了27种金属矿山尾矿样品,进行大量尾砂浓密试验,结合萤火虫算法,构建FA-GBT杂化模型,实现了尾砂浓密智能化的初步探索;使用粒子群算法-自适应模糊神经推理系统,进行初始沉降速度预测,进一步提升人工智能方法在絮凝沉降中的预测精度[9]。然而,现阶段我国的尾砂浓密智能化仍处于初级阶段。不同学者在选择算法时存在较大差异,导致模型的适用性存在局限。常用的BP神经网络和SVM支持向量机等均存在明显缺陷。BP神经网络存在学习收敛速度慢[10]、不能保证收敛到全局最小点[11]、网络结构不易确定[12]等问题;SVM支持向量机则借助二次规划求解支持向量,涉及高阶矩阵计算,因此对大规模训练样本难以实施;因此,需要在了解单一算法的基础上,进行进一步优化,提高模型的适用范围和精准程度。
本文采用自制小型尾砂浓密系统获取动态浓密试验关键参数,为模型建立提供数据来源;利用BP神经网络在处理多输入、多输出、非线性映射关系的优点,以尾砂浓密影响因素为输入量,尾砂浓密效果参数为输出量,确定合理的隐层神经元个 数,设计网络结构;借助遗传算法优化神经网络的初始权值和阈值,构建了基于GA-BP神经网络的尾砂浓密多目标预测模型。预测模型学习收敛速度快,保证收敛到全局最优点,预测精度高,为实现尾砂浓密智能化提供参考。
1 全尾砂动态浓密试验
1.1 试验材料
试验所用全尾砂来自新疆某矿山,尾砂密度为2662 kg/m3。尾砂粒度组成采用激光粒度仪进行测量,粒度分布曲线如图1所示。试验所用全尾砂属于细粒级尾砂,小于20 μm 的尾砂颗粒质量分数约为30%,小于74 μm 的尾砂颗粒质量分数为64.32%。尾砂颗粒不均匀系数为18.36,曲率系数为1.62,级配良好。

图1 全尾砂粒度组成曲线
