
基于自然语言处理的大气质量舆情空间化方法
2022-04-02 08:06宋鹏飞孙勇季民张立国郑
测绘地理信息 2022年2期
宋鹏飞孙 勇季 民张立国郑 岩
1山东科技大学测绘与空间信息学院,山东 青岛,266590
2山东建筑大学测绘地理信息学院,山东 济南,250101
3山东省国土测绘院,山东 济南,250000
随着我国经济的快速发展,不断出现的区域性大气污染事件[1],已成为政府和公众关注的焦点。目前大气质量监测主要依赖的是国控站点,这些站点大多分布在城市,且点位稀疏,通过这些站点的长时序监测,可为宏观区域大气质量变化分析提供实测依据,但对频发的局域性或区域性大气污染事件的监测则显得有些不力。而公众是空气质量的直接感知者[2],对空气质量的满意度评价则可以成为政府职能部门进行大气环境治理的基础[3]。自从人类进入互联网时代,人们在网络上进行大气质量的议论和评价已经成为常态,通过收集公众对大气质量投诉的舆情信息,并加以空间化,可有效地反映出区域性大气污染状况分布,这不仅能够提高民众的政治参与度[4],而且还能够为政府部门对区域性大气污染事件的监管与治理提供决策依据。
关于空间化方法,国内外学者均进行了诸多研究,王明明等[5]利用夜间灯光数据进行了山东省乡镇级人口数据的空间化;尹言军等[6]利用FME软件对浮动车的交通数据进行了空间化。自然语言处理(natural language processing,NLP)技术也得到了快速发展,尤其在中文分词和词性标注等方面[7-9],Matci等[10]将自然语言处理融入到地理编码中,通过地址分解、错误修正及基于NLP的地址重组,实现了地址标准化;许普乐等[11]在大数据环境下,基于贝叶斯推理进行了海量中文地名地址的快速匹配。目前关于大气质量舆情信息的地址匹配和空间定位尚未有相关文献,本文以山东省环境保护厅公众投诉平台爬取的大气质量舆情数据为基础,通过使用基于条件随机场(conditional random field,CRF)模型的中文分词和词性标注等方法,进行了大众重点投诉区域的地址匹配和空间可视化表达,可为山东省从宏观到中小尺度下的大气质量监测提供一定的参考。
1 舆情数据来源及相关算法
1.1 数据来源
大气污染舆情数据来源于山东省环境保护厅公众投诉平台爬取的公众投诉信息,其中主要包含:投诉的大气污染类型、投诉时间、投诉内容以及针对投诉的处理状态、答复情况等,其中,大气污染类型主要包括了飞尘、恶臭/异味、油烟、机动车/移动源、工业废气、烟尘以及其他大气污染等;投诉内容以自然语言形式存在,需要对其进行分析和处理,以提取其中的中文地址信息和大气污染专题舆情语义信息。
1.2 自然舆情信息处理模型
在对大气质量舆情信息进行处理时主要用到了自然语言处理技术中的中文文辞和词性标注,主要的算法有隐马尔科夫模型(hidden Markov model,HMM)、最大熵模型、CRF模型等[12],鉴于CRF模型的性能优势,本文选择使用CRF模型来进行中文分词,并使用HMM模型对无法识别的未登录词进行标注。
1)CRF模型。
CRF模型在进行分词时,不仅能够统计某个词出现的频率,而且还将上下文语境也纳入考量范围内,在对数据中的一些未登录词,例如工厂名称等,具有良好的切分效果。其中最常用的是线性条件随机场模型,在随机变量X取值为x的条件下,随机变量Y取值为y的条件概率[13]。
2)HMM模型。
HMM模型包含一个可见的状态序列和一个隐藏状态序列,这两个序列概率相关,并由5个参数组成[14],可以用一个五元组{N,M,η,A,B}表示。其中,N表示隐藏状态的数量,每一个状态的概率可以有确定的值,也可以进行分析确定;M表示可见状态的数量,通过训练集获取;η=ηi表示每一个隐藏状态初始时刻发生的概率;A={aij}表示隐藏状态的转移矩阵,即从隐藏状态1到隐藏状态2事件发生的概率;B={bij}表示混淆矩阵,即在某个隐藏状态的条件下可见状态发生的概率。
2 大气舆情数据空间化方法
在大气污染空间化分析与评价中,需要将公众舆情数据中的地址信息进行解析提取,并通过地址匹配方法,实现空间位置转化,其数据处理过程可包括:数据预处理、自然语言处理、词性提取、地址匹配等。其中,数据预处理包括了内容提取和去停用词等两个步骤,自然语言处理包括了中文分词和词性标注等两个过程,如图1所示。

图1 大气舆情数据空间化过程Fig.1 Air Public Opinion Data Spatialization Process
2.1 数据预处理
数据预处理就是对公众投诉的舆情数据进行内容提取及停用词去除。首先为了便于管理和数据读写的方便,通过设计相应的数据库结构,将获取的公众投诉数据转存入数据库,并将包含位置信息的数据内容以单独字段进行存储,以提高数据分析过程中的读写效率,同时通过去除一些特殊符号、停用词等,实现对数据内容的清洗。
2.2 中文地名地址标注
借助CRF模型对公众投诉内容进行中文分词,将分词结果在百度词库中进行字符串匹配,查找词性,无法识别成功的词语既为未登录词,紧接着运用HMM模型对其进行词性标注。由于同一个词在不同的语句中具有多种词性,并且在不同应用领域中也存在诸多未登录词,从而造成词性标注存在诸多难点,为此,将词语的词性划分为普通名词、普通动词、代词、形容词等24类,如表1所示。为了进一步确定专有名称,又划分了人名(PER)、地名(LOC)、机构名(ORG)、时间(TIME)这4类专名词性,这些词性分类为自然语言处理过程中的词性标注提供了有力支撑。