本试验中,经过前期尾砂静态沉降试验,确 定的最佳尾砂入料质量浓度为15%,絮凝剂类型为Magnafloc 5250 型絮凝剂,其成分为聚丙烯酰胺(APAM),属于有机高分子阴离子型絮凝剂,最佳絮凝剂溶液质量浓度为0.02%,单耗为20 g/t。
1.2 试验过程
采用自主研发的小型尾砂动态浓密试验系统进行尾砂动态浓密试验。如图2所示,尾砂动态浓密试验系统由尾砂浆配置与添加系统、絮凝剂配置与添加系统、深锥浓密机模型、底流循环系统和底流排放系统组成,可模拟深锥浓密机内尾砂絮团形成、运移、压密等过程,更能贴合现场实际情况。
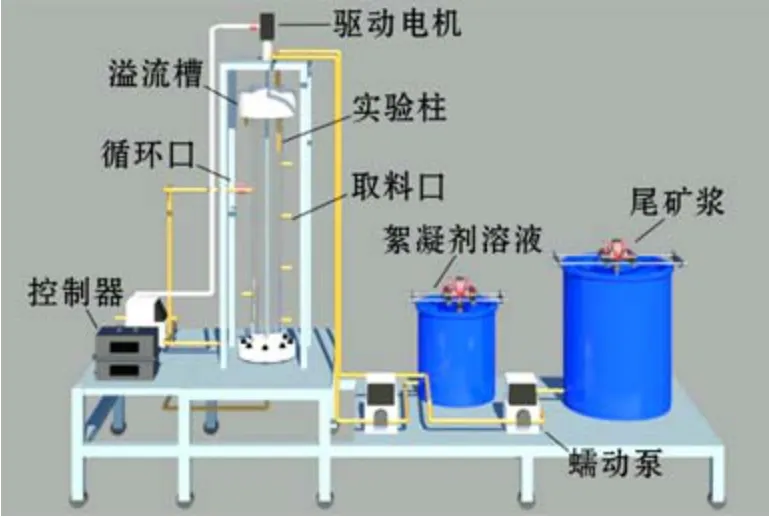
图2 小型尾矿浓密动态系统布置
尾砂动态浓密试验过程:利用尾砂浆配置与添加系统,将烘干后的尾砂配制质量浓度为10%~20 %的尾砂浆,在储料桶内搅拌均匀;利用絮凝剂配置与添加系统,配制质量浓度为0.010%~0.105%的絮凝剂溶液,在桶内搅拌均匀;按照絮凝剂单耗为10~30 g/t,计算尾砂浆和絮凝剂溶液的进料流量范围;根据经验,确定耙架转速的范围在0.50~1.45 r/min;按照表1所示的试验方案,通过蠕动泵,按照不连续与连续相结合的方式,将尾砂浆和絮凝剂溶液持续添加至深锥浓密机;待动态浓密过程稳定后,读取尾砂浆出料流量值,多点取样测量尾砂底流质量浓度和溢流水浊度,计算平均值。
2 基于GA-BP神经网络的尾砂浓密多目标 预测模型
膏体技术的尾砂浓密工艺是一项复杂的系统工程,是典型的多输入、多输出、非线性关系模型。鉴于浓密机内部理论分析尚不完善,建立精确的数学模型非常困难,因此,其优化设计不可避免地涉及到多源异构数据的处理与分析,获取信息间的映射关系。
本文借助Matlab开发环境,以尾砂浓密工艺关键参数为着眼点,以尾砂浓密的影响因素为输入层,尾砂浓密效果为输出层,确定最优的隐层神经元个数,选择合理的神经网络结构;将样本数据进行归一化处理,利用训练样本训练网络,利用测试样本对网络进行验证;将BP神经网络预测误差的范数作为目标函数的输出,利用遗传算法优化神经网络的初始权重和阈值;最终构建了基于GA-BP神经网络的尾砂浓密多目标预测模型。
2.1 样本数据处理
本文从某矿山尾砂浓密试验中选取20组试验结果作为建模的数据样本,其中1~15组作为训练样本,16~20组作为测试样本。
样本输入量为:尾砂浓密的入料质量浓度、入料流量、入料速度、絮凝剂溶液质量浓度、絮凝剂溶液流量、耙架转速;样本输出量为:底流质量浓度、底流流量、溢流浊度,具体参数见表1。
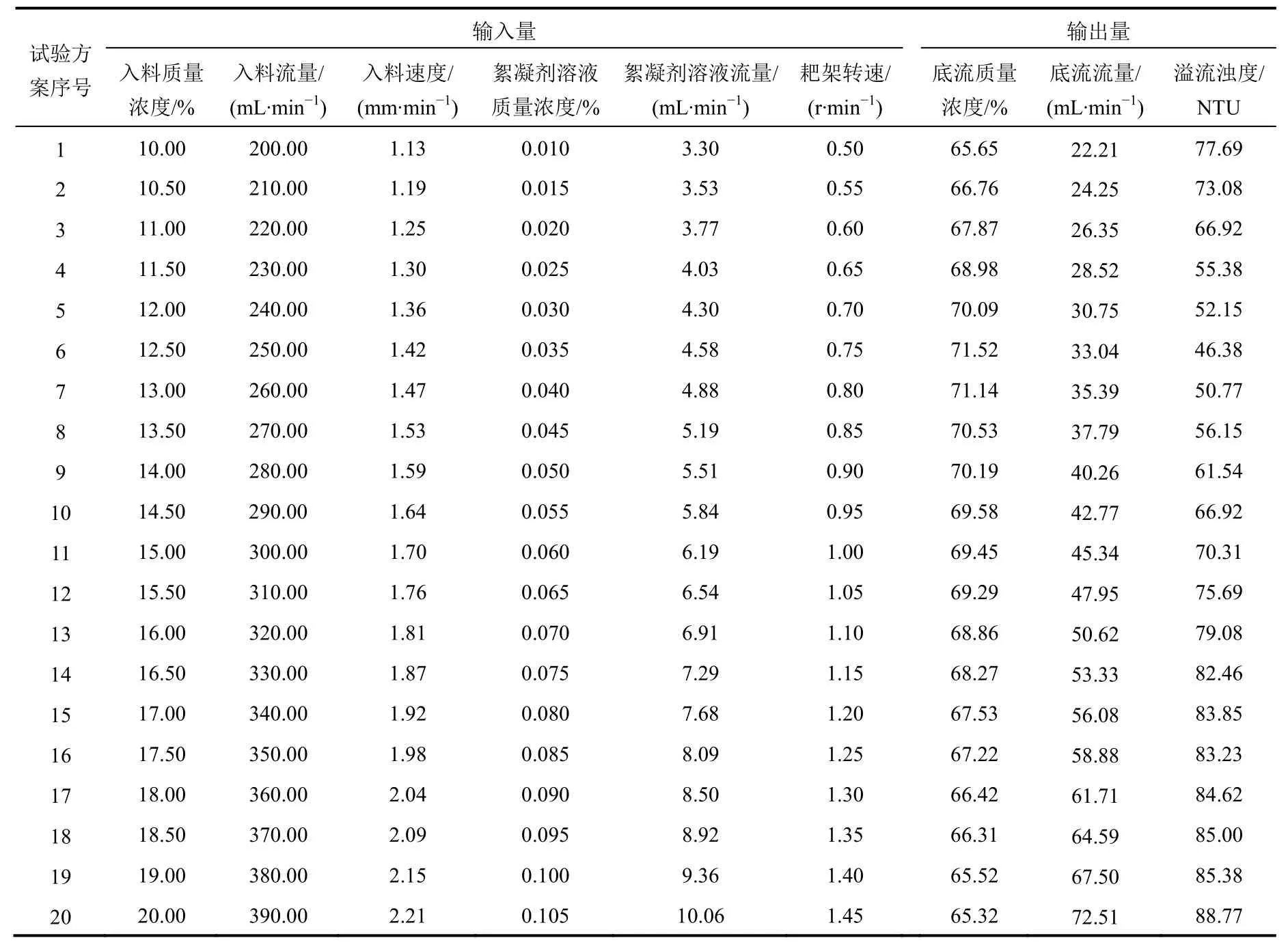
表1 尾砂浓密试验方案及结果
考虑到样本数据量纲和数值存在较大差异,为 了减轻BP神经网络训练难度,在网络训练前,按照式(1)~式(2)对样本数据进行归一化处理[19]。
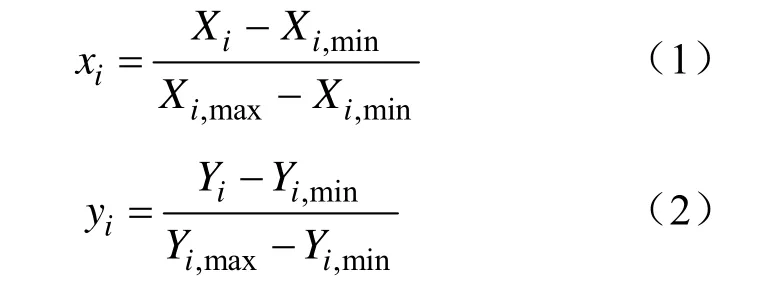
式中,xi和yi分别是尾砂浓密样本数据的输入量和输出量;Xi和Yi分别是归一化后的输入量和输出量;Xi,min和Yi,min分别是相应列的最小值;Xi,max和Yi,max分别是相应列的最大值。
2.2 网络结构设计
本文的神经网络分为3层,即输入层、隐含层和输出层。根据样本数据的输入量和输出量,确定的6个输入层神经元分别为:尾砂浓密的入料质量浓度、入料流量、入料速度、絮凝剂溶液质量浓度、絮凝剂溶液流量、耙架转速;3个输出层神经元分别为:底流质量浓度、底流流量、溢流浊度。
隐层神经元个数的确定:在BP神经网络中,隐含层神经元个数是不确定的, 但必须小于P-1(P是训练样本数),否则建立的网络模型没有泛化能力;训练样本数必须大于网络模型的连接权数,一般为2~10倍。因此,隐层神经元个数可以根据经验公式[20]来确定:
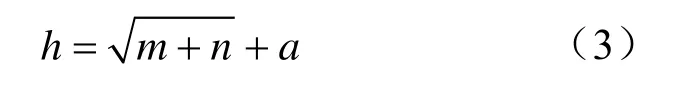
式中,h为隐含层神经元个数;m和n分别是输 入层和输出层神经元个数;a为1~10之间的调节常数。
计算出隐层神经元个数在[4, 13]之间。采用同一组数据,构建具有不同隐层神经元个数的神经网络,对其相对预测误差进行对比(见表2),选择相对误差最小的神经网络,其隐层神经元个数即为最优隐层神经元个数。相对预测误差计算公式[21]:
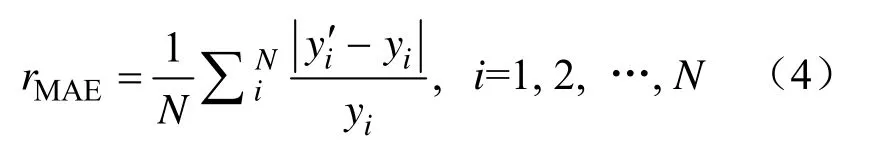
式中,rMAE为相对预测误差;N为样本个数;i为样本序号;y′i和yi分别为对应样本的预测值和测 量值。
由表2可知,隐层神经元个数为11时,神经网络误差最小。因此,确定因此神经元个数为11,BP神经网络网络结构为6-11-3。
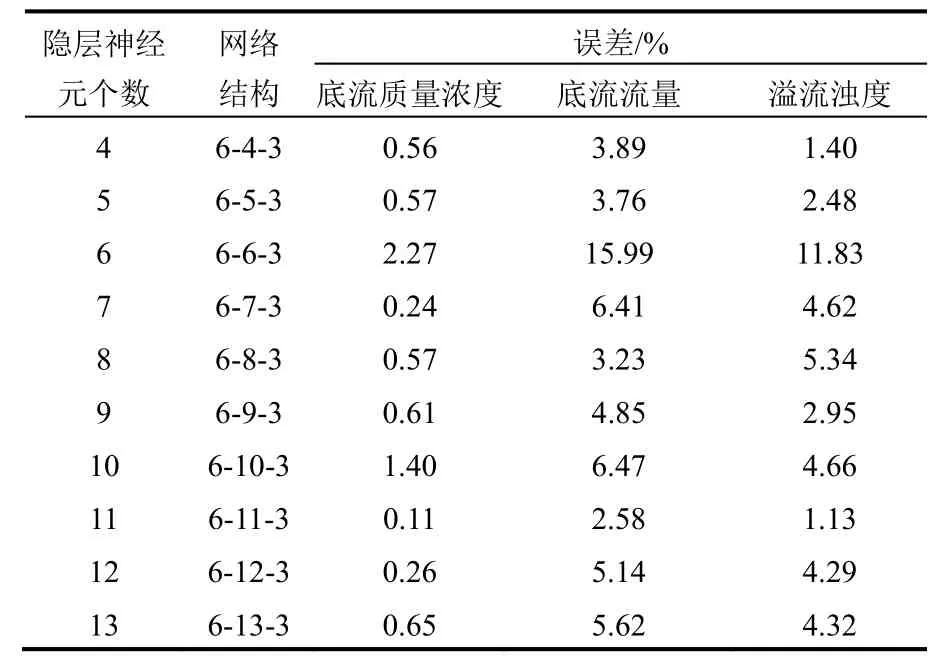
表2 隐层神经元个数及其神经网络相对误差
2.3 模型参数选择
BP神经网络隐层神经元的传递函数采用S型正切“tansig”函数,输出层神经元传递函数采用S型对数“logsig”函数。BP神经网络训练函数为“trainlm”函数,训练次数为1000,训练目标为0.001,学习速率为0.1。
然而,在上述BP神经网络构建过程中,网络的权值和阈值是[-0.5, 0.5]区间的随机数[16-17],初始化参数的无法准确获得,导致BP网络存在学习收敛速度慢[10]、不能保证收敛到全局最小点[11]、网络结构不易确定[12]等问题,可以通过引入遗传算法对神经网络进行优化,最终构建基于GA-BP神经网络的尾砂浓密多目标预测模型。
2.4 GA-BP多目标预测模型构建