表1 词性标注表Tab.1 Part of Speech Tag
2.3 词性提取及地址匹配
词性标注分析完成后,须将其中的地名(LOC)和机构名(ORG)进行提取,由于公众投诉内容中可能会包括工厂污染排放问题,因此提取的工厂名称会被标注为机构名。词性提取完成后,须按照提取的地点名称和机构名称实现投诉信息的空间定位,即地址匹配。所谓地址匹配是使用地理编码将地址信息转为经纬度坐标,并将地址匹配结果定位到地图上,通过制作热力图实现大气污染舆情信息的空间化。地址匹配时,根据提取的地名和机构名的情况,主要包括以下3种组合情况:①若解析后的词性只有地名没有机构名,则只对地名进行地址匹配;②若解析后的词性只有机构名没有地名,则只对机构名进行地址匹配;③若既有地名也有机构名,则对机构名和地名进行判断:机构名中如果包含地名,则选择机构名进行地址匹配,如果不包含则通过“地名+机构名”的方法进行地址匹配。
3 实例分析
3.1 舆情信息空间化
本文选取了山东省环境保护厅公众投诉平台上的2017年2月到2018年10月共5 000条公众投诉 信息,按照前述大气质量舆情信息空间化方法对这些数据进行了处理和分析,以区县为单元进行了统计,并运用GIS的核密度分析功能,制作了山东省大气污染投诉热力分布图,通过空间化结果可以看出,公众投诉的重点区域主要是淄博、潍坊、济南、莱芜以及枣庄等地市,东部沿海地区的总体情况较好,但是也有一些公众投诉比较集中的地方,如青岛、烟台等地市的市区范围。
3.2 舆情空间化分析结果与发布数据对比
为了验证舆情空间化分析结果与权威机构或部门发布数据的一致性,本文获取了山东省生态环境厅发布的2017年山东省17地市空气质量排名(见表2)和山东省2018年4月-10月综合空气指数排名(见图2),从与表2、图2的对比中可以看出,公众舆情数据分析结果和权威机构发布的结果基本一致,只有鲁西北和鲁西南地区的情况与权威机构发布的数据有所偏差,其原因可能与当地公众的维权意识和地区经济发展状况有关。

表2 2017年山东省各市空气质量排名Tab.2 Air Quality Ranking of Cities in Shandong Province in 2017
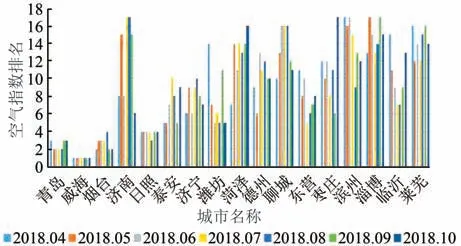
图2 山东省2018年4月-10月综合空气指数排名Fig.2 Shandong Province Comprehensive Air Index Rankings from April to October 2018
3.3 舆情信息市级对比分析
根据公众投诉数据的投诉类别分析,公众投诉内容主要集中在工矿企业的废气排放,尤其是一些空气质量较差的城市,废气排放占很大一部分比重,如投诉比较严重的淄博市。图3为从山东省生态环境厅获取的与公众投诉舆情数据时间同步的淄博市空气质量综合指数(air quality index,AQI)的月际变化趋势数据,通过图3可以看出,淄博市空气质量指数呈现一定的周期性变化,尤其在12月份致次年的1月份,大气污染最为严重,通过与公众投诉数据的对比分析,也反映了公众投诉情况在这个期间也最为集中。

图3 淄博市2017年2月-2018年10月空气质量数据图Fig.3 Zibo City Air Quality Data Map from February 2017 to October 2018
另外,国家发布的各地市的空气质量状况数据大多来自于国控监测站点,这些站点分布相对稀疏,因而针对一些局域性大气污染事件无法有效地发现。如图4所示,烟台市的监测站点主要分布在东北部沿海地区,这些站点监测的烟台市总体城市空气质量状况在山东省排名第2,全国排名123。而从图2烟台区域可以看出有投诉集中分布的情况,并且在莱州有化工污染和粉尘污染投诉较为集中的情形,这说明当地存在企业非法排放有毒有害气体和非法采矿事件的发生。因此,通过将公众投诉的舆情信息进行空间化,可有效反映较小时空尺度下的区域性大气污染状况,可实现对国控监测站点监测结果的强有力补充。

图4 烟台市空气质量监测站点分布Fig.4 Distribution of Air Quality Monitoring Stations in Yantai City
4 结束语
针对国控监测站点无法有效监测较小时空尺度下的区域性大气污染事件,本文提出了基于自然语言处理的大气质量舆情数据的空间化方法,通过对舆情数据进行中文分词、词性标注、地址匹配等处理过程,以热力图或核密度图的方式实现了公众投诉数据的空间定位与转化,通过进一步与国家权威部门发布的污染结果数据的对比分析,表明本文提出的方法能够从更细尺度上实现对大气污染状况的动态监测,能够有效提高公众对大气质量监控的参与度,可为国控监测站点的大气环境监测提供有益的补充。
猜你喜欢
农业灾害研究(2022年2期)2022-05-31
中国集体经济(2022年9期)2022-04-12
杂技与魔术(2022年1期)2022-03-16
红蜻蜓(2021年11期)2021-12-03
消费电子(2016年12期)2017-01-19
网络传播(2014年12期)2015-03-16
网络传播(2014年11期)2015-01-14