GA-BP神经网络多目标预测模型通过遗传算法寻求网络最佳初始权值和阈值,能够提高预测的精准度,加快预测模型的学习速度,保证模型收敛到全局最优解[18-20]。如图3所示,GA-BP预测模型构建的方法[21-22]为:首先,将神经网络中的输入层与隐层连接权值、隐层阈值、隐层与输出层连接权值、输出层阈值作为遗传算法种群中的个体,对个体进行二进制编码;其次,采用排序的适应度分配函数作为适应度函数,选择样本预测值与期望值误差矩阵的范数作为目标函数的输出;然后,将种群中的个体按照适应度大小进行排列,采用“轮盘赌选择法”对种群中的个体进行配对选择,作为下一代个体的父母;采用单点交叉方式,将父母进行交叉繁殖,交换部分基因,得到后代个体;采用单点变异形式,将染色体编码串中的第一个基因值替换,从而形成一个新的个体;最后,将遗传算法得到最优个体对BP网络进行初始权值和阈值的赋值,进行网络训练,对比优化前后神经网络的预测效果。
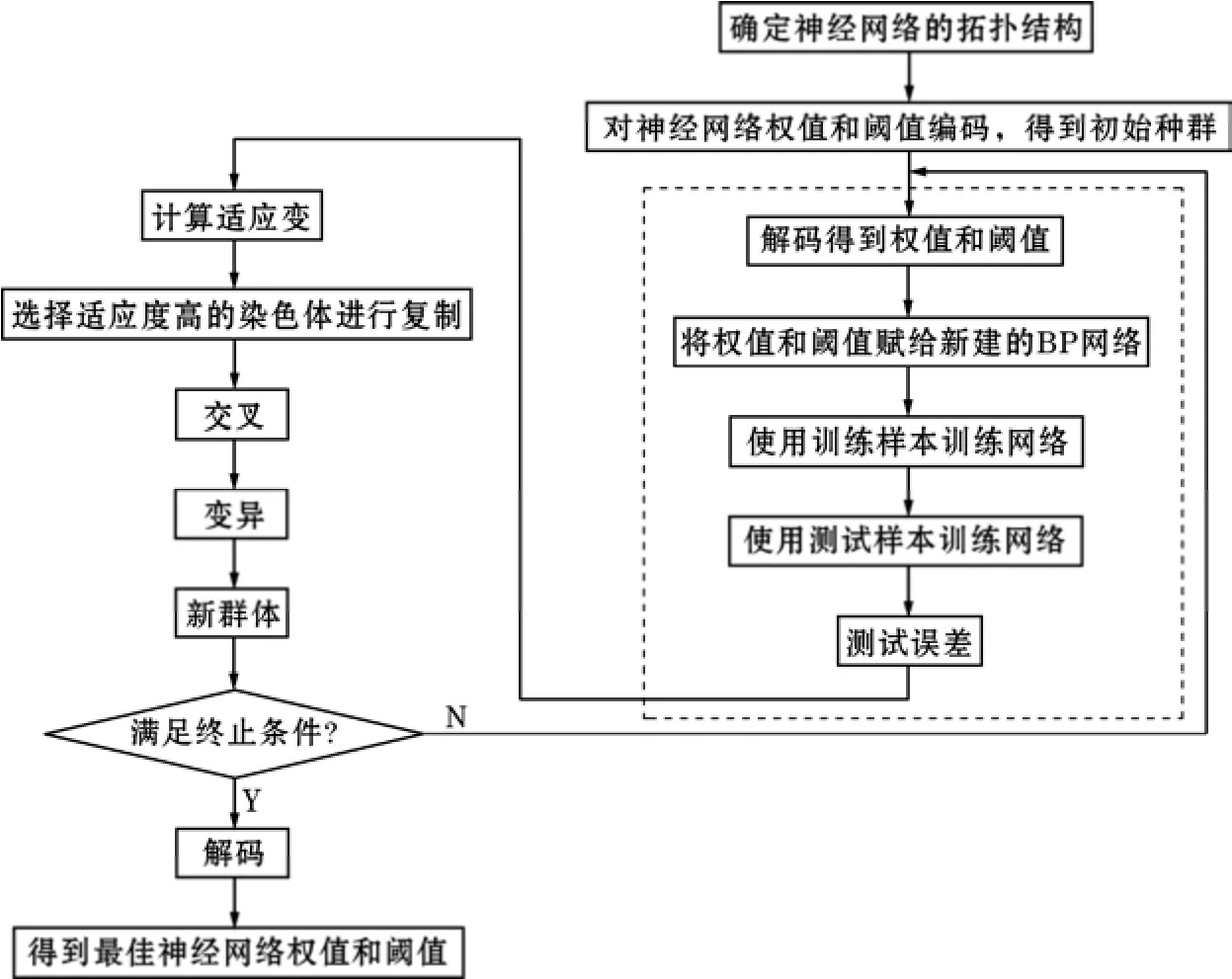
图3 GA-BP神经网络多目标预测模型构建流程
GA-BP神经网络多目标预测模型的基本运行参数[23-24]见表3。

表3 遗传算法运行参数设定
3 预测结果与现场验证
在构建尾砂浓密预测模型的基础上,结合样本数据中的第16~20组测试样本,对BP和GA-BP神经网络预测模型进行训练和测试。通过对比两个网络的预测误差,显示GA-BP神经网络预测模型精度更高。此外,根据新疆某矿山尾砂浓密的实际工艺生产参数,应用GA-BP神经网络预测模型对其尾砂浓密效果进行预测,对比实测值和预测值的误差,验证GA-BP神经网络尾砂浓密多目标预测模型的可靠性。
3.1 BP与GA-BP预测模型结果对比
如图4,在遗传算法优化神经网络的过程中,网络的期望输出和实际输出之间的误差在遗传代数5代以内,即实现误差的快速降低,在40代左右稳定收敛,说明GA-BP神经网络的收敛速度快,有利于提高神经网络的预测精度。
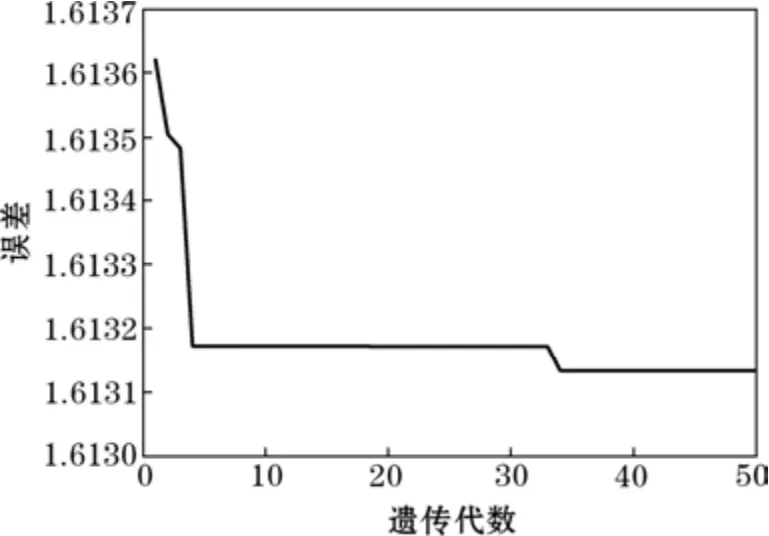
图4 GA-BP神经网络训练进化过程
在底流质量浓度、底流流量和溢流浊度的预测中,BP和GA-BP神经网络的预测值均在实际值附近(见图5至图7),说明二者均能够实现尾砂浓密效果的预测。相比于BP神经网络,GA-BP神经网络模型在3个输出层神经元的预测中,预测值都更接近实际值,表明遗传算法优化后的神经网络预测精度的提高。
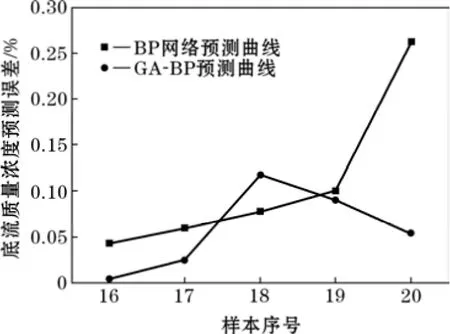
图5 底流质量浓度预测误差
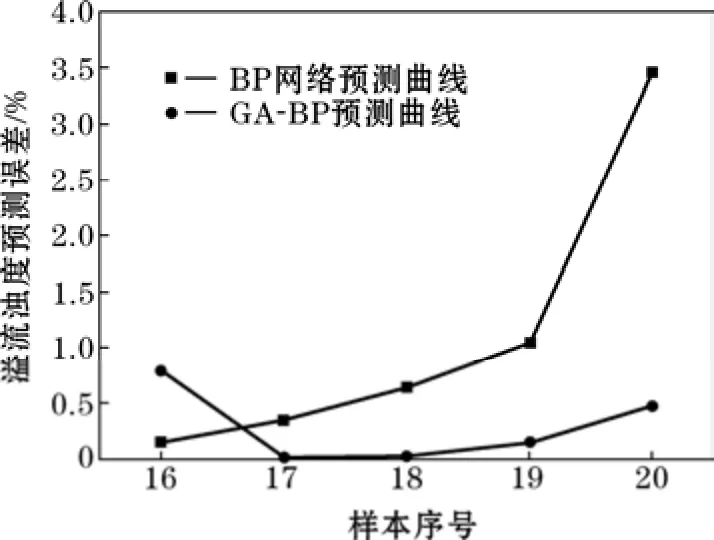
图7 溢流浊度预测误差
在针对第16~20组测试样本的底流质量浓度预测中,BP神经网络和GA-BP神经网络的预测误差均在0.30%以内,都能够满足预测精度的要求。GA-BP神经网络的预测误差保持在0.15%以内,预测精度更高。

图6 底流流量预测误差
在针对测试样本的底流流量预测中,BP神经网络的预测误差在6%以内,GA-BP神经网络的预测误差在2%以内。通过优化,GA-BP神经网络的预测精度显著提高。
在测试样本的溢流浊度预测中,BP神经网络和GA-BP神经网络的预测误差范围差异较大。BP神经网络的预测误差在4%以内,GA-BP神经网络的预测误差在1%以内。GA-BP神经网络的预测精度更高。
综上所述,在底流质量浓度、底流流量和溢流浊度的预测中,BP神经网络的预测误差在6%以内,GA-BP神经网络模型的预测误差在2%以内。通过遗传算法优化神经网络的权重和阈值,GA-BP神经网络的预测精度提高。
3.2 矿山现场验证
新疆某矿山尾砂浓密系统的入料质量浓度为15%,入料流量为1800 m3/h,入料速度3.00 m/s,絮凝剂溶液质量浓度为0.10%,耙架转速为0.2 r/min。应用该模型对其尾砂浓密效果进行预测,预测结果见表5。对比实测值和预测值的误差,验证了GA-BP神经网络尾砂浓密多目标预测模型的可靠性,其误差满足精度要求。
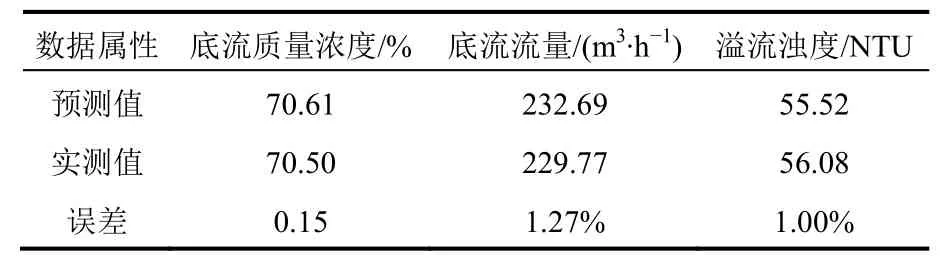
表5 矿山现场尾砂浓密预测与实测对比
4 结论
(1)尾砂浓密工艺是典型的多输入、多输出、非线性关系模型。采用自制小型尾砂浓密系统进行动态浓密试验,探索尾砂浓密关键参数变化规律,为预测模型的建立提供数据来源。
(2)以尾砂浓密的入料质量浓度、入料流量、入料速度、絮凝剂溶液质量浓度、絮凝剂溶液流量、耙架转速为输入层神经元,以底流质量浓度、底流流量、溢流浊度为输出层神经元,建立了6-11-3的BP神经网络,获得了尾砂浓密影响因素与效果评价指标之间的映射关系。
(3)借助GA的全局搜索能力,优化BP神经网络的初始权值和阈值,构建了基于GA-BP神经网络的尾砂浓密多目标预测模型,模型学习收敛速度快,保证收敛到全局最优点。
(4)结合测试样本,对BP神经网络和GA-BP神经网络进行对比,表明GA-BP神经网络的模型预测精度较高;根据矿山现场实测,对GA-BP神经网络模型的预测精度进行再次验证,其预测误差仍可达1%左右。
猜你喜欢
山西化工(2022年6期)2022-10-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
安徽化工(2021年3期)2021-05-29
电子产品世界(2021年8期)2021-01-16
科学导报·科学工程与电力(2019年36期)2019-09-10
中国计算机报(2019年49期)2019-02-07
中国新闻周刊(2017年36期)2017-10-21
软件(2017年6期)2017-09-23
